Структуры данных и алгоритмы - Краткое руководство
Структура данных - это систематический способ организации данных для их эффективного использования. Следующие термины являются основными терминами структуры данных.
Interface- Каждая структура данных имеет интерфейс. Интерфейс представляет собой набор операций, поддерживаемых структурой данных. Интерфейс предоставляет только список поддерживаемых операций, тип параметров, которые они могут принимать, и тип возвращаемого значения этих операций.
Implementation- Реализация обеспечивает внутреннее представление структуры данных. Реализация также обеспечивает определение алгоритмов, используемых в операциях со структурой данных.
Характеристики структуры данных
Correctness - Реализация структуры данных должна правильно реализовывать ее интерфейс.
Time Complexity - Время выполнения или время выполнения операций структуры данных должно быть как можно меньше.
Space Complexity - Использование памяти операцией структуры данных должно быть как можно меньше.
Потребность в структуре данных
По мере того как приложения становятся сложными и содержат много данных, в настоящее время приложения сталкиваются с тремя распространенными проблемами.
Data Search- Рассмотрим инвентаризацию 1 миллиона (10 6 ) товаров в магазине. Если приложение должно искать элемент, оно должно искать элемент в 1 миллионе (10 6 ) элементов каждый раз, замедляя поиск. По мере роста объема данных поиск будет замедляться.
Processor speed - Скорость процессора хотя и очень высока, но снижается, если объем данных увеличивается до миллиарда записей.
Multiple requests - Поскольку тысячи пользователей могут одновременно искать данные на веб-сервере, даже быстрый сервер дает сбой при поиске данных.
Для решения вышеупомянутых проблем на помощь приходят структуры данных. Данные могут быть организованы в структуру данных таким образом, что поиск по всем элементам может не требоваться, а поиск необходимых данных может выполняться практически мгновенно.
Случаи времени исполнения
Есть три случая, которые обычно используются для относительного сравнения времени выполнения различных структур данных.
Worst Case- Это сценарий, при котором операция с определенной структурой данных занимает максимальное время. Если время наихудшего случая операции равно (n), то эта операция не займет больше времени ƒ (n), где ƒ (n) представляет функцию от n.
Average Case- Это сценарий, отображающий среднее время выполнения операции структуры данных. Если операция занимает ƒ (n) раз, то m операций займут m m (n) раз.
Best Case- Это сценарий, отображающий наименьшее возможное время выполнения операции структуры данных. Если операция занимает (n) времени на выполнение, то фактическая операция может занять время как случайное число, которое будет максимальным как (n).
Базовая терминология
Data - Данные - это значения или набор значений.
Data Item - Элемент данных относится к одной единице значений.
Group Items - Элементы данных, которые разделены на подпункты, называются элементами группы.
Elementary Items - Элементы данных, которые нельзя разделить, называются элементарными элементами.
Attribute and Entity - Сущность - это то, что содержит определенные атрибуты или свойства, которым могут быть присвоены значения.
Entity Set - Объекты с похожими атрибутами образуют набор объектов.
Field - Поле - это единая элементарная единица информации, представляющая атрибут объекта.
Record - Запись - это набор значений полей данного объекта.
File - Файл - это набор записей сущностей в данном наборе сущностей.
Попробуйте вариант онлайн
Вам действительно не нужно создавать собственную среду, чтобы начать изучать язык программирования C. Причина очень проста: мы уже настроили среду программирования на C онлайн, так что вы можете компилировать и выполнять все доступные примеры онлайн одновременно, когда вы делаете свою теоретическую работу. Это дает вам уверенность в том, что вы читаете, и позволяет проверять результат с помощью различных параметров. Не стесняйтесь изменять любой пример и выполнять его онлайн.
Попробуйте следующий пример, используя Try it опция доступна в верхнем правом углу поля образца кода -
#include <stdio.h>
int main(){
/* My first program in C */
printf("Hello, World! \n");
return 0;
}Для большинства примеров, приведенных в этом руководстве, вы найдете опцию «Попробовать», так что просто используйте ее и наслаждайтесь обучением.
Настройка локальной среды
Если вы все еще хотите настроить свою среду для языка программирования C, вам понадобятся следующие два инструмента, доступные на вашем компьютере: (а) текстовый редактор и (б) компилятор C.
Текстовый редактор
Это будет использоваться для ввода вашей программы. Примеры нескольких редакторов включают Блокнот Windows, команду редактирования ОС, Brief, Epsilon, EMACS и vim или vi.
Название и версия текстового редактора могут различаться в разных операционных системах. Например, Блокнот будет использоваться в Windows, а vim или vi можно использовать в Windows, а также в Linux или UNIX.
Файлы, которые вы создаете с помощью своего редактора, называются исходными файлами и содержат исходный код программы. Исходные файлы для программ на C обычно имеют расширение ".c".
Перед началом программирования убедитесь, что у вас есть один текстовый редактор и у вас достаточно опыта, чтобы написать компьютерную программу, сохранить ее в файл, скомпилировать и, наконец, выполнить.
Компилятор C
Исходный код, записанный в исходном файле, является удобочитаемым источником вашей программы. Его необходимо «скомпилировать», превратить в машинный язык, чтобы ваш ЦП действительно мог выполнять программу в соответствии с данными инструкциями.
Этот компилятор языка программирования C будет использоваться для компиляции вашего исходного кода в окончательную исполняемую программу. Мы предполагаем, что у вас есть базовые знания о компиляторе языков программирования.
Наиболее часто используемый и бесплатный компилятор - это компилятор GNU C / C ++. В противном случае у вас могут быть компиляторы от HP или Solaris, если у вас есть соответствующие операционные системы (ОС).
В следующем разделе рассказывается, как установить компилятор GNU C / C ++ в различных ОС. Мы упоминаем C / C ++ вместе, потому что компилятор GNU GCC работает как для языков программирования C, так и для C ++.
Установка в UNIX / Linux
Если вы используете Linux or UNIX, затем проверьте, установлен ли GCC в вашей системе, введя следующую команду из командной строки -
$ gcc -vЕсли на вашем компьютере установлен компилятор GNU, он должен напечатать сообщение, подобное следующему:
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix = /usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)Если GCC не установлен, вам придется установить его самостоятельно, используя подробные инструкции, доступные на https://gcc.gnu.org/install/
Это руководство было написано на основе Linux, и все приведенные примеры были скомпилированы в версии Cent OS системы Linux.
Установка на Mac OS
Если вы используете Mac OS X, самый простой способ получить GCC - загрузить среду разработки Xcode с веб-сайта Apple и следовать простым инструкциям по установке. После настройки Xcode вы сможете использовать компилятор GNU для C / C ++.
Xcode в настоящее время доступен по адресу developer.apple.com/technologies/tools/.
Установка в Windows
Чтобы установить GCC в Windows, вам необходимо установить MinGW. Чтобы установить MinGW, перейдите на домашнюю страницу MinGW, www.mingw.org , и перейдите по ссылке на страницу загрузки MinGW. Загрузите последнюю версию программы установки MinGW, которая должна называться MinGW- <version> .exe.
При установке MinWG, как минимум, вы должны установить gcc-core, gcc-g ++, binutils и среду выполнения MinGW, но вы можете установить больше.
Добавьте подкаталог bin вашей установки MinGW в свой PATH переменная окружения, чтобы вы могли указать эти инструменты в командной строке по их простым именам.
Когда установка будет завершена, вы сможете запускать gcc, g ++, ar, ranlib, dlltool и несколько других инструментов GNU из командной строки Windows.
Алгоритм - это пошаговая процедура, которая определяет набор инструкций, которые должны выполняться в определенном порядке для получения желаемого результата. Алгоритмы обычно создаются независимо от основных языков, т.е. алгоритм может быть реализован на нескольких языках программирования.
С точки зрения структуры данных, ниже приведены некоторые важные категории алгоритмов:
Search - Алгоритм поиска элемента в структуре данных.
Sort - Алгоритм сортировки предметов в определенном порядке.
Insert - Алгоритм вставки элемента в структуру данных.
Update - Алгоритм обновления существующего элемента в структуре данных.
Delete - Алгоритм удаления существующего элемента из структуры данных.
Характеристики алгоритма
Не все процедуры можно назвать алгоритмом. Алгоритм должен иметь следующие характеристики -
Unambiguous- Алгоритм должен быть четким и однозначным. Каждый из его шагов (или фаз) и их входы / выходы должны быть ясными и иметь только одно значение.
Input - Алгоритм должен иметь 0 или более четко определенных входов.
Output - Алгоритм должен иметь 1 или несколько четко определенных выходов и должен соответствовать желаемому выходу.
Finiteness - Алгоритмы должны завершаться после конечного числа шагов.
Feasibility - Должно быть осуществимо при имеющихся ресурсах.
Independent - Алгоритм должен иметь пошаговые инструкции, которые не должны зависеть от программного кода.
Как написать алгоритм?
Четко определенных стандартов написания алгоритмов не существует. Скорее, это проблема и зависит от ресурсов. Алгоритмы никогда не пишутся для поддержки определенного программного кода.
Как мы знаем, все языки программирования разделяют базовые конструкции кода, такие как циклы (do, for, while), управление потоком (if-else) и т. Д. Эти общие конструкции можно использовать для написания алгоритма.
Мы пишем алгоритмы поэтапно, но это не всегда так. Написание алгоритма - это процесс, который выполняется после того, как проблемная область четко определена. То есть мы должны знать проблемную область, для которой мы разрабатываем решение.
пример
Попробуем научиться писать алгоритмы на примере.
Problem - Разработайте алгоритм сложения двух чисел и отображения результата.
Step 1 − START
Step 2 − declare three integers a, b & c
Step 3 − define values of a & b
Step 4 − add values of a & b
Step 5 − store output of step 4 to c
Step 6 − print c
Step 7 − STOPАлгоритмы говорят программистам, как писать программу. В качестве альтернативы алгоритм можно записать как -
Step 1 − START ADD
Step 2 − get values of a & b
Step 3 − c ← a + b
Step 4 − display c
Step 5 − STOPПри разработке и анализе алгоритмов обычно используется второй метод описания алгоритма. Это позволяет аналитику легко анализировать алгоритм, игнорируя все нежелательные определения. Он может наблюдать, какие операции используются и как протекает процесс.
Письмо step numbers, не является обязательным.
Мы разрабатываем алгоритм для решения данной проблемы. Проблема может быть решена несколькими способами.
Следовательно, для данной проблемы можно вывести множество алгоритмов решения. Следующим шагом является анализ предложенных алгоритмов решения и реализация наиболее подходящего решения.
Анализ алгоритмов
Эффективность алгоритма можно проанализировать на двух разных этапах: до реализации и после реализации. Они следующие -
A Priori Analysis- Это теоретический анализ алгоритма. Эффективность алгоритма измеряется исходя из предположения, что все остальные факторы, например, скорость процессора, постоянны и не влияют на реализацию.
A Posterior Analysis- Это эмпирический анализ алгоритма. Выбранный алгоритм реализован на языке программирования. Затем это выполняется на целевом компьютере. В этом анализе собирается фактическая статистика, такая как время работы и необходимое пространство.
Мы узнаем об априорном алгоритме анализа. Анализ алгоритмов имеет дело с выполнением или временем выполнения различных задействованных операций. Время выполнения операции можно определить как количество компьютерных инструкций, выполняемых за операцию.
Сложность алгоритма
Предположим X это алгоритм и n - размер входных данных, время и пространство, используемые алгоритмом X, - два основных фактора, которые определяют эффективность X.
Time Factor - Время измеряется путем подсчета количества ключевых операций, таких как сравнения, в алгоритме сортировки.
Space Factor - Пространство измеряется путем подсчета максимального объема памяти, требуемого алгоритмом.
Сложность алгоритма f(n) дает время работы и / или объем памяти, требуемый алгоритмом с точки зрения n как размер входных данных.
Космическая сложность
Сложность алгоритма представляет собой объем памяти, необходимый алгоритму в его жизненном цикле. Пространство, необходимое для алгоритма, равно сумме следующих двух компонентов:
Фиксированная часть, которая представляет собой пространство, необходимое для хранения определенных данных и переменных, которые не зависят от размера проблемы. Например, используемые простые переменные и константы, размер программы и т. Д.
Переменная часть - это пространство, необходимое для переменных, размер которых зависит от размера проблемы. Например, распределение динамической памяти, пространство стека рекурсии и т. Д.
Сложность пространства S (P) любого алгоритма P равна S (P) = C + SP (I), где C - фиксированная часть, а S (I) - переменная часть алгоритма, которая зависит от характеристики экземпляра I. это простой пример, который пытается объяснить концепцию -
Algorithm: SUM(A, B)
Step 1 - START
Step 2 - C ← A + B + 10
Step 3 - StopЗдесь у нас есть три переменные A, B и C и одна константа. Следовательно, S (P) = 1 + 3. Теперь пространство зависит от типов данных заданных переменных и типов констант, и оно будет соответственно умножаться.
Сложность времени
Сложность алгоритма по времени представляет собой время, необходимое алгоритму для выполнения до завершения. Требования ко времени можно определить как числовую функцию T (n), где T (n) можно измерить как количество шагов, при условии, что каждый шаг требует постоянного времени.
Например, сложение двух n-битных целых чисел требует nшаги. Следовательно, общее время вычислений равно T (n) = c ∗ n, где c - время, необходимое для добавления двух битов. Здесь мы видим, что T (n) линейно растет с увеличением размера ввода.
Асимптотический анализ алгоритма относится к определению математических границ / рамок его производительности во время выполнения. Используя асимптотический анализ, мы можем очень хорошо сделать вывод о наилучшем, среднем и наихудшем сценариях алгоритма.
Асимптотический анализ - это входная граница, то есть, если нет входной информации для алгоритма, предполагается, что он работает в постоянное время. Все остальные факторы, кроме «входа», считаются постоянными.
Асимптотический анализ относится к вычислению времени выполнения любой операции в математических единицах вычисления. Например, время выполнения одной операции вычисляется как f (n), а для другой операции оно может быть вычислено как g (n 2 ). Это означает, что время работы первой операции будет линейно увеличиваться с увеличениемn и время выполнения второй операции будет экспоненциально увеличиваться, когда nувеличивается. Точно так же время выполнения обеих операций будет примерно одинаковым, еслиn значительно мала.
Обычно время, необходимое алгоритму, подпадает под три типа:
Best Case - Минимальное время, необходимое для выполнения программы.
Average Case - Среднее время, необходимое для выполнения программы.
Worst Case - Максимальное время, необходимое для выполнения программы.
Асимптотические обозначения
Ниже приведены обычно используемые асимптотические обозначения для вычисления временной сложности алгоритма.
- Ο Обозначение
- Ω Обозначение
- θ Обозначение
Обозначение Big Oh,
Обозначение Ο (n) - это формальный способ выразить верхнюю границу времени работы алгоритма. Он измеряет временную сложность наихудшего случая или максимальное время, которое может потребоваться для выполнения алгоритма.
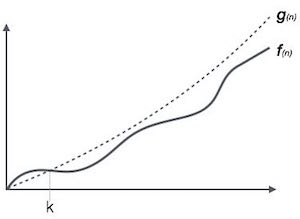
Например, для функции f(n)
Ο(f(n)) = { g(n) : there exists c > 0 and n0 such that f(n) ≤ c.g(n) for all n > n0. }Омега-обозначение, Ω
Обозначение Ω (n) - это формальный способ выразить нижнюю границу времени работы алгоритма. Он измеряет наилучшую временную сложность случая или наилучшее время, которое может занять алгоритм.
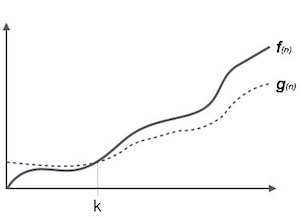
Например, для функции f(n)
Ω(f(n)) ≥ { g(n) : there exists c > 0 and n0 such that g(n) ≤ c.f(n) for all n > n0. }Обозначение тета, θ
Обозначение θ (n) - это формальный способ выразить как нижнюю, так и верхнюю границу времени работы алгоритма. Он представлен следующим образом -
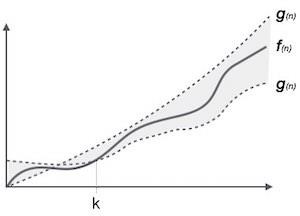
θ(f(n)) = { g(n) if and only if g(n) = Ο(f(n)) and g(n) = Ω(f(n)) for all n > n0. }Общие асимптотические обозначения
Ниже приводится список некоторых распространенных асимптотических обозначений -
| постоянный | - | Ο (1) |
| логарифмический | - | Ο (журнал n) |
| линейный | - | Ο (п) |
| п войти п | - | Ο (п войти п) |
| квадратичный | - | Ο (п 2 ) |
| кубический | - | Ο (п 3 ) |
| многочлен | - | п (1) |
| экспоненциальный | - | 2 Ο (п) |
Алгоритм предназначен для достижения оптимального решения данной проблемы. При использовании жадного алгоритма решения принимаются из заданной области решения. Будучи жадным, выбирается ближайшее решение, которое, кажется, обеспечивает оптимальное решение.
Жадные алгоритмы пытаются найти локализованное оптимальное решение, которое в конечном итоге может привести к глобально оптимизированным решениям. Однако обычно жадные алгоритмы не предоставляют решений, оптимизированных на глобальном уровне.
Подсчет монет
Эта проблема состоит в том, чтобы считать до желаемого значения, выбирая наименьшее количество монет, а жадный подход заставляет алгоритм выбирать наибольшую возможную монету. Если нам предоставят монеты номиналом 1, 2, 5 и 10 фунтов стерлингов, и нас попросят сосчитать 18 фунтов стерлингов, то жадная процедура будет -
1 - Выберите одну монету ₹ 10, оставшееся количество - 8
2 - Затем выберите одну монету ₹ 5, осталось 3
3 - Затем выберите одну монету ₹ 2, оставшийся счет равен 1.
4 - И наконец, выбор одной монеты ₹ 1 решает проблему
Хотя вроде работает нормально, для этого счета нам нужно выбрать только 4 монеты. Но если мы немного изменим задачу, тот же подход может не дать такого же оптимального результата.
Для валютной системы, где у нас есть монеты достоинством 1, 7, 10, подсчет монет на 18 будет абсолютно оптимальным, но для подсчета вроде 15 он может использовать больше монет, чем необходимо. Например, жадный подход будет использовать 10 + 1 + 1 + 1 + 1 + 1, всего 6 монет. Тогда как ту же проблему можно решить, используя всего 3 монеты (7 + 7 + 1).
Следовательно, мы можем сделать вывод, что жадный подход выбирает немедленное оптимизированное решение и может потерпеть неудачу там, где глобальная оптимизация является серьезной проблемой.
Примеры
Большинство сетевых алгоритмов используют жадный подход. Вот список некоторых из них -
- Задача коммивояжера
- Алгоритм минимального связующего дерева Прима
- Минимальный алгоритм связующего дерева Краскала
- Алгоритм минимального остовного дерева Дейкстры
- График - Раскраска карты
- График - вершинное покрытие
- Проблема с рюкзаком
- Проблема с расписанием работы
Есть много подобных проблем, которые используют жадный подход для поиска оптимального решения.
В подходе «разделяй и властвуй» рассматриваемая проблема делится на более мелкие подзадачи, а затем каждая проблема решается независимо. Когда мы продолжаем разделять подзадачи на еще более мелкие подзадачи, мы в конечном итоге можем достичь стадии, когда разделение станет невозможным. Эти «атомарные» наименьшие возможные подзадачи (дроби) решены. Окончательно решение всех подзадач объединяется, чтобы получить решение исходной проблемы.
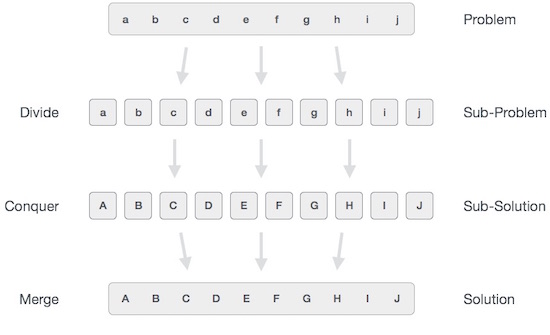
В широком смысле мы можем понять divide-and-conquer подход в трехэтапном процессе.
Разделить / Разбить
Этот шаг включает разбиение проблемы на более мелкие подзадачи. Подзадачи должны представлять собой часть исходной проблемы. На этом шаге обычно используется рекурсивный подход для разделения проблемы до тех пор, пока ни одна из подзадач не станет делимой. На этом этапе подзадачи становятся атомарными по своей природе, но все же представляют некоторую часть реальной проблемы.
Завоевать / Решить
На этом этапе необходимо решить множество более мелких подзадач. Обычно на этом уровне проблемы считаются «решенными» сами по себе.
Слияние / объединение
Когда более мелкие подзадачи решены, этот этап рекурсивно объединяет их, пока они не сформулируют решение исходной проблемы. Этот алгоритмический подход работает рекурсивно, и этапы "завоевать и объединить" работают настолько близко, что кажутся единым целым.
Примеры
Следующие компьютерные алгоритмы основаны на divide-and-conquer подход к программированию -
- Сортировка слиянием
- Быстрая сортировка
- Бинарный поиск
- Умножение матриц Штрассена
- Ближайшая пара (баллы)
Существуют различные способы решения любой компьютерной проблемы, но упомянутые выше являются хорошим примером подхода «разделяй и властвуй».
Подход динамического программирования аналогичен принципу «разделяй и властвуй» в разбиении проблемы на более мелкие и все же более мелкие возможные подзадачи. Но в отличие от «разделяй и властвуй», эти подзадачи не решаются независимо. Скорее, результаты этих меньших подзадач запоминаются и используются для аналогичных или перекрывающихся подзадач.
Динамическое программирование используется там, где у нас есть проблемы, которые можно разделить на похожие подзадачи, чтобы их результаты можно было использовать повторно. В основном эти алгоритмы используются для оптимизации. Перед тем как решить текущую подзадачу, динамический алгоритм попытается изучить результаты ранее решенных подзадач. Решения подзадач объединяются для достижения наилучшего решения.
Итак, мы можем сказать, что -
Проблема должна быть разделена на более мелкие перекрывающиеся подзадачи.
Оптимального решения можно достичь, используя оптимальное решение небольших подзадач.
В динамических алгоритмах используется мемоизация.
Сравнение
В отличие от жадных алгоритмов, в которых рассматривается локальная оптимизация, динамические алгоритмы мотивированы для общей оптимизации проблемы.
В отличие от алгоритмов «разделяй и властвуй», где решения объединяются для достижения общего решения, динамические алгоритмы используют выходные данные меньшей подзадачи, а затем пытаются оптимизировать более крупную подзадачу. Динамические алгоритмы используют мемоизацию для запоминания результатов уже решенных подзадач.
пример
Следующие компьютерные проблемы могут быть решены с использованием подхода динамического программирования -
- Числовой ряд Фибоначчи
- Задача о рюкзаке
- Ханойская башня
- Кратчайший путь для всех пар от Флойда-Уоршалла
- Кратчайший путь от Дейкстры
- Планирование проекта
Динамическое программирование можно использовать как сверху вниз, так и снизу вверх. И, конечно же, в большинстве случаев ссылка на предыдущий результат решения дешевле, чем пересчет циклов процессора.
В этой главе объясняются основные термины, относящиеся к структуре данных.
Определение данных
Определение данных определяет конкретные данные со следующими характеристиками.
Atomic - Определение должно определять единое понятие.
Traceable - Определение должно иметь возможность отображать какой-либо элемент данных.
Accurate - Определение должно быть однозначным.
Clear and Concise - Определение должно быть понятным.
Объект данных
Объект данных представляет собой объект, содержащий данные.
Тип данных
Тип данных - это способ классификации различных типов данных, таких как целые числа, строки и т. Д., Который определяет значения, которые могут использоваться с соответствующим типом данных, тип операций, которые могут выполняться с соответствующим типом данных. Есть два типа данных -
- Встроенный тип данных
- Производный тип данных
Встроенный тип данных
Типы данных, для которых язык имеет встроенную поддержку, известны как встроенные типы данных. Например, большинство языков предоставляют следующие встроенные типы данных.
- Integers
- Логическое (истина, ложь)
- Плавающий (десятичные числа)
- Персонаж и строки
Производный тип данных
Те типы данных, которые не зависят от реализации, поскольку они могут быть реализованы тем или иным способом, известны как производные типы данных. Эти типы данных обычно создаются путем комбинации основных или встроенных типов данных и связанных с ними операций. Например -
- List
- Array
- Stack
- Queue
Основные операции
Данные в структурах данных обрабатываются определенными операциями. Выбор конкретной структуры данных во многом зависит от частоты операций, которые необходимо выполнить над структурой данных.
- Traversing
- Searching
- Insertion
- Deletion
- Sorting
- Merging
Массив - это контейнер, который может содержать фиксированное количество элементов, и эти элементы должны быть одного типа. Большинство структур данных используют массивы для реализации своих алгоритмов. Ниже приведены важные термины для понимания концепции массива.
Element - Каждый элемент, хранящийся в массиве, называется элементом.
Index - Каждое расположение элемента в массиве имеет числовой индекс, который используется для идентификации элемента.
Представление массива
Массивы можно объявлять по-разному на разных языках. Для иллюстрации возьмем объявление массива C.

