Elasticsearch - Краткое руководство
Elasticsearch - это поисковый сервер на базе Apache Lucene. Он был разработан Шэем Бэноном и опубликован в 2010 году. В настоящее время поддерживается Elasticsearch BV. Его последняя версия - 7.0.0.
Elasticsearch - это распределенная система полнотекстового поиска и аналитики с открытым исходным кодом в реальном времени. Он доступен из интерфейса веб-службы RESTful и использует документы JSON без схемы (JavaScript Object Notation) для хранения данных. Он построен на языке программирования Java, поэтому Elasticsearch может работать на разных платформах. Это позволяет пользователям исследовать очень большие объемы данных с очень высокой скоростью.
Общие особенности
Общие особенности Elasticsearch следующие:
Elasticsearch масштабируется до петабайт структурированных и неструктурированных данных.
Elasticsearch можно использовать в качестве замены хранилищ документов, таких как MongoDB и RavenDB.
Elasticsearch использует денормализацию для повышения производительности поиска.
Elasticsearch - одна из популярных поисковых систем для предприятий, которая в настоящее время используется многими крупными организациями, такими как Wikipedia, The Guardian, StackOverflow, GitHub и т. Д.
Elasticsearch - это открытый исходный код, доступный по лицензии Apache версии 2.0.
Ключевые понятия
Ключевые концепции Elasticsearch следующие:
Узел
Это относится к одному запущенному экземпляру Elasticsearch. Один физический и виртуальный сервер вмещает несколько узлов в зависимости от возможностей их физических ресурсов, таких как ОЗУ, хранилище и вычислительная мощность.
Кластер
Это набор из одного или нескольких узлов. Кластер предоставляет возможности коллективного индексирования и поиска по всем узлам для всех данных.
Индекс
Это собрание документов разного типа и их свойств. Индекс также использует концепцию осколков для повышения производительности. Например, набор документов содержит данные приложения социальной сети.
Документ
Это набор полей, определенных определенным образом в формате JSON. Каждый документ принадлежит к типу и находится внутри индекса. Каждый документ связан с уникальным идентификатором, называемым UID.
Осколок
Индексы по горизонтали подразделяются на сегменты. Это означает, что каждый сегмент содержит все свойства документа, но содержит меньше объектов JSON, чем индекс. Горизонтальное разделение делает шард независимым узлом, который можно хранить в любом узле. Первичный осколок - это исходная горизонтальная часть индекса, а затем эти первичные осколки реплицируются в реплики.
Реплики
Elasticsearch позволяет пользователю создавать реплики своих индексов и шардов. Репликация не только помогает повысить доступность данных в случае сбоя, но также повышает производительность поиска за счет выполнения операции параллельного поиска в этих репликах.
Преимущества
Elasticsearch разработан на Java, что делает его совместимым практически с любой платформой.
Elasticsearch работает в реальном времени, другими словами, через одну секунду добавленный документ становится доступным для поиска в этом движке.
Elasticsearch распространяется, что позволяет легко масштабировать и интегрировать его в любую крупную организацию.
Создавать полные резервные копии легко с помощью концепции шлюза, которая присутствует в Elasticsearch.
Обработка мультитенантности в Elasticsearch очень проста по сравнению с Apache Solr.
Elasticsearch использует объекты JSON в качестве ответов, что позволяет вызывать сервер Elasticsearch с большим количеством разных языков программирования.
Elasticsearch поддерживает почти все типы документов, кроме тех, которые не поддерживают отрисовку текста.
Недостатки
Elasticsearch не имеет многоязычной поддержки с точки зрения обработки данных запросов и ответов (возможно только в JSON), в отличие от Apache Solr, где это возможно в форматах CSV, XML и JSON.
Иногда у Elasticsearch возникает проблема с разделением мозга.
Сравнение Elasticsearch и СУБД
В Elasticsearch индекс аналогичен таблицам в СУБД (системе управления реляционными базами данных). Каждая таблица представляет собой набор строк, так же как каждый индекс - это набор документов в Elasticsearch.
В следующей таблице приводится прямое сравнение этих терминов:
| Elasticsearch | СУБД |
|---|---|
| Кластер | База данных |
| Осколок | Осколок |
| Индекс | Стол |
| Поле | Столбец |
| Документ | Строка |
В этой главе мы подробно разберемся с процедурой установки Elasticsearch.
Чтобы установить Elasticsearch на локальный компьютер, вам нужно будет выполнить следующие шаги:
Step 1- Проверьте версию java, установленную на вашем компьютере. Это должна быть java 7 или выше. Вы можете проверить, выполнив следующие действия -
В операционной системе (ОС) Windows (с помощью командной строки) -
> java -versionВ ОС UNIX (с использованием терминала) -
$ echo $JAVA_HOMEStep 2 - В зависимости от вашей операционной системы загрузите Elasticsearch с www.elastic.co, как указано ниже -
Для ОС Windows скачайте ZIP-файл.
Для ОС UNIX загрузите файл TAR.
Для ОС Debian загрузите файл DEB.
Для Red Hat и других дистрибутивов Linux загрузите файл RPN.
Утилиты APT и Yum также можно использовать для установки Elasticsearch во многих дистрибутивах Linux.
Step 3 - Процесс установки Elasticsearch прост и описан ниже для разных ОС -
Windows OS- Разархивируйте zip-пакет, и Elasticsearch будет установлен.
UNIX OS- Извлеките tar-файл в любое место, и Elasticsearch будет установлен.
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gzUsing APT utility for Linux OS- Загрузите и установите открытый ключ подписи.
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -Сохраните определение репозитория, как показано ниже -
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listЗапустите обновление, используя следующую команду -
$ sudo apt-get updateТеперь вы можете установить, используя следующую команду -
$ sudo apt-get install elasticsearchDownload and install the Debian package manually using the command given here −
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0Using YUM utility for Debian Linux OS
Загрузите и установите открытый ключ подписи -
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchДОБАВЬТЕ следующий текст в файл с суффиксом .repo в каталоге «/etc/yum.repos.d/». Например, elasticsearch.repo
elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdТеперь вы можете установить Elasticsearch, используя следующую команду
sudo yum install elasticsearchStep 4- Перейдите в домашний каталог Elasticsearch и в папку bin. Запустите файл elasticsearch.bat в случае Windows или вы можете сделать то же самое с помощью командной строки и через терминал в случае файла Elasticsearch для UNIX.
В Windows
> cd elasticsearch-2.1.0/bin
> elasticsearchВ Linux
$ cd elasticsearch-2.1.0/bin
$ ./elasticsearchNote - В случае с Windows вы можете получить сообщение об ошибке, указывающее, что JAVA_HOME не установлен, установите его в переменных среды на «C: \ Program Files \ Java \ jre1.8.0_31» или в место, где вы установили java.
Step 5- Порт по умолчанию для веб-интерфейса Elasticsearch - 9200, или вы можете изменить его, изменив http.port внутри файла elasticsearch.yml, находящегося в каталоге bin. Вы можете проверить, работает ли сервер, просмотревhttp://localhost:9200. Он вернет объект JSON, который содержит информацию об установленном Elasticsearch следующим образом:
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Step 6- На этом этапе давайте установим Kibana. Следуйте соответствующему коду, приведенному ниже, для установки в Linux и Windows -
For Installation on Linux −
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz
tar -xzf kibana-7.0.0-linux-x86_64.tar.gz
cd kibana-7.0.0-linux-x86_64/
./bin/kibanaFor Installation on Windows −
Загрузите Kibana для Windows из https://www.elastic.co/products/kibana. После того, как вы нажмете ссылку, вы найдете домашнюю страницу, как показано ниже -
Разархивируйте и перейдите в домашний каталог Kibana, а затем запустите его.
CD c:\kibana-7.0.0-windows-x86_64
.\bin\kibana.batВ этой главе давайте узнаем, как добавить индекс, сопоставление и данные в Elasticsearch. Обратите внимание, что некоторые из этих данных будут использоваться в примерах, описанных в этом руководстве.
Создать индекс
Вы можете использовать следующую команду для создания индекса -
PUT schoolотклик
Если индекс создан, вы можете увидеть следующий результат -
{"acknowledged": true}Добавить данные
Elasticsearch сохранит документы, которые мы добавляем в индекс, как показано в следующем коде. Документам присваиваются идентификаторы, которые используются для идентификации документа.
Тело запроса
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}отклик
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Здесь мы добавляем еще один похожий документ.
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}отклик
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}Таким образом, в следующих главах мы продолжим добавлять любые примеры данных, которые нам понадобятся для работы.
Добавление образцов данных в Kibana
Kibana - это инструмент с графическим интерфейсом для доступа к данным и создания визуализации. В этом разделе давайте поймем, как мы можем добавить к нему образцы данных.
На домашней странице Kibana выберите следующую опцию, чтобы добавить образец данных электронной торговли:
Следующий экран покажет некоторую визуализацию и кнопку для добавления данных -
При нажатии на Добавить данные откроется следующий экран, подтверждающий, что данные были добавлены в индекс с именем eCommerce.
В любой системе или программном обеспечении при обновлении до более новой версии нам необходимо выполнить несколько шагов, чтобы сохранить настройки, конфигурации, данные и другие параметры приложения. Эти шаги необходимы, чтобы сделать приложение стабильным в новой системе или сохранить целостность данных (предотвратить повреждение данных).
Чтобы обновить Elasticsearch, вам необходимо выполнить следующие шаги:
Читать документы по обновлению от https://www.elastic.co/
Протестируйте обновленную версию в непроизводственной среде, например в среде UAT, E2E, SIT или DEV.
Обратите внимание, что откат к предыдущей версии Elasticsearch невозможен без резервного копирования данных. Следовательно, перед обновлением до более новой версии рекомендуется сделать резервную копию данных.
Мы можем выполнить обновление с помощью полного перезапуска кластера или последовательного обновления. Прокатное обновление предназначено для новых версий. Обратите внимание, что при использовании метода последовательного обновления для миграции не происходит сбоев в обслуживании.
Шаги по обновлению
Перед обновлением производственного кластера протестируйте обновление в среде разработки.
Сделайте резервную копию ваших данных. Вы не можете вернуться к более ранней версии, если у вас нет снимка данных.
