SAS - odczyt surowych danych
SAS może czytać dane z różnych źródeł, które obejmują wiele formatów plików. Formaty plików używane w środowisku SAS zostały omówione poniżej.
- Zestaw danych ASCII (tekst)
- Dane rozdzielane
- Dane programu Excel
- Dane hierarchiczne
Czytanie zestawu danych ASCII (tekst)
Są to pliki zawierające dane w formacie tekstowym. Dane są zwykle oddzielane spacjami, ale mogą istnieć różne typy ograniczników, które mogą być obsługiwane przez SAS. Rozważmy plik ASCII zawierający dane pracowników. Czytamy ten plik przy użyciu rozszerzeniaInfile wyciąg dostępny w SAS.
Przykład
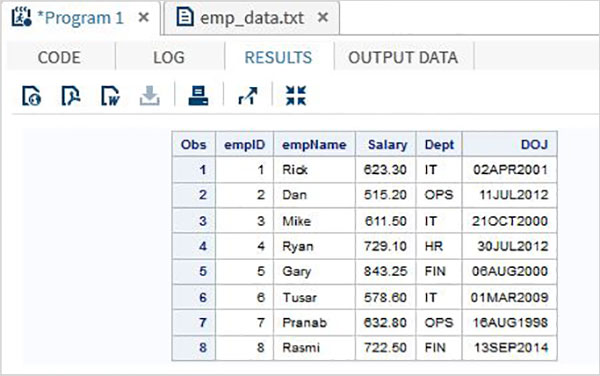
W poniższym przykładzie czytamy plik danych o nazwie emp_data.txt ze środowiska lokalnego.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Czytanie danych rozdzielonych
Są to pliki danych, w których wartości kolumn są oddzielone znakiem ograniczającym, takim jak przecinek lub potok itp. W tym przypadku używamy dlm opcja w infile komunikat.
Przykład
W poniższym przykładzie czytamy plik danych o nazwie emp.csv ze środowiska lokalnego.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
Czytanie danych programu Excel
SAS może bezpośrednio odczytać plik Excel za pomocą funkcji importu. Jak widać w rozdziale Zestawy danych SAS, może obsługiwać szeroką gamę typów plików, w tym MS Excel. Zakładając, że plik emp.xls jest dostępny lokalnie w środowisku SAS.
Przykład
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;Powyższy kod odczytuje dane z pliku Excela i daje takie same dane wyjściowe jak powyższe dwa typy plików.
Czytanie plików hierarchicznych
W tych plikach dane są obecne w formacie hierarchicznym. Dla danej obserwacji istnieje rekord nagłówka, pod którym wymieniono wiele rekordów szczegółowych. Liczba rekordów szczegółowych może się różnić w zależności od obserwacji. Poniżej znajduje się ilustracja hierarchicznego pliku.
W poniższym pliku wymienione są dane każdego pracownika w każdym dziale. Pierwszy rekord to nagłówek zawierający informacje o dziale, a następny rekord to kilka rekordów zaczynających się od DTLS.
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452Przykład
Aby odczytać plik hierarchiczny, używamy poniższego kodu, w którym identyfikujemy rekord nagłówka za pomocą klauzuli IF i używamy pętli do do przetwarzania rekordu szczegółów.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @;
if Type = 'DEP' then
input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;Po wykonaniu powyższego kodu otrzymujemy następujące dane wyjściowe.
