SAS - Conjuntos de dados concatenados
Vários conjuntos de dados SAS podem ser concatenados para fornecer um único conjunto de dados usando o SETdeclaração. O número total de observações no conjunto de dados concatenados é a soma do número de observações nos conjuntos de dados originais. A ordem das observações é sequencial. Todas as observações do primeiro conjunto de dados são seguidas por todas as observações do segundo conjunto de dados e assim por diante.
Idealmente, todos os conjuntos de dados combinados têm as mesmas variáveis, mas no caso de terem um número diferente de variáveis, então no resultado todas as variáveis aparecem, com valores perdidos para o conjunto de dados menor.
Sintaxe
A sintaxe básica para a instrução SET no SAS é -
SET data-set 1 data-set 2 data-set 3.....;A seguir está a descrição dos parâmetros usados -
data-set1,data-set2 são nomes de conjuntos de dados escritos um após o outro.
Exemplo
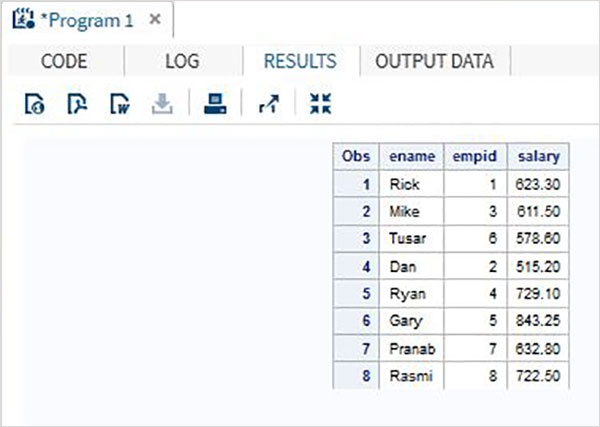
Considere os dados de funcionários de uma organização que estão disponíveis em dois conjuntos de dados diferentes, um para o departamento de TI e outro para o departamento não relacionado à TI. Para obter os detalhes completos de todos os funcionários, concatenamos os dois conjuntos de dados usando a instrução SET mostrada abaixo.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Cenários
Quando temos muitas variações nos conjuntos de dados para concatenação, o resultado das variáveis pode ser diferente, mas o número total de observações no conjunto de dados concatenados é sempre a soma das observações em cada conjunto de dados. Consideraremos a seguir muitos cenários dessa variação.
Número diferente de variáveis
Se um dos conjuntos de dados originais tiver mais número de variáveis do que outro, os conjuntos de dados ainda serão combinados, mas no conjunto de dados menor essas variáveis aparecem como ausentes.
Exemplo
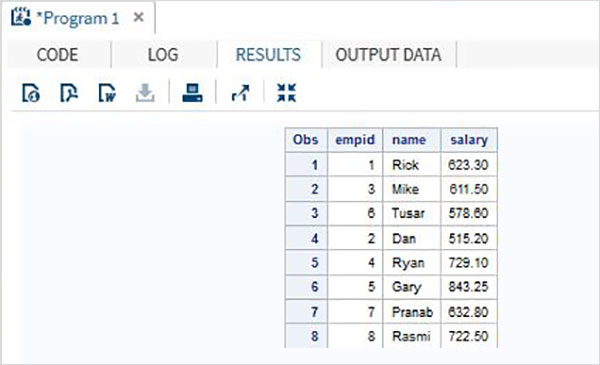
No exemplo a seguir, o primeiro conjunto de dados possui uma variável extra chamada DOJ. No resultado, o valor de DOJ para o segundo conjunto de dados aparecerá como ausente.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.

Nome de variável diferente
Neste cenário, os conjuntos de dados têm o mesmo número de variáveis, mas um nome de variável difere entre eles. Nesse caso, uma concatenação normal produzirá todas as variáveis no conjunto de resultados e dará resultados ausentes para as duas variáveis que diferem. Embora não possamos alterar o nome da variável nos conjuntos de dados originais, podemos aplicar a função RENAME no conjunto de dados concatenado que criamos. Isso produzirá o mesmo resultado de uma concatenação normal, mas é claro com um novo nome de variável no lugar de dois nomes de variáveis diferentes presentes no conjunto de dados original.
Exemplo
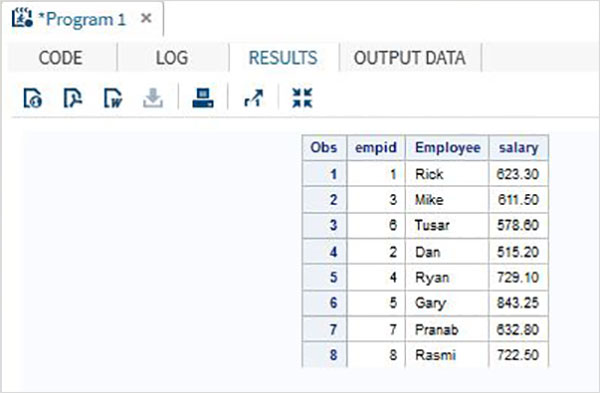
No exemplo a seguir, o conjunto de dados ITDEPT tem o nome da variável ename enquanto o conjunto de dados NON_ITDEPT tem o nome da variável empname.Mas ambas as variáveis representam o mesmo tipo (personagem). Nós aplicamos oRENAME função na instrução SET conforme mostrado abaixo.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Comprimentos variáveis diferentes
Se os comprimentos das variáveis nos dois conjuntos de dados forem diferentes, o conjunto de dados concatenados terá valores nos quais alguns dados serão truncados para a variável com comprimento menor. Isso acontece se o primeiro conjunto de dados tiver um comprimento menor. Para resolver isso, aplicamos o comprimento maior a ambos os conjuntos de dados, conforme mostrado abaixo.
Exemplo
No exemplo abaixo, a variável enametem comprimento 5 no primeiro conjunto de dados e 7 no segundo. Ao concatenar, aplicamos a instrução LENGTH no conjunto de dados concatenados para definir o comprimento do ename como 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.