Рассмотрите возможность закрытия заданий машинного обучения, прежде чем начинать процесс обновления. Хотя задания машинного обучения могут продолжать выполняться во время последовательного обновления, это увеличивает накладные расходы на кластер во время процесса обновления.
Обновите компоненты своего эластичного стека в следующем порядке:
- Elasticsearch
- Kibana
- Logstash
- Beats
- Сервер APM
Обновление с 6.6 или более ранней версии
Чтобы выполнить обновление непосредственно до Elasticsearch 7.1.0 с версий 6.0–6.6, необходимо вручную переиндексировать все индексы 5.x, которые необходимо перенести, и выполнить полный перезапуск кластера.
Полный перезапуск кластера
Процесс полного перезапуска кластера включает выключение каждого узла в кластере, обновление каждого узла до 7x и затем перезапуск кластера.
Ниже приведены шаги высокого уровня, которые необходимо выполнить для полного перезапуска кластера.
- Отключить выделение сегментов
- Остановить индексацию и выполнить синхронизированную очистку
- Выключите все узлы
- Обновите все узлы
- Обновите любые плагины
- Запустите каждый обновленный узел
- Подождите, пока все узлы присоединятся к кластеру, и сообщат о желтом статусе
- Повторно включить выделение
После повторного включения выделения кластер начинает выделять шарды реплик узлам данных. На этом этапе можно безопасно возобновить индексирование и поиск, но ваш кластер будет восстанавливаться быстрее, если вы можете подождать, пока все первичные и реплики шарды не будут успешно выделены, а статус всех узлов станет зеленым.
Интерфейс прикладного программирования (API) в сети - это группа вызовов функций или других программных инструкций для доступа к программному компоненту в этом конкретном веб-приложении. Например, Facebook API помогает разработчику создавать приложения, получая доступ к данным или другим функциям из Facebook; это может быть дата рождения или обновление статуса.
Elasticsearch предоставляет REST API, доступ к которому осуществляется JSON через HTTP. Elasticsearch использует некоторые соглашения, которые мы сейчас обсудим.
Несколько индексов
Большинство операций, в основном поиск и другие операции, в API предназначены для одного или нескольких индексов. Это помогает пользователю выполнять поиск в нескольких местах или по всем доступным данным, просто выполнив запрос один раз. Для выполнения операций с несколькими индексами используется множество различных обозначений. Мы обсудим некоторые из них в этой главе.
Обозначение, разделенное запятыми
POST /index1,index2,index3/_searchТело запроса
{
"query":{
"query_string":{
"query":"any_string"
}
}
}отклик
Объекты JSON из index1, index2, index3, содержащие any_string.
_все ключевые слова для всех индексов
POST /_all/_searchТело запроса
{
"query":{
"query_string":{
"query":"any_string"
}
}
}отклик
Объекты JSON из всех индексов и имеющие в нем any_string.
Подстановочные знаки (*, +, -)
POST /school*/_searchТело запроса
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}отклик
Объекты JSON из всех индексов, которые начинаются со школы, в которой есть CBSE.
В качестве альтернативы вы также можете использовать следующий код -
POST /school*,-schools_gov /_searchТело запроса
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}отклик
Объекты JSON из всех индексов, которые начинаются со слова «школа», но не из schools_gov и содержат в себе CBSE.
Есть также некоторые параметры строки запроса URL -
- ignore_unavailable- Ошибка не произойдет или никакая операция не будет остановлена, если один или несколько индексов, присутствующих в URL, не существуют. Например, индекс школ существует, а книжных магазинов нет.
POST /school*,book_shops/_searchТело запроса
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Тело запроса
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}Рассмотрим следующий код -
POST /school*,book_shops/_search?ignore_unavailable = trueТело запроса
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Ответ (без ошибок)
Объекты JSON из всех индексов, которые начинаются со школы, в которой есть CBSE.
allow_no_indices
trueзначение этого параметра предотвратит ошибку, если URL с подстановочным знаком не дает индексов. Например, не существует индекса, который начинается с schools_pri -
POST /schools_pri*/_search?allow_no_indices = trueТело запроса
{
"query":{
"match_all":{}
}
}Ответ (без ошибок)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}expand_wildcards
Этот параметр определяет, нужно ли расширять подстановочные знаки до открытых индексов или закрытых индексов или выполнять и то и другое. Значение этого параметра может быть открытым и закрытым или ни одного и всех.
Например, закрытые индексные школы -
POST /schools/_closeотклик
{"acknowledged":true}Рассмотрим следующий код -
POST /school*/_search?expand_wildcards = closedТело запроса
{
"query":{
"match_all":{}
}
}отклик
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}Поддержка математических дат в именах индексов
Elasticsearch предлагает функцию поиска индексов по дате и времени. Нам нужно указать дату и время в определенном формате. Например, accountdetail-2015.12.30, index будет хранить реквизиты банковского счета на 30 декабря 2015 года. Можно выполнять математические операции, чтобы получить подробную информацию для определенной даты или диапазона дат и времени.
Формат имени математического индекса даты -
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_searchstatic_name - это часть выражения, которая остается неизменной в каждом математическом индексе даты, как и сведения об учетной записи. date_math_expr содержит математическое выражение, которое определяет дату и время динамически, как now-2d. date_format содержит формат, в котором дата записывается в виде индекса, например YYYY.MM.dd. Если сегодня 30 декабря 2015 г., то <accountdetail- {now-2d {YYYY.MM.dd}}> вернет accountdetail-2015.12.28.
| Выражение | Постановляет |
|---|---|
| <accountdetail- {now-d}> | accountdetail-2015.12.29 |
| <accountdetail- {now-M}> | accountdetail-2015.11.30 |
| <accountdetail- {сейчас {YYYY.MM}}> | accountdetail-2015.12 |
Теперь мы увидим некоторые общие параметры, доступные в Elasticsearch, которые можно использовать для получения ответа в указанном формате.
Хорошие результаты
Мы можем получить ответ в виде хорошо отформатированного объекта JSON, просто добавив параметр запроса URL, то есть pretty = true.
POST /schools/_search?pretty = trueТело запроса
{
"query":{
"match_all":{}
}
}отклик
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….Человекочитаемый вывод
Эта опция может изменять статистические ответы либо в удобочитаемой форме (если человек = true), либо в удобочитаемой форме (если человек = ложь). Например, если human = true, то distance_kilometer = 20KM, а если human = false, то distance_meter = 20000, когда ответ должен использоваться другой компьютерной программой.
Фильтрация ответов
Мы можем отфильтровать ответ на меньшее количество полей, добавив их в параметр field_path. Например,
POST /schools/_search?filter_path = hits.totalТело запроса
{
"query":{
"match_all":{}
}
}отклик
{"hits":{"total":3}}Elasticsearch предоставляет API для одного документа и API для нескольких документов, где вызов API нацелен на один документ и несколько документов соответственно.
Индекс API
Это помогает добавить или обновить документ JSON в индексе, когда делается запрос к соответствующему индексу с определенным отображением. Например, следующий запрос добавит объект JSON для индексации школ и в соответствии с отображением школ:
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Автоматическое создание индекса
Когда делается запрос на добавление объекта JSON к определенному индексу и если этот индекс не существует, этот API автоматически создает этот индекс, а также базовое сопоставление для этого конкретного объекта JSON. Эту функцию можно отключить, изменив значения следующих параметров на false, которые присутствуют в файле elasticsearch.yml.
action.auto_create_index:false
index.mapper.dynamic:falseВы также можете ограничить автоматическое создание индекса, где разрешено только имя индекса с определенными шаблонами, изменив значение следующего параметра -
action.auto_create_index:+acc*,-bank*Note - Здесь + означает разрешено, а - означает, что запрещено.
Управление версиями
Elasticsearch также предоставляет возможность контроля версий. Мы можем использовать параметр запроса версии, чтобы указать версию конкретного документа.
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}Управление версиями - это процесс в реальном времени, и на него не влияют операции поиска в реальном времени.
Есть два наиболее важных типа управления версиями:
Внутреннее управление версиями
Внутреннее управление версиями - это версия по умолчанию, которая начинается с 1 и увеличивается с каждым обновлением, включая удаления.
Внешнее управление версиями
Он используется, когда управление версиями документов хранится во внешней системе, например в сторонних системах управления версиями. Чтобы включить эту функцию, нам нужно установить version_type на external. Здесь Elasticsearch сохранит номер версии, указанный внешней системой, и не будет увеличивать его автоматически.
Тип операции
Тип операции используется для принудительного создания операции. Это помогает избежать перезаписи существующего документа.
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Автоматическая генерация ID
Если идентификатор не указан в операции индексации, Elasticsearch автоматически генерирует идентификатор для этого документа.
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Получить API
API помогает извлекать объект типа JSON, выполняя запрос на получение определенного документа.
pre class="prettyprint notranslate" > GET schools/_doc/5Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Эта операция выполняется в режиме реального времени и не зависит от частоты обновления индекса.
Вы также можете указать версию, тогда Elasticsearch получит только эту версию документа.
Вы также можете указать _all в запросе, чтобы Elasticsearch мог искать этот идентификатор документа в каждом типе и возвращал первый совпавший документ.
Вы также можете указать поля, которые вы хотите получить в результате из этого конкретного документа.
GET schools/_doc/5?_source_includes=name,feesЗапустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}Вы также можете получить исходную часть в своем результате, просто добавив часть _source в свой запрос на получение.
GET schools/_doc/5?_sourceЗапустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Вы также можете обновить сегмент перед выполнением операции получения, установив для параметра обновления значение true.
Удалить API
Вы можете удалить определенный индекс, сопоставление или документ, отправив HTTP-запрос DELETE в Elasticsearch.
DELETE schools/_doc/4Запустив приведенный выше код, мы получаем следующий результат -
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}Версия документа может быть указана для удаления этой конкретной версии. Можно указать параметр маршрутизации для удаления документа от конкретного пользователя, и операция завершится ошибкой, если документ не принадлежит этому конкретному пользователю. В этой операции вы можете указать параметр обновления и тайм-аута так же, как GET API.
