Weka - Краткое руководство
В основе любого приложения машинного обучения лежат данные - не просто небольшие данные, а огромные данные, которые называются Big Data в текущей терминологии.
Чтобы научить машину анализировать большие данные, вам нужно учитывать несколько факторов:
- Данные должны быть чистыми.
- Он не должен содержать нулевых значений.
Кроме того, не все столбцы в таблице данных будут полезны для того типа аналитики, которого вы пытаетесь достичь. Нерелевантные столбцы данных или «функции», как они называются в терминологии машинного обучения, должны быть удалены до того, как данные будут загружены в алгоритм машинного обучения.
Короче говоря, ваши большие данные нуждаются в большой предварительной обработке, прежде чем их можно будет использовать для машинного обучения. Когда данные будут готовы, вы примените различные алгоритмы машинного обучения, такие как классификация, регрессия, кластеризация и т. Д., Чтобы решить проблему со своей стороны.
Тип применяемых вами алгоритмов во многом зависит от ваших знаний в предметной области. Даже в рамках одного типа, например классификации, доступно несколько алгоритмов. Вы можете протестировать разные алгоритмы в одном классе, чтобы построить эффективную модель машинного обучения. При этом вы предпочитаете визуализацию обработанных данных и, следовательно, вам также потребуются инструменты визуализации.
В следующих главах вы узнаете о Weka, программном обеспечении, которое легко выполняет все вышеперечисленное и позволяет комфортно работать с большими данными.
WEKA - программное обеспечение с открытым исходным кодом, которое предоставляет инструменты для предварительной обработки данных, реализации нескольких алгоритмов машинного обучения и инструментов визуализации, чтобы вы могли разрабатывать методы машинного обучения и применять их к реальным задачам интеллектуального анализа данных. То, что предлагает WEKA, суммировано на следующей диаграмме -
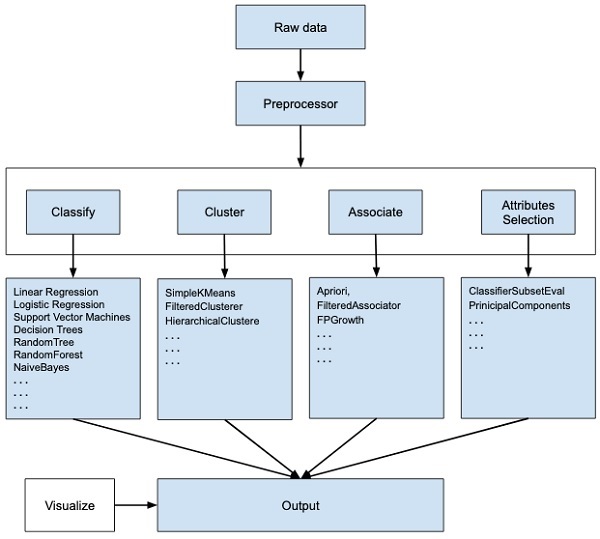
Если вы заметите начало потока изображения, вы поймете, что есть много этапов в работе с большими данными, чтобы сделать их подходящими для машинного обучения -
Сначала вы начнете с необработанных данных, собранных с поля. Эти данные могут содержать несколько нулевых значений и нерелевантных полей. Вы используете инструменты предварительной обработки данных, представленные в WEKA, для очистки данных.
Затем вы сохраните предварительно обработанные данные в локальном хранилище для применения алгоритмов машинного обучения.
Затем, в зависимости от типа модели машинного обучения, которую вы пытаетесь разработать, вы должны выбрать один из вариантов, например Classify, Cluster, или же Associate. ВAttributes Selection позволяет автоматически выбирать объекты для создания сокращенного набора данных.
Обратите внимание, что в каждой категории WEKA предлагает реализацию нескольких алгоритмов. Вы должны выбрать алгоритм по вашему выбору, установить желаемые параметры и запустить его для набора данных.
Затем WEKA предоставит вам статистический результат обработки модели. Он предоставляет вам инструмент визуализации для проверки данных.
К одному и тому же набору данных можно применять разные модели. Затем вы можете сравнить результаты различных моделей и выбрать лучшую, соответствующую вашим целям.
Таким образом, использование WEKA приводит к более быстрой разработке моделей машинного обучения в целом.
Теперь, когда мы узнали, что такое WEKA и что она делает, в следующей главе мы узнаем, как установить WEKA на локальный компьютер.
Чтобы установить WEKA на свой компьютер, посетите официальный сайт WEKA и загрузите установочный файл. WEKA поддерживает установку в Windows, Mac OS X и Linux. Вам просто нужно следовать инструкциям на этой странице, чтобы установить WEKA для вашей ОС.
Шаги для установки на Mac следующие:
- Загрузите установочный файл Mac.
- Дважды щелкните загруженный weka-3-8-3-corretto-jvm.dmg file.
После успешной установки вы увидите следующий экран.
- Нажми на weak-3-8-3-corretto-jvm значок для запуска Weka.
- При желании вы можете запустить его из командной строки -
java -jar weka.jarПриложение WEKA GUI Chooser запустится, и вы увидите следующий экран -
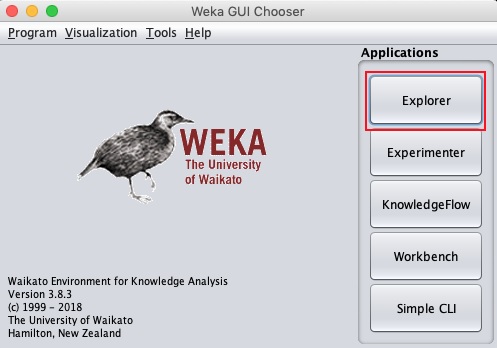
Приложение GUI Chooser позволяет запускать пять различных типов приложений, перечисленных здесь:
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- Простой интерфейс командной строки
Мы будем использовать Explorer в этом руководстве.
В этой главе давайте рассмотрим различные функции, которые предоставляет проводник для работы с большими данными.
