Aprendizado de máquina - Guia rápido
A Inteligência Artificial (IA) de hoje ultrapassou em muito o hype do blockchain e da computação quântica. Isso se deve ao fato de que enormes recursos de computação estão facilmente disponíveis para o homem comum. Os desenvolvedores agora tiram vantagem disso na criação de novos modelos de aprendizado de máquina e para treinar novamente os modelos existentes para obter melhor desempenho e resultados. A fácil disponibilidade de High Performance Computing (HPC) resultou em um aumento repentino da demanda por profissionais de TI com habilidades de aprendizado de máquina.
Neste tutorial, você aprenderá em detalhes sobre -
Qual é o ponto crucial do aprendizado de máquina?
Quais são os diferentes tipos de aprendizado de máquina?
Quais são os diferentes algoritmos disponíveis para desenvolver modelos de aprendizado de máquina?
Quais ferramentas estão disponíveis para desenvolver esses modelos?
Quais são as opções de linguagem de programação?
Quais plataformas oferecem suporte ao desenvolvimento e implantação de aplicativos de aprendizado de máquina?
Quais IDEs (Integrated Development Environment) estão disponíveis?
Como atualizar rapidamente suas habilidades nesta área importante?
Quando você marca um rosto em uma foto do Facebook, é a IA que está rodando nos bastidores e identificando os rostos em uma imagem. A marcação de rosto agora é onipresente em vários aplicativos que exibem fotos com rostos humanos. Por que apenas rostos humanos? São vários aplicativos que detectam objetos como gatos, cachorros, garrafas, carros, etc. Temos carros autônomos circulando em nossas estradas que detectam objetos em tempo real para dirigir o carro. Quando você viaja, você usa o GoogleDirectionspara conhecer as situações de trânsito em tempo real e seguir o melhor caminho sugerido pelo Google naquele momento. Esta é mais uma implementação da técnica de detecção de objetos em tempo real.
Vamos considerar o exemplo do Google Translateaplicativo que normalmente usamos ao visitar países estrangeiros. O aplicativo tradutor online do Google no seu celular ajuda você a se comunicar com as pessoas locais que falam um idioma que você não conhece.
Existem várias aplicações de IA que usamos praticamente hoje. Na verdade, cada um de nós usa IA em muitas partes de nossas vidas, mesmo sem nosso conhecimento. A IA de hoje pode realizar trabalhos extremamente complexos com grande precisão e velocidade. Vamos discutir um exemplo de tarefa complexa para entender quais recursos são esperados em um aplicativo de IA que você estaria desenvolvendo hoje para seus clientes.
Exemplo
Todos nós usamos o Google Directionsdurante nossa viagem em qualquer lugar da cidade para um trajeto diário ou mesmo para viagens intermunicipais. O aplicativo Google Directions sugere o caminho mais rápido para o nosso destino naquela instância de tempo. Ao seguirmos esse caminho, observamos que o Google acertou quase 100% em suas sugestões e economizamos nosso valioso tempo na viagem.
Você pode imaginar a complexidade envolvida no desenvolvimento desse tipo de aplicativo, considerando que existem vários caminhos para o seu destino e o aplicativo deve avaliar a situação do tráfego em cada caminho possível para fornecer uma estimativa de tempo de viagem para cada um deles. Além disso, considere o fato de que o Google Directions cobre todo o globo. Sem dúvida, muitas técnicas de IA e de aprendizado de máquina estão em uso sob o capô de tais aplicativos.
Considerando a demanda contínua para o desenvolvimento de tais aplicativos, agora você vai entender porque há uma demanda repentina por profissionais de TI com habilidades de IA.
Em nosso próximo capítulo, aprenderemos o que é necessário para desenvolver programas de IA.
A jornada da IA começou na década de 1950, quando o poder da computação era uma fração do que é hoje. AI começou com as previsões feitas pela máquina da mesma forma que um estatístico faz previsões usando sua calculadora. Assim, todo o desenvolvimento inicial da IA foi baseado principalmente em técnicas estatísticas.
Neste capítulo, vamos discutir em detalhes o que são essas técnicas estatísticas.
Técnicas Estatísticas
O desenvolvimento dos aplicativos de IA de hoje começou com o uso de técnicas estatísticas tradicionais antiquíssimas. Você deve ter usado a interpolação em linha reta nas escolas para prever um valor futuro. Existem várias outras técnicas estatísticas que são aplicadas com sucesso no desenvolvimento dos chamados programas de IA. Dizemos “assim chamados” porque os programas de IA que temos hoje são muito mais complexos e usam técnicas muito além das técnicas estatísticas usadas pelos primeiros programas de IA.
Alguns dos exemplos de técnicas estatísticas que são usadas para desenvolver aplicativos de IA naquela época e ainda estão em prática estão listados aqui -
- Regression
- Classification
- Clustering
- Teorias de Probabilidade
- Árvores de decisão
Listamos aqui apenas algumas técnicas primárias que são suficientes para você começar na IA sem assustá-lo com a vastidão que a IA exige. Se você estiver desenvolvendo aplicativos de IA com base em dados limitados, estará usando essas técnicas estatísticas.
No entanto, hoje os dados são abundantes. Para analisar o tipo de dados enormes que possuímos, técnicas estatísticas não ajudam muito, pois têm algumas limitações próprias. Métodos mais avançados, como aprendizado profundo, são desenvolvidos para resolver muitos problemas complexos.
À medida que avançamos neste tutorial, entenderemos o que é Aprendizado de Máquina e como ele é usado para desenvolver tais aplicativos complexos de IA.
Considere a figura a seguir, que mostra um gráfico dos preços das casas versus seu tamanho em pés quadrados.