Обновить API
Для выполнения этой операции используется сценарий, а управление версиями используется, чтобы убедиться, что во время получения и повторного индексирования не произошло никаких обновлений. Например, вы можете обновить плату за обучение в школе с помощью скрипта -
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}Вы можете проверить обновление, отправив запрос на получение обновленного документа.
Этот API используется для поиска контента в Elasticsearch. Пользователь может выполнить поиск, отправив запрос на получение со строкой запроса в качестве параметра, или они могут опубликовать запрос в теле сообщения почтового запроса. В основном все поисковые APIS бывают многоиндексными, многотипными.
Мультииндекс
Elasticsearch позволяет нам искать документы, присутствующие во всех индексах или в некоторых конкретных индексах. Например, если нам нужно выполнить поиск по всем документам с именем, содержащим центральный, мы можем сделать, как показано здесь -
GET /_all/_search?q=city:paprolaПри запуске приведенного выше кода мы получаем следующий ответ -
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Поиск URI
Многие параметры могут быть переданы в операции поиска с использованием унифицированного идентификатора ресурса -
| S.No | Параметр и описание |
|---|---|
| 1 | Q Этот параметр используется для указания строки запроса. |
| 2 | lenient Этот параметр используется для указания строки запроса. Ошибки, связанные с форматированием, можно игнорировать, просто установив для этого параметра значение true. По умолчанию - false. |
| 3 | fields Этот параметр используется для указания строки запроса. |
| 4 | sort Мы можем получить отсортированный результат, используя этот параметр, возможные значения для этого параметра: fieldName, fieldName: asc / fieldname: desc |
| 5 | timeout Мы можем ограничить время поиска с помощью этого параметра, и ответ будет содержать только совпадения за это указанное время. По умолчанию тайм-аут отсутствует. |
| 6 | terminate_after Мы можем ограничить ответ определенным количеством документов для каждого шарда, при достижении которых запрос будет завершен досрочно. По умолчанию terminate_after отсутствует. |
| 7 | from Начальный индекс возвращаемых совпадений. По умолчанию 0. |
| 8 | size Он обозначает количество возвращаемых совпадений. По умолчанию 10. |
Запросить поиск тела
Мы также можем указать запрос, используя запрос DSL в теле запроса, и в предыдущих главах уже было много примеров. Один из таких примеров приведен здесь -
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}При запуске приведенного выше кода мы получаем следующий ответ -
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Платформа агрегирования собирает все данные, выбранные поисковым запросом, и состоит из множества строительных блоков, которые помогают в построении сложных сводок данных. Базовая структура агрегации показана здесь -
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}Существуют разные типы агрегатов, каждое из которых имеет свою цель. Они подробно обсуждаются в этой главе.
Агрегаты показателей
Эти агрегации помогают в вычислении матриц из значений полей агрегированных документов, и иногда некоторые значения могут быть сгенерированы из скриптов.
Числовые матрицы могут быть однозначными, как агрегирование средних значений, или многозначными, как статистика.
Среднее агрегирование
Это агрегирование используется для получения среднего значения любого числового поля, присутствующего в агрегированных документах. Например,
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}Агрегация мощности
Эта агрегация дает количество различных значений определенного поля.
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}Note - Значение количества элементов равно 2, потому что существует два различных значения сборов.
Расширенное агрегирование статистики
Эта агрегация генерирует всю статистику по конкретному числовому полю в агрегированных документах.
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}Максимальное агрегирование
Эта агрегация находит максимальное значение определенного числового поля в агрегированных документах.
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}Мин. Агрегирование
Эта агрегация находит минимальное значение определенного числового поля в агрегированных документах.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}Сумма агрегирования
Эта агрегация вычисляет сумму определенного числового поля в агрегированных документах.
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}Существуют и другие агрегаты метрик, которые используются в особых случаях, например агрегирование географических границ и агрегирование геоцентроидов для целей геолокации.
Статистические агрегаты
Агрегирование многозначных метрик, которое вычисляет статистику по числовым значениям, извлеченным из агрегированных документов.
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}Метаданные агрегирования
Вы можете добавить некоторые данные об агрегировании во время запроса с помощью метатега и получить их в ответ.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}Эти API отвечают за управление всеми аспектами индекса, такими как настройки, псевдонимы, сопоставления, шаблоны индекса.
Создать индекс
Этот API поможет вам создать индекс. Индекс может быть создан автоматически, когда пользователь передает объекты JSON в любой индекс, или он может быть создан до этого. Чтобы создать индекс, вам просто нужно отправить запрос PUT с настройками, сопоставлениями и псевдонимами или просто запрос без тела.
PUT collegesПри запуске приведенного выше кода мы получаем результат, как показано ниже -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Мы также можем добавить некоторые настройки в приведенную выше команду -
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}При запуске приведенного выше кода мы получаем результат, как показано ниже -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Удалить указатель
Этот API поможет вам удалить любой index. Вам просто нужно передать запрос на удаление с именем этого конкретного индекса.
DELETE /collegesВы можете удалить все индексы, просто используя _all или *.
Получить индекс
Этот API можно вызвать, просто отправив запрос на получение одному или нескольким индексам. Это возвращает информацию об index.
GET collegesПри запуске приведенного выше кода мы получаем результат, как показано ниже -
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Вы можете получить информацию обо всех индексах, используя _all или *.
Индекс существует
Существование индекса можно определить, просто отправив этому индексу запрос на получение. Если ответ HTTP - 200, он существует; если это 404, его не существует.
HEAD collegesПри запуске приведенного выше кода мы получаем результат, как показано ниже -
200-OKНастройки индекса
Вы можете получить настройки индекса, просто добавив ключевое слово _settings в конец URL-адреса.
GET /colleges/_settingsПри запуске приведенного выше кода мы получаем результат, как показано ниже -
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Статистика индекса
Этот API помогает вам извлекать статистику по определенному индексу. Вам просто нужно отправить запрос на получение с URL-адресом индекса и ключевым словом _stats в конце.
GET /_statsПри запуске приведенного выше кода мы получаем результат, как показано ниже -
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………Румянец
Процесс очистки индекса гарантирует, что любые данные, которые в настоящее время сохраняются только в журнале транзакций, также постоянно сохраняются в Lucene. Это сокращает время восстановления, поскольку эти данные не нужно переиндексировать из журналов транзакций после открытия индексированного Lucene.
POST colleges/_flushПри запуске приведенного выше кода мы получаем результат, как показано ниже -
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}Обычно результаты различных API-интерфейсов Elasticsearch отображаются в формате JSON. Но JSON не всегда легко читать. Таким образом, функция Cat API, доступная в Elasticsearch, помогает упростить чтение и понимание формата печати результатов. В cat API используются различные параметры, для которых используется различное назначение сервера, например - термин V делает вывод подробным.
Давайте узнаем об API cat более подробно в этой главе.
Подробный
Подробный вывод дает хорошее отображение результатов команды cat. В приведенном ниже примере мы получаем подробную информацию о различных индексах, присутствующих в кластере.
GET /_cat/indices?vПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb
yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b
yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb
yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283bЗаголовки
Параметр h, также называемый заголовком, используется для отображения только тех столбцов, которые упомянуты в команде.
GET /_cat/nodes?h=ip,portПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
127.0.0.1 9300Сортировать
Команда sort принимает строку запроса, которая может отсортировать таблицу по указанному столбцу в запросе. По умолчанию используется сортировка по возрастанию, но это можно изменить, добавив: desc в столбец.
В приведенном ниже примере показан результат шаблонов, упорядоченных в порядке убывания заполненных шаблонов индекса.
GET _cat/templates?v&s=order:desc,index_patternsПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
name index_patterns order version
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-9 [.watcher-history-9*] 2147483647
.watches [.watches*] 2147483647
.kibana_task_manager [.kibana_task_manager] 0 7000099Считать
Параметр count обеспечивает подсчет общего количества документов во всем кластере.
GET /_cat/count?vПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
epoch timestamp count
1557633536 03:58:56 17809API кластера используется для получения информации о кластере и его узлах, а также для внесения в них изменений. Чтобы вызвать этот API, нам нужно указать имя узла, адрес или _local.
GET /_nodes/_localПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………Состояние кластера
Этот API используется для получения статуса работоспособности кластера путем добавления ключевого слова «здоровье».
GET /_cluster/healthПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}Состояние кластера
Этот API используется для получения информации о состоянии кластера путем добавления URL-адреса ключевого слова state. Информация о состоянии содержит версию, главный узел, другие узлы, таблицу маршрутизации, метаданные и блоки.
GET /_cluster/stateПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………Статистика кластера
Этот API помогает получать статистику о кластере с помощью ключевого слова stats. Этот API возвращает номер шарда, размер хранилища, использование памяти, количество узлов, ролей, ОС и файловую систему.
GET /_cluster/statsПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….Настройки обновления кластера
Этот API позволяет обновлять настройки кластера с помощью ключевого слова settings. Есть два типа настроек - постоянные (применяются при перезагрузках) и временные (не выдерживают полного перезапуска кластера).
Статистика узла
Этот API используется для получения статистики еще одного узла кластера. Статистика узла почти такая же, как и у кластера.
GET /_nodes/statsПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….Узлы hot_threads
Этот API помогает получить информацию о текущих горячих потоках на каждом узле кластера.
GET /_nodes/hot_threadsПри запуске приведенного выше кода мы получаем ответ, как показано ниже -
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:В Elasticsearch поиск осуществляется с помощью запроса на основе JSON. Запрос состоит из двух предложений -
Leaf Query Clauses - Эти предложения представляют собой совпадение, термин или диапазон, которые ищут конкретное значение в определенном поле.
Compound Query Clauses - Эти запросы представляют собой комбинацию предложений конечных запросов и других составных запросов для извлечения нужной информации.
Elasticsearch поддерживает большое количество запросов. Запрос начинается с ключевого слова запроса, а затем содержит условия и фильтры в виде объекта JSON. Ниже описаны различные типы запросов.
Соответствовать всем запросам
Это самый простой запрос; он возвращает все содержимое и каждый объект получает оценку 1,0.
POST /schools/_search
{
"query":{
"match_all":{}
}
}Запустив приведенный выше код, мы получаем следующий результат -
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Полнотекстовые запросы
Эти запросы используются для поиска по всему тексту, например по главе или новостной статье. Этот запрос работает в соответствии с анализатором, связанным с этим конкретным индексом или документом. В этом разделе мы обсудим различные типы полнотекстовых запросов.
