SAS - Guia Rápido
SAS apoia Statistical Analysis Software. Foi criado no ano de 1960 pelo SAS Institute. A partir de 1º de janeiro de 1960, o SAS foi usado para gerenciamento de dados, inteligência de negócios, análise preditiva, análise descritiva e prescritiva, etc. Desde então, muitos novos procedimentos estatísticos e componentes foram introduzidos no software.
Com a introdução do JMP (Jump) para estatísticas, o SAS tirou proveito do Graphical user Interfaceque foi introduzido pelo Macintosh. O Jump é usado basicamente para aplicações como Six Sigma, projetos, controle de qualidade e análise de engenharia e científica.
O SAS é independente de plataforma, o que significa que você pode executar o SAS em qualquer sistema operacional Linux ou Windows. SAS é conduzido por programadores SAS que usam várias sequências de operações nos conjuntos de dados SAS para fazer relatórios adequados para análise de dados.
Ao longo dos anos, a SAS adicionou várias soluções ao seu portfólio de produtos. Possui solução para Governança de Dados, Qualidade de Dados, Big Data Analytics, Text Mining, Gerenciamento de Fraudes, Ciências da Saúde etc. Podemos assumir com segurança que o SAS tem uma solução para cada domínio de negócio.
Para dar uma olhada na lista de produtos disponíveis, você pode visitar SAS Components
Por que usamos SAS
SAS é basicamente trabalhado em grandes conjuntos de dados. Com a ajuda do software SAS, você pode realizar várias operações nos dados, como -
- Gestão de dados
- Análise Estatística
- Formação de relatórios com gráficos perfeitos
- Planejamento de negócios
- Pesquisa operacional e gerenciamento de projetos
- Melhoria da Qualidade
- Desenvolvimento de aplicações
- Extração de dados
- Transformação de dados
- Atualização e modificação de dados
Se falamos sobre os componentes do SAS, então mais de 200 componentes estão disponíveis no SAS.
| Sr. Não. | Componente SAS e seu uso |
|---|---|
| 1 | Base SAS É um componente central que contém facilidade de gerenciamento de dados e uma linguagem de programação para análise de dados. É também o mais utilizado. |
| 2 | SAS/GRAPH Crie gráficos, apresentações para melhor compreensão e apresentação do resultado em um formato adequado. |
| 3 | SAS/STAT Realizar análise estatística com a análise de variância, regressão, análise multivariada, análise de sobrevivência e análise psicométrica, análise de modelo misto. |
| 4 | SAS/OR Pesquisa operacional. |
| 5 | SAS/ETS Econometria e análise de séries temporais. |
| 6 | SAS/IML C Linguagem de matriz interativa. |
| 7 | SAS/AF Instalação de aplicativos. |
| 8 | SAS/QC Controle de qualidade. |
| 9 | SAS/INSIGHT Mineração de dados. |
| 10 | SAS/PH Análise de ensaios clínicos. |
| 11 | SAS/Enterprise Miner Mineração de dados. |
Tipos de software SAS
- Windows ou PC SAS
- SAS EG (guia empresarial)
- SAS EM (Enterprise Miner, ou seja, para análise preditiva)
- SAS significa
- SAS Stats
Geralmente usamos o Window SAS na organização e também no instituto de treinamento. Algumas organizações usam Linux, mas não há interface gráfica com o usuário, portanto, você deve escrever o código para cada consulta. Mas na janela SAS há muitos utilitários disponíveis que ajudam muito os programadores e também reduzem o tempo de escrita dos códigos.
Uma janela SaS possui 5 partes.
| Sr. Não. | Janela SAS e seu uso |
|---|---|
| 1 | Log Window Uma janela de log é como uma janela de execução onde podemos verificar a execução do programa SAS. Nesta janela também podemos verificar os erros. É muito importante verificar sempre a janela de log após a execução do programa. Para que possamos ter um entendimento adequado sobre a execução do nosso programa. |
| 2 | Editor Window
A janela do editor é a parte do SAS onde escrevemos todos os códigos. É como um bloco de notas. |
| 3 | Output Window A janela de saída é a janela de resultados onde podemos ver a saída de nosso programa. |
| 4 | Result Window É como um índice para todas as saídas. Todos os programas que executamos em uma sessão do SAS estão listados lá e você pode abrir a saída clicando no resultado da saída. Mas eles são mencionados apenas em uma sessão do SAS. Se fecharmos o software e depois abri-lo, a janela de resultados ficará vazia. |
| 5 | Explore Window Aqui estão todas as bibliotecas listadas. Você também pode navegar pelos arquivos compatíveis com SAS do sistema a partir daqui. |
Bibliotecas no SAS
Bibliotecas são como armazenamento em SAS. Você pode criar uma biblioteca e salvar todos os programas semelhantes nessa biblioteca. SAS fornece a você a facilidade de criar várias bibliotecas. Uma biblioteca SAS tem apenas 8 caracteres.
Existem dois tipos de bibliotecas disponíveis no SAS -
| Sr. Não. | Janela SAS e seu uso |
|---|---|
| 1 | Temporary or Work Library Esta é a biblioteca padrão do SAS. Todos os programas que criamos são armazenados nesta biblioteca de trabalho, se não atribuirmos nenhuma outra biblioteca a eles. Você pode verificar esta biblioteca de trabalho na janela de exploração. Se você criar um programa SAS e não tiver atribuído nenhuma biblioteca permanente a ele, se você encerrar a sessão depois disso novamente, você iniciará o software, então este programa não estará na biblioteca de trabalho. Porque só estará lá na biblioteca de trabalho enquanto durar a sessão. |
| 2 | Permanent Library Estas são as bibliotecas permanentes do SAS. Podemos criar uma nova biblioteca SAS usando utilitários SAS ou escrevendo os códigos na janela do editor. Essas bibliotecas são nomeadas como permanentes porque se criarmos um programa no SAS e salvá-lo nessas bibliotecas permanentes, elas estarão disponíveis pelo tempo que quisermos. |
SAS Institute Inc. lançou um gratuito SAS University Editiono que é bom o suficiente para aprender programação SAS. Ele fornece todos os recursos que você precisa aprender na programação BASE SAS que, por sua vez, permite que você aprenda qualquer outro componente SAS.
O processo de download e instalação do SAS University Edition é muito direto. Ele está disponível como uma máquina virtual que precisa ser executada em um ambiente virtual. Você precisa ter um software de virtualização já instalado em seu PC antes de executar o software SAS. Neste tutorial, usaremosVMware. Abaixo estão os detalhes das etapas para baixar, configurar o ambiente SAS e verificar a instalação.
Baixar SAS University Edition
SAS University Editionestá disponível para download no URL SAS University Edition . Role para baixo para ler os requisitos do sistema antes de iniciar o download. A tela a seguir aparece ao visitar este URL.
Software de virtualização de configuração
Role para baixo na mesma página para localizar a instalação stpe-1. Esta etapa fornece os links para obter o software de virtualização adequado para você. Caso você já tenha algum desses softwares instalados em seu sistema, pode pular esta etapa.

Software de virtualização de início rápido
Caso você seja totalmente novo no ambiente de virtualização, familiarize-se com ele, consultando os seguintes guias e vídeos disponíveis na etapa 2. Novamente, você pode pular esta etapa caso já esteja familiarizado.

Baixe o arquivo Zip
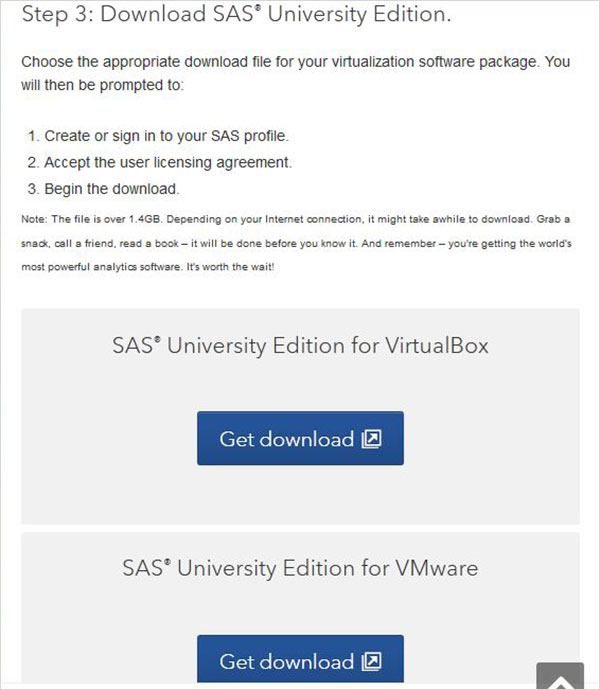
Na etapa 3, você pode escolher a versão apropriada do SAS University Edition compatível com o ambiente de virtualização que você possui. Ele é baixado como um arquivo zip com nome semelhante a unvbasicvapp__9411005__vmx__en__sp0__1.zip
Descompacte o arquivo zip
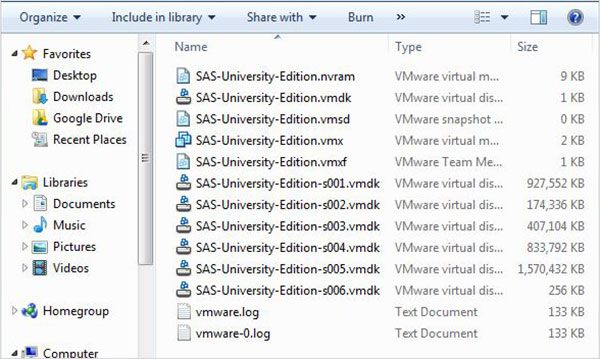
O arquivo zip acima precisa ser descompactado e armazenado em um diretório apropriado. Em nosso caso, escolhemos o arquivo zip VMware que mostra os seguintes arquivos após a descompactação.
Carregando a máquina virtual
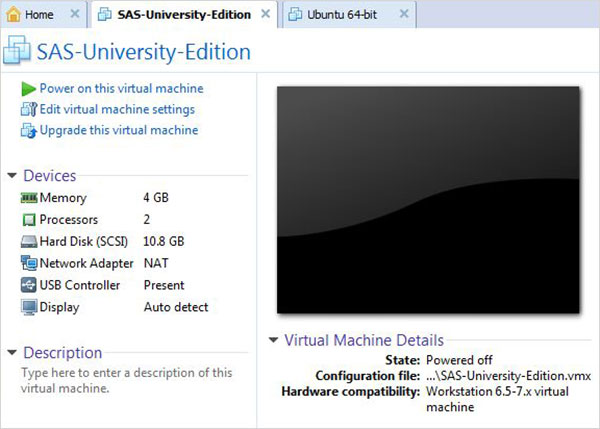
Inicie o VMware player (ou estação de trabalho) e abra o arquivo que termina com a extensão .vmx. A tela abaixo é exibida. Observe as configurações básicas como memória e espaço no disco rígido alocado para a VM.
Ligue a máquina virtual
Clique no Power on this virtual machineao lado da marca de seta verde para iniciar a máquina virtual. A tela a seguir é exibida.

A tela abaixo aparece quando o SAS vm está no estado de carregamento, após o qual o VM em execução fornece um prompt para ir para um local de URL que abrirá o ambiente SAS.
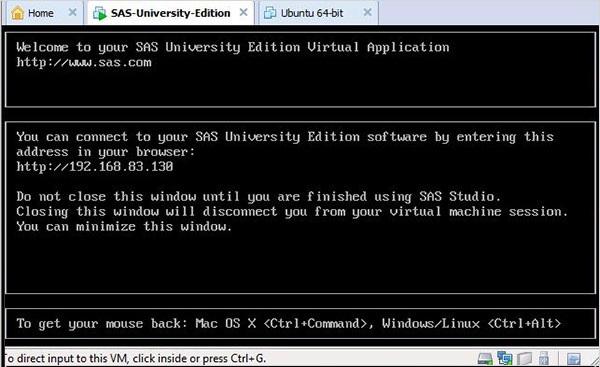
Iniciando SAS Studio
Abra uma nova guia do navegador e carregue o URL acima (que difere de um PC para outro). A tela abaixo aparece indicando que o ambiente SAS está pronto.
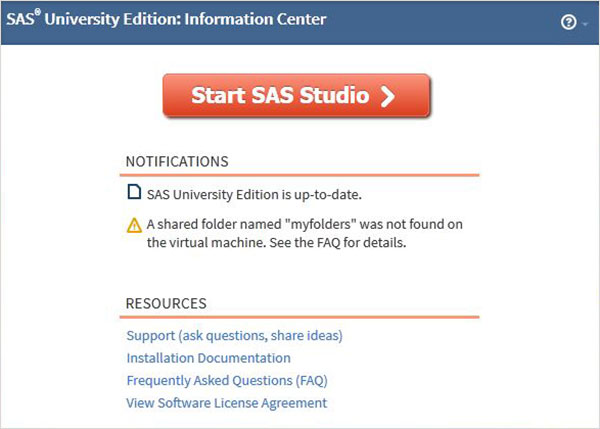
O ambiente SAS
Ao clicar no Start SAS Studio obtemos o ambiente SAS que, por padrão, abre no modo de programador visual, conforme mostrado abaixo.
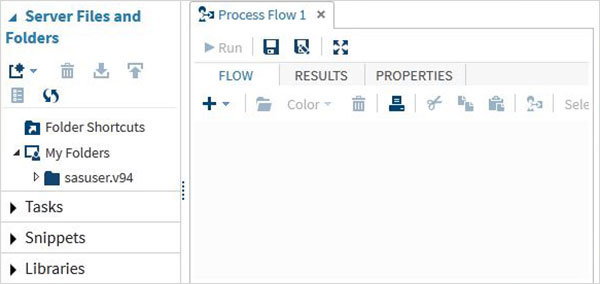
Também podemos alterá-lo para o modo de programador SAS clicando no menu suspenso.
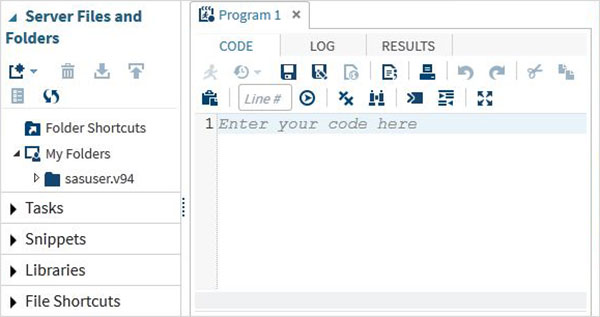
Agora estamos prontos para escrever programas SAS.
Os programas SAS são criados usando uma interface de usuário conhecida como SAS Studio.
Abaixo está uma descrição de várias janelas e seu uso.
Janela Principal SAS
Esta é a janela que você vê ao entrar no ambiente SAS. Na esquerda está oNavigation Paneusado para navegar por vários recursos de programação. À direita está oWork Area que é usado para escrever o código e executá-lo.

Preenchimento Automático de Código
Este é um recurso muito poderoso que ajuda a obter a sintaxe correta das palavras-chave do SAS, bem como fornece um link para a documentação dessa palavra-chave.
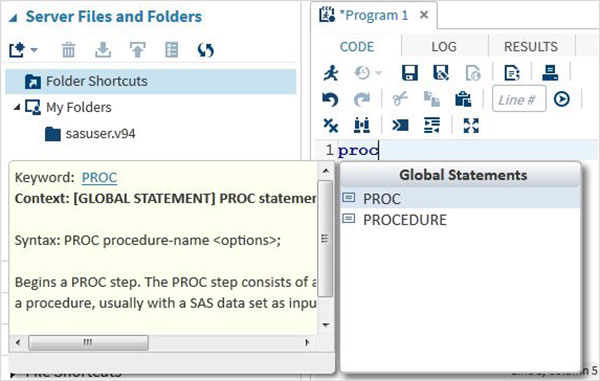
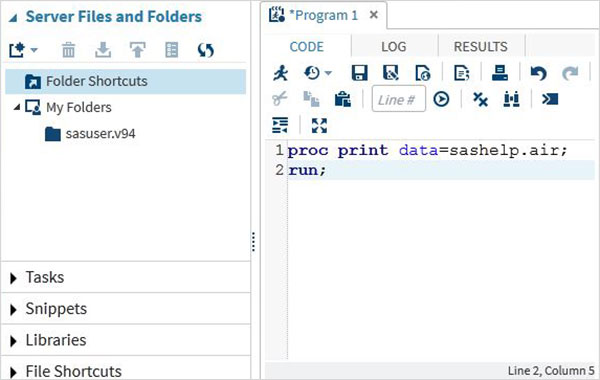
Execução do Programa
A execução do código é feita pressionando o ícone de execução, que é o primeiro ícone da esquerda ou o botão F3.
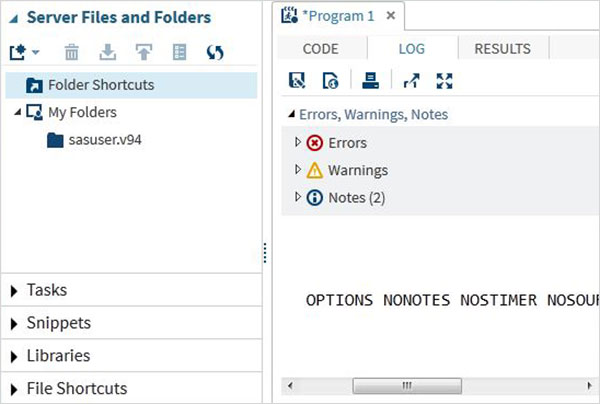
Log do programa
O log do código executado está disponível no Logaba. Descreve os erros, avisos ou notas sobre a execução do programa. Esta é a janela onde você obtém todas as dicas para solucionar problemas de seu código.
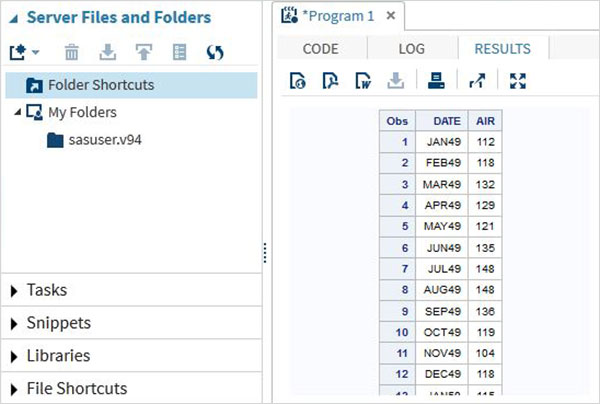
Resultado do programa
O resultado da execução do código é visto na guia RESULTADOS. Por padrão, eles são formatados como tabelas html.
Guias de programa
A área de navegação contém recursos para criar e gerenciar programas. Ele também fornece as funcionalidades predefinidas para serem usadas com seu programa.
Arquivos e pastas do servidor
Nesta guia, podemos criar programas adicionais, importar dados a serem analisados e consultar os dados existentes. Ele também pode ser usado para criar atalhos de pasta.
Tarefas
A guia Tarefas fornece recursos para usar programas SAS integrados, fornecendo apenas as variáveis de entrada. Por exemplo, na pasta de estatísticas, você pode encontrar um programa SAS para fazer regressão linear, fornecendo apenas o nome do conjunto de dados SAS e os nomes das variáveis.
Trechos
A guia snippets fornece recursos para escrever macro SAS e gerar arquivos do conjunto de dados existente