Когда вы нажимаете на Explorer кнопка в Applications селектор, он открывает следующий экран -
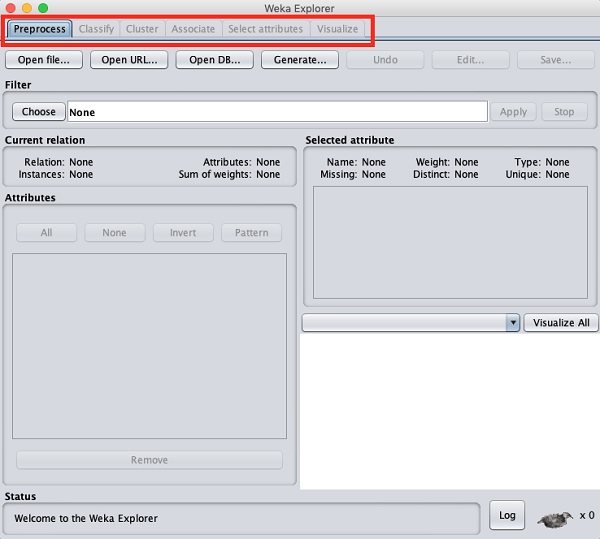
Вверху вы увидите несколько вкладок, перечисленных здесь -
- Preprocess
- Classify
- Cluster
- Associate
- Выберите атрибуты
- Visualize
На этих вкладках есть несколько предварительно реализованных алгоритмов машинного обучения. Давайте теперь подробно рассмотрим каждый из них.
Вкладка Preprocess
Первоначально, когда вы открываете проводник, только PreprocessВкладка включена. Первый шаг в машинном обучении - это предварительная обработка данных. Таким образом, вPreprocess В этом случае вы выберете файл данных, обработаете его и сделаете пригодным для применения различных алгоритмов машинного обучения.
Вкладка "Классификация"
В ClassifyВкладка предоставляет вам несколько алгоритмов машинного обучения для классификации ваших данных. Чтобы перечислить несколько, вы можете применить такие алгоритмы, как линейная регрессия, логистическая регрессия, машины опорных векторов, деревья решений, RandomTree, RandomForest, NaiveBayes и т. Д. Список очень исчерпывающий и содержит как контролируемые, так и неконтролируемые алгоритмы машинного обучения.
Вкладка кластера
Под Cluster На вкладке представлено несколько алгоритмов кластеризации, таких как SimpleKMeans, FilteredClusterer, HierarchicalClusterer и т. д.
Связанная вкладка
Под Associate На вкладке вы найдете Apriori, FilteredAssociator и FPGrowth.
Выберите вкладку атрибутов
Select Attributes позволяет вам выбирать функции на основе нескольких алгоритмов, таких как ClassifierSubsetEval, PrinicipalComponents и т. д.
Вкладка "Визуализация"
Наконец, Visualize опция позволяет визуализировать обработанные данные для анализа.
Как вы заметили, WEKA предоставляет несколько готовых алгоритмов для тестирования и создания приложений машинного обучения. Чтобы использовать WEKA эффективно, вы должны хорошо знать эти алгоритмы, то, как они работают, какой из них выбрать при каких обстоятельствах, что искать в их обработанных выводах и т. Д. Короче говоря, у вас должен быть прочный фундамент в области машинного обучения, чтобы эффективно использовать WEKA при создании своих приложений.
В следующих главах вы подробно изучите каждую вкладку в проводнике.
В этой главе мы начнем с первой вкладки, которую вы используете для предварительной обработки данных. Это общее для всех алгоритмов, которые вы применили бы к своим данным для построения модели, и является общим шагом для всех последующих операций в WEKA.
Чтобы алгоритм машинного обучения давал приемлемую точность, важно, чтобы вы сначала очистили свои данные. Это связано с тем, что необработанные данные, собранные из поля, могут содержать нулевые значения, нерелевантные столбцы и так далее.
В этой главе вы узнаете, как предварительно обработать необработанные данные и создать чистый, содержательный набор данных для дальнейшего использования.
Сначала вы научитесь загружать файл данных в проводник WEKA. Данные могут быть загружены из следующих источников -
- Локальная файловая система
- Web
- Database
В этой главе мы подробно рассмотрим все три варианта загрузки данных.
Загрузка данных из локальной файловой системы
Сразу под вкладками машинного обучения, которые вы изучали на предыдущем уроке, вы найдете следующие три кнопки:
- Открыть файл …
- Открыть URL…
- Открыть БД…
Нажми на Open file... кнопка. Откроется окно навигатора каталогов, как показано на следующем экране -
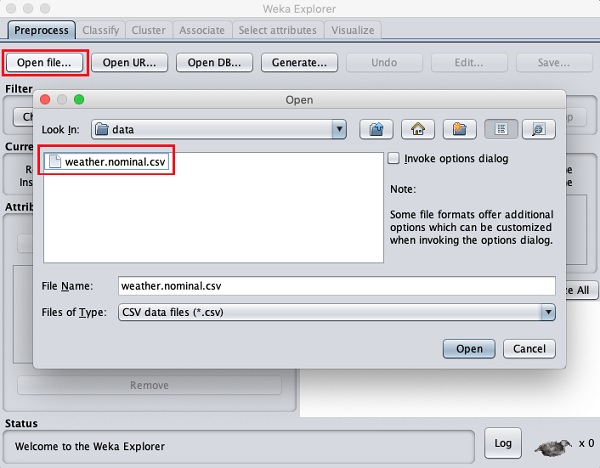
Теперь перейдите в папку, в которой хранятся ваши файлы данных. Установка WEKA включает в себя множество примеров баз данных для экспериментов. Они доступны вdata папка установки WEKA.
Для обучения выберите любой файл данных из этой папки. Содержимое файла будет загружено в среду WEKA. Очень скоро мы узнаем, как проверять и обрабатывать эти загруженные данные. Перед этим давайте посмотрим, как загрузить файл данных из Интернета.
Загрузка данных из Интернета
Как только вы нажмете на Open URL … кнопку, вы можете увидеть следующее окно -
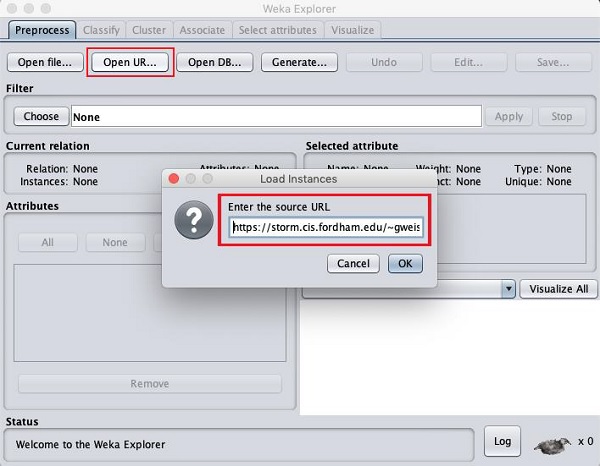
Мы откроем файл с общедоступного URL-адреса. Введите следующий URL-адрес во всплывающем окне -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
Вы можете указать любой другой URL, где хранятся ваши данные. ВExplorer загрузит данные с удаленного сайта в свою среду.