Соответствующий запрос
Этот запрос соответствует тексту или фразе со значениями одного или нескольких полей.
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Запрос на несколько совпадений
Этот запрос соответствует тексту или фразе с более чем одним полем.
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Запрос строки запроса
В этом запросе используется парсер запроса и ключевое слово query_string.
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….Запросы на уровне термина
Эти запросы в основном имеют дело со структурированными данными, такими как числа, даты и перечисления.
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..Запрос диапазона
Этот запрос используется для поиска объектов, значения которых находятся между заданными диапазонами значений. Для этого нам нужно использовать такие операторы, как -
- gte - больше чем равно
- gt - больше чем
- lte - меньше чем равно
- lt - менее чем
Например, обратите внимание на код, приведенный ниже -
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Существуют и другие типы запросов на уровне терминов, такие как -
Exists query - Если определенное поле имеет ненулевое значение.
Missing query - Это полностью противоположно существующему запросу, этот запрос ищет объекты без определенных полей или полей, имеющих нулевое значение.
Wildcard or regexp query - Этот запрос использует регулярные выражения для поиска шаблонов в объектах.
Составные запросы
Эти запросы представляют собой набор различных запросов, объединенных друг с другом с использованием логических операторов, таких как and, or, not, для разных индексов или с вызовами функций и т. Д.
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}Географические запросы
Эти запросы касаются географических местоположений и географических точек. Эти запросы помогают найти школы или любой другой географический объект рядом с любым местом. Вам необходимо использовать тип данных гео-точки.
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}Теперь размещаем данные в созданном выше индексе.
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}Сопоставление - это схема документов, хранящихся в индексе. Он определяет тип данных, например geo_point или string, и формат полей, присутствующих в документах, и правилах для управления отображением динамически добавляемых полей.
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}Когда мы запускаем приведенный выше код, мы получаем ответ, как показано ниже -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}Типы данных полей
Elasticsearch поддерживает ряд различных типов данных для полей в документе. Типы данных, используемые для хранения полей в Elasticsearch, подробно обсуждаются здесь.
Основные типы данных
Это основные типы данных, такие как текст, ключевое слово, дата, long, double, boolean или ip, которые поддерживаются почти всеми системами.
Сложные типы данных
Эти типы данных представляют собой комбинацию основных типов данных. К ним относятся массив, объект JSON и вложенный тип данных. Пример вложенного типа данных показан ниже & минус
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}Когда мы запускаем приведенный выше код, мы получаем ответ, как показано ниже -
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Другой пример кода показан ниже -
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}Когда мы запускаем приведенный выше код, мы получаем ответ, как показано ниже -
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Мы можем проверить приведенный выше документ, используя следующую команду -
GET /accountdetails/_mappings?include_type_name=falseУдаление типов сопоставления
Индексы, созданные в Elasticsearch 7.0.0 или более поздней версии, больше не принимают сопоставление _default_. Индексы, созданные в 6.x, будут продолжать работать, как и раньше, в Elasticsearch 6.x. Типы устарели в API версии 7.0.
Когда запрос обрабатывается во время операции поиска, содержимое любого индекса анализируется модулем анализа. Этот модуль состоит из анализатора, токенизатора, tokenfilters и charfilters. Если анализатор не определен, то по умолчанию встроенные анализаторы, токен, фильтры и токенизаторы регистрируются в модуле анализа.
В следующем примере мы используем стандартный анализатор, который используется, когда не указан другой анализатор. Он проанализирует предложение на основе грамматики и произведет слова, используемые в предложении.
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}Настройка стандартного анализатора
Мы можем настроить стандартный анализатор с различными параметрами в соответствии с нашими индивидуальными требованиями.
В следующем примере мы настраиваем стандартный анализатор так, чтобы max_token_length равнялось 5.
Для этого сначала создаем индекс с анализатором, имеющим параметр max_length_token.
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}Далее мы применяем анализатор с текстом, как показано ниже. Обратите внимание, как токен не отображается, поскольку он имеет два пробела в начале и два пробела в конце. Для слова «есть» есть пробел в начале и пробел в конце. Взяв все из них, получается 4 буквы с пробелами, и это не превращается в слово. По крайней мере, в начале или в конце должен быть символ без пробела, чтобы слово было подсчитанным.
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}Список различных анализаторов и их описание приведены в таблице ниже -
| S.No | Анализатор и описание |
|---|---|
| 1 | Standard analyzer (standard) Для этого анализатора можно задать параметры stopwords и max_token_length. По умолчанию список стоп-слов пуст, а max_token_length равно 255. |
| 2 | Simple analyzer (simple) Этот анализатор состоит из токенизатора нижнего регистра. |
| 3 | Whitespace analyzer (whitespace) Этот анализатор состоит из токенизатора пробелов. |
| 4 | Stop analyzer (stop) Stopwords и stopwords_path можно настроить. По умолчанию стоп-слова инициализируются английскими стоп-словами, а stopwords_path содержит путь к текстовому файлу со стоп-словами. |
Токенизаторы
Токенизаторы используются для генерации токенов из текста в Elasticsearch. Текст можно разбить на токены с учетом пробелов или других знаков препинания. Elasticsearch имеет множество встроенных токенизаторов, которые можно использовать в настраиваемом анализаторе.
Пример токенизатора, который разбивает текст на термины всякий раз, когда он встречает символ, который не является буквой, но также делает все термины строчными буквами, показан ниже.
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}Список токенизаторов и их описания показаны здесь в таблице, приведенной ниже -
| S.No | Токенизатор и описание |
|---|---|
| 1 | Standard tokenizer (standard) Он построен на основе токенизатора на основе грамматики, и для этого токенизатора можно настроить max_token_length. |
| 2 | Edge NGram tokenizer (edgeNGram) Для этого токенизатора можно установить такие настройки, как min_gram, max_gram, token_chars. |
| 3 | Keyword tokenizer (keyword) Это генерирует весь ввод как вывод, и для этого можно установить buffer_size. |
| 4 | Letter tokenizer (letter) Это захватывает все слово, пока не встретится не буква. |
Elasticsearch состоит из ряда модулей, которые отвечают за его функциональность. Эти модули имеют два типа настроек, а именно:
Static Settings- Эти параметры необходимо настроить в файле config (elasticsearch.yml) перед запуском Elasticsearch. Вам необходимо обновить все интересующие узлы в кластере, чтобы отразить изменения этих параметров.
Dynamic Settings - Эти настройки можно установить в реальном времени Elasticsearch.
Мы обсудим различные модули Elasticsearch в следующих разделах этой главы.
Маршрутизация на уровне кластера и распределение сегментов
Параметры уровня кластера определяют распределение шардов по разным узлам и перераспределение шардов для ребалансировки кластера. Это следующие параметры для управления выделением сегментов.
Распределение сегментов на уровне кластера
| Настройка | Возможное значение | Описание |
|---|---|---|
| cluster.routing.allocation.enable | ||
| все | Это значение по умолчанию позволяет выделять сегменты для всех видов сегментов. | |
| праймериз | Это позволяет выделять сегменты только для основных сегментов. | |
| new_primaries | Это позволяет выделять сегменты только для основных сегментов для новых индексов. | |
| никто | Это не позволяет выделять осколки. | |
| cluster.routing.allocation .node_concurrent_recoveries | Числовое значение (по умолчанию 2) | Это ограничивает количество одновременных восстановлений сегментов. |
| cluster.routing.allocation .node_initial_primaries_recoveries | Числовое значение (по умолчанию 4) | Это ограничивает количество параллельных начальных первичных восстановлений. |
| cluster.routing.allocation .same_shard.host | Логическое значение (по умолчанию false) | Это ограничивает выделение более одной реплики одного и того же шарда на одном физическом узле. |
| index.recovery.concurrent _streams | Числовое значение (по умолчанию 3) | Это контролирует количество открытых сетевых потоков на узел во время восстановления шарда из одноранговых шардов. |
| index.recovery.concurrent _small_file_streams | Числовое значение (по умолчанию 2) | Это контролирует количество открытых потоков на узел для небольших файлов размером менее 5 МБ во время восстановления осколка. |
| cluster.routing.rebalance.enable | ||
| все | Это значение по умолчанию позволяет балансировать для всех видов шардов. | |
| праймериз | Это позволяет балансировать сегменты только для основных сегментов. | |
| реплики | Это позволяет балансировать шарды только для шардов реплик. | |
| никто | Это не позволяет выполнять балансировку сегментов. | |
| cluster.routing.allocation .allow_rebalance | ||
| всегда | Это значение по умолчанию всегда разрешает перебалансировку. | |
| index_primaries _active | Это позволяет перебалансировать, когда все основные шарды в кластере выделены. | |
| Индексы_все_активные | Это позволяет перебалансировать, когда все первичные и реплики распределены. | |
| cluster.routing.allocation.cluster _concurrent_rebalance | Числовое значение (по умолчанию 2) | Это ограничивает количество одновременных балансировок сегментов в кластере. |
| cluster.routing.allocation .balance.shard | Плавающее значение (по умолчанию 0,45f) | Это определяет весовой коэффициент для шардов, выделенных на каждом узле. |
| cluster.routing.allocation .balance.index | Плавающее значение (по умолчанию 0.55f) | Это определяет соотношение количества шардов на индекс, выделенный на конкретном узле. |
| cluster.routing.allocation .balance.threshold | Неотрицательное значение с плавающей запятой (по умолчанию 1.0f) | Это минимальное значение оптимизации операций, которые необходимо выполнить. |
Распределение сегментов на диске
| Настройка | Возможное значение | Описание |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | Логическое значение (по умолчанию true) | Это включает и отключает решение о выделении диска. |
| cluster.routing.allocation.disk.watermark.low | Строковое значение (по умолчанию 85%) | Это означает максимальное использование диска; после этого ни один другой сегмент не может быть размещен на этом диске. |
| cluster.routing.allocation.disk.watermark.high | Строковое значение (по умолчанию 90%) | Это означает максимальное использование во время распределения; если эта точка будет достигнута во время выделения, Elasticsearch разместит этот сегмент на другом диске. |
| cluster.info.update.interval | Строковое значение (по умолчанию 30 секунд) | Это интервал между проверками использования диска. |
| cluster.routing.allocation.disk.include_relocations | Логическое значение (по умолчанию true) | Это решает, следует ли учитывать выделенные в данный момент сегменты при расчете использования диска. |
Открытие
Этот модуль помогает кластеру обнаруживать и поддерживать состояние всех узлов в нем. Состояние кластера изменяется при добавлении или удалении узла. Настройка имени кластера используется для создания логической разницы между разными кластерами. Есть несколько модулей, которые помогут вам использовать API-интерфейсы, предоставляемые поставщиками облачных услуг, и они приведены ниже:
- Лазурное открытие
- Открытие EC2
- Обнаружение вычислительного механизма Google
- Открытие дзен
Шлюз
Этот модуль поддерживает состояние кластера и данные о сегменте при полном перезапуске кластера. Ниже приведены статические настройки этого модуля -
| Настройка | Возможное значение | Описание |
|---|---|---|
| gateway.expected_nodes | числовое значение (по умолчанию 0) | Количество узлов, которые, как ожидается, будут в кластере для восстановления локальных сегментов. |
| gateway.expected_master_nodes | числовое значение (по умолчанию 0) | Ожидаемое количество главных узлов в кластере до начала восстановления. |
| gateway.expected_data_nodes | числовое значение (по умолчанию 0) | Ожидаемое количество узлов данных в кластере до начала восстановления. |
| gateway.recover_after_time | Строковое значение (по умолчанию 5 м) | Это интервал между проверками использования диска. |
| cluster.routing.allocation. disk.include_relocations | Логическое значение (по умолчанию true) | Это указывает время, в течение которого процесс восстановления будет ждать начала независимо от количества узлов, объединенных в кластер. gateway.recover_ after_nodes |
HTTP
Этот модуль управляет обменом данными между HTTP-клиентом и API-интерфейсами Elasticsearch. Этот модуль можно отключить, изменив значение http.enabled на false.