Массивы можно объявлять по-разному на разных языках. Для иллюстрации возьмем объявление массива C.
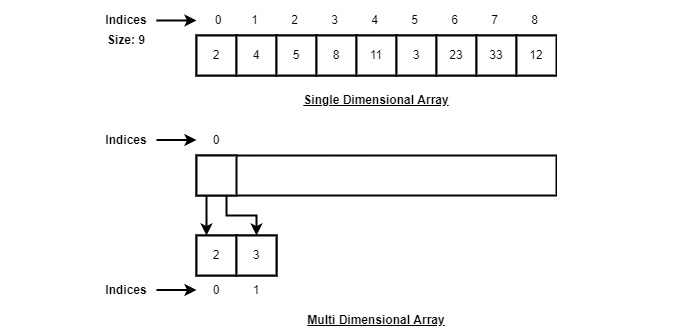
В соответствии с приведенной выше иллюстрацией следует учитывать следующие важные моменты.
Индекс начинается с 0.
Длина массива 10, что означает, что он может хранить 10 элементов.
К каждому элементу можно получить доступ через его индекс. Например, мы можем получить элемент с индексом 6 как 9.
Основные операции
Ниже приведены основные операции, поддерживаемые массивом.
Traverse - распечатать все элементы массива один за другим.
Insertion - Добавляет элемент по указанному индексу.
Deletion - Удаляет элемент по данному индексу.
Search - Ищет элемент по заданному индексу или по значению.
Update - Обновляет элемент по заданному индексу.
В C, когда массив инициализируется размером, он присваивает значения по умолчанию своим элементам в следующем порядке.
| Тип данных | Значение по умолчанию |
|---|---|
| bool | false |
| char | 0 |
| int | 0 |
| float | 0.0 |
| double | 0.0f |
| void | |
| wchar_t | 0 |
Traverse Operation
This operation is to traverse through the elements of an array.
Example
Following program traverses and prints the elements of an array:
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}When we compile and execute the above program, it produces the following result −
Output
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8Insertion Operation
Insert operation is to insert one or more data elements into an array. Based on the requirement, a new element can be added at the beginning, end, or any given index of array.
Here, we see a practical implementation of insertion operation, where we add data at the end of the array −
Example
Following is the implementation of the above algorithm −
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
n = n + 1;
while( j >= k) {
LA[j+1] = LA[j];
j = j - 1;
}
LA[k] = item;
printf("The array elements after insertion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}When we compile and execute the above program, it produces the following result −
Output
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after insertion :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 10
LA[4] = 7
LA[5] = 8For other variations of array insertion operation click here
Deletion Operation
Deletion refers to removing an existing element from the array and re-organizing all elements of an array.
Algorithm
Consider LA is a linear array with N elements and K is a positive integer such that K<=N. Following is the algorithm to delete an element available at the Kth position of LA.
1. Start
2. Set J = K
3. Repeat steps 4 and 5 while J < N
4. Set LA[J] = LA[J + 1]
5. Set J = J+1
6. Set N = N-1
7. StopExample
Following is the implementation of the above algorithm −
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
j = k;
while( j < n) {
LA[j-1] = LA[j];
j = j + 1;
}
n = n -1;
printf("The array elements after deletion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}When we compile and execute the above program, it produces the following result −
Output
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after deletion :
LA[0] = 1
LA[1] = 3
LA[2] = 7
LA[3] = 8Search Operation
You can perform a search for an array element based on its value or its index.
Algorithm
Consider LA is a linear array with N elements and K is a positive integer such that K<=N. Following is the algorithm to find an element with a value of ITEM using sequential search.
1. Start
2. Set J = 0
3. Repeat steps 4 and 5 while J < N
4. IF LA[J] is equal ITEM THEN GOTO STEP 6
5. Set J = J +1
6. PRINT J, ITEM
7. StopExample
Following is the implementation of the above algorithm −
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int item = 5, n = 5;
int i = 0, j = 0;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
while( j < n){
if( LA[j] == item ) {
break;
}
j = j + 1;
}
printf("Found element %d at position %d\n", item, j+1);
}When we compile and execute the above program, it produces the following result −
Output
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
Found element 5 at position 3Update Operation
Update operation refers to updating an existing element from the array at a given index.
Algorithm
Consider LA is a linear array with N elements and K is a positive integer such that K<=N. Following is the algorithm to update an element available at the Kth position of LA.
1. Start
2. Set LA[K-1] = ITEM
3. StopExample
Following is the implementation of the above algorithm −
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5, item = 10;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
LA[k-1] = item;
printf("The array elements after updation :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}When we compile and execute the above program, it produces the following result −
Output
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after updation :
LA[0] = 1
LA[1] = 3
LA[2] = 10
LA[3] = 7
LA[4] = 8A linked list is a sequence of data structures, which are connected together via links.
Linked List is a sequence of links which contains items. Each link contains a connection to another link. Linked list is the second most-used data structure after array. Following are the important terms to understand the concept of Linked List.
Link − Each link of a linked list can store a data called an element.
Next − Each link of a linked list contains a link to the next link called Next.
LinkedList − A Linked List contains the connection link to the first link called First.
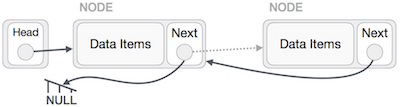
Linked List Representation
Linked list can be visualized as a chain of nodes, where every node points to the next node.