Depois de traçar vários pontos de dados no gráfico XY, desenhamos uma linha de melhor ajuste para fazer nossas previsões para qualquer outra casa, dado seu tamanho. Você alimentará a máquina com os dados conhecidos e solicitará que ela encontre a linha de melhor ajuste. Assim que a linha de melhor ajuste for encontrada pela máquina, você testará sua adequação alimentando um galpão de tamanho conhecido, ou seja, o valor Y na curva acima. A máquina agora retornará o valor X estimado, ou seja, o preço esperado da casa. O diagrama pode ser extrapolado para descobrir o preço de uma casa de 3000 pés quadrados ou até maior. Isso é chamado de regressão nas estatísticas. Particularmente, esse tipo de regressão é chamado de regressão linear, pois a relação entre os pontos de dados X e Y é linear.
Em muitos casos, a relação entre os pontos de dados X e Y pode não ser uma linha reta e pode ser uma curva com uma equação complexa. Sua tarefa agora seria descobrir a melhor curva de ajuste que pode ser extrapolada para prever os valores futuros. Um tal gráfico de aplicação é mostrado na figura abaixo.
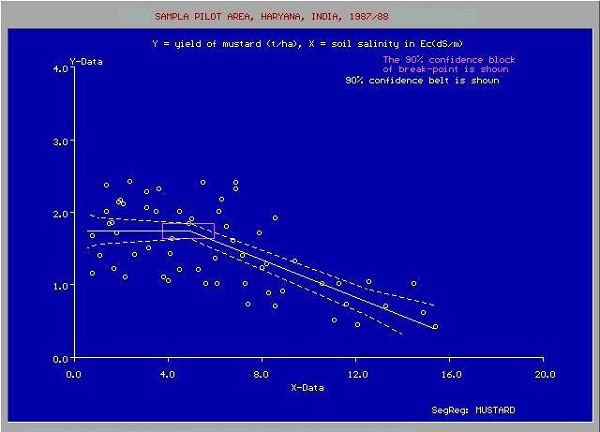
Fonte:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
Você usará as técnicas de otimização estatística para descobrir a equação para a curva de melhor ajuste aqui. E é exatamente disso que se trata o Aprendizado de Máquina. Você usa técnicas de otimização conhecidas para encontrar a melhor solução para seu problema.
A seguir, vamos examinar as diferentes categorias de aprendizado de máquina.
O aprendizado de máquina é amplamente categorizado sob os seguintes títulos -
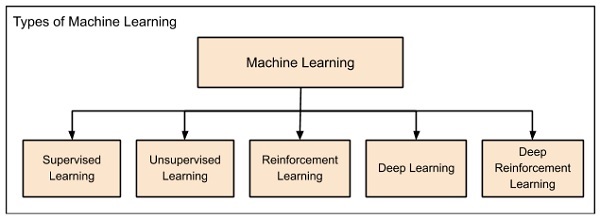
O aprendizado de máquina evoluiu da esquerda para a direita, conforme mostrado no diagrama acima.
Inicialmente, os pesquisadores começaram com a Aprendizagem Supervisionada. Este é o caso da previsão do preço da habitação discutida anteriormente.
Isso foi seguido por um aprendizado não supervisionado, em que a máquina é feita para aprender por conta própria, sem qualquer supervisão.
Os cientistas descobriram ainda que pode ser uma boa ideia recompensar a máquina quando ela faz o trabalho da maneira esperada e surgiu o Aprendizado por Reforço.
Muito em breve, os dados disponíveis hoje em dia se tornaram tão gigantescos que as técnicas convencionais desenvolvidas até agora falharam em analisar o big data e nos fornecer as previsões.
Assim, surgiu o aprendizado profundo onde o cérebro humano é simulado nas Redes Neurais Artificiais (RNA) criadas em nossos computadores binários.
A máquina agora aprende por conta própria, usando o alto poder de computação e os enormes recursos de memória disponíveis hoje.
Agora é observado que o Deep Learning resolveu muitos dos problemas anteriormente insolúveis.
A técnica agora é mais avançada, dando incentivos às redes de Deep Learning como prêmios e, finalmente, vem o Deep Reinforcement Learning.
Vamos agora estudar cada uma dessas categorias com mais detalhes.
Aprendizagem Supervisionada
A aprendizagem supervisionada é análoga a treinar uma criança para andar. Você vai segurar a mão da criança, mostrar-lhe como levar o pé para a frente, andar para uma demonstração e assim por diante, até que a criança aprenda a andar sozinha.
Regressão
Da mesma forma, no caso da aprendizagem supervisionada, você dá exemplos concretos conhecidos ao computador. Você diz que, para determinado valor de característica x1, a saída é y1, para x2 é y2, para x3 é y3 e assim por diante. Com base nesses dados, você permite que o computador descubra uma relação empírica entre x e y.
Uma vez que a máquina é treinada desta forma com um número suficiente de pontos de dados, agora você pediria à máquina para prever Y para um determinado X. Supondo que você saiba o valor real de Y para este X dado, você será capaz de deduzir se a previsão da máquina está correta.
Assim, você testará se a máquina aprendeu usando os dados de teste conhecidos. Quando estiver satisfeito com o fato de que a máquina é capaz de fazer as previsões com um nível desejado de precisão (digamos de 80 a 90%), você pode interromper o treinamento adicional da máquina.
Agora, você pode usar a máquina com segurança para fazer as previsões em pontos de dados desconhecidos ou pedir à máquina para prever Y para um determinado X para o qual você não sabe o valor real de Y. Este treinamento vem sob a regressão de que falamos mais cedo.
Classificação
Você também pode usar técnicas de aprendizado de máquina para problemas de classificação. Em problemas de classificação, você classifica objetos de natureza semelhante em um único grupo. Por exemplo, em um conjunto de 100 alunos, digamos, você pode querer agrupá-los em três grupos com base em suas alturas - curto, médio e longo. Medindo a altura de cada aluno, você os colocará em um grupo adequado.
Agora, quando um novo aluno chegar, você o colocará em um grupo apropriado medindo sua altura. Seguindo os princípios do treinamento de regressão, você treinará a máquina para classificar um aluno com base em sua característica - a altura. Quando a máquina aprender como os grupos são formados, ela será capaz de classificar qualquer aluno novo desconhecido corretamente. Mais uma vez, você usaria os dados de teste para verificar se a máquina aprendeu sua técnica de classificação antes de colocar o modelo desenvolvido em produção.
