SAS - konkatenacja zbiorów danych
Wiele zestawów danych SAS może zostać połączonych w celu uzyskania jednego zestawu danych przy użyciu rozszerzenia SETkomunikat. Całkowita liczba obserwacji w połączonym zbiorze danych jest sumą liczby obserwacji w oryginalnych zbiorach danych. Kolejność obserwacji jest sekwencyjna. Po wszystkich obserwacjach z pierwszego zestawu danych następują wszystkie obserwacje z drugiego zestawu danych i tak dalej.
W idealnym przypadku wszystkie łączone zestawy danych mają te same zmienne, ale w przypadku gdy mają różną liczbę zmiennych, w wyniku pojawiają się wszystkie zmienne z brakami wartości dla mniejszego zestawu danych.
Składnia
Podstawowa składnia instrukcji SET w SAS to -
SET data-set 1 data-set 2 data-set 3.....;Poniżej znajduje się opis użytych parametrów -
data-set1,data-set2 to nazwy zbiorów danych zapisywane jedna po drugiej.
Przykład
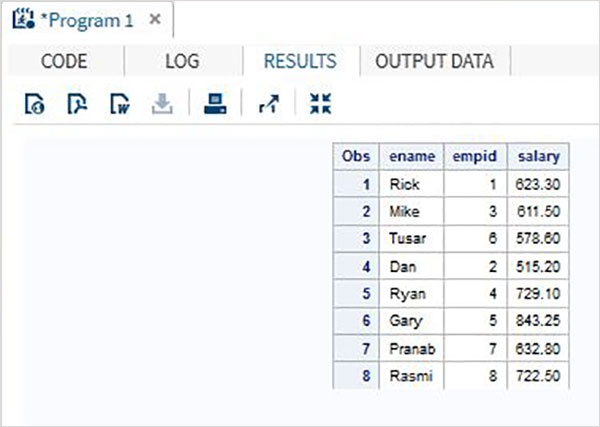
Weź pod uwagę dane pracowników organizacji, które są dostępne w dwóch różnych zestawach danych, jednym dla działu IT, a drugim dla działu Non-It. Aby uzyskać pełne dane wszystkich pracowników, łączymy oba zestawy danych za pomocą instrukcji SET, jak pokazano poniżej.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Scenariusze
Kiedy mamy wiele odmian w zestawach danych do konkatenacji, wynik zmiennych może się różnić, ale całkowita liczba obserwacji w połączonym zestawie danych jest zawsze sumą obserwacji w każdym zestawie danych. Poniżej rozważymy wiele scenariuszy dotyczących tej odmiany.
Różna liczba zmiennych
Jeśli jeden z oryginalnych zestawów danych ma większą liczbę zmiennych niż inny, to zestawy danych nadal są łączone, ale w mniejszym zestawie danych te zmienne pojawiają się jako brakujące.
Przykład
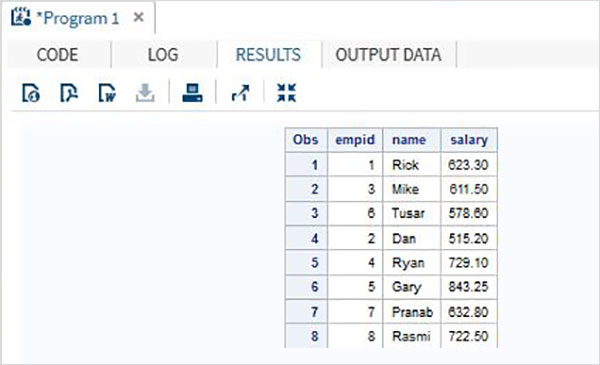
W poniższym przykładzie pierwszy zestaw danych ma dodatkową zmienną o nazwie DOJ. W rezultacie wartość DOJ dla drugiego zestawu danych pojawi się jako brakująca.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Inna nazwa zmiennej
W tym scenariuszu zbiory danych mają taką samą liczbę zmiennych, ale nazwa zmiennej jest między nimi inna. W takim przypadku zwykła konkatenacja da w wyniku wszystkie zmienne w zestawie wyników i da brakujące wyniki dla dwóch zmiennych, które się różnią. Chociaż nie możemy zmienić nazwy zmiennej w oryginalnych zestawach danych, możemy zastosować funkcję RENAME w utworzonym przez nas połączonym zestawie danych. To da ten sam wynik, co zwykłe konkatenacje, ale oczywiście z jedną nową nazwą zmiennej zamiast dwóch różnych nazw zmiennych obecnych w pierwotnym zbiorze danych.
Przykład
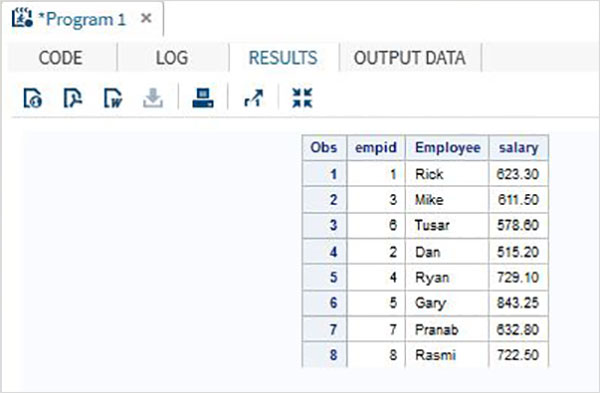
W poniższym przykładzie zbiór danych ITDEPT ma nazwę zmiennej ename natomiast zbiór danych NON_ITDEPT ma nazwę zmiennej empname.Ale obie te zmienne reprezentują ten sam typ (znak). StosujemyRENAME funkcji w instrukcji SET, jak pokazano poniżej.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Różne długości o różnej długości
Jeśli zmienne długości w dwóch zestawach danych są różne, niż połączony zestaw danych będzie zawierał wartości, w których część danych zostanie obcięta dla zmiennej o mniejszej długości. Dzieje się tak, jeśli pierwszy zestaw danych ma mniejszą długość. Aby rozwiązać ten problem, zastosujemy większą długość do obu zestawów danych, jak pokazano poniżej.
Przykład
W poniższym przykładzie zmienna enamema długość 5 w pierwszym zestawie danych i 7 w drugim. Podczas konkatenacji stosujemy instrukcję LENGTH w połączonym zestawie danych, aby ustawić długość ename na 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.