As per the above illustration, following are the important points to be considered.
Linked List contains a link element called first.
Each link carries a data field(s) and a link field called next.
Each link is linked with its next link using its next link.
Last link carries a link as null to mark the end of the list.
Types of Linked List
Following are the various types of linked list.
Simple Linked List − Item navigation is forward only.
Doubly Linked List − Items can be navigated forward and backward.
Circular Linked List − Last item contains link of the first element as next and the first element has a link to the last element as previous.
Basic Operations
Following are the basic operations supported by a list.
Insertion − Adds an element at the beginning of the list.
Deletion − Deletes an element at the beginning of the list.
Display − Displays the complete list.
Search − Searches an element using the given key.
Delete − Deletes an element using the given key.
Insertion Operation
Adding a new node in linked list is a more than one step activity. We shall learn this with diagrams here. First, create a node using the same structure and find the location where it has to be inserted.

Imagine that we are inserting a node B (NewNode), between A (LeftNode) and C (RightNode). Then point B.next to C −
NewNode.next −> RightNode;It should look like this −

Now, the next node at the left should point to the new node.
LeftNode.next −> NewNode;
This will put the new node in the middle of the two. The new list should look like this −

Similar steps should be taken if the node is being inserted at the beginning of the list. While inserting it at the end, the second last node of the list should point to the new node and the new node will point to NULL.
Deletion Operation
Deletion is also a more than one step process. We shall learn with pictorial representation. First, locate the target node to be removed, by using searching algorithms.

The left (previous) node of the target node now should point to the next node of the target node −
LeftNode.next −> TargetNode.next;
This will remove the link that was pointing to the target node. Now, using the following code, we will remove what the target node is pointing at.
TargetNode.next −> NULL;
We need to use the deleted node. We can keep that in memory otherwise we can simply deallocate memory and wipe off the target node completely.

Reverse Operation
This operation is a thorough one. We need to make the last node to be pointed by the head node and reverse the whole linked list.
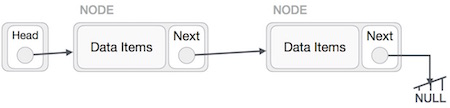
First, we traverse to the end of the list. It should be pointing to NULL. Now, we shall make it point to its previous node −
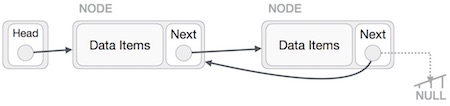
We have to make sure that the last node is not the last node. So we'll have some temp node, which looks like the head node pointing to the last node. Now, we shall make all left side nodes point to their previous nodes one by one.
Except the node (first node) pointed by the head node, all nodes should point to their predecessor, making them their new successor. The first node will point to NULL.

We'll make the head node point to the new first node by using the temp node.
The linked list is now reversed. To see linked list implementation in C programming language, please click here.
Doubly Linked List is a variation of Linked list in which navigation is possible in both ways, either forward and backward easily as compared to Single Linked List. Following are the important terms to understand the concept of doubly linked list.
Link − Each link of a linked list can store a data called an element.
Next − Each link of a linked list contains a link to the next link called Next.
Prev − Each link of a linked list contains a link to the previous link called Prev.
LinkedList − A Linked List contains the connection link to the first link called First and to the last link called Last.
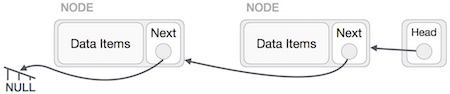
Doubly Linked List Representation

As per the above illustration, following are the important points to be considered.
Doubly Linked List contains a link element called first and last.
Each link carries a data field(s) and two link fields called next and prev.
Each link is linked with its next link using its next link.
Each link is linked with its previous link using its previous link.
The last link carries a link as null to mark the end of the list.
Basic Operations
Following are the basic operations supported by a list.
Insertion − Adds an element at the beginning of the list.
Deletion − Deletes an element at the beginning of the list.
Insert Last − Adds an element at the end of the list.
Delete Last − Deletes an element from the end of the list.
Insert After − Adds an element after an item of the list.
Delete − Deletes an element from the list using the key.
Display forward − Displays the complete list in a forward manner.
Display backward − Displays the complete list in a backward manner.
Insertion Operation
Following code demonstrates the insertion operation at the beginning of a doubly linked list.
Example
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//update first prev link
head->prev = link;
}
//point it to old first link
link->next = head;
//point first to new first link
head = link;
}Deletion Operation
Following code demonstrates the deletion operation at the beginning of a doubly linked list.
Example
//delete first item
struct node* deleteFirst() {
//save reference to first link
struct node *tempLink = head;
//if only one link
if(head->next == NULL) {
last = NULL;
} else {
head->next->prev = NULL;
}
head = head->next;
//return the deleted link
return tempLink;
}Insertion at the End of an Operation
Following code demonstrates the insertion operation at the last position of a doubly linked list.
Example
//insert link at the last location
void insertLast(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//make link a new last link
last->next = link;
//mark old last node as prev of new link
link->prev = last;
}
//point last to new last node
last = link;
}To see the implementation in C programming language, please click here.
Circular Linked List is a variation of Linked list in which the first element points to the last element and the last element points to the first element. Both Singly Linked List and Doubly Linked List can be made into a circular linked list.
Singly Linked List as Circular
In singly linked list, the next pointer of the last node points to the first node.

Doubly Linked List as Circular
In doubly linked list, the next pointer of the last node points to the first node and the previous pointer of the first node points to the last node making the circular in both directions.

As per the above illustration, following are the important points to be considered.
The last link's next points to the first link of the list in both cases of singly as well as doubly linked list.
The first link's previous points to the last of the list in case of doubly linked list.
Basic Operations
Following are the important operations supported by a circular list.
insert − Inserts an element at the start of the list.
delete − Deletes an element from the start of the list.
display − Displays the list.
Insertion Operation
Following code demonstrates the insertion operation in a circular linked list based on single linked list.
пример
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data= data;
if (isEmpty()) {
head = link;
head->next = head;
} else {
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}Операция удаления
Следующий код демонстрирует операцию удаления в круговом связном списке на основе односвязного списка.
//delete first item
struct node * deleteFirst() {
//save reference to first link
struct node *tempLink = head;
if(head->next == head) {
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}Отображение списка операций
Следующий код демонстрирует работу списка отображения в круговом связном списке.
//display the list
void printList() {
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL) {
while(ptr->next != ptr) {
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}Чтобы узнать о его реализации на языке программирования C, нажмите здесь .
Стек - это абстрактный тип данных (ADT), обычно используемый в большинстве языков программирования. Он называется стеком, поскольку ведет себя, например, как реальный стек - колода карт, стопка тарелок и т. Д.

Реальный стек позволяет выполнять операции только на одном конце. Например, мы можем разместить или удалить карту или тарелку только из верхней части стопки. Точно так же Stack ADT позволяет все операции с данными только на одном конце. В любой момент времени мы можем получить доступ только к верхнему элементу стека.
Эта функция делает его структурой данных LIFO. LIFO расшифровывается как Last-in-first-out. Здесь первым осуществляется доступ к элементу, который помещен (вставлен или добавлен) последним. В терминологии стека операция вставки называетсяPUSH операция и операция удаления называется POP операция.
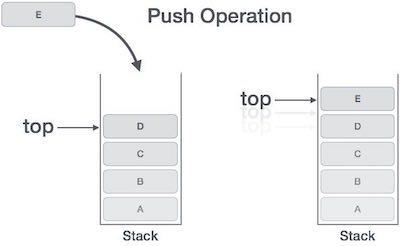
Представление стека
На следующей диаграмме изображен стек и его операции.

Стек может быть реализован с помощью массива, структуры, указателя и связанного списка. Стек может быть либо фиксированного размера, либо иметь динамическое изменение размера. Здесь мы собираемся реализовать стек с использованием массивов, что делает его реализацией стека фиксированного размера.
Основные операции
Операции со стеком могут включать инициализацию стека, его использование и последующую деинициализацию. Помимо этих основных вещей, стек используется для следующих двух основных операций:
push() - Размещение (сохранение) элемента в стеке.
pop() - Удаление (доступ) элемента из стека.
Когда данные помещаются в стек.
Чтобы использовать стек эффективно, нам также необходимо проверить его состояние. С той же целью в стеки добавлены следующие функции:
peek() - получить верхний элемент данных стека, не удаляя его.
isFull() - проверить, заполнен ли стек.
isEmpty() - проверить, пуст ли стек.
Мы всегда поддерживаем указатель на последние PUSH-данные в стеке. Поскольку этот указатель всегда представляет верхнюю часть стека, поэтому он называетсяtop. Вtop указатель предоставляет верхнее значение стека, не удаляя его.
Сначала мы должны узнать о процедурах для поддержки функций стека -
заглянуть ()
Алгоритм функции peek () -
begin procedure peek
return stack[top]
end procedureРеализация функции peek () на языке программирования C -
Example
int peek() {
return stack[top];
}полон()
Алгоритм функции isfull () -
begin procedure isfull
if top equals to MAXSIZE
return true
else
return false
endif
end procedureРеализация функции isfull () на языке программирования C -
Example
bool isfull() {
if(top == MAXSIZE)
return true;
else
return false;
}пусто()
Алгоритм функции isempty () -
begin procedure isempty
if top less than 1
return true
else
return false
endif
end procedureРеализация функции isempty () на языке программирования C немного отличается. Мы инициализируем вершину со значением -1, поскольку индекс в массиве начинается с 0. Итак, мы проверяем, находится ли вершина ниже нуля или -1, чтобы определить, пуст ли стек. Вот код -
Example
bool isempty() {
if(top == -1)
return true;
else
return false;
}Нажать операцию
Процесс помещения нового элемента данных в стек известен как операция проталкивания. Операция выталкивания включает в себя ряд шагов -
Step 1 - Проверяет, заполнен ли стек.
Step 2 - Если стек заполнен, выдает ошибку и выходит.
Step 3 - Если стек не заполнен, увеличивается top чтобы указать следующее пустое пространство.
Step 4 - Добавляет элемент данных в то место стека, куда указывает вершина.
Step 5 - Возвращает успех.
Если связанный список используется для реализации стека, то на шаге 3 нам нужно динамически распределять пространство.
Алгоритм работы PUSH
Простой алгоритм для операции Push может быть получен следующим образом:
begin procedure push: stack, data
if stack is full
return null
endif
top ← top + 1
stack[top] ← data
end procedureРеализовать этот алгоритм на C очень просто. См. Следующий код -
Example
void push(int data) {
if(!isFull()) {
top = top + 1;
stack[top] = data;
} else {
printf("Could not insert data, Stack is full.\n");
}
}Поп-операция
Доступ к содержимому при удалении его из стека известен как Pop Operation. В массиве реализации операции pop () элемент данных фактически не удаляется, вместо этогоtopуменьшается до более низкой позиции в стеке, чтобы указать на следующее значение. Но в реализации связанного списка pop () фактически удаляет элемент данных и освобождает пространство памяти.
Операция Pop может включать следующие шаги:
Step 1 - Проверяет, пуста ли стопка.
Step 2 - Если стек пуст, выдает ошибку и выходит.
Step 3 - Если стек не пуст, обращается к элементу данных, в котором top указывает.
Step 4 - Уменьшает значение вершины на 1.
Step 5 - Возвращает успех.

