SAS - Szybki przewodnik
SAS oznacza Statistical Analysis Software. Został stworzony w 1960 roku przez SAS Institute. Od 1 stycznia 1960 roku SAS był używany do zarządzania danymi, Business Intelligence, Predictive Analysis, Descriptive and Prescriptive Analysis itp. Od tego czasu do oprogramowania wprowadzono wiele nowych procedur statystycznych i komponentów.
Wraz z wprowadzeniem JMP (Jump) do statystyk SAS skorzystał z możliwości Graphical user Interfacektóry został wprowadzony na komputerach Macintosh. Jump jest zasadniczo używany w aplikacjach takich jak Six Sigma, projektowanie, kontrola jakości oraz inżynieria i analizy naukowe.
SAS jest niezależny od platformy, co oznacza, że możesz uruchomić SAS w dowolnym systemie operacyjnym, zarówno Linux, jak i Windows. SAS jest napędzany przez programistów SAS, którzy używają kilku sekwencji operacji na zbiorach danych SAS do tworzenia odpowiednich raportów do analizy danych.
Przez lata SAS dodawał liczne rozwiązania do swojego portfolio produktów. Posiada rozwiązania do zarządzania danymi, jakości danych, analizy dużych zbiorów danych, eksploracji tekstu, zarządzania oszustwami, nauk o zdrowiu itp. Możemy bezpiecznie założyć, że SAS ma rozwiązanie dla każdej domeny biznesowej.
Aby rzucić okiem na listę dostępnych produktów, odwiedź SAS Components
Dlaczego używamy SAS
SAS zasadniczo działa na dużych zbiorach danych. Za pomocą oprogramowania SAS można wykonywać różne operacje na danych, takie jak -
- Zarządzanie danymi
- Analiza statystyczna
- Tworzenie raportów z doskonałą grafiką
- Planowanie biznesu
- Badania operacyjne i zarządzanie projektami
- Polepszanie jakości
- Tworzenie aplikacji
- Ekstrakcja danych
- Transformacja danych
- Aktualizacja i modyfikacja danych
Jeśli mówimy o komponentach SAS, to ponad 200 komponentów jest dostępnych w SAS.
| Sr.No. | Komponent SAS i ich użycie |
|---|---|
| 1 | Base SAS Jest to podstawowy komponent zawierający narzędzie do zarządzania danymi i język programowania do analizy danych. Jest również najczęściej stosowany. |
| 2 | SAS/GRAPH Twórz wykresy, prezentacje, aby lepiej zrozumieć i zaprezentować wynik w odpowiednim formacie. |
| 3 | SAS/STAT Wykonaj analizę statystyczną z analizą wariancji, regresją, analizą wielu zmiennych, analizą przeżycia i analizą psychometryczną, analizą modelu mieszanego. |
| 4 | SAS/OR Badania operacyjne. |
| 5 | SAS/ETS Ekonometria i analiza szeregów czasowych. |
| 6 | SAS/IML C Interaktywny język macierzy. |
| 7 | SAS/AF Placówka aplikacji. |
| 8 | SAS/QC Kontrola jakości. |
| 9 | SAS/INSIGHT Eksploracja danych. |
| 10 | SAS/PH Analiza badań klinicznych. |
| 11 | SAS/Enterprise Miner Eksploracja danych. |
Rodzaje oprogramowania SAS
- Windows lub PC SAS
- SAS EG (przewodnik dla przedsiębiorstw)
- SAS EM (Enterprise Miner, czyli analiza predykcyjna)
- Środki SAS
- SAS Stats
Najczęściej używamy Window SAS zarówno w organizacji, jak iw instytucie szkoleniowym. Niektóre organizacje używają Linuksa, ale nie ma graficznego interfejsu użytkownika, więc do każdego zapytania trzeba pisać kod. Ale w oknie SAS dostępnych jest wiele narzędzi, które bardzo pomagają programistom, a także skracają czas pisania kodów.
Okno SaS składa się z 5 części.
| Sr.No. | Okno SAS i ich użycie |
|---|---|
| 1 | Log Window Okno dziennika przypomina okno wykonywania, w którym możemy sprawdzić działanie programu SAS. W tym oknie możemy również sprawdzić błędy. Bardzo ważne jest każdorazowe sprawdzanie okna dziennika po uruchomieniu programu. Abyśmy mogli właściwie zrozumieć działanie naszego programu. |
| 2 | Editor Window
Okno edytora to ta część SAS, w której piszemy wszystkie kody. To jest jak notatnik. |
| 3 | Output Window Okno wyjściowe to okno wyników, w którym możemy zobaczyć wyjście naszego programu. |
| 4 | Result Window Jest jak indeks wszystkich wyników. Wszystkie programy, które uruchomiliśmy w jednej sesji SAS-a, są tam wymienione i możesz otworzyć wyjście, klikając wynik wyjściowy. Ale wspomina się o nich tylko na jednej sesji SAS. Jeśli zamkniemy oprogramowanie, a następnie je otworzymy, okno wyników będzie puste. |
| 5 | Explore Window Tutaj wszystkie wymienione biblioteki. Możesz również przeglądać pliki obsługiwane przez system SAS z tego miejsca. |
Biblioteki w SAS
Biblioteki są jak magazyny w SAS. Możesz utworzyć bibliotekę i zapisać w niej wszystkie podobne programy. SAS zapewnia możliwość tworzenia wielu bibliotek. Biblioteka SAS ma tylko 8 znaków.
W SAS są dostępne dwa typy bibliotek -
| Sr.No. | Okno SAS i ich użycie |
|---|---|
| 1 | Temporary or Work Library To jest domyślna biblioteka SAS. Wszystkie programy, które tworzymy, są przechowywane w tej bibliotece roboczej, jeśli nie przypiszemy do nich żadnej innej biblioteki. Możesz sprawdzić tę bibliotekę roboczą w oknie eksploracji. Jeśli utworzysz program SAS i nie przypiszesz do niego żadnej stałej biblioteki, to jeśli po tym zakończysz sesję, ponownie uruchomisz oprogramowanie, wówczas ten program nie będzie w bibliotece roboczej. Ponieważ będzie tam w Bibliotece Work tylko tak długo, jak długo sesja będzie trwała. |
| 2 | Permanent Library To są biblioteki stałe SAS. Możemy stworzyć nową bibliotekę SAS za pomocą narzędzi SAS lub pisząc kody w oknie edytora. Te biblioteki są nazywane jako trwałe, ponieważ jeśli utworzymy program w SAS i zapiszemy go w tych stałych bibliotekach, będą one dostępne tak długo, jak będziemy ich potrzebować. |
SAS Institute Inc. wydał darmowy SAS University Editionco jest wystarczająco dobre do nauki programowania w SAS. Zapewnia wszystkie funkcje, których potrzebujesz nauczyć się programowania BASE SAS, co z kolei umożliwia naukę dowolnego innego komponentu SAS.
Proces pobierania i instalacji SAS University Edition jest bardzo prosty. Jest dostępny jako maszyna wirtualna, która musi działać w środowisku wirtualnym. Aby móc uruchomić oprogramowanie SAS, musisz mieć już zainstalowane oprogramowanie do wirtualizacji na swoim komputerze. W tym samouczku będziemy używaćVMware. Poniżej znajdują się szczegółowe informacje dotyczące czynności pobierania, konfigurowania środowiska SAS i weryfikacji instalacji.
Pobierz SAS University Edition
SAS University Editionjest dostępny do pobrania pod adresem URL SAS University Edition . Przed rozpoczęciem pobierania przewiń w dół, aby przeczytać wymagania systemowe. Po odwiedzeniu tego adresu URL pojawia się następujący ekran.
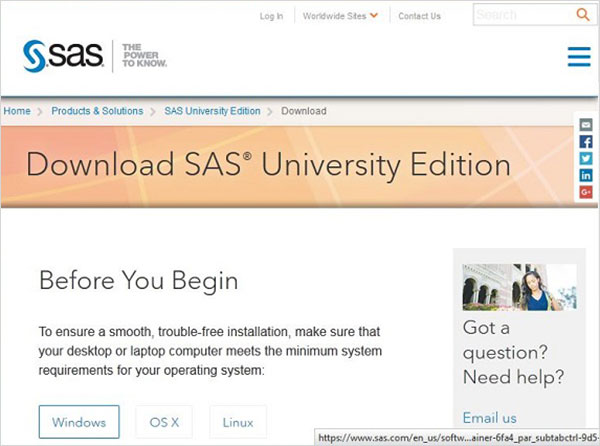
Skonfiguruj oprogramowanie do wirtualizacji
Przewiń w dół na tej samej stronie, aby zlokalizować stpe-1 instalacji. W tym kroku znajdują się łącza umożliwiające pobranie odpowiedniego oprogramowania do wirtualizacji. Jeśli masz już zainstalowane jedno z tych programów w swoim systemie, możesz pominąć ten krok.

Oprogramowanie do szybkiego uruchamiania wirtualizacji
Jeśli jesteś zupełnie nowy w środowisku wirtualizacji, możesz zapoznać się z nim, przeglądając następujące przewodniki i filmy dostępne jako krok-2. Ponownie możesz pominąć ten krok, jeśli już wiesz.

Pobierz plik ZIP
W kroku 3 możesz wybrać odpowiednią wersję SAS University Edition zgodną z posiadanym środowiskiem wirtualizacji. Pobiera się jako plik zip o nazwie podobnej do unvbasicvapp__9411005__vmx__en__sp0__1.zip
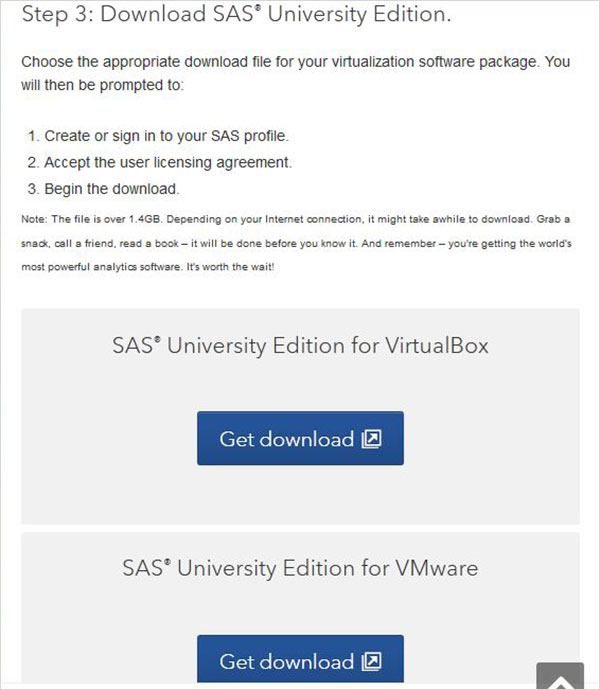
Rozpakuj plik zip
Powyższy plik zip należy rozpakować i zapisać w odpowiednim katalogu. W naszym przypadku wybraliśmy plik zip VMware, który po rozpakowaniu pokazuje następujące pliki.
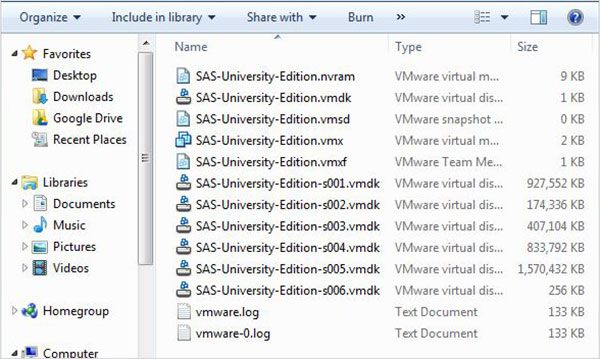
Ładowanie maszyny wirtualnej
Uruchom odtwarzacz VMware (lub stację roboczą) i otwórz plik z rozszerzeniem .vmx. Pojawi się poniższy ekran. Zwróć uwagę na podstawowe ustawienia, takie jak pamięć i miejsce na dysku twardym przydzielone do maszyny wirtualnej.
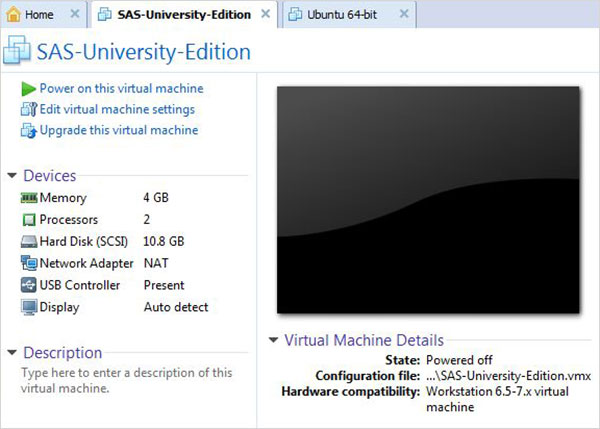
Włącz maszynę wirtualną
Kliknij Power on this virtual machineobok zielonego znaku strzałki, aby uruchomić maszynę wirtualną. Pojawi się następujący ekran.

Poniższy ekran pojawia się, gdy maszyna wirtualna SAS jest w stanie ładowania, po czym uruchomiona maszyna wirtualna wyświetla monit o przejście do lokalizacji adresu URL, która otworzy środowisko SAS.
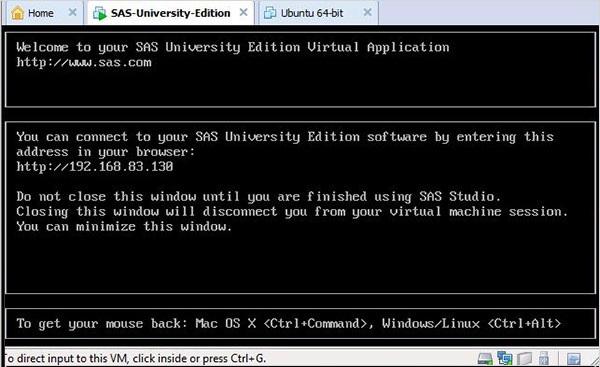
Uruchomienie studia SAS
Otwórz nową kartę przeglądarki i załaduj powyższy adres URL (który różni się w zależności od komputera). Pojawi się poniższy ekran wskazujący, że środowisko SAS jest gotowe.
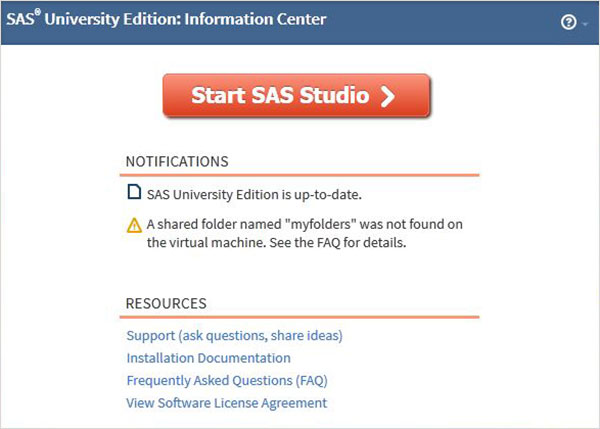
Środowisko SAS
Po kliknięciu Start SAS Studio otrzymujemy środowisko SAS, które domyślnie otwiera się w trybie wizualnego programisty, jak pokazano poniżej.
Możemy również zmienić go na tryb programisty SAS, klikając listę rozwijaną.
Teraz jesteśmy gotowi do pisania programów SAS.
Programy SAS są tworzone przy użyciu interfejsu użytkownika znanego jako SAS Studio.
Poniżej znajduje się opis różnych okien i ich zastosowania.
Główne okno SAS
To jest okno, które widzisz po wejściu do środowiska SAS. Po lewej stronie jestNavigation Panesłuży do poruszania się po różnych funkcjach programowania. Po prawej jestWork Area który jest używany do pisania kodu i wykonywania go.

Autouzupełnianie kodu
Jest to bardzo potężna funkcja, która pomaga uzyskać poprawną składnię słów kluczowych SAS, a także zapewnia łącze do dokumentacji tego słowa kluczowego.
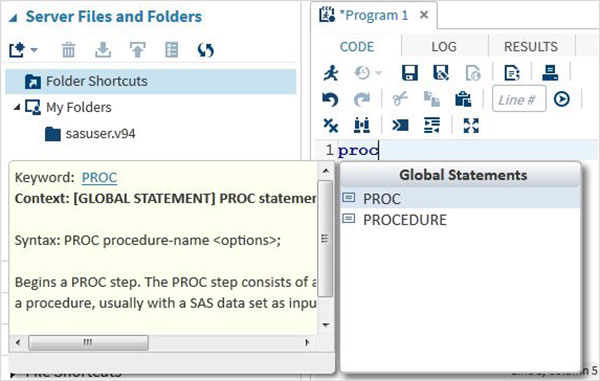
Wykonanie programu
Wykonanie kodu odbywa się poprzez naciśnięcie ikony uruchamiania, która jest pierwszą ikoną od lewej lub przycisku F3.
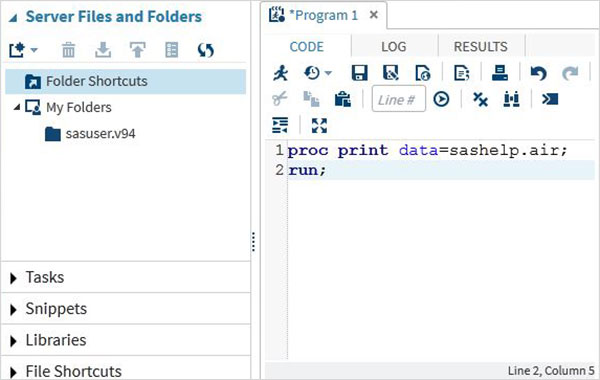
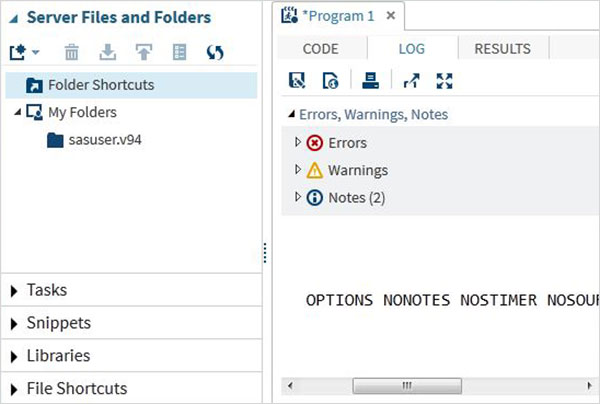
Dziennik programu
Dziennik wykonanego kodu jest dostępny pod adresem Logpatka. Opisuje błędy, ostrzeżenia lub uwagi dotyczące wykonania programu. To jest okno, w którym otrzymujesz wszystkie wskazówki dotyczące rozwiązywania problemów z kodem.
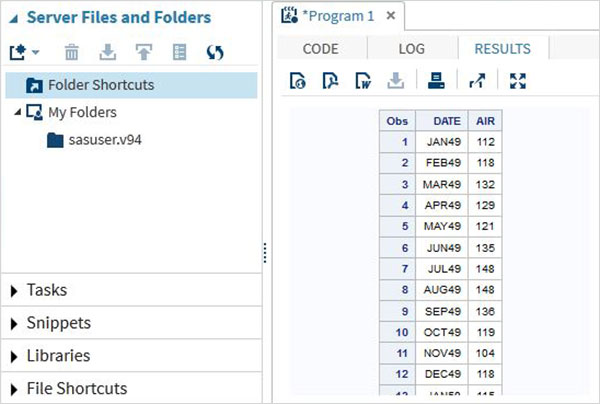
Wynik programu
Wynik wykonania kodu widoczny jest w zakładce WYNIKI. Domyślnie są one sformatowane jako tabele html.
Zakładki programów
Obszar nawigacji zawiera funkcje do tworzenia programów i zarządzania nimi. Zapewnia również gotowe funkcje, których można używać z programem.
Pliki i foldery na serwerze
W tej zakładce możemy tworzyć dodatkowe programy, importować dane do analizy oraz przeszukiwać istniejące dane. Może być również używany do tworzenia skrótów do folderów.
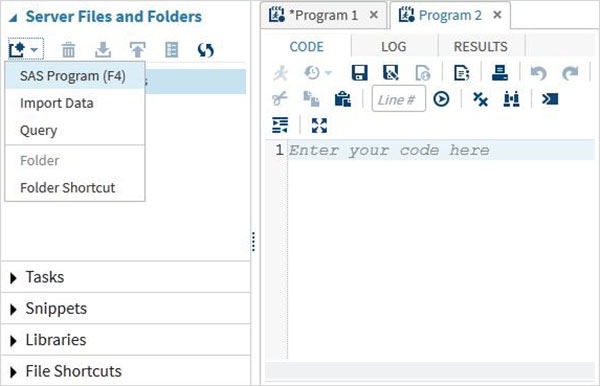
Zadania
Karta Zadania udostępnia funkcje umożliwiające korzystanie z wbudowanych programów SAS-owych, dostarczając tylko zmienne wejściowe. Na przykład w folderze statystyk można znaleźć program SAS do wykonywania regresji liniowej, podając tylko nazwę zestawu danych SAS i nazwy zmiennych.
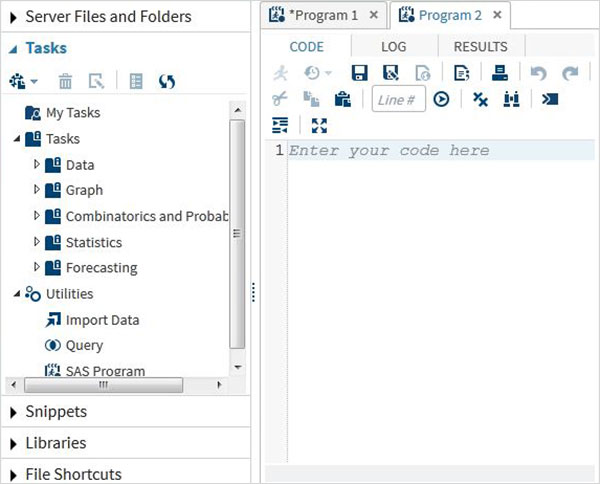
Fragmenty
Karta snippets zapewnia funkcje do pisania makr SAS i generowania plików na podstawie istniejącego zestawu danych

