Алгоритм KNN - поиск ближайших соседей
Введение
Алгоритм K-ближайших соседей (KNN) - это тип контролируемого алгоритма машинного обучения, который может использоваться как для классификации, так и для задач прогнозирования регрессии. Однако он в основном используется для задач прогнозирования классификации в промышленности. Следующие два свойства хорошо определяют KNN:
Lazy learning algorithm - KNN - это алгоритм ленивого обучения, потому что он не имеет специальной фазы обучения и использует все данные для обучения при классификации.
Non-parametric learning algorithm - KNN также является непараметрическим алгоритмом обучения, потому что он ничего не предполагает о базовых данных.
Работа алгоритма KNN
Алгоритм K-ближайших соседей (KNN) использует «сходство признаков» для прогнозирования значений новых точек данных, что дополнительно означает, что новой точке данных будет присвоено значение в зависимости от того, насколько близко она соответствует точкам в обучающем наборе. Мы можем понять его работу с помощью следующих шагов -
Step 1- Для реализации любого алгоритма нужен набор данных. Итак, на первом этапе KNN мы должны загрузить обучающие, а также тестовые данные.
Step 2- Далее нам нужно выбрать значение K, т.е. ближайшие точки данных. K может быть любым целым числом.
Step 3 - Для каждой точки в тестовых данных сделайте следующее -
3.1- Рассчитайте расстояние между тестовыми данными и каждой строкой обучающих данных с помощью любого метода, а именно: Евклидова, Манхэттенского или Хэммингового расстояния. Наиболее часто используемый метод расчета расстояния - евклидов.
3.2 - Теперь по значению расстояния отсортируйте их в порядке возрастания.
3.3 - Затем он выберет верхние K строк из отсортированного массива.
3.4 - Теперь он назначит класс контрольной точке на основе наиболее частого класса этих строк.
Step 4 - Конец
пример
Ниже приведен пример для понимания концепции K и работы алгоритма KNN.
Предположим, у нас есть набор данных, который можно построить следующим образом:
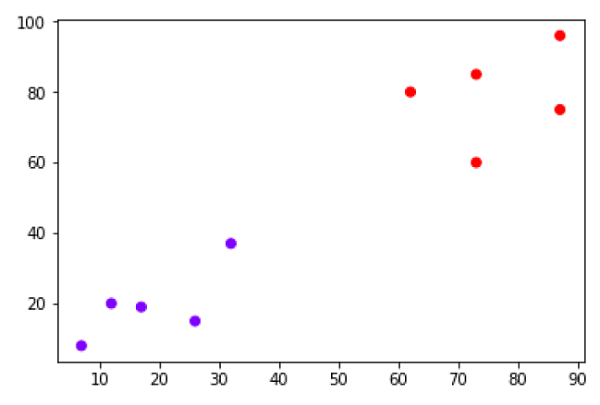
Теперь нам нужно классифицировать новую точку данных с черной точкой (в точке 60,60) на синий или красный класс. Мы предполагаем, что K = 3, т.е. он найдет три ближайших точки данных. Это показано на следующей диаграмме -

На приведенной выше диаграмме мы видим трех ближайших соседей точки данных, отмеченных черной точкой. Среди этих трех два из них относятся к красному классу, поэтому черная точка также будет присвоена красному классу.
Реализация на Python
Как мы знаем, алгоритм K-ближайших соседей (KNN) может использоваться как для классификации, так и для регрессии. Ниже приведены рецепты в Python для использования KNN в качестве классификатора, а также регрессора.