Алгоритм работы Pop
Простой алгоритм работы Pop может быть получен следующим образом:
begin procedure pop: stack
if stack is empty
return null
endif
data ← stack[top]
top ← top - 1
return data
end procedureРеализация этого алгоритма на C выглядит следующим образом:
Example
int pop(int data) {
if(!isempty()) {
data = stack[top];
top = top - 1;
return data;
} else {
printf("Could not retrieve data, Stack is empty.\n");
}
}Чтобы получить полную стековую программу на языке программирования C, щелкните здесь .
Способ написания арифметического выражения известен как notation. Арифметическое выражение может быть записано в трех различных, но эквивалентных обозначениях, т. Е. Без изменения сути или вывода выражения. Эти обозначения -
- Обозначение инфиксов
- Префиксное (польское) обозначение
- Постфиксная (обратнопольская) нотация
Эти обозначения названы так, как они используют оператор в выражении. Мы узнаем то же самое здесь, в этой главе.
Обозначение инфиксов
Записываем выражение в infix обозначение, например a - b + c, где используются операторы in-между операндами. Нам, людям, легко читать, писать и говорить в инфиксной нотации, но это плохо сочетается с вычислительными устройствами. Алгоритм обработки инфиксной записи может быть трудным и дорогостоящим с точки зрения затрат времени и места.
Обозначение префикса
В этих обозначениях оператор prefixed в операнды, т.е. оператор записывается перед операндами. Например,+ab. Это эквивалентно его инфиксной записиa + b. Обозначение префикса также известно какPolish Notation.
Постфиксная нотация
Этот стиль обозначений известен как Reversed Polish Notation. В этом стиле записи операторpostfixed в операнды, т. е. оператор записывается после операндов. Например,ab+. Это эквивалентно его инфиксной записиa + b.
Следующая таблица вкратце пытается показать разницу во всех трех обозначениях -
| Sr.No. | Обозначение инфиксов | Обозначение префикса | Постфиксная нотация |
|---|---|---|---|
| 1 | а + б | + ab | ab + |
| 2 | (a + b) ∗ c | ∗ + abc | ab + c ∗ |
| 3 | а * (Ь + с) | ∗ a + bc | abc + ∗ |
| 4 | а / б + в / г | + / ab / cd | ab / cd / + |
| 5 | (а + б) * (с + г) | * + Ab + cd | ab + cd + ∗ |
| 6 | ((a + b) ∗ c) - d | - ∗ + abcd | ab + c ∗ d - |
Анализ выражений
Как мы уже говорили, это не очень эффективный способ разработки алгоритма или программы для анализа инфиксных обозначений. Вместо этого эти инфиксные обозначения сначала преобразуются в постфиксные или префиксные обозначения, а затем вычисляются.
Чтобы проанализировать любое арифметическое выражение, нам также необходимо позаботиться о приоритете операторов и ассоциативности.
Приоритет
Когда операнд находится между двумя разными операторами, какой оператор примет операнд первым, определяется приоритетом оператора над другими. Например -

Поскольку операция умножения имеет приоритет перед сложением, сначала будет вычисляться b * c. Таблица приоритета операторов представлена позже.
Ассоциативность
Ассоциативность описывает правило, при котором в выражении появляются операторы с одинаковым приоритетом. Например, в выражении a + b - c оба символа + и - имеют одинаковый приоритет, тогда какая часть выражения будет оценена первой, определяется ассоциативностью этих операторов. Здесь оба символа + и - остаются ассоциативными, поэтому выражение будет оцениваться как(a + b) − c.
Приоритет и ассоциативность определяют порядок оценки выражения. Ниже приведена таблица приоритетов и ассоциативности операторов (от высшей к низшей).
| Sr.No. | Оператор | Приоритет | Ассоциативность |
|---|---|---|---|
| 1 | Возведение в степень ^ | Самый высокий | Правый ассоциативный |
| 2 | Умножение (*) и деление (/) | Второй по величине | Левая ассоциативная |
| 3 | Сложение (+) и вычитание (-) | Самый низкий | Левая ассоциативная |
В приведенной выше таблице показано поведение операторов по умолчанию. В любой момент при оценке выражения порядок можно изменить, используя круглые скобки. Например -
В a + b*c, часть выражения b*cбудет оцениваться первым, умножение будет иметь приоритет перед сложением. Здесь мы используем скобки дляa + b быть оцененным в первую очередь, например (a + b)*c.
Постфиксный алгоритм оценки
Теперь мы рассмотрим алгоритм того, как оценивать постфиксную нотацию -
Step 1 − scan the expression from left to right
Step 2 − if it is an operand push it to stack
Step 3 − if it is an operator pull operand from stack and perform operation
Step 4 − store the output of step 3, back to stack
Step 5 − scan the expression until all operands are consumed
Step 6 − pop the stack and perform operationЧтобы увидеть реализацию на языке программирования C, щелкните здесь .
Очередь - это абстрактная структура данных, чем-то похожая на стеки. В отличие от стеков, очередь открыта с обоих концов. Один конец всегда используется для вставки данных (постановка в очередь), а другой - для удаления данных (постановка из очереди). Очередь следует методологии «первым пришел - первым обслужен», то есть первым будет осуществлен доступ к элементу данных, который хранится первым.

Реальным примером очереди может быть однополосная дорога с односторонним движением, когда автомобиль входит первым, а выезжает первым. Более реальные примеры можно увидеть в очередях у касс и автобусных остановках.
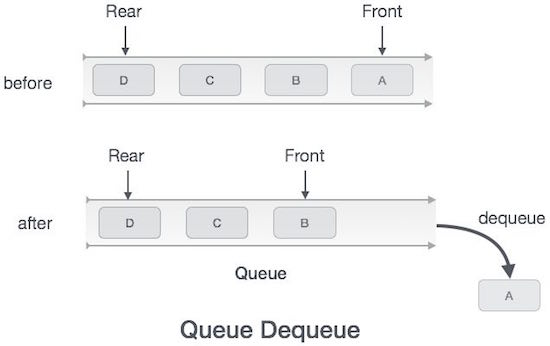
Представление очереди
Как мы теперь понимаем, в очереди мы обращаемся к обоим концам по разным причинам. Следующая диаграмма, приведенная ниже, пытается объяснить представление очереди как структуру данных -

Как и в случае стека, очередь также может быть реализована с использованием массивов, связанных списков, указателей и структур. Для простоты будем реализовывать очереди с использованием одномерного массива.
Основные операции
Операции с очередями могут включать инициализацию или определение очереди, ее использование и затем полное стирание из памяти. Здесь мы попытаемся понять основные операции, связанные с очередями -
enqueue() - добавить (сохранить) элемент в очередь.
dequeue() - удалить (получить доступ) элемент из очереди.
Для повышения эффективности вышеупомянутой операции с очередью требуется еще несколько функций. Это -
peek() - Получает элемент в начале очереди, не удаляя его.
isfull() - Проверяет, заполнена ли очередь.
isempty() - Проверяет, пуста ли очередь.
В очереди мы всегда удаляем из очереди (или получаем доступ) данные, на которые указывает front указатель и при постановке (или хранении) данных в очереди мы используем rear указатель.
Давайте сначала узнаем о вспомогательных функциях очереди -
заглянуть ()
Эта функция помогает видеть данные в frontочереди. Алгоритм функции peek () следующий:
Algorithm
begin procedure peek
return queue[front]
end procedureРеализация функции peek () на языке программирования C -
Example
int peek() {
return queue[front];
}полон()
Поскольку мы используем одномерный массив для реализации очереди, мы просто проверяем, достигает ли задний указатель MAXSIZE, чтобы определить, что очередь заполнена. Если мы ведем очередь в круговом связном списке, алгоритм будет другим. Алгоритм функции isfull () -
Algorithm
begin procedure isfull
if rear equals to MAXSIZE
return true
else
return false
endif
end procedureРеализация функции isfull () на языке программирования C -
Example
bool isfull() {
if(rear == MAXSIZE - 1)
return true;
else
return false;
}пусто()
Алгоритм функции isempty () -
Algorithm
begin procedure isempty
if front is less than MIN OR front is greater than rear
return true
else
return false
endif
end procedureЕсли значение front меньше MIN или 0, это означает, что очередь еще не инициализирована, следовательно, пуста.
Вот программный код C -
Example
bool isempty() {
if(front < 0 || front > rear)
return true;
else
return false;
}Операция постановки в очередь
Очереди поддерживают два указателя данных, front и rear. Следовательно, его операции сравнительно сложно реализовать, чем операции стеков.
Для постановки (вставки) данных в очередь необходимо предпринять следующие шаги:
Step 1 - Проверьте, не заполнена ли очередь.
Step 2 - Если очередь заполнена, вывести ошибку переполнения и выйти.
Step 3 - Если очередь не заполнена, увеличивайте rear указатель, указывающий на следующее пустое пространство.
Step 4 - Добавить элемент данных в то место очереди, куда указывает задняя часть.
Step 5 - вернуть успех.

Иногда мы также проверяем, инициализирована ли очередь или нет, чтобы справиться с любыми непредвиденными ситуациями.
Алгоритм постановки в очередь
procedure enqueue(data)
if queue is full
return overflow
endif
rear ← rear + 1
queue[rear] ← data
return true
end procedureРеализация enqueue () на языке программирования C -
Example
int enqueue(int data)
if(isfull())
return 0;
rear = rear + 1;
queue[rear] = data;
return 1;
end procedureУдаление из очереди
Доступ к данным из очереди - это процесс, состоящий из двух задач: доступ к данным, в которых frontуказывает и удаляет данные после доступа. Следующие шаги предпринимаются для выполненияdequeue операция -
Step 1 - Проверьте, пуста ли очередь.
Step 2 - Если очередь пуста, вывести ошибку переполнения и выйти.
Step 3 - Если очередь не пуста, доступ к данным, где front указывает.
Step 4 - Приращение front указатель, указывающий на следующий доступный элемент данных.
Step 5 - Верни успех.
Алгоритм удаления из очереди
procedure dequeue
if queue is empty
return underflow
end if
data = queue[front]
front ← front + 1
return true
end procedureРеализация dequeue () на языке программирования C -
Example
int dequeue() {
if(isempty())
return 0;
int data = queue[front];
front = front + 1;
return data;
}Чтобы просмотреть полную программу Queue на языке программирования C, щелкните здесь .
Линейный поиск - это очень простой алгоритм поиска. В этом типе поиска выполняется последовательный поиск по всем элементам один за другим. Каждый элемент проверяется, и если совпадение найдено, возвращается этот конкретный элемент, в противном случае поиск продолжается до конца сбора данных.

Алгоритм
Linear Search ( Array A, Value x)
Step 1: Set i to 1
Step 2: if i > n then go to step 7
Step 3: if A[i] = x then go to step 6
Step 4: Set i to i + 1
Step 5: Go to Step 2
Step 6: Print Element x Found at index i and go to step 8
Step 7: Print element not found
Step 8: ExitПсевдокод
procedure linear_search (list, value)
for each item in the list
if match item == value
return the item's location
end if
end for
end procedureЧтобы узнать о реализации линейного поиска на языке программирования C, нажмите здесь .
Двоичный поиск - это алгоритм быстрого поиска со сложностью выполнения Ο (log n). Этот алгоритм поиска работает по принципу «разделяй и властвуй». Чтобы этот алгоритм работал правильно, сбор данных должен быть в отсортированном виде.
Двоичный поиск ищет конкретный элемент, сравнивая самый средний элемент коллекции. Если совпадение происходит, возвращается индекс элемента. Если средний элемент больше, чем элемент, то этот элемент ищется в подмассиве слева от среднего элемента. В противном случае элемент ищется в подмассиве справа от среднего элемента. Этот процесс продолжается и с субмассивом до тех пор, пока размер субмассива не уменьшится до нуля.
Как работает двоичный поиск?
Чтобы бинарный поиск работал, необходимо, чтобы целевой массив был отсортирован. Мы изучим процесс двоичного поиска на наглядном примере. Ниже представлен наш отсортированный массив, и давайте предположим, что нам нужно найти местоположение значения 31 с помощью двоичного поиска.

Сначала мы определим половину массива, используя эту формулу -
mid = low + (high - low) / 2Вот оно, 0 + (9-0) / 2 = 4 (целое значение 4,5). Итак, 4 - это середина массива.

Теперь мы сравниваем значение, сохраненное в ячейке 4, с искомым значением, т.е. 31. Мы обнаруживаем, что значение в ячейке 4 равно 27, что не является совпадением. Поскольку значение больше 27 и у нас есть отсортированный массив, мы также знаем, что целевое значение должно находиться в верхней части массива.

Мы меняем наш низкий на средний + 1 и снова находим новое среднее значение.
low = mid + 1
mid = low + (high - low) / 2Нашему новому миду сейчас 7 лет. Мы сравниваем значение, сохраненное в ячейке 7, с нашим целевым значением 31.

Значение, хранящееся в ячейке 7, не совпадает, скорее, это больше, чем то, что мы ищем. Значит, значение должно быть в нижней части от этого места.

Следовательно, мы снова вычисляем мид. На этот раз 5.

Мы сравниваем значение, сохраненное в ячейке 5, с нашим целевым значением. Мы обнаруживаем, что это совпадение.

Мы заключаем, что целевое значение 31 хранится в ячейке 5.
Двоичный поиск вдвое сокращает доступные для поиска элементы и, таким образом, сокращает количество производимых сравнений до очень меньшего числа.
Псевдокод
Псевдокод алгоритмов двоичного поиска должен выглядеть так -
Procedure binary_search
A ← sorted array
n ← size of array
x ← value to be searched
Set lowerBound = 1
Set upperBound = n
while x not found
if upperBound < lowerBound
EXIT: x does not exists.
set midPoint = lowerBound + ( upperBound - lowerBound ) / 2
if A[midPoint] < x
set lowerBound = midPoint + 1
if A[midPoint] > x
set upperBound = midPoint - 1
if A[midPoint] = x
EXIT: x found at location midPoint
end while
end procedureЧтобы узнать о реализации двоичного поиска с использованием массива на языке программирования C, нажмите здесь .
Поиск с интерполяцией - это улучшенный вариант двоичного поиска. Этот алгоритм поиска работает с поиском позиции искомого значения. Чтобы этот алгоритм работал правильно, сбор данных должен быть в отсортированном виде и равномерно распределен.
Двоичный поиск имеет огромное преимущество во временной сложности перед линейным поиском. Линейный поиск имеет сложность наихудшего случая Ο (n), тогда как двоичный поиск имеет сложность Ο (log n).
Бывают случаи, когда местоположение целевых данных может быть известно заранее. Например, в случае телефонного справочника, если мы хотим найти телефонный номер Морфиуса. Здесь линейный поиск и даже двоичный поиск будут казаться медленными, поскольку мы можем напрямую перейти в область памяти, где хранятся имена, начинающиеся с «M».
Позиционирование в двоичном поиске
При бинарном поиске, если нужные данные не найдены, остальная часть списка делится на две части: нижнюю и верхнюю. Поиск ведется в любом из них.




Даже когда данные отсортированы, двоичный поиск не использует преимущества для проверки положения требуемых данных.
Определение местоположения при поиске с интерполяцией
Поиск с интерполяцией находит конкретный элемент, вычисляя положение зонда. Первоначально позиция зонда - это позиция самого среднего элемента коллекции.