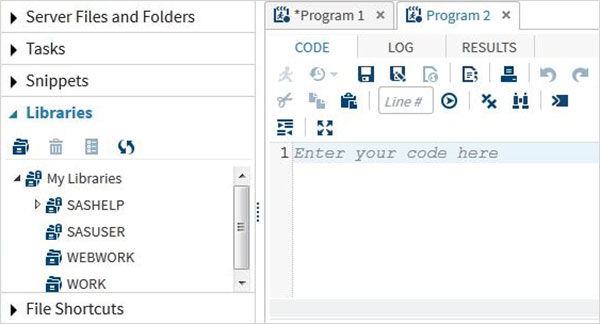
Biblioteki programów
SAS przechowuje zestawy danych w bibliotekach SAS. Biblioteka tymczasowa jest dostępna tylko dla jednej sesji i nosi nazwę WORK. Ale biblioteki stałe są zawsze dostępne.
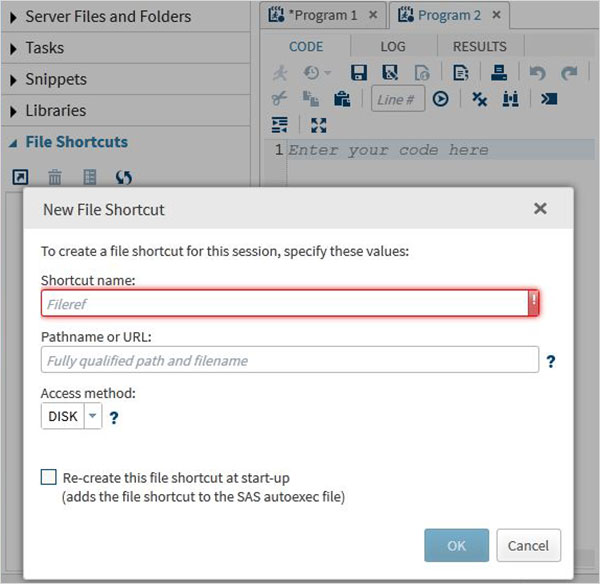
Skróty do plików
Ta karta służy do uzyskiwania dostępu do plików przechowywanych poza środowiskiem SAS. Skróty do takich plików są przechowywane w tej zakładce.
Programowanie w SAS obejmuje najpierw utworzenie / odczytanie zestawów danych do pamięci, a następnie wykonanie analizy tych danych. Aby to osiągnąć, musimy zrozumieć przepływ, w jakim program jest napisany.
Struktura programu SAS
Poniższy diagram przedstawia kroki, które należy zapisać w podanej kolejności, aby utworzyć program SAS.
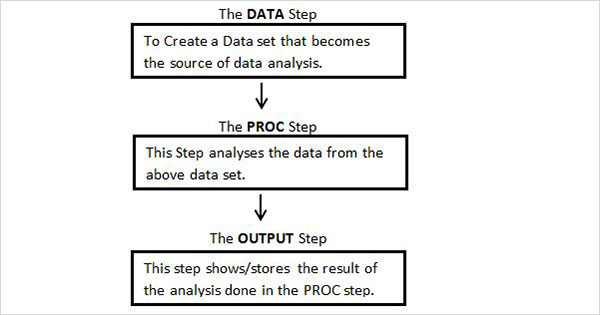
Każdy program SAS musi mieć wszystkie te kroki, aby zakończyć odczytywanie danych wejściowych, analizowanie danych i przedstawianie wyników analizy. RównieżRUN oświadczenie na końcu każdego kroku jest wymagane do zakończenia wykonywania tego kroku.
DANE Krok
Ten krok obejmuje załadowanie wymaganego zestawu danych do pamięci SAS i identyfikację zmiennych (zwanych także kolumnami) zestawu danych. Przechwytuje również zapisy (zwane również obserwacjami lub tematami). Składnia instrukcji DATA jest następująca.
Składnia
DATA data_set_name; #Name the data set.
INPUT var1,var2,var3; #Define the variables in this data set.
NEW_VAR; #Create new variables.
LABEL; #Assign labels to variables.
DATALINES; #Enter the data.
RUN;Przykład
Poniższy przykład przedstawia prosty przypadek nazwania zbioru danych, zdefiniowania zmiennych, tworzenia nowych zmiennych i wprowadzania danych. Tutaj zmienne łańcuchowe mają na końcu znak $, a wartości liczbowe są bez niego.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
comm = SALARY*0.25;
LABEL ID = 'Employee ID' comm = 'COMMISION';
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;PROC Krok
Ten krok obejmuje wywołanie wbudowanej procedury sygnatury dostępu Współdzielonego w celu przeanalizowania danych.
Składnia
PROC procedure_name options; #The name of the proc.
RUN;Przykład
Poniższy przykład pokazuje użycie MEANS procedura drukowania średnich wartości zmiennych numerycznych w zestawie danych.
PROC MEANS;
RUN;Krok OUTPUT
Dane ze zbiorów danych można wyświetlić za pomocą warunkowych instrukcji wyjściowych.
Składnia
PROC PRINT DATA = data_set;
OPTIONS;
RUN;Przykład
Poniższy przykład pokazuje użycie klauzuli where w danych wyjściowych w celu uzyskania tylko kilku rekordów ze zbioru danych.
PROC PRINT DATA = TEMP;
WHERE SALARY > 700;
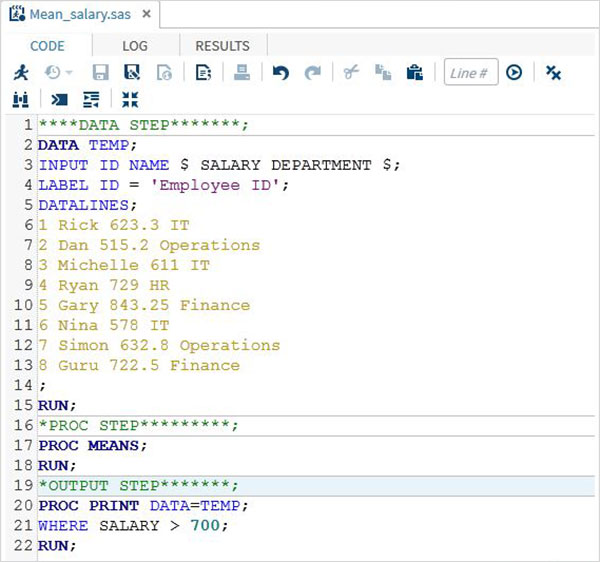
RUN;Kompletny program SAS
Poniżej znajduje się pełny kod dla każdego z powyższych kroków.
Wyjście programu
RESULTS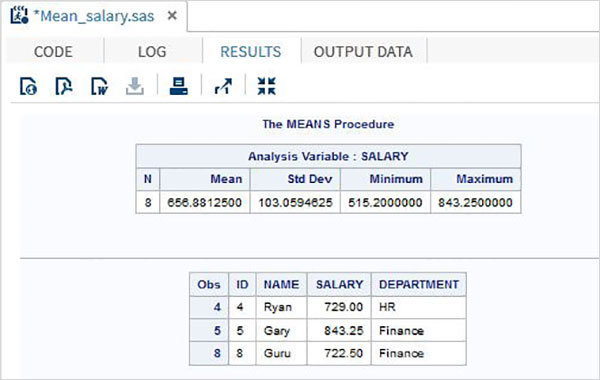
Jak każdy inny język programowania, język SAS ma swoje własne reguły składni do tworzenia programów SAS.
Trzy składniki dowolnego programu SAS - instrukcje, zmienne i zbiory danych są zgodne z poniższymi zasadami dotyczącymi składni.
Oświadczenia SAS
Oświadczenia mogą zaczynać się w dowolnym miejscu i kończyć w dowolnym miejscu. Średnik na końcu ostatniej linii oznacza koniec instrukcji.
Wiele instrukcji SAS może znajdować się w tym samym wierszu, a każda instrukcja kończy się średnikiem.
Przestrzeń można wykorzystać do oddzielenia komponentów w instrukcji programu SAS.
Słowa kluczowe SAS nie uwzględniają wielkości liter.
Każdy program w SAS musi kończyć się instrukcją RUN.
Nazwy zmiennych SAS
Zmienne w SAS reprezentują kolumnę w zestawie danych SAS. Nazwy zmiennych są zgodne z poniższymi zasadami.
Może mieć maksymalnie 32 znaki.
Nie może zawierać spacji.
Musi zaczynać się od liter od A do Z (bez rozróżniania wielkości liter) lub podkreślenia (_).
Może zawierać cyfry, ale nie jako pierwszy znak.
W nazwach zmiennych wielkość liter nie jest rozróżniana.
Przykład
# Valid Variable Names
REVENUE_YEAR
MaxVal
_Length
# Invalid variable Names
Miles Per Liter #contains Space.
RainfFall% # contains apecial character other than underscore.
90_high # Starts with a number.Zestaw danych SAS
Instrukcja DATA oznacza utworzenie nowego zestawu danych SAS. Zasady tworzenia zestawu DANYCH są następujące.
Pojedyncze słowo po instrukcji DATA wskazuje tymczasową nazwę zestawu danych. Oznacza to, że zestaw danych zostaje usunięty na koniec sesji.
Nazwa zestawu danych może być poprzedzona nazwą biblioteki, co czyni go stałym zestawem danych. Oznacza to, że zestaw danych utrzymuje się po zakończeniu sesji.
Jeśli nazwa zestawu danych SAS zostanie pominięta, SAS tworzy tymczasowy zestaw danych o nazwie wygenerowanej przez SAS, takiej jak - DATA1, DATA2 itp.
Przykład
# Temporary data sets.
DATA TempData;
DATA abc;
DATA newdat;
# Permanent data sets.
DATA LIBRARY1.DATA1
DATA MYLIB.newdat;Rozszerzenia plików SAS
Programy SAS, pliki danych i wyniki programów są zapisywane z różnymi rozszerzeniami w oknach.
*.sas - Reprezentuje plik kodu SAS, który można edytować za pomocą edytora SAS lub dowolnego edytora tekstu.
*.log - Reprezentuje plik dziennika SAS, zawiera informacje, takie jak błędy, ostrzeżenia i szczegóły zestawu danych dla przesłanego programu SAS.
*.mht / *.html −To reprezentuje plik wyników SAS.
*.sas7bdat - Reprezentuje plik danych SAS, który zawiera zestaw danych SAS, w tym nazwy zmiennych, etykiety i wyniki obliczeń.
Komentarze w SAS
Komentarze w kodzie SAS są określane na dwa sposoby. Poniżej znajdują się te dwa formaty.
*wiadomość; wpisz komentarz
Komentarz w formie *message;nie może zawierać wewnątrz średników ani niedopasowanych cudzysłowów. W takich komentarzach nie powinno być również żadnych odniesień do makr. Może obejmować wiele linii i może mieć dowolną długość. Poniżej znajduje się przykład komentarza w jednym wierszu -
* This is comment ;Poniżej znajduje się przykład wielowierszowego komentarza -
* This is first line of the comment
* This is second line of the comment;/ * wiadomość * / wpisz komentarz
Komentarz w formie /*message*/jest używany częściej i nie można go zagnieżdżać. Ale może obejmować wiele linii i może mieć dowolną długość. Poniżej znajduje się przykład komentarza w jednym wierszu -
/* This is comment */Poniżej znajduje się przykład wielowierszowego komentarza -
/* This is first line of the comment
* This is second line of the comment */Dane, które są dostępne dla programu SAS do analizy, są określane jako zbiór danych SAS. Jest tworzony za pomocą kroku DATA.SAS może odczytywać różne pliki jako źródła danychCSV, Excel, Access, SPSS and also raw data. Posiada również wiele wbudowanych źródeł danych dostępnych do użycia.
Zestawy danych noszą nazwę temporary Data Set jeśli są używane przez program SAS, a następnie odrzucane po uruchomieniu sesji.
Ale jeśli jest przechowywany na stałe do przyszłego użytku, nazywa się go permanent Data set. Wszystkie stałe zbiory danych są przechowywane w określonej bibliotece.
Zestaw danych SAS jest przechowywany w postaci wierszy i kolumn, a także nazywany tabelą danych SAS. Poniżej widzimy przykłady stałych zestawów danych, które są wbudowane i czerwone ze źródeł zewnętrznych.
Wbudowane zestawy danych SAS
Te zbiory danych są już dostępne w zainstalowanym oprogramowaniu SAS. Można je badać i wykorzystywać do formułowania przykładowych wyrażeń do analizy danych. Aby zbadać te zestawy danych, przejdź doLibraries -> My Libraries -> SASHELP. Po rozwinięciu widzimy listę nazw wszystkich dostępnych wbudowanych zbiorów danych.
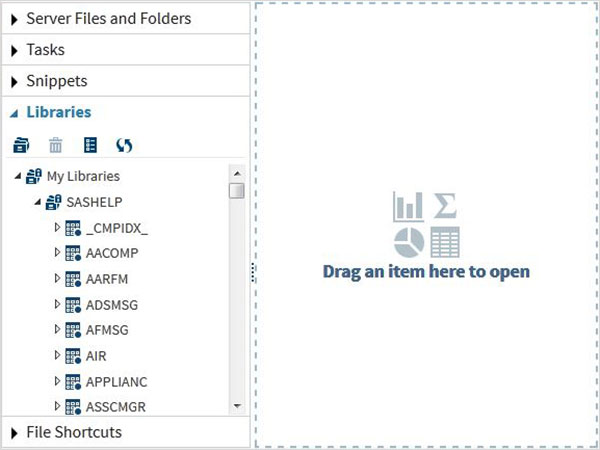
Przewiń w dół, aby znaleźć nazwany zbiór danych CARSDwukrotne kliknięcie tego zbioru danych otwiera go w prawym panelu, gdzie możemy go dokładniej zbadać. Możemy również zminimalizować lewy panel, używając przycisku maksymalizacji widoku pod prawym panelem.
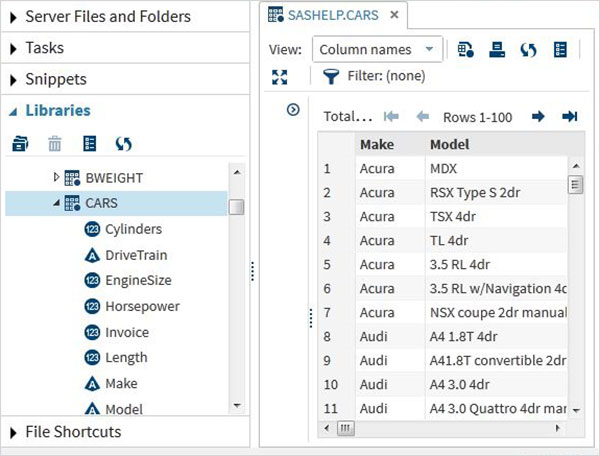
Możemy przewinąć w prawo za pomocą paska przewijania na dole, aby zbadać wszystkie kolumny i ich wartości w tabeli.
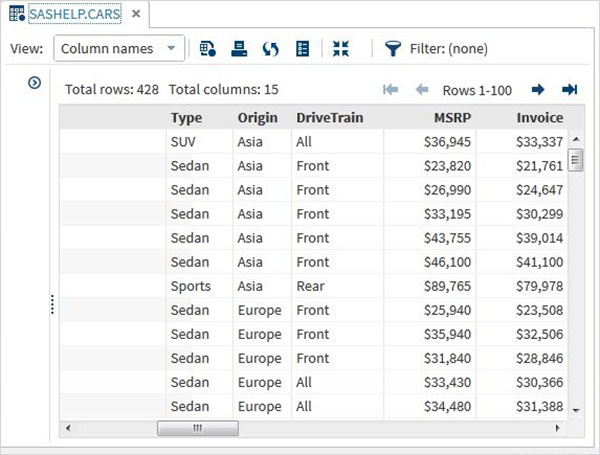
Importowanie zewnętrznych zestawów danych
Możemy eksportować własne pliki jako zestawy danych, korzystając z funkcji importu dostępnej w SAS Studio. Ale te pliki muszą być dostępne w folderach serwera SAS. Musimy więc przesłać źródłowe pliki danych do folderu SAS, korzystając z opcji przesyłania w ramachServer Files and Folders.
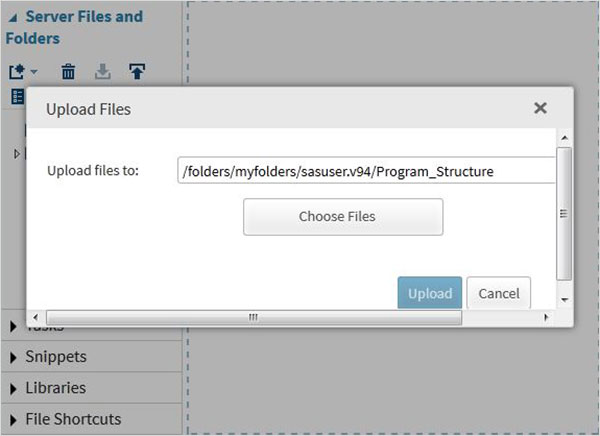
Następnie używamy powyższego pliku w programie SAS, importując go. W tym celu korzystamy z opcjiTasks -> Utilities -> Import data jak pokazano niżej. Kliknij dwukrotnie przycisk Importuj dane, który otwiera okno po prawej stronie, aby wybrać plik dla zbioru danych.
Dalej Kliknij Select Filespod programem importu danych w prawym panelu. Poniżej znajduje się lista typów plików, które można importować.
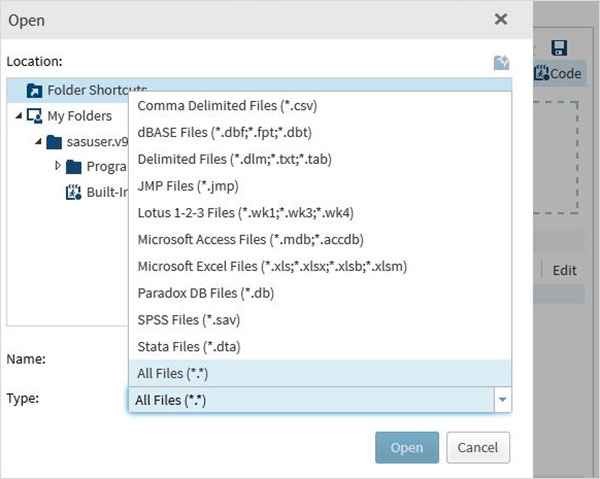
Wybieramy plik „worker.txt” przechowywany w systemie lokalnym i importujemy plik, jak pokazano poniżej.
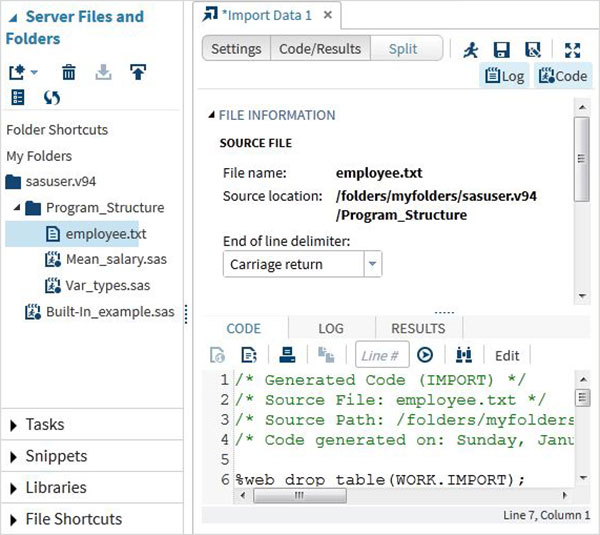
Wyświetl zaimportowane dane
Możemy wyświetlić zaimportowane dane, uruchamiając domyślny kod importu wygenerowany za pomocą opcji Uruchom
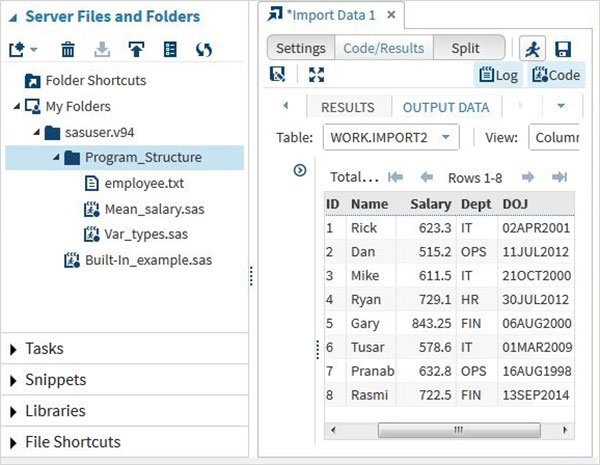
Możemy importować dowolne inne typy plików, używając tego samego podejścia, co powyżej i używać go w różnych programach SAS.
Ogólnie zmienne w SAS reprezentują nazwy kolumn tabel danych, które analizuje. Ale może być również używany do innych celów, takich jak używanie go jako licznika w pętli programowania. W bieżącym rozdziale zobaczymy użycie zmiennych SAS jako nazw kolumn zestawu danych SAS.
Typy zmiennych SAS
SAS ma trzy typy zmiennych, jak poniżej -
Zmienne liczbowe
To jest domyślny typ zmiennej. Te zmienne są używane w wyrażeniach matematycznych.
Składnia
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.W powyższej składni instrukcja INPUT przedstawia deklarację zmiennych numerycznych.
Przykład
INPUT ID SALARY COMM_PERCENT;Zmienne znaków
Zmienne znakowe są używane dla wartości, które nie są używane w wyrażeniach matematycznych. Są traktowane jako tekst lub ciągi. Zmienna staje się zmienną znakową poprzez dodanie znaku $ sing ze spacją na końcu nazwy zmiennej.
Składnia
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.W powyższej składni instrukcja INPUT przedstawia deklarację zmiennych znakowych.
Przykład
INPUT FNAME $ LNAME $ ADDRESS $;Zmienne daty
Te zmienne są traktowane tylko jako daty i muszą mieć prawidłowe formaty daty. Zmienna staje się zmienną daty poprzez dodanie formatu daty ze spacją na końcu nazwy zmiennej.
Składnia
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.W powyższej składni instrukcja INPUT przedstawia deklarację zmiennych daty.
Przykład
INPUT DOB DATE11. START_DATE MMDDYY10. ;Używanie zmiennych w programie SAS
Powyższe zmienne są używane w programie SAS, jak pokazano w poniższych przykładach.
Przykład
Poniższy kod pokazuje, w jaki sposób trzy typy zmiennych są deklarowane i używane w programie SAS
DATA TEMP;
INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ;
FORMAT DOJ DATE9. ;
DATALINES;
1 Rick 623.3 IT 02APR2001
2 Dan 515.2 OPS 11JUL2012
3 Michelle 611 IT 21OCT2000
4 Ryan 729 HR 30JUL2012
5 Gary 843.25 FIN 06AUG2000
6 Tusar 578 IT 01MAR2009
7 Pranab 632.8 OPS 16AUG1998
8 Rasmi 722.5 FIN 13SEP2014
;
PROC PRINT DATA = TEMP;
RUN;W powyższym przykładzie zadeklarowano wszystkie zmienne znakowe, po których następuje znak $, a zmienne daty są zadeklarowane, a następnie format daty. Wynik powyższego programu jest następujący.
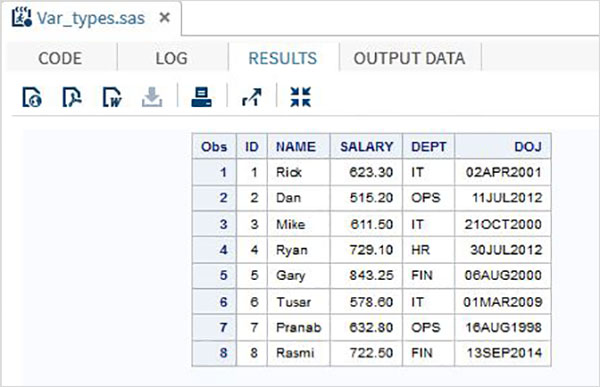
Korzystanie ze zmiennych
Zmienne są bardzo przydatne w analizie danych. Są używane w wyrażeniach, w których stosowana jest analiza statystyczna. Zobaczmy przykład analizy wbudowanego zestawu danych o nazwieCARS który jest obecny pod Libraries → My Libraries → SASHELP. Kliknij dwukrotnie, aby zbadać zmienne i ich typy danych.

Następnie możemy stworzyć podsumowanie statystyk niektórych z tych zmiennych, używając opcji Tasks w SAS Studio. Iść doTasks -> Statistics -> Summary Statisticsi kliknij go dwukrotnie, aby otworzyć okno, jak pokazano poniżej. Wybierz zbiór danychSASHELP.CARSi wybierz trzy zmienne - MPG_CITY, MPG_Highway i Weight w sekcji Analysis Variables. Przytrzymaj klawisz Ctrl podczas wybierania zmiennych, klikając. Kliknij Uruchom.