Загрузка данных из БД
Как только вы нажмете на Open DB ..., вы можете увидеть следующее окно -
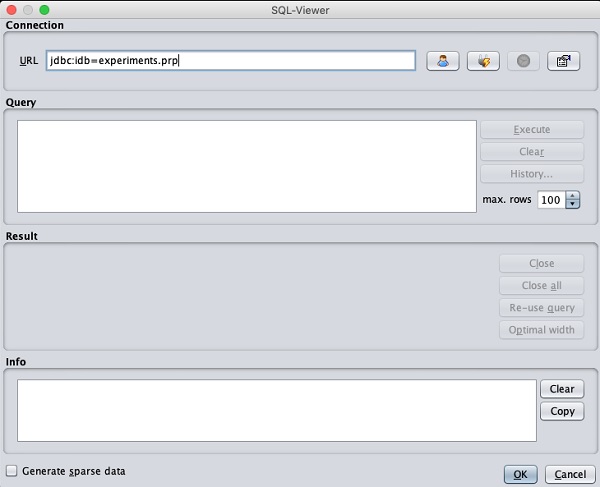
Установите строку подключения к своей базе данных, настройте запрос на выбор данных, обработайте запрос и загрузите выбранные записи в WEKA.
WEKA поддерживает большое количество файловых форматов данных. Вот полный список -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
Типы файлов, которые он поддерживает, перечислены в раскрывающемся списке в нижней части экрана. Это показано на скриншоте ниже.
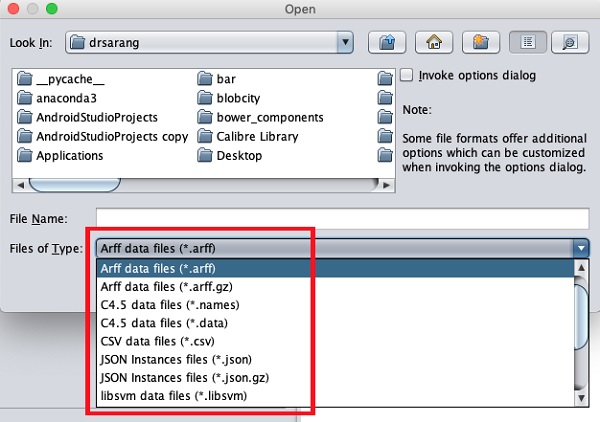
Как вы могли заметить, он поддерживает несколько форматов, включая CSV и JSON. Тип файла по умолчанию - Arff.
Формат Arff
An Arff Файл содержит два раздела - заголовок и данные.
- Заголовок описывает типы атрибутов.
- Раздел данных содержит список данных, разделенных запятыми.
В качестве примера для формата Arff Weather файл данных, загруженный из образцов баз данных WEKA, показан ниже -

Из скриншота вы можете сделать следующие выводы:
Тег @relation определяет имя базы данных.
Тег @attribute определяет атрибуты.
Тег @data запускает список строк данных, каждая из которых содержит поля, разделенные запятыми.
Атрибуты могут принимать номинальные значения, как в случае перспективы, показанной здесь -
@attribute outlook (sunny, overcast, rainy)Атрибуты могут принимать реальные значения, как в этом случае -
@attribute temperature realВы также можете установить переменную Target или Class с именем play, как показано здесь -
@attribute play (yes, no)Цель принимает два номинальных значения: да или нет.
Другие форматы
Проводник может загружать данные в любом из ранее упомянутых форматов. Поскольку arff является предпочтительным форматом в WEKA, вы можете загружать данные из любого формата и сохранять их в формате arff для дальнейшего использования. После предварительной обработки данных просто сохраните их в формате arff для дальнейшего анализа.
Теперь, когда вы узнали, как загружать данные в WEKA, в следующей главе вы узнаете, как предварительно обработать данные.
Данные, собранные с мест, содержат много нежелательного, что приводит к неправильному анализу. Например, данные могут содержать пустые поля, могут содержать столбцы, не относящиеся к текущему анализу, и так далее. Таким образом, данные должны быть предварительно обработаны, чтобы соответствовать требованиям того типа анализа, который вы ищете. Это делается в модуле предварительной обработки.
Чтобы продемонстрировать доступные функции предварительной обработки, мы будем использовать Weather база данных, которая предоставляется в установке.
Используя Open file ... вариант под Preprocess тег выберите weather-nominal.arff файл.
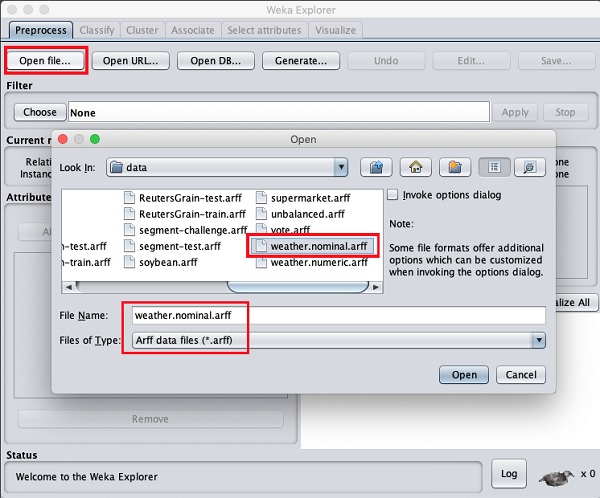
Когда вы открываете файл, ваш экран выглядит так, как показано здесь -
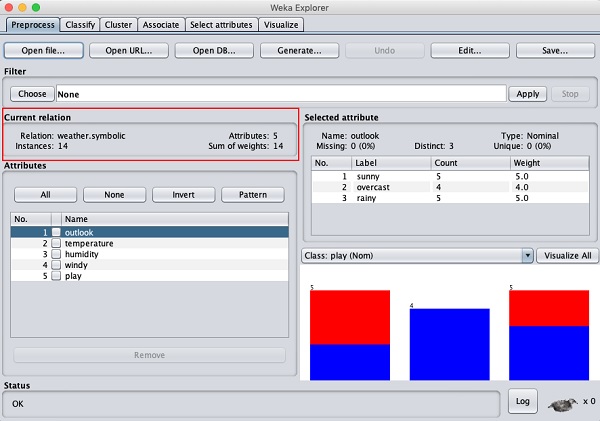
Этот экран сообщает нам несколько вещей о загруженных данных, которые обсуждаются далее в этой главе.