A Aprendizagem Supervisionada é onde a IA realmente começou sua jornada. Esta técnica foi aplicada com sucesso em vários casos. Você usou este modelo ao fazer o reconhecimento de escrita à mão em sua máquina. Vários algoritmos foram desenvolvidos para aprendizagem supervisionada. Você aprenderá sobre eles nos próximos capítulos.
Aprendizagem Não Supervisionada
Na aprendizagem não supervisionada, não especificamos uma variável de destino para a máquina, em vez disso, perguntamos à máquina “O que você pode me dizer sobre X?”. Mais especificamente, podemos fazer perguntas como, dado um enorme conjunto de dados X, "Quais são os cinco melhores grupos que podemos fazer de X?" ou “Quais recursos ocorrem juntos com mais frequência no X?”. Para chegar às respostas a essas perguntas, você pode entender que o número de pontos de dados que a máquina exigiria para deduzir uma estratégia seria muito grande. No caso de aprendizado supervisionado, a máquina pode ser treinada até mesmo com alguns milhares de pontos de dados. No entanto, no caso de aprendizagem não supervisionada, o número de pontos de dados que são razoavelmente aceitos para aprendizagem começa em alguns milhões. Atualmente, os dados geralmente estão disponíveis em abundância. Idealmente, os dados requerem curadoria. No entanto, a quantidade de dados que flui continuamente em uma rede de área social, na maioria dos casos, a curadoria de dados é uma tarefa impossível.
A figura a seguir mostra o limite entre os pontos amarelos e vermelhos, conforme determinado pelo aprendizado de máquina não supervisionado. Você pode ver claramente que a máquina seria capaz de determinar a classe de cada um dos pontos pretos com uma precisão bastante boa.
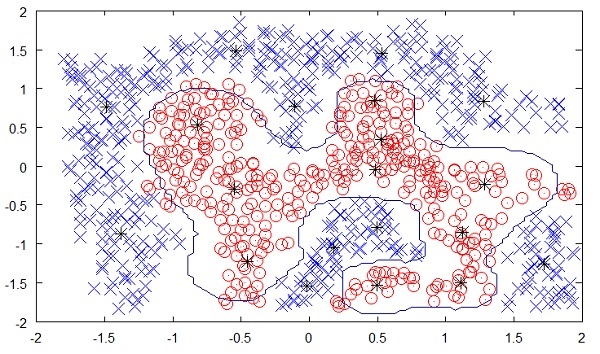
Fonte:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
O aprendizado não supervisionado mostrou um grande sucesso em muitas aplicações modernas de IA, como detecção de rosto, detecção de objeto e assim por diante.
Aprendizagem por Reforço
Considere treinar um cachorro de estimação, nós treinamos nosso animal de estimação para trazer uma bola para nós. Jogamos a bola a uma certa distância e pedimos ao cachorro que a traga de volta para nós. Cada vez que o cão faz isso direito, nós o recompensamos. Lentamente, o cão aprende que fazer o trabalho da maneira certa lhe dá uma recompensa e então começa a fazer o trabalho da maneira certa sempre no futuro. Exatamente, este conceito é aplicado no tipo de aprendizagem “Reforço”. A técnica foi desenvolvida inicialmente para as máquinas jogarem. A máquina recebe um algoritmo para analisar todos os movimentos possíveis em cada fase do jogo. A máquina pode selecionar um dos movimentos aleatoriamente. Se a jogada for correta, a máquina é recompensada, caso contrário, pode ser penalizada. Lentamente, a máquina começará a diferenciar entre os movimentos certos e errados e, após várias iterações, aprenderá a resolver o quebra-cabeça do jogo com uma precisão melhor. A precisão de ganhar o jogo melhoraria à medida que a máquina jogasse mais e mais jogos.
Todo o processo pode ser descrito no diagrama a seguir -
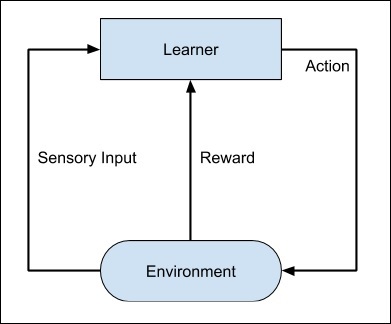
Essa técnica de aprendizado de máquina difere do aprendizado supervisionado porque você não precisa fornecer os pares de entrada / saída rotulados. O foco está em encontrar o equilíbrio entre explorar as novas soluções e explorar as soluções aprendidas.
Aprendizado Profundo
O aprendizado profundo é um modelo baseado em Redes Neurais Artificiais (RNA), mais especificamente Redes Neurais Convolucionais (CNN) s. Existem várias arquiteturas usadas no aprendizado profundo, como redes neurais profundas, redes de crenças profundas, redes neurais recorrentes e redes neurais convolucionais.
Essas redes têm sido aplicadas com sucesso na solução de problemas de visão computacional, reconhecimento de fala, processamento de linguagem natural, bioinformática, design de medicamentos, análise de imagens médicas e jogos. Existem vários outros campos nos quais o aprendizado profundo é aplicado de forma proativa. O aprendizado profundo requer grande poder de processamento e dados enormes, que geralmente estão facilmente disponíveis hoje em dia.
Falaremos sobre aprendizado profundo com mais detalhes nos próximos capítulos.
Aprendizagem por Reforço Profundo
O Deep Reinforcement Learning (DRL) combina as técnicas de aprendizado profundo e de reforço. Os algoritmos de aprendizagem por reforço, como Q-learning, agora são combinados com aprendizagem profunda para criar um modelo DRL poderoso. A técnica tem obtido grande sucesso nas áreas de robótica, videogames, finanças e saúde. Muitos problemas anteriormente insolúveis agora são resolvidos com a criação de modelos DRL. Há muitas pesquisas em andamento nessa área, que são ativamente realizadas pelas indústrias.
Até agora, você teve uma breve introdução a vários modelos de aprendizado de máquina, agora vamos explorar um pouco mais a fundo os vários algoritmos disponíveis nesses modelos.
