TensorFlow - Guia rápido
TensorFlow é uma biblioteca ou estrutura de software projetada pela equipe do Google para implementar conceitos de aprendizado de máquina e deep learning da maneira mais fácil. Ele combina a álgebra computacional de técnicas de otimização para facilitar o cálculo de muitas expressões matemáticas.
O site oficial do TensorFlow é mencionado abaixo -
www.tensorflow.org
Vamos agora considerar os seguintes recursos importantes do TensorFlow -
Inclui um recurso que define, otimiza e calcula expressões matemáticas facilmente com a ajuda de matrizes multidimensionais chamadas tensores.
Inclui suporte de programação de redes neurais profundas e técnicas de aprendizado de máquina.
Inclui um recurso de computação altamente escalonável com vários conjuntos de dados.
O TensorFlow usa computação GPU, automatizando o gerenciamento. Também inclui um recurso exclusivo de otimização da mesma memória e dos dados usados.
Por que o TensorFlow é tão popular?
O TensorFlow é bem documentado e inclui muitas bibliotecas de aprendizado de máquina. Ele oferece algumas funcionalidades e métodos importantes para o mesmo.
O TensorFlow também é chamado de produto “Google”. Inclui uma variedade de algoritmos de aprendizado de máquina e aprendizado profundo. O TensorFlow pode treinar e executar redes neurais profundas para classificação de dígitos manuscritos, reconhecimento de imagem, incorporação de palavras e criação de vários modelos de sequência.
Para instalar o TensorFlow, é importante ter o “Python” instalado em seu sistema. O Python versão 3.4+ é considerado o melhor para começar com a instalação do TensorFlow.
Considere as seguintes etapas para instalar o TensorFlow no sistema operacional Windows.
Step 1 - Verifique a versão do Python que está sendo instalada.
Step 2- Um usuário pode escolher qualquer mecanismo para instalar o TensorFlow no sistema. Recomendamos “pip” e “Anaconda”. Pip é um comando usado para executar e instalar módulos em Python.
Antes de instalar o TensorFlow, precisamos instalar o framework Anaconda em nosso sistema.
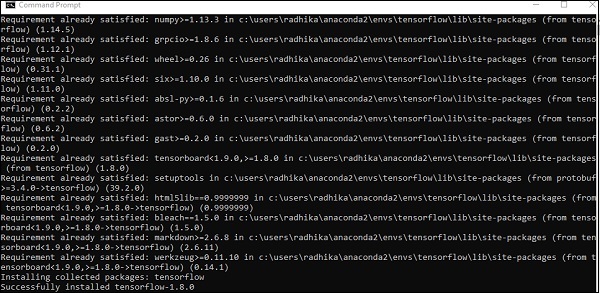
Após a instalação bem-sucedida, verifique no prompt de comando através do comando “conda”. A execução do comando é exibida abaixo -
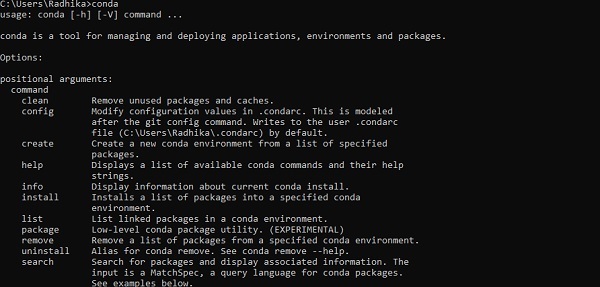
Step 3 - Execute o seguinte comando para inicializar a instalação do TensorFlow -
conda create --name tensorflow python = 3.5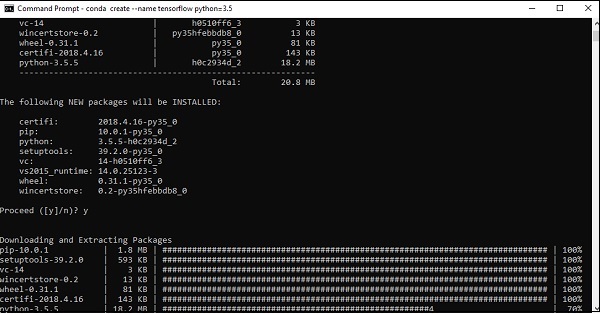
Ele baixa os pacotes necessários para a configuração do TensorFlow.
Step 4 - Após a configuração ambiental bem-sucedida, é importante ativar o módulo TensorFlow.
activate tensorflow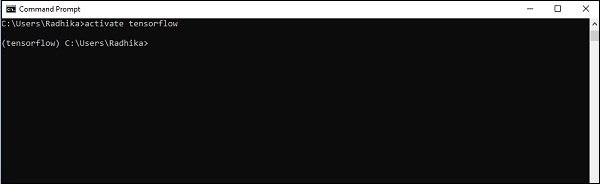
Step 5- Use pip para instalar o “Tensorflow” no sistema. O comando usado para instalação é mencionado abaixo -
pip install tensorflowE,
pip install tensorflow-gpu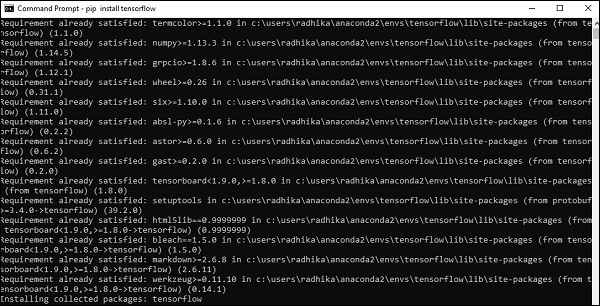
Após a instalação bem-sucedida, é importante conhecer a execução do programa de amostra do TensorFlow.
O exemplo a seguir nos ajuda a entender a criação do programa básico "Hello World" no TensorFlow.
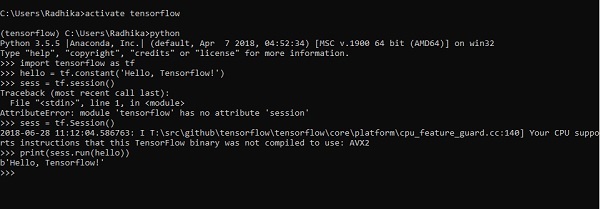
O código para a implementação do primeiro programa é mencionado abaixo -
>> activate tensorflow
>> python (activating python shell)
>> import tensorflow as tf
>> hello = tf.constant(‘Hello, Tensorflow!’)
>> sess = tf.Session()
>> print(sess.run(hello))A Inteligência Artificial inclui o processo de simulação da inteligência humana por máquinas e sistemas de computador especiais. Os exemplos de inteligência artificial incluem aprendizado, raciocínio e autocorreção. As aplicações de IA incluem reconhecimento de voz, sistemas especialistas e reconhecimento de imagem e visão de máquina.
O aprendizado de máquina é o ramo da inteligência artificial, que lida com sistemas e algoritmos que podem aprender quaisquer novos dados e padrões de dados.
Vamos nos concentrar no diagrama de Venn mencionado abaixo para entender os conceitos de aprendizado de máquina e aprendizado profundo.
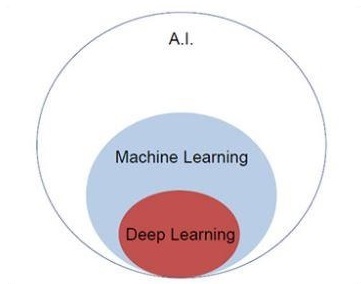
O aprendizado de máquina inclui uma seção de aprendizado de máquina e o aprendizado profundo faz parte do aprendizado de máquina. A capacidade do programa que segue os conceitos de aprendizado de máquina é melhorar o desempenho dos dados observados. O principal motivo da transformação de dados é aprimorar seus conhecimentos para obter melhores resultados no futuro, fornecer uma saída mais próxima da saída desejada para aquele sistema específico. O aprendizado de máquina inclui “reconhecimento de padrão”, que inclui a capacidade de reconhecer os padrões nos dados.
Os padrões devem ser treinados para mostrar a saída da maneira desejável.
O aprendizado de máquina pode ser treinado de duas maneiras diferentes -
- Treinamento supervisionado
- Treinamento não supervisionado
Aprendizagem Supervisionada
A aprendizagem supervisionada ou treinamento supervisionado inclui um procedimento onde o conjunto de treinamento é fornecido como entrada para o sistema, em que cada exemplo é rotulado com um valor de saída desejado. O treinamento neste tipo é executado usando a minimização de uma função de perda particular, que representa o erro de saída em relação ao sistema de saída desejado.
Após a conclusão do treinamento, a precisão de cada modelo é medida em relação aos exemplos separados do conjunto de treinamento, também chamado de conjunto de validação.
O melhor exemplo para ilustrar “Aprendizagem supervisionada” é com um monte de fotos fornecidas com informações nelas incluídas. Aqui, o usuário pode treinar uma modelo para reconhecer novas fotos.
Aprendizagem Não Supervisionada
No aprendizado não supervisionado ou treinamento não supervisionado, inclua exemplos de treinamento, que não são rotulados pelo sistema a qual classe pertencem. O sistema procura os dados que compartilham características comuns e os altera com base em recursos de conhecimento interno. Esse tipo de algoritmo de aprendizagem é usado basicamente em problemas de agrupamento.
O melhor exemplo para ilustrar o “aprendizado não supervisionado” é com um monte de fotos sem informações incluídas e um modelo de treinamento do usuário com classificação e agrupamento. Este tipo de algoritmo de treinamento funciona com suposições, pois nenhuma informação é fornecida.

É importante entender os conceitos matemáticos necessários para o TensorFlow antes de criar o aplicativo básico no TensorFlow. A matemática é considerada o coração de qualquer algoritmo de aprendizado de máquina. É com a ajuda de conceitos centrais da Matemática, uma solução para um algoritmo específico de aprendizado de máquina é definida.
Vetor
Uma matriz de números, que é contínua ou discreta, é definida como um vetor. Algoritmos de aprendizado de máquina lidam com vetores de comprimento fixo para melhor geração de saída.
Os algoritmos de aprendizado de máquina lidam com dados multidimensionais, de modo que os vetores desempenham um papel crucial.

A representação pictórica do modelo vetorial é mostrada abaixo -
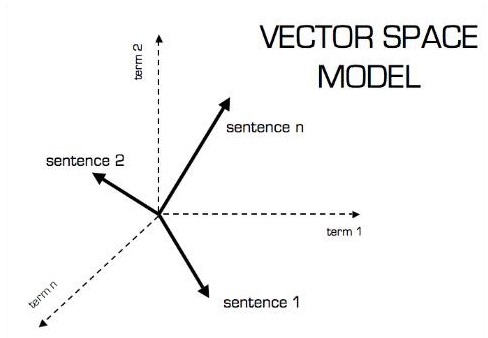
Escalar
O escalar pode ser definido como um vetor unidimensional. Escalares são aqueles que incluem apenas magnitude e nenhuma direção. Com escalares, estamos preocupados apenas com a magnitude.
Exemplos de escalares incluem parâmetros de peso e altura de crianças.
Matriz
Matrix pode ser definida como arrays multidimensionais, que são organizados no formato de linhas e colunas. O tamanho da matriz é definido pelo comprimento da linha e comprimento da coluna. A figura a seguir mostra a representação de qualquer matriz especificada.