Понимание данных
Давайте сначала посмотрим на выделенные Current relationдополнительное окно. Он показывает имя загруженной в данный момент базы данных. Из этого подокна вы можете сделать два вывода:
Всего 14 экземпляров - количество строк в таблице.
В таблице 5 атрибутов - поля, о которых пойдет речь в следующих разделах.
С левой стороны обратите внимание на Attributes дополнительное окно, в котором отображаются различные поля в базе данных.
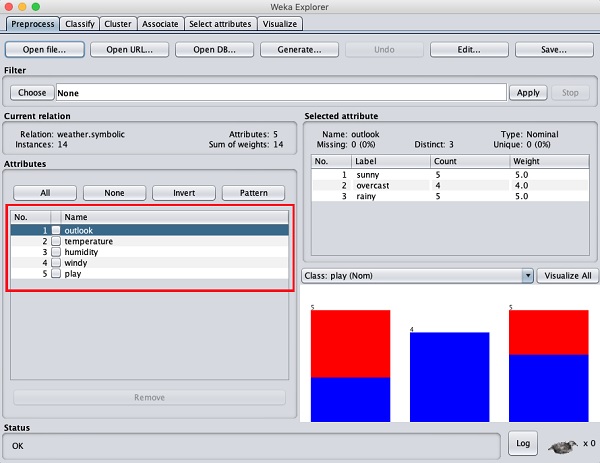
В weatherБаза данных содержит пять полей - внешний вид, температура, влажность, ветрено и игра. Когда вы выбираете атрибут из этого списка, щелкнув по нему, дополнительные сведения о самом атрибуте отображаются справа.
Давайте сначала выберем атрибут температуры. Когда вы нажмете на него, вы увидите следующий экран -
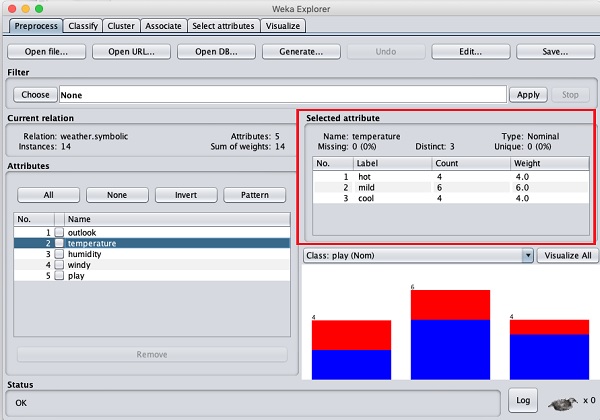
в Selected Attribute подокно, вы можете наблюдать следующее -
Отображаются имя и тип атрибута.
Тип для temperature атрибут Nominal.
Номер Missing значения равно нулю.
Есть три различных значения без уникального значения.
В таблице под этой информацией указаны номинальные значения для этого поля: горячее, умеренное и холодное.
Он также показывает количество и вес в процентах для каждого номинального значения.
Внизу окна вы видите визуальное представление class значения.
Если вы нажмете на Visualize All кнопку, вы сможете увидеть все функции в одном окне, как показано здесь -
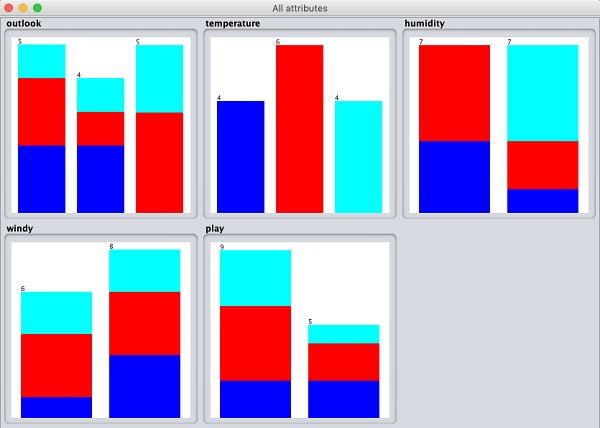
Удаление атрибутов
Часто данные, которые вы хотите использовать для построения модели, содержат множество нерелевантных полей. Например, база данных клиентов может содержать номер его мобильного телефона, который важен для анализа его кредитного рейтинга.
Чтобы удалить атрибут / ы, выберите их и нажмите Remove кнопку внизу.
Выбранные атрибуты будут удалены из базы данных. После полной предварительной обработки данных вы можете сохранить их для построения модели.
Далее вы научитесь предварительно обрабатывать данные, применяя фильтры к этим данным.
Применение фильтров
Некоторые методы машинного обучения, такие как интеллектуальный анализ ассоциативных правил, требуют категориальных данных. Чтобы проиллюстрировать использование фильтров, мы будем использоватьweather-numeric.arff база данных, содержащая два numeric атрибуты - temperature и humidity.
Мы преобразуем их в nominalприменяя фильтр к нашим необработанным данным. Нажми наChoose кнопка в Filter подокно и выберите следующий фильтр -
weka→filters→supervised→attribute→Discretize

Нажми на Apply кнопку и изучите temperature и / или humidityатрибут. Вы заметите, что они изменились с числовых на номинальные.
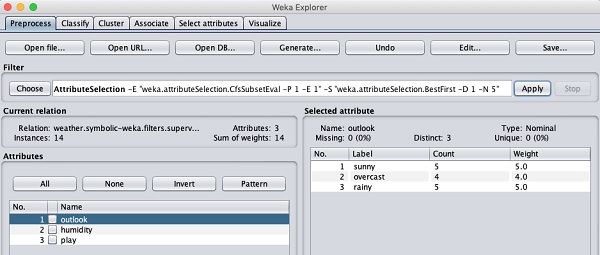
Давайте теперь рассмотрим другой фильтр. Предположим, вы хотите выбрать лучшие атрибуты для определенияplay. Выберите и примените следующий фильтр -
weka→filters→supervised→attribute→AttributeSelection
Вы заметите, что он удаляет атрибуты температуры и влажности из базы данных.