A aprendizagem supervisionada é um dos modelos importantes de aprendizagem envolvidos em máquinas de treinamento. Este capítulo fala em detalhes sobre o mesmo.
Algoritmos para aprendizagem supervisionada
Existem vários algoritmos disponíveis para aprendizagem supervisionada. Alguns dos algoritmos amplamente usados de aprendizagem supervisionada são mostrados abaixo -
- k-vizinhos mais próximos
- Árvores de decisão
- Baías ingénuas
- Regressão Logística
- Máquinas de vetor de suporte
À medida que avançamos neste capítulo, vamos discutir em detalhes sobre cada um dos algoritmos.
k-vizinhos mais próximos
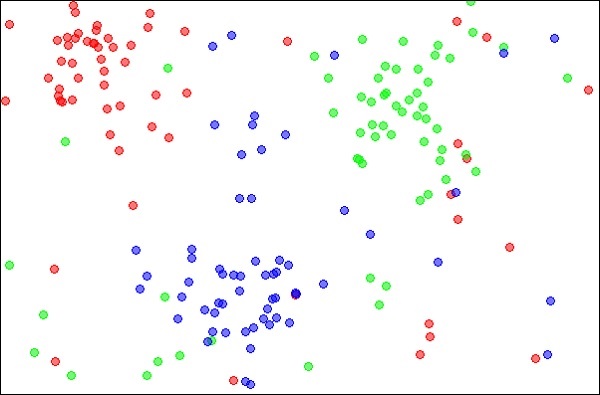
Os k-vizinhos mais próximos, simplesmente chamados de kNN, são uma técnica estatística que pode ser usada para resolver problemas de classificação e regressão. Vamos discutir o caso de classificação de um objeto desconhecido usando kNN. Considere a distribuição de objetos conforme mostrado na imagem abaixo -
Fonte:
https://en.wikipedia.org/wiki/K-nearest_neighbours_algorithm
O diagrama mostra três tipos de objetos, marcados nas cores vermelha, azul e verde. Quando você executa o classificador kNN no conjunto de dados acima, os limites para cada tipo de objeto serão marcados como mostrado abaixo -

Fonte:
https://en.wikipedia.org/wiki/K-nearest_neighbours_algorithm
Agora, considere um novo objeto desconhecido que você deseja classificar como vermelho, verde ou azul. Isso é ilustrado na figura abaixo.
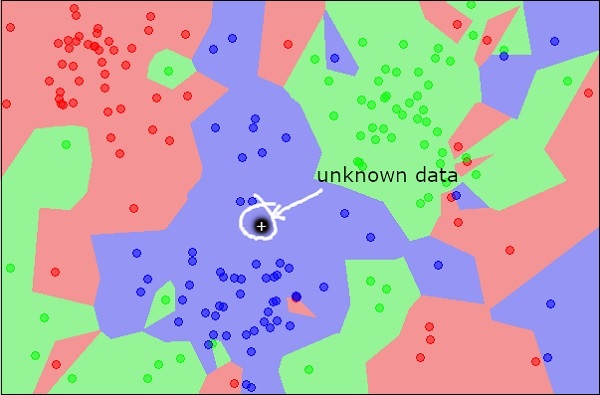
Como você vê visualmente, o ponto de dados desconhecido pertence a uma classe de objetos azuis. Matematicamente, isso pode ser concluído medindo a distância desse ponto desconhecido com todos os outros pontos do conjunto de dados. Ao fazer isso, você saberá que a maioria de seus vizinhos são azuis. A distância média para objetos vermelhos e verdes seria definitivamente mais do que a distância média para objetos azuis. Assim, este objeto desconhecido pode ser classificado como pertencente à classe azul.
O algoritmo kNN também pode ser usado para problemas de regressão. O algoritmo kNN está disponível como pronto para uso na maioria das bibliotecas de ML.
Árvores de decisão
Uma árvore de decisão simples em formato de fluxograma é mostrada abaixo -
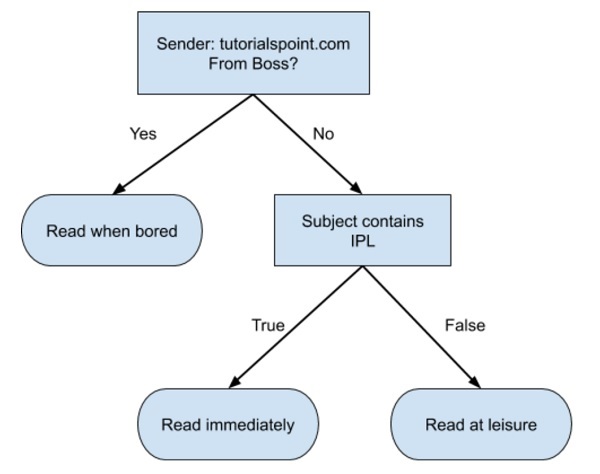
Você escreveria um código para classificar seus dados de entrada com base neste fluxograma. O fluxograma é autoexplicativo e trivial. Nesse cenário, você está tentando classificar um e-mail recebido para decidir quando lê-lo.
Na realidade, as árvores de decisão podem ser grandes e complexas. Existem vários algoritmos disponíveis para criar e percorrer essas árvores. Como um entusiasta do Machine Learning, você precisa entender e dominar essas técnicas de criação e análise de árvores de decisão.
Baías ingénuas
Naive Bayes é usado para criar classificadores. Suponha que você queira separar (classificar) frutas de diferentes tipos de uma cesta de frutas. Você pode usar recursos como cor, tamanho e formato de uma fruta, por exemplo, qualquer fruta de cor vermelha, forma redonda e cerca de 10 cm de diâmetro pode ser considerada maçã. Portanto, para treinar o modelo, você usaria esses recursos e testaria a probabilidade de um determinado recurso corresponder às restrições desejadas. As probabilidades de diferentes características são então combinadas para chegar a uma probabilidade de que uma determinada fruta seja uma maçã. Naive Bayes geralmente requer um pequeno número de dados de treinamento para classificação.