Ниже приведены настройки (настроенные в elasticsearch.yml) для управления этим модулем:
| S.No | Настройка и описание |
|---|---|
| 1 | http.port Это порт для доступа к Elasticsearch, диапазон значений от 9200 до 9300. |
| 2 | http.publish_port Этот порт предназначен для http-клиентов, а также полезен в случае брандмауэра. |
| 3 | http.bind_host Это адрес хоста для службы http. |
| 4 | http.publish_host Это адрес хоста для http-клиента. |
| 5 | http.max_content_length Это максимальный размер содержимого в HTTP-запросе. Его значение по умолчанию - 100 МБ. |
| 6 | http.max_initial_line_length Это максимальный размер URL, значение по умолчанию - 4 КБ. |
| 7 | http.max_header_size Это максимальный размер заголовка http, значение по умолчанию - 8 КБ. |
| 8 | http.compression Это включает или отключает поддержку сжатия, а его значение по умолчанию - false. |
| 9 | http.pipelinig Это включает или отключает конвейерную обработку HTTP. |
| 10 | http.pipelining.max_events Это ограничивает количество событий, которые должны быть поставлены в очередь перед закрытием HTTP-запроса. |
Индексы
Этот модуль поддерживает настройки, которые устанавливаются глобально для каждого индекса. Следующие настройки в основном связаны с использованием памяти -
Автоматический выключатель
Это используется для предотвращения возникновения ошибки OutOfMemroyError. Этот параметр в основном ограничивает размер кучи JVM. Например, параметр index.breaker.total.limit, который по умолчанию составляет 70% кучи JVM.
Кэш полевых данных
Это используется в основном при агрегировании по полю. Рекомендуется иметь достаточно памяти для ее выделения. Объем памяти, используемый для кэша данных поля, можно контролировать с помощью параметра index.fielddata.cache.size.
Кэш запросов узла
Эта память используется для кэширования результатов запроса. Этот кэш использует политику выселения из числа недавно использованных (LRU). Параметр Indices.queries.cahce.size контролирует размер памяти этого кеша.
Индексирующий буфер
Этот буфер сохраняет вновь созданные документы в индексе и сбрасывает их, когда буфер заполняется. Такие настройки, как index.memory.index_buffer_size, управляют размером кучи, выделенной для этого буфера.
Кэш запроса осколков
Этот кеш используется для хранения данных локального поиска для каждого шарда. Кэш можно включить во время создания индекса или отключить, отправив параметр URL.
Disable cache - ?request_cache = true
Enable cache "index.requests.cache.enable": trueВосстановление индексов
Он контролирует ресурсы в процессе восстановления. Ниже приведены настройки -
| Настройка | Значение по умолчанию |
|---|---|
| index.recovery.concurrent_streams | 3 |
| index.recovery.concurrent_small_file_streams | 2 |
| index.recovery.file_chunk_size | 512кб |
| index.recovery.translog_ops | 1000 |
| index.recovery.translog_size | 512кб |
| index.recovery.compress | правда |
| index.recovery.max_bytes_per_sec | 40 МБ |
TTL интервал
Интервал времени жизни (TTL) определяет время документа, по истечении которого документ удаляется. Ниже приведены динамические настройки для управления этим процессом -
| Настройка | Значение по умолчанию |
|---|---|
| index.ttl.interval | 60-е годы |
| index.ttl.bulk_size | 1000 |
Узел
Каждый узел может быть узлом данных или нет. Вы можете изменить это свойство, изменивnode.dataнастройка. Установка значения какfalse определяет, что узел не является узлом данных.
Это модули, которые создаются для каждого индекса и управляют настройками и поведением индексов. Например, сколько осколков может использовать индекс или количество реплик, которые первичный осколок может иметь для этого индекса и т. Д. Существует два типа настроек индекса:
- Static - Их можно установить только во время создания индекса или для закрытого индекса.
- Dynamic - Их можно изменить в живом индексе.
Настройки статического индекса
В следующей таблице показан список настроек статического индекса -
| Настройка | Возможное значение | Описание |
|---|---|---|
| index.number_of_shards | По умолчанию 5, максимум 1024 | Количество первичных шардов, которые должен иметь индекс. |
| index.shard.check_on_startup | По умолчанию - false. Может быть правдой | Следует ли перед открытием проверять шарды на наличие повреждений. |
| index.codec | Сжатие LZ4. | Тип сжатия, используемый для хранения данных. |
| index.routing_partition_size | 1 | Число сегментов, к которым может перейти значение настраиваемой маршрутизации. |
| index.load_fixed_bitset_filters_eagerly | ложный | Указывает, предварительно загружены ли кэшированные фильтры для вложенных запросов |
Настройки динамического индекса
В следующей таблице показан список настроек динамического индекса -
| Настройка | Возможное значение | Описание |
|---|---|---|
| index.number_of_replicas | По умолчанию 1 | Количество реплик, которые имеет каждый первичный шард. |
| index.auto_expand_replicas | Нижняя и верхняя границы разделены тире (0–5) | Автоматически увеличивайте количество реплик в зависимости от количества узлов данных в кластере. |
| index.search.idle.after | 30 секунд | Как долго сегмент не может получать поиск или запрос до тех пор, пока поиск не будет считаться бездействующим. |
| index.refresh_interval | 1 секунда | Как часто выполнять операцию обновления, которая делает последние изменения индекса видимыми для поиска. |
| index.blocks.read_only | 1 верно / неверно | Установите значение true, чтобы сделать индекс и метаданные индекса только для чтения, false, чтобы разрешить запись и изменение метаданных. |
Иногда нам нужно преобразовать документ, прежде чем мы его проиндексируем. Например, мы хотим удалить поле из документа или переименовать поле, а затем проиндексировать его. Этим занимается узел Ingest.
Каждый узел в кластере может принимать данные, но его также можно настроить для обработки только определенными узлами.
Вовлеченные шаги
Работа узла приема состоит из двух этапов:
- Создание конвейера
- Создание документа
Создать конвейер
Сначала создайте конвейер, который содержит процессоры, а затем выполните конвейер, как показано ниже -
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}Запустив приведенный выше код, мы получаем следующий результат -
{
"acknowledged" : true
}Создать документ
Далее мы создаем документ с помощью конвейерного конвертера.
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Затем мы ищем документ, созданный выше, с помощью команды GET, как показано ниже -
GET /logs/_doc/1Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}Вы можете видеть выше, что 21 стало целым числом.
Без трубопровода
Теперь создаем документ без использования конвейера.
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}Вы можете видеть выше, что 11 - это строка без использования конвейера.
Управление жизненным циклом индекса включает выполнение управленческих действий на основе таких факторов, как размер сегмента и требования к производительности. API-интерфейсы управления жизненным циклом индексов (ILM) позволяют автоматизировать процесс управления индексами с течением времени.
В этой главе приводится список API-интерфейсов ILM и их использование.