Kliknij kartę wyników po wykonaniu powyższych czynności. Przedstawia podsumowanie statystyczne trzech wybranych zmiennych. Ostatnia kolumna wskazuje liczbę obserwacji (rekordów) wykorzystanych w analizie.
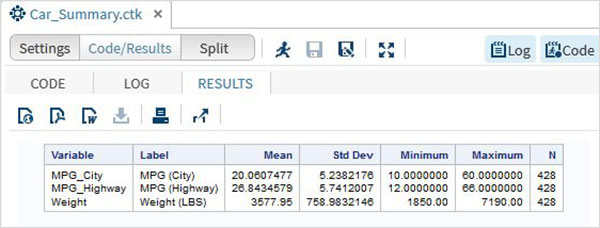
Łańcuchy w sygnaturze dostępu Współdzielonego to wartości ujęte w parę pojedynczych cudzysłowów. Również zmienne łańcuchowe są deklarowane poprzez dodanie spacji i znaku $ na końcu deklaracji zmiennej. SAS ma wiele zaawansowanych funkcji do analizowania i manipulowania łańcuchami.
Deklarowanie zmiennych łańcuchowych
Możemy zadeklarować zmienne łańcuchowe i ich wartości, jak pokazano poniżej. W poniższym kodzie deklarujemy dwie zmienne znakowe o długości 6 i 5. Słowo kluczowe LENGTH służy do deklarowania zmiennych bez tworzenia wielu obserwacji.
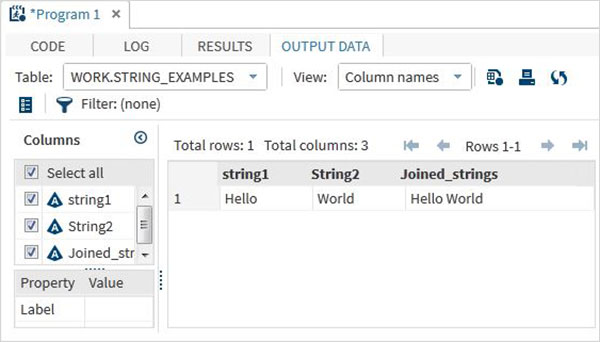
data string_examples;
LENGTH string1 $ 6 String2 $ 5;
/*String variables of length 6 and 5 */
String1 = 'Hello';
String2 = 'World';
Joined_strings = String1 ||String2 ;
run;
proc print data = string_examples noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy wyjście, które pokazuje nazwy zmiennych i ich wartości.
Funkcje łańcuchowe
Poniżej znajdują się przykłady niektórych funkcji SAS, które są często używane.
SUBSTRN
Ta funkcja wyodrębnia podciąg na podstawie pozycji początkowej i końcowej. W przypadku braku pozycji końcowej wyodrębnia wszystkie znaki do końca łańcucha.
Składnia
SUBSTRN('stringval',p1,p2)Poniżej znajduje się opis użytych parametrów -
- stringval jest wartością zmiennej łańcuchowej.
- p1 to pozycja początkowa ekstrakcji.
- p2 to ostateczna pozycja ekstrakcji.
Przykład
data string_examples;
LENGTH string1 $ 6 ;
String1 = 'Hello';
sub_string1 = substrn(String1,2,4) ;
/*Extract from position 2 to 4 */
sub_string2 = substrn(String1,3) ;
/*Extract from position 3 onwards */
run;
proc print data = string_examples noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy wyjście, które pokazuje wynik działania funkcji substrn.

TRIMN
Ta funkcja usuwa końcową spację z ciągu.
Składnia
TRIMN('stringval')Poniżej znajduje się opis użytych parametrów -
- stringval jest wartością zmiennej łańcuchowej.
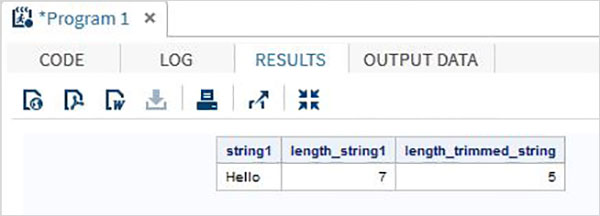
data string_examples;
LENGTH string1 $ 7 ;
String1='Hello ';
length_string1 = lengthc(String1);
length_trimmed_string = lengthc(TRIMN(String1));
run;
proc print data = string_examples noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy wyjście, które pokazuje wynik działania funkcji TRIMN.
Tablice w sygnaturze dostępu Współdzielonego są używane do przechowywania i pobierania serii wartości przy użyciu wartości indeksu. Indeks reprezentuje lokalizację w zarezerwowanym obszarze pamięci.
Składnia
W SAS tablica jest deklarowana przy użyciu następującej składni -
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUESW powyższej składni -
ARRAY jest słowem kluczowym SAS do deklarowania tablicy.
ARRAY-NAME to nazwa tablicy, która podlega tej samej zasadzie co nazwy zmiennych.
SUBSCRIPT to liczba wartości, które tablica będzie przechowywać.
($) jest opcjonalnym parametrem, który ma być używany tylko wtedy, gdy tablica ma przechowywać wartości znakowe.
VARIABLE-LIST to opcjonalna lista zmiennych, które są miejscami dla wartości tablicowych.
ARRAY-VALUESsą rzeczywistymi wartościami przechowywanymi w tablicy. Można je tutaj zadeklarować lub odczytać z pliku lub z linii danych.
Przykłady deklaracji tablicy
Tablice można deklarować na wiele sposobów, korzystając z powyższej składni. Poniżej znajdują się przykłady.
# Declare an array of length 5 named AGE with values.
ARRAY AGE[5] (12 18 5 62 44);
# Declare an array of length 5 named COUNTRIES with values starting at index 0.
ARRAY COUNTRIES(0:8) A B C D E F G H I;
# Declare an array of length 5 named QUESTS which contain character values.
ARRAY QUESTS(1:5) $ Q1-Q5;
# Declare an array of required length as per the number of values supplied.
ARRAY ANSWER(*) A1-A100;Dostęp do wartości tablicowych
Dostęp do wartości przechowywanych w tablicy można uzyskać za pomocą printprocedurę, jak pokazano poniżej. Po zadeklarowaniu za pomocą jednej z powyższych metod, dane są dostarczane za pomocą instrukcji DATALINES.
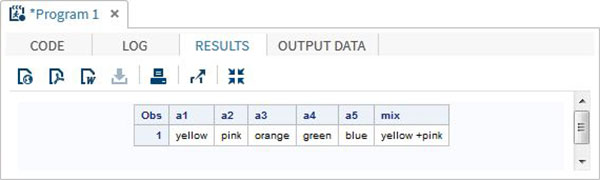
DATA array_example;
INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5;
mix = a1||'+'||a2;
DATALINES;
yello pink orange green blue
;
RUN;
PROC PRINT DATA = array_example;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
Korzystanie z operatora OF
Operator OF jest używany podczas analizy danych w postaci tablicy do wykonywania obliczeń na całym wierszu tablicy. W poniższym przykładzie stosujemy sumę i średnią wartości w każdym wierszu.
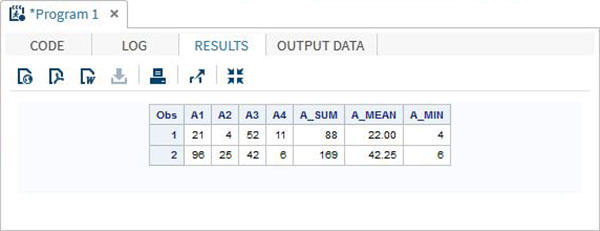
DATA array_example_OF;
INPUT A1 A2 A3 A4;
ARRAY A(4) A1-A4;
A_SUM = SUM(OF A(*));
A_MEAN = MEAN(OF A(*));
A_MIN = MIN(OF A(*));
DATALINES;
21 4 52 11
96 25 42 6
;
RUN;
PROC PRINT DATA = array_example_OF;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
Korzystanie z operatora IN
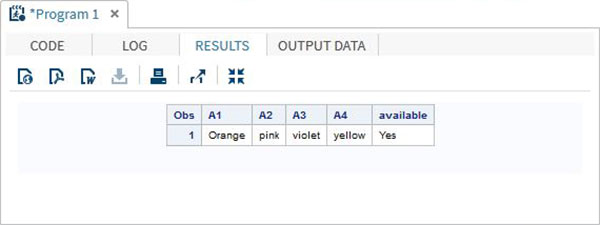
Dostęp do wartości w tablicy można również uzyskać za pomocą operatora IN, który sprawdza obecność wartości w wierszu tablicy. W poniższym przykładzie sprawdzamy dostępność koloru „Yellow” w danych. W tej wartości rozróżniana jest wielkość liter.
DATA array_in_example;
INPUT A1 $ A2 $ A3 $ A4 $;
ARRAY COLOURS(4) A1-A4;
IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No';
DATALINES;
Orange pink violet yellow
;
RUN;
PROC PRINT DATA = array_in_example;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
SAS obsługuje szeroką gamę formatów danych numerycznych. Używa tych formatów na końcu nazw zmiennych, aby zastosować określony format liczbowy do danych. SAS używa dwóch rodzajów formatów liczbowych. Jeden do odczytu określonych formatów danych numerycznych, który jest nazywanyinformat a drugi do wyświetlania danych liczbowych w określonym formacie zwanym as output format.
Składnia
Składnia dla informacji numerycznej to -
Varname Formatnamew.dPoniżej znajduje się opis użytych parametrów -
Varname to nazwa zmiennej.
Formatname to nazwa nazwy formatu liczbowego zastosowanego do zmiennej.
w to maksymalna liczba kolumn danych (w tym cyfry po przecinku i sama kropka dziesiętna), które mogą być przechowywane dla zmiennej.
d to liczba cyfr po prawej stronie przecinka.
Czytanie formatów liczbowych
Poniżej znajduje się lista formatów używanych do wczytywania danych do SAS.
Wprowadź formaty liczbowe
| Format | Posługiwać się |
|---|---|
| n. | Maksymalna liczba „n” kolumn bez separatora dziesiętnego. |
| n.p | Maksymalna liczba kolumn „n” z miejscami dziesiętnymi „p”. |
| COMMAn.p | Maksymalna liczba kolumn „n” z miejscami dziesiętnymi „p”, która usuwa wszelkie przecinki lub znaki dolara. |
| COMMAn.p | Maksymalna liczba kolumn „n” z miejscami dziesiętnymi „p”, która usuwa wszelkie przecinki lub znaki dolara. |
Wyświetlanie formatów liczbowych
Podobnie jak w przypadku stosowania formatu podczas odczytu danych, poniżej znajduje się lista formatów używanych do wyświetlania danych na wyjściu programu SAS.
Wyjściowe formaty liczbowe
| Format | Posługiwać się |
|---|---|
| n. | Wpisz maksymalną liczbę „n” cyfr bez separatora dziesiętnego. |
| n.p | Wpisz maksymalną liczbę kolumn „np” z separatorami dziesiętnymi „p”. |
| DOLLARn.p | Wpisz maksymalną liczbę „n” kolumn z miejscami dziesiętnymi p, wiodącymi znakami dolara i przecinkiem na tysięcznym miejscu. |
Uwaga -
Jeśli liczba cyfr po przecinku jest mniejsza niż specyfikator formatu, tozeros will be appended na końcu.
Jeśli liczba cyfr po przecinku jest większa niż specyfikator formatu, to ostatnia cyfra będzie rounded off.
Przykłady
Poniższe przykłady ilustrują powyższe scenariusze.
DATA MYDATA1;
input x 6.; /*maxiiuum width of the data*/
format x 6.3;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA1;
RUN;
DATA MYDATA2;
input x 6.; /*maximum width of the data*/
format x 5.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA2;
RUN;
DATA MYDATA3;
input x 6.; /*maximum width of the data*/
format x DOLLAR10.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA3;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
# MYDATA1.
Obs x
1 8722.0 # Display 6 columns with zero appended after decimal.
2 93.200 # Display 6 columns with zero appended after decimal.
3 0.112 # No integers before decimal, so display 3 available digits after decimal.
4 15.116 # Display 6 columns with 3 available digits after decimal.
# MYDATA2
Obs x
1 8722 # Display 5 columns. Only 4 are available.
2 93.20 # Display 5 columns with zero appended after decimal.
3 0.11 # Display 5 columns with 2 places after decimal.
4 15.12 # Display 5 columns with 2 places after decimal.
# MYDATA3
Obs x
1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal.
2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal.
4 $15.12 # Only 2 integers available before decimal and two available after the decimal.Operator w SAS to symbol używany w wyrażeniach matematycznych, logicznych lub porównawczych. Symbole te są wbudowane w język SAS i wiele operatorów można połączyć w jednym wyrażeniu, aby uzyskać ostateczny wynik.
Poniżej znajduje się lista operatorów kategorii SAS.
- Operatory arytmetyczne
- Operatory logiczne
- Operatory porównania
- Operatory minimum / maksimum
- Operator łączenia
Przyjrzymy się każdemu po kolei. Operatory są zawsze używane ze zmiennymi, które są częścią danych analizowanych przez program SAS.
Operatory arytmetyczne
Poniższa tabela opisuje szczegóły operatorów arytmetycznych. Załóżmy, że mamy dwie zmienne danychV1 i V2wartościami 8 i 4 odpowiednio.
| Operator | Opis | Przykład |
|---|---|---|
| + | Dodanie | V1 + V2 = 12 |
| - | Odejmowanie | V1-V2 = 4 |
| * | Mnożenie | V1 * V2 = 32 |
| / | Podział | V1 / V2 = 2 |
| ** | Potęgowanie | V1 ** V2 = 4096 |
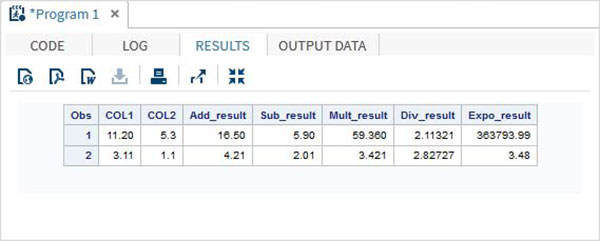
Przykład
DATA MYDATA1;
input @1 COL1 4.2 @7 COL2 3.1;
Add_result = COL1+COL2;
Sub_result = COL1-COL2;
Mult_result = COL1*COL2;
Div_result = COL1/COL2;
Expo_result = COL1**COL2;
datalines;
11.21 5.3
3.11 11
;
PROC PRINT DATA = MYDATA1;
RUN;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Operatory logiczne
Poniższa tabela opisuje szczegóły operatorów logicznych. Te operatory oceniają wartość Prawdy wyrażenia. Zatem wynik operatorów logicznych to zawsze 1 lub 0. Załóżmy, że istnieją dwie zmienne danychV1 i V2wartościami 8 i 4 odpowiednio.
| Operator | Opis | Przykład |
|---|---|---|
| & | Operator AND. Jeśli obie wartości danych są prawdziwe, wówczas wynikiem jest 1, w przeciwnym razie jest to 0. | (V1> 2 i V2> 3) daje 0. |
| | | Operator OR. Jeśli którakolwiek z wartości danych jest prawdziwa, wynikiem jest 1, w przeciwnym razie jest to 0. | (V1> 9 i V2> 3) wynosi 1. |
| ~ | Operator NOT. Wynik operatora NOT w postaci wyrażenia, którego wartością jest FAŁSZ lub brakująca wartość to 1, w przeciwnym razie jest to 0. | NOT (V1> 3) wynosi 1. |
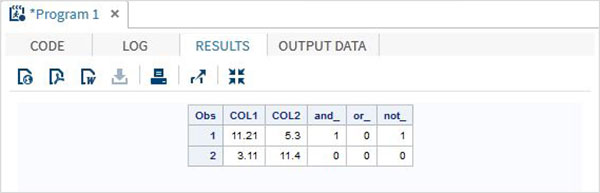
Przykład
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
and_=(COL1 > 10 & COL2 > 5 );
or_ = (COL1 > 12 | COL2 > 15 );
not_ = ~( COL2 > 7 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Operatory porównania
Poniższa tabela opisuje szczegóły operatorów porównania. Operatory te porównują wartości zmiennych, a wynik jest wartością prawdziwą przedstawioną przez 1 dla PRAWDA i 0 dla Fałsz. Załóżmy, że mamy dwie zmienne danychV1 i V2wartościami 8 i 4 odpowiednio.
| Operator | Opis | Przykład |
|---|---|---|
| = | Operator EQUAL. Jeśli obie wartości danych są równe, wynikiem jest 1, w przeciwnym razie 0. | (V1 = 8) daje 1. |
| ^ = | Operator NOT EQUAL. Jeśli obie wartości danych są nierówne, wynikiem jest 1, w przeciwnym razie 0. | (V1 ^ = V2) daje 1. |
| < | MNIEJ NIŻ Operator. | (V2 <V2) daje 1. |
| <= | MNIEJ NIŻ LUB RÓWNE Operatorowi. | (V2 <= 4) daje 1. |
| > | WIĘKSZY NIŻ Operator. | (V2> V1) daje 1. |
| > = | WIĘKSZA NIŻ LUB RÓWNA Operatorowi. | (V2> = V1) daje 0. |
| W | Operator IN. Jeśli wartość zmiennej jest równa którejkolwiek z wartości z danej listy wartości, wówczas zwraca 1, w przeciwnym razie zwraca 0. | V1 w (5,7,9,8) daje 1. |
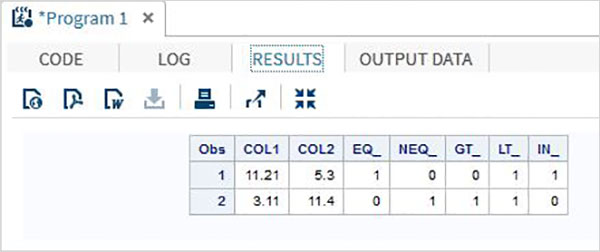
Przykład
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
EQ_ = (COL1 = 11.21);
NEQ_= (COL1 ^= 11.21);
GT_ = (COL2 => 8);
LT_ = (COL2 <= 12);
IN_ = COL2 in( 6.2,5.3,12 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Operatory minimum / maksimum
Poniższa tabela opisuje szczegóły operatorów minimum / maksimum. Te operatory porównują wartości zmiennych w wierszu i zwracana jest minimalna lub maksymalna wartość z listy wartości w wierszach.
| Operator | Opis | Przykład |
|---|---|---|
| MIN | Operator MIN. Zwraca minimalną wartość z listy wartości w wierszu. | MIN (45,2,11,6,15,41) daje 11,6 |
| MAX | Operator MAX. Zwraca maksymalną wartość z listy wartości w wierszu. | MAX (45,2,11,6,15,41) daje 45,2 |
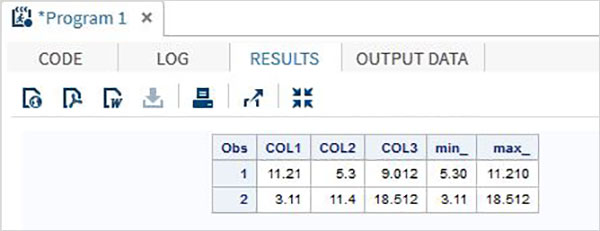
Przykład
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3;
min_ = MIN(COL1 , COL2 , COL3);
max_ = MAX( COL1, COl2 , COL3);
datalines;
11.21 5.3 29.012
3.11 11.4 18.512
;
PROC PRINT DATA = MYDATA1;
RUN;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Operator łączenia
Poniższa tabela opisuje szczegóły operatora konkatenacji. Ten operator łączy dwie lub więcej wartości łańcuchowych. Zwracana jest wartość pojedynczego znaku.
| Operator | Opis | Przykład |
|---|---|---|
| || | Operator konkatenacji. Zwraca konkatenację dwóch lub więcej wartości. | 'Cześć' || ' World ”daje Hello World |
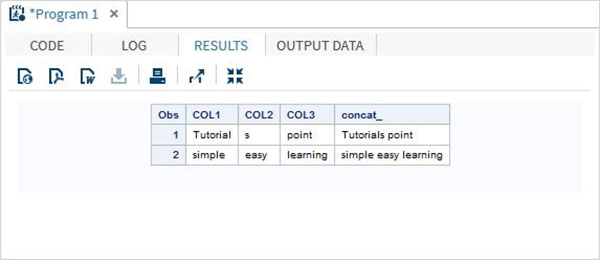
Przykład
DATA MYDATA1;
input COL1 $ COL2 $ COL3 $;
concat_ = (COL1 || COL2 || COL3);
datalines;
Tutorial s point
simple easy learning
;
PROC PRINT DATA = MYDATA1;
RUN;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Pierwszeństwo operatorów
Pierwszeństwo operatorów wskazuje kolejność oceny wielu operatorów obecnych w złożonym wyrażeniu. W poniższej tabeli opisano kolejność pierwszeństwa w grupie operatorów.
| Grupa | Zamówienie | Symbolika |
|---|---|---|
| Grupa I | Od prawej do lewej | ** + - NIE MIN MAX |
| Grupa II | Z lewej na prawą | * / |
| Grupa III | Z lewej na prawą | + - |
| Grupa IV | Z lewej na prawą | || |
| Grupa V | Z lewej na prawą | <<= => => |
Możesz napotkać sytuacje, w których blok kodu będzie musiał zostać wykonany kilka razy. Ogólnie instrukcje są wykonywane sekwencyjnie - pierwsza instrukcja funkcji jest wykonywana jako pierwsza, po niej następuje druga i tak dalej. Ale jeśli chcesz, aby ten sam zestaw instrukcji był wykonywany wielokrotnie, potrzebujemy pomocy Loops.
W SAS zapętlenie odbywa się za pomocą instrukcji DO. Nazywa się to równieżDO Loop. Poniżej podano ogólną postać instrukcji pętli DO w SAS.
Diagram przepływu

Poniżej przedstawiono typy pętli DO w SAS.
| Sr.No. | Typ i opis pętli |
|---|---|
| 1 | Indeks DO. Pętla jest kontynuowana od wartości początkowej do wartości końcowej zmiennej indeksu. |
| 2 | ZRÓB W CZASIE. Pętla trwa do momentu, gdy warunek while stanie się fałszywy. |
| 3 | RÓB DOPÓKI. Pętla trwa, dopóki warunek UNTIL nie stanie się True. |
Struktury decyzyjne wymagają od programisty określenia jednego lub więcej warunków, które mają być ocenione lub przetestowane przez program, wraz z instrukcją lub instrukcjami do wykonania, jeśli warunek zostanie określony jako truei opcjonalnie inne instrukcje do wykonania, jeśli warunek zostanie określony false.
Poniżej przedstawiono ogólną formę typowej struktury podejmowania decyzji występującej w większości języków programowania -
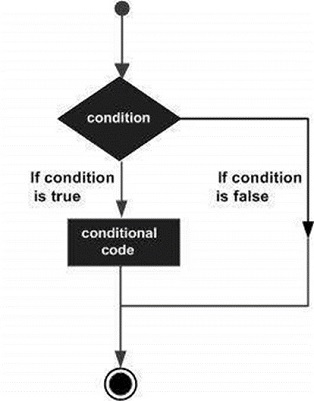
SAS udostępnia następujące typy oświadczeń decyzyjnych. Kliknij poniższe łącza, aby sprawdzić ich szczegóły.
| Sr.No. | Typ i opis wyciągu |
|---|---|
| 1 | Instrukcja IF. Na if statementskłada się z warunku. Jeśli warunek jest prawdziwy, pobierane są określone dane. |
| 2 | Instrukcja IF-THEN-INSE. Na if statement po którym następuje instrukcja else, która jest wykonywana, gdy warunek logiczny jest fałszywy. |
| 3 | Instrukcja IF-THEN-INSE-IF. Na if statement po którym następuje instrukcja else, po której ponownie następuje kolejna para instrukcji IF-THEN. |
| 4 | Instrukcja IF-THEN-DELETE. Na if statement składa się z warunku, który gdy jest prawdziwy, usuwa określone dane z obserwacji. |
SAS ma szeroką gamę wbudowanych funkcji, które pomagają w analizie i przetwarzaniu danych. Funkcje te są używane jako część instrukcji DATA. Biorą zmienne danych jako argumenty i zwracają wynik, który jest przechowywany w innej zmiennej. W zależności od typu funkcji liczba przyjmowanych przez nią argumentów może się różnić. Niektóre funkcje akceptują zero argumentów, podczas gdy inne akceptują stałą liczbę zmiennych. Poniżej znajduje się lista typów funkcji oferowanych przez SAS.
Składnia
Ogólna składnia używania funkcji w SAS jest następująca.
FUNCTIONNAME(argument1, argument2...argumentn)Tutaj argumentem może być stała, zmienna, wyrażenie lub inna funkcja.
Kategorie funkcji
W zależności od ich wykorzystania funkcje w SAS są podzielone na poniższe kategorie.
- Mathematical
- Data i godzina
- Character
- Truncation
- Miscellaneous
Funkcje matematyczne
Są to funkcje używane do wykonywania obliczeń matematycznych na wartościach zmiennych.
Przykłady
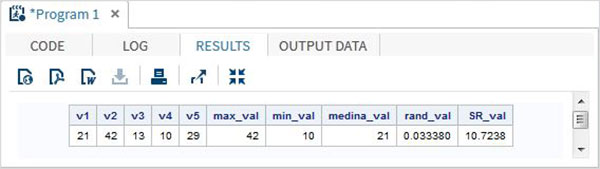
Poniższy program SAS pokazuje użycie niektórych ważnych funkcji matematycznych.
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29;
/* Get Maximum value */
max_val = MAX(v1,v2,v3,v4,v5);
/* Get Minimum value */
min_val = MIN (v1,v2,v3,v4,v5);
/* Get Median value */
med_val = MEDIAN (v1,v2,v3,v4,v5);
/* Get a random number */
rand_val = RANUNI(0);
/* Get Square root of sum of the values */
SR_val= SQRT(sum(v1,v2,v3,v4,v5));
proc print data = Math_functions noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe -
Funkcje daty i czasu
Są to funkcje używane do przetwarzania wartości daty i godziny.
Przykłady
Poniższy program SAS pokazuje użycie funkcji daty i czasu.
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe -
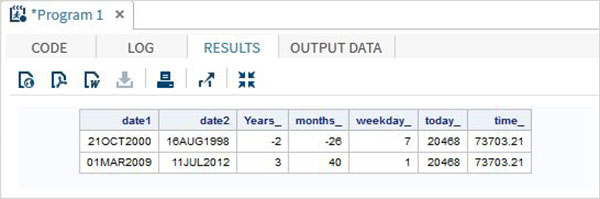
Funkcje postaci
Są to funkcje używane do przetwarzania wartości znakowych lub tekstowych.
Przykłady
Poniższy program SAS przedstawia użycie funkcji znakowych.
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe -
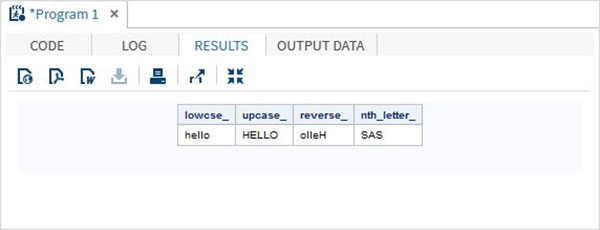
Funkcje obcinania
Oto funkcje używane do obcinania wartości liczbowych.
Przykłady
Poniższy program SAS pokazuje użycie funkcji obcięcia.
data trunc_functions;
/* Nearest greatest integer */
ceil_ = CEIL(11.85);
/* Nearest greatest integer */
floor_ = FLOOR(11.85);
/* Integer portion of a number */
int_ = INT(32.41);
/* Round off to nearest value */
round_ = ROUND(5621.78);
run;
proc print data = trunc_functions noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe -

Różne funkcje
Rozumiemy teraz różne funkcje SAS na kilku przykładach.
Przykłady
Poniższy program SAS pokazuje użycie różnych funkcji.
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe -

Do odczytu surowych danych używane są metody wejściowe. Surowe dane mogą pochodzić ze źródła zewnętrznego lub z linii danych strumieniowych. Instrukcja input tworzy zmienną o nazwie przypisanej do każdego pola. Musisz więc utworzyć zmienną w instrukcji wejściowej. Ta sama zmienna zostanie wyświetlona w danych wyjściowych SAS Dataset. Poniżej znajdują się różne metody wprowadzania dostępne w SAS.
- Metoda wprowadzania listy
- Nazwana metoda wprowadzania
- Metoda wprowadzania kolumn
- Sformatowana metoda wprowadzania
Szczegóły każdej metody wprowadzania zostały opisane poniżej.
Metoda wprowadzania listy
W tej metodzie zmienne są wymienione z typami danych. Surowe dane są dokładnie analizowane, aby kolejność zadeklarowanych zmiennych była zgodna z danymi. Separator (zwykle spacja) powinien być jednolity między dowolną parą sąsiednich kolumn. Wszelkie brakujące dane spowodują problem z wynikiem, ponieważ wynik będzie nieprawidłowy.
Przykład
Poniższy kod i dane wyjściowe pokazują użycie metody wprowadzania listy.
DATA TEMP;
INPUT EMPID ENAME $ DEPT $ ;
DATALINES;
1 Rick IT
2 Dan OPS
3 Tusar IT
4 Pranab OPS
5 Rasmi FIN
;
PROC PRINT DATA = TEMP;
RUN;Po uruchomieniu kodu bove otrzymujemy następujące dane wyjściowe.
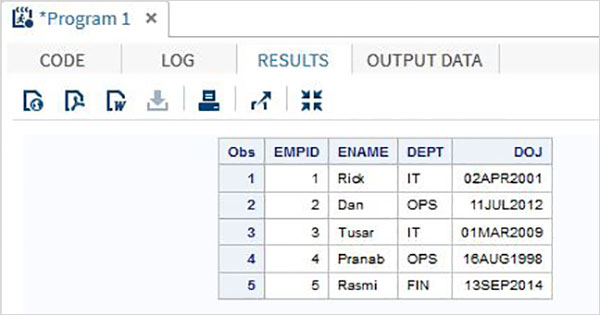
Nazwana metoda wprowadzania
W tej metodzie zmienne są wymienione z typami danych. Surowe dane są modyfikowane w celu zadeklarowania nazw zmiennych przed pasującymi danymi. Separator (zwykle spacja) powinien być jednolity między dowolną parą sąsiednich kolumn.
Przykład
Poniższy kod i dane wyjściowe przedstawiają użycie nazwanej metody wprowadzania.
DATA TEMP;
INPUT
EMPID= ENAME= $ DEPT= $ ;
DATALINES;
EMPID = 1 ENAME = Rick DEPT = IT
EMPID = 2 ENAME = Dan DEPT = OPS
EMPID = 3 ENAME = Tusar DEPT = IT
EMPID = 4 ENAME = Pranab DEPT = OPS
EMPID = 5 ENAME = Rasmi DEPT = FIN
;
PROC PRINT DATA = TEMP;
RUN;Po uruchomieniu kodu bove otrzymujemy następujące dane wyjściowe.
Metoda wprowadzania kolumn
W tej metodzie zmienne są wyświetlane z typami danych i szerokością kolumn, które określają wartość pojedynczej kolumny danych. Na przykład, jeśli imię i nazwisko pracownika zawiera maksymalnie 9 znaków, a nazwisko każdego pracownika zaczyna się od dziesiątej kolumny, wówczas szerokość kolumny dla zmiennej zawierającej nazwisko pracownika będzie wynosić 10-19.
Przykład
Poniższy kod ilustruje użycie metody wprowadzania kolumn.
DATA TEMP;
INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16;
DATALINES;
14 Rick IT
241Dan OPS
30 Sanvi IT
410Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
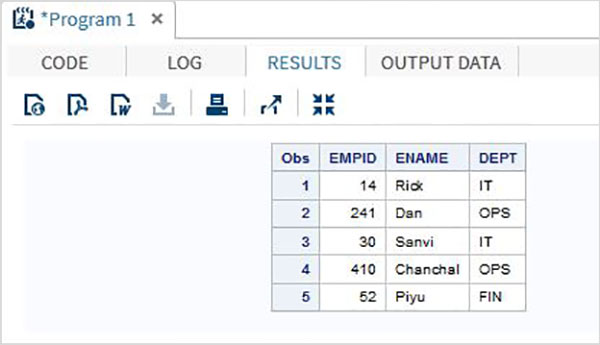
Sformatowana metoda wprowadzania
W tej metodzie zmienne są odczytywane od ustalonego punktu początkowego, aż do napotkania spacji. Ponieważ każda zmienna ma ustalony punkt początkowy, liczba kolumn między dowolną parą zmiennych staje się szerokością pierwszej zmiennej. Znak „@n” służy do określenia pozycji początkowej kolumny zmiennej jako n-tej kolumny.
Przykład
Poniższy kod przedstawia użycie sformatowanej metody wprowadzania
DATA TEMP;
INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ;
DATALINES;
14 Rick IT
241 Dan OPS
30 Sanvi IT
410 Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
SAS ma potężną funkcję programowania o nazwie Macrosco pozwala nam uniknąć powtarzających się sekcji kodu i używać ich wielokrotnie, gdy zajdzie taka potrzeba. Pomaga również w tworzeniu zmiennych dynamicznych w kodzie, które mogą przyjmować różne wartości dla różnych uruchomionych instancji tego samego kodu. Makra można również zadeklarować dla bloków kodu, które będą wielokrotnie używane w podobny sposób jak makrozmienne. Zobaczymy oba z poniższych przykładów.
Zmienne makro
Są to zmienne, które mają wartość, która ma być używana wielokrotnie przez program SAS. Są deklarowane na początku programu SAS i wywoływane później w treści programu. Mogą mieć zasięg globalny lub lokalny.
Globalna zmienna makro
Nazywa się je globalnymi makrozmiennymi, ponieważ mają do nich dostęp dowolny program SAS dostępny w środowisku SAS. Na ogół są to zmienne przypisane do systemu, do których dostęp ma wiele programów. Ogólnym przykładem jest data systemowa.
Przykład
Poniżej znajduje się przykład zmiennej SAS o nazwie SYSDATE, która reprezentuje datę systemową. Rozważ scenariusz drukowania daty systemowej w tytule raportu SAS każdego dnia generowania raportu. Tytuł pokaże aktualną datę i dzień bez kodowania dla nich żadnych wartości. Używamy wbudowanego zestawu danych SAS o nazwie CARS dostępnego w bibliotece SASHELP.
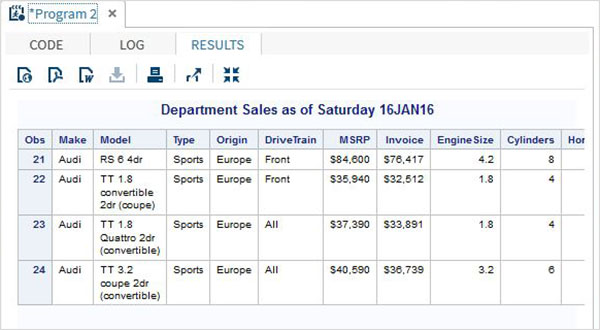
proc print data = sashelp.cars;
where make = 'Audi' and type = 'Sports' ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Lokalna zmienna makro
Dostęp do tych zmiennych mogą uzyskać programy SAS-owe, w których są zadeklarowane jako część programu. Są one zwykle używane do dostarczania różnych zmiennych do tych samych oświadczeń SAS sl, że mogą przetwarzać różne obserwacje zbioru danych.
Składnia
Zmienne lokalne są dekalowane za pomocą poniższej składni.
% LET (Macro Variable Name) = Value;W tym przypadku pole Wartość może przyjąć dowolną wartość liczbową, tekstową lub datę, zgodnie z wymaganiami programu. Nazwa makrozmiennej to dowolna prawidłowa zmienna SAS.
Przykład
Zmienne są używane przez instrukcje SAS przy użyciu rozszerzenia & znak dołączany na początku nazwy zmiennej. Poniższy program zawiera wszystkie spostrzeżenia dotyczące marki „Audi” i typu „Sport”. Na wypadek, gdybyśmy chcieli uzyskać wynikdifferent make, musimy zmienić wartość zmiennej make_namebez zmiany jakiejkolwiek innej części programu. W przypadku programów typu bring ta zmienna może być ponownie przywoływana w dowolnych instrukcjach SAS.
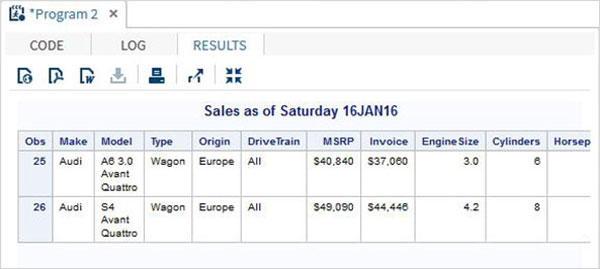
%LET make_name = 'Audi';
%LET type_name = 'Sports';
proc print data = sashelp.cars;
where make = &make_name and type = &type_name ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Po uruchomieniu powyższego kodu otrzymujemy takie same dane wyjściowe, jak w poprzednim programie. Ale zmieńmytype name do 'Wagon'i uruchom ten sam program. Otrzymamy poniższy wynik.
Programy makr
Makro to grupa instrukcji SAS-owych, do których odwołuje się nazwa i których można używać w programie w dowolnym miejscu, używając tej nazwy. Rozpoczyna się instrukcją% MACRO i kończy instrukcją% MEND.
Składnia
Zmienne lokalne są deklarowane przy użyciu poniższej składni.
# Creating a Macro program.
%MACRO <macro name>(Param1, Param2,….Paramn);
Macro Statements;
%MEND;
# Calling a Macro program.
%MacroName (Value1, Value2,…..Valuen);Przykład
Poniższy program odwzorowuje grupę stacji SAT pod makro o nazwie 'show_result'; To makro jest wywoływane przez inne instrukcje SAS.
%MACRO show_result(make_ , type_);
proc print data = sashelp.cars;
where make = "&make_" and type = "&type_" ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;
%MEND;
%show_result(BMW,SUV);Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Powszechnie używane makra
SAS ma wiele instrukcji MACRO, które są wbudowane w język programowania SAS. Są używane przez inne programy SAS-owe bez ich jawnego zadeklarowania. Typowe przykłady to - przerywanie programu, gdy spełniony jest jakiś warunek lub przechwytywanie wartości zmiennej w dzienniku programu. Poniżej znajduje się kilka przykładów.
Makro% PUT
Ta instrukcja makra zapisuje tekst lub informacje o makrozmiennych w dzienniku SAS. W poniższym przykładzie wartość zmiennej „Today” jest zapisywana w dzienniku programu.
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Makro% RETURN
Wykonanie tego makra powoduje normalne zakończenie aktualnie wykonywanego makra, gdy określony warunek zostanie uznany za prawdziwy. W poniższym przykładzie, gdy wartość zmiennej"val" staje się 10, makro kończy się w przeciwnym razie kontynuuje.
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Makro% END
Ta definicja makra zawiera rozszerzenie %DO %WHILEpętla, która kończy się, zgodnie z wymaganiami, instrukcją% END. W poniższym przykładzie makro o nazwie test pobiera dane wejściowe użytkownika i uruchamia pętlę DO przy użyciu tej wartości wejściowej. Koniec pętli DO uzyskuje się za pomocą instrukcji% end, natomiast koniec makra uzyskuje się za pomocą instrukcji% mend.
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)Po uruchomieniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Daty IN SAS to szczególny przypadek wartości liczbowych. Każdemu dniu przypisywana jest określona wartość liczbowa, począwszy od 1 stycznia 1960 r. Dacie tej przypisywana jest wartość 0, a następna data ma wartość 1 i tak dalej. Poprzednie dni do tej daty są reprezentowane przez -1, -2 i tak dalej. Dzięki temu podejściu SAS może reprezentować dowolną datę w przyszłości i dowolną datę w przeszłości.
Kiedy SAS odczytuje dane ze źródła, konwertuje odczytane dane na określony format daty określony w formacie daty. Zmienna do przechowywania wartości daty jest zadeklarowana z wymaganymi odpowiednimi informacjami. Data wyjściowa jest wyświetlana przy użyciu formatów danych wyjściowych.
SAS Date Informat
Dane źródłowe można poprawnie odczytać przy użyciu określonych informacji o dacie, jak pokazano poniżej. Cyfra na końcu informacji wskazuje minimalną szerokość ciągu daty, który ma być odczytany w całości przy użyciu informatu. Mniejsza szerokość da nieprawidłowy wynik. W przypadku SAS V9 istnieje ogólny format datyanydtdte15. który może przetwarzać dowolne dane wejściowe.
| Data wprowadzenia | Szerokość daty | Informat |
|---|---|---|
| 03.11.2014 | 10 | mmddyy10. |
| 11.03.14 | 8 | mmddyy8. |
| 11 grudnia 2012 | 20 | worddate20. |
| 14mar2011 | 9 | data9. |
| 14-mar-2011 | 11 | data11. |
| 14-mar-2011 | 15 | anydtdte15. |
Przykład
Poniższy kod przedstawia odczyt różnych formatów dat. Należy pamiętać, że wszystkie wartości wyjściowe są tylko liczbami, ponieważ nie zastosowaliśmy żadnych instrukcji formatu do wartości wyjściowych.
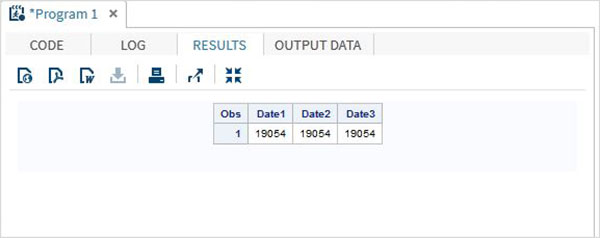
DATA TEMP;
INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ;
DATALINES;
02-mar-2012 3/02/2012 3/02/2012
;
PROC PRINT DATA = TEMP;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Format wyjściowy daty SAS
Daty po odczytaniu można przekonwertować na inny format zgodnie z wymaganiami wyświetlacza. Osiąga się to za pomocą instrukcji formatu dla typów dat. Mają taki sam format jak informacje.
Przykład
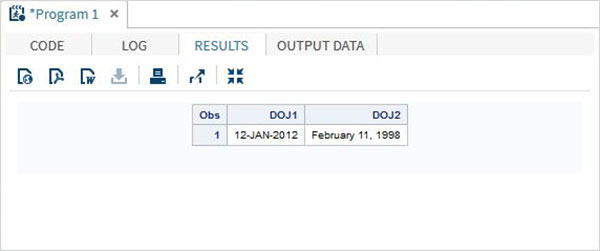
W poniższym przykładzie data jest odczytywana w jednym formacie, ale wyświetlana w innym formacie.
DATA TEMP;
INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.;
format DOJ1 date11. DOJ2 worddate20. ;
DATALINES;
01/12/2012 02/11/1998
;
PROC PRINT DATA = TEMP;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
SAS może czytać dane z różnych źródeł, które obejmują wiele formatów plików. Formaty plików używane w środowisku SAS omówiono poniżej.
- Zestaw danych ASCII (tekst)
- Dane rozdzielane
- Dane programu Excel
- Dane hierarchiczne
Czytanie zestawu danych ASCII (tekst)
Są to pliki zawierające dane w formacie tekstowym. Dane są zwykle oddzielane spacjami, ale mogą istnieć różne typy separatorów, które mogą być obsługiwane przez SAS. Rozważmy plik ASCII zawierający dane pracowników. Czytamy ten plik przy użyciu rozszerzeniaInfile wyciąg dostępny w SAS.
Przykład
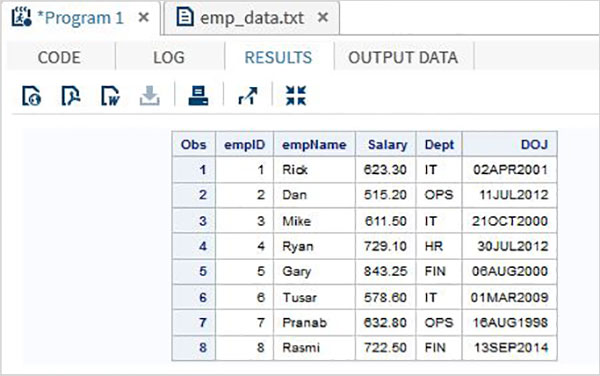
W poniższym przykładzie czytamy plik danych o nazwie emp_data.txt ze środowiska lokalnego.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Czytanie danych rozdzielonych
Są to pliki danych, w których wartości kolumn są oddzielone znakiem ograniczającym, takim jak przecinek lub potok itp. W tym przypadku używamy dlm opcja w infile komunikat.
Przykład
W poniższym przykładzie czytamy plik danych o nazwie emp.csv ze środowiska lokalnego.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Czytanie danych programu Excel
SAS może bezpośrednio odczytać plik Excel za pomocą funkcji importu. Jak widać w rozdziale Zestawy danych SAS, może on obsługiwać wiele różnych typów plików, w tym MS Excel. Zakładając, że plik emp.xls jest dostępny lokalnie w środowisku SAS.
Przykład
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;Powyższy kod odczytuje dane z pliku Excela i daje takie same dane wyjściowe jak powyższe dwa typy plików.
Czytanie plików hierarchicznych
W tych plikach dane są obecne w formacie hierarchicznym. Dla danej obserwacji istnieje rekord nagłówka, pod którym wymieniono wiele rekordów szczegółowych. Liczba rekordów szczegółowych może się różnić w zależności od obserwacji. Poniżej znajduje się ilustracja hierarchicznego pliku.
W poniższym pliku wymienione są dane każdego pracownika w każdym dziale. Pierwszy rekord to nagłówek zawierający informacje o dziale, a następny rekord to kilka rekordów zaczynających się od DTLS.
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452Przykład
Aby odczytać plik hierarchiczny, używamy poniższego kodu, w którym identyfikujemy rekord nagłówka za pomocą klauzuli IF i używamy pętli do do przetwarzania rekordu szczegółów.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @; if Type = 'DEP' then input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Podobnie jak w przypadku czytania zbiorów danych, SAS może zapisywać zbiory danych w różnych formatach. Może zapisywać dane z plików SAS do zwykłego pliku tekstowego, które mogą być odczytywane przez inne programy. SAS używaPROC EXPORT do pisania zbiorów danych.
EKSPORT PROCESÓW
Jest to wbudowana procedura SAS używana do eksportowania zestawów danych SAS do zapisywania danych w plikach o różnych formatach.
Składnia
Podstawowa składnia do pisania procedury w SAS to -
PROC EXPORT
DATA = libref.SAS data-set (SAS data-set-options)
OUTFILE = "filename"
DBMS = identifier LABEL(REPLACE);Poniżej znajduje się opis użytych parametrów -
SAS data-setto nazwa eksportowanego zestawu danych. SAS może udostępniać zestawy danych ze swojego środowiska innym aplikacjom, tworząc pliki, które mogą być odczytywane przez różne systemy operacyjne. Wykorzystuje wbudowaną funkcję EKSPORTU, aby wyświetlić pliki zestawów danych w różnych formatach. W tym rozdziale zobaczymy pisanie zestawów danych SAS za pomocąproc export wraz z opcjami dlm i dbms.
SAS data-set-options służy do określenia podzbioru kolumn do wyeksportowania.
filename to nazwa pliku, do którego zapisywane są dane.
identifier jest używany do wskazania separatora, który zostanie zapisany w pliku.
LABEL Opcja służy do podania nazwy zmiennych zapisywanych do pliku.
Przykład
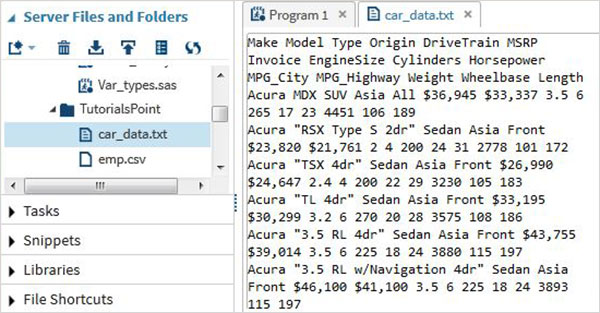
Będziemy korzystać z zestawu danych SAS o nazwie cars dostępnego w bibliotece SASHELP. Eksportujemy go jako plik tekstowy rozdzielany spacjami z kodem, jak pokazano w poniższym programie.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt'
dbms = dlm;
delimiter = ' ';
run;Wykonując powyższy kod, możemy zobaczyć wynik jako plik tekstowy i kliknąć go prawym przyciskiem myszy, aby zobaczyć jego zawartość, jak pokazano poniżej.
Pisanie pliku CSV
Aby napisać plik rozdzielany przecinkami, możemy skorzystać z opcji dlm o wartości "csv". Poniższy kod zapisuje plik car_data.csv.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv'
dbms = csv;
run;Po wykonaniu powyższego kodu otrzymujemy poniższe dane wyjściowe.