Bibliotecas de programas
SAS armazena os conjuntos de dados em bibliotecas SAS. A biblioteca temporária está disponível apenas para uma única sessão e é denominada WORK. Mas as bibliotecas permanentes estão sempre disponíveis.
Atalhos de arquivo
Esta guia é usada para acessar arquivos armazenados fora do ambiente SAS. Os atalhos para esses arquivos são armazenados nesta guia.
A Programação SAS envolve primeiro a criação / leitura dos conjuntos de dados na memória e, em seguida, a análise desses dados. Precisamos entender o fluxo no qual um programa é escrito para conseguir isso.
Estrutura do programa SAS
O diagrama abaixo mostra as etapas a serem escritas na sequência fornecida para criar um Programa SAS.
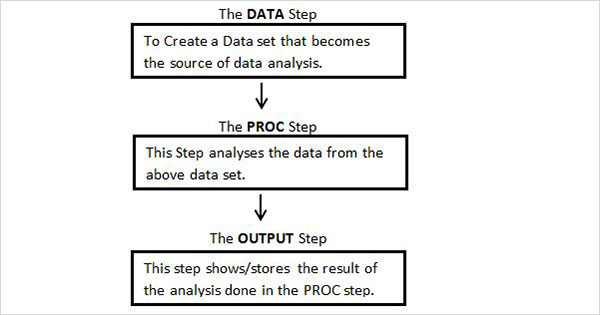
Cada programa SAS deve ter todas essas etapas para completar a leitura dos dados de entrada, analisando os dados e fornecendo a saída da análise. Também oRUN declaração no final de cada etapa é necessária para concluir a execução dessa etapa.
Etapa DATA
Esta etapa envolve o carregamento do conjunto de dados necessário na memória SAS e a identificação das variáveis (também chamadas de colunas) do conjunto de dados. Também captura os registros (também chamados de observações ou assuntos). A sintaxe para a instrução DATA é a seguinte.
Sintaxe
DATA data_set_name; #Name the data set.
INPUT var1,var2,var3; #Define the variables in this data set.
NEW_VAR; #Create new variables.
LABEL; #Assign labels to variables.
DATALINES; #Enter the data.
RUN;Exemplo
O exemplo a seguir mostra um caso simples de nomear o conjunto de dados, definir as variáveis, criar novas variáveis e inserir os dados. Aqui, as variáveis de string têm um $ no final e os valores numéricos estão sem ele.
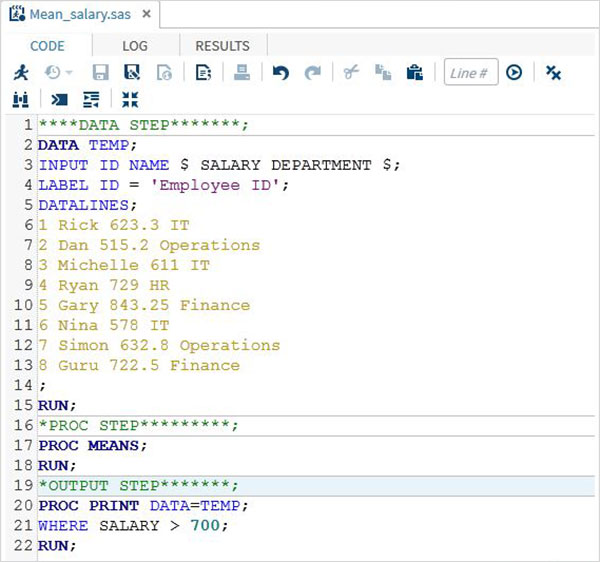
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
comm = SALARY*0.25;
LABEL ID = 'Employee ID' comm = 'COMMISION';
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;PROC Step
Esta etapa envolve a chamada de um procedimento integrado do SAS para analisar os dados.
Sintaxe
PROC procedure_name options; #The name of the proc.
RUN;Exemplo
O exemplo abaixo mostra o uso do MEANS procedimento para imprimir os valores médios das variáveis numéricas no conjunto de dados.
PROC MEANS;
RUN;A Etapa OUTPUT
Os dados dos conjuntos de dados podem ser exibidos com instruções de saída condicionais.
Sintaxe
PROC PRINT DATA = data_set;
OPTIONS;
RUN;Exemplo
O exemplo a seguir mostra o uso da cláusula where na saída para produzir apenas alguns registros do conjunto de dados.
PROC PRINT DATA = TEMP;
WHERE SALARY > 700;
RUN;O Programa SAS completo
Abaixo está o código completo para cada uma das etapas acima.
Resultado do programa
RESULTS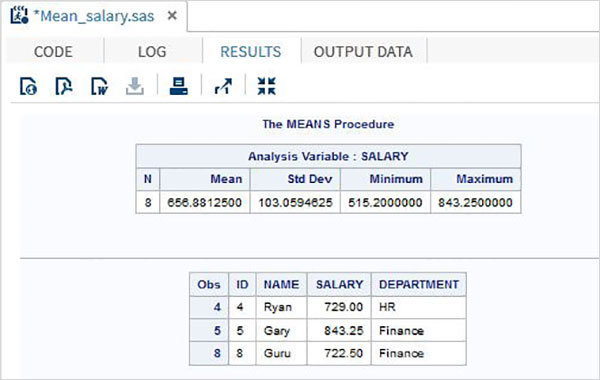
Como qualquer outra linguagem de programação, a linguagem SAS tem suas próprias regras de sintaxe para criar os programas SAS.
Os três componentes de qualquer programa SAS - declarações, variáveis e conjuntos de dados seguem as regras de sintaxe abaixo.
Declarações SAS
As declarações podem começar em qualquer lugar e terminar em qualquer lugar. Um ponto e vírgula no final da última linha marca o final da declaração.
Muitas instruções SAS podem estar na mesma linha, com cada instrução terminando com um ponto-e-vírgula.
O espaço pode ser usado para separar os componentes em uma instrução de programa SAS.
As palavras-chave do SAS não diferenciam maiúsculas de minúsculas.
Cada programa SAS deve terminar com uma instrução RUN.
Nomes de variáveis SAS
As variáveis no SAS representam uma coluna no conjunto de dados SAS. Os nomes das variáveis seguem as regras abaixo.
Pode ter no máximo 32 caracteres.
Não pode incluir espaços em branco.
Deve começar com as letras de A a Z (sem distinção entre maiúsculas e minúsculas) ou um sublinhado (_).
Pode incluir números, mas não como o primeiro caractere.
Os nomes das variáveis não diferenciam maiúsculas de minúsculas.
Exemplo
# Valid Variable Names
REVENUE_YEAR
MaxVal
_Length
# Invalid variable Names
Miles Per Liter #contains Space.
RainfFall% # contains apecial character other than underscore.
90_high # Starts with a number.Conjunto de dados SAS
A instrução DATA marca a criação de um novo conjunto de dados SAS. As regras para a criação do conjunto de DADOS são as seguintes.
Uma única palavra após a instrução DATA indica um nome de conjunto de dados temporário. O que significa que o conjunto de dados é apagado no final da sessão.
O nome do conjunto de dados pode ser prefixado com um nome de biblioteca, o que o torna um conjunto de dados permanente. O que significa que o conjunto de dados persiste após o término da sessão.
Se o nome do conjunto de dados SAS for omitido, o SAS criará um conjunto de dados temporário com um nome gerado pelo SAS como - DATA1, DATA2 etc.
Exemplo
# Temporary data sets.
DATA TempData;
DATA abc;
DATA newdat;
# Permanent data sets.
DATA LIBRARY1.DATA1
DATA MYLIB.newdat;Extensões de arquivo SAS
Os programas SAS, arquivos de dados e os resultados dos programas são salvos com várias extensões no Windows.
*.sas - Representa o arquivo de código SAS que pode ser editado usando o Editor SAS ou qualquer editor de texto.
*.log - Representa o arquivo de log do SAS, ele contém informações como erros, avisos e detalhes do conjunto de dados para um programa SAS enviado.
*.mht / *.html −Representa o arquivo de resultados do SAS.
*.sas7bdat −Representa o arquivo de dados SAS que contém um conjunto de dados SAS incluindo nomes de variáveis, rótulos e resultados de cálculos.
Comentários no SAS
Os comentários no código SAS são especificados de duas maneiras. Abaixo estão esses dois formatos.
*mensagem; digite comentário
Um comentário na forma de *message;não pode conter ponto-e-vírgula ou aspas sem correspondência dentro dele. Além disso, não deve haver nenhuma referência a quaisquer instruções macro dentro de tais comentários. Ele pode se estender por várias linhas e ter qualquer comprimento. A seguir está um exemplo de comentário de uma única linha -
* This is comment ;A seguir está um exemplo de comentário de várias linhas -
* This is first line of the comment
* This is second line of the comment;/ * mensagem * / tipo de comentário
Um comentário na forma de /*message*/é usado com mais frequência e não pode ser aninhado. Mas pode abranger várias linhas e ter qualquer comprimento. A seguir está um exemplo de comentário de uma única linha -
/* This is comment */A seguir está um exemplo de comentário de várias linhas -
/* This is first line of the comment
* This is second line of the comment */Os dados que estão disponíveis para um programa SAS para análise são chamados de Conjunto de dados SAS. Ele é criado usando a etapa DATA.SAS pode ler uma variedade de arquivos como suas fontes de dados comoCSV, Excel, Access, SPSS and also raw data. Ele também tem muitas fontes de dados embutidas disponíveis para uso.
Os conjuntos de dados são chamados temporary Data Set se forem usados pelo programa SAS e, em seguida, descartados após a execução da sessão.
Mas se for armazenado permanentemente para uso futuro, é chamado de permanent Data set. Todos os conjuntos de dados permanentes são armazenados em uma biblioteca específica.
O conjunto de dados SAS é armazenado na forma de linhas e colunas e também conhecido como tabela de dados SAS. A seguir, vemos os exemplos de conjuntos de dados permanentes que são embutidos, bem como vermelhos de fontes externas.
Conjuntos de dados integrados SAS
Esses conjuntos de dados já estão disponíveis no software SAS instalado. Eles podem ser explorados e usados na formulação de expressões de amostra para análise de dados. Para explorar esses conjuntos de dados, vá paraLibraries -> My Libraries -> SASHELP. Ao expandi-lo, vemos a lista de nomes de todos os conjuntos de dados integrados disponíveis.
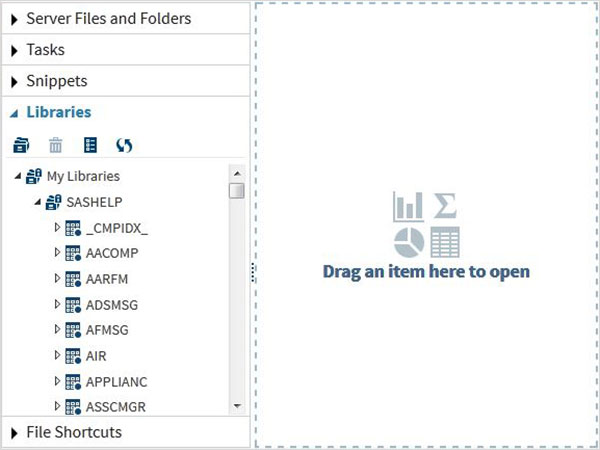
Vamos rolar para baixo para localizar um conjunto de dados chamado CARS.Clique duas vezes neste conjunto de dados para abri-lo no painel direito da janela, onde podemos explorá-lo ainda mais. Também podemos minimizar o painel esquerdo usando o botão maximizar visualização sob o painel direito.
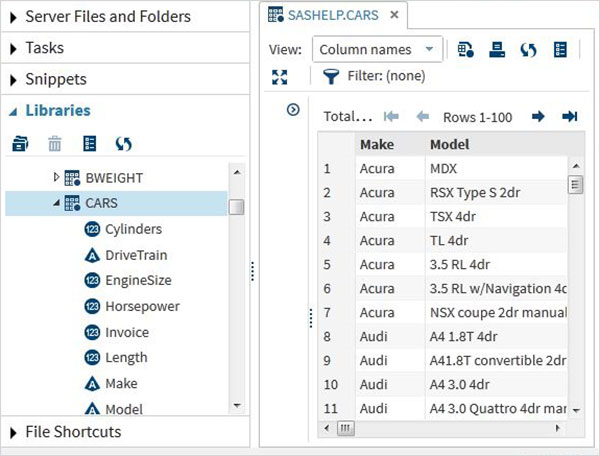
Podemos rolar para a direita usando a barra de rolagem na parte inferior para explorar todas as colunas e seus valores na tabela.
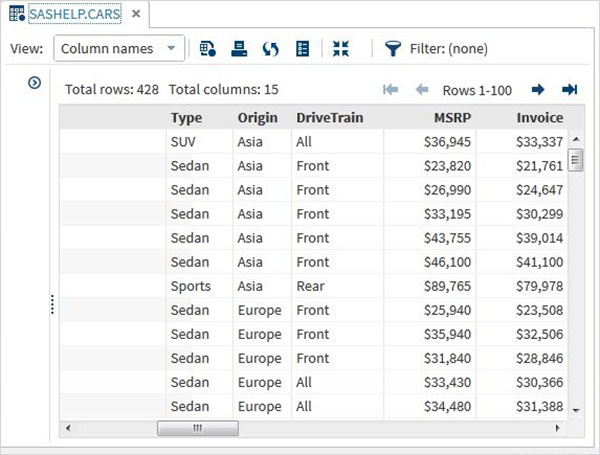
Importando conjuntos de dados externos
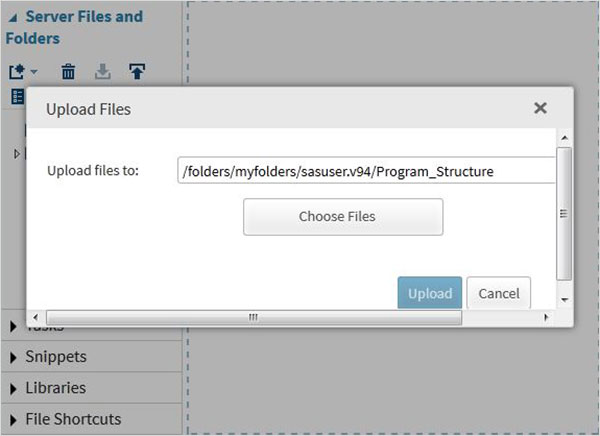
Podemos exportar nossos próprios arquivos como conjuntos de dados usando o recurso de importação disponível no SAS Studio. Mas esses arquivos devem estar disponíveis nas pastas do servidor SAS. Portanto, temos que fazer o upload dos arquivos de dados de origem para a pasta SAS usando a opção de upload noServer Files and Folders.
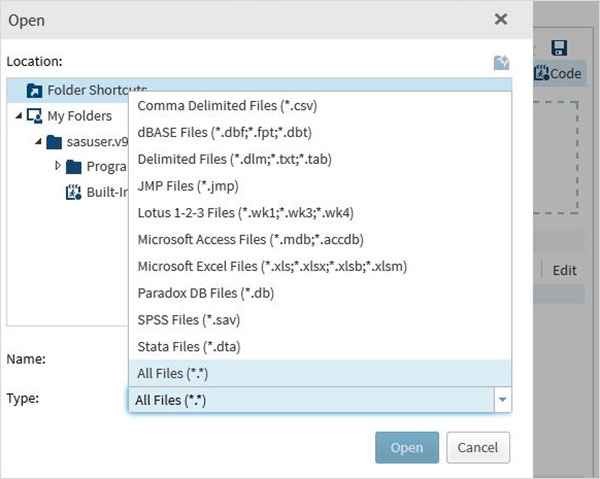
Em seguida, usamos o arquivo acima em um programa SAS, importando-o. Para fazer isso, usamos a opçãoTasks -> Utilities -> Import data como mostrado abaixo. Dê um duplo clique no botão Importar Dados que abre a janela à direita para escolher o arquivo para o Conjunto de Dados.
Próximo clique no Select Filesbotão sob o programa de importação de dados no painel direito. A seguir está a lista dos tipos de arquivo que podem ser importados.
Escolhemos o arquivo "employee.txt" armazenado no sistema local e importamos o arquivo conforme mostrado abaixo.
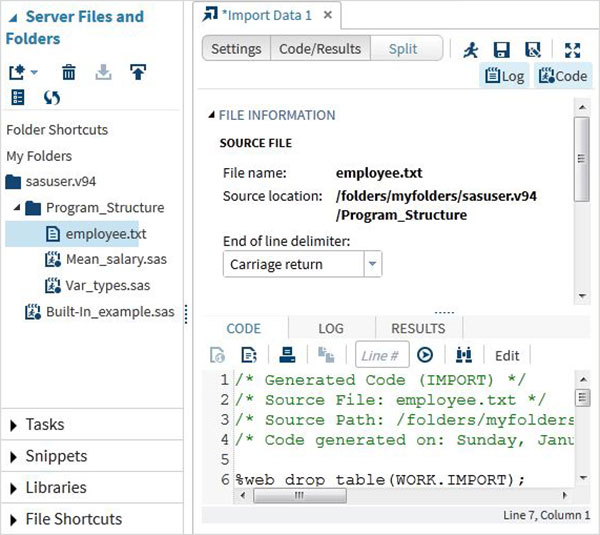
Ver os dados importados
Podemos ver os dados importados executando o código de importação padrão gerado usando a opção Executar
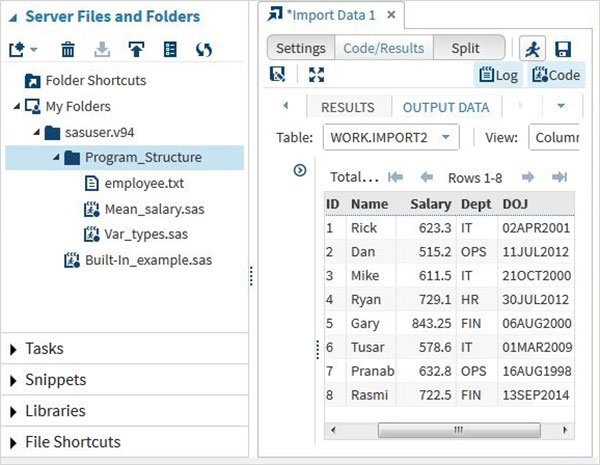
Podemos importar qualquer outro tipo de arquivo usando a mesma abordagem acima e usá-lo em vários programas SAS.
Em geral, as variáveis no SAS representam os nomes das colunas das tabelas de dados que está analisando. Mas também pode ser usado para outros fins, como usá-lo como contador em um loop de programação. No capítulo atual, veremos o uso de variáveis SAS como nomes de colunas do conjunto de dados SAS.
Tipos de variáveis SAS
O SAS tem três tipos de variáveis, conforme abaixo -
Variáveis Numéricas
Este é o tipo de variável padrão. Essas variáveis são usadas em expressões matemáticas.
Sintaxe
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.Na sintaxe acima, a instrução INPUT mostra a declaração de variáveis numéricas.
Exemplo
INPUT ID SALARY COMM_PERCENT;Variáveis de personagem
Variáveis de caracteres são usadas para valores que não são usados em expressões matemáticas. Eles são tratados como texto ou strings. Uma variável se torna uma variável de caractere adicionando um $ sing com um espaço no final do nome da variável.
Sintaxe
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.Na sintaxe acima, a instrução INPUT mostra a declaração de variáveis de caracteres.
Exemplo
INPUT FNAME $ LNAME $ ADDRESS $;Variáveis de Data
Essas variáveis são tratadas apenas como datas e precisam estar em formatos de data válidos. Uma variável se torna uma variável de data adicionando um formato de data com um espaço no final do nome da variável.
Sintaxe
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.Na sintaxe acima, a instrução INPUT mostra a declaração das variáveis de data.
Exemplo
INPUT DOB DATE11. START_DATE MMDDYY10. ;Uso de variáveis no programa SAS
As variáveis acima são usadas no programa SAS, conforme mostrado nos exemplos abaixo.
Exemplo
O código a seguir mostra como os três tipos de variáveis são declarados e usados em um programa SAS
DATA TEMP;
INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ;
FORMAT DOJ DATE9. ;
DATALINES;
1 Rick 623.3 IT 02APR2001
2 Dan 515.2 OPS 11JUL2012
3 Michelle 611 IT 21OCT2000
4 Ryan 729 HR 30JUL2012
5 Gary 843.25 FIN 06AUG2000
6 Tusar 578 IT 01MAR2009
7 Pranab 632.8 OPS 16AUG1998
8 Rasmi 722.5 FIN 13SEP2014
;
PROC PRINT DATA = TEMP;
RUN;No exemplo acima, todas as variáveis de caracteres são declaradas seguidas por um sinal $ e as variáveis de data são declaradas seguidas por um formato de data. A saída do programa acima é a seguinte.
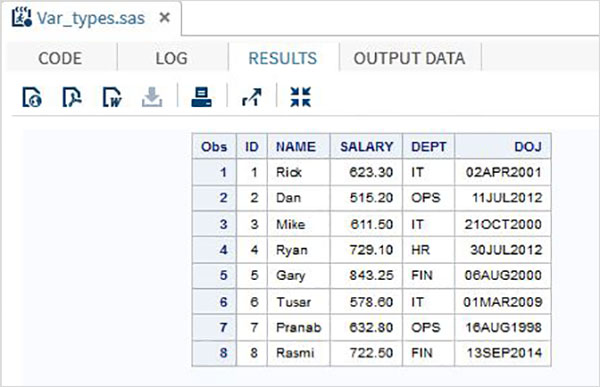
Usando as Variáveis
As variáveis são muito úteis na análise dos dados. Eles são usados em expressões nas quais a análise estatística é aplicada. Vejamos um exemplo de análise do conjunto de dados integrado denominadoCARS que está presente sob Libraries → My Libraries → SASHELP. Clique duas vezes nele para explorar as variáveis e seus tipos de dados.

A seguir, podemos produzir estatísticas resumidas de algumas dessas variáveis usando as opções de Tarefas no SAS Studio. Vamos paraTasks -> Statistics -> Summary Statisticse clique duas vezes nele para abrir a janela conforme mostrado abaixo. Escolha o conjunto de dadosSASHELP.CARSe selecione as três variáveis - MPG_CITY, MPG_Highway e Weight nas Variáveis de Análise. Segure a tecla Ctrl enquanto seleciona as variáveis clicando. Clique em executar.

Clique na guia de resultados após as etapas acima. Mostra o resumo estatístico das três variáveis escolhidas. A última coluna indica o número de observações (registros) usados na análise.
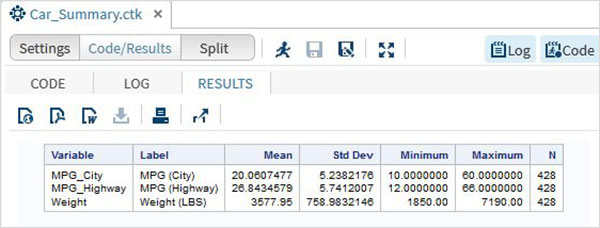
Strings no SAS são os valores colocados entre um par de aspas simples. Além disso, as variáveis de string são declaradas adicionando um espaço e o sinal $ no final da declaração da variável. SAS tem muitas funções poderosas para analisar e manipular strings.
Declarando Variáveis de String
Podemos declarar as variáveis de string e seus valores conforme mostrado abaixo. No código a seguir, declaramos duas variáveis de caracteres de comprimentos 6 e 5. A palavra-chave LENGTH é usada para declarar variáveis sem criar múltiplas observações.
data string_examples;
LENGTH string1 $ 6 String2 $ 5;
/*String variables of length 6 and 5 */
String1 = 'Hello';
String2 = 'World';
Joined_strings = String1 ||String2 ;
run;
proc print data = string_examples noobs;
run;Ao executar o código acima, obtemos a saída que mostra os nomes das variáveis e seus valores.
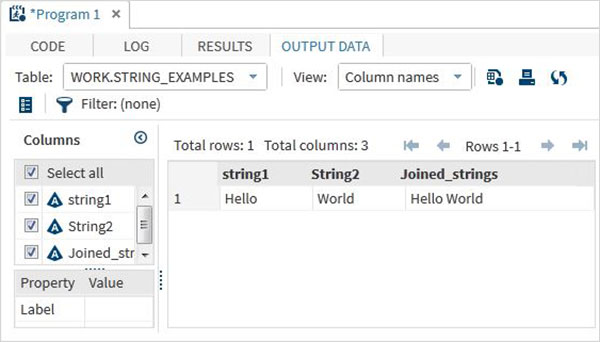
Funções de String
Abaixo estão os exemplos de algumas funções SAS que são usadas com frequência.
SUBSTRN
Esta função extrai uma substring usando as posições inicial e final. No caso de nenhuma posição final ser mencionada, ele extrai todos os caracteres até o final da string.
Sintaxe
SUBSTRN('stringval',p1,p2)A seguir está a descrição dos parâmetros usados -
- stringval é o valor da variável string.
- p1 é a posição inicial de extração.
- p2 é a posição final de extração.
Exemplo
data string_examples;
LENGTH string1 $ 6 ;
String1 = 'Hello';
sub_string1 = substrn(String1,2,4) ;
/*Extract from position 2 to 4 */
sub_string2 = substrn(String1,3) ;
/*Extract from position 3 onwards */
run;
proc print data = string_examples noobs;
run;Ao executar o código acima, obtemos a saída que mostra o resultado da função substrn.