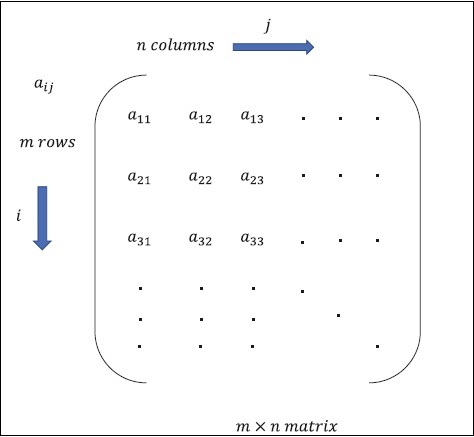
Considere a matriz com “m” linhas e “n” colunas como mencionado acima, a representação da matriz será especificada como “m * n matriz” que definiu o comprimento da matriz também.
Computações Matemáticas
Nesta seção, aprenderemos sobre os diferentes cálculos matemáticos no TensorFlow.
Adição de matrizes
A adição de duas ou mais matrizes é possível se as matrizes forem da mesma dimensão. A adição implica a adição de cada elemento de acordo com a posição fornecida.
Considere o seguinte exemplo para entender como a adição de matrizes funciona -
$$ Exemplo: A = \ begin {bmatrix} 1 e 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 e 6 \\ 7 & 8 \ end {bmatrix} \: então \: A + B = \ begin {bmatrix} 1 + 5 & 2 + 6 \\ 3 + 7 & 4 + 8 \ end {bmatrix} = \ begin {bmatrix} 6 e 8 \\ 10 & 12 \ end {bmatrix} $$
Subtração de matrizes
A subtração de matrizes opera de maneira semelhante, como a adição de duas matrizes. O usuário pode subtrair duas matrizes, desde que as dimensões sejam iguais.
$$ Exemplo: A- \ begin {bmatrix} 1 e 2 \\ 3 & 4 \ end {bmatrix} B- \ begin {bmatrix} 5 e 6 \\ 7 & 8 \ end {bmatrix} \: então \: AB - \ begin {bmatrix} 1-5 e 2-6 \\ 3-7 & 4-8 \ end {bmatrix} - \ begin {bmatrix} -4 e -4 \\ - 4 e -4 \ end {bmatrix} $$
Multiplicação de matrizes
Para que duas matrizes A m * n e B p * q sejam multiplicáveis, n deve ser igual a p. A matriz resultante é -
C m * q
$$ A = \ begin {bmatrix} 1 e 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 e 6 \\ 7 e 8 \ end {bmatrix} $$
$$ c_ {11} = \ begin {bmatrix} 1 e 2 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 1 \ times5 + 2 \ times7 = 19 \: c_ {12} = \ begin {bmatrix} 1 e 2 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 1 \ times6 + 2 \ times8 = 22 $$
$$ c_ {21} = \ begin {bmatrix} 3 & 4 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 3 \ times5 + 4 \ times7 = 43 \: c_ {22} = \ begin {bmatrix} 3 e 4 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 3 \ times6 + 4 \ times8 = 50 $$
$$ C = \ begin {bmatrix} c_ {11} & c_ {12} \\ c_ {21} & c_ {22} \ end {bmatrix} = \ begin {bmatrix} 19 e 22 \\ 43 & 50 \ end {bmatrix} $$
Transpor da matriz
A transposta de uma matriz A, m * n é geralmente representada por AT (transposta) n * m e é obtida pela transposição dos vetores coluna como vetores linha.
$$ Exemplo: A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} \: então \: A ^ {T} \ begin {bmatrix} 1 & 3 \\ 2 & 4 \ end { bmatrix} $$
Produto escalar de vetores
Qualquer vetor de dimensão n pode ser representado como uma matriz v = R ^ n * 1.
$$ v_ {1} = \ begin {bmatrix} v_ {11} \\ v_ {12} \\\ cdot \\\ cdot \\\ cdot \\ v_ {1n} \ end {bmatrix} v_ {2} = \ begin {bmatrix} v_ {21} \\ v_ {22} \\\ cdot \\\ cdot \\\ cdot \\ v_ {2n} \ end {bmatrix} $$
O produto escalar de dois vetores é a soma do produto dos componentes correspondentes - Componentes ao longo da mesma dimensão e podem ser expressos como
$$ v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = v_2 ^ Tv_ {1} = v_ {11} v_ {21} + v_ {12} v_ {22} + \ cdot \ cdot + v_ {1n} v_ {2n} = \ displaystyle \ sum \ limits_ {k = 1} ^ n v_ {1k} v_ {2k} $$
O exemplo de produto escalar de vetores é mencionado abaixo -
$$ Exemplo: v_ {1} = \ begin {bmatrix} 1 \\ 2 \\ 3 \ end {bmatrix} v_ {2} = \ begin {bmatrix} 3 \\ 5 \\ - 1 \ end {bmatrix} v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = 1 \ times3 + 2 \ times5-3 \ times1 = 10 $$
A Inteligência Artificial é uma das tendências mais populares dos últimos tempos. O aprendizado de máquina e o aprendizado profundo constituem inteligência artificial. O diagrama de Venn mostrado abaixo explica a relação entre aprendizado de máquina e aprendizado profundo -
Aprendizado de Máquina
O aprendizado de máquina é a arte da ciência de fazer com que os computadores funcionem de acordo com os algoritmos projetados e programados. Muitos pesquisadores acreditam que o aprendizado de máquina é a melhor maneira de progredir em direção à IA de nível humano. O aprendizado de máquina inclui os seguintes tipos de padrões
- Padrão de aprendizagem supervisionado
- Padrão de aprendizagem não supervisionado
Aprendizado Profundo
O aprendizado profundo é um subcampo do aprendizado de máquina, no qual os algoritmos em questão são inspirados na estrutura e na função do cérebro, chamadas de redes neurais artificiais.
Todo o valor hoje em dia do aprendizado profundo é através do aprendizado supervisionado ou aprendizado de dados e algoritmos rotulados.
Cada algoritmo de aprendizado profundo passa pelo mesmo processo. Inclui uma hierarquia de transformação não linear de entrada que pode ser usada para gerar um modelo estatístico como saída.
Considere as seguintes etapas que definem o processo de aprendizado de máquina
- Identifica conjuntos de dados relevantes e os prepara para análise.
- Escolhe o tipo de algoritmo a usar
- Constrói um modelo analítico com base no algoritmo usado.
- Treina o modelo em conjuntos de dados de teste, revisando-o conforme necessário.
- Executa o modelo para gerar pontuações de teste.
Diferença entre aprendizado de máquina e aprendizado profundo
Nesta seção, aprenderemos sobre a diferença entre aprendizado de máquina e aprendizado profundo.
Quantidade de dados
O aprendizado de máquina funciona com grandes quantidades de dados. É útil também para pequenas quantidades de dados. O aprendizado profundo, por outro lado, funciona de maneira eficiente se a quantidade de dados aumentar rapidamente. O diagrama a seguir mostra o funcionamento do aprendizado de máquina e do aprendizado profundo com a quantidade de dados -
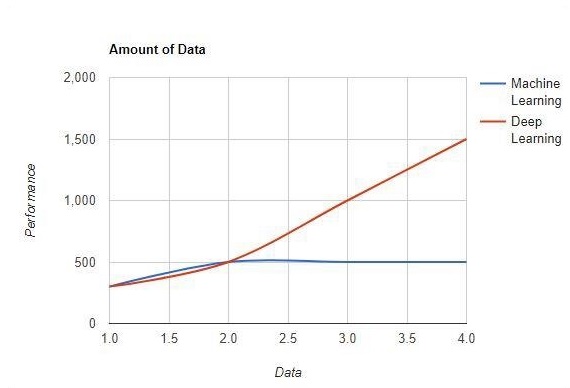
Dependências de Hardware
Os algoritmos de aprendizado profundo são projetados para depender muito de máquinas de última geração, ao contrário dos algoritmos de aprendizado de máquina tradicionais. Algoritmos de aprendizado profundo executam várias operações de multiplicação de matrizes, que requerem uma grande quantidade de suporte de hardware.
Engenharia de Recursos
A engenharia de recursos é o processo de colocar conhecimento de domínio em recursos especificados para reduzir a complexidade dos dados e criar padrões visíveis para os algoritmos de aprendizagem em que funciona.
Exemplo - os padrões de aprendizado de máquina tradicionais se concentram em pixels e outros atributos necessários para o processo de engenharia de recursos. Algoritmos de aprendizado profundo focam em recursos de alto nível de dados. Ele reduz a tarefa de desenvolver um novo extrator de recursos para cada novo problema.
Abordagem de resolução de problemas
Os algoritmos de aprendizado de máquina tradicionais seguem um procedimento padrão para resolver o problema. Ele divide o problema em partes, resolve cada uma delas e as combina para obter o resultado desejado. O aprendizado profundo se concentra em resolver o problema de ponta a ponta, em vez de dividi-los em divisões.
Tempo de execução
O tempo de execução é a quantidade de tempo necessária para treinar um algoritmo. O aprendizado profundo requer muito tempo para treinar, pois inclui muitos parâmetros que levam mais tempo do que o normal. O algoritmo de aprendizado de máquina, comparativamente, requer menos tempo de execução.
Interpretabilidade
A interpretabilidade é o principal fator para comparação de algoritmos de aprendizado de máquina e aprendizado profundo. A principal razão é que o aprendizado profundo ainda é levado em consideração antes de seu uso na indústria.
Aplicações de aprendizado de máquina e aprendizado profundo
Nesta seção, aprenderemos sobre as diferentes aplicações de Aprendizado de Máquina e Aprendizado Profundo.
Visão computacional que é utilizada para reconhecimento facial e marcação de atendimento por meio de impressões digitais ou identificação do veículo por placa.
Recuperação de informações de mecanismos de pesquisa, como pesquisa de texto para pesquisa de imagens.
Marketing de email automatizado com identificação de alvo especificada.
Diagnóstico médico de tumores cancerígenos ou identificação de anomalias de alguma doença crônica.
Processamento de linguagem natural para aplicativos como marcação de fotos. O melhor exemplo para explicar esse cenário é usado no Facebook.
Publicidade on-line.
Tendências futuras
Com a tendência crescente de uso de ciência de dados e aprendizado de máquina no setor, será importante para cada organização inculcar o aprendizado de máquina em seus negócios.
O aprendizado profundo está ganhando mais importância do que o aprendizado de máquina. O aprendizado profundo está provando ser uma das melhores técnicas em performance de última geração.
O aprendizado de máquina e o aprendizado profundo serão benéficos no campo acadêmico e de pesquisa.
Conclusão
Neste artigo, tivemos uma visão geral do aprendizado de máquina e do aprendizado profundo com ilustrações e diferenças também com foco nas tendências futuras. Muitos dos aplicativos de IA utilizam algoritmos de aprendizado de máquina principalmente para conduzir o autoatendimento, aumentar a produtividade do agente e os fluxos de trabalho mais confiáveis. O aprendizado de máquina e os algoritmos de aprendizado profundo incluem uma perspectiva interessante para muitas empresas e líderes do setor.
Neste capítulo, aprenderemos sobre os fundamentos do TensorFlow. Começaremos entendendo a estrutura de dados do tensor.
Estrutura de dados do tensor
Os tensores são usados como estruturas de dados básicas na linguagem TensorFlow. Os tensores representam as bordas de conexão em qualquer diagrama de fluxo denominado Gráfico de fluxo de dados. Os tensores são definidos como matriz ou lista multidimensional.
