Структура данных - первый обход в ширину
Алгоритм поиска в ширину (BFS) перемещается по графу вширь и использует очередь, чтобы не забыть получить следующую вершину для начала поиска, когда на любой итерации возникает тупик.

Как и в приведенном выше примере, алгоритм BFS сначала переходит от A к B, от E к F, затем к C и G, наконец, к D. Он использует следующие правила.
Rule 1- Посетите соседнюю непосещенную вершину. Отметьте его как посещенное. Покажите это. Вставьте его в очередь.
Rule 2 - Если смежная вершина не найдена, удалите первую вершину из очереди.
Rule 3 - Повторяйте правило 1 и правило 2, пока очередь не станет пустой.
| Шаг | Обход | Описание |
|---|---|---|
| 1 |

|
Инициализируйте очередь. |
| 2 |
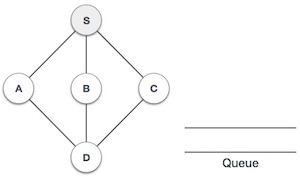
|
Начнем с посещения S (начальный узел) и отметьте его как посещенный. |
| 3 |

|
Затем мы видим непосещенный соседний узел из S. В этом примере у нас есть три узла, но по алфавиту мы выбираемA, отметьте его как посещенное и поставьте в очередь. |
| 4 |

|
Затем непосещенный соседний узел из S является B. Мы отмечаем его как посещенное и ставим в очередь. |
| 5 |

|
Затем непосещенный соседний узел из S является C. Мы отмечаем его как посещенное и ставим в очередь. |
| 6 |

|
Сейчас же, Sостается без непосещенных соседних узлов. Итак, выводим из очереди и находимA. |
| 7 |

|
Из A у нас есть Dкак непосещенный соседний узел. Мы отмечаем его как посещенное и ставим в очередь. |
На этом этапе у нас нет неотмеченных (непосещенных) узлов. Но согласно алгоритму мы продолжаем исключать из очереди, чтобы получить все непосещенные узлы. Когда очередь опорожняется, программа завершается.
Реализацию этого алгоритма на языке программирования C можно увидеть здесь .