API управления политиками
| Имя API | Цель | пример |
|---|---|---|
| Создайте политику жизненного цикла. | Создает политику жизненного цикла. Если указанная политика существует, она заменяется, а версия политики увеличивается. | PUT_ilm / policy / policy_id |
| Получите политику жизненного цикла. | Возвращает указанное определение политики. Включает версию политики и дату последнего изменения. Если политика не указана, возвращает все определенные политики. | GET_ilm / policy / policy_id |
| Удалить политику жизненного цикла | Удаляет указанное определение политики жизненного цикла. Вы не можете удалить политики, которые используются в данный момент. Если политика используется для управления какими-либо индексами, запрос не выполняется и возвращает ошибку. | DELETE_ilm / policy / policy_id |
API управления индексами
| Имя API | Цель | пример |
|---|---|---|
| Перейти к API этапа жизненного цикла. | Вручную перемещает индекс на указанный шаг и выполняет этот шаг. | POST_ilm / move / index |
| Политика повторных попыток. | Устанавливает политику обратно на шаг, на котором произошла ошибка, и выполняет шаг. | Индекс POST / _ilm / retry |
| Удалить политику из редактирования API индекса. | Удаляет назначенную политику жизненного цикла и прекращает управление указанным индексом. Если указан шаблон индекса, удаляет назначенные политики из всех соответствующих индексов. | Индекс POST / _ilm / remove |
API управления операциями
| Имя API | Цель | пример |
|---|---|---|
| Получите API статуса управления жизненным циклом индекса. | Возвращает статус плагина ILM. Поле operation_mode в ответе показывает одно из трех состояний: STARTED, STOPPING или STOPPED. | GET / _ilm / status |
| Запустить API управления жизненным циклом индекса. | Запускает плагин ILM, если он в данный момент остановлен. ILM запускается автоматически при формировании кластера. | POST / _ilm / start |
| Остановить API управления жизненным циклом индекса. | Останавливает все операции управления жизненным циклом и останавливает плагин ILM. Это полезно, когда вы выполняете обслуживание кластера и вам нужно запретить ILM выполнять какие-либо действия с вашими индексами. | POST / _ilm / stop |
| Объясните API жизненного цикла. | Извлекает информацию о текущем состоянии жизненного цикла индекса, например о выполняемой в данный момент фазе, действии и шаге. Показывает, когда индекс входил в каждый из них, определение этапа выполнения и информацию о любых сбоях. | ПОЛУЧИТЬ index / _ilm / объяснять |
Это компонент, который позволяет в реальном времени выполнять SQL-подобные запросы к Elasticsearch. Вы можете думать об Elasticsearch SQL как о переводчике, который понимает как SQL, так и Elasticsearch и упрощает чтение и обработку данных в реальном времени в любом масштабе за счет использования возможностей Elasticsearch.
Преимущества Elasticsearch SQL
It has native integration - Каждый запрос эффективно выполняется для соответствующих узлов в соответствии с базовым хранилищем.
No external parts - Нет необходимости в дополнительном оборудовании, процессах, средах выполнения или библиотеках для запросов Elasticsearch.
Lightweight and efficient - он включает и предоставляет SQL для правильного полнотекстового поиска в реальном времени.
пример
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}SQL-запрос
В следующем примере показано, как мы формируем запрос SQL -
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}При запуске приведенного выше кода мы получаем ответ, как показано ниже -
Address | name | start_date | student_count
--------------------+---------------+------------------------+---------------
Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482
Main Street |Sunshine |1965-06-01T00:00:00.000Z|604Note - Изменяя приведенный выше запрос SQL, вы можете получить разные наборы результатов.
Чтобы отслеживать работоспособность кластера, функция мониторинга собирает метрики с каждого узла и сохраняет их в индексах Elasticsearch. Все настройки, связанные с мониторингом в Elasticsearch, должны быть установлены либо в файле elasticsearch.yml для каждого узла, либо, где это возможно, в настройках динамического кластера.
Чтобы начать мониторинг, нам нужно проверить настройки кластера, что можно сделать следующим образом:
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}Каждый компонент в стеке отвечает за самоконтроль, а затем за пересылку этих документов в производственный кластер Elasticsearch как для маршрутизации, так и для индексации (хранения). Процессы маршрутизации и индексации в Elasticsearch обрабатываются так называемыми сборщиками и экспортерами.
Коллекционеры
Сборщик запускается один раз за каждый интервал сбора для получения данных из общедоступных API-интерфейсов в Elasticsearch, которые он выбирает для мониторинга. Когда сбор данных завершен, данные массово передаются экспортерам для отправки в кластер мониторинга.
Для каждого типа данных существует только один коллектор. Каждый сборщик может создать ноль или более документов мониторинга.
Экспортеры
Экспортеры берут данные, собранные из любого источника Elastic Stack, и направляют их в кластер мониторинга. Можно настроить более одного экспортера, но общая настройка по умолчанию - использование одного экспортера. Экспортеры можно настраивать как на уровне узла, так и на уровне кластера.
В Elasticsearch есть два типа экспортеров:
local - Этот экспортер направляет данные обратно в тот же кластер
http - Предпочтительный экспортер, который можно использовать для маршрутизации данных в любой поддерживаемый кластер Elasticsearch, доступный через HTTP.
Прежде чем экспортеры смогут направлять данные мониторинга, они должны настроить определенные ресурсы Elasticsearch. Эти ресурсы включают шаблоны и конвейеры приема.
Сводное задание - это периодическая задача, которая суммирует данные из индексов, указанных в шаблоне индекса, и преобразует их в новый индекс. В следующем примере мы создаем индекс с именем sensor с разными отметками даты и времени. Затем мы создаем задание объединения для периодического объединения данных из этих индексов с помощью задания cron.
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}Запустив приведенный выше код, мы получаем следующий результат -
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Теперь добавьте второй документ и так далее для других документов.
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}Создать задание объединения
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}Параметр cron определяет, когда и как часто задание активируется. Когда срабатывает расписание cron задания накопления, оно начинает сворачиваться с того места, где оно остановилось после последней активации.
После того, как задание будет выполнено и обработаны некоторые данные, мы можем использовать запрос DSL для поиска.
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}Индексы, по которым часто выполняется поиск, хранятся в памяти, потому что на их восстановление и помощь в эффективном поиске требуется время. С другой стороны, могут быть индексы, к которым мы редко обращаемся. Эти индексы не должны занимать память и могут быть перестроены при необходимости. Такие индексы известны как замороженные индексы.
Elasticsearch создает временные структуры данных для каждого сегмента замороженного индекса при каждом поиске в этом сегменте и отбрасывает эти структуры данных, как только поиск завершается. Поскольку Elasticsearch не поддерживает эти временные структуры данных в памяти, замороженные индексы потребляют гораздо меньше кучи, чем обычные индексы. Это позволяет добиться гораздо более высокого отношения диска к куче, чем было бы возможно в противном случае.
Пример замораживания и размораживания
В следующем примере замораживается и размораживается индекс -
POST /index_name/_freeze
POST /index_name/_unfreezeОжидается, что поиск по замороженным индексам будет выполняться медленно. Замороженные индексы не предназначены для высокой поисковой нагрузки. Возможно, что поиск замороженного индекса может занять секунды или минуты, даже если тот же поиск завершился за миллисекунды, когда индексы не были заморожены.
Поиск по замороженному индексу
Количество одновременно загружаемых замороженных индексов на узел ограничено количеством потоков в пуле потоков search_throttled, которое по умолчанию равно 1. Чтобы включить замороженные индексы, необходимо выполнить поисковый запрос с параметром запроса - ignore_throttled = false.
GET /index_name/_search?q=user:tpoint&ignore_throttled=falseМониторинг замороженных индексов
Замороженные индексы - это обычные индексы, использующие регулирование поиска и реализацию сегментов с эффективным использованием памяти.
GET /_cat/indices/index_name?v&h=i,sthElasticsearch предоставляет файл jar, который можно добавить в любую Java IDE и использовать для тестирования кода, связанного с Elasticsearch. Ряд тестов может быть выполнен с использованием инфраструктуры, предоставляемой Elasticsearch. В этой главе мы подробно обсудим эти тесты -
- Модульное тестирование
- Интеграционное тестирование
- Рандомизированное тестирование
Предпосылки
Чтобы начать тестирование, вам нужно добавить в свою программу зависимость тестирования Elasticsearch. Вы можете использовать maven для этой цели и можете добавить следующее в pom.xml.
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.1.0</version>
</dependency>EsSetup был инициализирован для запуска и остановки узла Elasticsearch, а также для создания индексов.
EsSetup esSetup = new EsSetup();Функция esSetup.execute () с createIndex создаст индексы, вам нужно указать настройки, тип и данные.
Модульное тестирование
Модульное тестирование выполняется с использованием тестовой среды JUnit и Elasticsearch. Узел и индексы могут быть созданы с использованием классов Elasticsearch, а метод тестирования может использоваться для выполнения тестирования. Для этого тестирования используются классы ESTestCase и ESTokenStreamTestCase.
Интеграционное тестирование
Интеграционное тестирование использует несколько узлов в кластере. Для этого тестирования используется класс ESIntegTestCase. Существуют различные методы, упрощающие подготовку тестового примера.
| S.No | Метод и описание |
|---|---|
| 1 | refresh() Все индексы в кластере обновляются |
| 2 | ensureGreen() Обеспечивает состояние зеленого кластера здоровья |
| 3 | ensureYellow() Обеспечивает желтое состояние кластера работоспособности |
| 4 | createIndex(name) Создать индекс с именем, переданным этому методу |
| 5 | flush() Все индексы в кластере сбрасываются |
| 6 | flushAndRefresh() flush () и refresh () |
| 7 | indexExists(name) Проверяет наличие указанного индекса |
| 8 | clusterService() Возвращает Java-класс службы кластеров |
| 9 | cluster() Возвращает класс тестового кластера |
Методы тестового кластера
| S.No | Метод и описание |
|---|---|
| 1 | ensureAtLeastNumNodes(n) Гарантирует, что минимальное количество узлов в кластере больше или равно указанному количеству. |
| 2 | ensureAtMostNumNodes(n) Гарантирует, что максимальное количество узлов в кластере меньше или равно указанному количеству. |
| 3 | stopRandomNode() Чтобы остановить случайный узел в кластере |
| 4 | stopCurrentMasterNode() Чтобы остановить главный узел |
| 5 | stopRandomNonMaster() Чтобы остановить случайный узел в кластере, который не является главным узлом. |
| 6 | buildNode() Создать новый узел |
| 7 | startNode(settings) Начать новый узел |
| 8 | nodeSettings() Переопределите этот метод для изменения настроек узла. |
Доступ к клиентам
Клиент используется для доступа к различным узлам в кластере и выполнения некоторых действий. Метод ESIntegTestCase.client () используется для получения случайного клиента. Elasticsearch предлагает и другие методы для доступа к клиенту, и к этим методам можно получить доступ с помощью метода ESIntegTestCase.internalCluster ().
| S.No | Метод и описание |
|---|---|
| 1 | iterator() Это поможет вам получить доступ ко всем доступным клиентам. |
| 2 | masterClient() Это возвращает клиента, который обменивается данными с главным узлом. |
| 3 | nonMasterClient() Это возвращает клиента, который не взаимодействует с главным узлом. |
| 4 | clientNodeClient() Это возвращает клиента, который в настоящее время работает на клиентском узле. |
Рандомизированное тестирование
Это тестирование используется для тестирования кода пользователя со всеми возможными данными, чтобы в будущем не было сбоев с любыми типами данных. Случайные данные - лучший вариант для проведения этого тестирования.
