SAS - объединенные наборы данных
Несколько наборов данных SAS можно объединить в один набор данных с помощью SETзаявление. Общее количество наблюдений в объединенном наборе данных является суммой количества наблюдений в исходных наборах данных. Порядок наблюдений - последовательный. За всеми наблюдениями из первого набора данных следуют все наблюдения из второго набора данных и так далее.
В идеале все объединяемые наборы данных имеют одинаковые переменные, но если они имеют разное количество переменных, в результате появляются все переменные с пропущенными значениями для меньшего набора данных.
Синтаксис
Базовый синтаксис оператора SET в SAS -
SET data-set 1 data-set 2 data-set 3.....;Ниже приводится описание используемых параметров -
data-set1,data-set2 - имена наборов данных, записанные одно за другим.
пример
Рассмотрим данные о сотрудниках организации, которые доступны в двух разных наборах данных: один для ИТ-отдела, а другой для не-ИТ-отдела. Чтобы получить полную информацию обо всех сотрудниках, мы объединяем оба набора данных с помощью оператора SET, показанного ниже.
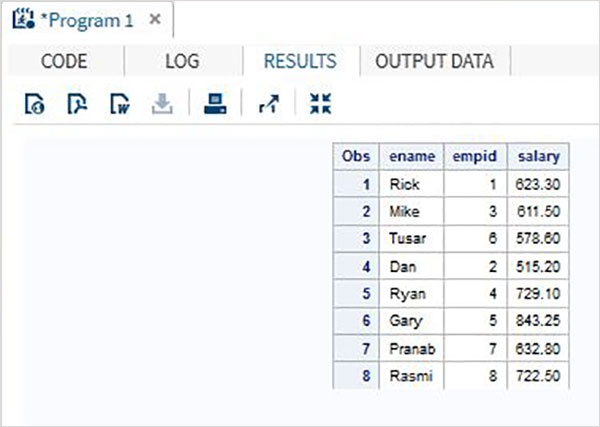
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Когда приведенный выше код выполняется, мы получаем следующий результат.
Сценарии
Когда у нас есть много вариаций в наборах данных для конкатенации, результат переменных может отличаться, но общее количество наблюдений в объединенном наборе данных всегда является суммой наблюдений в каждом наборе данных. Ниже мы рассмотрим многие сценарии этого варианта.
Различное количество переменных
Если один из исходных наборов данных имеет большее количество переменных, чем другой, тогда наборы данных все равно объединяются, но в меньшем наборе данных эти переменные отображаются как отсутствующие.
пример
В приведенном ниже примере первый набор данных имеет дополнительную переменную с именем DOJ. В результате значение DOJ для второго набора данных будет отображаться как отсутствующее.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Когда приведенный выше код выполняется, мы получаем следующий результат.

Другое имя переменной
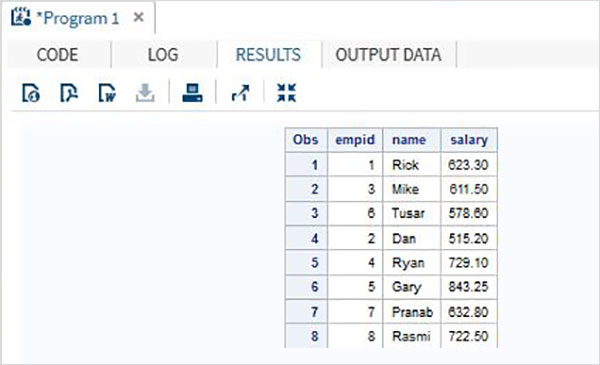
В этом сценарии наборы данных имеют одинаковое количество переменных, но имена переменных у них различаются. В этом случае обычная конкатенация произведет все переменные в наборе результатов и даст недостающие результаты для двух переменных, которые различаются. Хотя мы не можем изменять имя переменной в исходных наборах данных, мы можем применить функцию RENAME в объединенном наборе данных, который мы создаем. Это даст тот же результат, что и обычная конкатенация, но, конечно, с одним новым именем переменной вместо двух разных имен переменных, присутствующих в исходном наборе данных.
пример
В приведенном ниже примере набора данных ITDEPT имеет имя переменной ename тогда как набор данных NON_ITDEPT имеет имя переменной empname.Но обе эти переменные представляют один и тот же тип (символ). Мы применяемRENAME в операторе SET, как показано ниже.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Когда приведенный выше код выполняется, мы получаем следующий результат.
Различная переменная длина
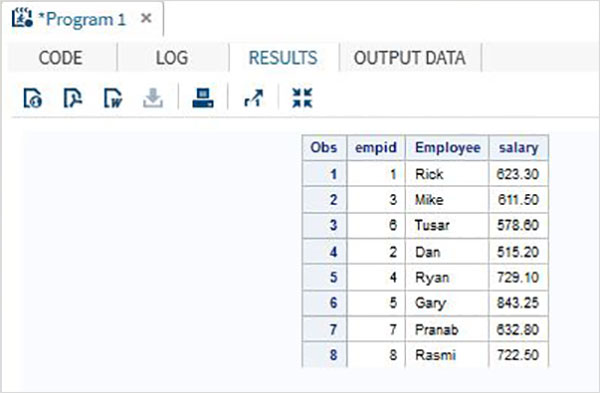
Если длина переменной в двух наборах данных отличается, чем объединенный набор данных будет иметь значения, в которых некоторые данные усечены для переменной меньшей длины. Это случается, если первый набор данных имеет меньшую длину. Чтобы решить эту проблему, мы применяем большую длину к обоим наборам данных, как показано ниже.
пример
В приведенном ниже примере переменная enameимеет длину 5 в первом наборе данных и 7 во втором. При объединении мы применяем оператор LENGTH в объединенном наборе данных, чтобы установить длину ename равной 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Когда приведенный выше код выполняется, мы получаем следующий результат.