TRIMN
Esta função remove o espaço à direita de uma string.
Sintaxe
TRIMN('stringval')A seguir está a descrição dos parâmetros usados -
- stringval é o valor da variável string.
data string_examples;
LENGTH string1 $ 7 ;
String1='Hello ';
length_string1 = lengthc(String1);
length_trimmed_string = lengthc(TRIMN(String1));
run;
proc print data = string_examples noobs;
run;Ao executar o código acima, obtemos a saída que mostra o resultado da função TRIMN.
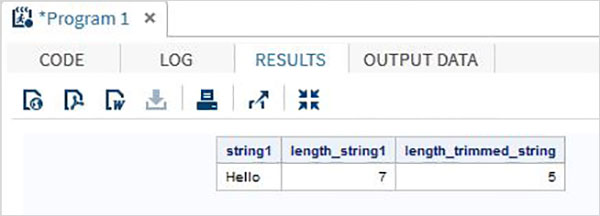
Matrizes no SAS são usadas para armazenar e recuperar uma série de valores usando um valor de índice. O índice representa a localização em uma área de memória reservada.
Sintaxe
No SAS, uma matriz é declarada usando a seguinte sintaxe -
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUESNa sintaxe acima -
ARRAY é a palavra-chave do SAS para declarar uma matriz.
ARRAY-NAME é o nome da matriz que segue a mesma regra dos nomes de variáveis.
SUBSCRIPT é o número de valores que a matriz irá armazenar.
($) é um parâmetro opcional a ser usado apenas se a matriz for armazenar valores de caracteres.
VARIABLE-LIST é a lista opcional de variáveis que ocupam o lugar dos valores da matriz.
ARRAY-VALUESsão os valores reais armazenados na matriz. Eles podem ser declarados aqui ou podem ser lidos de um arquivo ou dataline.
Exemplos de declaração de matriz
Os arrays podem ser declarados de várias maneiras usando a sintaxe acima. Abaixo estão os exemplos.
# Declare an array of length 5 named AGE with values.
ARRAY AGE[5] (12 18 5 62 44);
# Declare an array of length 5 named COUNTRIES with values starting at index 0.
ARRAY COUNTRIES(0:8) A B C D E F G H I;
# Declare an array of length 5 named QUESTS which contain character values.
ARRAY QUESTS(1:5) $ Q1-Q5;
# Declare an array of required length as per the number of values supplied.
ARRAY ANSWER(*) A1-A100;Acessando Valores de Matriz
Os valores armazenados em uma matriz podem ser acessados usando o printprocedimento conforme mostrado abaixo. Após serem declarados usando um dos métodos acima, os dados são fornecidos usando a instrução DATALINES.
DATA array_example;
INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5;
mix = a1||'+'||a2;
DATALINES;
yello pink orange green blue
;
RUN;
PROC PRINT DATA = array_example;
RUN;Quando executamos o código acima, ele produz o seguinte resultado -
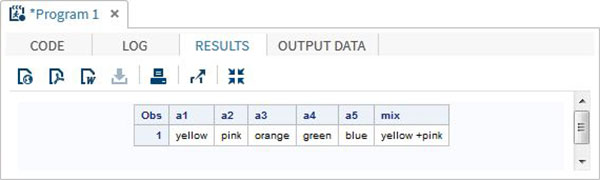
Usando o operador OF
O operador OF é usado ao analisar os dados que formam uma matriz para realizar cálculos em toda a linha de uma matriz. No exemplo abaixo, aplicamos a Soma e a Média dos valores em cada linha.
DATA array_example_OF;
INPUT A1 A2 A3 A4;
ARRAY A(4) A1-A4;
A_SUM = SUM(OF A(*));
A_MEAN = MEAN(OF A(*));
A_MIN = MIN(OF A(*));
DATALINES;
21 4 52 11
96 25 42 6
;
RUN;
PROC PRINT DATA = array_example_OF;
RUN;Quando executamos o código acima, ele produz o seguinte resultado -
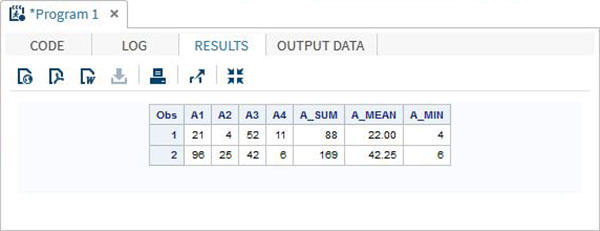
Usando o operador IN
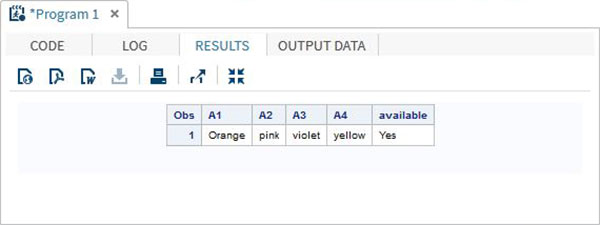
O valor em uma matriz também pode ser acessado usando o operador IN, que verifica a presença de um valor na linha da matriz. No exemplo abaixo verificamos a disponibilidade da cor "Amarelo" nos dados. Este valor diferencia maiúsculas de minúsculas.
DATA array_in_example;
INPUT A1 $ A2 $ A3 $ A4 $;
ARRAY COLOURS(4) A1-A4;
IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No';
DATALINES;
Orange pink violet yellow
;
RUN;
PROC PRINT DATA = array_in_example;
RUN;Quando executamos o código acima, ele produz o seguinte resultado -
O SAS pode lidar com uma ampla variedade de formatos de dados numéricos. Ele usa esses formatos no final dos nomes das variáveis para aplicar um formato numérico específico aos dados. SAS usa dois tipos de formatos numéricos. Um para ler formatos específicos dos dados numéricos que é chamadoinformat e outro para exibir os dados numéricos em formato específico chamado de output format.
Sintaxe
A sintaxe para uma informação numérica é -
Varname Formatnamew.dA seguir está a descrição dos parâmetros usados -
Varname é o nome da variável.
Formatname é o nome do nome do formato numérico aplicado à variável.
w é o número máximo de colunas de dados (incluindo dígitos após decimal e o próprio ponto decimal) permitido para ser armazenado para a variável.
d é o número de dígitos à direita do decimal.
Leitura de formatos numéricos
Abaixo está uma lista de formatos usados para ler os dados no SAS.
Formatos numéricos de entrada
| Formato | Usar |
|---|---|
| n. | Número máximo "n" de colunas sem casa decimal. |
| n.p | Número máximo "n" de colunas com casas decimais "p". |
| COMMAn.p | Número máximo de "n" colunas com casas decimais "p" que remove qualquer vírgula ou cifrão. |
| COMMAn.p | Número máximo de "n" colunas com casas decimais "p" que remove qualquer vírgula ou cifrão. |
Exibindo formatos numéricos
Semelhante à aplicação de formato durante a leitura dos dados, a seguir está uma lista de formatos usados para exibir os dados na saída de um programa SAS.
Formatos numéricos de saída
| Formato | Usar |
|---|---|
| n. | Escreva o número máximo "n" de dígitos sem casa decimal. |
| n.p | Escreva o número máximo "np" de colunas com casas decimais "p". |
| DOLLARn.p | Escreva o número máximo "n" de colunas com p casas decimais, o cifrão à esquerda e uma vírgula na milésima casa. |
Observe -
Se o número de dígitos após o ponto decimal for menor que o especificador de formato, entãozeros will be appended no fim.
Se o número de dígitos após o ponto decimal for maior que o especificador de formato, o último dígito será rounded off.
Exemplos
Os exemplos abaixo ilustram os cenários acima.
DATA MYDATA1;
input x 6.; /*maxiiuum width of the data*/
format x 6.3;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA1;
RUN;
DATA MYDATA2;
input x 6.; /*maximum width of the data*/
format x 5.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA2;
RUN;
DATA MYDATA3;
input x 6.; /*maximum width of the data*/
format x DOLLAR10.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA3;
RUN;Quando executamos o código acima, ele produz o seguinte resultado -
# MYDATA1.
Obs x
1 8722.0 # Display 6 columns with zero appended after decimal.
2 93.200 # Display 6 columns with zero appended after decimal.
3 0.112 # No integers before decimal, so display 3 available digits after decimal.
4 15.116 # Display 6 columns with 3 available digits after decimal.
# MYDATA2
Obs x
1 8722 # Display 5 columns. Only 4 are available.
2 93.20 # Display 5 columns with zero appended after decimal.
3 0.11 # Display 5 columns with 2 places after decimal.
4 15.12 # Display 5 columns with 2 places after decimal.
# MYDATA3
Obs x
1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal.
2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal.
4 $15.12 # Only 2 integers available before decimal and two available after the decimal.Um operador no SAS é um símbolo que é usado em uma expressão matemática, lógica ou de comparação. Esses símbolos são integrados à linguagem SAS e muitos operadores podem ser combinados em uma única expressão para fornecer uma saída final.
Abaixo está uma lista de categorias de operadoras SAS.
- Operadores aritméticos
- Operadores lógicos
- Operadores de comparação
- Operadores mínimos / máximos
- Operador de concatenação
Veremos cada um um por um. Os operadores são sempre usados com variáveis que fazem parte dos dados que estão sendo analisados pelo programa SAS.
Operadores aritméticos
A tabela abaixo descreve os detalhes dos operadores aritméticos. Vamos supor duas variáveis de dadosV1 e V2com valores 8 e 4 respectivamente.
| Operador | Descrição | Exemplo |
|---|---|---|
| + | Adição | V1 + V2 = 12 |
| - | Subtração | V1-V2 = 4 |
| * | Multiplicação | V1 * V2 = 32 |
| / | Divisão | V1 / V2 = 2 |
| ** | Exponenciação | V1 ** V2 = 4096 |
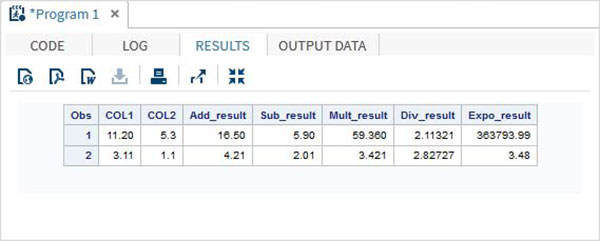
Exemplo
DATA MYDATA1;
input @1 COL1 4.2 @7 COL2 3.1;
Add_result = COL1+COL2;
Sub_result = COL1-COL2;
Mult_result = COL1*COL2;
Div_result = COL1/COL2;
Expo_result = COL1**COL2;
datalines;
11.21 5.3
3.11 11
;
PROC PRINT DATA = MYDATA1;
RUN;Ao executar o código acima, obtemos a seguinte saída.
Operadores lógicos
A tabela abaixo descreve os detalhes dos operadores lógicos. Esses operadores avaliam o valor Truth de uma expressão. Portanto, o resultado dos operadores lógicos é sempre 1 ou 0. Vamos assumir duas variáveis de dadosV1 e V2com valores 8 e 4 respectivamente.
| Operador | Descrição | Exemplo |
|---|---|---|
| E | O operador AND. Se ambos os valores de dados forem avaliados como verdadeiros, o resultado será 1, caso contrário, será 0. | (V1> 2 e V2> 3) dá 0. |
| | | O operador OR. Se qualquer um dos valores de dados for avaliado como verdadeiro, o resultado será 1, caso contrário, será 0. | (V1> 9 e V2> 3) é 1. |
| ~ | O operador NOT. O resultado do operador NOT na forma de uma expressão cujo valor é FALSE ou um valor ausente é 1, caso contrário, é 0. | NÃO (V1> 3) é 1. |
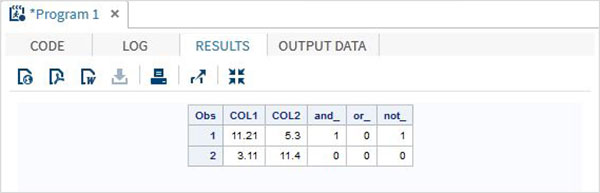
Exemplo
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
and_=(COL1 > 10 & COL2 > 5 );
or_ = (COL1 > 12 | COL2 > 15 );
not_ = ~( COL2 > 7 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Ao executar o código acima, obtemos a seguinte saída.
Operadores de comparação
A tabela abaixo descreve os detalhes dos operadores de comparação. Esses operadores comparam os valores das variáveis e o resultado é um valor verdade apresentado por 1 para TRUE e 0 para False. Vamos supor duas variáveis de dadosV1 e V2com valores 8 e 4 respectivamente.
| Operador | Descrição | Exemplo |
|---|---|---|
| = | O operador EQUAL. Se ambos os valores dos dados forem iguais, o resultado será 1, caso contrário, será 0. | (V1 = 8) dá 1. |
| ^ = | O operador NOT EQUAL. Se ambos os valores de dados forem desiguais, o resultado será 1, caso contrário, será 0. | (V1 ^ = V2) dá 1. |
| < | O MENOS QUE O operador. | (V2 <V2) dá 1. |
| <= | MENOS OU IGUAL AO Operador. | (V2 <= 4) dá 1. |
| > | O MAIOR DO QUE O operador. | (V2> V1) dá 1. |
| > = | O MAIOR DO QUE OU IGUAL AO Operador. | (V2> = V1) dá 0. |
| DENTRO | O operador IN. Se o valor da variável for igual a qualquer um dos valores em uma determinada lista de valores, ela retorna 1, caso contrário, retorna 0. | V1 em (5,7,9,8) dá 1. |
Exemplo
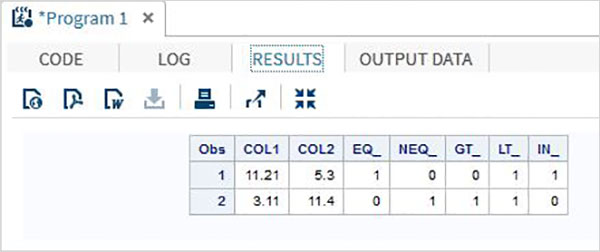
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
EQ_ = (COL1 = 11.21);
NEQ_= (COL1 ^= 11.21);
GT_ = (COL2 => 8);
LT_ = (COL2 <= 12);
IN_ = COL2 in( 6.2,5.3,12 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Ao executar o código acima, obtemos a seguinte saída.
Operadores mínimos / máximos
A tabela abaixo descreve os detalhes dos operadores Mínimo / Máximo. Esses operadores comparam os valores das variáveis em uma linha e o valor mínimo ou máximo da lista de valores nas linhas é retornado.
| Operador | Descrição | Exemplo |
|---|---|---|
| MIN | O operador MIN. Ele retorna o valor mínimo da lista de valores na linha. | MIN (45,2,11,6,15,41) dá 11,6 |
| MAX | O operador MAX. Ele retorna o valor máximo da lista de valores na linha. | MAX (45,2,11,6,15,41) dá 45,2 |
Exemplo
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3;
min_ = MIN(COL1 , COL2 , COL3);
max_ = MAX( COL1, COl2 , COL3);
datalines;
11.21 5.3 29.012
3.11 11.4 18.512
;
PROC PRINT DATA = MYDATA1;
RUN;Ao executar o código acima, obtemos a seguinte saída.
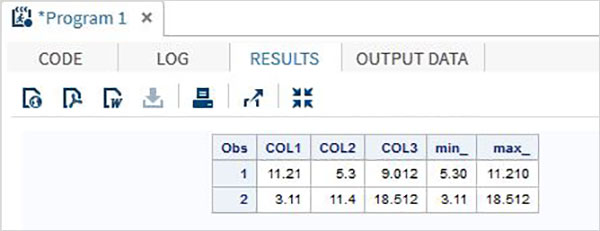
Operador de concatenação
A tabela abaixo descreve os detalhes do operador Concatenação. Este operador concatena dois ou mais valores de string. Um único valor de caractere é retornado.
| Operador | Descrição | Exemplo |
|---|---|---|
| || | O operador concatenar. Ele retorna a concatenação de dois ou mais valores. | 'Olá' || ' World 'dá Hello World |
Exemplo
DATA MYDATA1;
input COL1 $ COL2 $ COL3 $;
concat_ = (COL1 || COL2 || COL3);
datalines;
Tutorial s point
simple easy learning
;
PROC PRINT DATA = MYDATA1;
RUN;Ao executar o código acima, obtemos a seguinte saída.
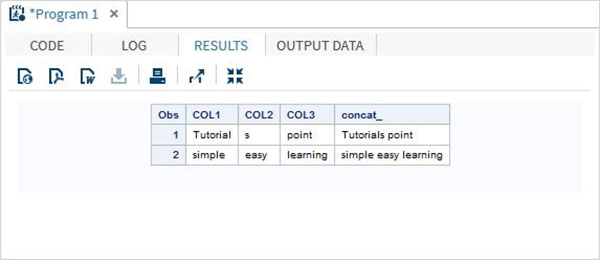
Precedência de operadores
A precedência do operador indica a ordem de avaliação dos vários operadores presentes na expressão complexa. A tabela abaixo descreve a ordem de precedência em um grupo de operadores.
| Grupo | Ordem | Símbolos |
|---|---|---|
| Grupo I | Direita para esquerda | ** + - NÃO MIN MÁX |
| Grupo II | Da esquerda para direita | * / |
| Grupo III | Da esquerda para direita | + - |
| Grupo IV | Da esquerda para direita | || |
| Grupo V | Da esquerda para direita | <<= => => |
Você pode encontrar situações em que um bloco de código precise ser executado várias vezes. Em geral, as instruções são executadas sequencialmente - a primeira instrução em uma função é executada primeiro, seguida pela segunda e assim por diante. Mas quando você deseja que o mesmo conjunto de instruções seja executado repetidamente, precisamos da ajuda de Loops.
No SAS, o loop é feito usando a instrução DO. Também é chamadoDO Loop. A seguir está a forma geral de instruções de loop DO no SAS.
Diagrama de fluxo

A seguir estão os tipos de loops DO no SAS.
| Sr. Não. | Tipo de Loop e Descrição |
|---|---|
| 1 | Índice DO. O loop continua do valor inicial até o valor final da variável de índice. |
| 2 | FAZER ENQUANTO. O loop continua até que a condição while se torne falsa. |
| 3 | FAÇA ATÉ. O loop continua até que a condição UNTIL se torne verdadeira. |
As estruturas de tomada de decisão requerem que o programador especifique uma ou mais condições a serem avaliadas ou testadas pelo programa, juntamente com uma instrução ou instruções a serem executadas se a condição for determinada como truee, opcionalmente, outras instruções a serem executadas se a condição for determinada como false.
A seguir está a forma geral de uma estrutura típica de tomada de decisão encontrada na maioria das linguagens de programação -
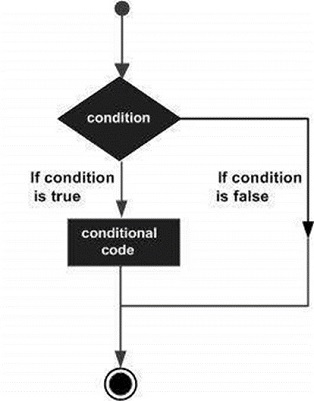
O SAS fornece os seguintes tipos de declarações de tomada de decisão. Clique nos links a seguir para verificar seus detalhes.
| Sr. Não. | Tipo e descrição da declaração |
|---|---|
| 1 | Declaração IF. A if statementconsiste em uma condição. Se a condição for verdadeira, os dados específicos são buscados. |
| 2 | Declaração IF-THEN-ELSE. A if statement seguida pela instrução else, que é executada quando a condição booleana é falsa. |
| 3 | Declaração IF-THEN-ELSE-IF. A if statement seguida pela instrução else, que é novamente seguida por outro par de instruções IF-THEN. |
| 4 | Instrução IF-THEN-DELETE. A if statement consiste em uma condição que, quando verdadeira, exclui os dados específicos das observações. |
SAS tem uma grande variedade de funções integradas que ajudam na análise e processamento dos dados. Essas funções são usadas como parte das instruções DATA. Eles pegam as variáveis de dados como argumentos e retornam o resultado que é armazenado em outra variável. Dependendo do tipo de função, o número de argumentos que leva pode variar. Algumas funções aceitam nenhum argumento, enquanto outras aceitam um número fixo de variáveis. Abaixo está uma lista de tipos de funções que o SAS oferece.
Sintaxe
A sintaxe geral para usar uma função no SAS é a seguinte.
FUNCTIONNAME(argument1, argument2...argumentn)Aqui, o argumento pode ser uma constante, variável, expressão ou outra função.
Categorias de Função
Dependendo de seu uso, as funções no SAS são categorizadas conforme abaixo.
- Mathematical
- Data e hora
- Character
- Truncation
- Miscellaneous
Funções Matemáticas
Estas são as funções usadas para aplicar alguns cálculos matemáticos aos valores das variáveis.
Exemplos
O programa SAS abaixo mostra o uso de algumas funções matemáticas importantes.
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29;
/* Get Maximum value */
max_val = MAX(v1,v2,v3,v4,v5);
/* Get Minimum value */
min_val = MIN (v1,v2,v3,v4,v5);
/* Get Median value */
med_val = MEDIAN (v1,v2,v3,v4,v5);
/* Get a random number */
rand_val = RANUNI(0);
/* Get Square root of sum of the values */
SR_val= SQRT(sum(v1,v2,v3,v4,v5));
proc print data = Math_functions noobs;
run;Quando o código acima é executado, obtemos a seguinte saída -
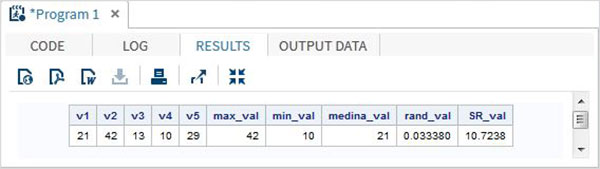
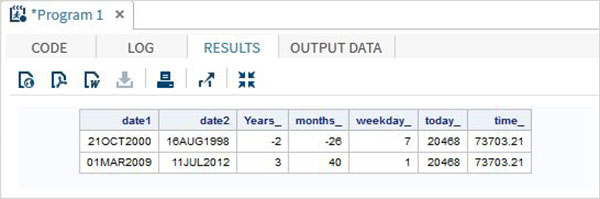
Funções de data e hora
Estas são as funções usadas para processar os valores de data e hora.
Exemplos
O programa SAS abaixo mostra o uso das funções de data e hora.
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;Quando o código acima é executado, obtemos a seguinte saída -
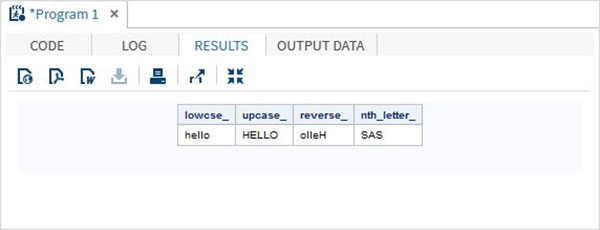
Funções de personagem
Estas são as funções usadas para processar valores de caracteres ou texto.
Exemplos
O programa SAS abaixo mostra o uso de funções de caracteres.
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;Quando o código acima é executado, obtemos a seguinte saída -
Funções de truncamento
Essas são as funções usadas para truncar valores numéricos.
Exemplos
O programa SAS abaixo mostra o uso de funções de truncamento.
data trunc_functions;
/* Nearest greatest integer */
ceil_ = CEIL(11.85);
/* Nearest greatest integer */
floor_ = FLOOR(11.85);
/* Integer portion of a number */
int_ = INT(32.41);
/* Round off to nearest value */
round_ = ROUND(5621.78);
run;
proc print data = trunc_functions noobs;
run;Quando o código acima é executado, obtemos a seguinte saída -