Генерация случайных данных
В этом тестировании экземпляр класса Random создается экземпляром, предоставленным RandomizedTest, и предлагает множество методов для получения различных типов данных.
| Метод | Возвращаемое значение |
|---|---|
| getRandom () | Экземпляр случайного класса |
| randomBoolean () | Случайное логическое значение |
| randomByte () | Случайный байт |
| randomShort () | Случайное короткое |
| randomInt () | Случайное целое число |
| randomLong () | Случайный длинный |
| randomFloat () | Случайное плавание |
| randomDouble () | Случайный двойной |
| randomLocale () | Случайная локаль |
| randomTimeZone () | Случайный часовой пояс |
| randomFrom () | Случайный элемент из массива |
Утверждения
Классы ElasticsearchAssertions и ElasticsearchGeoAssertions содержат утверждения, которые используются для выполнения некоторых общих проверок во время тестирования. Например, обратите внимание на приведенный здесь код -
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);Панель управления Kibana - это набор визуализаций и поисков. Вы можете упорядочивать, изменять размер и редактировать содержимое панели мониторинга, а затем сохранять панель, чтобы вы могли поделиться ею. В этой главе мы увидим, как создавать и редактировать информационную панель.
Создание приборной панели
На главной странице Kibana выберите опцию панели управления на левой панели управления, как показано ниже. Вам будет предложено создать новую панель управления.
Чтобы добавить визуализации на панель инструментов, мы выбираем меню «Добавить» и выбираем из имеющихся готовых визуализаций. Мы выбрали следующие варианты визуализации из списка.
При выборе вышеуказанных визуализаций мы получаем панель, как показано здесь. Позже мы сможем добавить и отредактировать панель управления для изменения элементов и добавления новых элементов.
Проверка элементов
Мы можем проверить элементы панели мониторинга, выбрав меню панели визуализаций и выбрав Inspect. Это позволит выявить данные за элементом, которые также можно будет загрузить.
Совместное использование панели управления
Мы можем поделиться панелью инструментов, выбрав меню общего доступа и выбрав опцию для получения гиперссылки, как показано ниже -

Функциональность обнаружения, доступная на домашней странице Kibana, позволяет нам исследовать наборы данных с разных сторон. Вы можете искать и фильтровать данные для выбранных шаблонов индекса. Данные обычно доступны в виде распределения значений за период времени.
Чтобы изучить образец данных электронной торговли, мы нажимаем на Discoverзначок, как показано на рисунке ниже. Это приведет к отображению данных вместе с диаграммой.
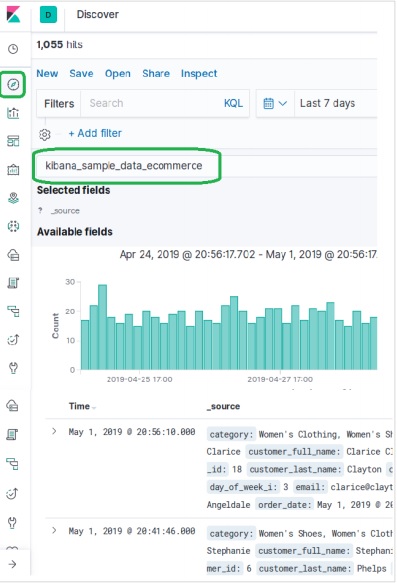
Фильтрация по времени
Чтобы отфильтровать данные по определенному временному интервалу, мы используем параметр временного фильтра, как показано ниже. По умолчанию фильтр установлен на 15 минут.
Фильтрация по полям
Набор данных также можно фильтровать по полям с помощью Add Filterвариант, как показано ниже. Здесь мы добавляем одно или несколько полей и после применения фильтров получаем соответствующий результат. В нашем примере мы выбираем полеday_of_week а затем оператор для этого поля как is и ценность как Sunday.
Затем мы нажимаем Сохранить с указанными выше условиями фильтрации. Набор результатов, содержащий примененные условия фильтрации, показан ниже.
Таблица данных - это тип визуализации, который используется для отображения необработанных данных составной агрегации. Существуют различные типы агрегатов, которые представлены с помощью таблиц данных. Чтобы создать таблицу данных, мы должны выполнить шаги, которые подробно обсуждаются здесь.
Визуализировать
На главном экране Kibana мы находим имя опции «Визуализировать», которая позволяет нам создавать визуализацию и агрегаты из индексов, хранящихся в Elasticsearch. На следующем изображении показан вариант.
Выбрать таблицу данных
Затем мы выбираем параметр «Таблица данных» среди различных доступных вариантов визуализации. Вариант показан на следующем изображении & miuns;
Выберите показатели
Затем мы выбираем метрики, необходимые для создания визуализации таблицы данных. Этот выбор определяет тип агрегирования, который мы собираемся использовать. Для этого мы выбираем определенные поля, показанные ниже, из набора данных электронной торговли.
При запуске вышеуказанной конфигурации для таблицы данных мы получаем результат, как показано на изображении здесь -
Карты регионов отображают показатели на географической карте. Это полезно для просмотра данных, привязанных к разным географическим регионам с разной интенсивностью. Более темные оттенки обычно указывают на более высокие значения, а более светлые оттенки указывают на более низкие значения.
Шаги по созданию этой визуализации подробно описаны ниже:
Визуализировать
На этом шаге мы переходим к кнопке визуализации, доступной на левой панели главного экрана Kibana, а затем выбираем вариант добавления новой визуализации.
На следующем экране показано, как мы выбираем опцию карты региона.
Выберите метрики
Следующий экран предлагает нам выбрать метрики, которые будут использоваться при создании карты региона. Здесь мы выбираем среднюю цену в качестве показателя и country_iso_code в качестве поля в корзине, которое будет использоваться при создании визуализации.
Окончательный результат ниже показывает карту региона после применения выделения. Обратите внимание на оттенки цвета и их значения, указанные на этикетке.
Круговые диаграммы - один из самых простых и известных инструментов визуализации. Он представляет данные в виде срезов круга, каждый из которых окрашен по-разному. Ярлыки вместе с процентными значениями данных могут быть представлены вместе с кружком. Круг также может иметь форму пончика.
Визуализировать
На главном экране Kibana мы находим имя опции «Визуализировать», которая позволяет нам создавать визуализацию и агрегирование на основе индексов, хранящихся в Elasticsearch. Мы решили добавить новую визуализацию и выбрать круговую диаграмму, как показано ниже.
Выберите метрики
Следующий экран предлагает нам выбрать метрики, которые будут использоваться при создании круговой диаграммы. Здесь мы выбираем количество базовых цен за единицу в качестве метрики и Bucket Aggregation в качестве гистограммы. Кроме того, минимальный интервал выбран равным 20. Таким образом, цены будут отображаться в виде блоков значений с 20 в качестве диапазона.
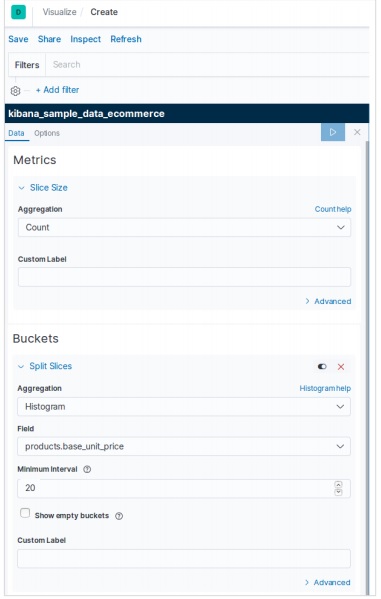
Результат ниже показывает круговую диаграмму после применения выделения. Обратите внимание на оттенки цвета и их значения, указанные на этикетке.

Параметры круговой диаграммы
Перейдя на вкладку параметров под круговой диаграммой, мы можем увидеть различные параметры конфигурации, чтобы изменить внешний вид, а также расположение данных на круговой диаграмме. В следующем примере круговая диаграмма выглядит как пончик, а метки отображаются вверху.
Диаграмма с областями - это продолжение линейной диаграммы, где область между линейной диаграммой и осями выделена некоторым цветом. Гистограмма представляет данные, организованные в диапазон значений, а затем нанесенные на оси. Он может состоять из горизонтальных или вертикальных полос.
В этой главе мы увидим все три типа графиков, созданных с помощью Kibana. Как обсуждалось в предыдущих главах, мы продолжим использовать данные в индексе электронной торговли.
Диаграмма с областями
На главном экране Kibana мы находим имя опции «Визуализировать», которая позволяет нам создавать визуализацию и агрегирование на основе индексов, хранящихся в Elasticsearch. Мы решили добавить новую визуализацию и выбрать Area Chart как вариант, показанный на изображении ниже.
Выберите метрики
На следующем экране нам предлагается выбрать метрики, которые будут использоваться при создании диаграммы с областями. Здесь мы выбираем сумму как тип показателя агрегирования. Затем мы выбираем поле total_quantity в качестве поля, которое будет использоваться в качестве метрики. На оси X мы выбрали поле order_date и разделили серию с заданной метрикой размером 5.

При запуске вышеуказанной конфигурации мы получаем следующую диаграмму с областями в качестве вывода -
Горизонтальная гистограмма
Точно так же для горизонтальной гистограммы мы выбираем новую визуализацию на главном экране Kibana и выбираем вариант для горизонтальной полосы. Затем мы выбираем показатели, как показано на изображении ниже. Здесь мы выбираем Сумму в качестве агрегирования указанного количества продукта в поле. Затем мы выбираем сегменты с гистограммой даты для даты заказа поля.
При запуске вышеуказанной конфигурации мы можем увидеть горизонтальную гистограмму, как показано ниже -
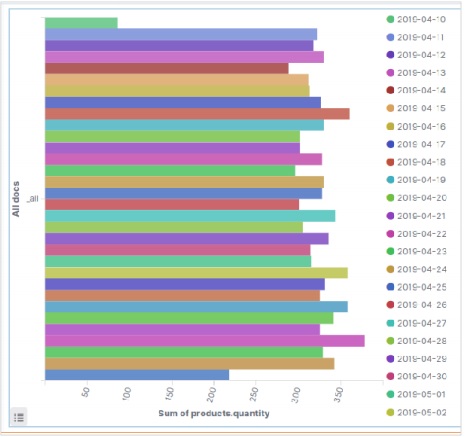
Вертикальная гистограмма
Для вертикальной гистограммы мы выбираем новую визуализацию на главном экране Kibana и выбираем вариант для вертикальной полосы. Затем мы выбираем показатели, как показано на изображении ниже.