Os tensores são identificados pelos três parâmetros a seguir -
Classificação
A unidade de dimensionalidade descrita no tensor é chamada de classificação. Ele identifica o número de dimensões do tensor. Uma classificação de um tensor pode ser descrita como a ordem ou n-dimensões de um tensor definido.
Forma
O número de linhas e colunas juntas define a forma do Tensor.
Tipo
Tipo descreve o tipo de dados atribuído aos elementos do Tensor.
Um usuário precisa considerar as seguintes atividades para construir um Tensor -
- Construa uma matriz n-dimensional
- Converta a matriz n-dimensional.
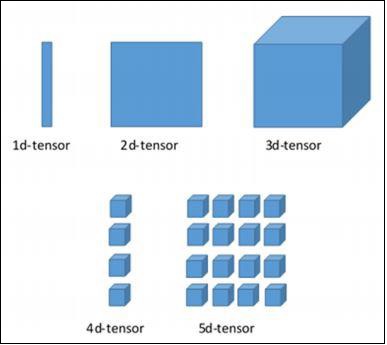
Várias dimensões do TensorFlow
O TensorFlow inclui várias dimensões. As dimensões são descritas resumidamente abaixo -
Tensor unidimensional
Tensor unidimensional é uma estrutura de array normal que inclui um conjunto de valores do mesmo tipo de dados.
Declaration
>>> import numpy as np
>>> tensor_1d = np.array([1.3, 1, 4.0, 23.99])
>>> print tensor_1dA implementação com a saída é mostrada na captura de tela abaixo -
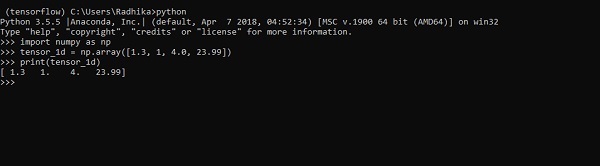
A indexação de elementos é igual às listas Python. O primeiro elemento começa com índice de 0; para imprimir os valores através do índice, basta mencionar o número do índice.
>>> print tensor_1d[0]
1.3
>>> print tensor_1d[2]
4.0
Tensores bidimensionais
A sequência de matrizes é usada para criar “tensores bidimensionais”.
A criação de tensores bidimensionais é descrita abaixo -

A seguir está a sintaxe completa para criar matrizes bidimensionais -
>>> import numpy as np
>>> tensor_2d = np.array([(1,2,3,4),(4,5,6,7),(8,9,10,11),(12,13,14,15)])
>>> print(tensor_2d)
[[ 1 2 3 4]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
>>>Os elementos específicos dos tensores bidimensionais podem ser rastreados com a ajuda do número da linha e do número da coluna especificados como números de índice.
>>> tensor_2d[3][2]
14
Manipulação e manipulação de tensores
Nesta seção, aprenderemos sobre Manipulação e manipulação de tensores.
Para começar, vamos considerar o seguinte código -
import tensorflow as tf
import numpy as np
matrix1 = np.array([(2,2,2),(2,2,2),(2,2,2)],dtype = 'int32')
matrix2 = np.array([(1,1,1),(1,1,1),(1,1,1)],dtype = 'int32')
print (matrix1)
print (matrix2)
matrix1 = tf.constant(matrix1)
matrix2 = tf.constant(matrix2)
matrix_product = tf.matmul(matrix1, matrix2)
matrix_sum = tf.add(matrix1,matrix2)
matrix_3 = np.array([(2,7,2),(1,4,2),(9,0,2)],dtype = 'float32')
print (matrix_3)
matrix_det = tf.matrix_determinant(matrix_3)
with tf.Session() as sess:
result1 = sess.run(matrix_product)
result2 = sess.run(matrix_sum)
result3 = sess.run(matrix_det)
print (result1)
print (result2)
print (result3)Output
O código acima irá gerar a seguinte saída -
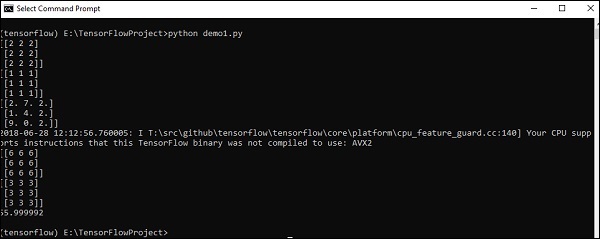
Explicação
Criamos matrizes multidimensionais no código-fonte acima. Agora, é importante entender que criamos o gráfico e as sessões, que gerenciam os tensores e geram a saída apropriada. Com a ajuda do gráfico, temos a saída especificando os cálculos matemáticos entre tensores.
Depois de entender os conceitos de aprendizado de máquina, agora podemos mudar nosso foco para os conceitos de aprendizado profundo. O aprendizado profundo é uma divisão do aprendizado de máquina e é considerado um passo crucial dado pelos pesquisadores nas últimas décadas. Os exemplos de implementação de aprendizado profundo incluem aplicativos como reconhecimento de imagem e reconhecimento de voz.
A seguir estão os dois tipos importantes de redes neurais profundas -
- Redes Neurais Convolucionais
- Redes Neurais Recorrentes
Neste capítulo, vamos nos concentrar na CNN, Redes Neurais Convolucionais.
Redes Neurais Convolucionais
As redes neurais convolucionais são projetadas para processar dados por meio de várias camadas de matrizes. Esse tipo de rede neural é usado em aplicativos como reconhecimento de imagem ou reconhecimento de rosto. A principal diferença entre o CNN e qualquer outra rede neural comum é que o CNN recebe a entrada como uma matriz bidimensional e opera diretamente nas imagens, em vez de focar na extração de recursos em que outras redes neurais se concentram.
A abordagem dominante da CNN inclui soluções para problemas de reconhecimento. Grandes empresas como Google e Facebook têm investido em pesquisa e desenvolvimento para projetos de reconhecimento para realizar atividades com maior agilidade.
Uma rede neural convolucional usa três idéias básicas -
- Respectivos campos locais
- Convolution
- Pooling
Vamos entender essas idéias em detalhes.
A CNN utiliza correlações espaciais que existem nos dados de entrada. Cada camada simultânea de uma rede neural conecta alguns neurônios de entrada. Essa região específica é chamada de campo receptivo local. O campo receptivo local concentra-se nos neurônios ocultos. Os neurônios ocultos processam os dados de entrada dentro do campo mencionado, sem perceber as mudanças fora do limite específico.
A seguir está uma representação de diagrama de geração de respectivos campos locais -
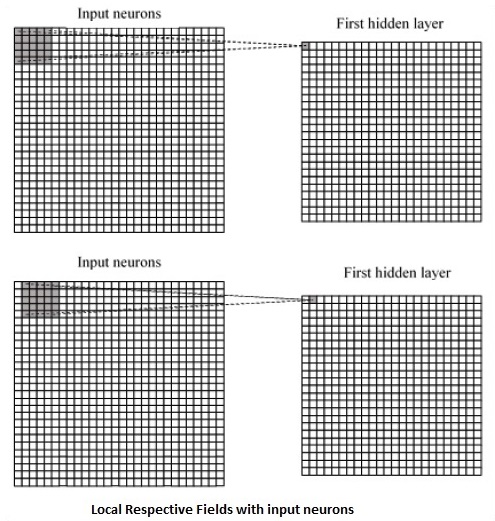
Se observarmos a representação acima, cada conexão aprende um peso do neurônio oculto com uma conexão associada com o movimento de uma camada para outra. Aqui, os neurônios individuais realizam uma mudança de tempos em tempos. Este processo é denominado “convolução”.
O mapeamento de conexões da camada de entrada para o mapa de feições ocultas é definido como “pesos compartilhados” e o viés incluído é chamado de “viés compartilhado”.
CNN ou redes neurais convolucionais usam camadas de pooling, que são as camadas, posicionadas imediatamente após a declaração da CNN. Ele recebe a entrada do usuário como um mapa de características que sai de redes convolucionais e prepara um mapa de características condensado. O agrupamento de camadas ajuda a criar camadas com neurônios de camadas anteriores.
Implementação do TensorFlow de CNN
Nesta seção, aprenderemos sobre a implementação do TensorFlow do CNN. As etapas, que exigem a execução e dimensionamento adequado de toda a rede, são as apresentadas a seguir -
Step 1 - Inclui os módulos necessários para TensorFlow e os módulos de conjunto de dados, que são necessários para calcular o modelo CNN.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_dataStep 2 - Declare uma função chamada run_cnn(), que inclui vários parâmetros e variáveis de otimização com declaração de marcadores de posição de dados. Essas variáveis de otimização irão declarar o padrão de treinamento.
def run_cnn():
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
learning_rate = 0.0001
epochs = 10
batch_size = 50Step 3 - Nesta etapa, declararemos os marcadores de posição de dados de treinamento com parâmetros de entrada - para 28 x 28 pixels = 784. Estes são os dados de imagem nivelada que são extraídos de mnist.train.nextbatch().
Podemos remodelar o tensor de acordo com nossos requisitos. O primeiro valor (-1) diz à função para moldar dinamicamente essa dimensão com base na quantidade de dados transmitidos a ela. As duas dimensões intermediárias são definidas para o tamanho da imagem (ou seja, 28 x 28).
x = tf.placeholder(tf.float32, [None, 784])
x_shaped = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, [None, 10])Step 4 - Agora é importante criar algumas camadas convolucionais -
layer1 = create_new_conv_layer(x_shaped, 1, 32, [5, 5], [2, 2], name = 'layer1')
layer2 = create_new_conv_layer(layer1, 32, 64, [5, 5], [2, 2], name = 'layer2')Step 5- Vamos nivelar a saída pronta para o estágio de saída totalmente conectado - depois de duas camadas de passada 2 agrupando com as dimensões de 28 x 28, para a dimensão de 14 x 14 ou no mínimo 7 x 7 x, coordenadas y, mas com 64 canais de saída. Para criar a camada totalmente conectada com "densa", a nova forma precisa ser [-1, 7 x 7 x 64]. Podemos definir alguns pesos e valores de polarização para esta camada e, em seguida, ativar com ReLU.
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev = 0.03), name = 'wd1')
bd1 = tf.Variable(tf.truncated_normal([1000], stddev = 0.01), name = 'bd1')
dense_layer1 = tf.matmul(flattened, wd1) + bd1
dense_layer1 = tf.nn.relu(dense_layer1)Step 6 - Outra camada com ativações específicas do softmax com o otimizador necessário define a avaliação da precisão, que faz a configuração do operador de inicialização.
wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev = 0.03), name = 'wd2')
bd2 = tf.Variable(tf.truncated_normal([10], stddev = 0.01), name = 'bd2')
dense_layer2 = tf.matmul(dense_layer1, wd2) + bd2
y_ = tf.nn.softmax(dense_layer2)
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = dense_layer2, labels = y))
optimiser = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_op = tf.global_variables_initializer()Step 7- Devemos configurar variáveis de gravação. Isso adiciona um resumo para armazenar a precisão dos dados.