Funções Diversas
Vamos agora entender as funções diversas do SAS com alguns exemplos.
Exemplos
O programa SAS abaixo mostra o uso de funções diversas.
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;Quando o código acima é executado, obtemos a seguinte saída -

Os métodos de entrada são usados para ler os dados brutos. Os dados brutos podem ser de uma fonte externa ou de linhas de dados in stream. A instrução de entrada cria uma variável com o nome que você atribui a cada campo. Portanto, você deve criar uma variável na declaração de entrada. A mesma variável será mostrada na saída do SAS Dataset. Abaixo estão os diferentes métodos de entrada disponíveis no SAS.
- Método de entrada da lista
- Método de entrada nomeado
- Método de entrada de coluna
- Método de entrada formatado
Os detalhes de cada método de entrada são descritos a seguir.
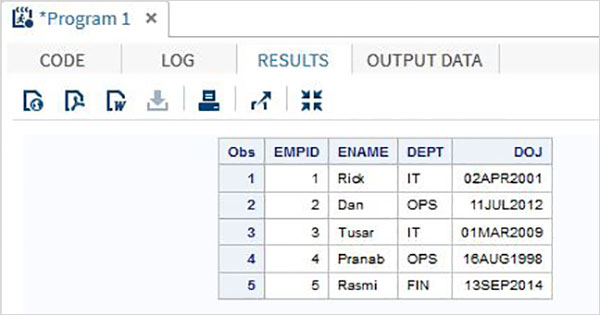
Método de entrada da lista
Neste método, as variáveis são listadas com os tipos de dados. Os dados brutos são analisados cuidadosamente para que a ordem das variáveis declaradas corresponda aos dados. O delimitador (geralmente espaço) deve ser uniforme entre qualquer par de colunas adjacentes. Quaisquer dados ausentes causarão problemas na saída, pois o resultado estará errado.
Exemplo
O código a seguir e a saída mostram o uso do método de entrada de lista.
DATA TEMP;
INPUT EMPID ENAME $ DEPT $ ;
DATALINES;
1 Rick IT
2 Dan OPS
3 Tusar IT
4 Pranab OPS
5 Rasmi FIN
;
PROC PRINT DATA = TEMP;
RUN;Ao executar o código bove, obtemos a seguinte saída.
Método de entrada nomeado
Neste método, as variáveis são listadas com os tipos de dados. Os dados brutos são modificados para que os nomes das variáveis sejam declarados antes dos dados correspondentes. O delimitador (geralmente espaço) deve ser uniforme entre qualquer par de colunas adjacentes.
Exemplo
O código a seguir e a saída mostram o uso do Método de entrada nomeada.
DATA TEMP;
INPUT
EMPID= ENAME= $ DEPT= $ ;
DATALINES;
EMPID = 1 ENAME = Rick DEPT = IT
EMPID = 2 ENAME = Dan DEPT = OPS
EMPID = 3 ENAME = Tusar DEPT = IT
EMPID = 4 ENAME = Pranab DEPT = OPS
EMPID = 5 ENAME = Rasmi DEPT = FIN
;
PROC PRINT DATA = TEMP;
RUN;Ao executar o código bove, obtemos a seguinte saída.
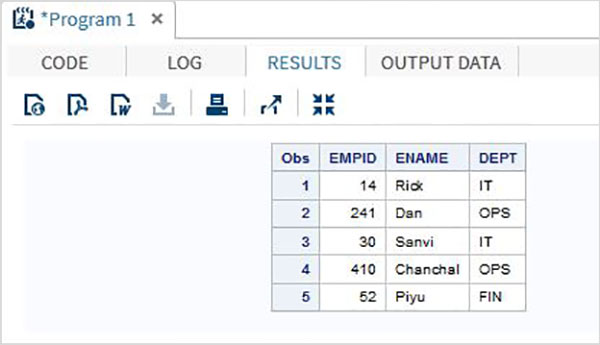
Método de entrada de coluna
Neste método, as variáveis são listadas com os tipos de dados e largura das colunas que especificam o valor de uma única coluna de dados. Por exemplo, se o nome de um funcionário contiver no máximo 9 caracteres e cada nome de funcionário começar na 10ª coluna, a largura da coluna para a variável do nome do funcionário será 10-19.
Exemplo
O código a seguir mostra o uso do Método de entrada de coluna.
DATA TEMP;
INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16;
DATALINES;
14 Rick IT
241Dan OPS
30 Sanvi IT
410Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Quando executamos o código acima, ele produz o seguinte resultado -
Método de entrada formatado
Neste método, as variáveis são lidas de um ponto de partida fixo até que um espaço seja encontrado. Como toda variável tem um ponto de partida fixo, o número de colunas entre qualquer par de variáveis torna-se a largura da primeira variável. O caractere '@n' é usado para especificar a posição inicial da coluna de uma variável como a enésima coluna.
Exemplo
O código a seguir mostra o uso do Método de entrada formatado
DATA TEMP;
INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ;
DATALINES;
14 Rick IT
241 Dan OPS
30 Sanvi IT
410 Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Quando executamos o código acima, ele produz o seguinte resultado -
SAS tem um poderoso recurso de programação chamado Macroso que nos permite evitar seções repetitivas de código e usá-las novamente e novamente quando necessário. Também ajuda a criar variáveis dinâmicas dentro do código que podem assumir valores diferentes para diferentes instâncias de execução do mesmo código. As macros também podem ser declaradas para blocos de código que serão reutilizados várias vezes de maneira semelhante às variáveis de macro. Veremos ambos nos exemplos abaixo.
Variáveis macro
Essas são as variáveis que contêm um valor a ser usado repetidamente por um programa SAS. Eles são declarados no início de um programa SAS e chamados posteriormente no corpo do programa. Eles podem ser globais ou locais em escopo.
Variável macro global
Elas são chamadas de variáveis de macro globais porque podem ser acessadas por qualquer programa SAS disponível no ambiente SAS. Em geral, são as variáveis atribuídas pelo sistema que são acessadas por vários programas. Um exemplo geral é a data do sistema.
Exemplo
Abaixo está um exemplo da variável SAS chamada SYSDATE que representa a data do sistema. Considere um cenário para imprimir a data do sistema no título do relatório SAS todos os dias em que o relatório é gerado. O título mostrará a data e o dia atuais sem codificarmos nenhum valor para eles. Usamos o conjunto de dados SAS integrado denominado CARS, disponível na biblioteca SASHELP.
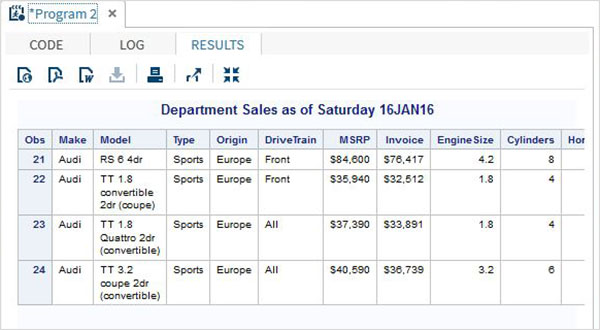
proc print data = sashelp.cars;
where make = 'Audi' and type = 'Sports' ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Quando o código acima é executado, obtemos a seguinte saída.
Variável macro local
Essas variáveis podem ser acessadas por programas SAS nos quais são declaradas como parte do programa. Eles são normalmente usados para fornecer variáveis diferentes às mesmas declarações SAS, de modo que podem processar diferentes observações de um conjunto de dados.
Sintaxe
As variáveis locais são decaladas com a sintaxe abaixo.
% LET (Macro Variable Name) = Value;Aqui, o campo Valor pode assumir qualquer valor numérico, texto ou data, conforme exigido pelo programa. O nome da variável Macro é qualquer variável SAS válida.
Exemplo
As variáveis são usadas pelas declarações SAS usando o & caractere anexado no início do nome da variável. O programa abaixo nos mostra todas as observações da marca 'Audi' e do tipo 'Esportes'. Caso queiramos o resultado dedifferent make, precisamos mudar o valor da variável make_namesem alterar qualquer outra parte do programa. No caso de programas trazer, essa variável pode ser referenciada repetidamente em quaisquer instruções SAS.
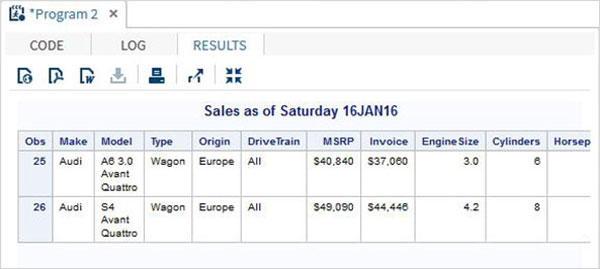
%LET make_name = 'Audi';
%LET type_name = 'Sports';
proc print data = sashelp.cars;
where make = &make_name and type = &type_name ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Quando o código acima é executado, obtemos a mesma saída do programa anterior. Mas vamos mudar otype name para 'Wagon'e execute o mesmo programa. Iremos obter o resultado abaixo.
Programas Macro
Macro é um grupo de instruções SAS que é referido por um nome e para usá-lo no programa em qualquer lugar, usando esse nome. Ele começa com uma instrução% MACRO e termina com a instrução% MEND.
Sintaxe
As variáveis locais são declaradas com a sintaxe abaixo.
# Creating a Macro program.
%MACRO <macro name>(Param1, Param2,….Paramn);
Macro Statements;
%MEND;
# Calling a Macro program.
%MacroName (Value1, Value2,…..Valuen);Exemplo
O programa abaixo decalifica um grupo de membros do SAT sob uma macro chamada 'show_result'; Esta macro está sendo chamada por outras instruções SAS.
%MACRO show_result(make_ , type_);
proc print data = sashelp.cars;
where make = "&make_" and type = "&type_" ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;
%MEND;
%show_result(BMW,SUV);Quando o código acima é executado, obtemos a seguinte saída.

Macros comumente usados
SAS tem muitas instruções MACRO que são embutidas na linguagem de programação SAS. Eles são usados por outros programas SAS sem declará-los explicitamente. Os exemplos comuns são - encerrar um programa quando alguma condição for atendida ou capturar o valor de tempo de execução de uma variável no log do programa. Abaixo estão alguns exemplos.
Macro% PUT
Esta instrução de macro grava informações de texto ou variável de macro no log do SAS. No exemplo abaixo, o valor da variável 'hoje' é escrito no log do programa.
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;Quando o código acima é executado, obtemos a seguinte saída.

Macro% RETURN
A execução desta macro causa o encerramento normal da macro atualmente em execução quando certa condição é avaliada como verdadeira. No exemplo a seguir, quando o valor da variável"val" torna-se 10, a macro termina, caso contrário, continua.
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;Quando o código acima é executado, obtemos a seguinte saída.

Macro% END
Esta definição de macro contém um %DO %WHILEloop que termina, conforme necessário, com uma instrução% END. No exemplo a seguir, a macro chamada test obtém uma entrada do usuário e executa o loop DO usando este valor de entrada. O fim do loop DO é alcançado por meio da instrução% end, enquanto o fim da macro é alcançado por meio da instrução% mend.
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)Quando o código acima é executado, obtemos a seguinte saída.

As datas do IN SAS são um caso especial de valores numéricos. Cada dia é atribuído um valor numérico específico a partir de 1º de janeiro de 1960. A esta data é atribuído o valor de data 0 e a próxima data tem um valor de data de 1 e assim por diante. Os dias anteriores a esta data são representados por -1, -2 e assim por diante. Com esta abordagem, o SAS pode representar qualquer data no futuro e qualquer data no passado.
Quando o SAS lê os dados de uma fonte, ele converte os dados lidos em um formato de data específico conforme especificado no formato de data. A variável para armazenar o valor da data é declarada com as informações adequadas necessárias. A data de saída é mostrada usando os formatos de dados de saída.
SAS Data Informat
Os dados de origem podem ser lidos corretamente usando informações de datas específicas conforme mostrado abaixo. O dígito no final da informação indica a largura mínima da string de data a ser lida completamente usando a informação. Uma largura menor dará resultado incorreto. com SAS V9, existe um formato de data genéricoanydtdte15. que pode processar qualquer entrada de data.
| Data de entrada | Largura da data | Informat |
|---|---|---|
| 11/03/2014 | 10 | mmddyy10. |
| 11/03/14 | 8 | mmddyy8. |
| 11 de dezembro de 2012 | 20 | worddate20. |
| 14mar2011 | 9 | data9. |
| 14-mar-2011 | 11 | date11. |
| 14-mar-2011 | 15 | anydtdte15. |
Exemplo
O código abaixo mostra a leitura de diferentes formatos de data. Observe que todos os valores de saída são apenas números, pois não aplicamos nenhuma instrução de formato aos valores de saída.
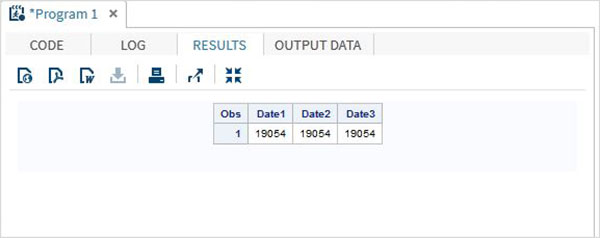
DATA TEMP;
INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ;
DATALINES;
02-mar-2012 3/02/2012 3/02/2012
;
PROC PRINT DATA = TEMP;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Formato de saída de data SAS
As datas, depois de lidas, podem ser convertidas para outro formato conforme exigido pelo display. Isso é obtido usando a instrução de formato para os tipos de data. Eles assumem os mesmos formatos das informações.
Exemplo
No exemplo a seguir, a data é lida em um formato, mas exibida em outro formato.
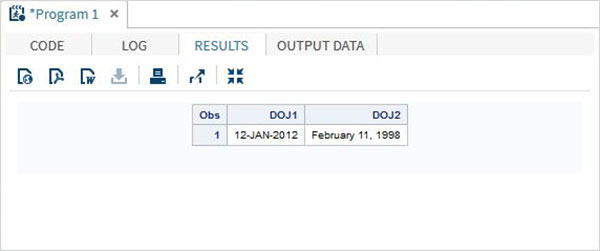
DATA TEMP;
INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.;
format DOJ1 date11. DOJ2 worddate20. ;
DATALINES;
01/12/2012 02/11/1998
;
PROC PRINT DATA = TEMP;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
O SAS pode ler dados de várias fontes, incluindo muitos formatos de arquivo. Os formatos de arquivo usados no ambiente SAS são discutidos abaixo.
- Conjunto de dados ASCII (texto)
- Dados Delimitados
- Dados Excel
- Dados Hierárquicos
Leitura do conjunto de dados ASCII (texto)
Estes são os arquivos que contêm os dados em formato de texto. Os dados geralmente são delimitados por um espaço, mas também pode haver diferentes tipos de delimitadores que o SAS pode manipular. Vamos considerar um arquivo ASCII contendo os dados do funcionário. Lemos este arquivo usando oInfile declaração disponível no SAS.
Exemplo
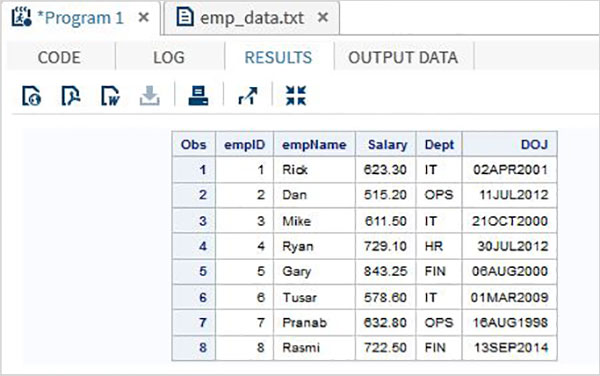
No exemplo abaixo, lemos o arquivo de dados denominado emp_data.txt do ambiente local.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Lendo Dados Delimitados
Estes são os arquivos de dados nos quais os valores da coluna são separados por um caractere delimitador, como uma vírgula ou pipeline, etc. Neste caso, usamos o dlm opção no infile declaração.
Exemplo
No exemplo a seguir, lemos o arquivo de dados denominado emp.csv do ambiente local.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Leitura de dados do Excel
O SAS pode ler diretamente um arquivo Excel usando o recurso de importação. Conforme visto no capítulo conjuntos de dados SAS, ele pode lidar com uma ampla variedade de tipos de arquivos, incluindo MS Excel. Supondo que o arquivo emp.xls esteja disponível localmente no ambiente SAS.
Exemplo
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;O código acima lê os dados do arquivo Excel e fornece a mesma saída dos dois tipos de arquivo acima.
Lendo Arquivos Hierárquicos
Nestes arquivos, os dados estão presentes em formato hierárquico. Para uma dada observação, há um registro de cabeçalho abaixo do qual muitos registros de detalhes são mencionados. O número de registros de detalhes pode variar de uma observação para outra. Abaixo está uma ilustração de um arquivo hierárquico.
No arquivo abaixo, estão listados os detalhes de cada funcionário de cada departamento. O primeiro registro é o registro de cabeçalho mencionando o departamento e o próximo registro alguns registros começando com DTLS são o registro de detalhes.
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452Exemplo
Para ler o arquivo hierárquico, usamos o código abaixo, no qual identificamos o registro de cabeçalho com uma cláusula IF e usamos um loop do para processar o registro de detalhes.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @; if Type = 'DEP' then input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;Quando o código acima é executado, obtemos a seguinte saída.

Semelhante à leitura de conjuntos de dados, o SAS pode gravar conjuntos de dados em diferentes formatos. Ele pode gravar dados de arquivos SAS em arquivo de texto normal. Esses arquivos podem ser lidos por outros programas de software. SAS usaPROC EXPORT para escrever conjuntos de dados.
PROC EXPORT
É um procedimento embutido no SAS usado para exportar os conjuntos de dados SAS para gravar os dados em arquivos de diferentes formatos.
Sintaxe
A sintaxe básica para escrever o procedimento no SAS é -
PROC EXPORT
DATA = libref.SAS data-set (SAS data-set-options)
OUTFILE = "filename"
DBMS = identifier LABEL(REPLACE);A seguir está a descrição dos parâmetros usados -
SAS data-seté o nome do conjunto de dados que está sendo exportado. O SAS pode compartilhar os conjuntos de dados de seu ambiente com outros aplicativos, criando arquivos que podem ser lidos por diferentes sistemas operacionais. Ele usa a função EXPORT embutida para enviar os arquivos do conjunto de dados em uma variedade de formatos. Neste capítulo, veremos a gravação de conjuntos de dados SAS usandoproc export junto com as opções dlm e dbms.
SAS data-set-options é usado para especificar um subconjunto de colunas a serem exportadas.
filename é o nome do arquivo no qual os dados são gravados.
identifier é usado para mencionar o delimitador que será gravado no arquivo.
LABEL opção é usada para mencionar o nome das variáveis gravadas no arquivo.
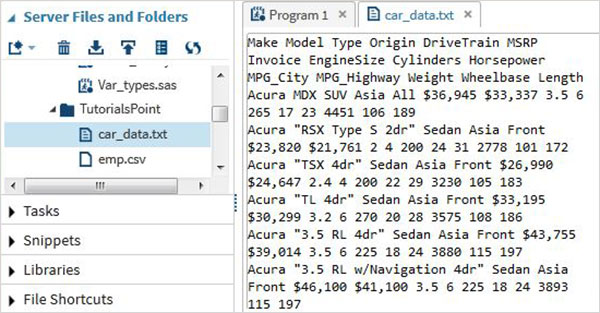
Exemplo
Usaremos o conjunto de dados SAS denominado cars disponíveis na biblioteca SASHELP. Nós o exportamos como um arquivo de texto delimitado por espaço com o código mostrado no programa a seguir.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt'
dbms = dlm;
delimiter = ' ';
run;Ao executar o código acima, podemos ver a saída como um arquivo de texto e clicar com o botão direito do mouse para ver seu conteúdo conforme mostrado abaixo.
Gravando um arquivo CSV
Para escrever um arquivo delimitado por vírgulas, podemos usar a opção dlm com um valor "csv". O código a seguir grava o arquivo car_data.csv.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv'
dbms = csv;
run;Ao executar o código acima, obtemos a saída abaixo.

Gravando um arquivo delimitado por tabulação
Para escrever um arquivo delimitado por tabulação, podemos usar o dlmopção com um valor "tab". O código a seguir grava o arquivocar_tab.txt.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt'
dbms = csv;
run;Os dados também podem ser gravados como arquivo HTML, que veremos no capítulo do sistema de entrega de saída.
Vários conjuntos de dados SAS podem ser concatenados para fornecer um único conjunto de dados usando o SETdeclaração. O número total de observações no conjunto de dados concatenados é a soma do número de observações nos conjuntos de dados originais. A ordem das observações é sequencial. Todas as observações do primeiro conjunto de dados são seguidas por todas as observações do segundo conjunto de dados e assim por diante.
Idealmente, todos os conjuntos de dados combinados têm as mesmas variáveis, mas no caso de terem um número diferente de variáveis, então no resultado todas as variáveis aparecem, com valores perdidos para o conjunto de dados menor.
Sintaxe
A sintaxe básica para a instrução SET no SAS é -
SET data-set 1 data-set 2 data-set 3.....;A seguir está a descrição dos parâmetros usados -
data-set1,data-set2 são nomes de conjuntos de dados escritos um após o outro.
Exemplo
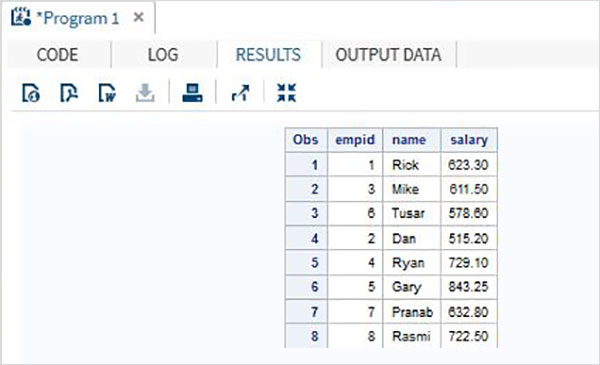
Considere os dados de funcionários de uma organização que estão disponíveis em dois conjuntos de dados diferentes, um para o departamento de TI e outro para o departamento não relacionado à TI. Para obter os detalhes completos de todos os funcionários, concatenamos os dois conjuntos de dados usando a instrução SET mostrada abaixo.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Cenários
Quando temos muitas variações nos conjuntos de dados para concatenação, o resultado das variáveis pode ser diferente, mas o número total de observações no conjunto de dados concatenados é sempre a soma das observações em cada conjunto de dados. Consideraremos a seguir muitos cenários dessa variação.
Número diferente de variáveis
Se um dos conjuntos de dados originais tiver mais número de variáveis do que outro, os conjuntos de dados ainda serão combinados, mas no conjunto de dados menor essas variáveis aparecem como ausentes.
Exemplo
No exemplo a seguir, o primeiro conjunto de dados possui uma variável extra chamada DOJ. No resultado, o valor de DOJ para o segundo conjunto de dados aparecerá como ausente.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.