После того, как вы будете удовлетворены предварительной обработкой ваших данных, сохраните данные, нажав кнопку Save... кнопка. Вы будете использовать этот сохраненный файл для построения модели.
В следующей главе мы исследуем построение модели с использованием нескольких предопределенных алгоритмов машинного обучения.
Многие приложения машинного обучения связаны с классификацией. Например, вы можете классифицировать опухоль как злокачественную или доброкачественную. Вы можете решить, играть ли во внешнюю игру, в зависимости от погодных условий. Как правило, это решение зависит от нескольких особенностей / условий погоды. Так что вы можете предпочесть использовать древовидный классификатор, чтобы принять решение, играть или нет.
В этой главе мы узнаем, как построить такой древовидный классификатор на основе данных о погоде, чтобы определить игровые условия.
Установка тестовых данных
Мы будем использовать предварительно обработанный файл данных о погоде из предыдущего урока. Откройте сохраненный файл, используяOpen file ... вариант под Preprocess вкладку, нажмите на Classify вкладка, и вы увидите следующий экран -
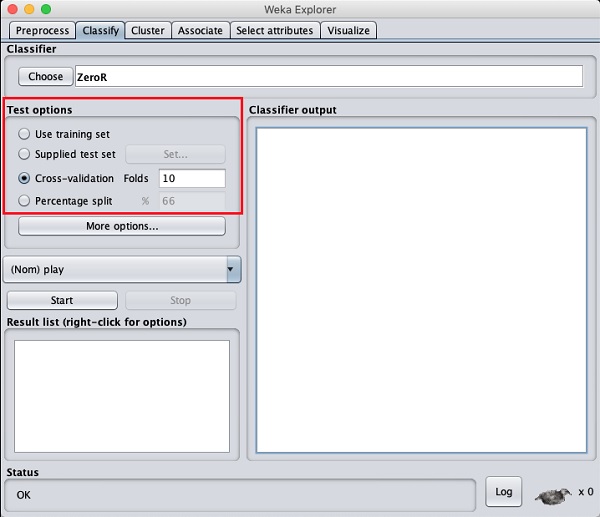
Прежде чем вы узнаете о доступных классификаторах, давайте рассмотрим варианты тестирования. Вы заметите четыре варианта тестирования, перечисленные ниже -
- Обучающий набор
- Поставляемый тестовый набор
- Cross-validation
- Процентное разделение
Если у вас нет собственного обучающего набора или набора тестов, предоставленного клиентом, вы должны использовать варианты перекрестной проверки или процентного разделения. При перекрестной проверке вы можете установить количество складок, в которых все данные будут разделены и использованы на каждой итерации обучения. В процентном разбиении вы разделите данные между обучением и тестированием, используя установленный процент разделения.
Теперь оставьте значение по умолчанию play вариант для выходного класса -
Далее вы выберете классификатор.
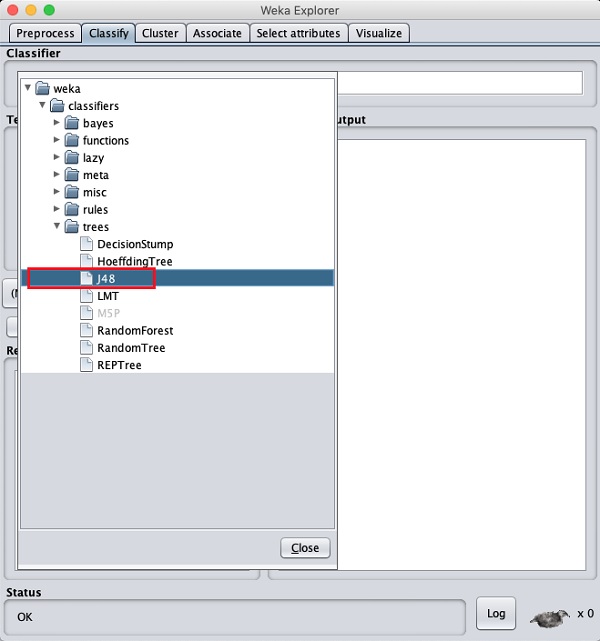
Выбор классификатора
Нажмите кнопку Выбрать и выберите следующий классификатор -
weka→classifiers>trees>J48
Это показано на скриншоте ниже -
Нажми на Startкнопку, чтобы начать процесс классификации. Через некоторое время результаты классификации будут представлены на вашем экране, как показано здесь -
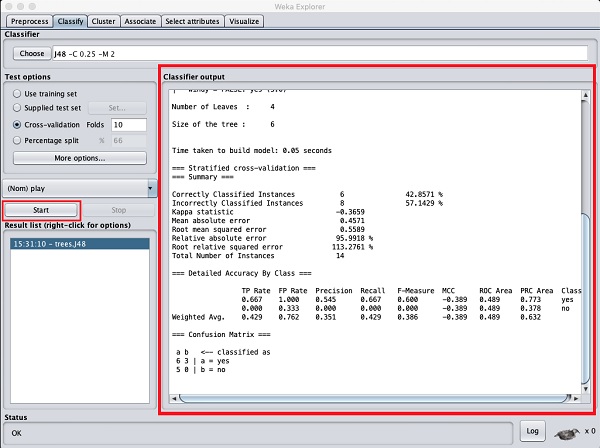
Давайте рассмотрим вывод, показанный в правой части экрана.
В нем говорится, что размер дерева равен 6. Вскоре вы увидите визуальное представление дерева. В Сводке говорится, что правильно классифицированные экземпляры как 2, а неправильно классифицированные экземпляры как 3, также говорят, что относительная абсолютная ошибка составляет 110%. Он также показывает матрицу неточностей. Анализ этих результатов выходит за рамки данного руководства. Тем не менее, вы можете легко понять из этих результатов, что классификация неприемлема, и вам потребуется больше данных для анализа, чтобы уточнить выбор ваших функций, перестроить модель и так далее, пока вы не будете удовлетворены точностью модели. Во всяком случае, в этом вся суть WEKA. Это позволяет быстро проверить свои идеи.
