TensorFlow - Perceptron de camada única
Para entender o perceptron de camada única, é importante entender as Redes Neurais Artificiais (RNA). Redes neurais artificiais são o sistema de processamento de informações cujo mecanismo é inspirado na funcionalidade de circuitos neurais biológicos. Uma rede neural artificial possui muitas unidades de processamento conectadas umas às outras. A seguir está a representação esquemática da rede neural artificial -
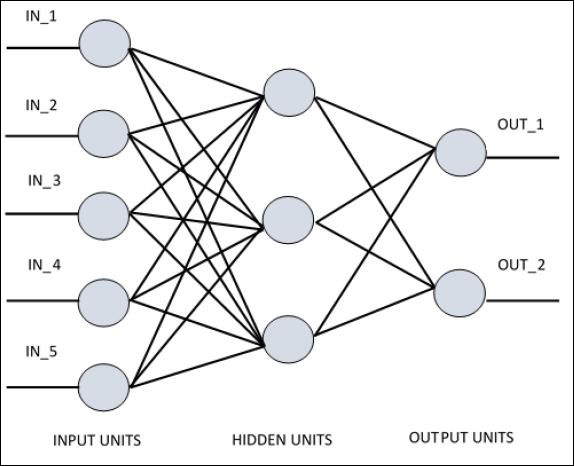
O diagrama mostra que as unidades ocultas se comunicam com a camada externa. Enquanto as unidades de entrada e saída se comunicam apenas por meio da camada oculta da rede.
O padrão de conexão com os nós, o número total de camadas e o nível de nós entre entradas e saídas com o número de neurônios por camada definem a arquitetura de uma rede neural.
Existem dois tipos de arquitetura. Esses tipos se concentram na funcionalidade de redes neurais artificiais da seguinte maneira -
- Perceptron de Camada Única
- Perceptron Multi-Camada
Perceptron de Camada Única
Perceptron de camada única é o primeiro modelo neural proposto criado. O conteúdo da memória local do neurônio consiste em um vetor de pesos. O cálculo de um perceptron de camada única é realizado sobre o cálculo da soma do vetor de entrada, cada um com o valor multiplicado pelo elemento correspondente do vetor dos pesos. O valor exibido na saída será a entrada de uma função de ativação.

Vamos nos concentrar na implementação do perceptron de camada única para um problema de classificação de imagem usando o TensorFlow. O melhor exemplo para ilustrar o perceptron de camada única é através da representação de “Regressão Logística”.
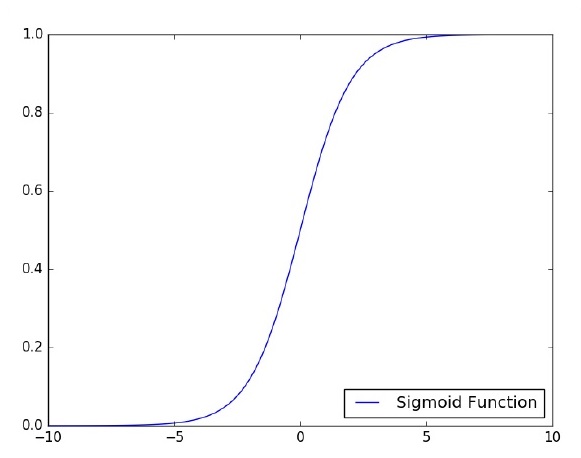
Agora, vamos considerar as seguintes etapas básicas de regressão logística de treinamento -
Os pesos são inicializados com valores aleatórios no início do treinamento.
Para cada elemento do conjunto de treinamento, o erro é calculado com a diferença entre a saída desejada e a saída real. O erro calculado é usado para ajustar os pesos.
O processo é repetido até que o erro cometido em todo o conjunto de treinamento não seja inferior ao limite especificado, até que o número máximo de iterações seja atingido.
O código completo para avaliação de regressão logística é mencionado abaixo -
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder("float", [None, 784]) # mnist data image of shape 28*28 = 784
y = tf.placeholder("float", [None, 10]) # 0-9 digits recognition => 10 classes
# Create model
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Construct model
activation = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
# Minimize error using cross entropy
cross_entropy = y*tf.log(activation)
cost = tf.reduce_mean\ (-tf.reduce_sum\ (cross_entropy,reduction_indices = 1))
optimizer = tf.train.\ GradientDescentOptimizer(learning_rate).minimize(cost)
#Plot settings
avg_set = []
epoch_set = []
# Initializing the variables init = tf.initialize_all_variables()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = \ mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, \ feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss avg_cost += sess.run(cost, \ feed_dict = {
x: batch_xs, \ y: batch_ys})/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print ("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
avg_set.append(avg_cost) epoch_set.append(epoch+1)
print ("Training phase finished")
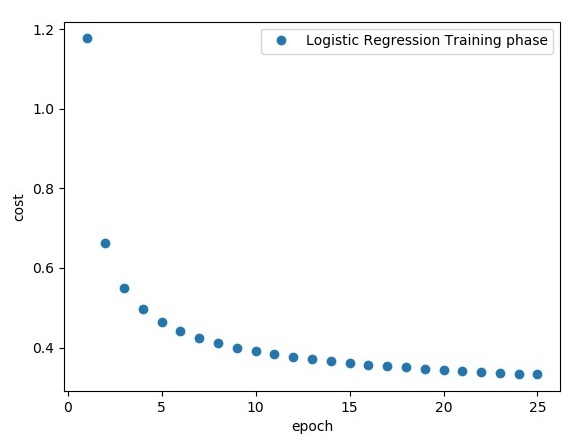
plt.plot(epoch_set,avg_set, 'o', label = 'Logistic Regression Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(activation, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print
("Model accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))Resultado
O código acima gera a seguinte saída -
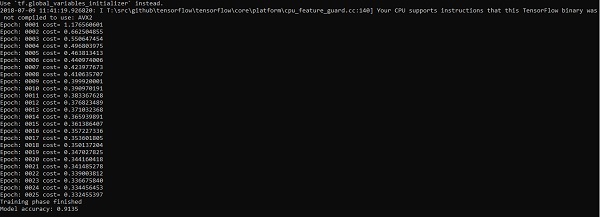
A regressão logística é considerada uma análise preditiva. A regressão logística é usada para descrever os dados e explicar a relação entre uma variável binária dependente e uma ou mais variáveis nominais ou independentes.