Nome de variável diferente
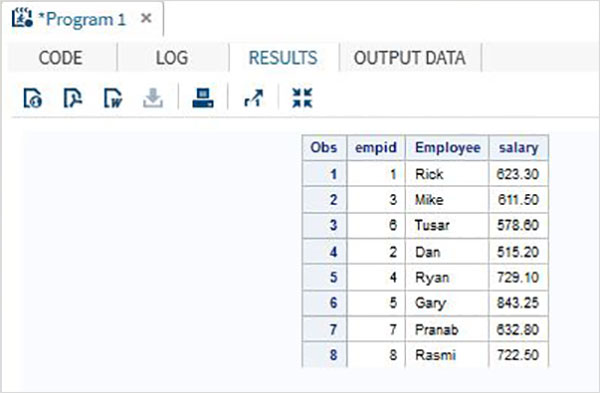
Neste cenário, os conjuntos de dados têm o mesmo número de variáveis, mas um nome de variável difere entre eles. Nesse caso, uma concatenação normal produzirá todas as variáveis no conjunto de resultados e dará resultados ausentes para as duas variáveis que diferem. Embora não possamos alterar o nome da variável nos conjuntos de dados originais, podemos aplicar a função RENAME no conjunto de dados concatenado que criamos. Isso produzirá o mesmo resultado de uma concatenação normal, mas é claro com um novo nome de variável no lugar de dois nomes de variáveis diferentes presentes no conjunto de dados original.
Exemplo
No exemplo a seguir, o conjunto de dados ITDEPT tem o nome da variável ename enquanto o conjunto de dados NON_ITDEPT tem o nome da variável empname.Mas ambas as variáveis representam o mesmo tipo (personagem). Nós aplicamos oRENAME função na instrução SET conforme mostrado abaixo.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Comprimentos variáveis diferentes
Se os comprimentos das variáveis nos dois conjuntos de dados forem diferentes, o conjunto de dados concatenados terá valores nos quais alguns dados serão truncados para a variável com comprimento menor. Isso acontece se o primeiro conjunto de dados tiver um comprimento menor. Para resolver isso, aplicamos o comprimento maior a ambos os conjuntos de dados, conforme mostrado abaixo.
Exemplo
No exemplo abaixo, a variável enametem comprimento 5 no primeiro conjunto de dados e 7 no segundo. Ao concatenar, aplicamos a instrução LENGTH no conjunto de dados concatenados para definir o comprimento do ename como 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
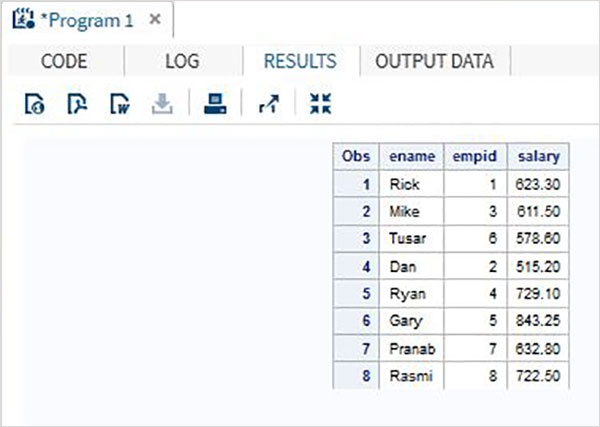
Vários conjuntos de dados SAS podem ser mesclados com base em uma variável comum específica para fornecer um único conjunto de dados. Isso é feito usando oMERGE declaração e BYdeclaração. O número total de observações no conjunto de dados mesclado é frequentemente menor que a soma do número de observações nos conjuntos de dados originais. É porque as variáveis de ambos os conjuntos de dados são mescladas como um registro com base quando há uma correspondência no valor da variável comum.
Existem dois pré-requisitos para mesclar conjuntos de dados fornecidos abaixo -
- os conjuntos de dados de entrada devem ter pelo menos uma variável comum para se fundir.
- os conjuntos de dados de entrada devem ser classificados pelas variáveis comuns que serão usadas para a fusão.
Sintaxe
A sintaxe básica para a instrução MERGE e BY no SAS é -
MERGE Data-Set 1 Data-Set 2
BY Common VariableA seguir está a descrição dos parâmetros usados -
Data-set1,Data-set2 são nomes de conjuntos de dados escritos um após o outro.
Common Variable é a variável baseada em cujos valores correspondentes os conjuntos de dados serão mesclados.
Mesclagem de dados
Vamos entender a fusão de dados com a ajuda de um exemplo.
Exemplo
Considere dois conjuntos de dados SAS, um contendo a ID do funcionário com nome e salário e outro contendo a ID do funcionário com ID do funcionário e departamento. Neste caso, para obter as informações completas de cada funcionário, podemos mesclar esses dois conjuntos de dados. O conjunto de dados final ainda terá uma observação por funcionário, mas conterá as variáveis de salário e departamento.
# Data set 1
ID NAME SALARY
1 Rick 623.3
2 Dan 515.2
3 Mike 611.5
4 Ryan 729.1
5 Gary 843.25
6 Tusar 578.6
7 Pranab 632.8
8 Rasmi 722.5
# Data set 2
ID DEPT
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
# Merged data set
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINO resultado acima é obtido usando o código a seguir, no qual a variável comum (ID) é usada na instrução BY. Observe que as observações em ambos os conjuntos de dados já estão classificadas na coluna ID.
DATA SALARY;
INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ;
DATALINES;
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
;
RUN;
DATA All_details;
MERGE SALARY DEPT;
BY (empid);
RUN;
PROC PRINT DATA = All_details;
RUN;Valores ausentes na coluna de correspondência
Pode haver casos em que alguns valores da variável comum não coincidam entre os conjuntos de dados. Em tais casos, os conjuntos de dados ainda são mesclados, mas fornecem valores ausentes no resultado.
Exemplo
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 . . IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 .
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINMesclando apenas as correspondências
Para evitar os valores perdidos no resultado, podemos considerar manter apenas as observações com valores correspondentes para a variável comum. Isso é conseguido usando oINdeclaração. A instrução de mesclagem do programa SAS precisa ser alterada.
Exemplo
No exemplo abaixo, o IN= valor mantém apenas as observações onde os valores de ambos os conjuntos de dados SALARY e DEPT partida.
DATA All_details;
MERGE SALARY(IN = a) DEPT(IN = b);
BY (empid);
IF a = 1 and b = 1;
RUN;
PROC PRINT DATA = All_details;
RUN;Após a execução do programa SAS acima com a parte alterada acima, obtemos a seguinte saída.
1 Rick 623.3 IT
2 Dan 515.2 OPS
4 Ryan 729.1 HR
5 Gary 843.25 FIN
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINSubconjunto de um conjunto de dados SAS significa extrair uma parte do conjunto de dados, selecionando menos número de variáveis ou menos número de observações ou ambos. Enquanto o subconjunto de variáveis é feito usandoKEEP e DROP declaração, a subconfiguração de observações é feita usando DELETE declaração.
Além disso, os dados resultantes da operação de subconjunto são mantidos em um novo conjunto de dados que pode ser usado para análise posterior. A configuração secundária é usada principalmente com o propósito de analisar uma parte do conjunto de dados sem usar as variáveis ou observações que podem não ser relevantes para a análise.
Subsetting Variables
Neste método, extraímos apenas algumas variáveis de todo o conjunto de dados.
Sintaxe
A sintaxe básica para variáveis de subconfiguração no SAS é -
KEEP var1 var2 ... ;
DROP var1 var2 ... ;A seguir está a descrição dos parâmetros usados -
var1 and var2 são os nomes das variáveis do conjunto de dados que precisam ser mantidos ou eliminados.
Exemplo
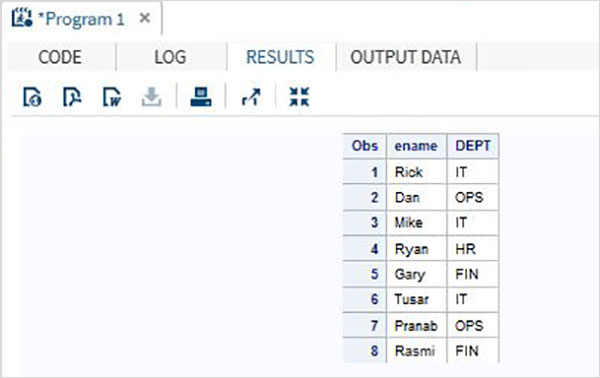
Considere o conjunto de dados SAS abaixo contendo os detalhes dos funcionários de uma organização. Se estivermos interessados apenas em obter os valores de Nome e Departamento do conjunto de dados, podemos usar o código abaixo.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
KEEP ename DEPT;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
O mesmo resultado pode ser obtido eliminando as variáveis que não são necessárias. O código a seguir ilustra isso.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
DROP empid salary;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Subsetting Observations
Neste método, extraímos apenas algumas observações de todo o conjunto de dados.
Sintaxe
Usamos PROC FREQ, que mantém o controle das observações selecionadas para o novo conjunto de dados.
A sintaxe para observações de subconfiguração é -
IF Var Condition THEN DELETE ;A seguir está a descrição dos parâmetros usados -
Var é o nome da variável com base em cujo valor as observações serão excluídas usando a condição especificada.
Exemplo
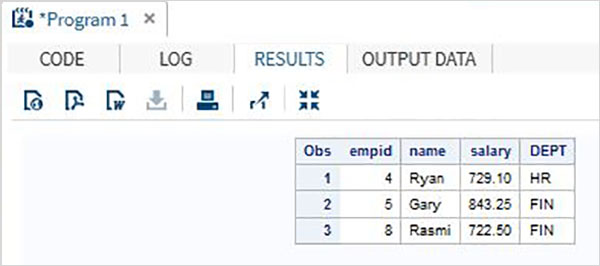
Considere o conjunto de dados SAS abaixo contendo os detalhes dos funcionários de uma organização. Se estivermos interessados apenas em obter os dados de funcionários com salário superior a 700, usamos o código abaixo.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
IF salary < 700 THEN DELETE;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
Às vezes, preferimos mostrar os dados analisados em um formato diferente do formato em que já estão presentes no conjunto de dados. Por exemplo, queremos adicionar o cifrão e duas casas decimais a uma variável que tem informações de preço. Ou podemos querer mostrar uma variável de texto, tudo em maiúsculas. Podemos usarFORMAT para aplicar os formatos SAS embutidos e PROC FORMATé aplicar formatos definidos pelo usuário. Além disso, um único formato pode ser aplicado a várias variáveis.
Sintaxe
A sintaxe básica para a aplicação de formatos SAS embutidos é -
format variable name format nameA seguir está a descrição dos parâmetros usados -
variable name é o nome da variável usado no conjunto de dados.
format name é o formato de dados a ser aplicado na variável.
Exemplo
Vamos considerar o conjunto de dados SAS abaixo contendo os detalhes dos funcionários de uma organização. Queremos mostrar todos os nomes em maiúsculas. oformatstatement é usado para conseguir isso.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
format name $upcase9. ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
PROC PRINT DATA = Employee;
RUN;Quando o código acima é executado, obtemos a seguinte saída.

Usando PROC FORMAT
Nós também podemos usar PROC FORMATpara formatar dados. No exemplo abaixo, atribuímos novos valores à variável DEPT, estendendo o nome do departamento.
DATA Employee;
INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; proc format; value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;Quando o código acima é executado, obtemos a seguinte saída.
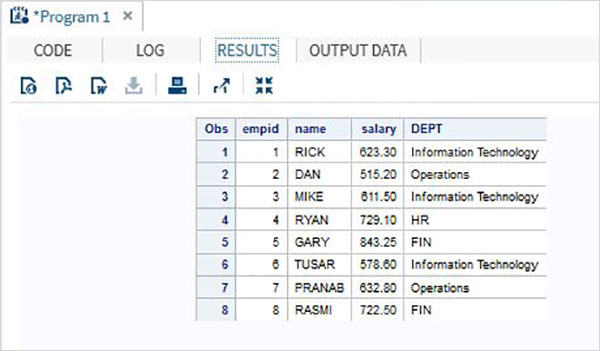
O SAS oferece amplo suporte para a maioria dos bancos de dados relacionais populares usando consultas SQL dentro de programas SAS. A maioria dosANSI SQLsintaxe é suportada. O procedimentoPROC SQLé usado para processar as instruções SQL. Este procedimento não pode apenas retornar o resultado de uma consulta SQL, mas também pode criar tabelas e variáveis SAS. O exemplo de todos esses cenários é descrito abaixo.
Sintaxe
A sintaxe básica para usar PROC SQL no SAS é -
PROC SQL;
SELECT Columns
FROM TABLE
WHERE Columns
GROUP BY Columns
;
QUIT;A seguir está a descrição dos parâmetros usados -
a consulta SQL é escrita abaixo da instrução PROC SQL seguida pela instrução QUIT.
Abaixo veremos como este procedimento SAS pode ser usado para o CRUD (Criar, Ler, Atualizar e Excluir) operações em SQL.
Operação SQL Create
Usando SQL, podemos criar novos conjuntos de dados de dados brutos. No exemplo abaixo, primeiro declaramos um conjunto de dados denominado TEMP contendo os dados brutos. Em seguida, escrevemos uma consulta SQL para criar uma tabela a partir das variáveis desse conjunto de dados.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES AS
SELECT * FROM TEMP;
QUIT;
PROC PRINT data = EMPLOYEES;
RUN;Quando o código acima é executado, obtemos o seguinte resultado -
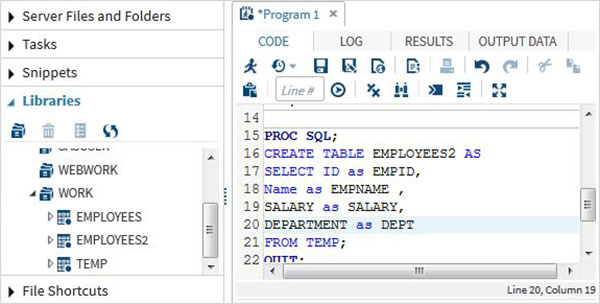
Operação de leitura SQL
A operação Read em SQL envolve a gravação de consultas SQL SELECT para ler os dados das tabelas. Em O programa a seguir consulta o conjunto de dados SAS denominado CARS disponível na biblioteca SASHELP. A consulta busca algumas das colunas do conjunto de dados.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
;
QUIT;Quando o código acima é executado, obtemos o seguinte resultado -
SQL SELECT com cláusula WHERE
O programa abaixo consulta o conjunto de dados CARS com um wherecláusula. No resultado, obtemos apenas a observação que temos como 'Audi' e tipo 'Esportes'.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
Where make = 'Audi'
and Type = 'Sports'
;
QUIT;Quando o código acima é executado, obtemos o seguinte resultado -
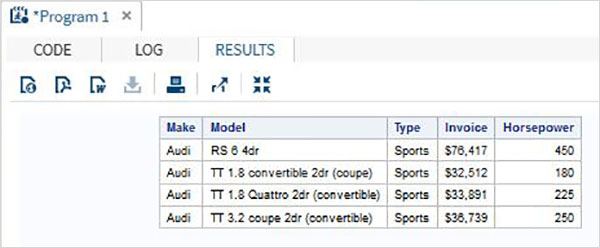
Operação SQL UPDATE
Podemos atualizar a tabela SAS usando a instrução SQL Update. A seguir, primeiro criamos uma nova tabela chamada EMPLOYEES2 e depois a atualizamos usando a instrução SQL UPDATE.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Quando o código acima é executado, obtemos o seguinte resultado -

Operação SQL DELETE
A operação de exclusão em SQL envolve a remoção de certos valores da tabela usando a instrução SQL DELETE. Continuamos a usar os dados do exemplo acima e excluímos as linhas da tabela em que o salário dos funcionários é maior que 900.
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Quando o código acima é executado, obtemos o seguinte resultado -

A saída de um programa SAS pode ser convertida em formas mais amigáveis ao usuário, como .html ou PDF. Isso é feito usando o ODSdeclaração disponível no SAS. ODS significaoutput delivery system.É usado principalmente para formatar os dados de saída de um programa SAS em relatórios agradáveis que são bons para olhar e entender. Isso também ajuda a compartilhar a saída com outras plataformas e softwares. Ele também pode combinar os resultados de várias instruções PROC em um único arquivo.
Sintaxe
A sintaxe básica para usar a instrução ODS no SAS é -
ODS outputtype
PATH path name
FILE = Filename and Path
STYLE = StyleName
;
PROC some proc
;
ODS outputtype CLOSE;A seguir está a descrição dos parâmetros usados -
PATHrepresenta a instrução usada no caso de saída HTML. Em outros tipos de saída, incluímos o caminho no nome do arquivo.
Style representa um dos estilos embutidos disponíveis no ambiente SAS.
Criação de saída HTML
Criamos a saída HTML usando a instrução ODS HTML. No exemplo a seguir, criamos um arquivo html em nosso caminho desejado. Aplicamos um estilo disponível na biblioteca de estilos. Podemos ver o arquivo de saída no caminho mencionado e podemos baixá-lo para salvar em um ambiente diferente do SAS. Observe que temos duas instruções SQL proc e ambas as saídas são capturadas em um único arquivo.
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;Quando o código acima é executado, obtemos o seguinte resultado -
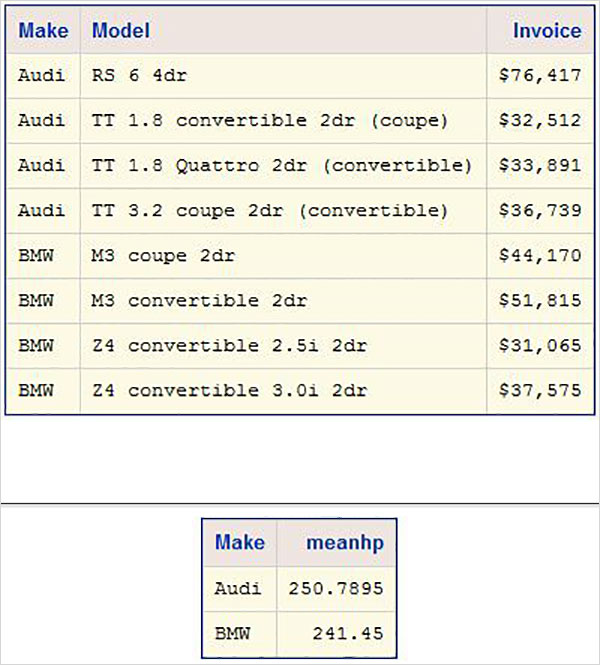
Criação de saída em PDF
No exemplo abaixo, criamos um arquivo PDF em nosso caminho desejado. Aplicamos um estilo disponível na biblioteca de estilos. Podemos ver o arquivo de saída no caminho mencionado e podemos baixá-lo para salvar em um ambiente diferente do SAS. Observe que temos duas instruções SQL proc e ambas as saídas são capturadas em um único arquivo.
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;Quando o código acima é executado, obtemos o seguinte resultado -
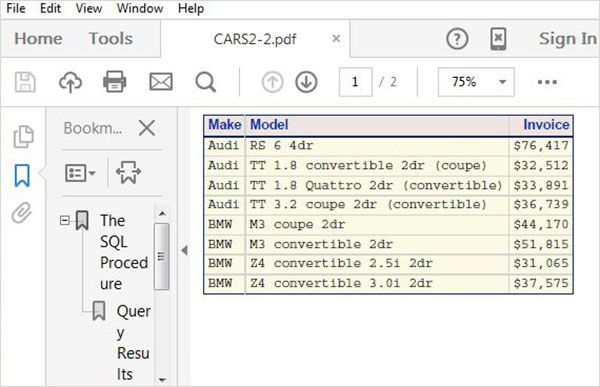
Criação de saída TRF (Word)
No exemplo abaixo, criamos um arquivo RTF em nosso caminho desejado. Aplicamos um estilo disponível na biblioteca de estilos. Podemos ver o arquivo de saída no caminho mencionado e podemos baixá-lo para salvar em um ambiente diferente do SAS. Observe que temos duas instruções SQL proc e ambas as saídas são capturadas em um único arquivo.
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;Quando o código acima é executado, obtemos o seguinte resultado -
Simulação é uma técnica computacional que usa computação repetida em muitas amostras aleatórias diferentes para estimar uma quantidade estatística. Usando o SAS, podemos simular dados complexos que possuem propriedades estatísticas especificadas no sistema do mundo real. Usamos software para construir um modelo do sistema e gerar numericamente os dados que podem ser usados para uma melhor compreensão do comportamento do sistema do mundo real. Parte da arte de projetar um modelo de simulação de computador é decidir quais aspectos do sistema da vida real são necessários para incluir no modelo para que os dados gerados pelo modelo possam ser usados para tomar decisões eficazes. Devido a essa complexidade, o SAS tem um componente de software dedicado para simulação.
O componente de software SAS que é usado na criação de simulação SAS é chamado SAS Simulation Studio. Sua interface gráfica de usuário fornece um conjunto completo de ferramentas para construir, executar e analisar os resultados de modelos de simulação de eventos discretos.
Diferentes tipos de distribuições estatísticas nas quais a simulação SAS pode ser aplicada estão listados abaixo.
- SIMULAR DADOS DE UMA DISTRIBUIÇÃO CONTÍNUA
- SIMULAR DADOS DE UMA DISTRIBUIÇÃO DISCRETA
- SIMULAR DADOS DE UMA MISTURA DE DISTRIBUIÇÕES
- SIMULAR DADOS DE UMA DISTRIBUIÇÃO COMPLEXA
- SIMULAR DADOS DE UMA DISTRIBUIÇÃO MULTIVARIADA
- APROXIMAR UMA DISTRIBUIÇÃO DE AMOSTRAGEM
- AVALIE AS ESTIMATIVAS DE REGRESSÃO
Um histograma é a exibição gráfica de dados usando barras de diferentes alturas. Ele agrupa os vários números no conjunto de dados em vários intervalos. Também representa a estimativa da probabilidade de distribuição de uma variável contínua. No SAS oPROC UNIVARIATE é usado para criar histogramas com as opções abaixo.
Sintaxe
A sintaxe básica para criar um histograma no SAS é -
PROC UNIVARAITE DATA = DATASET;
HISTOGRAM variables;
RUN;DATASET é o nome do conjunto de dados usado.
variables são os valores usados para traçar o histograma.
Histograma Simples
Um histograma simples é criado especificando o nome da variável e o intervalo a ser considerado para agrupar os valores.
Exemplo
No exemplo a seguir, consideramos os valores mínimo e máximo da variável de potência e tomamos um intervalo de 50. Portanto, os valores formam um grupo em etapas de 50.
proc univariate data = sashelp.cars;
histogram horsepower
/ midpoints = 176 to 350 by 50;
run;Quando executamos o código acima, obtemos a seguinte saída -
Histograma com ajuste de curva
Podemos ajustar algumas curvas de distribuição no histograma usando opções adicionais.
Exemplo
No exemplo abaixo, ajustamos uma curva de distribuição com valores de média e desvio padrão mencionados como EST. Esta opção usa e estima os parâmetros.
proc univariate data = sashelp.cars noprint;
histogram horsepower
/
normal (
mu = est
sigma = est
color = blue
w = 2.5
)
barlabel = percent
midpoints = 70 to 550 by 50;
run;Quando executamos o código acima, obtemos a seguinte saída -