Regressão Logística
Observe o diagrama a seguir. Mostra a distribuição dos pontos de dados no plano XY.

No diagrama, podemos inspecionar visualmente a separação dos pontos vermelhos dos pontos verdes. Você pode desenhar uma linha de limite para separar esses pontos. Agora, para classificar um novo ponto de dados, você só precisa determinar em que lado da linha o ponto está.
Máquinas de vetor de suporte
Observe a seguinte distribuição de dados. Aqui, as três classes de dados não podem ser separadas linearmente. As curvas de limite são não lineares. Nesse caso, encontrar a equação da curva torna-se uma tarefa complexa.
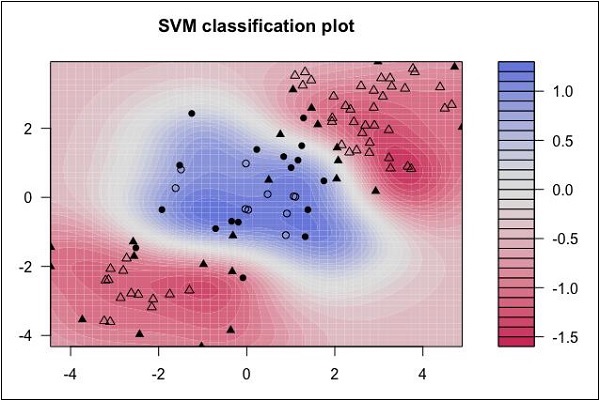
Fonte: http://uc-r.github.io/svm
O Support Vector Machines (SVM) é útil para determinar os limites de separação em tais situações.
Felizmente, na maioria das vezes, você não precisa codificar os algoritmos mencionados na lição anterior. Existem muitas bibliotecas padrão que fornecem a implementação pronta para uso desses algoritmos. Um kit de ferramentas popularmente usado é o scikit-learn. A figura abaixo ilustra o tipo de algoritmo que está disponível para uso nesta biblioteca.

Fonte: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
O uso desses algoritmos é trivial e, como são bem testados em campo, você pode usá-los com segurança em seus aplicativos de IA. A maioria dessas bibliotecas é gratuita para uso, mesmo para fins comerciais.
Até agora o que você viu é fazer a máquina aprender a encontrar a solução para o nosso objetivo. Na regressão, treinamos a máquina para prever um valor futuro. Na classificação, treinamos a máquina para classificar um objeto desconhecido em uma das categorias definidas por nós. Em suma, temos treinado máquinas para que possam prever Y para nossos dados X. Dado um enorme conjunto de dados e não estimando as categorias, seria difícil para nós treinar a máquina usando o aprendizado supervisionado. E se a máquina pudesse pesquisar e analisar o big data rodando em vários Gigabytes e Terabytes e nos dizer que esses dados contêm tantas categorias distintas?
Como exemplo, considere os dados do eleitor. Ao considerar algumas entradas de cada eleitor (esses são chamados de recursos na terminologia de IA), deixe a máquina prever que há tantos eleitores que votariam no partido político X e tantos votariam em Y e assim por diante. Portanto, em geral, estamos perguntando à máquina dada um grande conjunto de pontos de dados X, “O que você pode me dizer sobre X?”. Ou pode ser uma pergunta como “Quais são os cinco melhores grupos que podemos fazer de X?”. Ou pode ser até “Quais são os três recursos que ocorrem juntos com mais frequência no X?”.
Este é exatamente o objetivo do Aprendizado Não Supervisionado.
Algoritmos para aprendizagem não supervisionada
Vamos agora discutir um dos algoritmos amplamente usados para classificação em aprendizado de máquina não supervisionado.
agrupamento k-means
As eleições presidenciais de 2000 e 2004 nos Estados Unidos foram próximas - muito próximas. O maior percentual de voto popular que algum candidato recebeu foi de 50,7% e o menor foi de 47,9%. Se uma porcentagem dos eleitores tivesse mudado de lado, o resultado da eleição teria sido diferente. Existem pequenos grupos de eleitores que, quando devidamente apelados, mudam de lado. Esses grupos podem não ser enormes, mas com disputas tão acirradas, eles podem ser grandes o suficiente para mudar o resultado da eleição. Como você encontra esses grupos de pessoas? Como você os atrai com um orçamento limitado? A resposta é o agrupamento.
Vamos entender como isso é feito.
Primeiro, você coleta informações sobre as pessoas com ou sem o consentimento delas: qualquer tipo de informação que possa dar alguma pista sobre o que é importante para elas e o que influenciará a forma como votam.
Em seguida, você coloca essas informações em algum tipo de algoritmo de agrupamento.
Em seguida, para cada cluster (seria inteligente escolher o maior primeiro), você elabora uma mensagem que atrairá esses eleitores.
Por fim, você entrega a campanha e avalia se está funcionando.
Clustering é um tipo de aprendizagem não supervisionada que forma automaticamente clusters de coisas semelhantes. É como uma classificação automática. Você pode agrupar quase tudo e, quanto mais semelhantes os itens no agrupamento, melhores serão os agrupamentos. Neste capítulo, vamos estudar um tipo de algoritmo de agrupamento chamado k-means. É chamado de k-means porque encontra 'k' clusters únicos, e o centro de cada cluster é a média dos valores naquele cluster.
Identificação de Cluster
A identificação de cluster informa a um algoritmo: “Aqui estão alguns dados. Agora agrupe coisas semelhantes e me fale sobre esses grupos. ” A principal diferença da classificação é que, na classificação, você sabe o que está procurando. Embora esse não seja o caso do agrupamento.
O agrupamento às vezes é chamado de classificação não supervisionada porque produz o mesmo resultado que a classificação, mas sem ter classes predefinidas.
Agora, estamos confortáveis com o aprendizado supervisionado e não supervisionado. Para entender o resto das categorias de aprendizado de máquina, devemos primeiro entender Redes Neurais Artificiais (RNA), que aprenderemos no próximo capítulo.
