Spring Boot - usługa wsadowa
Możesz utworzyć wykonywalny plik JAR i uruchomić aplikację Spring Boot za pomocą poleceń Maven lub Gradle, jak pokazano poniżej -
W przypadku Mavena możesz użyć polecenia podanego poniżej -
mvn clean installPo „BUILD SUCCESS” można znaleźć plik JAR w katalogu docelowym.
W przypadku Gradle możesz użyć polecenia, jak pokazano -
gradle clean buildPo komunikacie „BUILD SUCCESSFUL” można znaleźć plik JAR w katalogu build / libs.
Uruchom plik JAR, używając polecenia podanego tutaj -
java –jar <JARFILE>Teraz aplikacja została uruchomiona na porcie Tomcat 8080, jak pokazano.

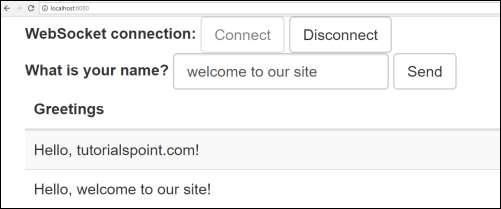
Teraz kliknij adres URL http://localhost:8080/ w przeglądarce internetowej i podłącz do gniazda sieciowego, wyślij pozdrowienie i odbierz wiadomość.
Usługa wsadowa to proces wykonywania więcej niż jednego polecenia w jednym zadaniu. W tym rozdziale dowiesz się, jak utworzyć usługę wsadową w aplikacji Spring Boot.
Rozważmy przykład, w którym zamierzamy zapisać zawartość pliku CSV w HSQLDB.
Aby utworzyć program Batch Service, musimy dodać zależność Spring Boot Starter Batch i HSQLDB do naszego pliku konfiguracji kompilacji.
Użytkownicy Mavena mogą dodać następujące zależności w pliku pom.xml.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
</dependency>Użytkownicy Gradle mogą dodawać następujące zależności w pliku build.gradle.
compile("org.springframework.boot:spring-boot-starter-batch")
compile("org.hsqldb:hsqldb")Teraz dodaj prosty plik danych CSV w zasobach ścieżki klas - src / main / resources i nazwij plik jako file.csv, jak pokazano -
William,John
Mike, Sebastian
Lawarance, LimeNastępnie napisz skrypt SQL dla HSQLDB - w katalogu zasobów ścieżki klas - request_fail_hystrix_timeout
DROP TABLE USERS IF EXISTS;
CREATE TABLE USERS (
user_id BIGINT IDENTITY NOT NULL PRIMARY KEY,
first_name VARCHAR(20),
last_name VARCHAR(20)
);Utwórz klasę POJO dla modelu USERS, jak pokazano -
package com.tutorialspoint.batchservicedemo;
public class User {
private String lastName;
private String firstName;
public User() {
}
public User(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@Override
public String toString() {
return "firstName: " + firstName + ", lastName: " + lastName;
}
}Teraz utwórz pośredni procesor do wykonywania operacji po odczytaniu danych z pliku CSV, a przed zapisaniem danych do SQL.
package com.tutorialspoint.batchservicedemo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
public class UserItemProcessor implements ItemProcessor<User, User> {
private static final Logger log = LoggerFactory.getLogger(UserItemProcessor.class);
@Override
public User process(final User user) throws Exception {
final String firstName = user.getFirstName().toUpperCase();
final String lastName = user.getLastName().toUpperCase();
final User transformedPerson = new User(firstName, lastName);
log.info("Converting (" + user + ") into (" + transformedPerson + ")");
return transformedPerson;
}
}Utwórzmy plik konfiguracyjny wsadowy, aby odczytać dane z CSV i zapisać do pliku SQL, jak pokazano poniżej. Musimy dodać adnotację @EnableBatchProcessing w pliku klasy konfiguracyjnej. Adnotacja @EnableBatchProcessing służy do włączania operacji wsadowych dla aplikacji Spring Boot.
package com.tutorialspoint.batchservicedemo;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Autowired
public DataSource dataSource;
@Bean
public FlatFileItemReader<User> reader() {
FlatFileItemReader<User> reader = new FlatFileItemReader<User>();
reader.setResource(new ClassPathResource("file.csv"));
reader.setLineMapper(new DefaultLineMapper<User>() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "firstName", "lastName" });
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<User>() {
{
setTargetType(User.class);
}
});
}
});
return reader;
}
@Bean
public UserItemProcessor processor() {
return new UserItemProcessor();
}
@Bean
public JdbcBatchItemWriter<User> writer() {
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter<User>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<User>());
writer.setSql("INSERT INTO USERS (first_name, last_name) VALUES (:firstName, :lastName)");
writer.setDataSource(dataSource);
return writer;
}
@Bean
public Job importUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory.get("importUserJob").incrementer(
new RunIdIncrementer()).listener(listener).flow(step1()).end().build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1").<User, User>chunk(10).reader(reader()).processor(processor()).writer(writer()).build();
}
}Plik reader() Metoda służy do odczytu danych z pliku CSV, a metoda writer () służy do zapisywania danych w SQL.
Następnie będziemy musieli napisać klasę odbiornika powiadomienia o zakończeniu pracy - używaną do powiadamiania po zakończeniu zadania.
package com.tutorialspoint.batchservicedemo;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Component;
@Component
public class JobCompletionNotificationListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED !! It's time to verify the results!!");
List<User> results = jdbcTemplate.query(
"SELECT first_name, last_name FROM USERS", new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int row) throws SQLException {
return new User(rs.getString(1), rs.getString(2));
}
});
for (User person : results) {
log.info("Found <" + person + "> in the database.");
}
}
}
}Teraz utwórz wykonywalny plik JAR i uruchom aplikację Spring Boot za pomocą następujących poleceń Maven lub Gradle.
W przypadku Mavena użyj polecenia, jak pokazano -
mvn clean installPo „BUILD SUCCESS” można znaleźć plik JAR w katalogu docelowym.
W przypadku Gradle możesz użyć polecenia, jak pokazano -
gradle clean buildPo komunikacie „BUILD SUCCESSFUL” można znaleźć plik JAR w katalogu build / libs.
Uruchom plik JAR, używając polecenia podanego tutaj -
java –jar <JARFILE>Możesz zobaczyć dane wyjściowe w oknie konsoli, jak pokazano -
