Weka - Классификаторы
Многие приложения машинного обучения связаны с классификацией. Например, вы можете классифицировать опухоль как злокачественную или доброкачественную. Вы можете решить, играть ли во внешнюю игру, в зависимости от погодных условий. Как правило, это решение зависит от нескольких особенностей / условий погоды. Так что вы можете предпочесть использовать древовидный классификатор, чтобы принять решение, играть или нет.
В этой главе мы узнаем, как построить такой древовидный классификатор на основе данных о погоде, чтобы определить игровые условия.
Установка тестовых данных
Мы будем использовать предварительно обработанный файл данных о погоде из предыдущего урока. Откройте сохраненный файл, используяOpen file ... вариант под Preprocess вкладку, нажмите на Classify вкладка, и вы увидите следующий экран -
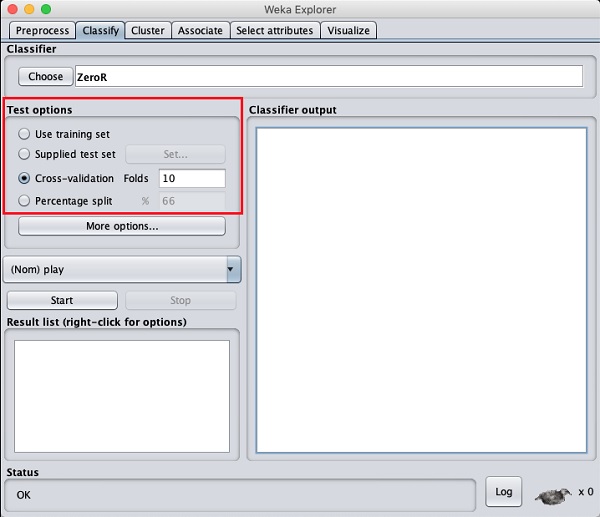
Прежде чем вы узнаете о доступных классификаторах, давайте рассмотрим варианты тестирования. Вы заметите четыре варианта тестирования, перечисленные ниже -
- Обучающий набор
- Поставляемый тестовый набор
- Cross-validation
- Процентное разделение
Если у вас нет собственного обучающего набора или набора тестов, предоставленного клиентом, вы должны использовать варианты перекрестной проверки или процентного разделения. При перекрестной проверке вы можете установить количество складок, в которых все данные будут разделены и использованы на каждой итерации обучения. В процентном разбиении вы разделите данные между обучением и тестированием, используя установленный процент разделения.
Теперь оставьте значение по умолчанию play вариант для выходного класса -
Далее вы выберете классификатор.
Выбор классификатора
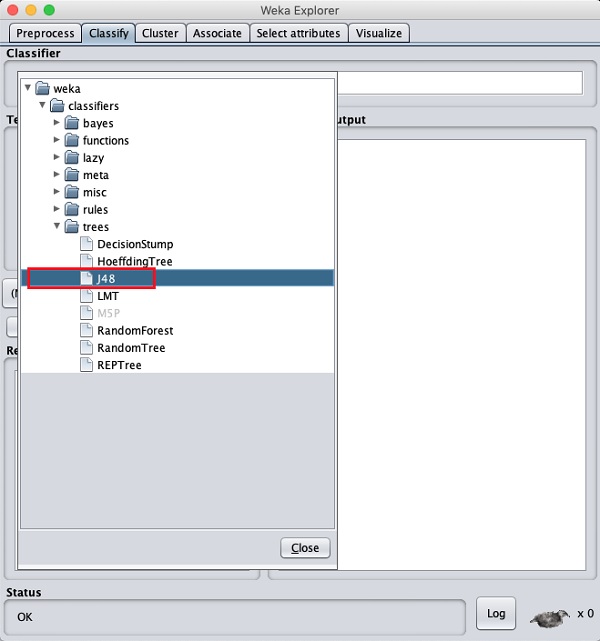
Нажмите кнопку Выбрать и выберите следующий классификатор -
weka→classifiers>trees>J48
Это показано на скриншоте ниже -
Нажми на Startкнопку, чтобы начать процесс классификации. Через некоторое время результаты классификации будут представлены на вашем экране, как показано здесь -
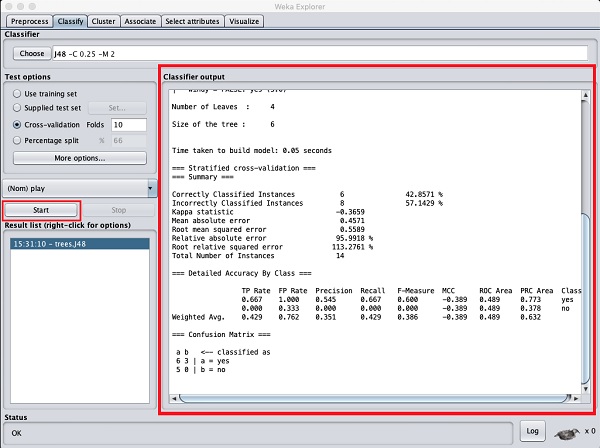
Давайте рассмотрим вывод, показанный в правой части экрана.
В нем говорится, что размер дерева равен 6. Вскоре вы увидите визуальное представление дерева. В Сводке говорится, что правильно классифицированные экземпляры как 2, а неправильно классифицированные экземпляры как 3, также говорят, что относительная абсолютная ошибка составляет 110%. Он также показывает матрицу неточностей. Анализ этих результатов выходит за рамки данного руководства. Тем не менее, вы можете легко понять из этих результатов, что классификация неприемлема, и вам потребуется больше данных для анализа, чтобы уточнить выбор ваших функций, перестроить модель и так далее, пока вы не будете удовлетворены точностью модели. Во всяком случае, в этом вся суть WEKA. Это позволяет быстро проверить свои идеи.