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('E:\TensorFlowProject')
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size = batch_size)
_, c = sess.run([optimiser, cross_entropy], feed_dict = {
x:batch_x, y: batch_y})
avg_cost += c / total_batch
test_acc = sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
summary = sess.run(merged, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
writer.add_summary(summary, epoch)
print("\nTraining complete!")
writer.add_graph(sess.graph)
print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels}))
def create_new_conv_layer(
input_data, num_input_channels, num_filters,filter_shape, pool_shape, name):
conv_filt_shape = [
filter_shape[0], filter_shape[1], num_input_channels, num_filters]
weights = tf.Variable(
tf.truncated_normal(conv_filt_shape, stddev = 0.03), name = name+'_W')
bias = tf.Variable(tf.truncated_normal([num_filters]), name = name+'_b')
#Out layer defines the output
out_layer =
tf.nn.conv2d(input_data, weights, [1, 1, 1, 1], padding = 'SAME')
out_layer += bias
out_layer = tf.nn.relu(out_layer)
ksize = [1, pool_shape[0], pool_shape[1], 1]
strides = [1, 2, 2, 1]
out_layer = tf.nn.max_pool(
out_layer, ksize = ksize, strides = strides, padding = 'SAME')
return out_layer
if __name__ == "__main__":
run_cnn()A seguir está a saída gerada pelo código acima -
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-19 17:22:58.802268: I
T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2
2018-09-19 17:25:41.522845: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.
2018-09-19 17:25:44.630941: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 501760000 exceeds 10% of system memory.
Epoch: 1 cost = 0.676 test accuracy: 0.940
2018-09-19 17:26:51.987554: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.Redes neurais recorrentes são um tipo de algoritmo orientado para aprendizagem profunda, que segue uma abordagem sequencial. Em redes neurais, sempre assumimos que cada entrada e saída é independente de todas as outras camadas. Esses tipos de redes neurais são chamados de recorrentes porque executam cálculos matemáticos de maneira sequencial.
Considere as seguintes etapas para treinar uma rede neural recorrente -
Step 1 - Insira um exemplo específico do conjunto de dados.
Step 2 - A rede pegará um exemplo e calculará alguns cálculos usando variáveis inicializadas aleatoriamente.
Step 3 - Um resultado previsto é então calculado.
Step 4 - A comparação do resultado real gerado com o valor esperado produzirá um erro.
Step 5 - Para rastrear o erro, ele é propagado pelo mesmo caminho onde as variáveis também são ajustadas.
Step 6 - As etapas de 1 a 5 são repetidas até que tenhamos certeza de que as variáveis declaradas para obter a saída estão definidas corretamente.
Step 7 - Uma previsão sistemática é feita aplicando essas variáveis para obter uma nova entrada invisível.
A abordagem esquemática de representação de redes neurais recorrentes é descrita abaixo -
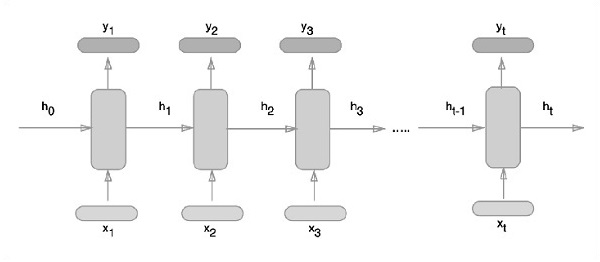
Implementação de rede neural recorrente com TensorFlow
Nesta seção, aprenderemos como implementar uma rede neural recorrente com o TensorFlow.
Step 1 - TensorFlow inclui várias bibliotecas para implementação específica do módulo de rede neural recorrente.
#Import necessary modules
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)Conforme mencionado acima, as bibliotecas ajudam a definir os dados de entrada, que constituem a parte principal da implementação da rede neural recorrente.
Step 2- Nosso motivo principal é classificar as imagens usando uma rede neural recorrente, onde consideramos cada linha de imagem como uma sequência de pixels. O formato da imagem MNIST é especificamente definido como 28 * 28 px. Agora lidaremos com 28 sequências de 28 etapas para cada amostra mencionada. Vamos definir os parâmetros de entrada para concluir o padrão sequencial.
n_input = 28 # MNIST data input with img shape 28*28
n_steps = 28
n_hidden = 128
n_classes = 10
# tf Graph input
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes]
weights = {
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([n_classes]))
}Step 3- Calcule os resultados usando uma função definida no RNN para obter os melhores resultados. Aqui, cada formato de dados é comparado com o formato de entrada atual e os resultados são calculados para manter a taxa de precisão.
def RNN(x, weights, biases):
x = tf.unstack(x, n_steps, 1)
# Define a lstm cell with tensorflow
lstm_cell = rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)
# Get lstm cell output
outputs, states = rnn.static_rnn(lstm_cell, x, dtype = tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
pred = RNN(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()Step 4- Nesta etapa, lançaremos o gráfico para obter os resultados computacionais. Isso também ajuda no cálculo da precisão dos resultados do teste.
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={x: test_data, y: test_label}))As imagens abaixo mostram a saída gerada -
O TensorFlow inclui uma ferramenta de visualização, chamada TensorBoard. É usado para analisar o gráfico de fluxo de dados e também para entender modelos de aprendizado de máquina. O recurso importante do TensorBoard inclui uma visualização de diferentes tipos de estatísticas sobre os parâmetros e detalhes de qualquer gráfico em alinhamento vertical.
A rede neural profunda inclui até 36.000 nós. O TensorBoard ajuda a recolher esses nós em blocos de alto nível e destacar as estruturas idênticas. Isso permite uma melhor análise do gráfico com foco nas seções primárias do gráfico de computação. A visualização do TensorBoard é considerada muito interativa, em que um usuário pode aplicar panorâmica, zoom e expandir os nós para exibir os detalhes.
A representação do diagrama esquemático a seguir mostra o funcionamento completo da visualização do TensorBoard -
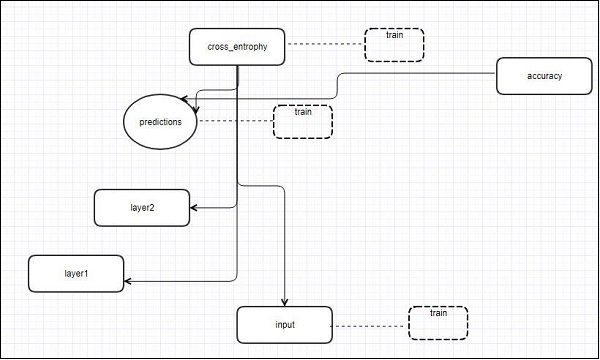
Os algoritmos reduzem os nós em blocos de alto nível e destacam os grupos específicos com estruturas idênticas, que separam os nós de alto grau. O TensorBoard assim criado é útil e tratado de forma igualmente importante para ajustar um modelo de aprendizado de máquina. Esta ferramenta de visualização é projetada para o arquivo de log de configuração com informações resumidas e detalhes que precisam ser exibidos.
Vamos nos concentrar no exemplo de demonstração da visualização do TensorBoard com a ajuda do seguinte código -
import tensorflow as tf
# Constants creation for TensorBoard visualization
a = tf.constant(10,name = "a")
b = tf.constant(90,name = "b")
y = tf.Variable(a+b*2,name = 'y')
model = tf.initialize_all_variables() #Creation of model
with tf.Session() as session:
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("/tmp/tensorflowlogs",session.graph)
session.run(model)
print(session.run(y))A tabela a seguir mostra os vários símbolos de visualização do TensorBoard usados para a representação do nó -

Embedding de palavras é o conceito de mapeamento de objetos discretos, como palavras, para vetores e números reais. É importante como contribuição para o aprendizado de máquina. O conceito inclui funções padrão, que efetivamente transformam objetos de entrada discretos em vetores úteis.
O exemplo de ilustração de entrada de incorporação de palavras é mostrado abaixo -
blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259)
blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158)
orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213)
oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976)Word2vec
Word2vec é a abordagem mais comum usada para a técnica de incorporação de palavras não supervisionada. Ele treina o modelo de forma que uma determinada palavra de entrada preveja o contexto da palavra usando skip-gramas.
O TensorFlow permite muitas maneiras de implementar esse tipo de modelo com níveis crescentes de sofisticação e otimização e usando conceitos de multithreading e abstrações de nível superior.
import os
import math
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
batch_size = 64
embedding_dimension = 5
negative_samples = 8
LOG_DIR = "logs/word2vec_intro"
digit_to_word_map = {
1: "One",
2: "Two",
3: "Three",
4: "Four",
5: "Five",
6: "Six",
7: "Seven",
8: "Eight",
9: "Nine"}
sentences = []
# Create two kinds of sentences - sequences of odd and even digits.
for i in range(10000):
rand_odd_ints = np.random.choice(range(1, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_odd_ints]))
rand_even_ints = np.random.choice(range(2, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_even_ints]))
# Map words to indices
word2index_map = {}
index = 0
for sent in sentences:
for word in sent.lower().split():
if word not in word2index_map:
word2index_map[word] = index
index += 1
index2word_map = {index: word for word, index in word2index_map.items()}
vocabulary_size = len(index2word_map)
# Generate skip-gram pairs
skip_gram_pairs = []
for sent in sentences:
tokenized_sent = sent.lower().split()
for i in range(1, len(tokenized_sent)-1):
word_context_pair = [[word2index_map[tokenized_sent[i-1]],
word2index_map[tokenized_sent[i+1]]], word2index_map[tokenized_sent[i]]]
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][0]])
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][1]])
def get_skipgram_batch(batch_size):
instance_indices = list(range(len(skip_gram_pairs)))
np.random.shuffle(instance_indices)
batch = instance_indices[:batch_size]
x = [skip_gram_pairs[i][0] for i in batch]
y = [[skip_gram_pairs[i][1]] for i in batch]
return x, y
# batch example
x_batch, y_batch = get_skipgram_batch(8)
x_batch
y_batch
[index2word_map[word] for word in x_batch] [index2word_map[word[0]] for word in y_batch]
# Input data, labels train_inputs = tf.placeholder(tf.int32, shape = [batch_size])
train_labels = tf.placeholder(tf.int32, shape = [batch_size, 1])
# Embedding lookup table currently only implemented in CPU with
tf.name_scope("embeddings"):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_dimension], -1.0, 1.0),
name = 'embedding')
# This is essentialy a lookup table
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Create variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_dimension], stddev = 1.0 /
math.sqrt(embedding_dimension)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(
tf.nn.nce_loss(weights = nce_weights, biases = nce_biases, inputs = embed,
labels = train_labels,num_sampled = negative_samples,
num_classes = vocabulary_size)) tf.summary.scalar("NCE_loss", loss)
# Learning rate decay
global_step = tf.Variable(0, trainable = False)
learningRate = tf.train.exponential_decay(learning_rate = 0.1,
global_step = global_step, decay_steps = 1000, decay_rate = 0.95, staircase = True)
train_step = tf.train.GradientDescentOptimizer(learningRate).minimize(loss)
merged = tf.summary.merge_all()
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(LOG_DIR,
graph = tf.get_default_graph())
saver = tf.train.Saver()
with open(os.path.join(LOG_DIR, 'metadata.tsv'), "w") as metadata:
metadata.write('Name\tClass\n') for k, v in index2word_map.items():
metadata.write('%s\t%d\n' % (v, k))
config = projector.ProjectorConfig()
embedding = config.embeddings.add() embedding.tensor_name = embeddings.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv')
projector.visualize_embeddings(train_writer, config)
tf.global_variables_initializer().run()
for step in range(1000):
x_batch, y_batch = get_skipgram_batch(batch_size) summary, _ = sess.run(
[merged, train_step], feed_dict = {train_inputs: x_batch, train_labels: y_batch})
train_writer.add_summary(summary, step)
if step % 100 == 0:
saver.save(sess, os.path.join(LOG_DIR, "w2v_model.ckpt"), step)
loss_value = sess.run(loss, feed_dict = {
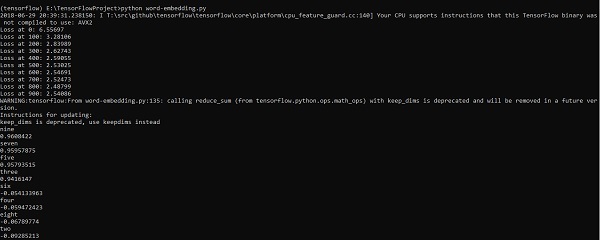
train_inputs: x_batch, train_labels: y_batch})
print("Loss at %d: %.5f" % (step, loss_value))
# Normalize embeddings before using
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims = True))
normalized_embeddings = embeddings /
norm normalized_embeddings_matrix = sess.run(normalized_embeddings)
ref_word = normalized_embeddings_matrix[word2index_map["one"]]
cosine_dists = np.dot(normalized_embeddings_matrix, ref_word)
ff = np.argsort(cosine_dists)[::-1][1:10] for f in ff: print(index2word_map[f])
print(cosine_dists[f])Resultado
O código acima gera a seguinte saída -
Para entender o perceptron de camada única, é importante entender as Redes Neurais Artificiais (RNA). Redes neurais artificiais são o sistema de processamento de informações cujo mecanismo é inspirado na funcionalidade de circuitos neurais biológicos. Uma rede neural artificial possui muitas unidades de processamento conectadas umas às outras. A seguir está a representação esquemática da rede neural artificial -
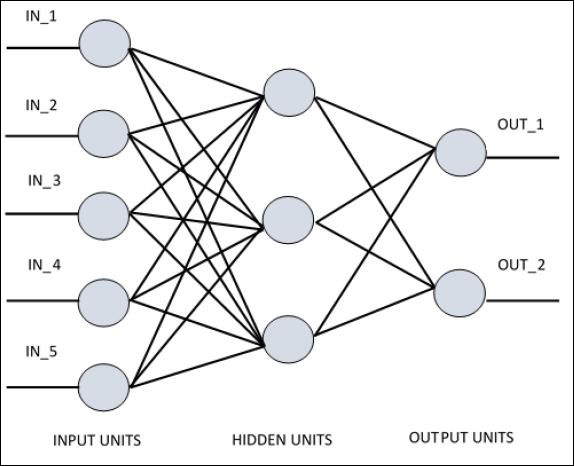
O diagrama mostra que as unidades ocultas se comunicam com a camada externa. Enquanto as unidades de entrada e saída se comunicam apenas por meio da camada oculta da rede.