Pisanie pliku rozdzielanego tabulatorami
Aby zapisać plik rozdzielany tabulatorami, możemy użyć rozszerzenia dlmopcja z wartością „tab”. Poniższy kod zapisuje plikcar_tab.txt.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt'
dbms = csv;
run;Dane można również zapisać jako plik HTML, który zobaczymy w rozdziale o systemie dostarczania wyników.
Wiele zestawów danych SAS może zostać połączonych w celu uzyskania jednego zestawu danych przy użyciu rozszerzenia SETkomunikat. Całkowita liczba obserwacji w połączonym zbiorze danych jest sumą liczby obserwacji w oryginalnych zbiorach danych. Kolejność obserwacji jest sekwencyjna. Po wszystkich obserwacjach z pierwszego zestawu danych następują wszystkie obserwacje z drugiego zestawu danych i tak dalej.
W idealnym przypadku wszystkie łączone zestawy danych mają te same zmienne, ale w przypadku gdy mają różną liczbę zmiennych, w wyniku pojawiają się wszystkie zmienne z brakującymi wartościami dla mniejszego zestawu danych.
Składnia
Podstawowa składnia instrukcji SET w SAS to -
SET data-set 1 data-set 2 data-set 3.....;Poniżej znajduje się opis użytych parametrów -
data-set1,data-set2 to nazwy zbiorów danych zapisywane jedna po drugiej.
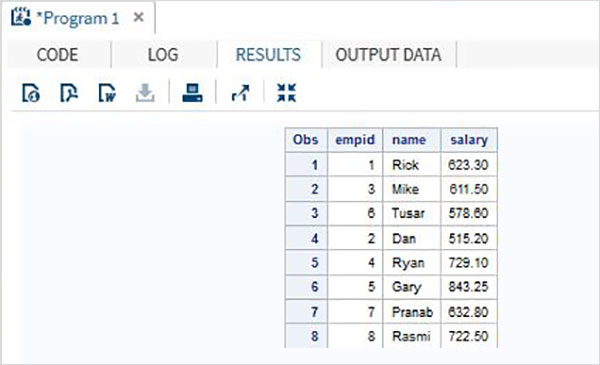
Przykład
Rozważ dane pracowników organizacji, które są dostępne w dwóch różnych zestawach danych, jednym dla działu IT i drugim dla działu Non-It. Aby uzyskać pełne dane wszystkich pracowników, łączymy oba zestawy danych za pomocą instrukcji SET, jak pokazano poniżej.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Scenariusze
Kiedy mamy wiele odmian w zestawach danych do konkatenacji, wyniki zmiennych mogą się różnić, ale całkowita liczba obserwacji w połączonym zestawie danych jest zawsze sumą obserwacji w każdym zestawie danych. Poniżej rozważymy wiele scenariuszy dotyczących tej odmiany.
Różna liczba zmiennych
Jeśli jeden z oryginalnych zestawów danych ma większą liczbę zmiennych niż inny, wówczas zestawy danych nadal są łączone, ale w mniejszym zestawie danych te zmienne pojawiają się jako brakujące.
Przykład
W poniższym przykładzie pierwszy zestaw danych ma dodatkową zmienną o nazwie DOJ. W rezultacie wartość DOJ dla drugiego zestawu danych pojawi się jako brakująca.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Inna nazwa zmiennej
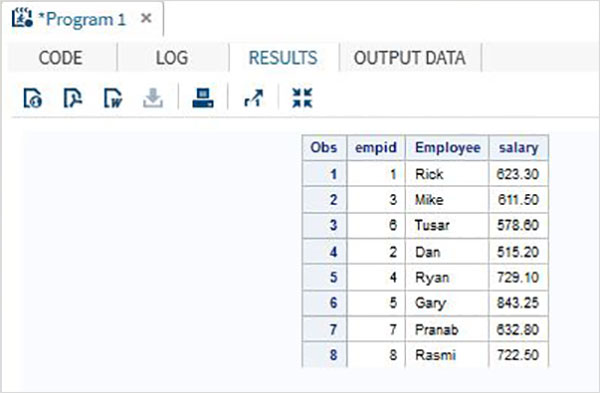
W tym scenariuszu zbiory danych mają taką samą liczbę zmiennych, ale nazwa zmiennej jest między nimi inna. W takim przypadku zwykła konkatenacja da wszystkie zmienne w zestawie wyników i da brakujące wyniki dla dwóch zmiennych, które się różnią. Chociaż nie możemy zmienić nazwy zmiennej w oryginalnych zestawach danych, możemy zastosować funkcję RENAME w utworzonym przez nas połączonym zestawie danych. To da ten sam wynik, co zwykłe konkatenacje, ale oczywiście z jedną nową nazwą zmiennej zamiast dwóch różnych nazw zmiennych obecnych w oryginalnym zbiorze danych.
Przykład
W poniższym przykładzie zbiór danych ITDEPT ma nazwę zmiennej ename natomiast zbiór danych NON_ITDEPT ma nazwę zmiennej empname.Ale obie te zmienne reprezentują ten sam typ (znak). StosujemyRENAME funkcji w instrukcji SET, jak pokazano poniżej.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Różne długości o różnej długości
Jeśli zmienne długości w dwóch zestawach danych są różne, niż połączony zestaw danych będzie zawierał wartości, w których część danych zostanie obcięta dla zmiennej o mniejszej długości. Dzieje się tak, jeśli pierwszy zestaw danych ma mniejszą długość. Aby rozwiązać ten problem, zastosujemy większą długość do obu zestawów danych, jak pokazano poniżej.
Przykład
W poniższym przykładzie zmienna enamema długość 5 w pierwszym zestawie danych i 7 w drugim. Podczas konkatenacji stosujemy instrukcję LENGTH w połączonym zestawie danych, aby ustawić długość ename na 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
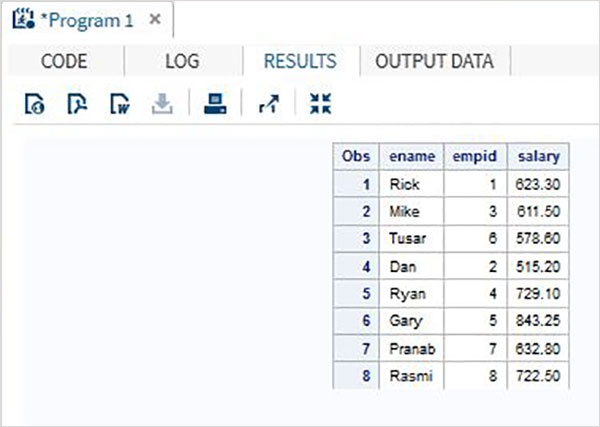
Wiele zestawów danych SAS może zostać połączonych na podstawie określonej wspólnej zmiennej, aby uzyskać jeden zestaw danych. Odbywa się to za pomocąMERGE oświadczenie i BYkomunikat. Całkowita liczba obserwacji w połączonym zestawie danych jest często mniejsza niż suma liczby obserwacji w oryginalnych zbiorach danych. Dzieje się tak, ponieważ zmienne z obu zestawów danych są łączone jako jeden rekord na podstawie zgodności wartości wspólnej zmiennej.
Istnieją dwa warunki wstępne dotyczące łączenia zestawów danych podane poniżej -
- zestawy danych wejściowych muszą mieć co najmniej jedną wspólną zmienną, z którą mają się łączyć.
- zestawy danych wejściowych muszą być sortowane według wspólnych zmiennych, które będą używane do scalania.
Składnia
Podstawowa składnia instrukcji MERGE i BY w SAS to -
MERGE Data-Set 1 Data-Set 2
BY Common VariablePoniżej znajduje się opis użytych parametrów -
Data-set1,Data-set2 to nazwy zbiorów danych zapisywane jedna po drugiej.
Common Variable jest zmienną, na podstawie której pasujące wartości zostaną scalone zestawy danych.
Łączenie danych
Zrozummy łączenie danych na przykładzie.
Przykład
Rozważ dwa zestawy danych SAS, jeden zawierający identyfikator pracownika z nazwiskiem i wynagrodzeniem, a drugi zawierający identyfikator pracownika z identyfikatorem pracownika i działem. W tym przypadku, aby uzyskać pełne informacje o każdym pracowniku, możemy połączyć te dwa zestawy danych. Ostateczny zestaw danych nadal będzie zawierał jedną obserwację na pracownika, ale będzie zawierał zarówno zmienne dotyczące wynagrodzenia, jak i działu.
# Data set 1
ID NAME SALARY
1 Rick 623.3
2 Dan 515.2
3 Mike 611.5
4 Ryan 729.1
5 Gary 843.25
6 Tusar 578.6
7 Pranab 632.8
8 Rasmi 722.5
# Data set 2
ID DEPT
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
# Merged data set
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINPowyższy wynik uzyskuje się za pomocą poniższego kodu, w którym w instrukcji BY użyto zmiennej wspólnej (ID). Należy pamiętać, że obserwacje w obu zbiorach danych są już posortowane w kolumnie ID.
DATA SALARY;
INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ;
DATALINES;
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
;
RUN;
DATA All_details;
MERGE SALARY DEPT;
BY (empid);
RUN;
PROC PRINT DATA = All_details;
RUN;Brakujące wartości w dopasowanej kolumnie
Mogą wystąpić przypadki, w których niektóre wartości zmiennej wspólnej nie będą pasować między zestawami danych. W takich przypadkach zbiory danych są nadal łączone, ale w wyniku pojawiają się brakujące wartości.
Przykład
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 . . IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 .
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINŁączenie tylko meczów
Aby uniknąć brakujących wartości w wyniku, można rozważyć pozostawienie tylko obserwacji z dopasowanymi wartościami dla zmiennej wspólnej. Osiąga się to za pomocąINkomunikat. Instrukcja scalania programu SAS wymaga zmiany.
Przykład
W poniższym przykładzie IN= wartość zachowuje tylko obserwacje, dla których wartości z obu zbiorów danych SALARY i DEPT mecz.
DATA All_details;
MERGE SALARY(IN = a) DEPT(IN = b);
BY (empid);
IF a = 1 and b = 1;
RUN;
PROC PRINT DATA = All_details;
RUN;Po wykonaniu powyższego programu SAS z powyższą zmienioną częścią otrzymujemy następujący wynik.
1 Rick 623.3 IT
2 Dan 515.2 OPS
4 Ryan 729.1 HR
5 Gary 843.25 FIN
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINPodzbiór zestawu danych SAS oznacza wyodrębnienie części zestawu danych poprzez wybranie mniejszej liczby zmiennych lub mniejszej liczby obserwacji lub obu. Podczas gdy podzbiór zmiennych odbywa się za pomocąKEEP i DROP instrukcji, nastawianie podrzędne obserwacji odbywa się za pomocą DELETE komunikat.
Również dane wynikowe z operacji podzbioru są przechowywane w nowym zestawie danych, który można wykorzystać do dalszej analizy. Ustawienie podrzędne jest używane głównie w celu analizy części zbioru danych bez użycia tych zmiennych lub obserwacji, które mogą nie mieć znaczenia dla analizy.
Podzbiór zmiennych
W tej metodzie wyodrębniamy tylko kilka zmiennych z całego zbioru danych.
Składnia
Podstawowa składnia zmiennych ustawień podrzędnych w SAS to -
KEEP var1 var2 ... ;
DROP var1 var2 ... ;Poniżej znajduje się opis użytych parametrów -
var1 and var2 to nazwy zmiennych ze zbioru danych, które należy zachować lub usunąć.
Przykład
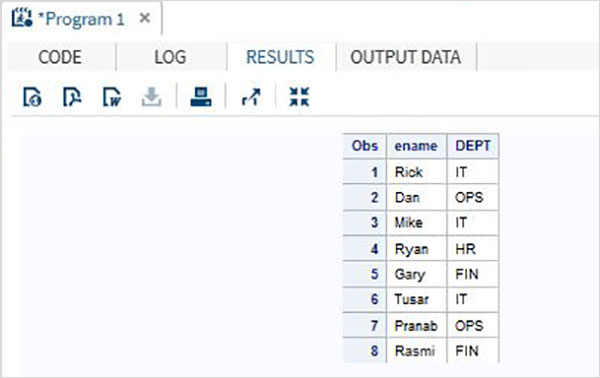
Rozważ poniższy zestaw danych SAS zawierający dane pracowników organizacji. Jeśli interesuje nas tylko pobranie wartości Name i Department ze zbioru danych, możemy skorzystać z poniższego kodu.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
KEEP ename DEPT;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Ten sam wynik można uzyskać, usuwając zmienne, które nie są wymagane. Poniższy kod ilustruje to.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
DROP empid salary;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Subsetting Observations
W tej metodzie wyodrębniamy tylko kilka obserwacji z całego zbioru danych.
Składnia
Używamy PROC FREQ, który śledzi obserwacje wybrane dla nowego zestawu danych.
Składnia obserwacji ustawień podrzędnych to -
IF Var Condition THEN DELETE ;Poniżej znajduje się opis użytych parametrów -
Var to nazwa zmiennej, na podstawie której wartości obserwacje zostaną usunięte przy użyciu określonego warunku.
Przykład
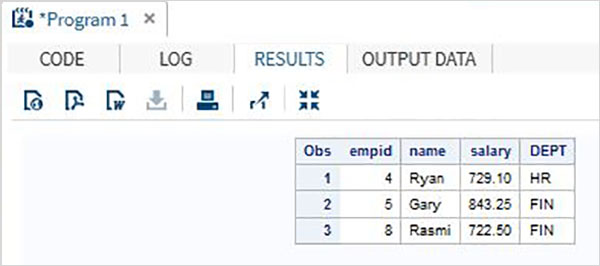
Rozważ poniższy zestaw danych SAS zawierający dane pracowników organizacji. Jeżeli interesuje nas tylko pozyskanie danych dla pracowników z wynagrodzeniem powyżej 700, to posługujemy się poniższym kodem.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
IF salary < 700 THEN DELETE;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Czasami wolimy pokazać analizowane dane w formacie innym niż format, w którym są już obecne w zbiorze danych. Na przykład chcemy dodać znak dolara i dwa miejsca po przecinku do zmiennej, która zawiera informacje o cenie. Lub możemy chcieć pokazać zmienną tekstową, całą wielkimi literami. Możemy użyćFORMAT aby zastosować wbudowane formaty SAS i PROC FORMATpolega na zastosowaniu formatów zdefiniowanych przez użytkownika. Jeden format można również zastosować do wielu zmiennych.
Składnia
Podstawowa składnia stosowania wbudowanych formatów SAS to -
format variable name format namePoniżej znajduje się opis użytych parametrów -
variable name to nazwa zmiennej używana w zbiorze danych.
format name to format danych, który ma być zastosowany do zmiennej.
Przykład
Rozważmy poniższy zestaw danych SAS zawierający dane pracowników organizacji. Chcemy, aby wszystkie nazwy były pisane wielkimi literami. Plikformatstatement służy do osiągnięcia tego.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
format name $upcase9. ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
PROC PRINT DATA = Employee;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.

Korzystanie z PROC FORMAT
Możemy również użyć PROC FORMATformatować dane. W poniższym przykładzie przypisujemy zmienną DEPT nowe wartości z wyodrębnieniem nazwy działu.
DATA Employee;
INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; proc format; value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
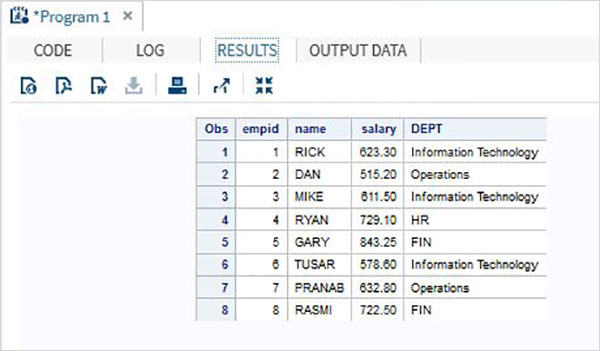
SAS oferuje szerokie wsparcie dla większości popularnych relacyjnych baz danych przy użyciu zapytań SQL wewnątrz programów SAS. WiększośćANSI SQLobsługiwana składnia. ProceduraPROC SQLsłuży do przetwarzania instrukcji SQL. Ta procedura może nie tylko zwrócić wynik zapytania SQL, ale może również utworzyć tabele i zmienne SAS. Przykłady wszystkich tych scenariuszy opisano poniżej.
Składnia
Podstawowa składnia używania PROC SQL w SAS to -
PROC SQL;
SELECT Columns
FROM TABLE
WHERE Columns
GROUP BY Columns
;
QUIT;Poniżej znajduje się opis użytych parametrów -
zapytanie SQL jest zapisywane pod instrukcją PROC SQL, po której następuje instrukcja QUIT.
Poniżej zobaczymy, jak ta procedura SAS może być używana dla CRUD (Tworzenie, odczytywanie, aktualizowanie i usuwanie) operacji w języku SQL.
Operacja tworzenia SQL
Używając SQL możemy stworzyć nowy zestaw danych z surowych danych. W poniższym przykładzie najpierw deklarujemy zbiór danych o nazwie TEMP zawierający surowe dane. Następnie piszemy zapytanie SQL, aby utworzyć tabelę ze zmiennych tego zestawu danych.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES AS
SELECT * FROM TEMP;
QUIT;
PROC PRINT data = EMPLOYEES;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
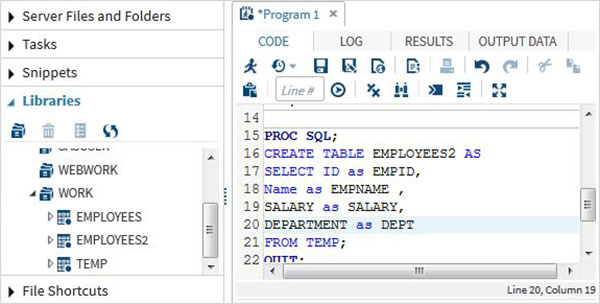
Operacja odczytu SQL
Operacja odczytu w języku SQL polega na pisaniu zapytań SQL SELECT w celu odczytania danych z tabel. W poniższym programie odpytuje zbiór danych SAS o nazwie CARS dostępny w bibliotece SASHELP. Zapytanie pobiera niektóre kolumny zestawu danych.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
;
QUIT;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
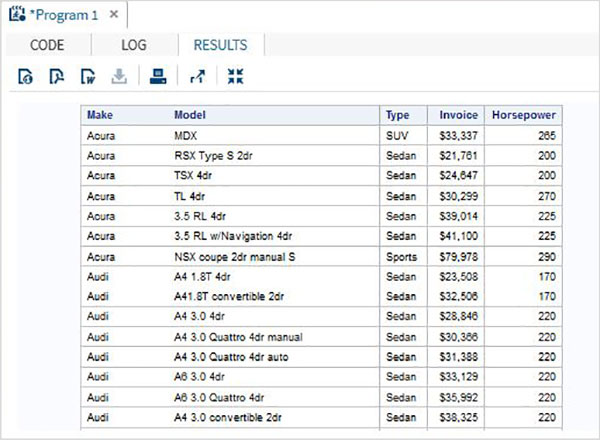
SQL SELECT z klauzulą WHERE
Poniższy program odpytuje zestaw danych CARS za pomocą pliku whereklauzula. W rezultacie otrzymujemy tylko obserwacje, które mają markę „Audi” i wpisz „Sport”.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
Where make = 'Audi'
and Type = 'Sports'
;
QUIT;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
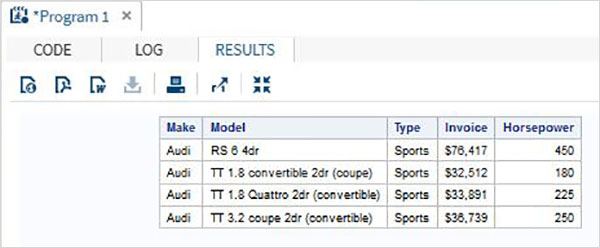
Operacja SQL UPDATE
Możemy zaktualizować tabelę SAS za pomocą instrukcji SQL Update. Poniżej najpierw tworzymy nową tabelę o nazwie EMPLOYEES2, a następnie aktualizujemy ją za pomocą instrukcji SQL UPDATE.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -

Operacja SQL DELETE
Operacja usuwania w języku SQL polega na usunięciu określonych wartości z tabeli za pomocą instrukcji SQL DELETE. Nadal korzystamy z danych z powyższego przykładu i usuwamy wiersze z tabeli, w której pensje pracowników są większe niż 900.
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -

Dane wyjściowe z programu SAS można przekonwertować na bardziej przyjazne dla użytkownika formy, takie jak .html lub PDF. Odbywa się to za pomocą ODSwyciąg dostępny w SAS. ODS oznaczaoutput delivery system.Jest głównie używany do formatowania danych wyjściowych programu SAS do ładnych raportów, które są dobre do obejrzenia i zrozumienia. Pomaga to również w dzieleniu się wynikami z innymi platformami i produktami miękkimi. Może również łączyć wyniki z wielu instrukcji PROC w jednym pliku.
Składnia
Podstawowa składnia użycia instrukcji ODS w SAS to -
ODS outputtype
PATH path name
FILE = Filename and Path
STYLE = StyleName
;
PROC some proc
;
ODS outputtype CLOSE;Poniżej znajduje się opis użytych parametrów -
PATHreprezentuje instrukcję używaną w przypadku wyjścia HTML. W innych typach danych wyjściowych dołączamy ścieżkę do nazwy pliku.
Style reprezentuje jeden z wbudowanych stylów dostępnych w środowisku SAS.
Tworzenie wyjścia HTML
Tworzymy wyjście HTML za pomocą instrukcji ODS HTML W poniższym przykładzie tworzymy plik html w wybranej przez nas ścieżce. Stosujemy styl dostępny w bibliotece stylów. Widzimy plik wyjściowy we wspomnianej ścieżce i możemy go pobrać i zapisać w środowisku innym niż środowisko SAS. Zwróć uwagę, że mamy dwie instrukcje proc SQL i obie ich dane wyjściowe są przechwytywane w jednym pliku.
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
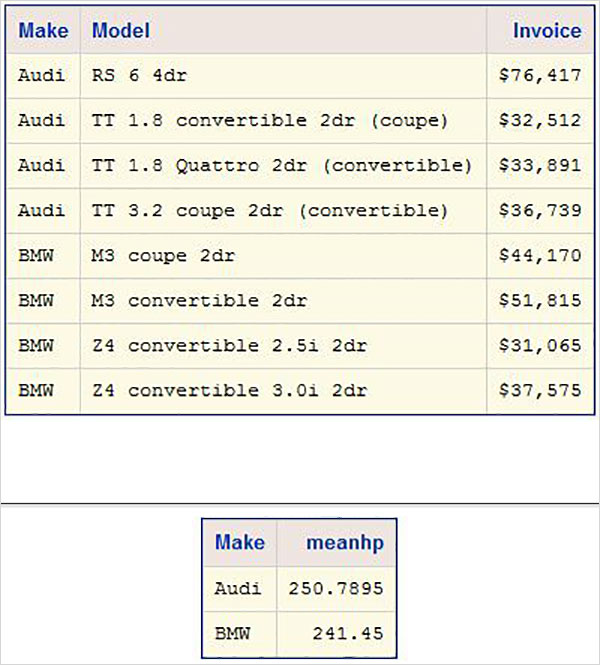
Tworzenie wyjścia PDF
W poniższym przykładzie tworzymy plik PDF w wybranej przez nas ścieżce. Stosujemy styl dostępny w bibliotece stylów. Widzimy plik wyjściowy we wspomnianej ścieżce i możemy go pobrać i zapisać w środowisku innym niż środowisko SAS. Zwróć uwagę, że mamy dwie instrukcje proc SQL i obie ich dane wyjściowe są przechwytywane w jednym pliku.
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
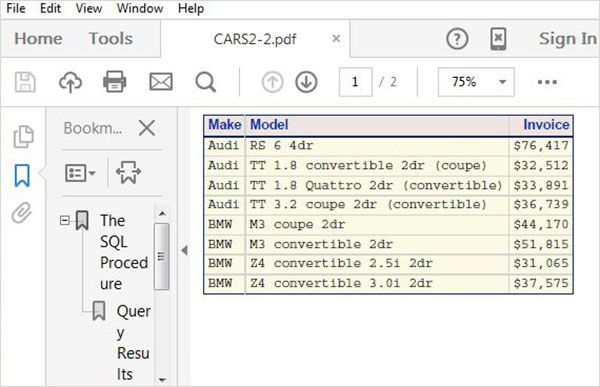
Tworzenie wyjścia TRF (Word)
W poniższym przykładzie tworzymy plik RTF w wybranej przez nas ścieżce. Stosujemy styl dostępny w bibliotece stylów. Widzimy plik wyjściowy we wspomnianej ścieżce i możemy go pobrać i zapisać w środowisku innym niż środowisko SAS. Zwróć uwagę, że mamy dwie instrukcje proc SQL i obie ich dane wyjściowe są przechwytywane w jednym pliku.
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
Symulacja to technika obliczeniowa, która wykorzystuje powtarzalne obliczenia na wielu różnych próbach losowych w celu oszacowania wielkości statystycznej. Za pomocą SAS możemy symulować złożone dane, które mają określone właściwości statystyczne w systemie świata rzeczywistego. Używamy oprogramowania do budowania modelu systemu i numerycznego generowania danych, które można wykorzystać do lepszego zrozumienia zachowania systemu w świecie rzeczywistym. Częścią sztuki projektowania komputerowego modelu symulacyjnego jest decydowanie, które aspekty rzeczywistego systemu należy uwzględnić w modelu, aby dane wygenerowane przez model można było wykorzystać do podejmowania skutecznych decyzji. Z powodu tej złożoności SAS ma dedykowany komponent oprogramowania do symulacji.
Składnik oprogramowania SAS, który jest używany do tworzenia symulacji SAS, nosi nazwę SAS Simulation Studio. Graficzny interfejs użytkownika zapewnia pełny zestaw narzędzi do budowania, wykonywania i analizowania wyników dyskretnych modeli symulacji zdarzeń.
Poniżej wymieniono różne typy rozkładów statystycznych, do których można zastosować symulację SAS.
- SYMULUJ DANE Z CIĄGŁEJ DYSTRYBUCJI
- SYMULUJ DANE Z DYSKRETNEJ DYSTRYBUCJI
- SYMULUJ DANE Z MIESZANKI DYSTRYBUCJI
- SYMULUJ DANE Z KOMPLEKSOWEJ DYSTRYBUCJI
- SYMULUJ DANE Z WIELOWARSTWOWEJ DYSTRYBUCJI
- OKREŚL ROZMIESZCZENIE PRÓBEK
- OCENA SZACUNKÓW REGRESJI
Histogram to graficzne przedstawienie danych za pomocą słupków o różnej wysokości. Grupuje różne liczby w zestawie danych w wiele zakresów. Reprezentuje również oszacowanie prawdopodobieństwa rozkładu zmiennej ciągłej. W SASPROC UNIVARIATE służy do tworzenia histogramów z poniższymi opcjami.
Składnia
Podstawowa składnia tworzenia histogramu w SAS to -
PROC UNIVARAITE DATA = DATASET;
HISTOGRAM variables;
RUN;DATASET to nazwa używanego zbioru danych.
variables są wartościami używanymi do wykreślenia histogramu.
Prosty histogram
Prosty histogram jest tworzony przez określenie nazwy zmiennej i zakresu, który ma być brany pod uwagę przy grupowaniu wartości.
Przykład
W poniższym przykładzie rozważymy minimalne i maksymalne wartości zmiennej mocy i przyjmujemy zakres 50. Zatem wartości tworzą grupę w krokach po 50.
proc univariate data = sashelp.cars;
histogram horsepower
/ midpoints = 176 to 350 by 50;
run;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
Histogram z dopasowaniem krzywej
Niektóre krzywe rozkładu możemy dopasować do histogramu za pomocą dodatkowych opcji.
Przykład
W poniższym przykładzie dopasowujemy krzywą rozkładu z wartościami średniej i odchylenia standardowego podanymi jako EST. Ta opcja wykorzystuje i szacuje parametry.
proc univariate data = sashelp.cars noprint;
histogram horsepower
/
normal (
mu = est
sigma = est
color = blue
w = 2.5
)
barlabel = percent
midpoints = 70 to 550 by 50;
run;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -

Wykres słupkowy przedstawia dane w prostokątnych słupkach o długości słupka proporcjonalnej do wartości zmiennej. SAS stosuje proceduręPROC SGPLOTdo tworzenia wykresów słupkowych. Na wykresie słupkowym możemy narysować zarówno proste, jak i skumulowane słupki. Na wykresie słupkowym każdy ze słupków może mieć inny kolor.
Składnia
Podstawowa składnia tworzenia wykresu słupkowego w SAS to -
PROC SGPLOT DATA = DATASET;
VBAR variables;
RUN;DATASET - to nazwa używanego zbioru danych.
variables - są wartościami używanymi do wykreślenia histogramu.
Prosty wykres słupkowy
Prosty wykres słupkowy to wykres słupkowy, na którym zmienna ze zbioru danych jest reprezentowana jako słupki.
Przykład
Poniższy skrypt utworzy wykres słupkowy przedstawiający długość samochodów w postaci słupków.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
Wykres słupkowy skumulowany
Skumulowany wykres słupkowy to wykres słupkowy, na którym zmienna ze zbioru danych jest obliczana w odniesieniu do innej zmiennej.
Przykład
Poniższy skrypt utworzy skumulowany wykres słupkowy, na którym obliczana jest długość samochodów dla każdego typu samochodu. Używamy opcji grupy, aby określić drugą zmienną.
proc SGPLOT data = work.cars1;
vbar length /group = type ;
title 'Lengths of Cars by Types';
run;
quit;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
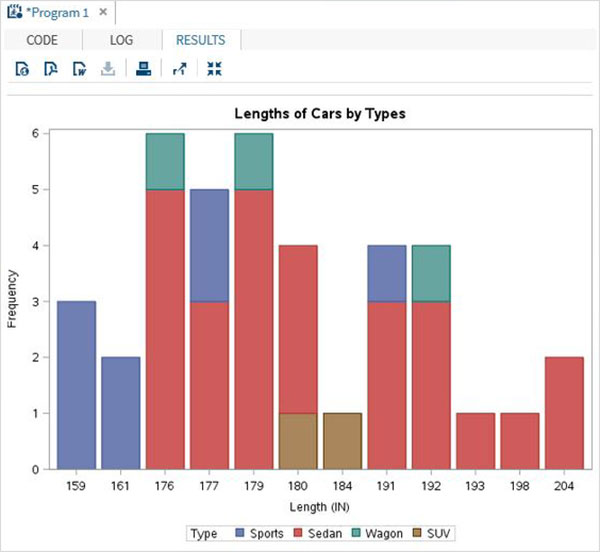
Wykres słupkowy grupowany
Wykres słupkowy grupowany jest tworzony w celu pokazania, jak wartości zmiennej są rozmieszczone w kulturze.
Przykład
Poniższy skrypt utworzy grupowany wykres słupkowy, na którym długość samochodów jest zgrupowana wokół typu samochodu. Widzimy więc dwa sąsiednie słupki o długości 191, jeden dla typu samochodu „Sedan”, a drugi dla samochodu typu „Wagon” .
proc SGPLOT data = work.cars1;
vbar length /group = type GROUPDISPLAY = CLUSTER;
title 'Cluster of Cars by Types';
run;
quit;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -

Wykres kołowy przedstawia wartości jako wycinki koła o różnych kolorach. Plasterki są oznaczone etykietami, a liczby odpowiadające każdemu wycinkowi są również przedstawione na wykresie.
W SAS wykres kołowy jest tworzony za pomocą PROC TEMPLATE który przyjmuje parametry, aby kontrolować procent, etykiety, kolor, tytuł itp.
Składnia
Podstawowa składnia tworzenia wykresu kołowego w SAS to -
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;variable to wartość, dla której tworzymy wykres kołowy.
Prosty wykres kołowy
Na tym wykresie kołowym pobieramy pojedynczą zmienną ze zbioru danych. Wykres kołowy tworzony jest z wartością wycinków reprezentujących ułamek liczebności zmiennej w stosunku do całkowitej wartości zmiennej.
Przykład
W poniższym przykładzie każdy wycinek reprezentuje ułamek typu samochodu z całkowitej liczby samochodów.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
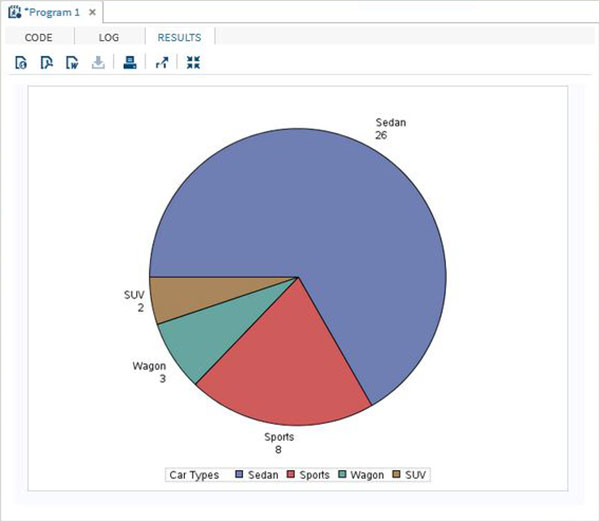
Wykres kołowy z etykietami danych
Na tym wykresie kołowym przedstawiamy zarówno wartość ułamkową, jak i procentową dla każdego wycinka. Zmieniamy również położenie etykiety, tak aby znajdowała się wewnątrz wykresu. Styl wyglądu wykresu jest modyfikowany za pomocą opcji DATASKIN. Używa jednego z wbudowanych stylów, dostępnych w środowisku SAS.
Przykład
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
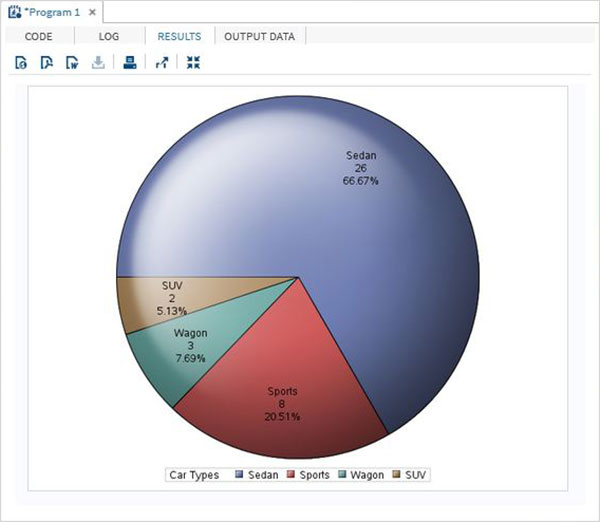
Zgrupowany wykres kołowy
Na tym wykresie kołowym wartość zmiennej przedstawionej na wykresie jest zgrupowana względem innej zmiennej o tym samym zbiorze danych. Każda grupa staje się jednym okręgiem, a wykres zawiera tyle koncentrycznych okręgów, ile jest dostępnych grup.
Przykład
W poniższym przykładzie grupujemy wykres ze względu na zmienną o nazwie „Make”. Ponieważ dostępne są dwie wartości („Audi” i „BMW”), otrzymujemy dwa koncentryczne okręgi, z których każdy reprezentuje wycinki typów samochodów własnej marki.
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
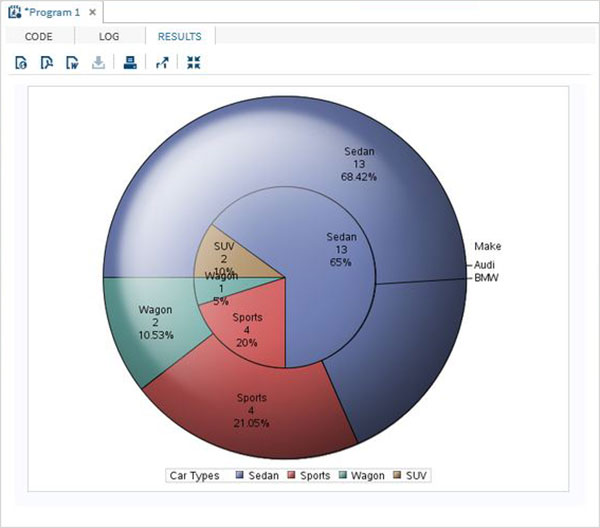
Wykres rozrzutu to rodzaj wykresu, który wykorzystuje wartości dwóch zmiennych wykreślonych na płaszczyźnie kartezjańskiej. Zwykle służy do znalezienia związku między dwiema zmiennymi. W SAS używamyPROC SGSCATTER do tworzenia wykresów rozrzutu.
Należy pamiętać, że w pierwszym przykładzie tworzymy zbiór danych o nazwie CARS1 i używamy tego samego zestawu danych dla wszystkich kolejnych zestawów danych. Ten zestaw danych pozostaje w bibliotece roboczej do końca sesji SAS.
Składnia
Podstawowa składnia tworzenia wykresu punktowego w SAS to -
PROC sgscatter DATA = DATASET;
PLOT VARIABLE_1 * VARIABLE_2
/ datalabel = VARIABLE group = VARIABLE;
RUN;Poniżej znajduje się opis użytych parametrów -
DATASET to nazwa zbioru danych.
VARIABLE jest zmienną używaną ze zbioru danych.
Prosty wykres rozrzutu
Na prostym wykresie rozrzutu wybieramy dwie zmienne ze zbioru danych i grupujemy je według trzeciej zmiennej. Możemy również oznaczyć dane. Wynik pokazuje, jak dwie zmienne są rozproszone wCartesian plane.
Przykład
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
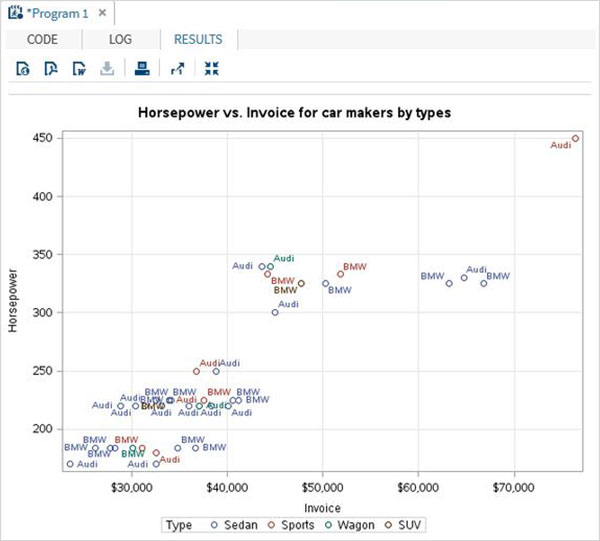
Wykres rozrzutu z prognozą
możemy użyć parametru estymacji, aby przewidzieć siłę korelacji między, rysując elipsę wokół wartości. Korzystamy z dodatkowych opcji procedury, aby narysować elipsę, jak pokazano poniżej.
Przykład
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -

Matryca rozproszona
Możemy również utworzyć wykres rozrzutu obejmujący więcej niż dwie zmienne, grupując je w pary. W poniższym przykładzie rozważymy trzy zmienne i narysujemy macierz wykresów punktowych. Otrzymujemy 3 pary wynikowej macierzy.
Przykład
PROC sgscatter DATA = CARS1;
matrix horsepower invoice length
/ group = type;
title 'Horsepower vs. Invoice vs. Length for car makers by types';
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
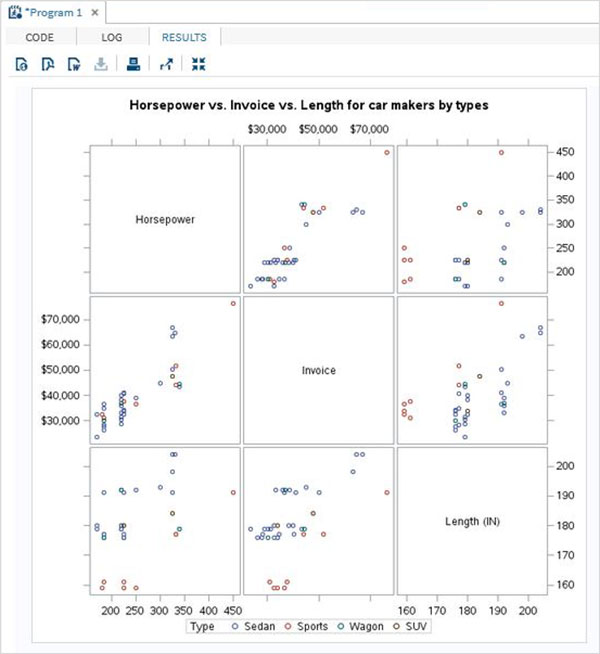
Wykres pudełkowy to graficzna reprezentacja grup danych liczbowych za pomocą ich kwartyli. Wykresy pudełkowe mogą również mieć linie wychodzące pionowo z prostokąta (wąsy) wskazujące na zmienność poza górny i dolny kwartyl. Dół i góra prostokąta to zawsze pierwszy i trzeci kwartyl, a pasmo wewnątrz prostokąta to zawsze drugi kwartyl (mediana). W SAS prosty Boxplot jest tworzony za pomocąPROC SGPLOT a panelowy wykres pudełkowy jest tworzony za pomocą PROC SGPANEL.
Należy pamiętać, że w pierwszym przykładzie tworzymy zbiór danych o nazwie CARS1 i używamy tego samego zestawu danych dla wszystkich kolejnych zestawów danych. Ten zestaw danych pozostaje w bibliotece roboczej do końca sesji SAS.
Składnia
Podstawowa składnia tworzenia wykresu pudełkowego w SAS to -
PROC SGPLOT DATA = DATASET;
VBOX VARIABLE / category = VARIABLE;
RUN;
PROC SGPANEL DATA = DATASET;;
PANELBY VARIABLE;
VBOX VARIABLE> / category = VARIABLE;
RUN;DATASET - to nazwa używanego zbioru danych.
VARIABLE - to wartość używana do wykreślania wykresu pudełkowego.
Prosty wykres pudełkowy
W prostym wykresie Boxplot wybieramy jedną zmienną ze zbioru danych, a drugą w celu utworzenia kategorii. Wartości pierwszej zmiennej są podzielone na kategorie w liczbie grup równej liczbie odrębnych wartości w drugiej zmiennej.
Przykład
W poniższym przykładzie wybieramy zmienną moc jako pierwszą zmienną i wpisujemy jako zmienną kategorii. Otrzymujemy więc wykresy pudełkowe dla rozkładu wartości mocy dla każdego typu samochodu.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
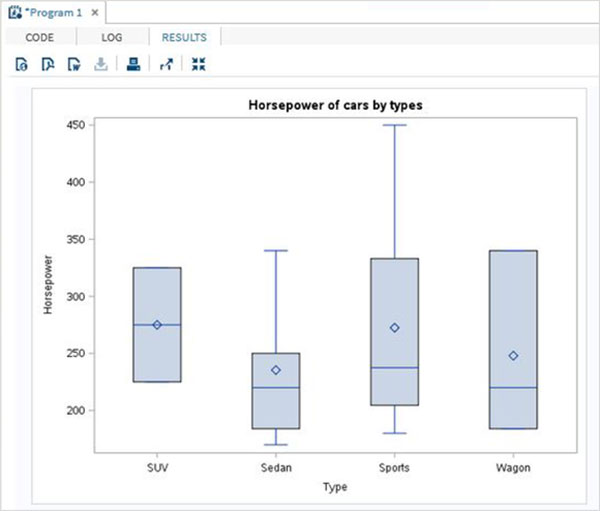
Boxplot w panelach pionowych
Możemy podzielić Boxplots zmiennej na wiele pionowych paneli (kolumn). Każdy panel zawiera wykresy pudełkowe dla wszystkich zmiennych kategorialnych. Ale wykresy pudełkowe są dalej grupowane przy użyciu innej trzeciej zmiennej, która dzieli wykres na wiele paneli.
Przykład
W poniższym przykładzie umieściliśmy wykres za pomocą zmiennej „make”. Ponieważ istnieją dwie różne wartości parametru „make”, otrzymujemy dwa panele pionowe.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
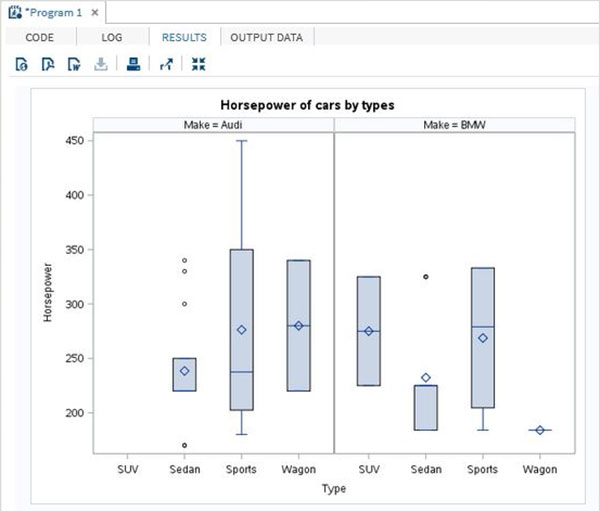
Boxplot w poziomych panelach
Możemy podzielić Boxplots zmiennej na wiele poziomych paneli (rzędów). Każdy panel zawiera wykresy pudełkowe dla wszystkich zmiennych kategorialnych. Ale wykresy pudełkowe są dalej grupowane przy użyciu innej trzeciej zmiennej, która dzieli wykres na wiele paneli. W poniższym przykładzie umieściliśmy wykres za pomocą zmiennej „make”. Ponieważ istnieją dwie różne wartości parametru „make”, otrzymujemy dwa poziome panele.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE / columns = 1 novarname;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Kiedy wykonujemy powyższy kod, otrzymujemy następujący wynik -
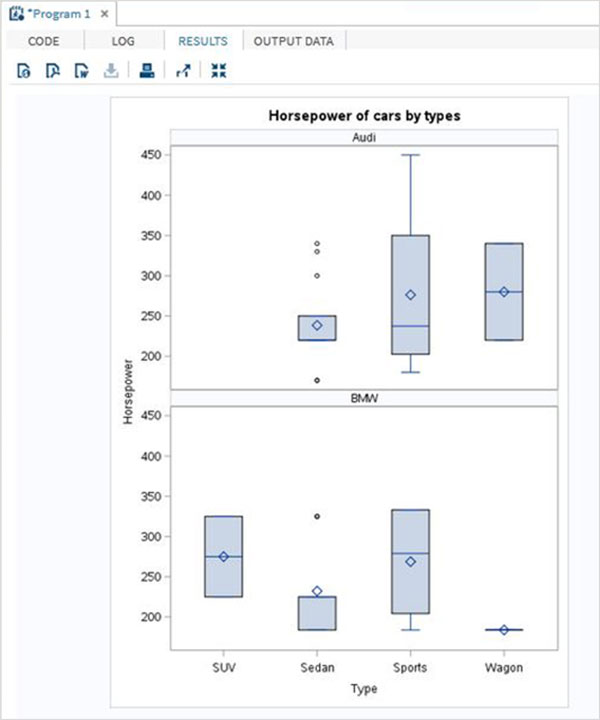
Średnia arytmetyczna to wartość otrzymana przez zsumowanie wartości zmiennych numerycznych, a następnie podzielenie sumy przez liczbę zmiennych. Nazywa się to również średnią. W SAS średnia arytmetyczna jest obliczana za pomocąPROC MEANS. Używając tej procedury SAS, możemy znaleźć średnią wszystkich zmiennych lub niektórych zmiennych zbioru danych. Możemy również tworzyć grupy i znaleźć średnią zmiennych o wartościach specyficznych dla tej grupy.
Składnia
Podstawowa składnia do obliczania średniej arytmetycznej w SAS to -
PROC MEANS DATA = DATASET;
CLASS Variables ;
VAR Variables;Poniżej znajduje się opis użytych parametrów -
DATASET - to nazwa używanego zbioru danych.
Variables - to nazwa zmiennej ze zbioru danych.
Średnia zbioru danych
Średnia z każdej zmiennej numerycznej w zbiorze danych jest obliczana przy użyciu funkcji PROC, podając tylko nazwę zbioru danych bez żadnych zmiennych.
Przykład
W poniższym przykładzie znajdujemy średnią wszystkich zmiennych numerycznych w zbiorze danych SAS o nazwie CARS. Określamy maksymalną liczbę cyfr po przecinku na 2, a także znajdujemy sumę tych zmiennych.
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
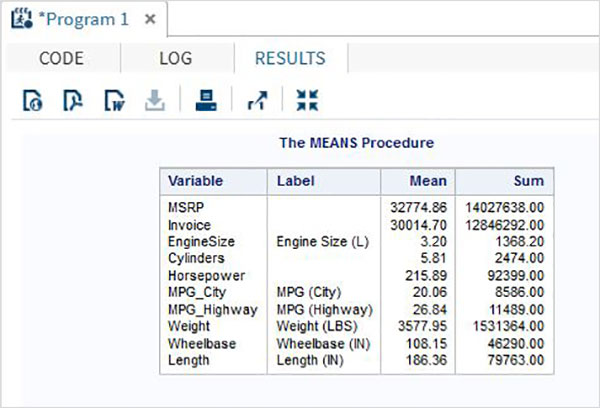
Średnia wybranych zmiennych
Możemy uzyskać średnią niektórych zmiennych, podając ich nazwy w var opcja.
Przykład
Poniżej obliczamy średnią z trzech zmiennych.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ;
var horsepower invoice EngineSize;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
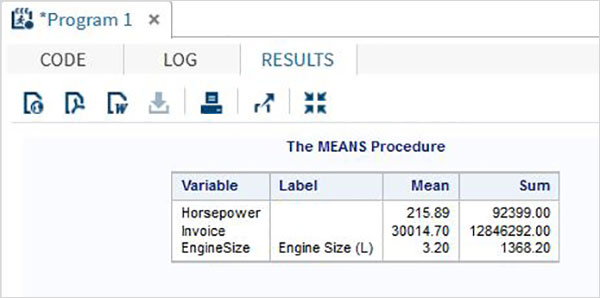
Średnia według klasy
Możemy znaleźć średnią zmiennych numerycznych, organizując je w grupy za pomocą innych zmiennych.
Przykład
W poniższym przykładzie znajdujemy średnią zmiennej mocy dla każdego typu dla każdej marki samochodu.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2;
class make type;
var horsepower;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
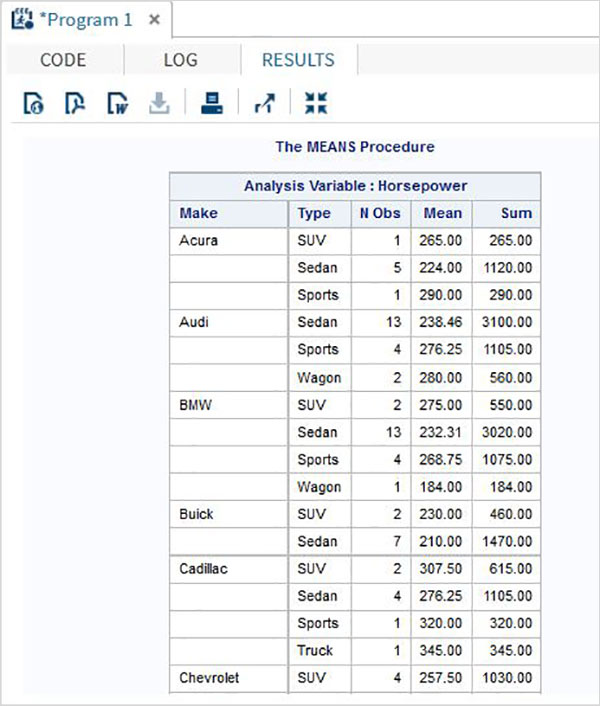
Odchylenie standardowe (SD) jest miarą zróżnicowania danych w zestawie danych. Matematycznie mierzy, jak odległa lub bliska jest każda wartość w stosunku do średniej wartości zbioru danych. Wartość odchylenia standardowego bliska 0 wskazuje, że punkty danych są zazwyczaj bardzo zbliżone do średniej zbioru danych, a wysokie odchylenie standardowe wskazuje, że punkty danych są rozłożone w szerszym zakresie wartości
W SAS wartości SD są mierzone za pomocą PROC MEAN oraz PROC SURVEYMEANS.
Używanie ŚRODKÓW PROC
Aby zmierzyć SD za pomocą proc meanswybieramy opcję STD w kroku PROC. Podaje wartości SD dla każdej zmiennej numerycznej obecnej w zestawie danych.
Składnia
Podstawowa składnia obliczania odchylenia standardowego w SAS to -
PROC means DATA = dataset STD;Poniżej znajduje się opis użytych parametrów -
Dataset - to nazwa zbioru danych.
Przykład
W poniższym przykładzie tworzymy zestaw danych CARS1 z zestawu danych CARS w bibliotece SASHELP. Wybieramy opcję STD z krokiem PROC oznacza.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;Kiedy wykonujemy powyższy kod, daje to następujące wyjście -
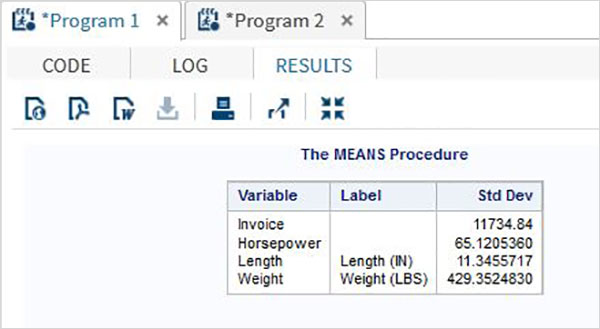
Korzystanie z PROC SURVEYMEANS
Ta procedura jest również używana do pomiaru odchylenia standardowego wraz z pewnymi zaawansowanymi funkcjami, takimi jak pomiar odchylenia standardowego dla zmiennych kategorialnych, a także zapewnia oszacowania wariancji.
Składnia
Składnia użycia PROC SURVEYMEANS to -
PROC SURVEYMEANS options statistic-keywords ;
BY variables ;
CLASS variables ;
VAR variables ;Poniżej znajduje się opis użytych parametrów -
BY - wskazuje zmienne używane do tworzenia grup obserwacji.
CLASS - wskazuje zmienne używane dla zmiennych kategorialnych.
VAR - wskazuje zmienne, dla których zostanie obliczone SD.
Przykład
Poniższy przykład opisuje użycie class opcja, która tworzy statystyki dla każdej wartości w zmiennej klasy.
proc surveymeans data = CARS1 STD;
class type;
var type horsepower;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Kiedy wykonujemy powyższy kod, daje to następujące wyjście -
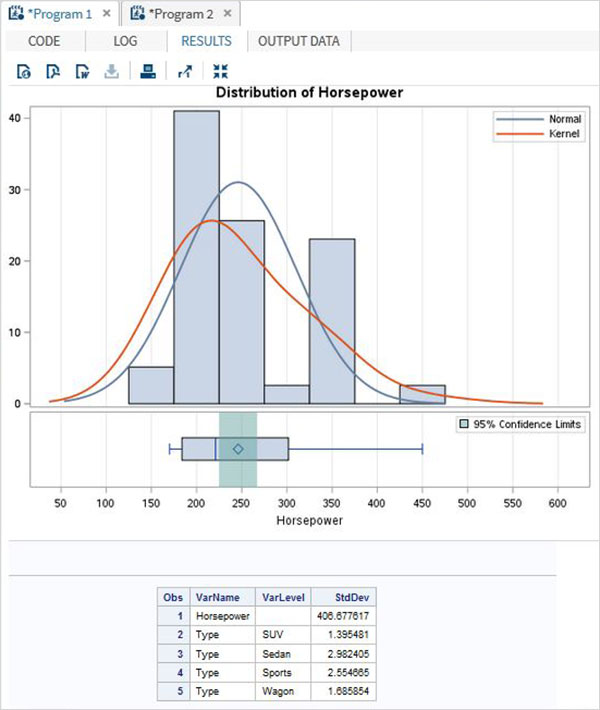
Korzystanie z opcji BY
Poniższy kod przedstawia przykład opcji BY. W nim wynik jest grupowany dla każdej wartości w opcji BY.
Przykład
proc surveymeans data = CARS1 STD;
var horsepower;
BY make;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Kiedy wykonujemy powyższy kod, daje to następujące wyjście -
Wynik dla make = „Audi”