Um gráfico de barras representa os dados em barras retangulares com comprimento da barra proporcional ao valor da variável. SAS usa o procedimentoPROC SGPLOTpara criar gráficos de barras. Podemos desenhar tanto barras simples quanto barras empilhadas no gráfico de barras. No gráfico de barras, cada uma das barras pode receber cores diferentes.
Sintaxe
A sintaxe básica para criar um gráfico de barras no SAS é -
PROC SGPLOT DATA = DATASET;
VBAR variables;
RUN;DATASET - é o nome do conjunto de dados usado.
variables - são os valores usados para traçar o histograma.
Gráfico de barras simples
Um gráfico de barras simples é um gráfico de barras no qual uma variável do conjunto de dados é representada como barras.
Exemplo
O script a seguir criará um gráfico de barras representando o comprimento dos carros como barras.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;Quando executamos o código acima, obtemos a seguinte saída -
Gráfico de barras empilhadas
Um gráfico de barras empilhadas é um gráfico de barras no qual uma variável do conjunto de dados é calculada em relação a outra variável.
Exemplo
O script a seguir criará um gráfico de barras empilhadas onde o comprimento dos carros é calculado para cada tipo de carro. Usamos a opção de grupo para especificar a segunda variável.
proc SGPLOT data = work.cars1;
vbar length /group = type ;
title 'Lengths of Cars by Types';
run;
quit;Quando executamos o código acima, obtemos a seguinte saída -
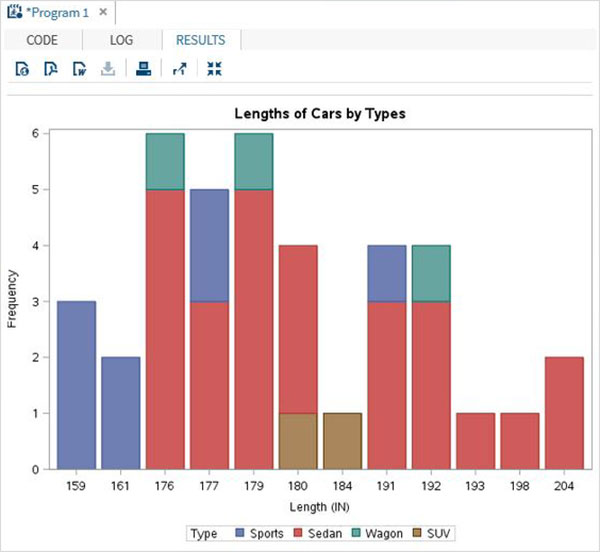
Gráfico de barras agrupadas
O gráfico de barras agrupadas é criado para mostrar como os valores de uma variável são espalhados por uma cultura.
Exemplo
O script a seguir criará um gráfico de barras agrupado onde o comprimento dos carros é agrupado em torno do tipo de carro. Portanto, vemos duas barras adjacentes no comprimento 191, uma para o tipo de carro 'Sedan' e outra para o tipo de carro 'Wagon' .
proc SGPLOT data = work.cars1;
vbar length /group = type GROUPDISPLAY = CLUSTER;
title 'Cluster of Cars by Types';
run;
quit;Quando executamos o código acima, obtemos a seguinte saída -

Um gráfico de pizza é uma representação de valores como fatias de um círculo com cores diferentes. As fatias são rotuladas e os números correspondentes a cada fatia também são representados no gráfico.
No SAS, o gráfico de pizza é criado usando PROC TEMPLATE que leva parâmetros para controlar a porcentagem, rótulos, cor, título etc.
Sintaxe
A sintaxe básica para criar um gráfico de pizza no SAS é -
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;variable é o valor para o qual criamos o gráfico de pizza.
Gráfico de pizza simples
Neste gráfico de pizza, consideramos uma única variável do conjunto de dados. O gráfico de pizza é criado com o valor das fatias que representam a fração da contagem da variável em relação ao valor total da variável.
Exemplo
No exemplo a seguir, cada fatia representa a fração do tipo de carro do número total de carros.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Quando executamos o código acima, obtemos a seguinte saída -
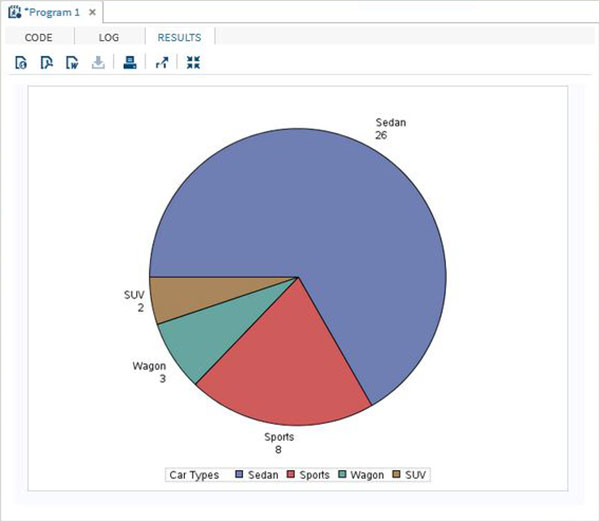
Gráfico de pizza com rótulos de dados
Neste gráfico de pizza, representamos tanto o valor fracionário quanto o valor percentual de cada fatia. Também alteramos a localização do rótulo para estar dentro do gráfico. O estilo de aparência do gráfico é modificado usando a opção DATASKIN. Ele usa um dos estilos embutidos, disponíveis no ambiente SAS.
Exemplo
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Quando executamos o código acima, obtemos a seguinte saída -
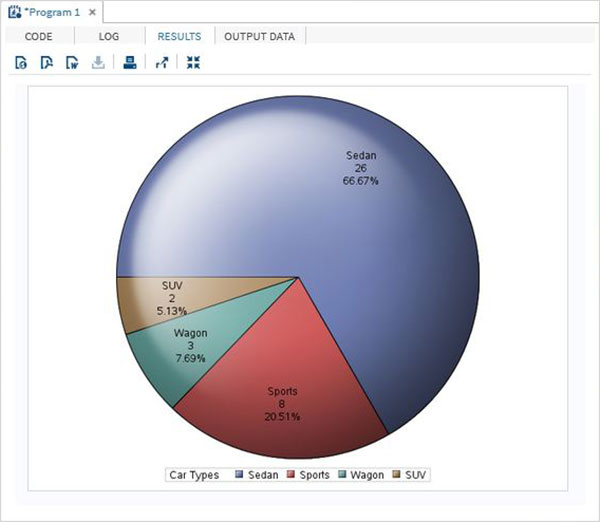
Grouped Pie Chart
Neste gráfico de pizza, o valor da variável apresentada no gráfico é agrupado em relação a outra variável do mesmo conjunto de dados. Cada grupo se torna um círculo e o gráfico tem tantos círculos concêntricos quanto o número de grupos disponíveis.
Exemplo
No exemplo abaixo, agrupamos o gráfico em relação à variável chamada "Marca". Como existem dois valores disponíveis ("Audi" e "BMW"), obtemos dois círculos concêntricos, cada um representando fatias de tipos de carros de sua própria marca.
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Quando executamos o código acima, obtemos a seguinte saída -
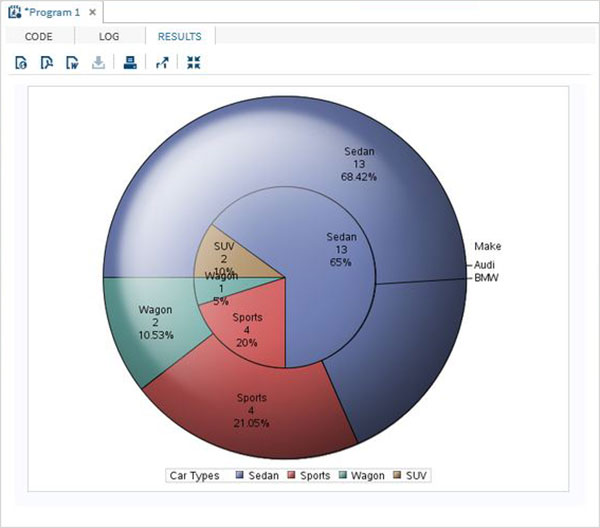
Um gráfico de dispersão é um tipo de gráfico que usa valores de duas variáveis traçadas em um plano cartesiano. Geralmente é usado para descobrir a relação entre duas variáveis. No SAS, usamosPROC SGSCATTER para criar gráficos de dispersão.
Observe que criamos o conjunto de dados denominado CARS1 no primeiro exemplo e usamos o mesmo conjunto de dados para todos os conjuntos de dados subsequentes. Este conjunto de dados permanece na biblioteca de trabalho até o final da sessão SAS.
Sintaxe
A sintaxe básica para criar um gráfico de dispersão no SAS é -
PROC sgscatter DATA = DATASET;
PLOT VARIABLE_1 * VARIABLE_2
/ datalabel = VARIABLE group = VARIABLE;
RUN;A seguir está a descrição dos parâmetros usados -
DATASET é o nome do conjunto de dados.
VARIABLE é a variável usada do conjunto de dados.
Gráfico de dispersão simples
Em um gráfico de dispersão simples, escolhemos duas variáveis do conjunto de dados e as agrupamos em relação a uma terceira variável. Também podemos rotular os dados. O resultado mostra como as duas variáveis estão espalhadas noCartesian plane.
Exemplo
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;Quando executamos o código acima, obtemos a seguinte saída -
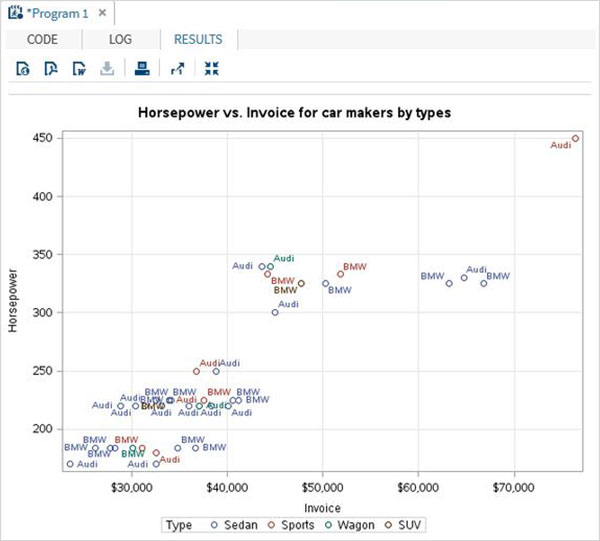
Gráfico de dispersão com previsão
podemos usar um parâmetro de estimativa para prever a intensidade da correlação entre eles, desenhando uma elipse em torno dos valores. Usamos as opções adicionais no procedimento para desenhar a elipse conforme mostrado abaixo.
Exemplo
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;Quando executamos o código acima, obtemos a seguinte saída -

Matriz de Dispersão
Também podemos ter um gráfico de dispersão envolvendo mais de duas variáveis agrupando-as em pares. No exemplo abaixo, consideramos três variáveis e desenhamos uma matriz de gráfico de dispersão. Obtemos 3 pares de matriz resultante.
Exemplo
PROC sgscatter DATA = CARS1;
matrix horsepower invoice length
/ group = type;
title 'Horsepower vs. Invoice vs. Length for car makers by types';
RUN;Quando executamos o código acima, obtemos a seguinte saída -
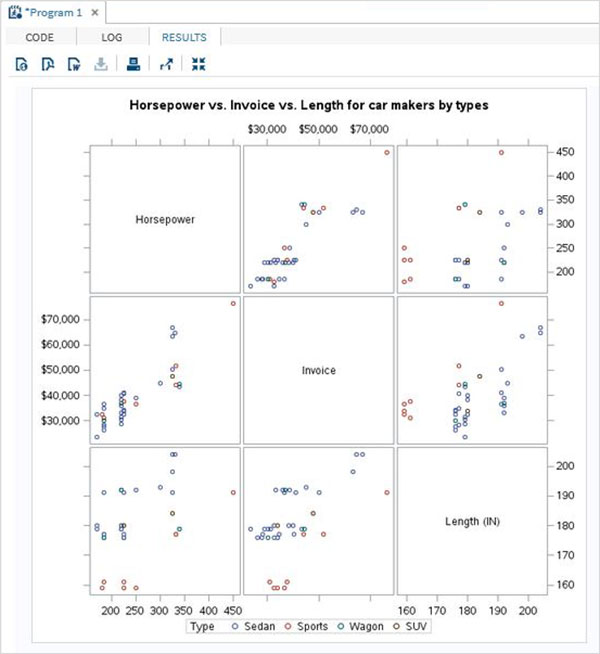
Um Boxplot é a representação gráfica de grupos de dados numéricos por meio de seus quartis. Os gráficos de caixa também podem ter linhas que se estendem verticalmente a partir das caixas (bigodes), indicando variabilidade fora dos quartis superior e inferior. A parte inferior e superior da caixa são sempre o primeiro e o terceiro quartis, e a faixa dentro da caixa é sempre o segundo quartil (a mediana). No SAS, um Boxplot simples é criado usandoPROC SGPLOT e boxplot com painéis é criado usando PROC SGPANEL.
Observe que criamos o conjunto de dados denominado CARS1 no primeiro exemplo e usamos o mesmo conjunto de dados para todos os conjuntos de dados subsequentes. Este conjunto de dados permanece na biblioteca de trabalho até o final da sessão SAS.
Sintaxe
A sintaxe básica para criar um boxplot no SAS é -
PROC SGPLOT DATA = DATASET;
VBOX VARIABLE / category = VARIABLE;
RUN;
PROC SGPANEL DATA = DATASET;;
PANELBY VARIABLE;
VBOX VARIABLE> / category = VARIABLE;
RUN;DATASET - é o nome do conjunto de dados usado.
VARIABLE - é o valor usado para plotar o Boxplot.
Boxplot simples
Em um Boxplot simples, escolhemos uma variável do conjunto de dados e outra para formar uma categoria. Os valores da primeira variável são categorizados em tantos grupos quanto o número de valores distintos na segunda variável.
Exemplo
No exemplo a seguir, escolhemos a variável de potência como a primeira variável e o tipo como a variável de categoria. Assim, obtemos boxplots para a distribuição dos valores de potência para cada tipo de carro.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;Quando executamos o código acima, obtemos a seguinte saída -
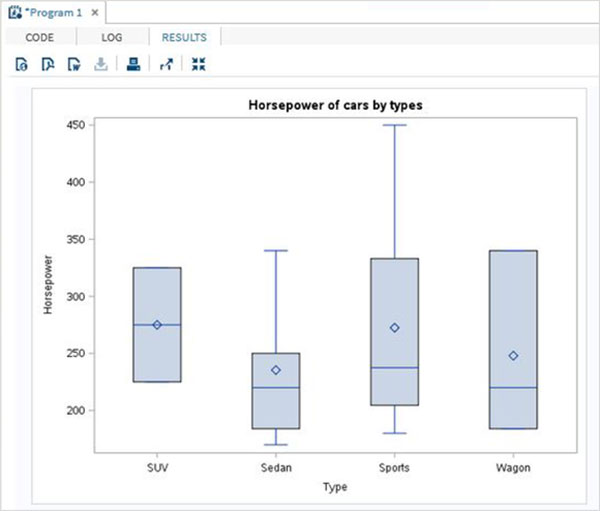
Boxplot em painéis verticais
Podemos dividir os Boxplots de uma variável em muitos painéis verticais (colunas). Cada painel contém os boxplots para todas as variáveis categóricas. Mas os boxplots são agrupados usando outra terceira variável que divide o gráfico em vários painéis.
Exemplo
No exemplo abaixo, colocamos o gráfico em painéis usando a variável 'make'. Como existem dois valores distintos de 'make', obtemos dois painéis verticais.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Quando executamos o código acima, obtemos a seguinte saída -
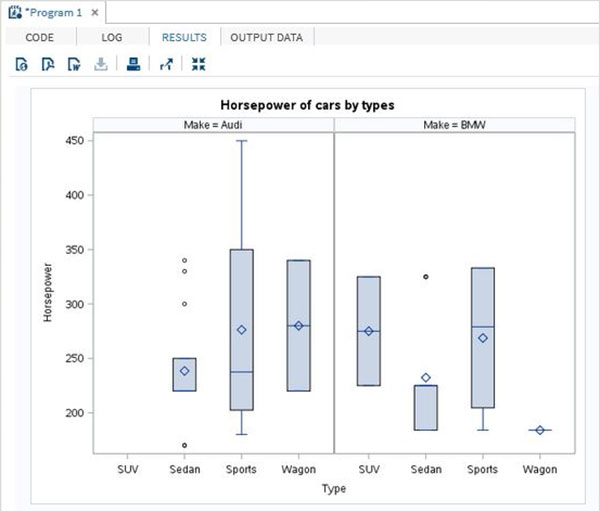
Boxplot em painéis horizontais
Podemos dividir os Boxplots de uma variável em muitos painéis horizontais (linhas). Cada painel contém os boxplots para todas as variáveis categóricas. Mas os boxplots são agrupados usando outra terceira variável que divide o gráfico em vários painéis. No exemplo abaixo, colocamos o gráfico em painéis usando a variável 'make'. Como existem dois valores distintos de 'make', obtemos dois painéis horizontais.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE / columns = 1 novarname;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Quando executamos o código acima, obtemos a seguinte saída -
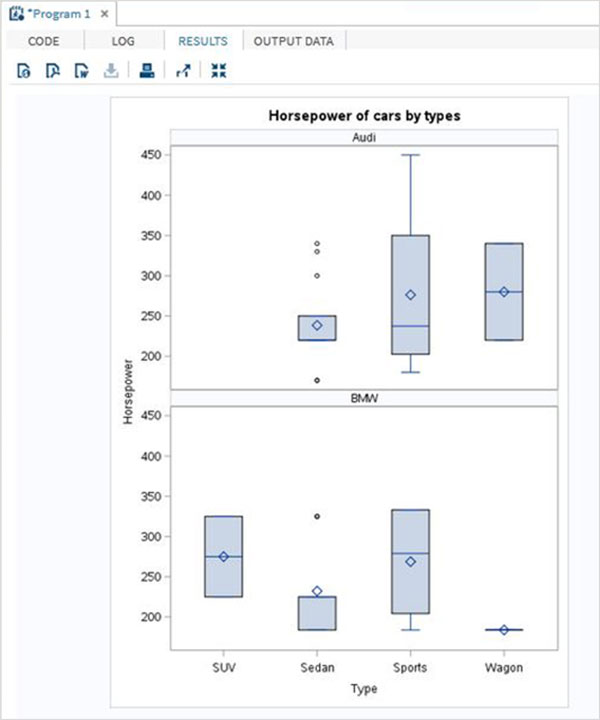
A média aritmética é o valor obtido somando o valor das variáveis numéricas e depois dividindo a soma pelo número de variáveis. Também é chamado de Média. No SAS, a média aritmética é calculada usandoPROC MEANS. Usando este procedimento SAS, podemos encontrar a média de todas as variáveis ou algumas variáveis de um conjunto de dados. Também podemos formar grupos e encontrar médias de variáveis de valores específicos para aquele grupo.
Sintaxe
A sintaxe básica para calcular a média aritmética no SAS é -
PROC MEANS DATA = DATASET;
CLASS Variables ;
VAR Variables;A seguir está a descrição dos parâmetros usados -
DATASET - é o nome do conjunto de dados usado.
Variables - são o nome da variável do conjunto de dados.
Média de um conjunto de dados
A média de cada variável numérica em um conjunto de dados é calculada usando o PROC, fornecendo apenas o nome do conjunto de dados sem nenhuma variável.
Exemplo
No exemplo abaixo, encontramos a média de todas as variáveis numéricas no conjunto de dados SAS denominado CARS. Especificamos os dígitos máximos após a casa decimal como 2 e também encontramos a soma dessas variáveis.
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2;
RUN;Quando o código acima é executado, obtemos a seguinte saída -
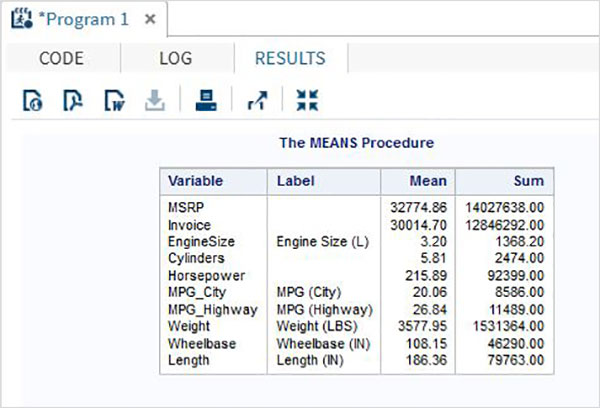
Média de variáveis selecionadas
Podemos obter a média de algumas das variáveis, fornecendo seus nomes no var opção.
Exemplo
A seguir, calculamos a média de três variáveis.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ;
var horsepower invoice EngineSize;
RUN;Quando o código acima é executado, obtemos a seguinte saída -
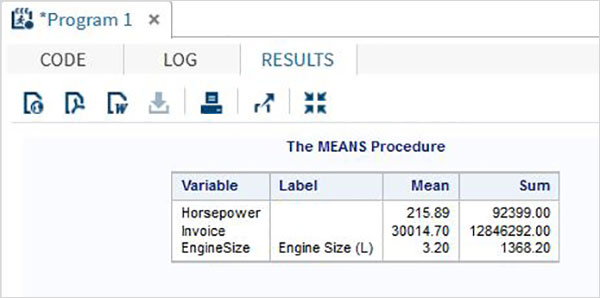
Média por classe
Podemos encontrar a média das variáveis numéricas organizando-as em grupos usando algumas outras variáveis.
Exemplo
No exemplo abaixo, encontramos a média da variável cavalos-vapor para cada tipo em cada marca do carro.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2;
class make type;
var horsepower;
RUN;Quando o código acima é executado, obtemos a seguinte saída -
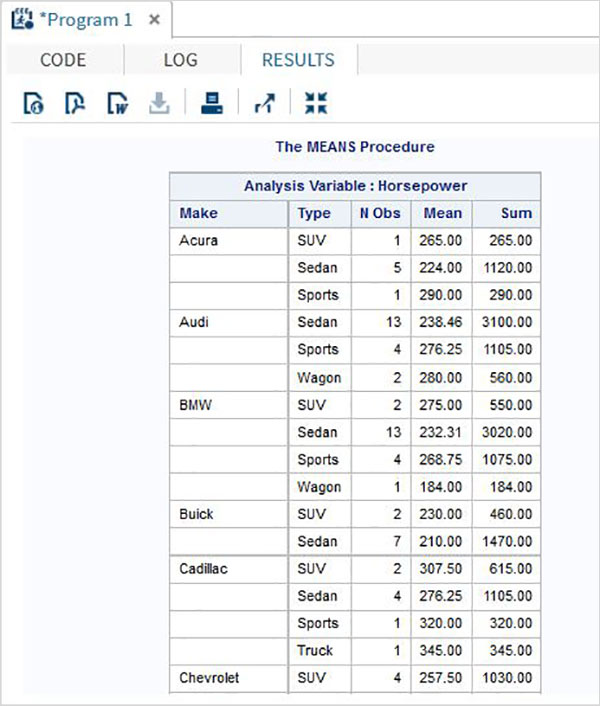
O desvio padrão (SD) é uma medida de quão variados são os dados em um conjunto de dados. Matematicamente, ele mede quão distantes ou próximos estão cada valor do valor médio de um conjunto de dados. Um valor de desvio padrão próximo de 0 indica que os pontos de dados tendem a estar muito próximos da média do conjunto de dados e um desvio padrão alto indica que os pontos de dados estão espalhados por uma faixa mais ampla de valores
No SAS, os valores SD são medidos usando PROC MEAN e PROC SURVEYMEANS.
Usando PROC MEANS
Para medir o SD usando proc meansescolhemos a opção STD na etapa PROC. Ele traz os valores SD para cada variável numérica presente no conjunto de dados.
Sintaxe
A sintaxe básica para calcular o desvio padrão no SAS é -
PROC means DATA = dataset STD;A seguir está a descrição dos parâmetros usados -
Dataset - é o nome do conjunto de dados.
Exemplo
No exemplo abaixo, criamos o conjunto de dados CARS1 do conjunto de dados CARS na biblioteca SASHELP. Escolhemos a opção STD com o PROC significa passo.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;Quando executamos o código acima, ele fornece a seguinte saída -
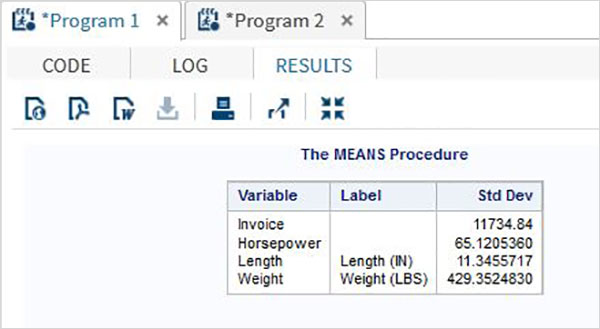
Usando PROC SURVEYMEANS
Este procedimento também é usado para medir o SD junto com alguns recursos avançados, como medir o SD para variáveis categóricas, bem como fornecer estimativas de variação.
Sintaxe
A sintaxe para usar PROC SURVEYMEANS é -
PROC SURVEYMEANS options statistic-keywords ;
BY variables ;
CLASS variables ;
VAR variables ;A seguir está a descrição dos parâmetros usados -
BY - indica as variáveis usadas para criar grupos de observações.
CLASS - indica as variáveis usadas para variáveis categóricas.
VAR - indica as variáveis para as quais o SD será calculado.
Exemplo
O exemplo abaixo descreve o uso de class opção que cria as estatísticas para cada um dos valores na variável de classe.
proc surveymeans data = CARS1 STD;
class type;
var type horsepower;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Quando executamos o código acima, ele fornece a seguinte saída -
Usando a opção BY
O código a seguir dá um exemplo da opção BY. Nele o resultado é agrupado para cada valor da opção BY.
Exemplo
proc surveymeans data = CARS1 STD;
var horsepower;
BY make;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Quando executamos o código acima, ele fornece a seguinte saída -
Resultado para make = "Audi"