Если совпадение происходит, возвращается индекс элемента. Чтобы разделить список на две части, мы используем следующий метод -
mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
where −
A = list
Lo = Lowest index of the list
Hi = Highest index of the list
A[n] = Value stored at index n in the listЕсли средний элемент больше, чем элемент, то позиция зонда снова вычисляется в подмассиве справа от среднего элемента. В противном случае элемент ищется в подмассиве слева от среднего элемента. Этот процесс продолжается и с подмассивом до тех пор, пока размер подмассива не уменьшится до нуля.
Сложность выполнения алгоритма интерполяционного поиска составляет Ο(log (log n)) по сравнению с Ο(log n) BST в благоприятных ситуациях.
Алгоритм
Поскольку это импровизация существующего алгоритма BST, мы упоминаем шаги для поиска «целевого» индекса значения данных с использованием определения положения -
Step 1 − Start searching data from middle of the list.
Step 2 − If it is a match, return the index of the item, and exit.
Step 3 − If it is not a match, probe position.
Step 4 − Divide the list using probing formula and find the new midle.
Step 5 − If data is greater than middle, search in higher sub-list.
Step 6 − If data is smaller than middle, search in lower sub-list.
Step 7 − Repeat until match.Псевдокод
A → Array list
N → Size of A
X → Target Value
Procedure Interpolation_Search()
Set Lo → 0
Set Mid → -1
Set Hi → N-1
While X does not match
if Lo equals to Hi OR A[Lo] equals to A[Hi]
EXIT: Failure, Target not found
end if
Set Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
if A[Mid] = X
EXIT: Success, Target found at Mid
else
if A[Mid] < X
Set Lo to Mid+1
else if A[Mid] > X
Set Hi to Mid-1
end if
end if
End While
End ProcedureЧтобы узнать о реализации поиска с интерполяцией в языке программирования C, щелкните здесь .
Хеш-таблица - это структура данных, в которой данные хранятся ассоциативно. В хеш-таблице данные хранятся в формате массива, где каждое значение данных имеет собственное уникальное значение индекса. Доступ к данным становится очень быстрым, если мы знаем индекс желаемых данных.
Таким образом, это становится структурой данных, в которой операции вставки и поиска выполняются очень быстро независимо от размера данных. Хэш-таблица использует массив в качестве носителя данных и использует метод хеширования для генерации индекса, в котором элемент должен быть вставлен или из которого должен быть расположен.
Хеширование
Хеширование - это метод преобразования диапазона значений ключа в диапазон индексов массива. Мы собираемся использовать оператор по модулю, чтобы получить диапазон значений ключа. Рассмотрим пример хеш-таблицы размером 20, и следующие элементы должны быть сохранены. Элементы имеют формат (ключ, значение).

- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Ключ | Хеш | Индекс массива |
|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 |
| 4 | 4 | 4% 20 = 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 |
Линейное зондирование
Как мы видим, может случиться так, что метод хеширования используется для создания уже использованного индекса массива. В таком случае мы можем искать следующую пустую ячейку в массиве, заглядывая в следующую ячейку, пока не найдем пустую ячейку. Этот метод называется линейным зондированием.
| Sr.No. | Ключ | Хеш | Индекс массива | После линейного измерения, индекс массива |
|---|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 | 3 |
| 4 | 4 | 4% 20 = 4 | 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 | 18 |
Основные операции
Ниже приведены основные основные операции хеш-таблицы.
Search - Ищет элемент в хеш-таблице.
Insert - вставляет элемент в хеш-таблицу.
delete - Удаляет элемент из хеш-таблицы.
DataItem
Определите элемент данных, содержащий некоторые данные и ключ, на основе которых будет проводиться поиск в хеш-таблице.
struct DataItem {
int data;
int key;
};Метод хеширования
Определите метод хеширования для вычисления хэш-кода ключа элемента данных.
int hashCode(int key){
return key % SIZE;
}Поисковая операция
Всякий раз, когда элемент должен быть найден, вычислите хэш-код переданного ключа и найдите элемент, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование, чтобы продвинуть элемент вперед, если элемент не найден в вычисленном хэш-коде.
пример
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}Вставить операцию
Каждый раз, когда элемент должен быть вставлен, вычислите хэш-код переданного ключа и найдите индекс, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование для пустого места, если элемент найден в вычисленном хэш-коде.
пример
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}Удалить операцию
Всякий раз, когда элемент должен быть удален, вычислите хэш-код переданного ключа и найдите индекс, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование, чтобы продвинуть элемент вперед, если элемент не найден в вычисленном хэш-коде. При обнаружении сохраните там фиктивный элемент, чтобы сохранить производительность хеш-таблицы.
пример
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}Чтобы узнать о реализации хэша на языке программирования C, нажмите здесь .
Сортировка относится к расположению данных в определенном формате. Алгоритм сортировки определяет способ упорядочивания данных в определенном порядке. Чаще всего заказывается в числовом или лексикографическом порядке.
Важность сортировки заключается в том, что поиск данных можно оптимизировать до очень высокого уровня, если данные хранятся в отсортированном виде. Сортировка также используется для представления данных в более удобочитаемых форматах. Ниже приведены некоторые примеры сортировки в реальных сценариях.
Telephone Directory - В телефонном справочнике хранятся телефонные номера людей, отсортированные по именам, что упрощает поиск по именам.
Dictionary - Словарь хранит слова в алфавитном порядке, поэтому поиск любого слова становится легким.
Сортировка на месте и сортировка без места
Алгоритмам сортировки может потребоваться дополнительное пространство для сравнения и временного хранения нескольких элементов данных. Эти алгоритмы не требуют дополнительного места, и говорят, что сортировка происходит на месте или, например, внутри самого массива. Это называетсяin-place sorting. Пузырьковая сортировка - это пример сортировки на месте.
Однако в некоторых алгоритмах сортировки программе требуется пространство, которое больше или равно сортируемым элементам. Сортировка, использующая равное или большее пространство, называетсяnot-in-place sorting. Сортировка слиянием - это пример сортировки не по месту.
Стабильная и нестабильная сортировка
Если алгоритм сортировки после сортировки содержимого не изменяет последовательность аналогичного содержимого, в котором они появляются, он называется stable sorting.

Если алгоритм сортировки после сортировки содержимого изменяет последовательность аналогичного содержимого, в котором они появляются, он называется unstable sorting.

Стабильность алгоритма имеет значение, когда мы хотим сохранить последовательность исходных элементов, например, в кортеже.
Адаптивный и неадаптивный алгоритм сортировки
Алгоритм сортировки называется адаптивным, если он использует уже «отсортированные» элементы в списке, который нужно отсортировать. То есть при сортировке, если в исходном списке есть уже отсортированный элемент, адаптивные алгоритмы учтут это и постараются не переупорядочивать их.
Неадаптивный алгоритм - это алгоритм, не учитывающий уже отсортированные элементы. Они пытаются принудительно переупорядочить каждый элемент, чтобы подтвердить их сортировку.
Важные термины
Некоторые термины обычно используются при обсуждении методов сортировки, вот краткое введение в них -
Возрастающий порядок
Говорят, что последовательность значений находится в increasing order, если следующий элемент больше предыдущего. Например, 1, 3, 4, 6, 8, 9 находятся в порядке возрастания, поскольку каждый следующий элемент больше предыдущего.
Убывающий порядок
Говорят, что последовательность значений находится в decreasing order, если следующий элемент меньше текущего. Например, 9, 8, 6, 4, 3, 1 находятся в порядке убывания, поскольку каждый следующий элемент меньше предыдущего.
Неувеличивающийся порядок
Говорят, что последовательность значений находится в non-increasing order, если последующий элемент меньше или равен своему предыдущему элементу в последовательности. Этот порядок возникает, когда последовательность содержит повторяющиеся значения. Например, 9, 8, 6, 3, 3, 1 находятся в невозрастающем порядке, поскольку каждый следующий элемент меньше или равен (в случае 3), но не больше любого предыдущего элемента.
Неубывающий порядок
Говорят, что последовательность значений находится в non-decreasing order, если последующий элемент больше или равен своему предыдущему элементу в последовательности. Этот порядок возникает, когда последовательность содержит повторяющиеся значения. Например, 1, 3, 3, 6, 8, 9 находятся в порядке неубывания, так как каждый следующий элемент больше или равен (в случае 3), но не меньше предыдущего.
Сортировка пузырьков - это простой алгоритм сортировки. Этот алгоритм сортировки основан на сравнении, в котором сравнивается каждая пара смежных элементов, и элементы меняются местами, если они не в порядке. Этот алгоритм не подходит для больших наборов данных, поскольку его средняя и наихудшая сложность составляют Ο (n 2 ), гдеn количество элементов.
Как работает пузырьковая сортировка?
В качестве примера возьмем несортированный массив. Сортировка пузырьков занимает Ο (n 2 ) времени, поэтому мы делаем ее короткой и точной.

Сортировка пузырьков начинается с самых первых двух элементов, сравнивая их, чтобы проверить, какой из них больше.

В этом случае значение 33 больше 14, поэтому оно уже находится в отсортированных местах. Далее мы сравниваем 33 с 27.

Мы обнаруживаем, что 27 меньше 33, и эти два значения необходимо поменять местами.

Новый массив должен выглядеть так -

Затем мы сравниваем 33 и 35. Мы обнаруживаем, что оба находятся в уже отсортированных позициях.

Затем мы переходим к следующим двум значениям: 35 и 10.

Тогда мы знаем, что 10 меньше 35. Следовательно, они не сортируются.

Мы меняем эти значения местами. Мы обнаруживаем, что достигли конца массива. После одной итерации массив должен выглядеть так:

Если быть точным, сейчас мы показываем, как должен выглядеть массив после каждой итерации. После второй итерации это должно выглядеть так -

Обратите внимание, что после каждой итерации в конце перемещается по крайней мере одно значение.

А когда свопинг не требуется, пузырьковая сортировка узнает, что массив полностью отсортирован.

Теперь мы должны рассмотреть некоторые практические аспекты пузырьковой сортировки.
Алгоритм
Мы предполагаем list это массив nэлементы. Далее предполагаем, чтоswap функция меняет местами значения заданных элементов массива.
begin BubbleSort(list)
for all elements of list
if list[i] > list[i+1]
swap(list[i], list[i+1])
end if
end for
return list
end BubbleSortПсевдокод
Мы наблюдаем в алгоритме, что пузырьковая сортировка сравнивает каждую пару элементов массива, если весь массив полностью не отсортирован в порядке возрастания. Это может вызвать несколько проблем со сложностью, например, что, если массив больше не нуждается в подкачке, поскольку все элементы уже восходят.
Чтобы облегчить проблему, мы используем одну флаговую переменную swappedчто поможет нам увидеть, произошел ли какой-либо обмен или нет. Если свопинг не произошел, т. Е. Массив не требует дополнительной обработки для сортировки, он выйдет из цикла.
Псевдокод алгоритма BubbleSort можно записать следующим образом:
procedure bubbleSort( list : array of items )
loop = list.count;
for i = 0 to loop-1 do:
swapped = false
for j = 0 to loop-1 do:
/* compare the adjacent elements */
if list[j] > list[j+1] then
/* swap them */
swap( list[j], list[j+1] )
swapped = true
end if
end for
/*if no number was swapped that means
array is sorted now, break the loop.*/
if(not swapped) then
break
end if
end for
end procedure return listРеализация
Еще одна проблема, которую мы не рассмотрели в нашем исходном алгоритме и его импровизированном псевдокоде, заключается в том, что после каждой итерации самые высокие значения устанавливаются в конце массива. Следовательно, следующая итерация не обязательно должна включать уже отсортированные элементы. Для этого в нашей реализации мы ограничиваем внутренний цикл, чтобы избежать уже отсортированных значений.
Чтобы узнать о реализации пузырьковой сортировки на языке программирования C, нажмите здесь .
Это алгоритм сортировки на основе сравнения на месте. Здесь ведется подсписок, который всегда отсортирован. Например, нижняя часть массива поддерживается для сортировки. Элемент, который должен быть «вставлен» в этот отсортированный подсписок, должен найти свое подходящее место, а затем он должен быть вставлен туда. Отсюда и название,insertion sort.
Поиск в массиве выполняется последовательно, а несортированные элементы перемещаются и вставляются в отсортированный подсписок (в том же массиве). Этот алгоритм не подходит для больших наборов данных, поскольку его средняя и наихудшая сложность составляют Ο (n 2 ), гдеn количество элементов.
Как работает сортировка вставкой?
В качестве примера возьмем несортированный массив.

Сортировка вставкой сравнивает первые два элемента.

Он обнаружил, что 14 и 33 уже находятся в порядке возрастания. На данный момент 14 находится в отсортированном подсписке.

Сортировка вставкой продвигается вперед и сравнивает 33 с 27.

И обнаруживает, что 33 не в правильном положении.

Он меняет местами 33 на 27. Он также проверяет все элементы отсортированного подсписка. Здесь мы видим, что отсортированный подсписок имеет только один элемент 14, а 27 больше 14. Следовательно, отсортированный подсписок остается отсортированным после замены.

К настоящему моменту в отсортированном подсписке имеется 14 и 27. Затем он сравнивает 33 с 10.

Эти значения не отсортированы.

Поэтому мы их меняем местами.

Однако свопинг составляет 27 и 10 несортированных.

Следовательно, мы их тоже меняем местами.

Снова мы находим 14 и 10 в несортированном порядке.

Мы снова их меняем местами. К концу третьей итерации у нас есть отсортированный подсписок из 4 пунктов.

Этот процесс продолжается до тех пор, пока все несортированные значения не будут включены в отсортированный подсписок. Теперь мы увидим некоторые программные аспекты сортировки вставками.
Алгоритм
Теперь у нас есть более широкая картина того, как работает этот метод сортировки, поэтому мы можем вывести простые шаги, с помощью которых мы можем достичь сортировки вставкой.
Step 1 − If it is the first element, it is already sorted. return 1;
Step 2 − Pick next element
Step 3 − Compare with all elements in the sorted sub-list
Step 4 − Shift all the elements in the sorted sub-list that is greater than the
value to be sorted
Step 5 − Insert the value
Step 6 − Repeat until list is sortedПсевдокод
procedure insertionSort( A : array of items )
int holePosition
int valueToInsert
for i = 1 to length(A) inclusive do:
/* select value to be inserted */
valueToInsert = A[i]
holePosition = i
/*locate hole position for the element to be inserted */
while holePosition > 0 and A[holePosition-1] > valueToInsert do:
A[holePosition] = A[holePosition-1]
holePosition = holePosition -1
end while
/* insert the number at hole position */
A[holePosition] = valueToInsert
end for
end procedureЧтобы узнать о реализации сортировки вставками на языке программирования C, нажмите здесь .
Выборочная сортировка - это простой алгоритм сортировки. Этот алгоритм сортировки представляет собой алгоритм на основе сравнения на месте, в котором список делится на две части: отсортированная часть на левом конце и несортированная часть на правом конце. Изначально отсортированная часть пуста, а несортированная часть - это весь список.
Наименьший элемент выбирается из несортированного массива и заменяется крайним левым элементом, и этот элемент становится частью отсортированного массива. Этот процесс продолжает перемещение границы несортированного массива на один элемент вправо.
Этот алгоритм не подходит для больших наборов данных, так как его средняя и худшая сложность составляют Ο (n 2 ), гдеn количество элементов.
Как работает сортировка по выбору?
Рассмотрим в качестве примера следующий изображенный массив.
Для первой позиции в отсортированном списке весь список просматривается последовательно. В первой позиции, где в настоящее время хранится 14, мы просматриваем весь список и обнаруживаем, что 10 - это наименьшее значение.