O padrão de conexão com os nós, o número total de camadas e o nível de nós entre entradas e saídas com o número de neurônios por camada definem a arquitetura de uma rede neural.
Existem dois tipos de arquitetura. Esses tipos se concentram na funcionalidade de redes neurais artificiais da seguinte maneira -
- Perceptron de Camada Única
- Perceptron Multi-Camada
Perceptron de Camada Única
Perceptron de camada única é o primeiro modelo neural proposto criado. O conteúdo da memória local do neurônio consiste em um vetor de pesos. O cálculo de um perceptron de camada única é realizado sobre o cálculo da soma do vetor de entrada, cada um com o valor multiplicado pelo elemento correspondente do vetor dos pesos. O valor exibido na saída será a entrada de uma função de ativação.

Vamos nos concentrar na implementação do perceptron de camada única para um problema de classificação de imagem usando o TensorFlow. O melhor exemplo para ilustrar o perceptron de camada única é através da representação de “Regressão Logística”.
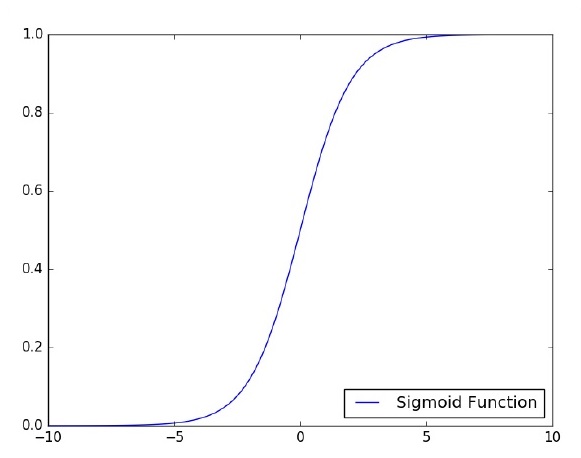
Agora, vamos considerar as seguintes etapas básicas de regressão logística de treinamento -
Os pesos são inicializados com valores aleatórios no início do treinamento.
Para cada elemento do conjunto de treinamento, o erro é calculado com a diferença entre a saída desejada e a saída real. O erro calculado é usado para ajustar os pesos.
O processo é repetido até que o erro cometido em todo o conjunto de treinamento não seja inferior ao limite especificado, até que o número máximo de iterações seja atingido.
O código completo para avaliação de regressão logística é mencionado abaixo -
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder("float", [None, 784]) # mnist data image of shape 28*28 = 784
y = tf.placeholder("float", [None, 10]) # 0-9 digits recognition => 10 classes
# Create model
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Construct model
activation = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
# Minimize error using cross entropy
cross_entropy = y*tf.log(activation)
cost = tf.reduce_mean\ (-tf.reduce_sum\ (cross_entropy,reduction_indices = 1))
optimizer = tf.train.\ GradientDescentOptimizer(learning_rate).minimize(cost)
#Plot settings
avg_set = []
epoch_set = []
# Initializing the variables init = tf.initialize_all_variables()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = \ mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, \ feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss avg_cost += sess.run(cost, \ feed_dict = {
x: batch_xs, \ y: batch_ys})/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
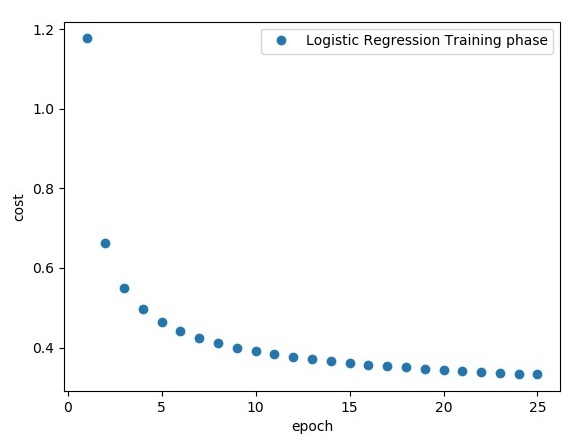
print ("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
avg_set.append(avg_cost) epoch_set.append(epoch+1)
print ("Training phase finished")
plt.plot(epoch_set,avg_set, 'o', label = 'Logistic Regression Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(activation, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print
("Model accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))Resultado
O código acima gera a seguinte saída -
A regressão logística é considerada uma análise preditiva. A regressão logística é usada para descrever os dados e explicar a relação entre uma variável binária dependente e uma ou mais variáveis nominais ou independentes.
Neste capítulo, vamos nos concentrar no exemplo básico de implementação de regressão linear usando o TensorFlow. A regressão logística ou regressão linear é uma abordagem de aprendizado de máquina supervisionada para a classificação de categorias discretas de ordem. Nosso objetivo neste capítulo é construir um modelo pelo qual um usuário pode prever o relacionamento entre variáveis preditoras e uma ou mais variáveis independentes.
A relação entre essas duas variáveis é considerada linear. Se y for a variável dependente e x for considerado a variável independente, então a relação de regressão linear de duas variáveis será semelhante à seguinte equação -
Y = Ax+bVamos projetar um algoritmo para regressão linear. Isso nos permitirá entender os seguintes dois conceitos importantes -
- Função de Custo
- Algoritmos de descida gradiente
A representação esquemática da regressão linear é mencionada abaixo -

A visão gráfica da equação de regressão linear é mencionada abaixo -
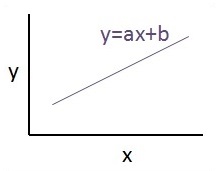
Etapas para projetar um algoritmo de regressão linear
Agora aprenderemos sobre as etapas que ajudam no projeto de um algoritmo de regressão linear.
Passo 1
É importante importar os módulos necessários para traçar o módulo de regressão linear. Começamos a importar a biblioteca Python NumPy e Matplotlib.
import numpy as np
import matplotlib.pyplot as pltPasso 2
Defina o número de coeficientes necessários para a regressão logística.
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78etapa 3
Repita as variáveis para gerar 300 pontos aleatórios em torno da equação de regressão -
Y = 0,22x + 0,78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])Passo 4
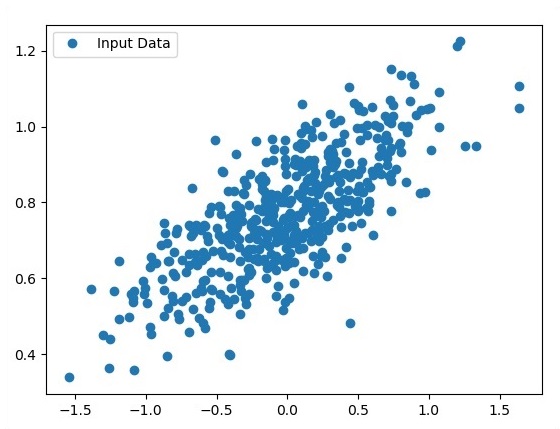
Veja os pontos gerados usando Matplotlib.
fplt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend() plt.show()O código completo para regressão logística é o seguinte -
import numpy as np
import matplotlib.pyplot as plt
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])
plt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend()
plt.show()O número de pontos considerados como entrada é considerado como dados de entrada.
O TFLearn pode ser definido como um aspecto de aprendizado profundo modular e transparente usado na estrutura do TensorFlow. O principal motivo do TFLearn é fornecer uma API de nível superior ao TensorFlow para facilitar e mostrar novos experimentos.
Considere os seguintes recursos importantes do TFLearn -
TFLearn é fácil de usar e entender.
Inclui conceitos fáceis para construir camadas de rede altamente modulares, otimizadores e várias métricas incorporadas a eles.
Inclui transparência total com o sistema de trabalho TensorFlow.
Inclui funções auxiliares poderosas para treinar os tensores integrados que aceitam múltiplas entradas, saídas e otimizadores.
Inclui visualização gráfica fácil e bonita.
A visualização do gráfico inclui vários detalhes de pesos, gradientes e ativações.