A ideia de redes neurais artificiais foi derivada das redes neurais do cérebro humano. O cérebro humano é muito complexo. Estudando cuidadosamente o cérebro, os cientistas e engenheiros criaram uma arquitetura que poderia caber em nosso mundo digital de computadores binários. Uma arquitetura típica é mostrada no diagrama abaixo -
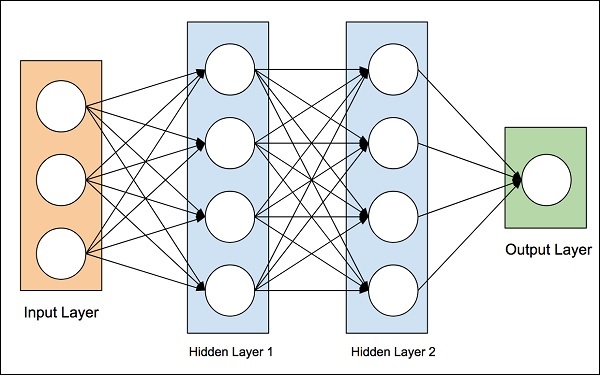
Existe uma camada de entrada que possui muitos sensores para coletar dados do mundo exterior. Do lado direito, temos uma camada de saída que nos dá o resultado previsto pela rede. Entre esses dois, várias camadas estão ocultas. Cada camada adicional adiciona mais complexidade no treinamento da rede, mas forneceria melhores resultados na maioria das situações. Existem vários tipos de arquiteturas projetadas que discutiremos agora.
Arquitetura ANN
O diagrama abaixo mostra várias arquiteturas de RNA desenvolvidas ao longo de um período de tempo e que estão em prática hoje.
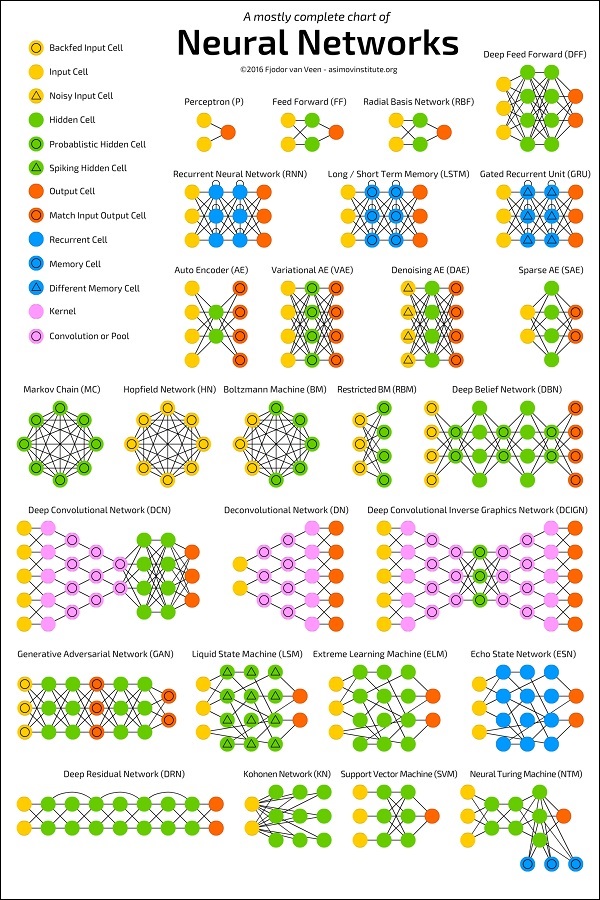
Fonte:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Cada arquitetura é desenvolvida para um tipo específico de aplicativo. Portanto, ao usar uma rede neural para seu aplicativo de aprendizado de máquina, você terá que usar uma das arquiteturas existentes ou projetar a sua própria. O tipo de aplicativo que você finalmente decide depende de suas necessidades de aplicativo. Não há uma diretriz única que diga a você para usar uma arquitetura de rede específica.
O Deep Learning usa ANN. Primeiro, veremos alguns aplicativos de aprendizado profundo que darão uma ideia de seu poder.
Formulários
O Deep Learning tem mostrado muito sucesso em várias áreas de aplicativos de aprendizado de máquina.
Self-driving Cars- Os carros autônomos e autônomos usam técnicas de aprendizagem profunda. Eles geralmente se adaptam às situações de trânsito em constante mudança e ficam cada vez melhores na direção ao longo do tempo.
Speech Recognition- Outra aplicação interessante do Deep Learning é o reconhecimento de fala. Todos nós usamos vários aplicativos móveis hoje que são capazes de reconhecer nossa fala. Siri da Apple, Alexa da Amazon, Cortena da Microsoft e Assistente do Google - todos usam técnicas de aprendizado profundo.
Mobile Apps- Usamos vários aplicativos baseados na web e móveis para organizar nossas fotos. Detecção de rosto, identificação de rosto, marcação de rosto, identificação de objetos em uma imagem - tudo isso usa aprendizado profundo.
Oportunidades inexploradas de aprendizado profundo
Depois de observar o grande sucesso que os aplicativos de aprendizado profundo alcançaram em muitos domínios, as pessoas começaram a explorar outros domínios onde o aprendizado de máquina ainda não era aplicado. Existem vários domínios nos quais as técnicas de aprendizagem profunda são aplicadas com sucesso e há muitos outros domínios que podem ser explorados. Alguns deles são discutidos aqui.
A agricultura é uma dessas indústrias onde as pessoas podem aplicar técnicas de aprendizado profundo para melhorar o rendimento da colheita.
O financiamento ao consumidor é outra área em que o aprendizado de máquina pode ajudar muito no fornecimento de detecção precoce de fraudes e na análise da capacidade de pagamento do cliente.
Técnicas de aprendizado profundo também são aplicadas ao campo da medicina para criar novos medicamentos e fornecer uma prescrição personalizada ao paciente.
As possibilidades são infinitas e é preciso ficar atento à medida que novas ideias e desenvolvimentos surgem com frequência.