Resultado para make = "BMW"
Uma distribuição de frequência é uma tabela que mostra a frequência dos pontos de dados em um conjunto de dados. Cada entrada na tabela contém a frequência ou contagem das ocorrências de valores dentro de um determinado grupo ou intervalo e, dessa forma, a tabela resume a distribuição dos valores na amostra.
SAS fornece um procedimento chamado PROC FREQ para calcular a distribuição de frequência de pontos de dados em um conjunto de dados.
Sintaxe
A sintaxe básica para calcular a distribuição de frequência no SAS é -
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;A seguir está a descrição dos parâmetros usados -
Dataset é o nome do conjunto de dados.
Variables_1 são os nomes das variáveis do conjunto de dados cuja distribuição de frequência precisa ser calculada.
Variables_2 são as variáveis que categorizaram o resultado da distribuição de frequência.
Distribuição de frequência de variável única
Podemos determinar a distribuição de frequência de uma única variável usando PROC FREQ.Neste caso, o resultado mostrará a frequência de cada valor da variável. O resultado também mostra a distribuição percentual, frequência cumulativa e porcentagem cumulativa.
Exemplo
No exemplo abaixo, encontramos a distribuição de frequência da variável de potência para o conjunto de dados denominado CARS1 que é criado a partir da biblioteca SASHELP.CARS.Podemos ver o resultado dividido em duas categorias de resultados. Um para cada marca do carro.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Quando o código acima é executado, obtemos o seguinte resultado -

Distribuição de frequência múltipla variável
Podemos encontrar as distribuições de frequência para variáveis múltiplas que as agrupam em todas as combinações possíveis.
Exemplo
No exemplo abaixo, calculamos a distribuição de frequência para a marca de um carro para grouped by car type e também a distribuição de frequência de cada tipo de carro grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Quando o código acima é executado, obtemos o seguinte resultado -
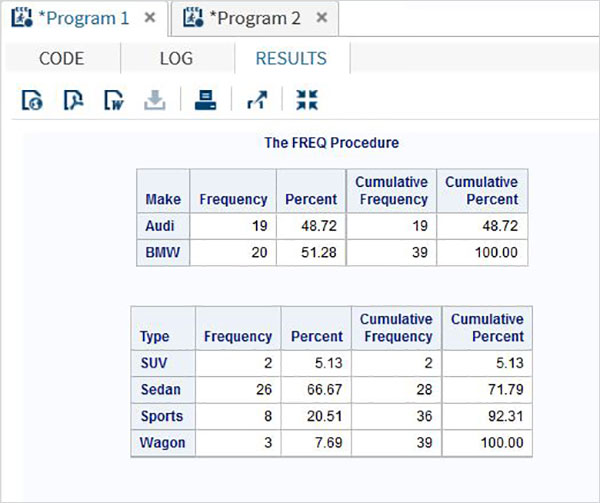
Distribuição de frequência com peso
Com a opção de peso podemos calcular a distribuição de frequência enviesada com o peso da variável. Aqui, o valor da variável é considerado o número de observações em vez da contagem do valor.
Exemplo
No exemplo abaixo, calculamos a distribuição de frequência das variáveis marca e tipo com peso atribuído à potência.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Quando o código acima é executado, obtemos o seguinte resultado -
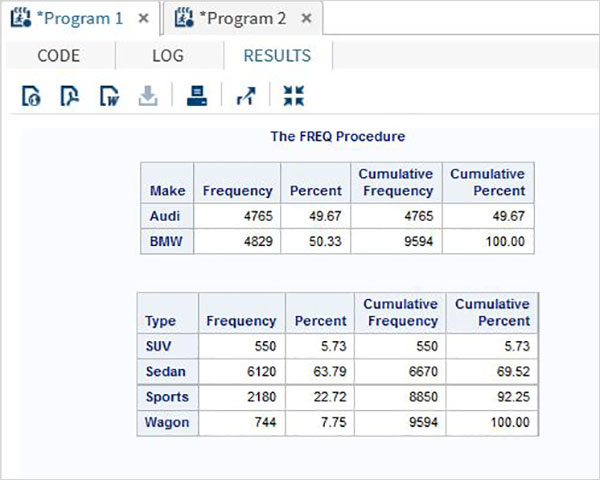
A tabulação cruzada envolve a produção de tabelas cruzadas, também chamadas de tabelas contingentes, usando todas as combinações possíveis de duas ou mais variáveis. No SAS, ele é criado usandoPROC FREQ juntamente com o TABLESopção. Por exemplo - se precisamos da frequência de cada modelo para cada marca em cada categoria de tipo de carro, precisamos usar a opção TABLES do PROC FREQ.
Sintaxe
A sintaxe básica para aplicar tabulação cruzada no SAS é -
PROC FREQ DATA = dataset;
TABLES variable_1*Variable_2;A seguir está a descrição dos parâmetros usados -
Dataset é o nome do conjunto de dados.
Variable_1 and Variable_2 são os nomes das variáveis do conjunto de dados cuja distribuição de frequência precisa ser calculada.
Exemplo
Considere o caso de descobrir quantos tipos de carros estão disponíveis em cada marca de carro do conjunto de dados cars1 que é criado de forma SASHELP.CARScomo mostrado abaixo. Nesse caso, precisamos dos valores de frequência individuais, bem como a soma dos valores de frequência entre as marcas e os tipos. Podemos observar que o resultado mostra valores nas linhas e nas colunas.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;Quando o código acima é executado, obtemos o seguinte resultado -
Tabulação cruzada de 3 variáveis
Quando temos três variáveis, podemos agrupar 2 delas e tabular cada uma delas com a terceira variável. Portanto, no resultado temos duas tabelas cruzadas.
Exemplo
No exemplo abaixo, encontramos a frequência de cada tipo de carro e cada modelo de carro em relação à marca do carro. Também usamos a opção nocol e norow para evitar os valores de soma e porcentagem.
proc FREQ data = CARS2 ;
tables make * (type model) / nocol norow nopercent;
run;Quando o código acima é executado, obtemos o seguinte resultado -
Tabulação cruzada de 4 variáveis
Com 4 variáveis, o número de combinações emparelhadas aumenta para 4. Cada variável do grupo 1 é emparelhada com cada variável do grupo 2.
Exemplo
No exemplo abaixo encontramos a frequência de comprimento do carro para cada marca e cada modelo. Da mesma forma, a frequência da potência para cada marca e cada modelo.
proc FREQ data = CARS2 ;
tables (make model) * (length horsepower) / nocol norow nopercent;
run;Quando o código acima é executado, obtemos o seguinte resultado -
Os testes T são realizados para calcular os limites de confiança para uma amostra ou duas amostras independentes, comparando suas médias e diferenças médias. O procedimento SAS denominadoPROC TTEST é usado para realizar testes t em uma única variável e um par de variáveis.
Sintaxe
A sintaxe básica para aplicar PROC TTEST no SAS é -
PROC TTEST DATA = dataset;
VAR variable;
CLASS Variable;
PAIRED Variable_1 * Variable_2;A seguir está a descrição dos parâmetros usados -
Dataset é o nome do conjunto de dados.
Variable_1 and Variable_2 são os nomes das variáveis do conjunto de dados usado no teste t.
Exemplo
Abaixo, vemos um teste t de amostra no qual encontra a estimativa do teste t para a variável de potência com limites de confiança de 95 por cento.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;Quando o código acima é executado, obtemos o seguinte resultado -
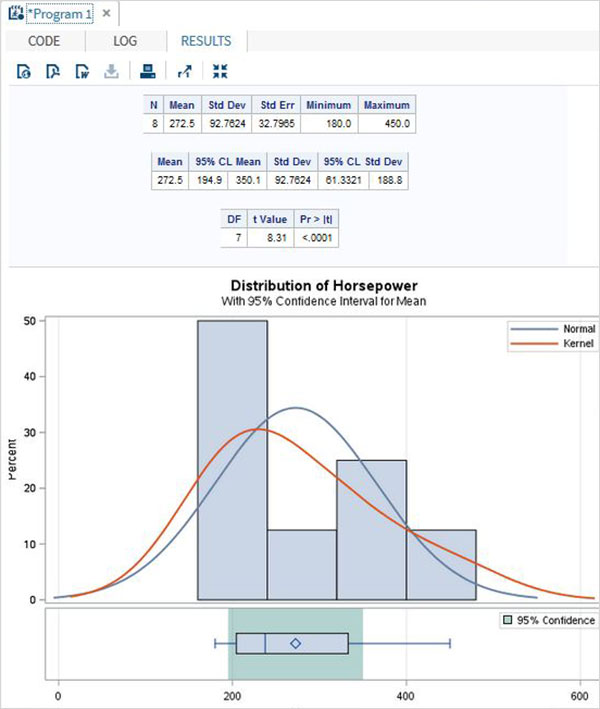
Teste t pareado
O teste T pareado é realizado para testar se duas variáveis dependentes são estatisticamente diferentes uma da outra ou não.
Exemplo
Como o comprimento e o peso de um carro dependem um do outro, aplicamos o teste T emparelhado conforme mostrado abaixo.
proc ttest data = cars1 ;
paired weight*length;
run;Quando o código acima é executado, obtemos o seguinte resultado -
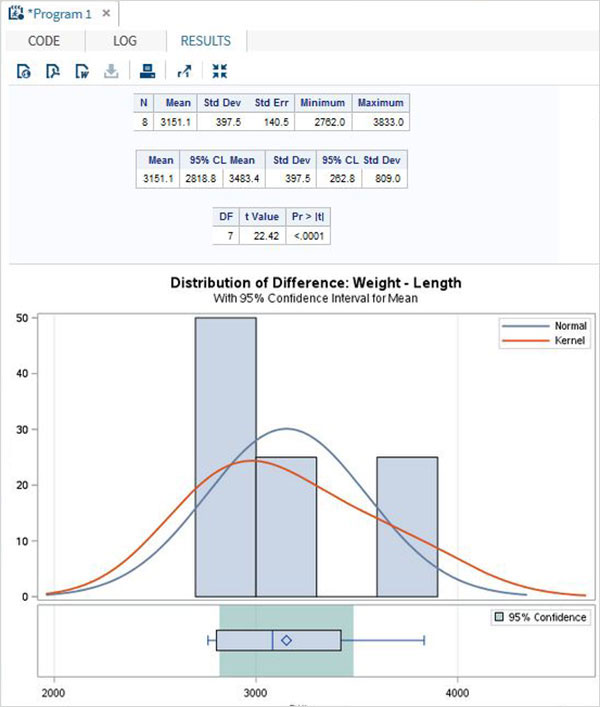
Teste t de duas amostras
Este teste t é projetado para comparar médias da mesma variável entre dois grupos.
Exemplo
Em nosso caso, comparamos a média da variável de potência entre as duas marcas diferentes de carros ("Audi" e "BMW").
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0;
title "Two sample t-test example";
class make;
var horsepower;
run;Quando o código acima é executado, obtemos o seguinte resultado -
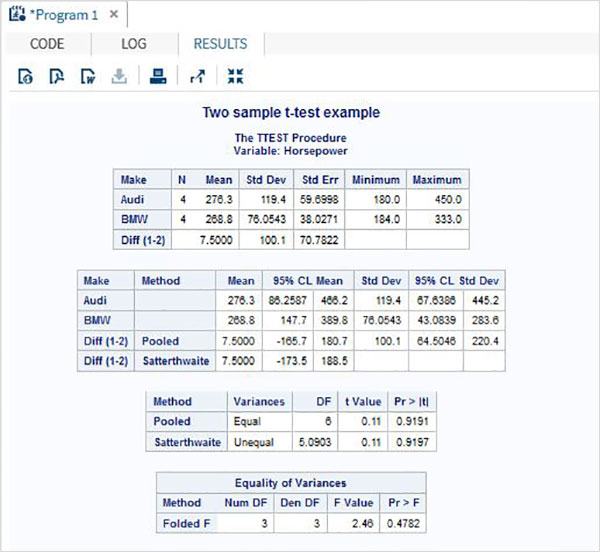
A análise de correlação lida com relacionamentos entre variáveis. O coeficiente de correlação é uma medida de associação linear entre duas variáveis. Os valores do coeficiente de correlação estão sempre entre -1 e +1. SAS fornece o procedimentoPROC CORR para encontrar os coeficientes de correlação entre um par de variáveis em um conjunto de dados.
Sintaxe
A sintaxe básica para aplicar PROC CORR no SAS é -
PROC CORR DATA = dataset options;
VAR variable;A seguir está a descrição dos parâmetros usados -
Dataset é o nome do conjunto de dados.
Options é a opção adicional com procedimento como plotar uma matriz etc.
Variable é o nome da variável do conjunto de dados usado para encontrar a correlação.
Exemplo
Os coeficientes de correlação entre um par de variáveis disponíveis em um conjunto de dados podem ser obtidos usando seus nomes na instrução VAR. No exemplo abaixo, usamos o conjunto de dados CARS1 e obtemos o resultado que mostra os coeficientes de correlação entre a potência e o peso.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;Quando o código acima é executado, obtemos o seguinte resultado -
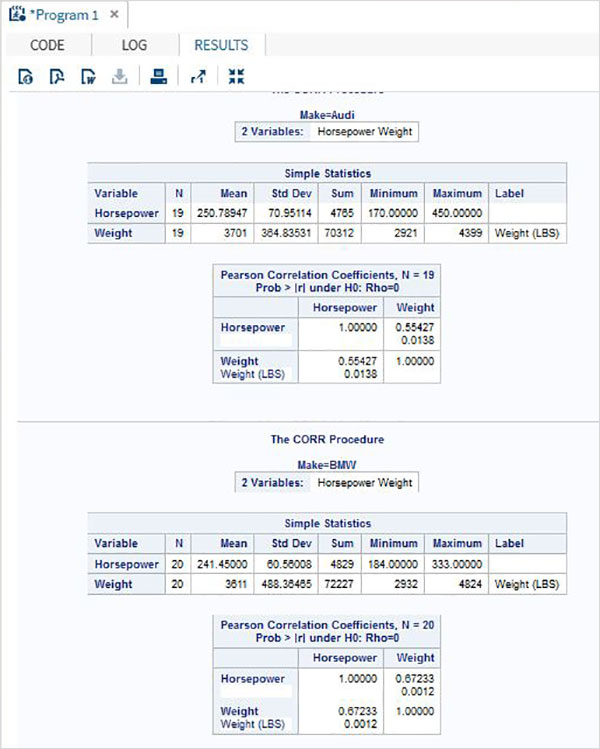
Correlação entre todas as variáveis
Coeficientes de correlação entre todas as variáveis disponíveis em um conjunto de dados podem ser obtidos simplesmente aplicando o procedimento com o nome do conjunto de dados.
Exemplo
No exemplo a seguir, usamos o conjunto de dados CARS1 e obtemos o resultado mostrando os coeficientes de correlação entre cada par de variáveis.
proc corr data = cars1 ;
run;Quando o código acima é executado, obtemos o seguinte resultado -
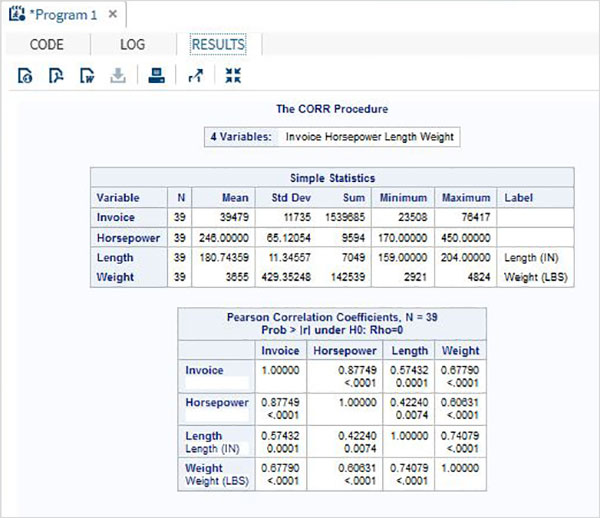
Matriz de correlação
Podemos obter uma matriz de gráfico de dispersão entre as variáveis, escolhendo a opção de plotar a matriz no PROC declaração.
Exemplo
No exemplo abaixo, obtemos a matriz entre potência e peso.
proc corr data = cars1 plots = matrix ;
VAR horsepower weight ;
run;Quando o código acima é executado, obtemos o seguinte resultado -
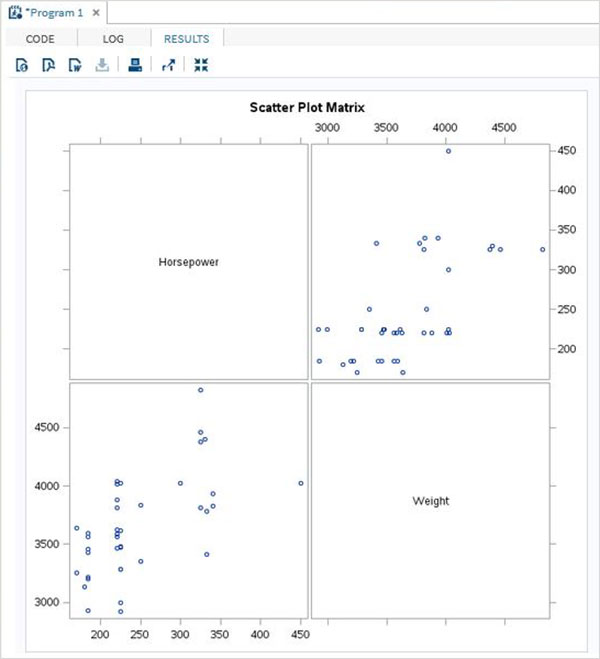
A regressão linear é usada para identificar a relação entre uma variável dependente e uma ou mais variáveis independentes. Um modelo do relacionamento é proposto e estimativas dos valores dos parâmetros são usadas para desenvolver uma equação de regressão estimada.
Vários testes são então usados para determinar se o modelo é satisfatório. Se for então, a equação de regressão estimada pode ser usada para prever o valor dos valores dados da variável dependente para as variáveis independentes. No SAS o procedimentoPROC REG é usado para encontrar o modelo de regressão linear entre duas variáveis.
Sintaxe
A sintaxe básica para aplicar PROC REG no SAS é -
PROC REG DATA = dataset;
MODEL variable_1 = variable_2;A seguir está a descrição dos parâmetros usados -
Dataset é o nome do conjunto de dados.
variable_1 and variable_2 são os nomes das variáveis do conjunto de dados usados para encontrar a correlação.
Exemplo
O exemplo abaixo mostra o processo para encontrar a correlação entre as duas variáveis de potência e peso de um carro usando PROC REG. No resultado, vemos os valores de interceptação que podem ser usados para formar a equação de regressão.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;Quando o código acima é executado, obtemos o seguinte resultado -
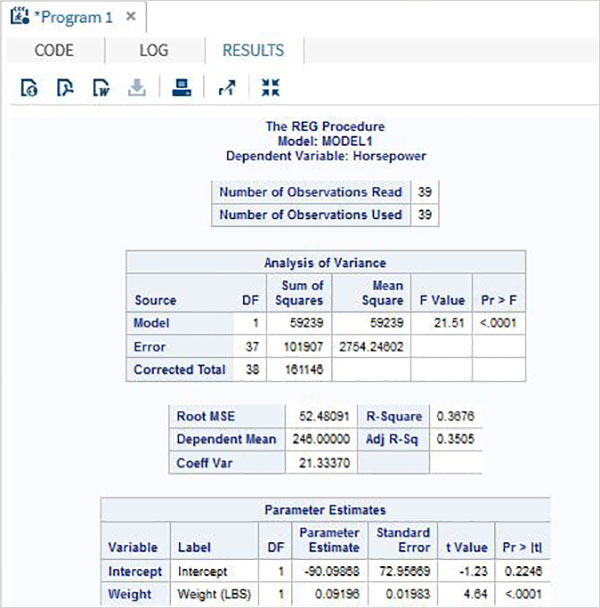
O código acima também fornece uma visão gráfica de várias estimativas do modelo, conforme mostrado abaixo. Por ser um procedimento SAS avançado, ele simplesmente não para em fornecer os valores de interceptação como saída.
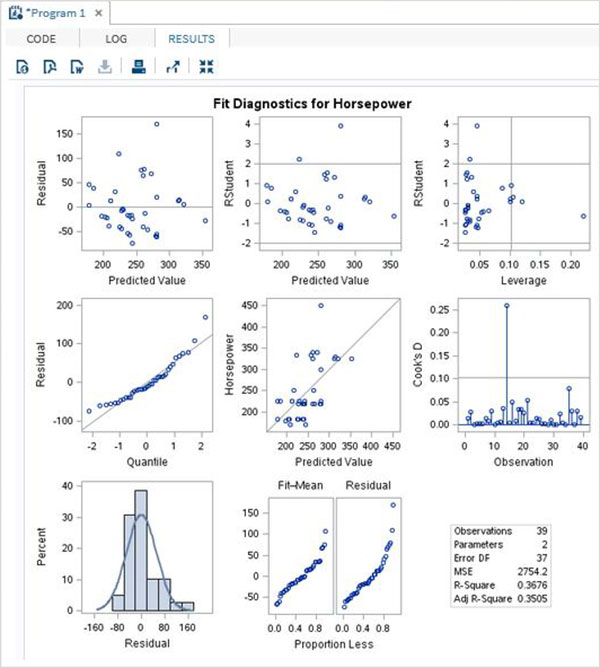
A análise de Bland-Altman é um processo para verificar a extensão da concordância ou discordância entre dois métodos projetados para medir os mesmos parâmetros. Uma alta correlação entre os métodos indica que uma amostra boa o suficiente foi escolhida na análise de dados. No SAS, criamos um gráfico de Bland-Altman calculando a média, o limite superior e o limite inferior dos valores das variáveis. Em seguida, usamos PROC SGPLOT para criar o gráfico de Bland-Altman.
Sintaxe
A sintaxe básica para aplicar PROC SGPLOT no SAS é -
PROC SGPLOT DATA = dataset;
SCATTER X = variable Y = Variable;
REFLINE value;A seguir está a descrição dos parâmetros usados -
Dataset é o nome do conjunto de dados.
SCATTER declaração cerates o gráfico de dispersão do valor fornecido na forma de X e Y.
REFLINE cria uma linha de referência horizontal ou vertical.
Exemplo
No exemplo a seguir, pegamos o resultado de dois experimentos gerados por dois métodos denominados novo e antigo. Calculamos as diferenças nos valores das variáveis e também a média das variáveis da mesma observação. Também calculamos os valores de desvio padrão a serem usados nos limites superior e inferior do cálculo.
O resultado mostra um gráfico de Bland-Altman como um gráfico de dispersão.
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Quando o código acima é executado, obtemos o seguinte resultado -
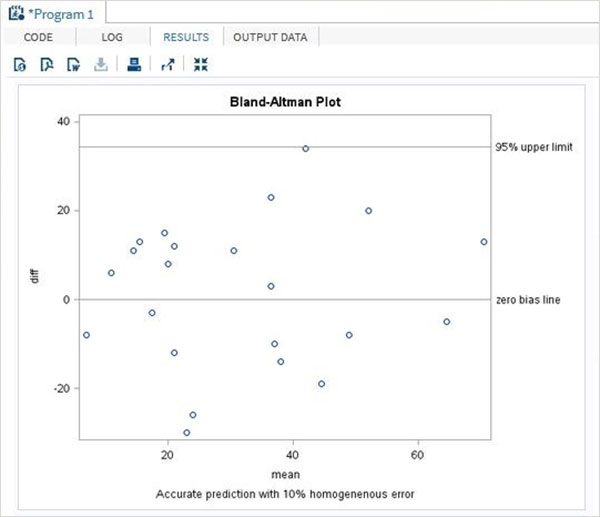
Modelo aprimorado
Em um modelo aprimorado do programa acima, obtemos um ajuste de curva de nível de confiança de 95%.
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Quando o código acima é executado, obtemos o seguinte resultado -
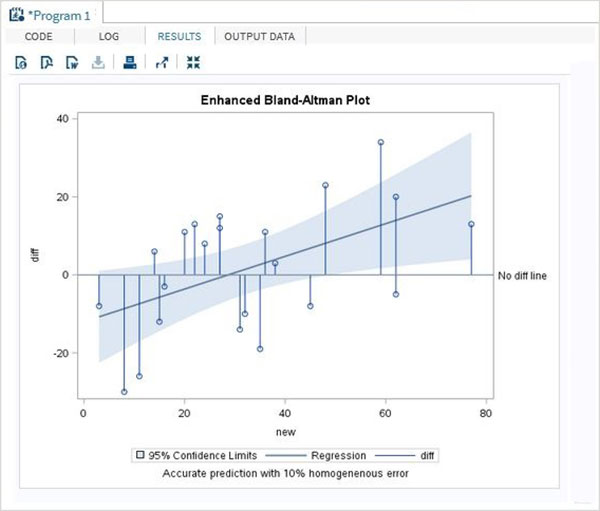
Um teste de qui-quadrado é usado para examinar a associação entre duas variáveis categóricas. Ele pode ser usado para testar a extensão da dependência e a extensão da independência entre as variáveis. SAS usaPROC FREQ junto com a opção chisq para determinar o resultado do teste Qui-quadrado.
Sintaxe
A sintaxe básica para aplicar PROC FREQ para o teste Qui-quadrado no SAS é -
PROC FREQ DATA = dataset;
TABLES variables
/CHISQ TESTP = (percentage values);A seguir está a descrição dos parâmetros usados -
Dataset é o nome do conjunto de dados.
Variables são os nomes das variáveis do conjunto de dados usados no teste do qui-quadrado.
Percentage Values na declaração TESTP representam a porcentagem dos níveis da variável.
Exemplo
No exemplo a seguir, consideramos um teste qui-quadrado na variável chamada tipo no conjunto de dados SASHELP.CARS. Essa variável tem seis níveis e atribuímos porcentagem a cada nível de acordo com o desenho do teste.
proc freq data = sashelp.cars;
tables type
/chisq
testp = (0.20 0.12 0.18 0.10 0.25 0.15);
run;Quando o código acima é executado, obtemos o seguinte resultado -