Instale o TFLearn executando o seguinte comando -
pip install tflearnApós a execução do código acima, a seguinte saída será gerada -
A ilustração a seguir mostra a implementação do TFLearn com o classificador Random Forest -
from __future__ import division, print_function, absolute_import
#TFLearn module implementation
import tflearn
from tflearn.estimators import RandomForestClassifier
# Data loading and pre-processing with respect to dataset
import tflearn.datasets.mnist as mnist
X, Y, testX, testY = mnist.load_data(one_hot = False)
m = RandomForestClassifier(n_estimators = 100, max_nodes = 1000)
m.fit(X, Y, batch_size = 10000, display_step = 10)
print("Compute the accuracy on train data:")
print(m.evaluate(X, Y, tflearn.accuracy_op))
print("Compute the accuracy on test set:")
print(m.evaluate(testX, testY, tflearn.accuracy_op))
print("Digits for test images id 0 to 5:")
print(m.predict(testX[:5]))
print("True digits:")
print(testY[:5])Neste capítulo, vamos nos concentrar na diferença entre CNN e RNN -
| CNN | RNN |
|---|---|
| É adequado para dados espaciais, como imagens. | RNN é adequado para dados temporais, também chamados de dados sequenciais. |
| A CNN é considerada mais poderosa do que a RNN. | O RNN inclui menos compatibilidade de recursos quando comparado ao CNN. |
| Essa rede aceita entradas de tamanho fixo e gera saídas de tamanho fixo. | RNN pode lidar com comprimentos de entrada / saída arbitrários. |
| CNN é um tipo de rede neural artificial feed-forward com variações de perceptrons multicamadas projetadas para usar quantidades mínimas de pré-processamento. | RNN, ao contrário de redes neurais de alimentação direta - pode usar sua memória interna para processar sequências arbitrárias de entradas. |
| CNNs usam padrão de conectividade entre os neurônios. Isso é inspirado pela organização do córtex visual animal, cujos neurônios individuais são organizados de tal maneira que respondem a regiões sobrepostas que formam o campo visual. | As redes neurais recorrentes usam informações de série temporal - o que um usuário falou por último terá impacto sobre o que ele falará em seguida. |
| CNNs são ideais para processamento de imagens e vídeo. | Os RNNs são ideais para análise de texto e fala. |
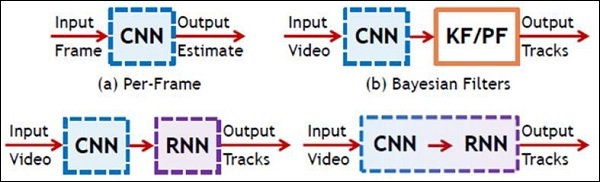
A ilustração a seguir mostra a representação esquemática da CNN e RNN -
Keras é uma biblioteca Python compacta, fácil de aprender e de alto nível executada na estrutura do TensorFlow. É feito com foco no entendimento de técnicas de aprendizado profundo, como a criação de camadas para redes neurais mantendo os conceitos de formas e detalhes matemáticos. A criação de freamework pode ser dos seguintes dois tipos -
- API sequencial
- API funcional
Considere as oito etapas a seguir para criar um modelo de aprendizado profundo no Keras -
- Carregando os dados
- Pré-processar os dados carregados
- Definição de modelo
- Compilando o modelo
- Ajustar ao modelo especificado
- Avalie
- Faça as previsões necessárias
- Salve o modelo
Usaremos o Jupyter Notebook para execução e exibição da saída conforme mostrado abaixo -
Step 1 - O carregamento dos dados e o pré-processamento dos dados carregados são implementados primeiro para executar o modelo de aprendizado profundo.
import warnings
warnings.filterwarnings('ignore')
import numpy as np
np.random.seed(123) # for reproducibility
from keras.models import Sequential
from keras.layers import Flatten, MaxPool2D, Conv2D, Dense, Reshape, Dropout
from keras.utils import np_utils
Using TensorFlow backend.
from keras.datasets import mnist
# Load pre-shuffled MNIST data into train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)Esta etapa pode ser definida como “Importar bibliotecas e módulos”, o que significa que todas as bibliotecas e módulos são importados como uma etapa inicial.
Step 2 - Nesta etapa, vamos definir a arquitetura do modelo -
model = Sequential()
model.add(Conv2D(32, 3, 3, activation = 'relu', input_shape = (28,28,1)))
model.add(Conv2D(32, 3, 3, activation = 'relu'))
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Step 3 - Vamos agora compilar o modelo especificado -
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])Step 4 - Agora ajustaremos o modelo usando dados de treinamento -
model.fit(X_train, Y_train, batch_size = 32, epochs = 10, verbose = 1)A saída das iterações criadas é a seguinte -
Epoch 1/10 60000/60000 [==============================] - 65s -
loss: 0.2124 -
acc: 0.9345
Epoch 2/10 60000/60000 [==============================] - 62s -
loss: 0.0893 -
acc: 0.9740
Epoch 3/10 60000/60000 [==============================] - 58s -
loss: 0.0665 -
acc: 0.9802
Epoch 4/10 60000/60000 [==============================] - 62s -
loss: 0.0571 -
acc: 0.9830
Epoch 5/10 60000/60000 [==============================] - 62s -
loss: 0.0474 -
acc: 0.9855
Epoch 6/10 60000/60000 [==============================] - 59s -
loss: 0.0416 -
acc: 0.9871
Epoch 7/10 60000/60000 [==============================] - 61s -
loss: 0.0380 -
acc: 0.9877
Epoch 8/10 60000/60000 [==============================] - 63s -
loss: 0.0333 -
acc: 0.9895
Epoch 9/10 60000/60000 [==============================] - 64s -
loss: 0.0325 -
acc: 0.9898
Epoch 10/10 60000/60000 [==============================] - 60s -
loss: 0.0284 -
acc: 0.9910Este capítulo se concentrará em como começar a usar o TensorFlow distribuído. O objetivo é ajudar os desenvolvedores a compreender os conceitos básicos de TF distribuídos que são recorrentes, como os servidores TF. Usaremos o Jupyter Notebook para avaliar o TensorFlow distribuído. A implementação da computação distribuída com TensorFlow é mencionada abaixo -
Step 1 - Importe os módulos necessários obrigatórios para computação distribuída -
import tensorflow as tfStep 2- Crie um cluster TensorFlow com um nó. Deixe este nó ser responsável por um trabalho que tem o nome "trabalhador" e que irá operar uma tomada em localhost: 2222.
cluster_spec = tf.train.ClusterSpec({'worker' : ['localhost:2222']})
server = tf.train.Server(cluster_spec)
server.targetOs scripts acima geram a seguinte saída -
'grpc://localhost:2222'
The server is currently running.Step 3 - A configuração do servidor com a respectiva sessão pode ser calculada executando o seguinte comando -
server.server_defO comando acima gera a seguinte saída -
cluster {
job {
name: "worker"
tasks {
value: "localhost:2222"
}
}
}
job_name: "worker"
protocol: "grpc"Step 4- Inicie uma sessão do TensorFlow com o mecanismo de execução sendo o servidor. Use o TensorFlow para criar um servidor local e uselsof para descobrir a localização do servidor.
sess = tf.Session(target = server.target)
server = tf.train.Server.create_local_server()Step 5 - Visualize os dispositivos disponíveis nesta sessão e feche a respectiva sessão.
devices = sess.list_devices()
for d in devices:
print(d.name)
sess.close()O comando acima gera a seguinte saída -
/job:worker/replica:0/task:0/device:CPU:0Aqui, vamos nos concentrar na formação do MetaGraph no TensorFlow. Isso nos ajudará a entender o módulo de exportação no TensorFlow. O MetaGraph contém as informações básicas necessárias para treinar, realizar avaliação ou executar inferência em um gráfico previamente treinado.
A seguir está o snippet de código para o mesmo -
def export_meta_graph(filename = None, collection_list = None, as_text = False):
"""this code writes `MetaGraphDef` to save_path/filename.
Arguments:
filename: Optional meta_graph filename including the path. collection_list:
List of string keys to collect. as_text: If `True`,
writes the meta_graph as an ASCII proto.
Returns:
A `MetaGraphDef` proto. """Um dos modelos de uso típico para o mesmo é mencionado abaixo -
# Build the model ...
with tf.Session() as sess:
# Use the model ...
# Export the model to /tmp/my-model.meta.
meta_graph_def = tf.train.export_meta_graph(filename = '/tmp/my-model.meta')Perceptron Multi-Layer define a arquitetura mais complicada de redes neurais artificiais. É substancialmente formado por múltiplas camadas de perceptron.
A representação diagramática da aprendizagem perceptron multicamadas é mostrada abaixo -
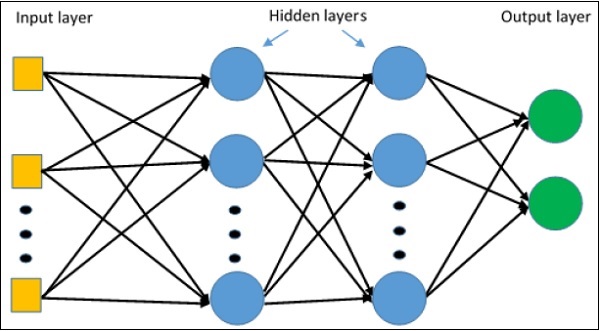
As redes MLP geralmente são usadas para o formato de aprendizagem supervisionada. Um algoritmo de aprendizado típico para redes MLP também é chamado de algoritmo de propagação reversa.
Agora, vamos nos concentrar na implementação com MLP para um problema de classificação de imagens.
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.001
training_epochs = 20
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256
# 1st layer num features
n_hidden_2 = 256 # 2nd layer num features
n_input = 784 # MNIST data input (img shape: 28*28) n_classes = 10
# MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
# weights layer 1
h = tf.Variable(tf.random_normal([n_input, n_hidden_1])) # bias layer 1
bias_layer_1 = tf.Variable(tf.random_normal([n_hidden_1]))
# layer 1 layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, h), bias_layer_1))
# weights layer 2
w = tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2]))
# bias layer 2
bias_layer_2 = tf.Variable(tf.random_normal([n_hidden_2]))
# layer 2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, w), bias_layer_2))
# weights output layer
output = tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
# biar output layer
bias_output = tf.Variable(tf.random_normal([n_classes])) # output layer
output_layer = tf.matmul(layer_2, output) + bias_output
# cost function
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = output_layer, labels = y))
#cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(output_layer, y))
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# optimizer = tf.train.GradientDescentOptimizer(
learning_rate = learning_rate).minimize(cost)
# Plot settings
avg_set = []
epoch_set = []
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples / batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss
avg_cost += sess.run(cost, feed_dict = {x: batch_xs, y: batch_ys}) / total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print
Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost)
avg_set.append(avg_cost)
epoch_set.append(epoch + 1)
print
"Training phase finished"
plt.plot(epoch_set, avg_set, 'o', label = 'MLP Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(output_layer, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print
"Model Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels})A linha de código acima gera a seguinte saída -
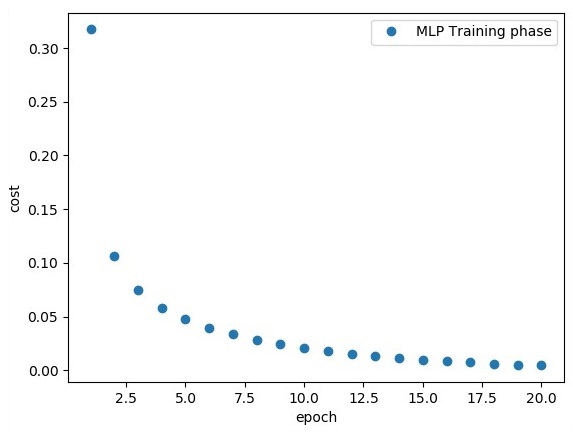
Neste capítulo, vamos nos concentrar na rede que teremos que aprender com um conjunto conhecido de pontos chamados x e f (x). Uma única camada oculta construirá essa rede simples.