Визуализировать результаты
Чтобы увидеть визуальное представление результатов, щелкните правой кнопкой мыши результат в Result listкоробка. На экране появятся несколько вариантов, как показано здесь -
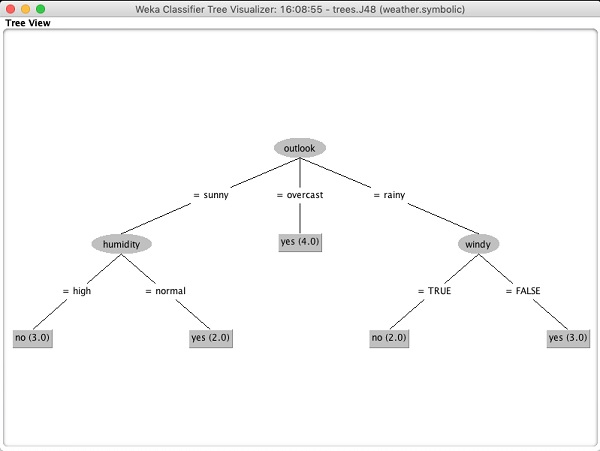
Выбрать Visualize tree чтобы получить визуальное представление дерева обхода, как показано на скриншоте ниже -
Выбор Visualize classifier errors построит результаты классификации, как показано здесь -
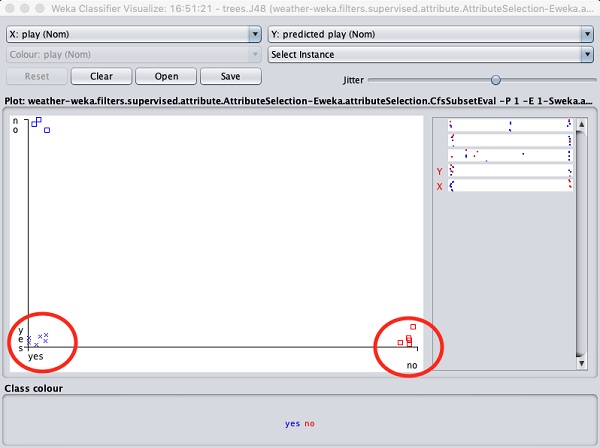
А cross представляет собой правильно классифицированный экземпляр, в то время как squaresпредставляет собой неправильно классифицированные экземпляры. В нижнем левом углу графика вы видите значокcross это указывает, если outlook тогда солнечно playигра. Так что это правильно классифицированный экземпляр. Чтобы найти экземпляры, вы можете внести в него некоторый джиттер, сдвинувjitter ползунок.
Текущий сюжет outlook против play. Они обозначены двумя выпадающими списками в верхней части экрана.
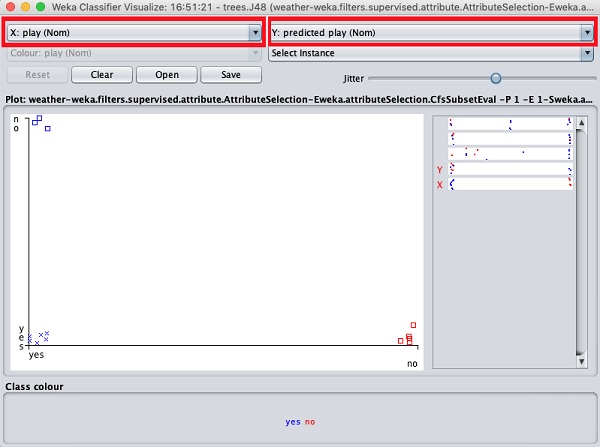
Теперь попробуйте другой выбор в каждом из этих полей и обратите внимание, как меняются оси X и Y. То же самое можно сделать, используя горизонтальные полосы в правой части участка. Каждая полоса представляет собой атрибут. Щелчок левой кнопкой мыши по полосе устанавливает выбранный атрибут по оси X, а щелчок правой кнопкой мыши устанавливает его по оси Y.
Для более глубокого анализа предусмотрено несколько других графиков. Используйте их с умом для точной настройки вашей модели. Один такой сюжетCost/Benefit analysis показан ниже для быстрого ознакомления.
Объяснение анализа на этих диаграммах выходит за рамки этого руководства. Читателю предлагается освежить свои знания в области анализа алгоритмов машинного обучения.
В следующей главе мы изучим следующий набор алгоритмов машинного обучения, то есть кластеризацию.
Алгоритм кластеризации находит группы похожих экземпляров во всем наборе данных. WEKA поддерживает несколько алгоритмов кластеризации, таких как EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans и т. Д. Вы должны полностью понимать эти алгоритмы, чтобы полностью использовать возможности WEKA.
Как и в случае классификации, WEKA позволяет визуализировать обнаруженные кластеры графически. Чтобы продемонстрировать кластеризацию, мы будем использовать предоставленную базу данных iris. Набор данных содержит три класса по 50 экземпляров в каждом. Каждый класс относится к типу ириса.
Загрузка данных
В проводнике WEKA выберите Preprocessтаб. Нажми наOpen file ... и выберите iris.arffфайл в диалоговом окне выбора файла. Когда вы загружаете данные, экран выглядит так, как показано ниже -
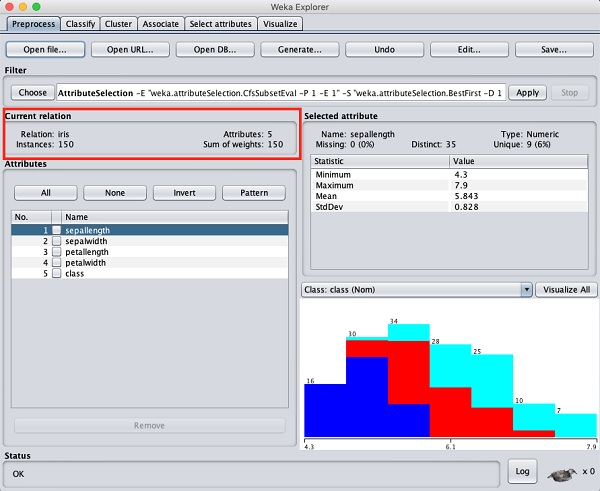
Вы можете заметить, что существует 150 экземпляров и 5 атрибутов. Имена атрибутов перечислены какsepallength, sepalwidth, petallength, petalwidth и class. Первые четыре атрибута относятся к числовому типу, а класс - к номинальному типу с 3 различными значениями. Изучите каждый атрибут, чтобы понять особенности базы данных. Мы не будем проводить предварительную обработку этих данных и сразу приступим к построению модели.
