SAS - Распределение частот
Частотное распределение - это таблица, показывающая частоту точек данных в наборе данных. Каждая запись в таблице содержит частоту или количество появлений значений в определенной группе или интервале, и, таким образом, таблица суммирует распределение значений в выборке.
SAS предоставляет процедуру, называемую PROC FREQ для расчета частотного распределения точек данных в наборе данных.
Синтаксис
Основной синтаксис для вычисления частотного распределения в SAS -
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;Ниже приводится описание используемых параметров -
Dataset это имя набора данных.
Variables_1 - это имена переменных набора данных, частотное распределение которых необходимо вычислить.
Variables_2 - переменные, которые классифицируют результат частотного распределения.
Распределение одной переменной частоты
Мы можем определить частотное распределение одной переменной, используя PROC FREQ.В этом случае результат покажет частоту каждого значения переменной. Результат также показывает процентное распределение, совокупную частоту и совокупный процент.
пример
В приведенном ниже примере мы находим частотное распределение переменной мощности для набора данных с именем CARS1 который создается из библиотеки SASHELP.CARS.Мы можем видеть результат, разделенный на две категории результатов. По одному на каждую марку автомобиля.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Когда приведенный выше код выполняется, мы получаем следующий результат -

Распределение множественных переменных частот
Мы можем найти частотные распределения для нескольких переменных, которые группируют их во все возможные комбинации.
пример
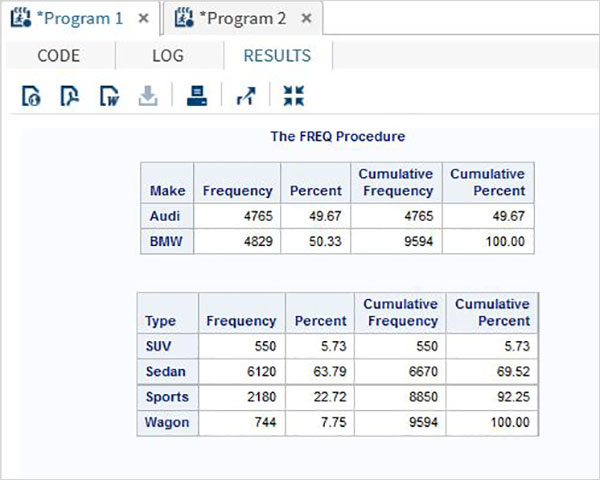
В приведенном ниже примере мы вычисляем частотное распределение для марки автомобиля для grouped by car type а также частотное распределение каждого типа авто grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Когда приведенный выше код выполняется, мы получаем следующий результат -
Распределение частот с учетом веса
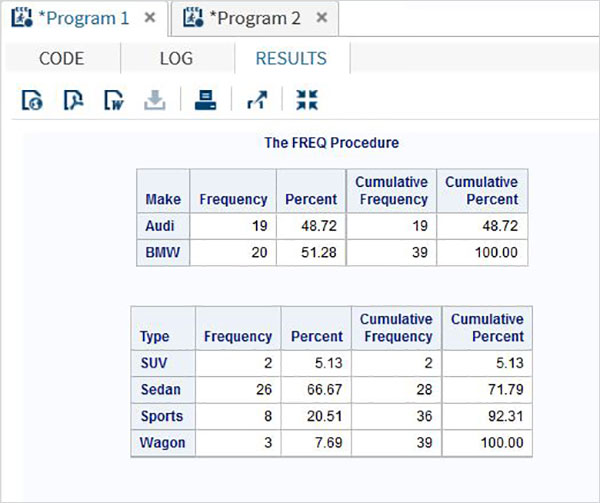
С помощью опции веса мы можем рассчитать частотное распределение с учетом веса переменной. Здесь значение переменной принимается как количество наблюдений, а не как количество значений.
пример
В приведенном ниже примере мы вычисляем частотное распределение производителей и типов переменных с весом, присвоенным лошадиным силам.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Когда приведенный выше код выполняется, мы получаем следующий результат -