O que é necessário para conseguir mais com o aprendizado profundo
Para usar o aprendizado profundo, o poder de supercomputação é um requisito obrigatório. Você precisa de memória e também de CPU para desenvolver modelos de aprendizado profundo. Felizmente, hoje temos uma fácil disponibilidade de HPC - High Performance Computing. Devido a isso, o desenvolvimento dos aplicativos de aprendizado profundo que mencionamos acima se tornou uma realidade hoje e no futuro também podemos ver os aplicativos nessas áreas inexploradas que discutimos anteriormente.
Agora, veremos algumas das limitações do aprendizado profundo que devemos considerar antes de usá-lo em nosso aplicativo de aprendizado de máquina.
Desvantagens do aprendizado profundo
Alguns dos pontos importantes que você precisa considerar antes de usar o aprendizado profundo estão listados abaixo -
- Abordagem de caixa preta
- Duração do Desenvolvimento
- Quantidade de dados
- Computacionalmente caro
Agora estudaremos cada uma dessas limitações em detalhes.
Abordagem de caixa preta
Uma RNA é como uma caixa preta. Você fornece uma determinada entrada e ela fornece uma saída específica. O diagrama a seguir mostra um desses aplicativos em que você alimenta uma imagem de animal em uma rede neural e diz que a imagem é de um cachorro.
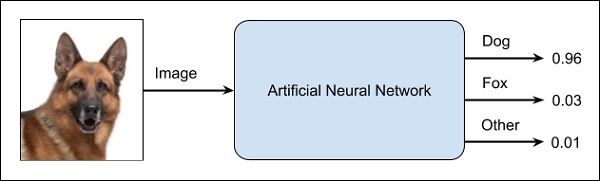
Por que isso é chamado de abordagem de caixa preta é que você não sabe por que a rede apresentou determinado resultado. Você não sabe como a rede concluiu que é um cachorro? Agora considere um aplicativo bancário em que o banco deseja decidir a qualidade de crédito de um cliente. A rede certamente fornecerá uma resposta a essa pergunta. Porém, você será capaz de justificar isso para um cliente? Os bancos precisam explicar a seus clientes por que o empréstimo não é sancionado?
Duração do Desenvolvimento
O processo de treinamento de uma rede neural é ilustrado no diagrama abaixo -

Você primeiro define o problema que deseja resolver, cria uma especificação para ele, decide sobre os recursos de entrada, projeta uma rede, implementa e testa a saída. Se a saída não for a esperada, considere isso como um feedback para reestruturar sua rede. Este é um processo iterativo e pode exigir várias iterações até que a rede de tempo esteja totalmente treinada para produzir os resultados desejados.
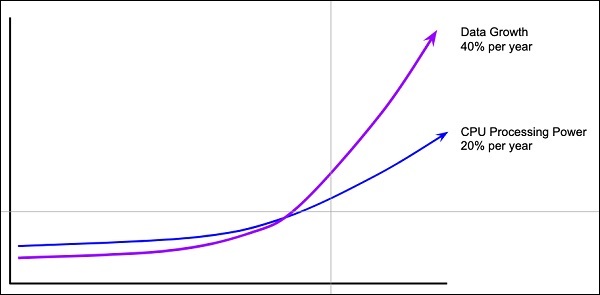
Quantidade de dados
As redes de aprendizado profundo geralmente exigem uma grande quantidade de dados para treinamento, enquanto os algoritmos de aprendizado de máquina tradicionais podem ser usados com grande sucesso mesmo com apenas alguns milhares de pontos de dados. Felizmente, a abundância de dados está crescendo a 40% ao ano e a capacidade de processamento da CPU está crescendo a 20% ao ano, conforme visto no diagrama abaixo -
Computacionalmente caro
Treinar uma rede neural requer várias vezes mais poder computacional do que aquele necessário para executar algoritmos tradicionais. O treinamento bem-sucedido de redes neurais profundas pode exigir várias semanas de tempo de treinamento.
Em contraste com isso, os algoritmos de aprendizado de máquina tradicionais levam apenas alguns minutos / horas para treinar. Além disso, a quantidade de potência computacional necessária para treinar redes neurais profundas depende muito do tamanho dos seus dados e da profundidade e complexidade da rede.
Depois de ter uma visão geral do que é o aprendizado de máquina, seus recursos, limitações e aplicativos, vamos mergulhar no aprendizado de “aprendizado de máquina”.
O aprendizado de máquina tem uma largura muito grande e requer habilidades em vários domínios. As habilidades que você precisa adquirir para se tornar um especialista em Aprendizado de Máquina estão listadas abaixo -
- Statistics
- Teorias de Probabilidade
- Calculus
- Técnicas de otimização
- Visualization
Necessidade de várias habilidades de aprendizado de máquina
Para lhe dar uma breve ideia de quais habilidades você precisa adquirir, vamos discutir alguns exemplos -
Notação Matemática
A maioria dos algoritmos de aprendizado de máquina é fortemente baseada em matemática. O nível de matemática que você precisa saber é provavelmente apenas um nível de iniciante. O importante é que você seja capaz de ler a notação que os matemáticos usam em suas equações. Por exemplo, se você for capaz de ler a notação e compreender o que ela significa, você está pronto para aprender o aprendizado de máquina. Caso contrário, você pode precisar aprimorar seus conhecimentos de matemática.
$$ f_ {AN} (net- \ theta) = \ begin {cases} \ gamma & if \: net- \ theta \ geq \ epsilon \\ net- \ theta & if - \ epsilon <net- \ theta <\ epsilon \\ - \ gamma & if \: net- \ theta \ leq- \ epsilon \ end {cases} $$
$$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i, j = 1} ^ m rótulo ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {array} {c} i \\ \ end {array} \ direita), x ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ rangle \ end {bmatrix} $$
$$ f_ {AN} (net- \ theta) = \ left (\ frac {e ^ {\ lambda (net- \ theta)} - e ^ {- \ lambda (net- \ theta)}} {e ^ { \ lambda (net- \ theta)} + e ^ {- \ lambda (net- \ theta)}} \ right) \; $$
Teoria da probabilidade
Aqui está um exemplo para testar seu conhecimento atual da teoria da probabilidade: Classificação com probabilidades condicionais.
$$ p (c_ {i} | x, y) \; = \ frac {p (x, y | c_ {i}) \; p (c_ {i}) \;} {p (x, y) \ ;} $$
Com essas definições, podemos definir a regra de classificação Bayesiana -
- Se P (c1 | x, y)> P (c2 | x, y), a classe é c1.