Кластеризация
Нажми на ClusterTAB, чтобы применить алгоритмы кластеризации к нашим загруженным данным. Нажми наChooseкнопка. Вы увидите следующий экран -

Теперь выберите EMкак алгоритм кластеризации. вCluster mode дополнительное окно, выберите Classes to clusters evaluation вариант, как показано на скриншоте ниже -

Нажми на Startкнопку для обработки данных. Через некоторое время результаты будут представлены на экране.
Далее изучим результаты.
Изучение вывода
Результат обработки данных показан на экране ниже -
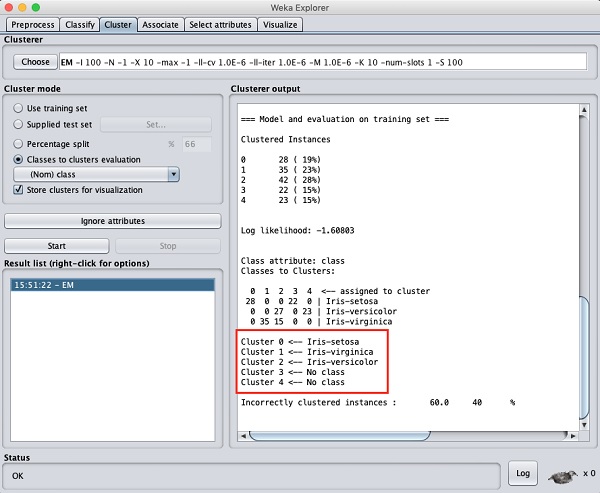
На экране вывода вы можете увидеть, что -
В базе данных обнаружено 5 кластерных экземпляров.
В Cluster 0 представляет сетоса, Cluster 1 представляет вирджинику, Cluster 2 представляет собой разноцветный, в то время как последние два кластера не имеют связанных с ними классов.
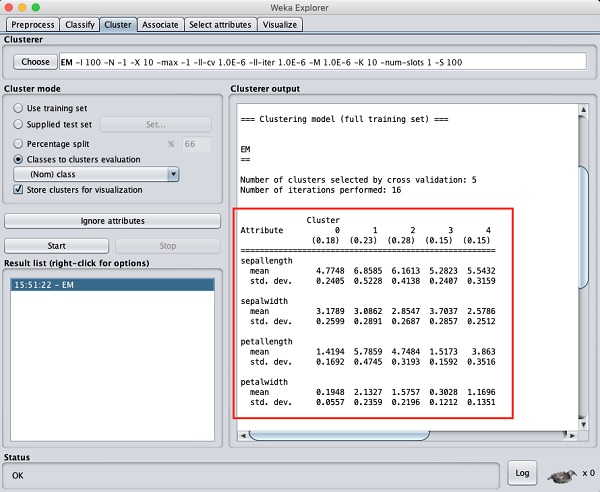
Если вы прокрутите окно вывода вверх, вы также увидите некоторую статистику, которая дает среднее значение и стандартное отклонение для каждого из атрибутов в различных обнаруженных кластерах. Это показано на скриншоте ниже -
Далее мы рассмотрим визуальное представление кластеров.
Визуализация кластеров
Чтобы визуализировать кластеры, щелкните правой кнопкой мыши на EM в результате Result list. Вы увидите следующие варианты -
Выбрать Visualize cluster assignments. Вы увидите следующий вывод -
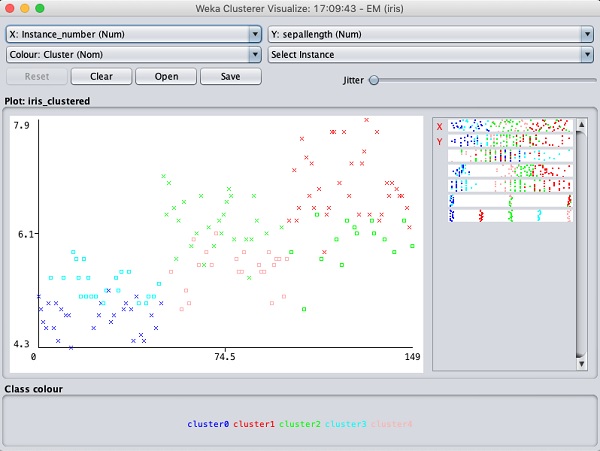
Как и в случае с классификацией, вы заметите различие между правильно и неправильно идентифицированными экземплярами. Вы можете поиграть, изменив оси X и Y, чтобы проанализировать результаты. Вы можете использовать дрожание, как и в случае классификации, чтобы узнать концентрацию правильно идентифицированных экземпляров. Операции на графике визуализации аналогичны тем, которые вы изучали в случае классификации.
Применение иерархического кластера
Чтобы продемонстрировать мощь WEKA, давайте теперь рассмотрим применение другого алгоритма кластеризации. В проводнике WEKA выберитеHierarchicalClusterer в качестве вашего алгоритма машинного обучения, как показано на скриншоте ниже -
Выбрать Cluster mode выбор в Classes to cluster evaluation, и нажмите на Startкнопка. Вы увидите следующий вывод -
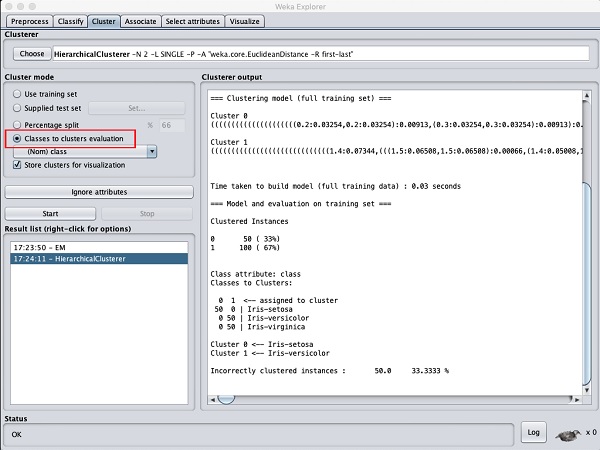
Обратите внимание, что в Result list, отображаются два результата: первый - результат EM, а второй - текущий иерархический. Точно так же вы можете применить несколько алгоритмов машинного обучения к одному и тому же набору данных и быстро сравнить их результаты.