Визуализировать результаты
Чтобы увидеть визуальное представление результатов, щелкните правой кнопкой мыши результат в Result listкоробка. На экране появятся несколько вариантов, как показано здесь -
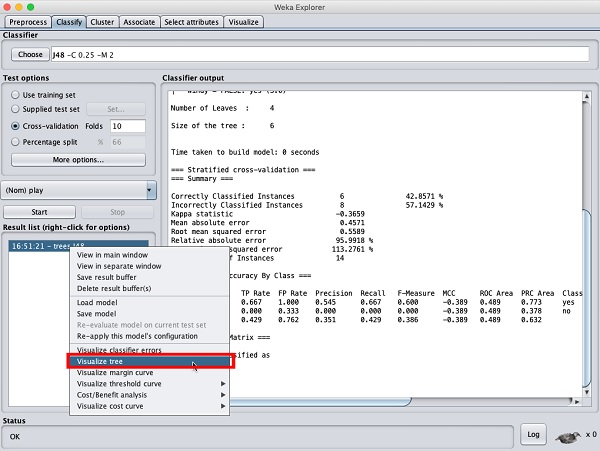
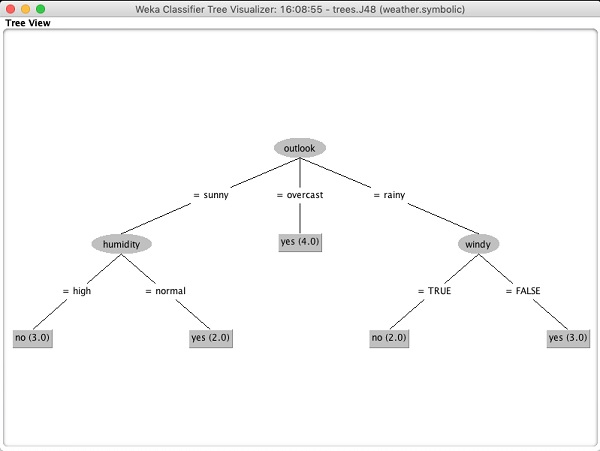
Выбрать Visualize tree чтобы получить визуальное представление дерева обхода, как показано на скриншоте ниже -
Выбор Visualize classifier errors построит результаты классификации, как показано здесь -
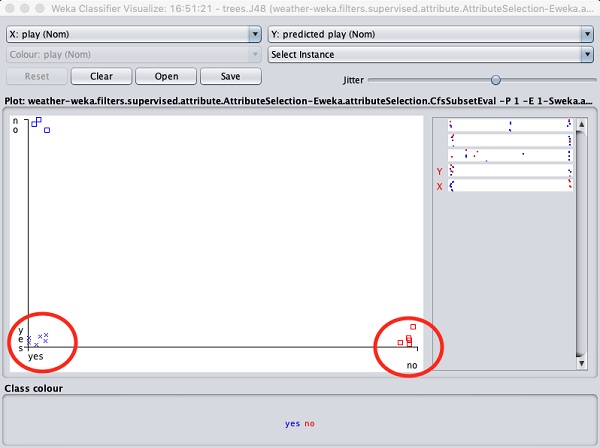
А cross представляет собой правильно классифицированный экземпляр, в то время как squaresпредставляет собой неправильно классифицированные экземпляры. В нижнем левом углу графика вы видите значокcross это указывает, если outlook тогда солнечно playигра. Так что это правильно классифицированный экземпляр. Чтобы найти экземпляры, вы можете внести в него некоторый джиттер, сдвинувjitter ползунок.
Текущий сюжет outlook против play. Они обозначены двумя выпадающими списками в верхней части экрана.
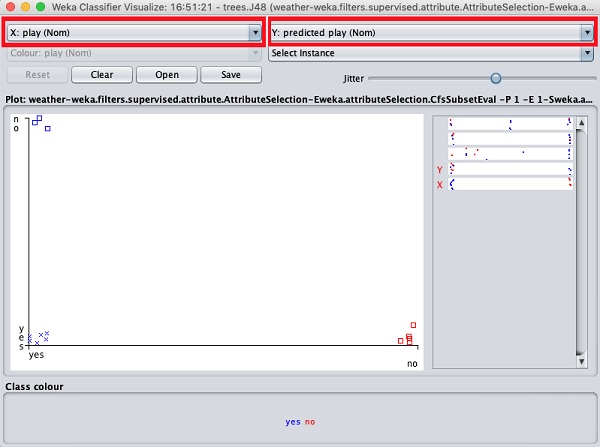
Теперь попробуйте другой выбор в каждом из этих полей и обратите внимание, как меняются оси X и Y. То же самое можно сделать, используя горизонтальные полосы в правой части участка. Каждая полоса представляет собой атрибут. Щелчок левой кнопкой мыши по полосе устанавливает выбранный атрибут по оси X, а щелчок правой кнопкой мыши устанавливает его по оси Y.
Для более глубокого анализа предусмотрено несколько других графиков. Используйте их с умом для точной настройки вашей модели. Один такой сюжетCost/Benefit analysis показан ниже для быстрого ознакомления.
Объяснение анализа на этих диаграммах выходит за рамки этого руководства. Читателю предлагается освежить свои знания в области анализа алгоритмов машинного обучения.
В следующей главе мы изучим следующий набор алгоритмов машинного обучения, то есть кластеризацию.