Здесь мы выбираем Сумму в качестве агрегирования для поля с названием количество продукта. Затем выбираем сегменты с гистограммой дат для даты заказа поля с недельным интервалом.
При запуске вышеуказанной конфигурации будет сгенерирована диаграмма, как показано ниже -
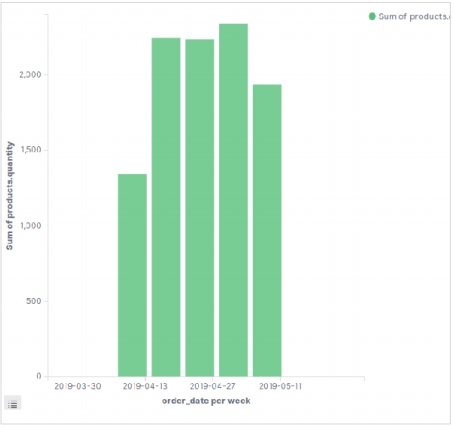
Временной ряд - это представление последовательности данных в определенной временной последовательности. Например, данные за каждый день, начиная с первого дня месяца до последнего дня. Интервал между точками данных остается постоянным. Любой набор данных, в котором есть временной компонент, может быть представлен как временной ряд.
В этой главе мы воспользуемся образцом набора данных электронной коммерции и построим подсчет количества заказов за каждый день, чтобы создать временной ряд.
Выберите показатели
Сначала мы выбираем шаблон индекса, поле данных и интервал, которые будут использоваться для создания временного ряда. В примере набора данных электронной торговли мы выбираем order_date в качестве поля и 1d в качестве интервала. Мы используемPanel Optionsвкладка, чтобы сделать этот выбор. Также мы оставляем другие значения на этой вкладке по умолчанию, чтобы получить цвет и формат по умолчанию для временного ряда.
в Data На вкладке мы выбираем счетчик в качестве параметра агрегации, группируем по параметрам как все и помещаем метку для диаграммы временных рядов.
Результат
Окончательный результат этой конфигурации выглядит следующим образом. Обратите внимание, что мы используем период времениMonth to Dateдля этого графика. Разные периоды времени дадут разные результаты.
Облако тегов представляет текст, который в основном является ключевыми словами и метаданными в визуально привлекательной форме. Они выровнены под разными углами и представлены разными цветами и разными размерами шрифта. Это помогает узнать наиболее важные термины в данных. Известность может быть определена одним или несколькими факторами, такими как частота использования термина, уникальность тега или на основании некоторого веса, присвоенного конкретным терминам и т. Д. Ниже мы видим шаги по созданию облака тегов.
Визуализировать
На главном экране Kibana мы находим имя опции «Визуализировать», которая позволяет нам создавать визуализацию и агрегирование на основе индексов, хранящихся в Elasticsearch. Мы решили добавить новую визуализацию и выбрать облако тегов, как показано ниже -
Выберите метрики
На следующем экране нам предлагается выбрать метрики, которые будут использоваться при создании облака тегов. Здесь мы выбираем счетчик как тип показателя агрегирования. Затем мы выбираем поле productname в качестве ключевого слова, которое будет использоваться в качестве тегов.
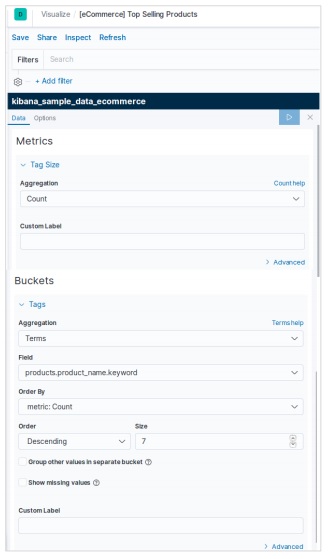
Показанный здесь результат показывает круговую диаграмму после того, как мы применили выделение. Обратите внимание на оттенки цвета и их значения, указанные на этикетке.

Параметры облака тегов
При переходе к optionsНа вкладке в облаке тегов мы можем увидеть различные параметры конфигурации, чтобы изменить внешний вид, а также порядок отображения данных в облаке тегов. В приведенном ниже примере появляется облако тегов с тегами, распределенными как в горизонтальном, так и в вертикальном направлениях.
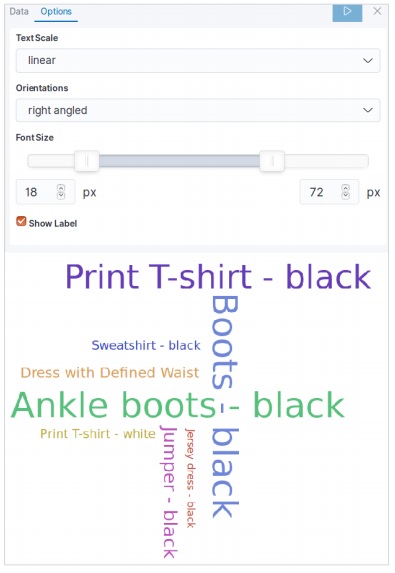
Тепловая карта - это тип визуализации, в которой разные оттенки цвета представляют разные области на графике. Значения могут непрерывно изменяться, и, следовательно, цветовые оттенки цвета меняются вместе со значениями. Они очень полезны для представления как непрерывно меняющихся данных, так и дискретных данных.
В этой главе мы будем использовать набор данных с именем sample_data_flights для построения диаграммы интенсивности движения. В нем мы рассматриваем переменные, названные страной отправления и страной назначения рейсов, и производим подсчет.
На главном экране Kibana мы находим имя опции «Визуализировать», которая позволяет нам создавать визуализацию и агрегирование на основе индексов, хранящихся в Elasticsearch. Мы решили добавить новую визуализацию и выбрать «Тепловая карта», как показано ниже & mimus;
Выберите метрики
На следующем экране нам предлагается выбрать метрики, которые будут использоваться при создании диаграммы тепловой карты. Здесь мы выбираем счетчик как тип показателя агрегирования. Затем для сегментов на оси Y мы выбираем Термины в качестве агрегирования для поля OriginCountry. Для оси X мы выбираем ту же агрегацию, но DestCountry в качестве поля, которое будет использоваться. В обоих случаях мы выбираем размер ведра 5.

При запуске показанной выше конфигурации мы получаем диаграмму тепловой карты, сгенерированную следующим образом.
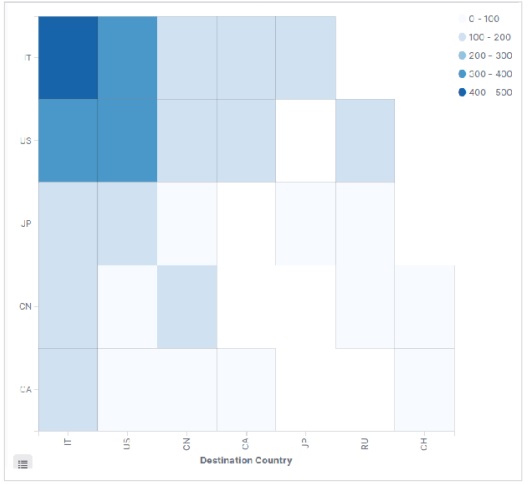
Note - Вы должны разрешить диапазон дат как «Этот год», чтобы на графике собирались данные за год для создания эффективной тепловой карты.
Приложение Canvas является частью Kibana, которая позволяет нам создавать динамические, многостраничные и точные по пикселям дисплеи данных. Его способность создавать инфографику, а не только диаграммы и метрики, делает его уникальным и привлекательным. В этой главе мы увидим различные особенности холста и то, как использовать рабочие панели холста.
Открытие холста
Перейдите на домашнюю страницу Kibana и выберите вариант, как показано на диаграмме ниже. Откроется список имеющихся у вас холстов. Мы выбрали отслеживание доходов от электронной торговли для нашего исследования.
Клонирование рабочей панели
Мы клонируем [eCommerce] Revenue Trackingрабочий стол, который будет использоваться в нашем исследовании. Чтобы клонировать его, мы выделяем строку с именем этой рабочей панели, а затем используем кнопку клонирования, как показано на схеме ниже -
В результате вышеупомянутого клона мы получим новую рабочую площадку с именем [eCommerce] Revenue Tracking – Copy который при открытии покажет следующую инфографику.
Он описывает общий объем продаж и выручку по категориям вместе с красивыми изображениями и диаграммами.
Модификация рабочей панели
Мы можем изменить стиль и фигуры на рабочем столе, используя параметры, доступные на вкладке справа. Здесь мы стремимся изменить цвет фона рабочей панели, выбрав другой цвет, как показано на схеме ниже. Выбор цвета вступает в силу немедленно, и мы получаем результат, как показано ниже -

Kibana также может помочь в визуализации данных журнала из различных источников. Журналы являются важными источниками анализа состояния инфраструктуры, требований к производительности и анализа нарушений безопасности и т. Д. Kibana может подключаться к различным журналам, таким как журналы веб-сервера, журналы эластичного поиска, журналы облачных наблюдений и т. Д.
Журналы Logstash
В Kibana мы можем подключаться к журналам logstash для визуализации. Сначала мы выбираем кнопку Журналы на главном экране Kibana, как показано ниже -
Затем мы выбираем опцию «Изменить конфигурацию источника», которая дает нам возможность выбрать Logstash в качестве источника. На приведенном ниже экране также показаны другие типы параметров, которые у нас есть в качестве источника журнала.
Вы можете выполнять потоковую передачу данных для хвоста журнала в реальном времени или приостановить потоковую передачу, чтобы сосредоточиться на данных журнала. При потоковой передаче журналов самый последний журнал отображается внизу консоли.
Для получения дополнительной информации вы можете обратиться к нашему руководству по Logstash .