Também obtemos o gráfico de barras mostrando o desvio do tipo de variável, conforme mostrado na imagem a seguir.
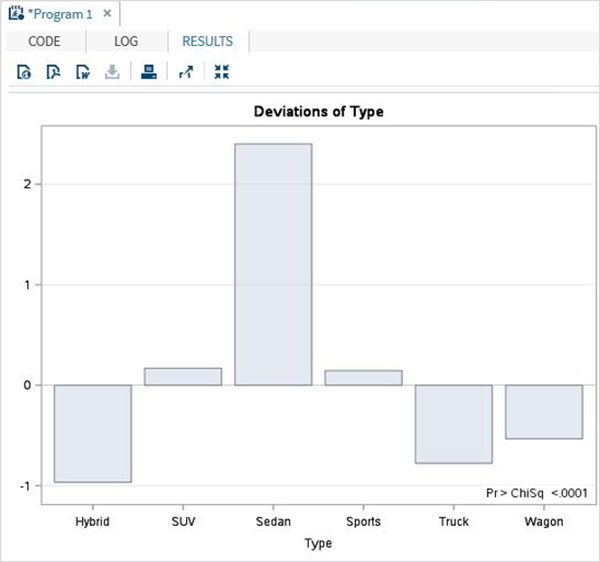
Qui-quadrado de duas vias
O teste qui-quadrado de duas vias é usado quando aplicamos os testes a duas variáveis do conjunto de dados.
Exemplo
No exemplo a seguir, aplicamos o teste do qui-quadrado em duas variáveis chamadas tipo e origem. O resultado mostra a forma tabular de todas as combinações dessas duas variáveis.
proc freq data = sashelp.cars;
tables type*origin
/chisq
;
run;Quando o código acima é executado, obtemos o seguinte resultado -
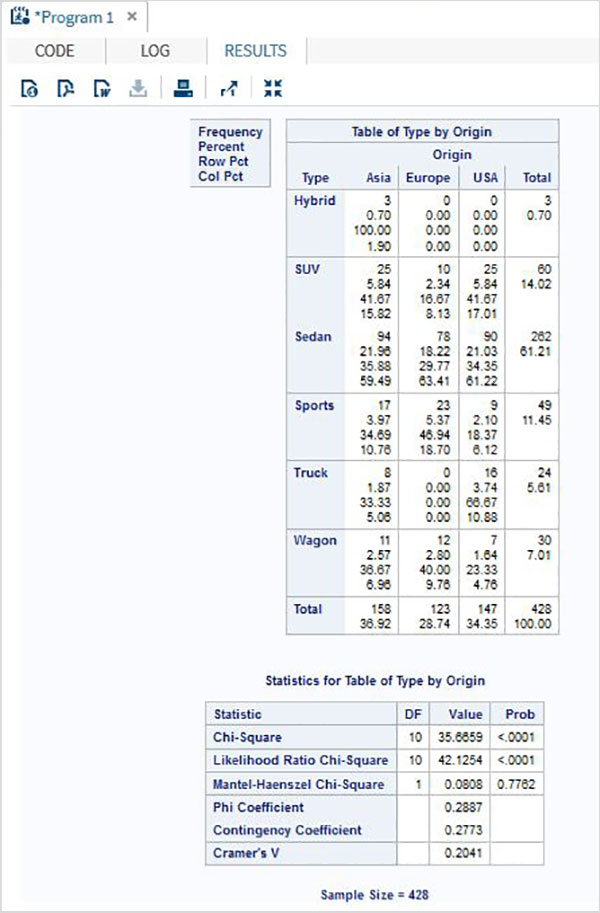
O teste exato de Fisher é um teste estatístico usado para determinar se há associações não aleatórias entre duas variáveis categóricas. No SAS, isso é realizado usando PROC FREQ. Usamos a opção Tabelas para usar as duas variáveis submetidas ao teste Exato de Fisher.
Sintaxe
A sintaxe básica para a aplicação do teste Exato de Fisher no SAS é -
PROC FREQ DATA = dataset ;
TABLES Variable_1*Variable_2 / fisher;A seguir está a descrição dos parâmetros usados -
dataset é o nome do conjunto de dados.
Variable_1*Variable_2 são as variáveis do conjunto de dados.
Aplicando o Teste Exato de Fisher
Para aplicar o Teste Exato de Fisher, escolhemos duas variáveis categóricas chamadas Teste1 e Teste2 e seus resultados. Usamos PROC FREQ para aplicar o teste mostrado abaixo.
Exemplo
data temp;
input Test1 Test2 Result @@;
datalines;
1 1 3 1 2 1 2 1 1 2 2 3
;
proc freq;
tables Test1*Test2 / fisher;
run;Quando o código acima é executado, obtemos o seguinte resultado -
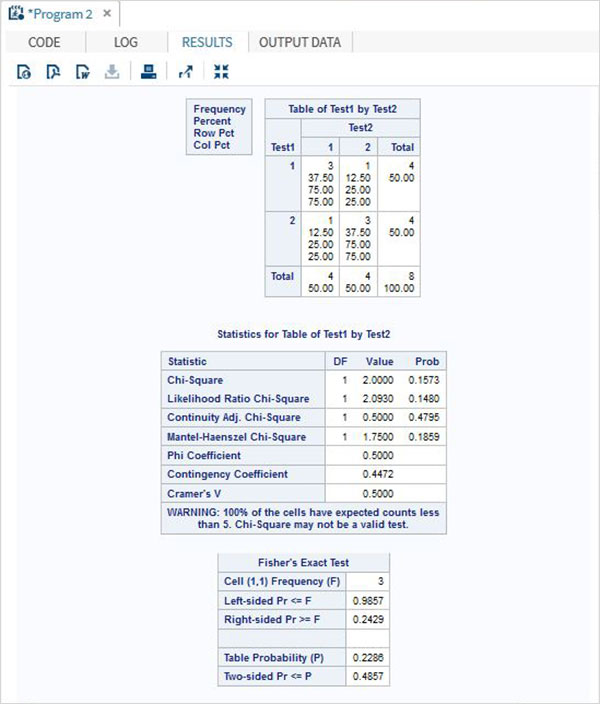
A análise de medidas repetidas é usada quando todos os membros de uma amostra aleatória são medidos em várias condições diferentes. À medida que a amostra é exposta a cada condição sucessivamente, a medição da variável dependente é repetida. Usar uma ANOVA padrão neste caso não é apropriado porque falha em modelar a correlação entre as medidas repetidas.
Deve-se ter clareza sobre a diferença entre um repeated measures design e um simple multivariate design. Para ambos, os membros da amostra são medidos em várias ocasiões, ou tentativas, mas no desenho de medidas repetidas, cada tentativa representa a medição da mesma característica sob uma condição diferente.
Em SAS PROC GLM é usado para realizar análises de medidas repetidas.
Sintaxe
A sintaxe básica para PROC GLM no SAS é -
PROC GLM DATA = dataset;
CLASS variable;
MODEL variables = group / NOUNI;
REPEATED TRIAL n;A seguir está a descrição dos parâmetros usados -
dataset é o nome do conjunto de dados.
CLASS dá às variáveis a variável usada como variável de classificação.
MODEL define o modelo a ser ajustado usando certas variáveis do conjunto de dados.
REPEATED define o número de medidas repetidas de cada grupo para testar a hipótese.
Exemplo
Considere o exemplo abaixo no qual temos dois grupos de pessoas submetidas a teste de efeito de uma droga. O tempo de reação de cada pessoa é registrado para cada um dos quatro tipos de medicamentos testados. Aqui, 5 testes são feitos para cada grupo de pessoas para ver a força da correlação entre o efeito dos quatro tipos de drogas.
DATA temp;
INPUT person group $ r1 r2 r3 r4;
CARDS;
1 A 2 1 6 5
2 A 5 4 11 9
3 A 6 14 12 10
4 A 2 4 5 8
5 A 0 5 10 9
6 B 9 11 16 13
7 B 12 4 13 14
8 B 15 9 13 8
9 B 6 8 12 5
10 B 5 7 11 9
;
RUN;
PROC PRINT DATA = temp ;
RUN;
PROC GLM DATA = temp;
CLASS group;
MODEL r1-r4 = group / NOUNI ;
REPEATED trial 5;
RUN;Quando o código acima é executado, obtemos o seguinte resultado -
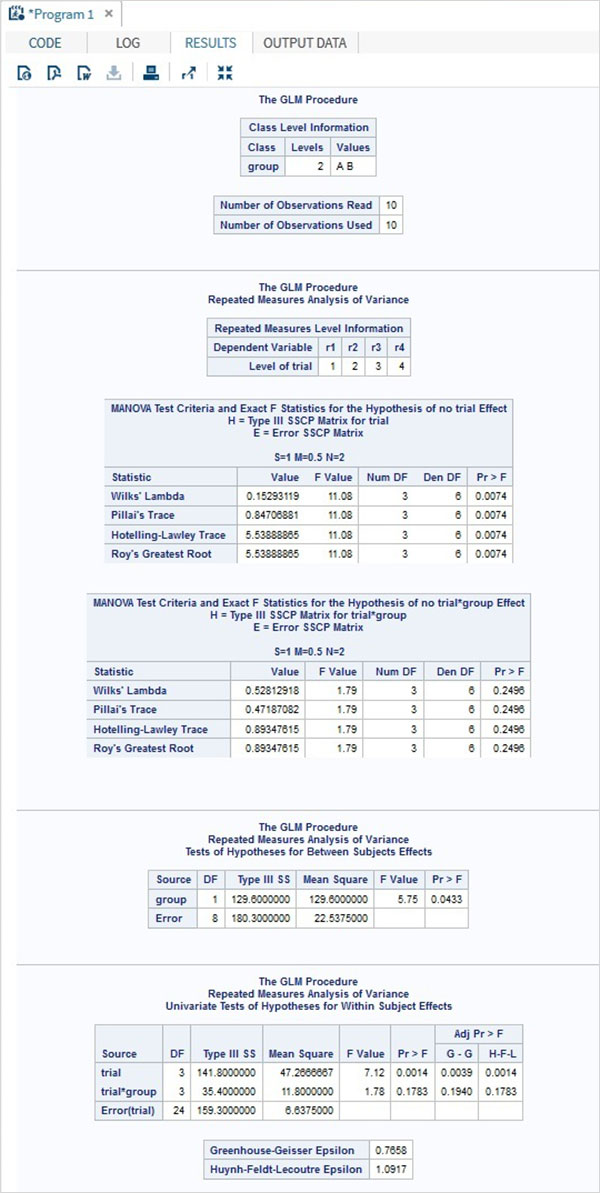
ANOVA significa Análise de Variância. No SAS é feito usandoPROC ANOVA. Ele realiza análises de dados de uma ampla variedade de projetos experimentais. Nesse processo, uma variável de resposta contínua, conhecida como variável dependente, é medida em condições experimentais identificadas por variáveis de classificação, conhecidas como variáveis independentes. Supõe-se que a variação na resposta seja devida a efeitos na classificação, com o erro aleatório sendo responsável pela variação restante.
Sintaxe
A sintaxe básica para aplicar PROC ANOVA no SAS é -
PROC ANOVA dataset ;
CLASS Variable;
MODEL Variable1 = variable2 ;
MEANS ;A seguir está a descrição dos parâmetros usados -
dataset é o nome do conjunto de dados.
CLASS dá às variáveis a variável usada como variável de classificação.
MODEL define o modelo a ser ajustado usando certas variáveis do conjunto de dados.
Variable_1 and Variable_2 são os nomes das variáveis do conjunto de dados usado na análise.
MEANS define o tipo de cálculo e comparação de meios.
Aplicando ANOVA
Vamos agora entender o conceito de aplicação de ANOVA no SAS.
Exemplo
Vamos considerar o conjunto de dados SASHELP.CARS. Aqui, estudamos a dependência entre as variáveis tipo de carro e sua potência. Como o tipo de carro é uma variável com valores categóricos, nós o consideramos como uma variável de classe e usamos ambas as variáveis no MODELO.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
RUN;Quando o código acima é executado, obtemos o seguinte resultado -

Aplicando ANOVA com MEANS
Vamos agora entender o conceito de aplicação de ANOVA com MEANS no SAS.
Exemplo
Também podemos estender o modelo aplicando a declaração MEANS, na qual usamos o método estudentizado da Turquia para comparar os valores médios de vários tipos de carros. A categoria de tipos de carros é listada com o valor médio da potência em cada categoria junto com alguns valores adicionais, como erro médio quadrado etc.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
MEANS type / tukey lines;
RUN;Quando o código acima é executado, obtemos o seguinte resultado -

O teste de hipóteses é o uso de estatísticas para determinar a probabilidade de uma dada hipótese ser verdadeira. O processo usual de teste de hipóteses consiste em quatro etapas, conforme mostrado abaixo.
Passo 1
Formule a hipótese nula H0 (comumente, que as observações são o resultado do puro acaso) e a hipótese alternativa H1 (comumente, que as observações mostram um efeito real combinado com um componente de variação do acaso).
Passo 2
Identifique uma estatística de teste que pode ser usada para avaliar a verdade da hipótese nula.
Etapa 3
Calcule o valor P, que é a probabilidade de que uma estatística de teste pelo menos tão significativa quanto a observada seria obtida assumindo que a hipótese nula fosse verdadeira. Quanto menor o valor P, mais forte será a evidência contra a hipótese nula.
Passo 4
Compare o valor p com um valor de significância aceitável alfa (às vezes chamado de valor alfa). Se p <= alfa, que o efeito observado é estatisticamente significativo, a hipótese nula é descartada e a hipótese alternativa é válida.
A linguagem de programação SAS tem recursos para realizar vários tipos de teste de hipótese, conforme mostrado abaixo.
| Teste | Descrição | SAS PROC |
|---|---|---|
| T-Test | Um teste t é usado para testar se a média de uma variável é significativamente diferente de um valor hipotético. Também determinamos se as médias para dois grupos independentes são significativamente diferentes e se as médias para grupos dependentes ou emparelhados são significativamente diferentes. | PROC TTEST |
| ANOVA | Também é usado para comparar médias quando há uma variável categórica independente. Queremos usar ANOVA unilateral ao testar para ver se as médias da variável dependente do intervalo são diferentes de acordo com a variável categórica independente. | PROC ANOVA |
| Chi-Square | Usamos a qualidade de ajuste do qui quadrado para avaliar se as frequências de uma variável categórica eram prováveis de acontecer devido ao acaso. O uso de um teste de qui quadrado é necessário se as proporções de uma variável categórica são um valor hipotético. | PROC FREQ |
| Linear Regression | A regressão linear simples é usada quando se deseja testar o quão bem uma variável prediz outra variável. A regressão linear múltipla permite testar quão bem várias variáveis predizem uma variável de interesse. Ao usar a regressão linear múltipla, também assumimos que as variáveis preditoras são independentes. | PROC REG |