O código para a explicação das camadas ocultas do perceptron é mostrado abaixo -
#Importing the necessary modules
import tensorflow as tf
import numpy as np
import math, random
import matplotlib.pyplot as plt
np.random.seed(1000)
function_to_learn = lambda x: np.cos(x) + 0.1*np.random.randn(*x.shape)
layer_1_neurons = 10
NUM_points = 1000
#Training the parameters
batch_size = 100
NUM_EPOCHS = 1500
all_x = np.float32(np.random.uniform(-2*math.pi, 2*math.pi, (1, NUM_points))).T
np.random.shuffle(all_x)
train_size = int(900)
#Training the first 700 points in the given set x_training = all_x[:train_size]
y_training = function_to_learn(x_training)
#Training the last 300 points in the given set x_validation = all_x[train_size:]
y_validation = function_to_learn(x_validation)
plt.figure(1)
plt.scatter(x_training, y_training, c = 'blue', label = 'train')
plt.scatter(x_validation, y_validation, c = 'pink', label = 'validation')
plt.legend()
plt.show()
X = tf.placeholder(tf.float32, [None, 1], name = "X")
Y = tf.placeholder(tf.float32, [None, 1], name = "Y")
#first layer
#Number of neurons = 10
w_h = tf.Variable(
tf.random_uniform([1, layer_1_neurons],\ minval = -1, maxval = 1, dtype = tf.float32))
b_h = tf.Variable(tf.zeros([1, layer_1_neurons], dtype = tf.float32))
h = tf.nn.sigmoid(tf.matmul(X, w_h) + b_h)
#output layer
#Number of neurons = 10
w_o = tf.Variable(
tf.random_uniform([layer_1_neurons, 1],\ minval = -1, maxval = 1, dtype = tf.float32))
b_o = tf.Variable(tf.zeros([1, 1], dtype = tf.float32))
#build the model
model = tf.matmul(h, w_o) + b_o
#minimize the cost function (model - Y)
train_op = tf.train.AdamOptimizer().minimize(tf.nn.l2_loss(model - Y))
#Start the Learning phase
sess = tf.Session() sess.run(tf.initialize_all_variables())
errors = []
for i in range(NUM_EPOCHS):
for start, end in zip(range(0, len(x_training), batch_size),\
range(batch_size, len(x_training), batch_size)):
sess.run(train_op, feed_dict = {X: x_training[start:end],\ Y: y_training[start:end]})
cost = sess.run(tf.nn.l2_loss(model - y_validation),\ feed_dict = {X:x_validation})
errors.append(cost)
if i%100 == 0:
print("epoch %d, cost = %g" % (i, cost))
plt.plot(errors,label='MLP Function Approximation') plt.xlabel('epochs')
plt.ylabel('cost')
plt.legend()
plt.show()Resultado
A seguir está a representação da aproximação da camada de função -
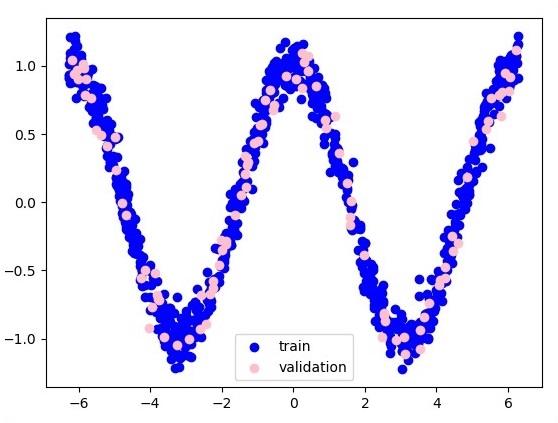
Aqui, dois dados são representados em forma de W. Os dois dados são: trem e validação, que são representados em cores distintas, conforme visíveis na seção da legenda.
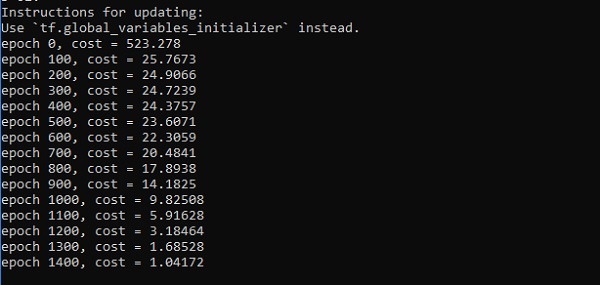
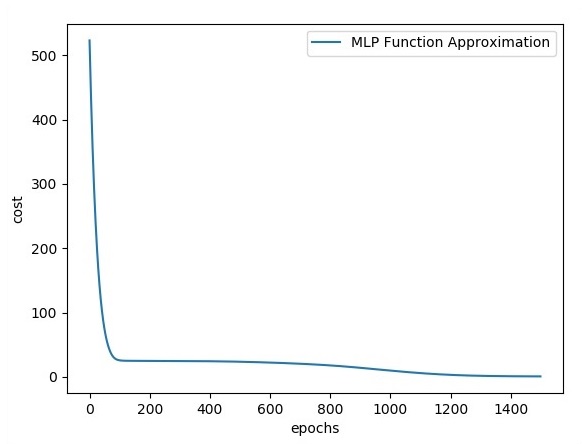
Otimizadores são a classe estendida, que inclui informações adicionais para treinar um modelo específico. A classe do otimizador é inicializada com parâmetros fornecidos, mas é importante lembrar que nenhum Tensor é necessário. Os otimizadores são usados para melhorar a velocidade e o desempenho para treinar um modelo específico.
O otimizador básico do TensorFlow é -
tf.train.OptimizerEsta classe é definida no caminho especificado de tensorflow / python / training / optimizer.py.
A seguir estão alguns otimizadores no Tensorflow -
- Descida do gradiente estocástico
- Descida do gradiente estocástico com recorte de gradiente
- Momentum
- Momento de Nesterov
- Adagrad
- Adadelta
- RMSProp
- Adam
- Adamax
- SMORMS3
Vamos nos concentrar na descida do Gradiente Estocástico. A ilustração para criar um otimizador para o mesmo é mencionada abaixo -
def sgd(cost, params, lr = np.float32(0.01)):
g_params = tf.gradients(cost, params)
updates = []
for param, g_param in zip(params, g_params):
updates.append(param.assign(param - lr*g_param))
return updatesOs parâmetros básicos são definidos dentro da função específica. Em nosso capítulo subsequente, vamos nos concentrar na Otimização de Gradiente Descendente com implementação de otimizadores.
Neste capítulo, aprenderemos sobre a implementação de XOR usando TensorFlow. Antes de começar a implementação do XOR no TensorFlow, vamos ver os valores da tabela XOR. Isso nos ajudará a entender o processo de criptografia e descriptografia.
| UMA | B | UMA XOR B |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
O método de criptografia XOR Cipher é basicamente usado para criptografar dados difíceis de serem quebrados com o método de força bruta, ou seja, gerando chaves de criptografia aleatórias que correspondem à chave apropriada.
O conceito de implementação com Cifra XOR é definir uma chave de criptografia XOR e, em seguida, executar a operação XOR dos caracteres na string especificada com essa chave, que um usuário tenta criptografar. Agora vamos nos concentrar na implementação de XOR usando TensorFlow, que é mencionado abaixo -
#Declaring necessary modules
import tensorflow as tf
import numpy as np
"""
A simple numpy implementation of a XOR gate to understand the backpropagation
algorithm
"""
x = tf.placeholder(tf.float64,shape = [4,2],name = "x")
#declaring a place holder for input x
y = tf.placeholder(tf.float64,shape = [4,1],name = "y")
#declaring a place holder for desired output y
m = np.shape(x)[0]#number of training examples
n = np.shape(x)[1]#number of features
hidden_s = 2 #number of nodes in the hidden layer
l_r = 1#learning rate initialization
theta1 = tf.cast(tf.Variable(tf.random_normal([3,hidden_s]),name = "theta1"),tf.float64)
theta2 = tf.cast(tf.Variable(tf.random_normal([hidden_s+1,1]),name = "theta2"),tf.float64)
#conducting forward propagation
a1 = tf.concat([np.c_[np.ones(x.shape[0])],x],1)
#the weights of the first layer are multiplied by the input of the first layer
z1 = tf.matmul(a1,theta1)
#the input of the second layer is the output of the first layer, passed through the
activation function and column of biases is added
a2 = tf.concat([np.c_[np.ones(x.shape[0])],tf.sigmoid(z1)],1)
#the input of the second layer is multiplied by the weights
z3 = tf.matmul(a2,theta2)
#the output is passed through the activation function to obtain the final probability
h3 = tf.sigmoid(z3)
cost_func = -tf.reduce_sum(y*tf.log(h3)+(1-y)*tf.log(1-h3),axis = 1)
#built in tensorflow optimizer that conducts gradient descent using specified
learning rate to obtain theta values
optimiser = tf.train.GradientDescentOptimizer(learning_rate = l_r).minimize(cost_func)
#setting required X and Y values to perform XOR operation
X = [[0,0],[0,1],[1,0],[1,1]]
Y = [[0],[1],[1],[0]]
#initializing all variables, creating a session and running a tensorflow session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
#running gradient descent for each iteration and printing the hypothesis
obtained using the updated theta values
for i in range(100000):
sess.run(optimiser, feed_dict = {x:X,y:Y})#setting place holder values using feed_dict
if i%100==0:
print("Epoch:",i)
print("Hyp:",sess.run(h3,feed_dict = {x:X,y:Y}))A linha de código acima gera uma saída conforme mostrado na captura de tela abaixo -
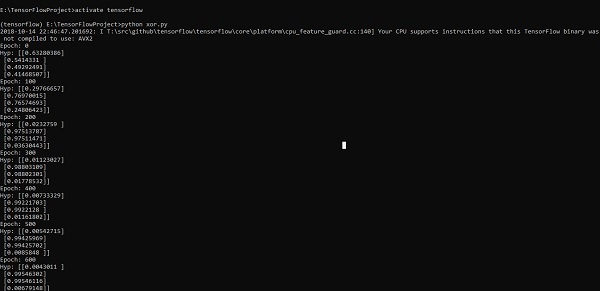
A otimização de gradiente descendente é considerada um conceito importante na ciência de dados.
Considere as etapas mostradas abaixo para entender a implementação da otimização de gradiente descendente -
Passo 1
Incluir módulos necessários e declaração das variáveis xey através das quais vamos definir a otimização da descida do gradiente.
import tensorflow as tf
x = tf.Variable(2, name = 'x', dtype = tf.float32)
log_x = tf.log(x)
log_x_squared = tf.square(log_x)
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(log_x_squared)Passo 2
Inicialize as variáveis necessárias e chame os otimizadores para definir e chamar com a respectiva função.
init = tf.initialize_all_variables()
def optimize():
with tf.Session() as session:
session.run(init)
print("starting at", "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
for step in range(10):
session.run(train)
print("step", step, "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
optimize()A linha de código acima gera uma saída conforme mostrado na captura de tela abaixo -
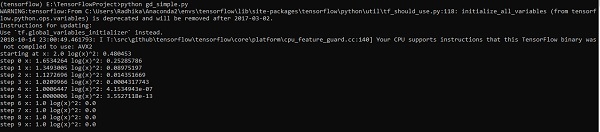
Podemos ver que as épocas e iterações necessárias são calculadas conforme mostrado na saída.
Uma equação diferencial parcial (PDE) é uma equação diferencial, que envolve derivadas parciais com função desconhecida de várias variáveis independentes. Com referência às equações diferenciais parciais, vamos nos concentrar na criação de novos gráficos.
Vamos supor que haja uma lagoa com dimensão 500 * 500 quadrados -
N = 500
Agora, vamos calcular a equação diferencial parcial e formar o respectivo gráfico usando-a. Considere as etapas fornecidas abaixo para calcular o gráfico.