- Se P (c1 | x, y) <P (c2 | x, y), a classe é c2.
Problema de Otimização
Aqui está uma função de otimização
$$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i, j = 1} ^ m rótulo ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {array} {c} i \\ \ end {array} \ direita), x ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ rangle \ end {bmatrix} $$
Sujeito às seguintes restrições -
$$ \ alpha \ geq0 e \: \ displaystyle \ sum \ limits_ {i-1} ^ m \ alpha_ {i} \ cdot \: rótulo ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) = 0 $$
Se você pode ler e entender o acima, está tudo pronto.
Visualização
Em muitos casos, você precisará entender os vários tipos de gráficos de visualização para entender sua distribuição de dados e interpretar os resultados da saída do algoritmo.
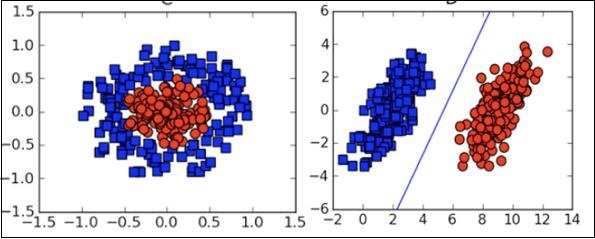
Além dos aspectos teóricos acima do aprendizado de máquina, você precisa de boas habilidades de programação para codificar esses algoritmos.
Então, o que é necessário para implementar o ML? Vamos examinar isso no próximo capítulo.
Para desenvolver aplicações de ML, você terá que decidir sobre a plataforma, o IDE e a linguagem de desenvolvimento. Existem várias opções disponíveis. A maioria deles atenderia aos seus requisitos facilmente, pois todos eles fornecem a implementação dos algoritmos de IA discutidos até agora.
Se você estiver desenvolvendo o algoritmo de ML por conta própria, os seguintes aspectos precisam ser entendidos com cuidado -
O idioma de sua escolha - essencialmente, é sua proficiência em uma das linguagens com suporte no desenvolvimento de ML.
O IDE que você usa - isso dependeria de sua familiaridade com os IDEs existentes e seu nível de conforto.
Development platform- Existem várias plataformas disponíveis para desenvolvimento e implantação. A maioria deles é de uso gratuito. Em alguns casos, pode ser necessário incorrer em uma taxa de licença além de uma certa quantidade de uso. Aqui está uma breve lista de opções de idiomas, IDEs e plataformas para sua referência imediata.
Escolha do idioma
Aqui está uma lista de linguagens que suportam o desenvolvimento de ML -
- Python
- R
- Matlab
- Octave
- Julia
- C++
- C
Esta lista não é essencialmente abrangente; no entanto, ele cobre muitas linguagens populares usadas no desenvolvimento de aprendizado de máquina. Dependendo do seu nível de conforto, selecione uma linguagem para o desenvolvimento, desenvolva seus modelos e teste.
IDEs
Aqui está uma lista de IDEs que suportam o desenvolvimento de ML -
- R Studio
- Pycharm
- Notebook iPython / Jupyter
- Julia
- Spyder
- Anaconda
- Rodeo
- Google –Colab
A lista acima não é essencialmente abrangente. Cada um tem seus próprios méritos e deméritos. O leitor é encorajado a experimentar esses diferentes IDEs antes de restringir a um único.
Plataformas
Aqui está uma lista de plataformas nas quais os aplicativos de ML podem ser implantados -
- IBM
- Microsoft Azure
- Nuvem do Google
- Amazon
- Mlflow
Mais uma vez, esta lista não é exaustiva. O leitor é incentivado a se inscrever nos serviços mencionados acima e experimentá-los por conta própria.
Este tutorial apresentou o aprendizado de máquina. Agora, você sabe que o aprendizado de máquina é uma técnica de treinar máquinas para realizar as atividades que um cérebro humano pode realizar, embora um pouco mais rápido e melhor do que um ser humano médio. Hoje vimos que as máquinas podem vencer campeões humanos em jogos como Xadrez, AlphaGO, que são considerados muito complexos. Você viu que as máquinas podem ser treinadas para realizar atividades humanas em várias áreas e podem ajudar os humanos a ter uma vida melhor.
O aprendizado de máquina pode ser supervisionado ou não supervisionado. Se você tiver menor quantidade de dados e dados claramente rotulados para treinamento, opte pelo Aprendizado Supervisionado. A aprendizagem não supervisionada geralmente forneceria melhor desempenho e resultados para grandes conjuntos de dados. Se você tem um grande conjunto de dados facilmente disponível, opte por técnicas de aprendizado profundo. Você também aprendeu Aprendizado por Reforço e Aprendizado por Reforço Profundo. Agora você sabe o que são redes neurais, suas aplicações e limitações.
Finalmente, quando se trata do desenvolvimento de seus próprios modelos de aprendizado de máquina, você analisou as opções de várias linguagens de desenvolvimento, IDEs e plataformas. A próxima coisa que você precisa fazer é começar a aprender e praticar cada técnica de aprendizado de máquina. O assunto é vasto, quer dizer que há largura, mas se você considerar a profundidade, cada tópico pode ser aprendido em poucas horas. Cada tópico é independente um do outro. Você precisa levar em consideração um tópico de cada vez, aprendê-lo, praticá-lo e implementar o (s) algoritmo (s) usando um idioma de sua escolha. Esta é a melhor maneira de começar a estudar Aprendizado de Máquina. Praticando um tópico de cada vez, logo você adquirirá a largura que é eventualmente exigida de um especialista em Aprendizado de Máquina.
Boa sorte!