Поэтому мы заменяем 14 на 10. После одной итерации 10, которое оказывается минимальным значением в списке, появляется в первой позиции отсортированного списка.

Для второй позиции, где проживает 33, мы начинаем сканировать оставшуюся часть списка линейным образом.

Мы обнаруживаем, что 14 - это второе наименьшее значение в списке, и оно должно стоять на втором месте. Мы меняем эти значения местами.

После двух итераций два наименьших значения располагаются в начале отсортированным способом.

Тот же процесс применяется к остальным элементам в массиве.
Ниже приводится графическое изображение всего процесса сортировки.

Теперь давайте изучим некоторые программные аспекты сортировки выбора.
Алгоритм
Step 1 − Set MIN to location 0
Step 2 − Search the minimum element in the list
Step 3 − Swap with value at location MIN
Step 4 − Increment MIN to point to next element
Step 5 − Repeat until list is sortedПсевдокод
procedure selection sort
list : array of items
n : size of list
for i = 1 to n - 1
/* set current element as minimum*/
min = i
/* check the element to be minimum */
for j = i+1 to n
if list[j] < list[min] then
min = j;
end if
end for
/* swap the minimum element with the current element*/
if indexMin != i then
swap list[min] and list[i]
end if
end for
end procedureЧтобы узнать о реализации сортировки выбора на языке программирования C, нажмите здесь .
Сортировка слиянием - это метод сортировки, основанный на технике «разделяй и властвуй». С временной сложностью наихудшего случая, равной Ο (n log n), это один из самых уважаемых алгоритмов.
Сортировка слиянием сначала делит массив на равные половины, а затем объединяет их в отсортированном порядке.
Как работает сортировка слиянием?
Чтобы понять сортировку слиянием, мы берем несортированный массив следующим образом:
Мы знаем, что сортировка слиянием сначала итеративно делит весь массив на равные половины, если не достигнуты атомарные значения. Здесь мы видим, что массив из 8 элементов разделен на два массива размером 4.

Это не меняет последовательность появления предметов в оригинале. Теперь разделим эти два массива пополам.

Далее мы разделяем эти массивы и получаем атомарное значение, которое больше не может быть разделено.

Теперь мы объединяем их точно так же, как они были разбиты. Обратите внимание на цветовые коды, указанные в этих списках.
Сначала мы сравниваем элементы для каждого списка, а затем объединяем их в другой список отсортированным способом. Мы видим, что 14 и 33 находятся в отсортированных позициях. Мы сравниваем 27 и 10 и в целевом списке из 2 значений ставим сначала 10, а затем 27. Мы меняем порядок 19 и 35, тогда как 42 и 44 размещаются последовательно.

На следующей итерации фазы объединения мы сравниваем списки двух значений данных и объединяем их в список найденных значений данных, размещая все в отсортированном порядке.

После окончательного объединения список должен выглядеть так -

Теперь мы должны изучить некоторые программные аспекты сортировки слиянием.
Алгоритм
Сортировка слиянием продолжает делить список на равные половины до тех пор, пока его больше нельзя будет разделить. По определению, если это только один элемент в списке, он сортируется. Затем сортировка слиянием объединяет более мелкие отсортированные списки, сохраняя при этом сортировку нового списка.
Step 1 − if it is only one element in the list it is already sorted, return.
Step 2 − divide the list recursively into two halves until it can no more be divided.
Step 3 − merge the smaller lists into new list in sorted order.Псевдокод
Теперь мы увидим псевдокоды для функций сортировки слиянием. Как показывают наши алгоритмы, две основные функции - разделить и объединить.
Сортировка слиянием работает с рекурсией, и мы увидим нашу реализацию таким же образом.
procedure mergesort( var a as array )
if ( n == 1 ) return a
var l1 as array = a[0] ... a[n/2]
var l2 as array = a[n/2+1] ... a[n]
l1 = mergesort( l1 )
l2 = mergesort( l2 )
return merge( l1, l2 )
end procedure
procedure merge( var a as array, var b as array )
var c as array
while ( a and b have elements )
if ( a[0] > b[0] )
add b[0] to the end of c
remove b[0] from b
else
add a[0] to the end of c
remove a[0] from a
end if
end while
while ( a has elements )
add a[0] to the end of c
remove a[0] from a
end while
while ( b has elements )
add b[0] to the end of c
remove b[0] from b
end while
return c
end procedureЧтобы узнать о реализации сортировки слиянием на языке программирования C, нажмите здесь .
Сортировка оболочки - это высокоэффективный алгоритм сортировки, основанный на алгоритме сортировки вставкой. Этот алгоритм позволяет избежать больших сдвигов, как в случае сортировки вставкой, если меньшее значение находится в крайнем правом углу и должно быть перемещено в крайнее левое положение.
Этот алгоритм использует сортировку вставкой для широко распространенных элементов, сначала для их сортировки, а затем для сортировки менее широко разнесенных элементов. Этот интервал называетсяinterval. Этот интервал рассчитывается на основе формулы Кнута как -
Формула Кнута
h = h * 3 + 1
where −
h is interval with initial value 1Этот алгоритм достаточно эффективен для наборов данных среднего размера, поскольку его средняя и наихудшая сложность составляет Ο (n), где n количество элементов.
Как работает сортировка оболочки?
Давайте рассмотрим следующий пример, чтобы понять, как работает сортировка оболочки. Мы берем тот же массив, который использовали в наших предыдущих примерах. Для нашего примера и простоты понимания мы берем интервал 4. Составьте виртуальный подсписок всех значений, расположенных с интервалом в 4 позиции. Здесь эти значения: {35, 14}, {33, 19}, {42, 27} и {10, 44}

Мы сравниваем значения в каждом подсписке и меняем их местами (при необходимости) в исходном массиве. После этого шага новый массив должен выглядеть так:

Затем мы берем интервал 2, и этот пробел генерирует два подсписка - {14, 27, 35, 42}, {19, 10, 33, 44}

Мы сравниваем и меняем местами значения, если необходимо, в исходном массиве. После этого шага массив должен выглядеть так -

Наконец, мы сортируем остальную часть массива, используя интервал значения 1. Сортировка оболочки использует сортировку вставкой для сортировки массива.
Ниже приводится пошаговое описание -

Мы видим, что для сортировки остальной части массива потребовалось всего четыре перестановки.
Алгоритм
Ниже приводится алгоритм сортировки по оболочке.
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedПсевдокод
Ниже приведен псевдокод для сортировки по оболочке.
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureЧтобы узнать о реализации сортировки оболочки на языке программирования C, нажмите здесь .
Сортировка оболочки - это высокоэффективный алгоритм сортировки, основанный на алгоритме сортировки вставкой. Этот алгоритм позволяет избежать больших сдвигов, как в случае сортировки вставкой, если меньшее значение находится в крайнем правом углу и должно быть перемещено в крайнее левое положение.
Этот алгоритм использует сортировку вставкой для широко распространенных элементов, сначала для их сортировки, а затем для сортировки менее широко разнесенных элементов. Этот интервал называетсяinterval. Этот интервал рассчитывается на основе формулы Кнута как -
Формула Кнута
h = h * 3 + 1
where −
h is interval with initial value 1Этот алгоритм довольно эффективен для наборов данных среднего размера, поскольку его средняя и наихудшая сложность этого алгоритма зависит от последовательности пропусков, наиболее известной является Ο (n), где n - количество элементов. А сложность пространства в худшем случае - O (n).
Как работает сортировка оболочки?
Давайте рассмотрим следующий пример, чтобы понять, как работает сортировка оболочки. Мы берем тот же массив, который использовали в наших предыдущих примерах. Для нашего примера и простоты понимания мы берем интервал 4. Составьте виртуальный подсписок всех значений, расположенных с интервалом в 4 позиции. Здесь эти значения: {35, 14}, {33, 19}, {42, 27} и {10, 44}
Мы сравниваем значения в каждом подсписке и меняем их местами (при необходимости) в исходном массиве. После этого шага новый массив должен выглядеть так:
Затем мы берем интервал 1, и этот пробел генерирует два подсписка - {14, 27, 35, 42}, {19, 10, 33, 44}
Мы сравниваем и меняем местами значения, если необходимо, в исходном массиве. После этого шага массив должен выглядеть так -
Наконец, мы сортируем остальную часть массива, используя интервал значения 1. Сортировка оболочки использует сортировку вставкой для сортировки массива.
Ниже приводится пошаговое описание -
Мы видим, что для сортировки остальной части массива потребовалось всего четыре перестановки.
Алгоритм
Ниже приводится алгоритм сортировки по оболочке.
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedПсевдокод
Ниже приведен псевдокод для сортировки по оболочке.
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureЧтобы узнать о реализации сортировки оболочки на языке программирования C, нажмите здесь .
Быстрая сортировка - это высокоэффективный алгоритм сортировки, основанный на разделении массива данных на более мелкие массивы. Большой массив разделен на два массива, один из которых содержит значения, меньшие заданного значения, например, pivot, на основе которого создается раздел, а другой массив содержит значения, превышающие значение pivot.
Быстрая сортировка разбивает массив на разделы, а затем дважды рекурсивно вызывает себя для сортировки двух результирующих подмассивов. Этот алгоритм достаточно эффективен для наборов данных большого размера, поскольку его средняя сложность и сложность наихудшего случая составляют O (nLogn) и image.png (n 2 ) соответственно.
Раздел в быстрой сортировке
Следующее анимированное представление объясняет, как найти значение поворота в массиве.

Значение pivot делит список на две части. И рекурсивно мы находим точку поворота для каждого подсписка, пока все списки не будут содержать только один элемент.
Алгоритм быстрой сортировки
Основываясь на нашем понимании разбиения при быстрой сортировке, мы попытаемся написать для этого алгоритм, который выглядит следующим образом.
Step 1 − Choose the highest index value has pivot
Step 2 − Take two variables to point left and right of the list excluding pivot
Step 3 − left points to the low index
Step 4 − right points to the high
Step 5 − while value at left is less than pivot move right
Step 6 − while value at right is greater than pivot move left
Step 7 − if both step 5 and step 6 does not match swap left and right
Step 8 − if left ≥ right, the point where they met is new pivotПсевдокод Quick Sort Pivot
Псевдокод для вышеуказанного алгоритма может быть получен как -
function partitionFunc(left, right, pivot)
leftPointer = left
rightPointer = right - 1
while True do
while A[++leftPointer] < pivot do
//do-nothing
end while
while rightPointer > 0 && A[--rightPointer] > pivot do
//do-nothing
end while
if leftPointer >= rightPointer
break
else
swap leftPointer,rightPointer
end if
end while
swap leftPointer,right
return leftPointer
end functionАлгоритм быстрой сортировки
Используя рекурсивный алгоритм поворота, мы получаем меньшие возможные разделы. Затем каждый раздел обрабатывается для быстрой сортировки. Мы определяем рекурсивный алгоритм для быстрой сортировки следующим образом:
Step 1 − Make the right-most index value pivot
Step 2 − partition the array using pivot value
Step 3 − quicksort left partition recursively
Step 4 − quicksort right partition recursivelyПсевдокод быстрой сортировки
Чтобы узнать больше, давайте посмотрим псевдокод для алгоритма быстрой сортировки -
procedure quickSort(left, right)
if right-left <= 0
return
else
pivot = A[right]
partition = partitionFunc(left, right, pivot)
quickSort(left,partition-1)
quickSort(partition+1,right)
end if
end procedureЧтобы узнать о реализации быстрой сортировки на языке программирования C, нажмите здесь .
Граф - это графическое представление набора объектов, в котором некоторые пары объектов связаны ссылками. Взаимосвязанные объекты представлены точками, обозначенными какvertices, а связи, соединяющие вершины, называются edges.
Формально граф - это пара множеств (V, E), где V - множество вершин и E- множество ребер, соединяющих пары вершин. Взгляните на следующий график -
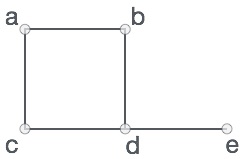
На приведенном выше графике
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}
Структура данных графика
Математические графики могут быть представлены в виде структуры данных. Мы можем представить граф, используя массив вершин и двумерный массив ребер. Прежде чем мы продолжим, давайте познакомимся с некоторыми важными терминами -
Vertex- Каждый узел графа представлен в виде вершины. В следующем примере отмеченный круг представляет вершины. Таким образом, от A до G - вершины. Мы можем представить их с помощью массива, как показано на следующем изображении. Здесь A можно идентифицировать по индексу 0. B можно идентифицировать по индексу 1 и так далее.
Edge- Ребро представляет собой путь между двумя вершинами или линию между двумя вершинами. В следующем примере линии от A до B, от B до C и так далее представляют ребра. Мы можем использовать двумерный массив для представления массива, как показано на следующем изображении. Здесь AB может быть представлен как 1 в строке 0, столбце 1, BC как 1 в строке 1, столбце 2 и так далее, сохраняя другие комбинации как 0.
Adjacency- Два узла или вершины являются смежными, если они соединены друг с другом ребром. В следующем примере B находится рядом с A, C находится рядом с B и так далее.
Path- Путь представляет собой последовательность ребер между двумя вершинами. В следующем примере ABCD представляет путь от A до D.
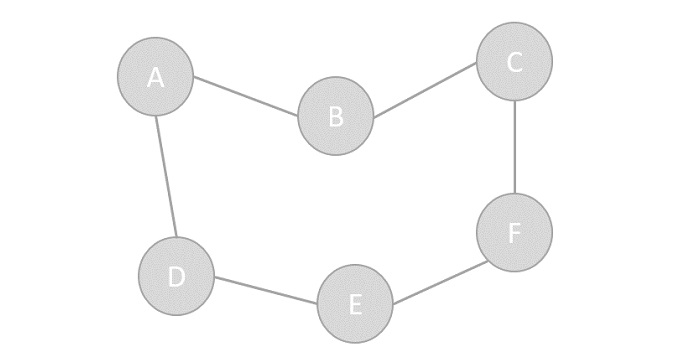
Основные операции
Ниже приведены основные основные операции графа.
Add Vertex - Добавляет вершину к графу.
Add Edge - Добавляет ребро между двумя вершинами графа.
Display Vertex - Отображает вершину графа.
Чтобы узнать больше о Graph, прочтите Учебное пособие по теории графов . Мы узнаем об обходе графа в следующих главах.
Алгоритм поиска в глубину (DFS) перемещается по графу в глубину и использует стек, чтобы не забыть получить следующую вершину для начала поиска, когда на любой итерации возникает тупик.