Step 1 - Importar bibliotecas para simulação.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltStep 2 - Inclui funções para transformação de um array 2D em um kernel de convolução e operação de convolução 2D simplificada.
def make_kernel(a):
a = np.asarray(a)
a = a.reshape(list(a.shape) + [1,1])
return tf.constant(a, dtype=1)
def simple_conv(x, k):
"""A simplified 2D convolution operation"""
x = tf.expand_dims(tf.expand_dims(x, 0), -1)
y = tf.nn.depthwise_conv2d(x, k, [1, 1, 1, 1], padding = 'SAME')
return y[0, :, :, 0]
def laplace(x):
"""Compute the 2D laplacian of an array"""
laplace_k = make_kernel([[0.5, 1.0, 0.5], [1.0, -6., 1.0], [0.5, 1.0, 0.5]])
return simple_conv(x, laplace_k)
sess = tf.InteractiveSession()Step 3 - Inclua o número de iterações e calcule o gráfico para exibir os registros de acordo.
N = 500
# Initial Conditions -- some rain drops hit a pond
# Set everything to zero
u_init = np.zeros([N, N], dtype = np.float32)
ut_init = np.zeros([N, N], dtype = np.float32)
# Some rain drops hit a pond at random points
for n in range(100):
a,b = np.random.randint(0, N, 2)
u_init[a,b] = np.random.uniform()
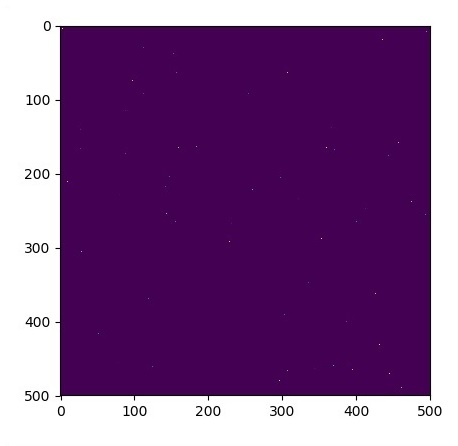
plt.imshow(u_init)
plt.show()
# Parameters:
# eps -- time resolution
# damping -- wave damping
eps = tf.placeholder(tf.float32, shape = ())
damping = tf.placeholder(tf.float32, shape = ())
# Create variables for simulation state
U = tf.Variable(u_init)
Ut = tf.Variable(ut_init)
# Discretized PDE update rules
U_ = U + eps * Ut
Ut_ = Ut + eps * (laplace(U) - damping * Ut)
# Operation to update the state
step = tf.group(U.assign(U_), Ut.assign(Ut_))
# Initialize state to initial conditions
tf.initialize_all_variables().run()
# Run 1000 steps of PDE
for i in range(1000):
# Step simulation
step.run({eps: 0.03, damping: 0.04})
# Visualize every 50 steps
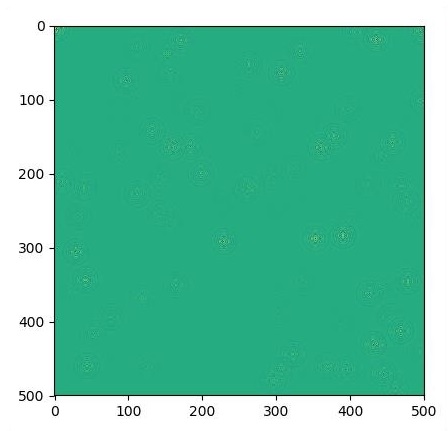
if i % 500 == 0:
plt.imshow(U.eval())
plt.show()Os gráficos são traçados conforme mostrado abaixo -
O TensorFlow inclui um recurso especial de reconhecimento de imagem e essas imagens são armazenadas em uma pasta específica. Com imagens relativamente iguais, será fácil implementar essa lógica para fins de segurança.
A estrutura da pasta de implementação do código de reconhecimento de imagem é mostrada abaixo -
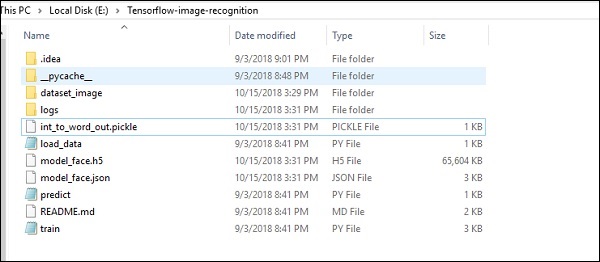
O dataset_image inclui as imagens relacionadas, que precisam ser carregadas. Vamos nos concentrar no reconhecimento de imagem com nosso logotipo definido nele. As imagens são carregadas com o script “load_data.py”, que ajuda a manter uma nota sobre os vários módulos de reconhecimento de imagem dentro delas.
import pickle
from sklearn.model_selection import train_test_split
from scipy import misc
import numpy as np
import os
label = os.listdir("dataset_image")
label = label[1:]
dataset = []
for image_label in label:
images = os.listdir("dataset_image/"+image_label)
for image in images:
img = misc.imread("dataset_image/"+image_label+"/"+image)
img = misc.imresize(img, (64, 64))
dataset.append((img,image_label))
X = []
Y = []
for input,image_label in dataset:
X.append(input)
Y.append(label.index(image_label))
X = np.array(X)
Y = np.array(Y)
X_train,y_train, = X,Y
data_set = (X_train,y_train)
save_label = open("int_to_word_out.pickle","wb")
pickle.dump(label, save_label)
save_label.close()O treinamento de imagens ajuda a armazenar os padrões reconhecíveis dentro da pasta especificada.
import numpy
import matplotlib.pyplot as plt
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import SGD
from keras.layers import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
import load_data
from keras.models import Sequential
from keras.layers import Dense
import keras
K.set_image_dim_ordering('tf')
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train,y_train) = load_data.data_set
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
#X_test = X_test.astype('float32')
X_train = X_train / 255.0
#X_test = X_test / 255.0
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
#y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), padding = 'same',
activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation = 'relu', padding = 'same',
kernel_constraint = maxnorm(3)))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Flatten())
model.add(Dense(512, activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation = 'softmax'))
# Compile model
epochs = 10
lrate = 0.01
decay = lrate/epochs
sgd = SGD(lr = lrate, momentum = 0.9, decay = decay, nesterov = False)
model.compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = ['accuracy'])
print(model.summary())
#callbacks = [keras.callbacks.EarlyStopping(
monitor = 'val_loss', min_delta = 0, patience = 0, verbose = 0, mode = 'auto')]
callbacks = [keras.callbacks.TensorBoard(log_dir='./logs',
histogram_freq = 0, batch_size = 32, write_graph = True, write_grads = False,
write_images = True, embeddings_freq = 0, embeddings_layer_names = None,
embeddings_metadata = None)]
# Fit the model
model.fit(X_train, y_train, epochs = epochs,
batch_size = 32,shuffle = True,callbacks = callbacks)
# Final evaluation of the model
scores = model.evaluate(X_train, y_train, verbose = 0)
print("Accuracy: %.2f%%" % (scores[1]*100))
# serialize model to JSONx
model_json = model.to_json()
with open("model_face.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model_face.h5")
print("Saved model to disk")A linha de código acima gera uma saída conforme mostrado abaixo -
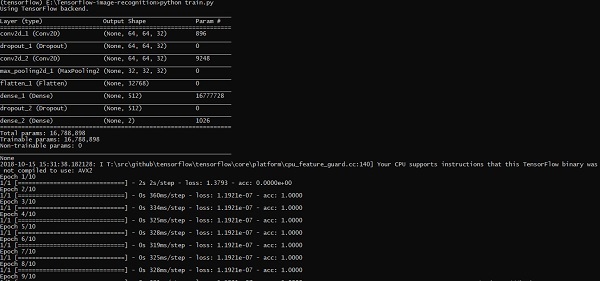
Neste capítulo, entenderemos os vários aspectos do treinamento de rede neural que podem ser implementados usando a estrutura TensorFlow.
A seguir estão as dez recomendações, que podem ser avaliadas -
Back Propagation
A propagação de retorno é um método simples para calcular derivados parciais, que inclui a forma básica de composição mais adequada para redes neurais.
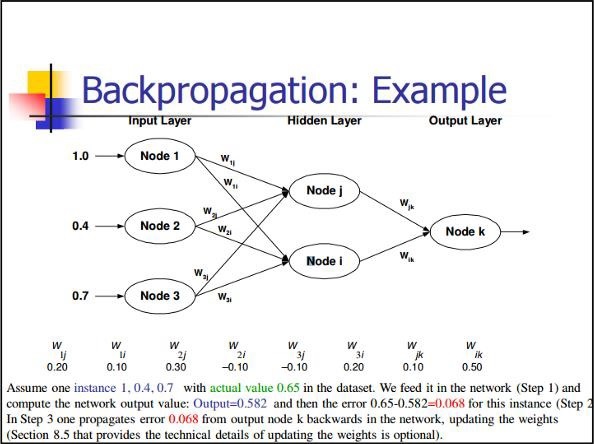
Descida gradiente estocástico
Na descida gradiente estocástica, um batché o número total de exemplos, que um usuário usa para calcular o gradiente em uma única iteração. Até agora, presume-se que o lote foi todo o conjunto de dados. A melhor ilustração está trabalhando na escala do Google; conjuntos de dados geralmente contêm bilhões ou mesmo centenas de bilhões de exemplos.
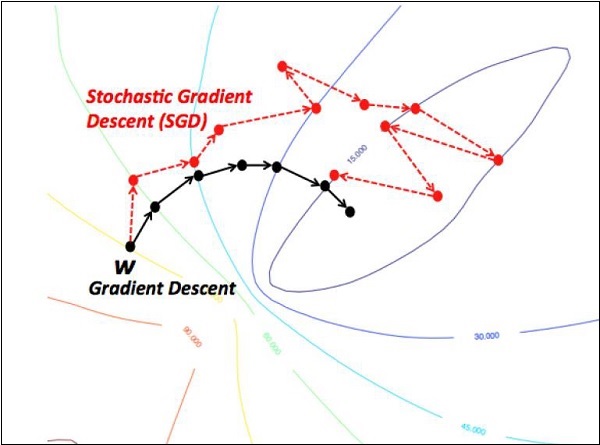
Diminuição da taxa de aprendizagem
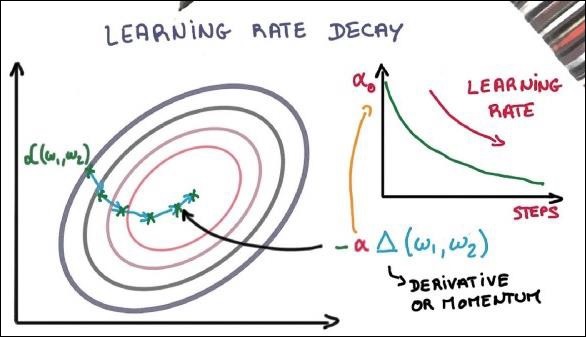
Adaptar a taxa de aprendizado é um dos recursos mais importantes da otimização de gradiente descendente. Isso é crucial para a implementação do TensorFlow.
Cair fora
Redes neurais profundas com um grande número de parâmetros formam poderosos sistemas de aprendizado de máquina. No entanto, o excesso de adaptação é um problema sério em tais redes.

Max Pooling
Max pooling é um processo de discretização baseado em amostra. O objetivo é reduzir a amostra de uma representação de entrada, o que reduz a dimensionalidade com as suposições necessárias.

Memória de longo prazo (LSTM)
LSTM controla a decisão sobre quais entradas devem ser tomadas dentro do neurônio especificado. Inclui o controle sobre a decisão do que deve ser computado e qual saída deve ser gerada.