KNN как классификатор
Сначала начнем с импорта необходимых пакетов Python -
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdЗатем загрузите набор данных iris по его веб-ссылке следующим образом:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"Затем нам нужно назначить имена столбцов набору данных следующим образом:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']Теперь нам нужно прочитать набор данных в фреймворке pandas следующим образом:
dataset = pd.read_csv(path, names=headernames)
dataset.head()| слно. | длина чашелистика | ширина чашелистика | длина лепестка | ширина лепестка | Класс |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0,2 | Ирис-сетоса |
| 1 | 4.9 | 3.0 | 1.4 | 0,2 | Ирис-сетоса |
| 2 | 4,7 | 3.2 | 1.3 | 0,2 | Ирис-сетоса |
| 3 | 4.6 | 3.1 | 1.5 | 0,2 | Ирис-сетоса |
| 4 | 5.0 | 3,6 | 1.4 | 0,2 | Ирис-сетоса |
Предварительная обработка данных будет выполняться с помощью следующих строк скрипта -
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].valuesДалее мы разделим данные на тренировочную и тестовую. Следующий код разделит набор данных на 60% данных обучения и 40% данных тестирования.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40)Далее масштабирование данных будет выполнено следующим образом -
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Затем обучите модель с помощью класса sklearn KNeighborsClassifier следующим образом:
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=8)
classifier.fit(X_train, y_train)Наконец-то нам нужно сделать прогноз. Это можно сделать с помощью следующего скрипта -
y_pred = classifier.predict(X_test)Затем распечатайте результаты следующим образом -
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)Вывод
Confusion Matrix:
[[21 0 0]
[ 0 16 0]
[ 0 7 16]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 21
Iris-versicolor 0.70 1.00 0.82 16
Iris-virginica 1.00 0.70 0.82 23
micro avg 0.88 0.88 0.88 60
macro avg 0.90 0.90 0.88 60
weighted avg 0.92 0.88 0.88 60
Accuracy: 0.8833333333333333KNN как Регрессор
Во-первых, начните с импорта необходимых пакетов Python -
import numpy as np
import pandas as pdЗатем загрузите набор данных iris по его веб-ссылке следующим образом:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"Затем нам нужно назначить имена столбцов набору данных следующим образом:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']Теперь нам нужно прочитать набор данных в фреймворке pandas следующим образом:
data = pd.read_csv(url, names=headernames)
array = data.values
X = array[:,:2]
Y = array[:,2]
data.shape
output:(150, 5)Затем импортируйте KNeighborsRegressor из sklearn, чтобы соответствовать модели -
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=10)
knnr.fit(X, y)Наконец, мы можем найти MSE следующим образом -
print ("The MSE is:",format(np.power(y-knnr.predict(X),2).mean()))Вывод
The MSE is: 0.12226666666666669Плюсы и минусы KNN
Плюсы
Это очень простой алгоритм для понимания и интерпретации.
Это очень полезно для нелинейных данных, потому что в этом алгоритме нет предположений о данных.
Это универсальный алгоритм, поскольку мы можем использовать его как для классификации, так и для регрессии.
Он имеет относительно высокую точность, но существуют модели обучения с учителем лучше, чем KNN.
Минусы
В вычислительном отношении это немного затратный алгоритм, потому что он хранит все данные обучения.
Требуется большой объем памяти по сравнению с другими алгоритмами контролируемого обучения.
Прогнозирование медленное в случае большого N.
Он очень чувствителен к масштабу данных, а также к несущественным функциям.
Приложения KNN
Ниже приведены некоторые из областей, в которых KNN может успешно применяться:
Банковская система
KNN можно использовать в банковской системе для прогнозирования того, подходит ли физическое лицо для утверждения кредита? Есть ли у этого человека характеристики, аналогичные характеристикам неплательщика?
Расчет кредитных рейтингов
Алгоритмы KNN могут использоваться для определения кредитного рейтинга человека путем сравнения с людьми, имеющими аналогичные черты характера.
Политика
С помощью алгоритмов KNN мы можем разделить потенциального избирателя на различные классы, такие как «проголосует», «не проголосует», «проголосует за конгресс партии», «проголосует за партию« BJP ».
Другие области, в которых может использоваться алгоритм KNN, - это распознавание речи, обнаружение рукописного ввода, распознавание изображений и распознавание видео.