Как и в примере, приведенном выше, алгоритм DFS сначала переходит от S к A, к D, к G, к E, к B, затем к F и, наконец, к C. Он использует следующие правила.
Rule 1- Посетите соседнюю непосещенную вершину. Отметьте его как посещенное. Покажите это. Сложите его стопкой.
Rule 2- Если смежная вершина не найдена, вытащить вершину из стека. (Это приведет к появлению всех вершин из стека, у которых нет смежных вершин.)
Rule 3 - Повторяйте Правило 1 и Правило 2, пока стопка не станет пустой.
| Шаг | Обход | Описание |
|---|---|---|
| 1 |

|
Инициализируйте стек. |
| 2 |

|
отметка Sкак посетили и положите в стек. Исследуйте любой непосещенный соседний узел изS. У нас есть три узла, и мы можем выбрать любой из них. В этом примере мы возьмем узел в алфавитном порядке. |
| 3 |

|
отметка Aкак посетили и положите в стек. Исследуйте любой непосещенный соседний узел из A. ОбаS и D примыкают к A но нас интересуют только непосещенные узлы. |
| 4 |

|
Визит Dи отметьте его как посещенное и положите в стопку. Здесь у нас естьB и C узлы, примыкающие к Dи оба не посещаются. Однако мы снова будем выбирать в алфавитном порядке. |
| 5 |

|
Мы выбираем B, отметьте его как посещенное и положите в стопку. ВотBне имеет непосещаемых соседних узлов. Итак, мы попB из стека. |
| 6 |

|
Мы проверяем вершину стека на возврат к предыдущему узлу и проверяем, есть ли в нем непосещенные узлы. Здесь мы находимD быть на вершине стека. |
| 7 |

|
Только непосещенный соседний узел из D является Cв настоящее время. Итак, мы посещаемC, отметьте его как посещенное и положите в стопку. |
В виде Cне имеет соседнего непосещенного узла, поэтому мы продолжаем выталкивать стек, пока не найдем узел, у которого есть непосещенный соседний узел. В этом случае их нет, и мы продолжаем выскакивать, пока стек не опустеет.
Чтобы узнать о реализации этого алгоритма на языке программирования C, щелкните здесь .
Алгоритм поиска в ширину (BFS) перемещается по графу вширь и использует очередь, чтобы не забыть получить следующую вершину для начала поиска, когда на любой итерации возникает тупик.

Как и в приведенном выше примере, алгоритм BFS сначала переходит от A к B, затем от E к F, затем к C и G, наконец, к D. Он использует следующие правила.
Rule 1- Посетите соседнюю непосещенную вершину. Отметьте его как посещенное. Покажите это. Вставьте его в очередь.
Rule 2 - Если смежная вершина не найдена, удалите первую вершину из очереди.
Rule 3 - Повторяйте правило 1 и правило 2, пока очередь не станет пустой.
| Шаг | Обход | Описание |
|---|---|---|
| 1 |

|
Инициализируйте очередь. |
| 2 |
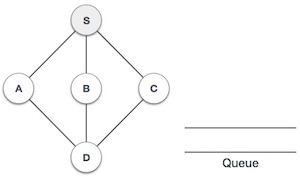
|
Начнем с посещения S (начальный узел) и отметьте его как посещенный. |
| 3 |

|
Затем мы видим непосещенный соседний узел из S. В этом примере у нас есть три узла, но по алфавиту мы выбираемA, отметьте его как посещенное и поставьте в очередь. |
| 4 |

|
Затем непосещенный соседний узел из S является B. Мы отмечаем его как посещенное и ставим в очередь. |
| 5 |

|
Затем непосещенный соседний узел из S является C. Мы отмечаем его как посещенное и ставим в очередь. |
| 6 |

|
В настоящее время, Sостается без непосещенных соседних узлов. Итак, выводим из очереди и находимA. |
| 7 |

|
Из A у нас есть Dкак непосещенный соседний узел. Мы отмечаем его как посещенное и ставим в очередь. |
На этом этапе у нас нет неотмеченных (непосещенных) узлов. Но согласно алгоритму мы продолжаем исключать из очереди, чтобы получить все непосещенные узлы. Когда очередь опорожняется, программа завершается.
Реализацию этого алгоритма на языке программирования C можно увидеть здесь .
Дерево представляет собой узлы, соединенные ребрами. Мы конкретно обсудим двоичное дерево или двоичное дерево поиска.
Двоичное дерево - это специальная структура данных, используемая для хранения данных. Бинарное дерево имеет особое условие, согласно которому каждый узел может иметь не более двух дочерних элементов. Двоичное дерево имеет преимущества как упорядоченного массива, так и связанного списка, поскольку поиск выполняется так же быстро, как в отсортированном массиве, а операции вставки или удаления выполняются так же быстро, как в связанном списке.

Важные термины
Ниже приведены важные термины, относящиеся к дереву.
Path - Путь означает последовательность узлов по краям дерева.
Root- Узел наверху дерева называется корнем. В каждом дереве есть только один корень и один путь от корневого узла к любому узлу.
Parent - Любой узел, кроме корневого, имеет одно ребро вверх до узла, называемого родительским.
Child - Узел ниже данного узла, соединенный его ребром вниз, называется его дочерним узлом.
Leaf - Узел, не имеющий дочернего узла, называется листовым узлом.
Subtree - Поддерево представляет потомков узла.
Visiting - Посещение относится к проверке значения узла, когда управление находится на узле.
Traversing - Перемещение означает прохождение узлов в определенном порядке.
Levels- Уровень узла представляет собой поколение узла. Если корневой узел находится на уровне 0, то его следующий дочерний узел находится на уровне 1, его внук - на уровне 2 и так далее.
keys - Ключ представляет собой значение узла, на основе которого должна выполняться операция поиска для узла.
Двоичное представление дерева поиска
Дерево двоичного поиска демонстрирует особое поведение. Левый дочерний узел узла должен иметь значение меньше, чем значение его родителя, а правый дочерний узел узла должен иметь значение больше, чем его родительское значение.

Мы собираемся реализовать дерево, используя объект узла и соединяя их через ссылки.
Узел дерева
Код для записи узла дерева будет аналогичен приведенному ниже. Он имеет часть данных и ссылки на его левый и правый дочерние узлы.
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};В дереве все узлы имеют общую конструкцию.
Основные операции BST
Основные операции, которые могут быть выполнены в структуре данных двоичного дерева поиска, следующие:
Insert - Вставляет элемент в дерево / создает дерево.
Search - Ищет элемент в дереве.
Preorder Traversal - Обходит дерево по предварительному заказу.
Inorder Traversal - Обходит дерево по порядку.
Postorder Traversal - Обходит дерево в режиме пост-заказа.
В этой главе мы изучим создание (вставку) древовидной структуры и поиск элемента данных в дереве. Мы узнаем о методах обхода дерева в следующей главе.
Вставить операцию
Самая первая вставка создает дерево. После этого, когда нужно вставить элемент, сначала найдите его правильное местоположение. Начните поиск с корневого узла, затем, если данные меньше значения ключа, найдите пустое место в левом поддереве и вставьте данные. В противном случае найдите пустое место в правом поддереве и вставьте данные.
Алгоритм
If root is NULL
then create root node
return
If root exists then
compare the data with node.data
while until insertion position is located
If data is greater than node.data
goto right subtree
else
goto left subtree
endwhile
insert data
end IfРеализация
Реализация функции вставки должна выглядеть так -
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty, create root node
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
}
//go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}Поисковая операция
Всякий раз, когда должен быть найден элемент, начинайте поиск с корневого узла, затем, если данные меньше значения ключа, ищите элемент в левом поддереве. В противном случае ищите элемент в правом поддереве. Следуйте одному и тому же алгоритму для каждого узла.
Алгоритм
If root.data is equal to search.data
return root
else
while data not found
If data is greater than node.data
goto right subtree
else
goto left subtree
If data found
return node
endwhile
return data not found
end ifРеализация этого алгоритма должна выглядеть так.
struct node* search(int data) {
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data) {
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data) {
current = current->leftChild;
}
//else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL) {
return NULL;
}
return current;
}
}Чтобы узнать о реализации структуры данных двоичного дерева поиска, нажмите здесь .
Обход - это процесс посещения всех узлов дерева и может также распечатать их значения. Поскольку все узлы соединены ребрами (связями), мы всегда начинаем с корневого (головного) узла. То есть мы не можем получить произвольный доступ к узлу в дереве. Есть три способа, которые мы используем, чтобы пройти по дереву:
- Обход по порядку
- Предварительный заказ обхода
- Пост-заказ обход
Как правило, мы просматриваем дерево для поиска или нахождения заданного элемента или ключа в дереве или для вывода всех содержащихся в нем значений.
Обход по порядку
В этом методе обхода сначала посещается левое поддерево, затем корень, а затем правое поддерево. Мы всегда должны помнить, что каждый узел может представлять собой поддерево.
Если пройдено двоичное дерево in-order, в результате будут выведены отсортированные ключевые значения в порядке возрастания.

Мы начинаем с A, и после обхода по порядку переходим к его левому поддереву B. Bтакже проходит по порядку. Процесс продолжается до тех пор, пока не будут посещены все узлы. Результатом обхода этого дерева будет -
D → B → E → A → F → C → G
Алгоритм
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.Предварительный заказ обхода
В этом методе обхода сначала посещается корневой узел, затем левое поддерево и, наконец, правое поддерево.

Мы начинаем с A, и после обхода предварительного заказа мы сначала посещаем A сам, а затем перейти к его левому поддереву B. Bтакже пройден предварительный заказ. Процесс продолжается до тех пор, пока не будут посещены все узлы. Выход предварительного заказа обхода этого дерева будет -
A → B → D → E → C → F → G
Алгоритм
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.Пост-заказ обход
В этом методе обхода корневой узел посещается последним, отсюда и название. Сначала мы обходим левое поддерево, затем правое поддерево и, наконец, корневой узел.

Мы начинаем с A, и после обхода Post-order мы сначала посещаем левое поддерево B. Bтакже пройден пост-заказ. Процесс продолжается до тех пор, пока не будут посещены все узлы. Результатом обхода этого дерева после заказа будет -
D → E → B → F → G → C → A
Алгоритм
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.Чтобы проверить реализацию обхода дерева в языке C, щелкните здесь .
Дерево двоичного поиска (BST) - это дерево, в котором все узлы следуют следующим свойствам:
Значение ключа левого поддерева меньше, чем значение ключа его родительского (корневого) узла.
Значение ключа правого поддерева больше или равно значению ключа его родительского (корневого) узла.
Таким образом, BST делит все свои поддеревья на два сегмента; левое поддерево и правое поддерево и может быть определено как -
left_subtree (keys) < node (key) ≤ right_subtree (keys)Представление
BST - это набор узлов, упорядоченных таким образом, что они поддерживают свойства BST. У каждого узла есть ключ и соответствующее значение. Во время поиска желаемый ключ сравнивается с ключами в BST и, если он найден, извлекается связанное значение.
Ниже приводится графическое изображение BST -
Мы замечаем, что ключ корневого узла (27) имеет все ключи с меньшим значением в левом поддереве и ключи с более высоким значением в правом поддереве.
Основные операции
Ниже приведены основные операции с деревом.
Search - Ищет элемент в дереве.
Insert - Вставляет элемент в дерево.
Pre-order Traversal - Обходит дерево по предварительному заказу.
In-order Traversal - Обходит дерево по порядку.
Post-order Traversal - Обходит дерево в режиме пост-заказа.
Узел
Определите узел, имеющий некоторые данные, ссылки на его левый и правый дочерние узлы.
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};Поисковая операция
Каждый раз, когда нужно искать элемент, начинайте поиск с корневого узла. Затем, если данные меньше значения ключа, найдите элемент в левом поддереве. В противном случае ищите элемент в правом поддереве. Следуйте одному и тому же алгоритму для каждого узла.
Алгоритм
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL) {
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
} //else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
}
return current;
}Вставить операцию
Каждый раз, когда нужно вставить элемент, сначала найдите его правильное местоположение. Начните поиск с корневого узла, затем, если данные меньше значения ключа, найдите пустое место в левом поддереве и вставьте данные. В противном случае найдите пустое место в правом поддереве и вставьте данные.
Алгоритм
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
} //go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}Что, если входные данные в двоичное дерево поиска поступают отсортированным (по возрастанию или по убыванию)? Тогда это будет выглядеть так -

Замечено, что производительность BST в худшем случае наиболее близка к алгоритмам линейного поиска, то есть (n). В данных в реальном времени мы не можем предсказать структуру данных и их частоту. Таким образом, возникает необходимость сбалансировать существующую BST.
Названный в честь их изобретателя Adelson, Velski & Landis, AVL treesбинарное дерево поиска с балансировкой высоты. Дерево AVL проверяет высоту левого и правого поддеревьев и гарантирует, что разница не превышает 1. Эта разница называетсяBalance Factor.
Здесь мы видим, что первое дерево сбалансировано, а следующие два дерева не сбалансированы -
Во втором дереве левое поддерево C имеет высоту 2, а правое поддерево имеет высоту 0, поэтому разница равна 2. В третьем дереве правое поддерево Aимеет высоту 2, а слева отсутствует, поэтому он равен 0, а разница снова равна 2. Дерево AVL позволяет разнице (коэффициенту баланса) быть только 1.
BalanceFactor = height(left-sutree) − height(right-sutree)Если разница в высоте левого и правого поддеревьев больше 1, дерево балансируется с помощью некоторых методов вращения.
AVL вращения
Чтобы сбалансировать себя, дерево AVL может выполнять следующие четыре вида вращения:
- Левое вращение
- Правое вращение
- Вращение влево-вправо
- Вращение вправо-влево
Первые два поворота - это одиночные вращения, а следующие два вращения - двойные вращения. Чтобы иметь несбалансированное дерево, нам нужно дерево высотой 2. Давайте разберемся с этим простым деревом по очереди.
Левое вращение
Если дерево становится несбалансированным, когда узел вставляется в правое поддерево правого поддерева, мы выполняем одно вращение влево -

В нашем примере узел Aстал несбалансированным, поскольку узел вставлен в правое поддерево правого поддерева A. Выполняем левый поворот, делаяA левое поддерево B.
Правое вращение
Дерево AVL может стать несбалансированным, если узел вставлен в левое поддерево левого поддерева. Затем дереву нужно повернуть вправо.

