Aprendizado de máquina - categorias
O aprendizado de máquina é amplamente categorizado sob os seguintes títulos -
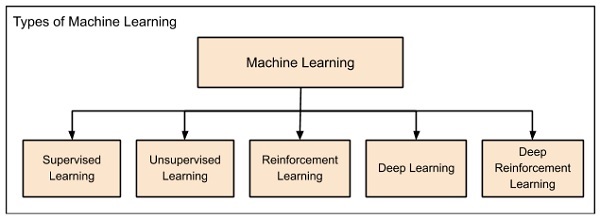
O aprendizado de máquina evoluiu da esquerda para a direita, conforme mostrado no diagrama acima.
Inicialmente, os pesquisadores começaram com a Aprendizagem Supervisionada. Este é o caso da previsão do preço da habitação discutida anteriormente.
Isso foi seguido por um aprendizado não supervisionado, em que a máquina é feita para aprender por conta própria, sem qualquer supervisão.
Os cientistas descobriram ainda que pode ser uma boa ideia recompensar a máquina quando ela faz o trabalho da maneira esperada e surgiu o Aprendizado por Reforço.
Muito em breve, os dados disponíveis hoje em dia se tornaram tão gigantescos que as técnicas convencionais desenvolvidas até agora falharam em analisar o big data e nos fornecer as previsões.
Assim, surgiu o aprendizado profundo onde o cérebro humano é simulado nas Redes Neurais Artificiais (RNA) criadas em nossos computadores binários.
A máquina agora aprende por conta própria, usando o alto poder de computação e os enormes recursos de memória disponíveis hoje.
Agora é observado que o Deep Learning resolveu muitos dos problemas anteriormente insolúveis.
A técnica agora é mais avançada, dando incentivos às redes de Deep Learning como prêmios e, finalmente, vem o Deep Reinforcement Learning.
Vamos agora estudar cada uma dessas categorias com mais detalhes.
Aprendizagem Supervisionada
A aprendizagem supervisionada é análoga a treinar uma criança para andar. Você vai segurar a mão da criança, mostrar-lhe como levar o pé para a frente, andar para uma demonstração e assim por diante, até que a criança aprenda a andar sozinha.
Regressão
Da mesma forma, no caso da aprendizagem supervisionada, você dá exemplos concretos conhecidos ao computador. Você diz que, para determinado valor de característica x1, a saída é y1, para x2 é y2, para x3 é y3 e assim por diante. Com base nesses dados, você permite que o computador descubra uma relação empírica entre x e y.
Uma vez que a máquina é treinada desta forma com um número suficiente de pontos de dados, agora você pediria à máquina para prever Y para um determinado X. Supondo que você saiba o valor real de Y para este X dado, você será capaz de deduzir se a previsão da máquina está correta.
Assim, você testará se a máquina aprendeu usando os dados de teste conhecidos. Quando estiver satisfeito com o fato de que a máquina é capaz de fazer as previsões com um nível desejado de precisão (digamos de 80 a 90%), você pode interromper o treinamento adicional da máquina.
Agora, você pode usar a máquina com segurança para fazer as previsões em pontos de dados desconhecidos ou pedir à máquina para prever Y para um determinado X para o qual você não sabe o valor real de Y. Este treinamento vem sob a regressão de que falamos mais cedo.
Classificação
Você também pode usar técnicas de aprendizado de máquina para problemas de classificação. Em problemas de classificação, você classifica objetos de natureza semelhante em um único grupo. Por exemplo, em um conjunto de 100 alunos, digamos, você pode querer agrupá-los em três grupos com base em suas alturas - curto, médio e longo. Medindo a altura de cada aluno, você os colocará em um grupo adequado.
Agora, quando um novo aluno chegar, você o colocará em um grupo apropriado medindo sua altura. Seguindo os princípios do treinamento de regressão, você treinará a máquina para classificar um aluno com base em sua característica - a altura. Quando a máquina aprender como os grupos são formados, ela será capaz de classificar qualquer aluno novo desconhecido corretamente. Mais uma vez, você usaria os dados de teste para verificar se a máquina aprendeu sua técnica de classificação antes de colocar o modelo desenvolvido em produção.
A Aprendizagem Supervisionada é onde a IA realmente começou sua jornada. Esta técnica foi aplicada com sucesso em vários casos. Você usou este modelo ao fazer o reconhecimento de escrita à mão em sua máquina. Vários algoritmos foram desenvolvidos para aprendizagem supervisionada. Você aprenderá sobre eles nos próximos capítulos.
Aprendizagem Não Supervisionada
Na aprendizagem não supervisionada, não especificamos uma variável de destino para a máquina, em vez disso, perguntamos à máquina “O que você pode me dizer sobre X?”. Mais especificamente, podemos fazer perguntas como, dado um enorme conjunto de dados X, "Quais são os cinco melhores grupos que podemos fazer de X?" ou “Quais recursos ocorrem juntos com mais frequência no X?”. Para chegar às respostas a essas perguntas, você pode entender que o número de pontos de dados que a máquina exigiria para deduzir uma estratégia seria muito grande. No caso de aprendizado supervisionado, a máquina pode ser treinada até mesmo com alguns milhares de pontos de dados. No entanto, no caso de aprendizagem não supervisionada, o número de pontos de dados que são razoavelmente aceitos para aprendizagem começa em alguns milhões. Atualmente, os dados geralmente estão disponíveis em abundância. Idealmente, os dados requerem curadoria. No entanto, a quantidade de dados que flui continuamente em uma rede de área social, na maioria dos casos, a curadoria de dados é uma tarefa impossível.