Wynik dla marki = „BMW”
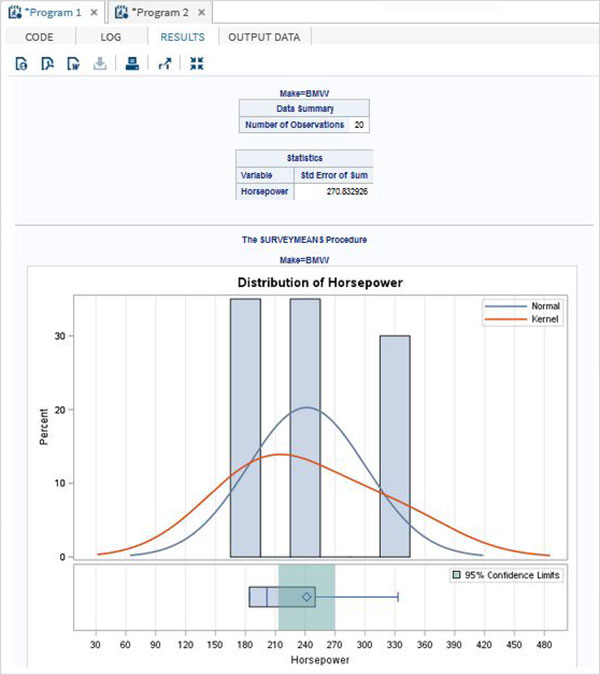
Rozkład częstotliwości to tabela pokazująca częstotliwość punktów danych w zbiorze danych. Każdy wpis w tabeli zawiera częstość lub liczbę wystąpień wartości w określonej grupie lub przedziale iw ten sposób tabela podsumowuje rozkład wartości w próbie.
SAS udostępnia procedurę o nazwie PROC FREQ obliczyć rozkład częstotliwości punktów danych w zbiorze danych.
Składnia
Podstawowa składnia do obliczania rozkładu częstotliwości w SAS to -
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;Poniżej znajduje się opis użytych parametrów -
Dataset to nazwa zbioru danych.
Variables_1 to nazwy zmiennych zbioru danych, którego rozkład częstotliwości ma zostać obliczony.
Variables_2 to zmienne, które klasyfikowały wynik rozkładu częstotliwości.
Rozkład pojedynczej zmiennej częstotliwości
Możemy określić rozkład częstotliwości pojedynczej zmiennej za pomocą PROC FREQ.W takim przypadku wynik pokaże częstotliwość każdej wartości zmiennej. Wynik pokazuje również rozkład procentowy, skumulowaną częstotliwość i skumulowany procent.
Przykład
W poniższym przykładzie znajdujemy rozkład częstotliwości zmiennej mocy dla nazwanego zbioru danych CARS1 który jest tworzony z biblioteki SASHELP.CARS.Widzimy wynik podzielony na dwie kategorie wyników. Po jednym dla każdej marki samochodu.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -

Rozkład wielu zmiennych częstotliwości
Możemy znaleźć rozkłady częstotliwości dla wielu zmiennych, które grupują je we wszystkie możliwe kombinacje.
Przykład
W poniższym przykładzie obliczamy rozkład częstotliwości dla marki samochodu dla grouped by car type a także rozkład częstotliwości każdego typu samochodu grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
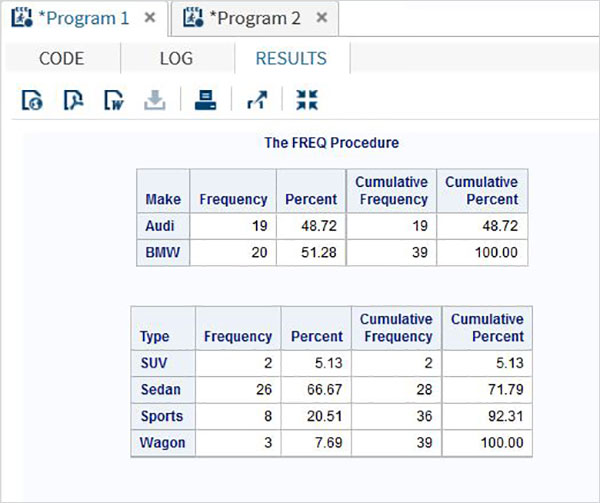
Rozkład częstotliwości z wagą
Dzięki opcji wagi możemy obliczyć rozkład częstotliwości obciążony wagą zmiennej. Tutaj wartość zmiennej jest przyjmowana jako liczba obserwacji, a nie liczba wartości.
Przykład
W poniższym przykładzie obliczamy rozkład częstotliwości marki i typu zmiennych z wagą przypisaną do mocy.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
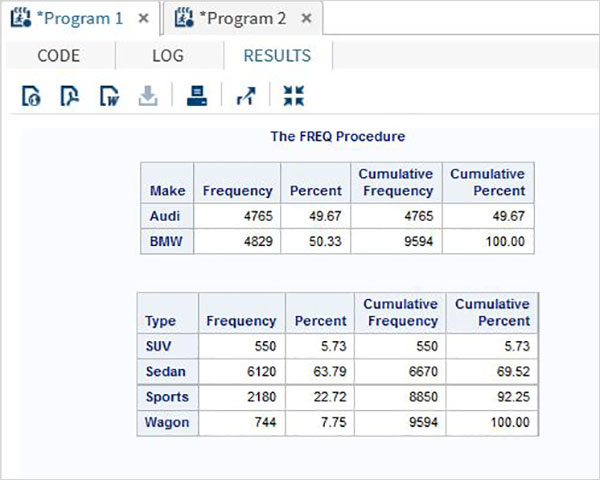
Tabele krzyżowe obejmują tworzenie tabel krzyżowych, zwanych również tabelami warunkowymi, przy użyciu wszystkich możliwych kombinacji dwóch lub więcej zmiennych. W SAS jest tworzony za pomocąPROC FREQ razem z TABLESopcja. Na przykład - jeśli potrzebujemy częstotliwości każdego modelu dla każdej marki w każdej kategorii typu samochodu, to musimy użyć opcji TABLES w PROC FREQ.
Składnia
Podstawowa składnia stosowania tabel krzyżowych w SAS to -
PROC FREQ DATA = dataset;
TABLES variable_1*Variable_2;Poniżej znajduje się opis użytych parametrów -
Dataset to nazwa zbioru danych.
Variable_1 and Variable_2 to nazwy zmiennych zbioru danych, którego rozkład częstotliwości ma zostać obliczony.
Przykład
Rozważmy przypadek znalezienia liczby typów samochodów dostępnych pod każdą marką na podstawie utworzonego formularza zbioru danych samochody1 SASHELP.CARSjak pokazano niżej. W tym przypadku potrzebujemy indywidualnych wartości częstotliwości, a także sumy wartości częstotliwości dla różnych marek i dla wszystkich typów. Możemy zaobserwować, że wynik pokazuje wartości w wierszach i kolumnach.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
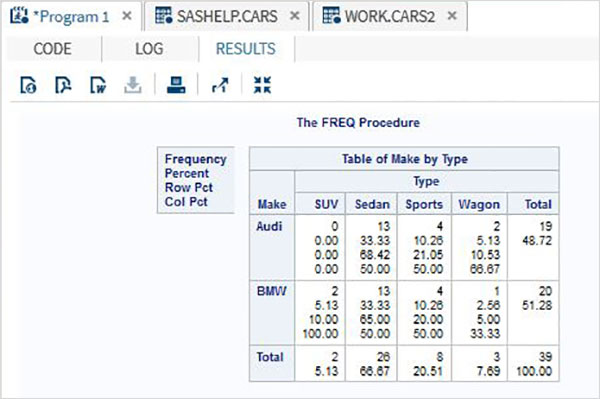
Zestawienie krzyżowe 3 zmiennych
Kiedy mamy trzy zmienne, możemy zgrupować 2 z nich i zestawić każdą z nich w tabeli z trzecią zmienną. W rezultacie mamy dwie tabele krzyżowe.
Przykład
W poniższym przykładzie znajdujemy częstotliwość występowania każdego typu samochodu i każdego modelu samochodu w odniesieniu do marki samochodu. Używamy również opcji nocol i norow, aby uniknąć sum i wartości procentowych.
proc FREQ data = CARS2 ;
tables make * (type model) / nocol norow nopercent;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
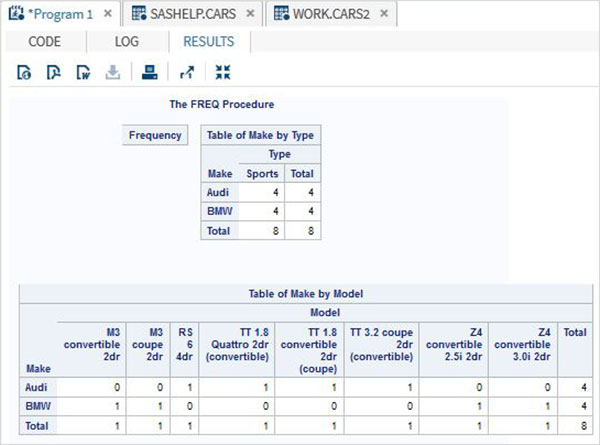
Zestawienie krzyżowe 4 zmiennych
Przy 4 zmiennych liczba sparowanych kombinacji wzrasta do 4. Każda zmienna z grupy 1 jest sparowana z każdą zmienną z grupy 2.
Przykład
W poniższym przykładzie znajdujemy częstotliwość długości samochodu dla każdej marki i każdego modelu. Podobnie częstotliwość koni mechanicznych dla każdej marki i każdego modelu.
proc FREQ data = CARS2 ;
tables (make model) * (length horsepower) / nocol norow nopercent;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
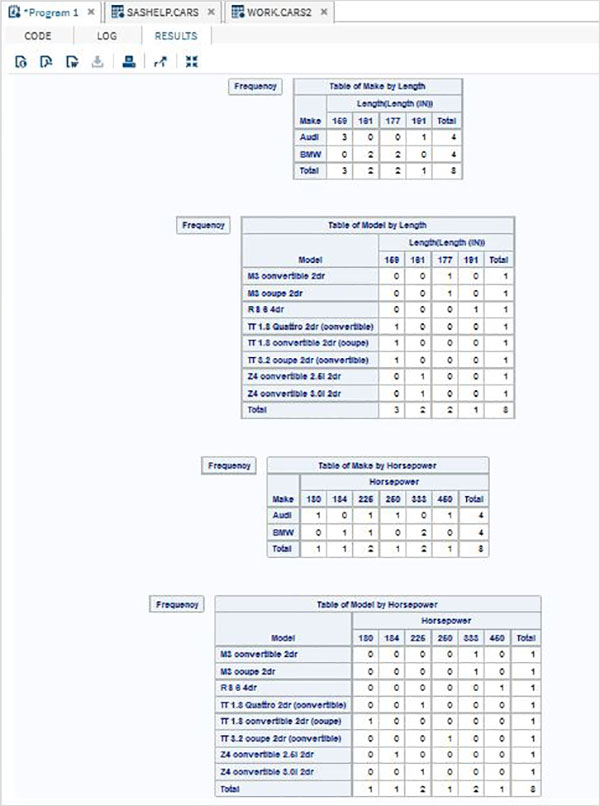
Testy T są wykonywane w celu obliczenia granic ufności dla jednej próbki lub dwóch niezależnych próbek poprzez porównanie ich średnich i średnich różnic. Procedura SAS o nazwiePROC TTEST służy do przeprowadzania testów t na jednej zmiennej i parze zmiennych.
Składnia
Podstawowa składnia stosowania PROC TTEST w SAS to -
PROC TTEST DATA = dataset;
VAR variable;
CLASS Variable;
PAIRED Variable_1 * Variable_2;Poniżej znajduje się opis użytych parametrów -
Dataset to nazwa zbioru danych.
Variable_1 and Variable_2 to nazwy zmiennych zbioru danych używanego w teście t.
Przykład
Poniżej widzimy jeden próbny test t, w którym znajduje się oszacowanie testu t dla zmiennej mocy z 95% granicami ufności.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
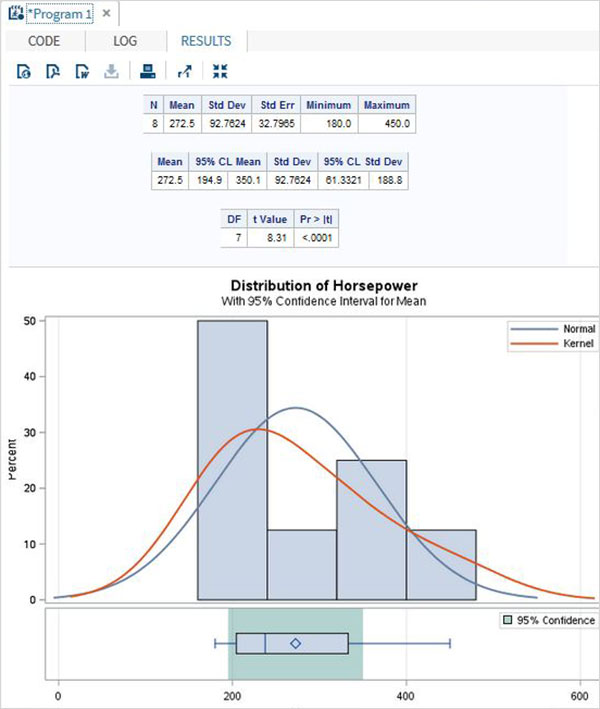
Sparowany test T.
Test T dla par jest przeprowadzany w celu sprawdzenia, czy dwie zmienne zależne różnią się od siebie statystycznie, czy nie.
Przykład
Ponieważ długość i waga samochodu będą od siebie zależne, stosujemy test T dla par, jak pokazano poniżej.
proc ttest data = cars1 ;
paired weight*length;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
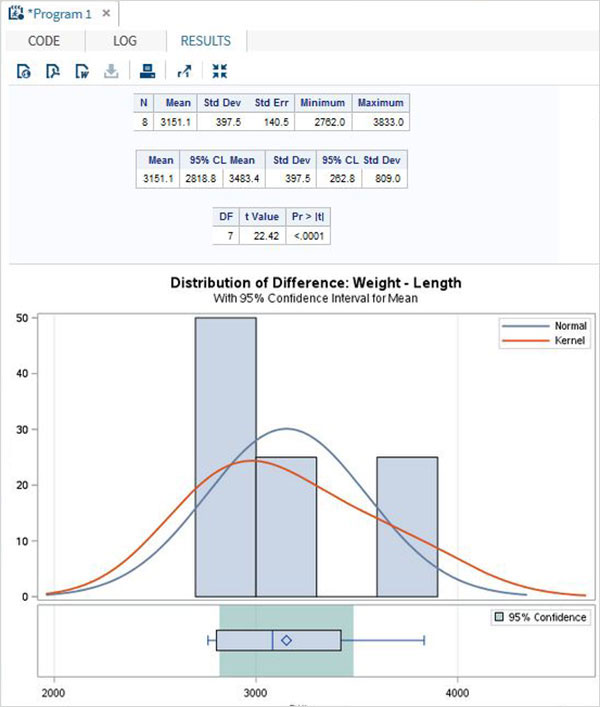
Test t dla dwóch próbek
Ten test t ma na celu porównanie średnich tej samej zmiennej między dwiema grupami.
Przykład
W naszym przypadku porównujemy średnią zmienną moc pomiędzy dwoma różnymi markami samochodów („Audi” i „BMW”).
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0;
title "Two sample t-test example";
class make;
var horsepower;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
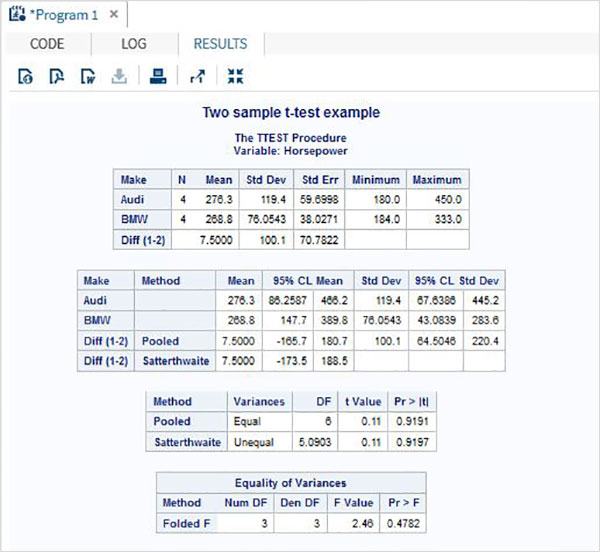
Analiza korelacji dotyczy relacji między zmiennymi. Współczynnik korelacji jest miarą zależności liniowej między dwiema zmiennymi. Wartości współczynnika korelacji zawsze mieszczą się w zakresie od -1 do +1. SAS zapewnia proceduręPROC CORR znaleźć współczynniki korelacji między parą zmiennych w zbiorze danych.
Składnia
Podstawowa składnia stosowania PROC CORR w SAS to -
PROC CORR DATA = dataset options;
VAR variable;Poniżej znajduje się opis użytych parametrów -
Dataset to nazwa zbioru danych.
Options to dodatkowa opcja z procedurą, taką jak wykreślanie macierzy itp.
Variable to nazwa zmiennej zbioru danych użyta do znalezienia korelacji.
Przykład
Współczynniki korelacji między parą zmiennych dostępnych w zbiorze danych można uzyskać, używając ich nazw w instrukcji VAR W poniższym przykładzie używamy zestawu danych CARS1 i otrzymujemy wynik pokazujący współczynniki korelacji między mocą mechaniczną a masą.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
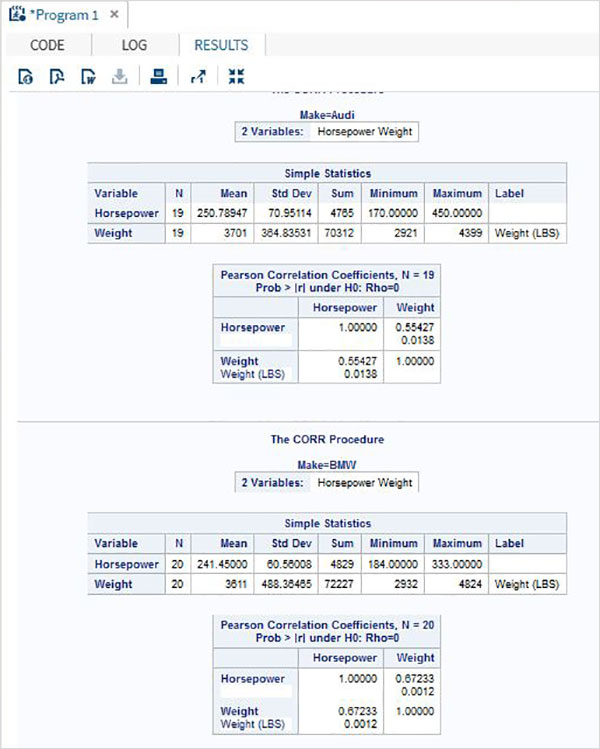
Korelacja między wszystkimi zmiennymi
Współczynniki korelacji między wszystkimi zmiennymi dostępnymi w zbiorze danych można uzyskać, po prostu stosując procedurę z nazwą zbioru danych.
Przykład
W poniższym przykładzie używamy zestawu danych CARS1 i otrzymujemy wynik pokazujący współczynniki korelacji między każdą parą zmiennych.
proc corr data = cars1 ;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
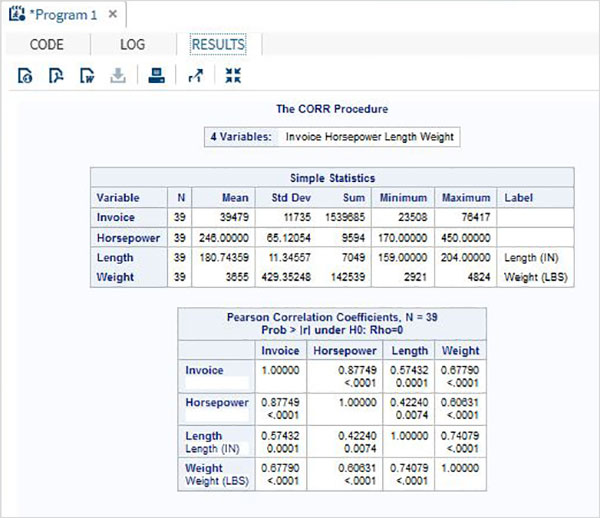
Macierz korelacji
Macierz wykresu rozrzutu między zmiennymi możemy uzyskać, wybierając opcję wykreślania macierzy w formacie PROC komunikat.
Przykład
W poniższym przykładzie otrzymujemy macierz między mocą a masą.
proc corr data = cars1 plots = matrix ;
VAR horsepower weight ;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
Regresja liniowa służy do identyfikacji związku między zmienną zależną a co najmniej jedną zmienną niezależną. Zaproponowano model zależności, a oszacowania wartości parametrów posłużą do opracowania oszacowanego równania regresji.
Następnie stosuje się różne testy, aby określić, czy model jest zadowalający. Jeśli tak jest, oszacowane równanie regresji można wykorzystać do przewidywania wartości zmiennej zależnej podanych wartości dla zmiennych niezależnych. W SAS proceduraPROC REG służy do znalezienia modelu regresji liniowej między dwiema zmiennymi.
Składnia
Podstawowa składnia stosowania PROC REG w SAS to -
PROC REG DATA = dataset;
MODEL variable_1 = variable_2;Poniżej znajduje się opis użytych parametrów -
Dataset to nazwa zbioru danych.
variable_1 and variable_2 są nazwami zmiennych zbioru danych użytymi do znalezienia korelacji.
Przykład
Poniższy przykład pokazuje proces znajdowania korelacji między dwiema zmiennymi moc i masą samochodu przy użyciu PROC REG. W rezultacie widzimy wartości przecięcia, które można wykorzystać do utworzenia równania regresji.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
Powyższy kod daje również graficzny widok różnych oszacowań modelu, jak pokazano poniżej. Będąc zaawansowaną procedurą SAS, po prostu nie kończy się na podawaniu wartości przecięcia jako danych wyjściowych.
Analiza Blanda-Altmana to proces mający na celu sprawdzenie zakresu zgodności lub braku zgody między dwiema metodami zaprojektowanymi do pomiaru tych samych parametrów. Wysoka korelacja między metodami wskazuje, że do analizy danych wybrano wystarczająco dobrą próbę. W SAS tworzymy wykres Blanda-Altmana, obliczając średnią, górną i dolną granicę wartości zmiennych. Następnie używamy PROC SGPLOT do tworzenia wykresu Blanda-Altmana.
Składnia
Podstawowa składnia stosowania PROC SGPLOT w SAS to -
PROC SGPLOT DATA = dataset;
SCATTER X = variable Y = Variable;
REFLINE value;Poniżej znajduje się opis użytych parametrów -
Dataset to nazwa zbioru danych.
SCATTER oświadczenie tworzy wykres punktowy wartości podanej w postaci X i Y.
REFLINE tworzy poziomą lub pionową linię odniesienia.
Przykład
W poniższym przykładzie bierzemy wynik dwóch eksperymentów wygenerowanych za pomocą dwóch metod nazwanych nowa i stara. Obliczamy różnice wartości zmiennych, a także średnią zmiennych z tej samej obserwacji. Obliczamy również wartości odchylenia standardowego, które mają być użyte w górnej i dolnej granicy obliczenia.
Wynik przedstawia wykres Blanda-Altmana jako wykres punktowy.
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
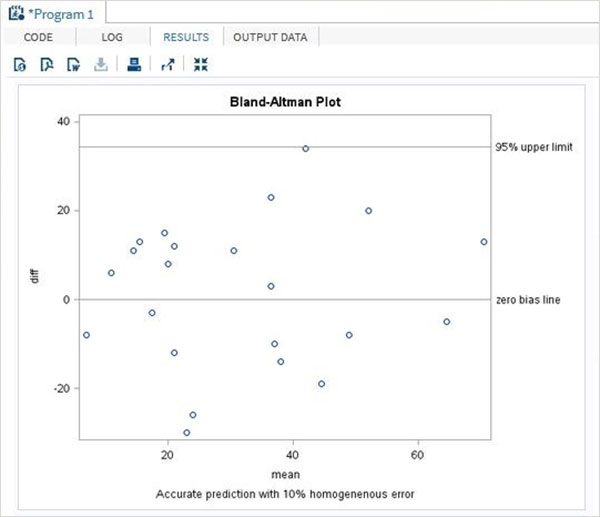
Ulepszony model
W ulepszonym modelu powyższego programu otrzymujemy dopasowanie krzywej poziomu ufności 95 procent.
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
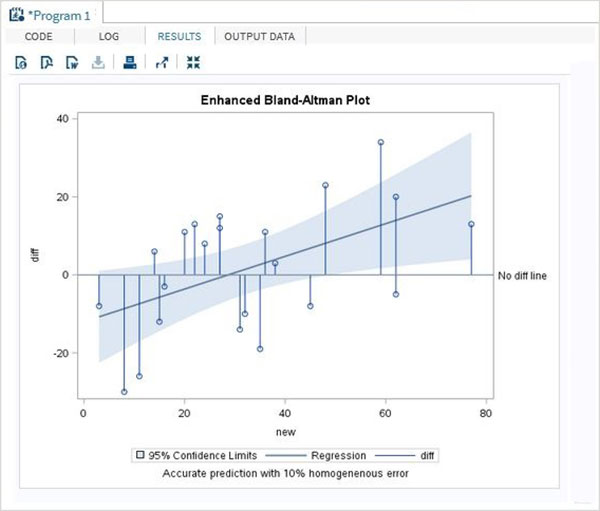
Test chi-kwadrat służy do badania związku między dwiema zmiennymi kategorialnymi. Można go używać do testowania zarówno stopnia zależności, jak i stopnia niezależności między zmiennymi. SAS używaPROC FREQ wraz z opcją chisq aby określić wynik testu Chi-kwadrat.
Składnia
Podstawowa składnia stosowania PROC FREQ do testu Chi-kwadrat w SAS to -
PROC FREQ DATA = dataset;
TABLES variables
/CHISQ TESTP = (percentage values);Poniżej znajduje się opis użytych parametrów -
Dataset to nazwa zbioru danych.
Variables są nazwami zmiennych zbioru danych używanymi w teście chi-kwadrat.
Percentage Values w instrukcji TESTP reprezentują procent poziomów zmiennej.
Przykład
W poniższym przykładzie rozważymy test chi-kwadrat na zmiennej o nazwie typ w zbiorze danych SASHELP.CARS. Ta zmienna ma sześć poziomów, a każdemu poziomowi przypisujemy procent zgodnie z projektem testu.
proc freq data = sashelp.cars;
tables type
/chisq
testp = (0.20 0.12 0.18 0.10 0.25 0.15);
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -

Otrzymujemy również wykres słupkowy pokazujący odchylenie typu zmiennej, jak pokazano na poniższym zrzucie ekranu.
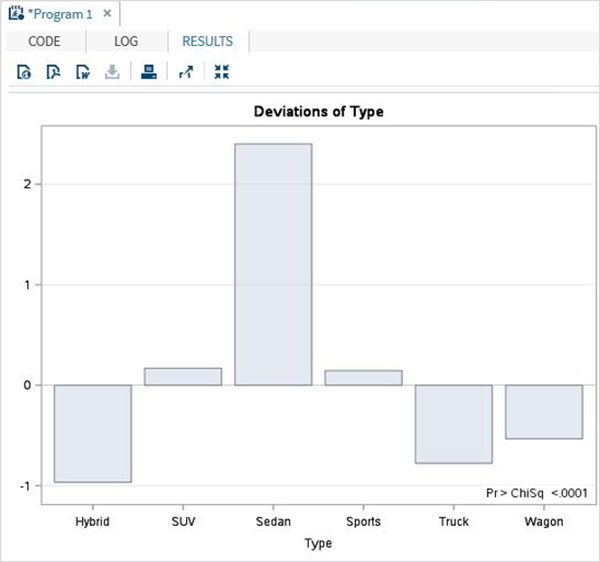
Dwukierunkowy chi-kwadrat
Dwukierunkowy test Chi-kwadrat jest używany, gdy stosujemy testy do dwóch zmiennych zbioru danych.
Przykład
W poniższym przykładzie stosujemy test chi-kwadrat na dwóch zmiennych o nazwach typ i pochodzenie. Wynik przedstawia tabelaryczną formę wszystkich kombinacji tych dwóch zmiennych.
proc freq data = sashelp.cars;
tables type*origin
/chisq
;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
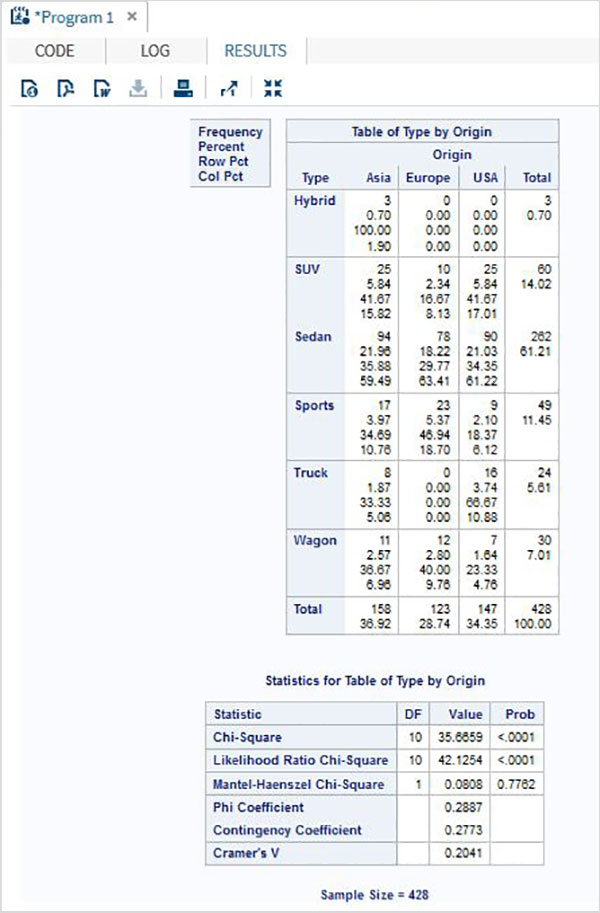
Dokładny test Fishera jest testem statystycznym używanym do określenia, czy istnieją nielosowe powiązania między dwiema zmiennymi kategorialnymi. PROC FREQ. Używamy opcji Tabele, aby użyć dwóch zmiennych poddanych dokładnemu testowi Fishera.
Składnia
Podstawowa składnia stosowania testu Fisher Exact w SAS to -
PROC FREQ DATA = dataset ;
TABLES Variable_1*Variable_2 / fisher;Poniżej znajduje się opis użytych parametrów -
dataset to nazwa zbioru danych.
Variable_1*Variable_2 to zmienne tworzące zbiór danych.
Stosowanie dokładnego testu Fishera
Aby zastosować dokładny test Fishera, wybieramy dwie zmienne kategorialne o nazwach Test1 i Test2 oraz ich wynik. Używamy PROC FREQ do zastosowania testu pokazanego poniżej.
Przykład
data temp;
input Test1 Test2 Result @@;
datalines;
1 1 3 1 2 1 2 1 1 2 2 3
;
proc freq;
tables Test1*Test2 / fisher;
run;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
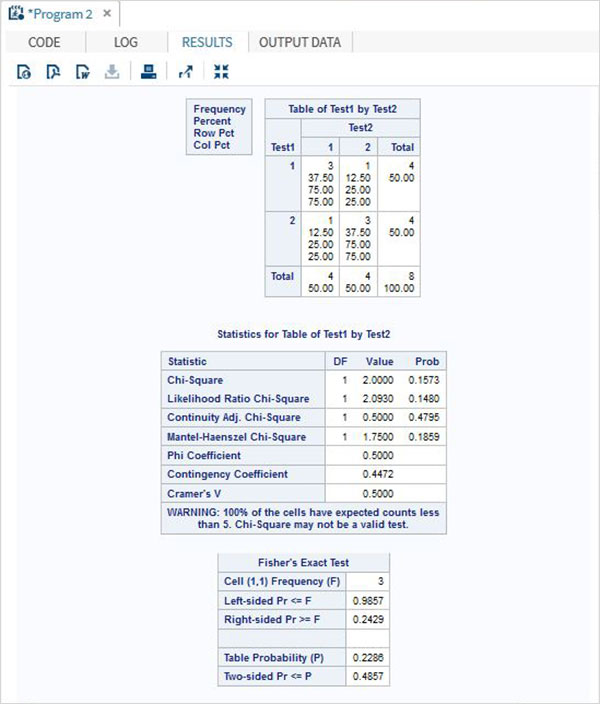
Analiza powtarzanych pomiarów jest stosowana, gdy wszyscy członkowie losowej próby są mierzeni w wielu różnych warunkach. Ponieważ próbka jest poddawana kolejno każdemu warunkowi, pomiar zmiennej zależnej jest powtarzany. Użycie standardowej ANOVA w tym przypadku nie jest właściwe, ponieważ nie umożliwia modelowania korelacji między powtarzanymi pomiarami.
Należy jasno określić różnicę między a repeated measures design i a simple multivariate design. W obu przypadkach elementy próbki są mierzone przy kilku okazjach lub próbach, ale w projekcie pomiarów powtarzanych każda próba reprezentuje pomiar tej samej charakterystyki w innych warunkach.
W SAS PROC GLM służy do przeprowadzania analizy powtarzanych pomiarów.
Składnia
Podstawowa składnia PROC GLM w SAS to -
PROC GLM DATA = dataset;
CLASS variable;
MODEL variables = group / NOUNI;
REPEATED TRIAL n;Poniżej znajduje się opis użytych parametrów -
dataset to nazwa zbioru danych.
CLASS nadaje zmiennym zmienną używaną jako zmienna klasyfikacyjna.
MODEL definiuje model do dopasowania przy użyciu pewnych zmiennych ze zbioru danych.
REPEATED określa liczbę powtarzanych pomiarów w każdej grupie w celu przetestowania hipotezy.
Przykład
Rozważ poniższy przykład, w którym mamy dwie grupy osób poddanych testowi działania leku. Rejestrowano czas reakcji każdej osoby dla każdego z czterech badanych typów leków. Tutaj 5 prób jest przeprowadzanych dla każdej grupy ludzi, aby zobaczyć siłę korelacji między efektami czterech typów narkotyków.
DATA temp;
INPUT person group $ r1 r2 r3 r4;
CARDS;
1 A 2 1 6 5
2 A 5 4 11 9
3 A 6 14 12 10
4 A 2 4 5 8
5 A 0 5 10 9
6 B 9 11 16 13
7 B 12 4 13 14
8 B 15 9 13 8
9 B 6 8 12 5
10 B 5 7 11 9
;
RUN;
PROC PRINT DATA = temp ;
RUN;
PROC GLM DATA = temp;
CLASS group;
MODEL r1-r4 = group / NOUNI ;
REPEATED trial 5;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -
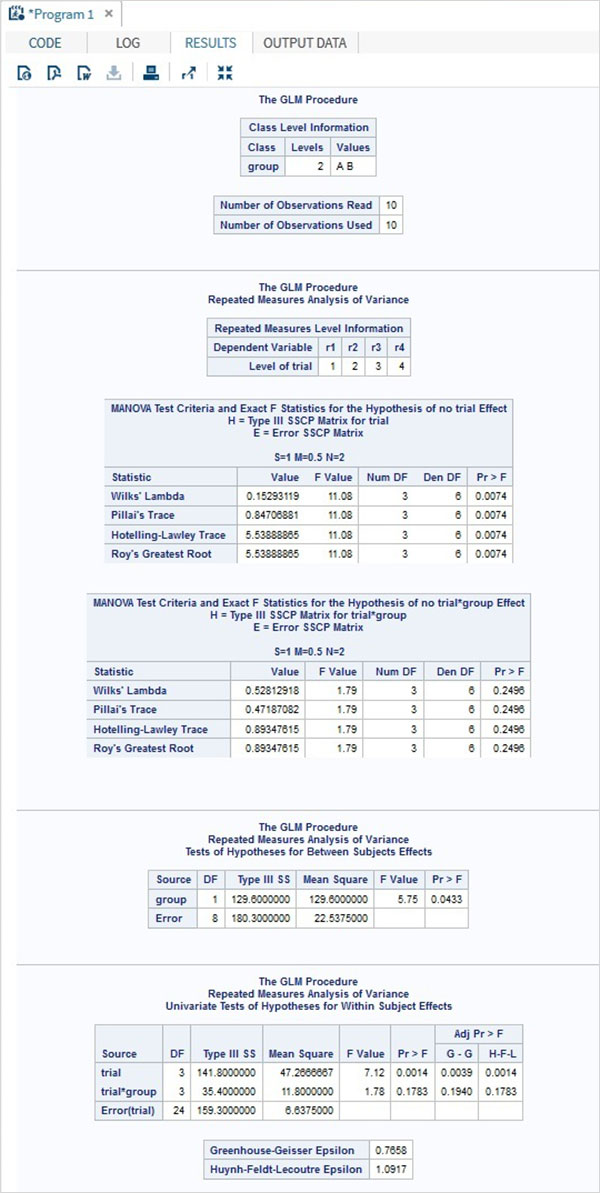
ANOVA oznacza analizę wariancji. W SAS robi się to za pomocąPROC ANOVA. Wykonuje analizę danych z szerokiej gamy projektów eksperymentalnych. W tym procesie ciągła zmienna odpowiedzi, znana jako zmienna zależna, jest mierzona w warunkach eksperymentalnych określonych przez zmienne klasyfikacyjne, zwane zmiennymi niezależnymi. Zakłada się, że zmienność odpowiedzi wynika z efektów w klasyfikacji, przy czym za pozostałą zmienność odpowiada przypadkowy błąd.
Składnia
Podstawowa składnia stosowania PROC ANOVA w SAS to -
PROC ANOVA dataset ;
CLASS Variable;
MODEL Variable1 = variable2 ;
MEANS ;Poniżej znajduje się opis użytych parametrów -
dataset to nazwa zbioru danych.
CLASS nadaje zmiennym zmienną używaną jako zmienna klasyfikacyjna.
MODEL definiuje model do dopasowania przy użyciu określonych zmiennych ze zbioru danych.
Variable_1 and Variable_2 to nazwy zmiennych zbioru danych używanego w analizie.
MEANS definiuje rodzaj obliczeń i porównania średnich.
Stosowanie ANOVA
Rozumiemy teraz koncepcję zastosowania ANOVA w SAS.
Przykład
Rozważmy zbiór danych SASHELP.CARS. Tutaj badamy zależność między zmiennymi typu samochodu a ich mocą. Ponieważ typ samochodu jest zmienną z wartościami kategorialnymi, traktujemy ją jako zmienną klasy i używamy obu tych zmiennych w MODELU.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -

Stosowanie ANOVA ze ŚREDNIMI
Rozumiemy teraz koncepcję stosowania ANOVA z MEANS w SAS.
Przykład
Możemy również rozszerzyć model, stosując stwierdzenie ŚRODKI, w którym do porównania średnich wartości różnych typów samochodów używamy metody steryzowanej Turcji. błąd średnia kwadratowa itp.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
MEANS type / tukey lines;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujący wynik -

Testowanie hipotez polega na wykorzystaniu statystyki do określenia prawdopodobieństwa, że dana hipoteza jest prawdziwa. Zwykły proces testowania hipotez składa się z czterech kroków, jak pokazano poniżej.
Krok 1
Sformułuj hipotezę zerową H0 (zwykle, że obserwacje są wynikiem czystego przypadku) i hipotezę alternatywną H1 (zwykle obserwacje pokazują rzeczywisty efekt połączony ze składową przypadkowej zmienności).
Krok 2
Zidentyfikuj statystykę testową, której można użyć do oceny prawdziwości hipotezy zerowej.
Krok 3
Oblicz wartość P, która jest prawdopodobieństwem, że statystyka testowa co najmniej tak istotna jak ta zaobserwowana została uzyskana przy założeniu, że hipoteza zerowa byłaby prawdziwa. Im mniejsza wartość P, tym silniejszy dowód przeciwko hipotezie zerowej.
Krok 4
Porównaj wartość p z akceptowalną wartością istotności alfa (czasami nazywaną wartością alfa). Jeśli p <= alfa, to obserwowany efekt jest statystycznie istotny, hipoteza zerowa jest wykluczona, a hipoteza alternatywna jest ważna.
Język programowania SAS ma funkcje umożliwiające przeprowadzanie różnego rodzaju testów hipotez, jak pokazano poniżej.
| Test | Opis | SAS PROC |
|---|---|---|
| T-Test | Test t-Studenta służy do testowania, czy średnia jednej zmiennej istotnie różni się od wartości hipotetycznej, a także określa, czy średnie dla dwóch niezależnych grup są znacząco różne oraz czy średnie dla grup zależnych lub par są znacząco różne. | PROC TTEST |
| ANOVA | Służy również do porównywania średnich, gdy istnieje jedna niezależna zmienna kategorialna. Chcemy użyć jednokierunkowej ANOVA podczas testowania, aby sprawdzić, czy średnie zmiennej zależnej od przedziału są różne w zależności od niezależnej zmiennej kategorialnej. | PROC ANOVA |
| Chi-Square | Używamy dobroci dopasowania chi-kwadrat, aby ocenić, czy częstości zmiennej kategorialnej mogą wystąpić przypadkowo. Zastosowanie testu chi-kwadrat jest konieczne, aby sprawdzić, czy proporcje zmiennej kategorialnej są wartością hipotetyczną. | PROC FREQ |
| Linear Regression | Prosta regresja liniowa jest używana, gdy chce się sprawdzić, jak dobrze zmienna przewiduje inną zmienną. Wielokrotna regresja liniowa pozwala sprawdzić, jak dobrze wiele zmiennych przewiduje zmienną będącą przedmiotem zainteresowania. Korzystając z wielokrotnej regresji liniowej, dodatkowo zakładamy, że zmienne predykcyjne są niezależne. | PROC REG |