Как показано, несбалансированный узел становится правым дочерним элементом своего левого дочернего элемента, выполняя правое вращение.
Вращение влево-вправо
Двойные вращения - это немного сложная версия уже объясненных версий вращений. Чтобы лучше их понять, мы должны записывать каждое действие, выполняемое во время вращения. Давайте сначала проверим, как выполнять вращение влево-вправо. Вращение влево-вправо - это комбинация вращения влево с последующим вращением вправо.
| состояние | Действие |
|---|---|

|
Узел был вставлен в правое поддерево левого поддерева. Это делаетCнесбалансированный узел. Эти сценарии заставляют дерево AVL выполнять вращение влево-вправо. |

|
Сначала мы выполняем левый поворот на левом поддереве C. Это делаетA, левое поддерево B. |

|
Узел C все еще несбалансирован, однако теперь это из-за левого поддерева левого поддерева. |

|
Теперь мы повернем дерево вправо, сделав B новый корневой узел этого поддерева. C теперь становится правым поддеревом своего левого поддерева. |

|
Теперь дерево сбалансировано. |
Вращение вправо-влево
Второй тип двойного вращения - вращение вправо-влево. Это комбинация вращения вправо с последующим вращением влево.
| состояние | Действие |
|---|---|

|
Узел был вставлен в левое поддерево правого поддерева. Это делаетA, несбалансированный узел с коэффициентом балансировки 2. |

|
Сначала выполняем правый поворот по C узел, делая C правое поддерево своего левого поддерева B. В настоящее время,B становится правым поддеревом A. |

|
Узел A по-прежнему несбалансирован из-за правого поддерева своего правого поддерева и требует поворота влево. |

|
Левое вращение выполняется путем B новый корневой узел поддерева. A становится левым поддеревом своего правого поддерева B. |
|
|
Теперь дерево сбалансировано. |
Остовное дерево - это подмножество Graph G, все вершины которого покрыты минимально возможным количеством ребер. Следовательно, остовное дерево не имеет циклов и его нельзя отключить.
По этому определению мы можем сделать вывод, что каждый связанный и неориентированный граф G имеет хотя бы одно остовное дерево. Несвязный граф не имеет остовного дерева, так как он не может быть натянут на все его вершины.

Мы нашли три остовных дерева из одного полного графа. Полный неориентированный граф может иметь максимумnn-2 количество остовных деревьев, где nколичество узлов. В приведенном выше примереn is 3, следовательно 33−2 = 3 возможны остовные деревья.
Общие свойства связующего дерева
Теперь мы понимаем, что один граф может иметь более одного остовного дерева. Ниже приведены несколько свойств остовного дерева, связанного с графом G:
Связный граф G может иметь более одного остовного дерева.
Все возможные остовные деревья графа G имеют одинаковое количество ребер и вершин.
Остовное дерево не имеет цикла (циклов).
Удаление одного ребра из остовного дерева приведет к отключению графа, т. Е. Остовное дерево будет minimally connected.
Добавление одного ребра к остовному дереву создаст цепь или цикл, т. Е. Остовное дерево будет maximally acyclic.
Математические свойства связующего дерева
Связующее дерево имеет n-1 края, где n - количество узлов (вершин).
Из полного графика, удалив максимум e - n + 1 ребер, мы можем построить остовное дерево.
Полный график может иметь максимум nn-2 количество остовных деревьев.
Таким образом, мы можем заключить, что остовные деревья являются подмножеством связного графа G, а несвязные графы не имеют остовного дерева.
Применение связующего дерева
Связующее дерево в основном используется для поиска минимального пути для соединения всех узлов в графе. Обычное применение остовных деревьев -
Civil Network Planning
Computer Network Routing Protocol
Cluster Analysis
Давайте разберемся в этом на небольшом примере. Рассмотрим городскую сеть как огромный граф, и теперь мы планируем развернуть телефонные линии таким образом, чтобы с помощью минимума линий мы могли подключиться ко всем городским узлам. Здесь на сцену выходит остовное дерево.
Минимальное связующее дерево (MST)
В взвешенном графе минимальное остовное дерево - это остовное дерево, которое имеет минимальный вес, чем все остальные остовные деревья того же графа. В реальных ситуациях этот вес может быть измерен как расстояние, затор, транспортная нагрузка или любое произвольное значение, обозначенное для краев.
Минимальный алгоритм связующего дерева
Здесь мы узнаем о двух наиболее важных алгоритмах связующего дерева -
Алгоритм Крускала
Алгоритм Прима
Оба алгоритма жадные.
Куча - это особый случай сбалансированной структуры данных двоичного дерева, в которой ключ корневого узла сравнивается со своими дочерними элементами и размещается соответствующим образом. Еслиα имеет дочерний узел β тогда -
ключ (α) ≥ ключ (β)
Поскольку значение parent больше, чем значение child, это свойство генерирует Max Heap. Исходя из этого критерия, куча может быть двух типов:
For Input → 35 33 42 10 14 19 27 44 26 31Min-Heap - Если значение корневого узла меньше или равно любому из его дочерних узлов.
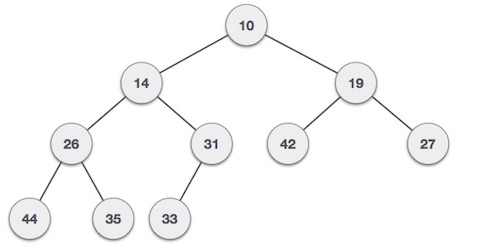
Max-Heap - Если значение корневого узла больше или равно любому из его дочерних узлов.

Оба дерева построены с использованием одного и того же ввода и порядка поступления.
Алгоритм построения максимальной кучи
Мы будем использовать тот же пример, чтобы продемонстрировать, как создается Max Heap. Процедура создания Min Heap аналогична, но мы используем минимальные значения вместо максимальных значений.
Мы собираемся получить алгоритм для максимальной кучи, вставляя по одному элементу за раз. В любой момент куча должна сохранять свое свойство. Во время вставки мы также предполагаем, что вставляем узел в уже сложенное дерево.
Step 1 − Create a new node at the end of heap.
Step 2 − Assign new value to the node.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.Note - В алгоритме построения Min Heap мы ожидаем, что значение родительского узла будет меньше, чем значение дочернего узла.
Давайте разберемся с построением Max Heap с помощью анимированной иллюстрации. Мы рассматриваем ту же входную выборку, которую использовали ранее.

Максимальный алгоритм удаления кучи
Давайте выведем алгоритм удаления из максимальной кучи. Удаление в максимальной (или минимальной) куче всегда происходит в корне, чтобы удалить максимальное (или минимальное) значение.
Step 1 − Remove root node.
Step 2 − Move the last element of last level to root.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.
Некоторые языки программирования позволяют модулю или функции вызывать себя. Этот метод известен как рекурсия. В рекурсии функцияα либо вызывает себя напрямую, либо вызывает функцию β который, в свою очередь, вызывает исходную функцию α. Функцияα называется рекурсивной функцией.
Example - функция, вызывающая сама себя.
int function(int value) {
if(value < 1)
return;
function(value - 1);
printf("%d ",value);
}Example - функция, которая вызывает другую функцию, которая, в свою очередь, вызывает ее снова.
int function1(int value1) {
if(value1 < 1)
return;
function2(value1 - 1);
printf("%d ",value1);
}
int function2(int value2) {
function1(value2);
}Свойства
Рекурсивная функция может быть бесконечной, как цикл. Чтобы избежать бесконечного выполнения рекурсивной функции, рекурсивная функция должна иметь два свойства:
Base criteria - Должен быть хотя бы один базовый критерий или условие, чтобы при выполнении этого условия функция перестала вызывать себя рекурсивно.
Progressive approach - Рекурсивные вызовы должны выполняться таким образом, чтобы каждый раз, когда выполняется рекурсивный вызов, он приближался к базовым критериям.
Реализация
Многие языки программирования реализуют рекурсию с помощью stacks. Как правило, когда функция (caller) вызывает другую функцию (callee) или себя как вызываемого, вызывающая функция передает управление выполнением вызываемому. Этот процесс передачи также может включать в себя передачу некоторых данных от вызывающего к вызываемому.
Это означает, что вызывающая функция должна временно приостановить свое выполнение и возобновить ее позже, когда управление выполнением вернется из вызываемой функции. Здесь вызывающая функция должна начинаться именно с той точки выполнения, в которой она приостанавливает выполнение. Ему также нужны те же самые значения данных, над которыми он работал. Для этого создается запись активации (или кадр стека) для вызывающей функции.

Эта запись активации хранит информацию о локальных переменных, формальных параметрах, адресе возврата и всю информацию, передаваемую вызывающей функции.
Анализ рекурсии
Кто-то может спорить, зачем использовать рекурсию, ведь ту же задачу можно решить с помощью итерации. Первая причина заключается в том, что рекурсия делает программу более читаемой, а благодаря новейшим усовершенствованным системам ЦП рекурсия более эффективна, чем итерации.
Сложность времени
В случае итераций мы берем количество итераций для подсчета временной сложности. Аналогичным образом, в случае рекурсии, предполагая, что все постоянно, мы пытаемся выяснить, сколько раз выполняется рекурсивный вызов. Вызов функции равен Ο (1), следовательно, (n) количество выполненных рекурсивных вызовов делает рекурсивную функцию Ο (n).
Космическая сложность
Сложность пространства считается количеством дополнительного пространства, необходимого для выполнения модуля. В случае итераций компилятор практически не требует лишнего места. Компилятор постоянно обновляет значения переменных, используемых в итерациях. Но в случае рекурсии системе необходимо сохранять запись активации каждый раз, когда выполняется рекурсивный вызов. Следовательно, считается, что пространственная сложность рекурсивной функции может быть выше, чем у функции с итерацией.
Башня Ханоя - это математическая головоломка, которая состоит из трех башен (колышков) и более одного кольца, как показано на рисунке -

Эти кольца имеют разные размеры и расположены в порядке возрастания, то есть меньшее находится над большим. Есть и другие варианты головоломки, в которых количество дисков увеличивается, но количество башен остается прежним.
Правила
Миссия - переместить все диски в какую-то другую башню, не нарушая порядок расположения. Несколько правил, которым необходимо следовать для Ханойской башни:
- В любой момент времени между башнями можно перемещать только один диск.
- Снять можно только «верхний» диск.
- Никакой большой диск не может находиться поверх маленького.
Ниже приведено анимированное изображение решения загадки Ханойской башни с тремя дисками.

Загадку Ханойской башни с n дисками можно решить за минимум 2n−1шаги. Эта презентация показывает, что пазл с 3 дисками занял23 - 1 = 7 шаги.
Алгоритм
Чтобы написать алгоритм для Ханойской башни, сначала нам нужно узнать, как решить эту проблему с меньшим количеством дисков, скажем → 1 или 2. Мы помечаем три башни именем, source, destination и aux(только для помощи при перемещении дисков). Если у нас есть только один диск, его можно легко переместить с исходного на целевой привязки.
Если у нас 2 диска -
- Сначала мы перемещаем меньший (верхний) диск на вспомогательную привязку.
- Затем мы перемещаем больший (нижний) диск на целевой колышек.
- И, наконец, мы перемещаем меньший диск с вспомогательной на конечную привязку.

Итак, теперь мы можем разработать алгоритм для Ханойской башни с более чем двумя дисками. Разделим стопку дисков на две части. Самый большой диск (n- й диск) находится в одной части, а все остальные (n-1) диски - во второй части.
Наша конечная цель - переместить диск nот источника к месту назначения, а затем поместите на него все остальные (n1) диски. Мы можем представить, как применить то же самое рекурсивным образом для всего заданного набора дисков.
Следующие шаги -
Step 1 − Move n-1 disks from source to aux
Step 2 − Move nth disk from source to dest
Step 3 − Move n-1 disks from aux to destРекурсивный алгоритм для Ханойской башни можно запустить следующим образом:
START
Procedure Hanoi(disk, source, dest, aux)
IF disk == 1, THEN
move disk from source to dest
ELSE
Hanoi(disk - 1, source, aux, dest) // Step 1
move disk from source to dest // Step 2
Hanoi(disk - 1, aux, dest, source) // Step 3
END IF
END Procedure
STOPЧтобы проверить реализацию в программировании на C, щелкните здесь .
Ряд Фибоначчи генерирует последующее число путем добавления двух предыдущих чисел. Ряд Фибоначчи начинается с двух чисел -F0 & F1. Начальные значения F 0 и F 1 могут быть приняты 0, 1 или 1, 1 соответственно.
Ряд Фибоначчи удовлетворяет следующим условиям -
Fn = Fn-1 + Fn-2Следовательно, ряд Фибоначчи может выглядеть так:
F 8 = 0 1 1 2 3 5 8 13
или, это -
Ж 8 = 1 1 2 3 5 8 13 21
В целях иллюстрации Фибоначчи F 8 отображается как -

Итерационный алгоритм Фибоначчи
Сначала мы пытаемся составить итерационный алгоритм для ряда Фибоначчи.
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
end procedureЧтобы узнать о реализации вышеуказанного алгоритма на языке программирования C, щелкните здесь .
Рекурсивный алгоритм Фибоначчи
Давайте узнаем, как создать рекурсивный алгоритм ряда Фибоначчи. Базовые критерии рекурсии.
START
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
ENDЧтобы увидеть реализацию вышеуказанного алгоритма на языке программирования c, щелкните здесь .