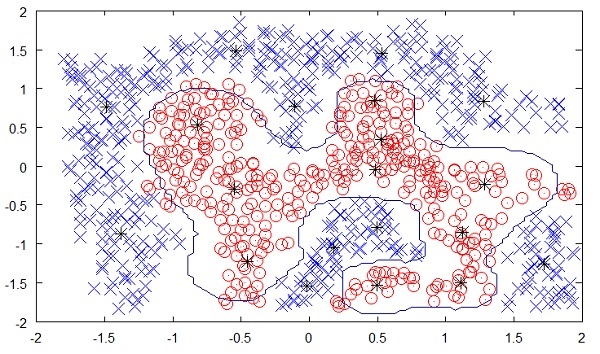
A figura a seguir mostra o limite entre os pontos amarelos e vermelhos, conforme determinado pelo aprendizado de máquina não supervisionado. Você pode ver claramente que a máquina seria capaz de determinar a classe de cada um dos pontos pretos com uma precisão bastante boa.
Fonte:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
O aprendizado não supervisionado mostrou um grande sucesso em muitas aplicações modernas de IA, como detecção de rosto, detecção de objeto e assim por diante.
Aprendizagem por Reforço
Considere treinar um cachorro de estimação, nós treinamos nosso animal de estimação para trazer uma bola para nós. Jogamos a bola a uma certa distância e pedimos ao cachorro que a traga de volta para nós. Cada vez que o cão faz isso direito, nós o recompensamos. Lentamente, o cão aprende que fazer o trabalho da maneira certa lhe dá uma recompensa e então começa a fazer o trabalho da maneira certa sempre no futuro. Exatamente, este conceito é aplicado no tipo de aprendizagem “Reforço”. A técnica foi desenvolvida inicialmente para as máquinas jogarem. A máquina recebe um algoritmo para analisar todos os movimentos possíveis em cada fase do jogo. A máquina pode selecionar um dos movimentos aleatoriamente. Se a jogada for correta, a máquina é recompensada, caso contrário, pode ser penalizada. Lentamente, a máquina começará a diferenciar entre os movimentos certos e errados e, após várias iterações, aprenderá a resolver o quebra-cabeça do jogo com uma precisão melhor. A precisão de ganhar o jogo melhoraria à medida que a máquina jogasse mais e mais jogos.
Todo o processo pode ser descrito no diagrama a seguir -
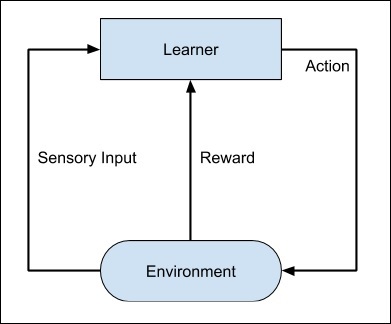
Essa técnica de aprendizado de máquina difere do aprendizado supervisionado porque você não precisa fornecer os pares de entrada / saída rotulados. O foco está em encontrar o equilíbrio entre explorar as novas soluções e explorar as soluções aprendidas.
Aprendizado Profundo
O aprendizado profundo é um modelo baseado em Redes Neurais Artificiais (RNA), mais especificamente Redes Neurais Convolucionais (CNN) s. Existem várias arquiteturas usadas no aprendizado profundo, como redes neurais profundas, redes de crenças profundas, redes neurais recorrentes e redes neurais convolucionais.
Essas redes têm sido aplicadas com sucesso na solução de problemas de visão computacional, reconhecimento de fala, processamento de linguagem natural, bioinformática, design de medicamentos, análise de imagens médicas e jogos. Existem vários outros campos nos quais o aprendizado profundo é aplicado de forma proativa. O aprendizado profundo requer grande poder de processamento e dados enormes, que geralmente estão facilmente disponíveis hoje em dia.
Falaremos sobre aprendizado profundo com mais detalhes nos próximos capítulos.
Aprendizagem por Reforço Profundo
O Deep Reinforcement Learning (DRL) combina as técnicas de aprendizado profundo e de reforço. Os algoritmos de aprendizagem por reforço, como Q-learning, agora são combinados com aprendizagem profunda para criar um modelo DRL poderoso. A técnica tem obtido grande sucesso nas áreas de robótica, videogames, finanças e saúde. Muitos problemas anteriormente insolúveis agora são resolvidos com a criação de modelos DRL. Há muitas pesquisas em andamento nessa área, que são ativamente realizadas pelas indústrias.
Até agora, você teve uma breve introdução a vários modelos de aprendizado de máquina, agora vamos explorar um pouco mais a fundo os vários algoritmos disponíveis nesses modelos.