Если вы изучите дерево, созданное этим алгоритмом, вы увидите следующий вывод:
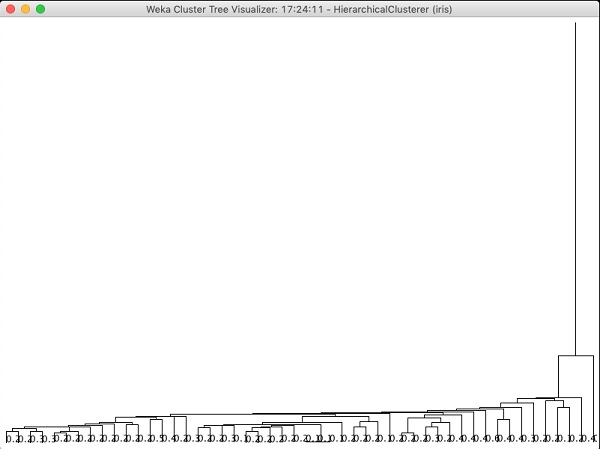
В следующей главе вы изучите Associate тип алгоритмов машинного обучения.
Было замечено, что люди, покупающие пиво, одновременно покупают и подгузники. То есть есть ассоциация по покупке пива и памперсов вместе. Хотя это кажется не очень убедительным, это правило ассоциации было получено из огромных баз данных супермаркетов. Точно так же можно найти связь между арахисовым маслом и хлебом.
Поиск таких ассоциаций становится жизненно важным для супермаркетов, поскольку они будут складировать подгузники рядом с пивом, чтобы покупатели могли легко найти оба товара, что приведет к увеличению продаж в супермаркете.
В AprioriАлгоритм является одним из таких алгоритмов в ML, который обнаруживает вероятные ассоциации и создает правила ассоциации. WEKA предоставляет реализацию алгоритма априори. Вы можете определить минимальную поддержку и приемлемый уровень уверенности при вычислении этих правил. Вы применитеApriori алгоритм к supermarket данные предоставлены в установке WEKA.
Загрузка данных
В проводнике WEKA откройте Preprocess вкладку, нажмите на Open file ... и выберите supermarket.arffбазу данных из установочной папки. После загрузки данных вы увидите следующий экран -
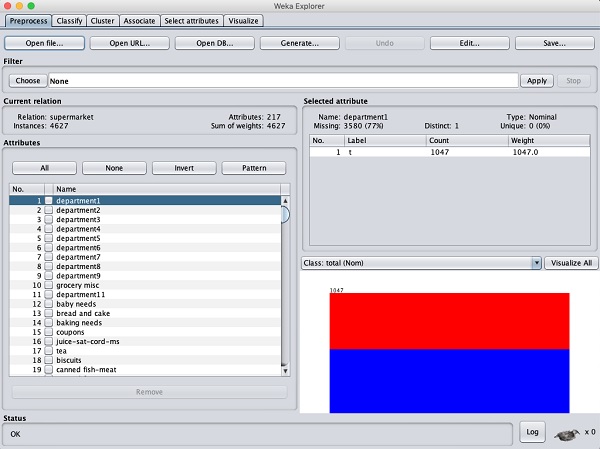
База данных содержит 4627 экземпляров и 217 атрибутов. Вы легко можете понять, насколько сложно было бы обнаружить связь между таким большим количеством атрибутов. К счастью, эта задача автоматизирована с помощью алгоритма Apriori.
Ассоциатор
Нажми на Associate TAB и нажмите на Chooseкнопка. ВыберитеApriori ассоциация, как показано на скриншоте -
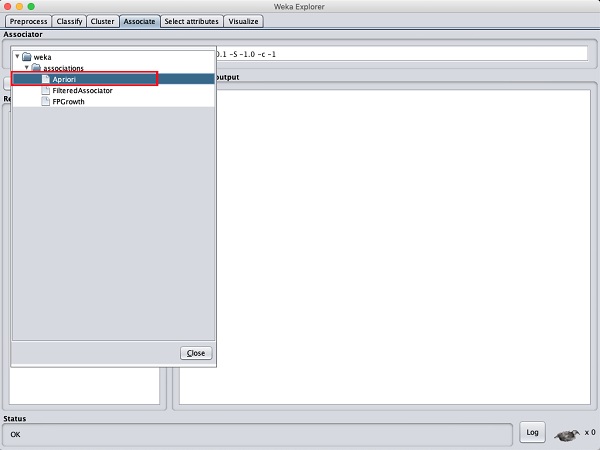
Чтобы установить параметры для алгоритма Apriori, щелкните его имя, появится всплывающее окно, как показано ниже, которое позволяет вам установить параметры -
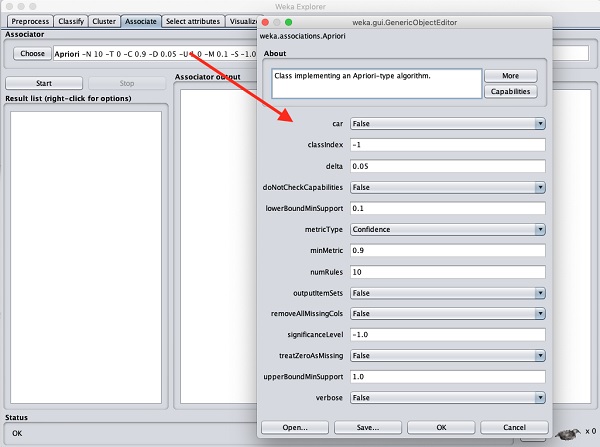
После настройки параметров щелкните значок Startкнопка. Через некоторое время вы увидите результаты, как показано на скриншоте ниже -
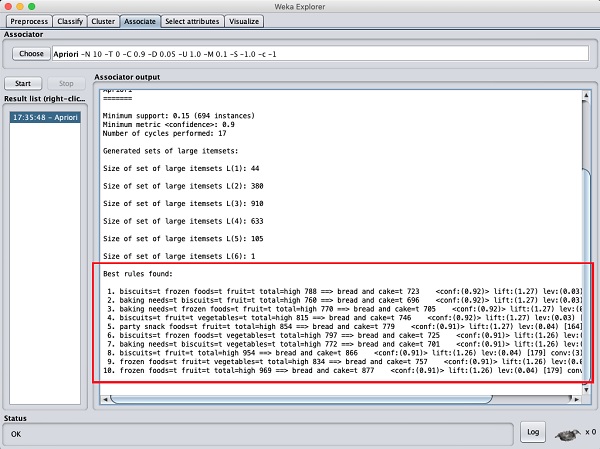
Внизу вы найдете обнаруженные лучшие правила ассоциаций. Это поможет супермаркету разместить свои продукты на соответствующих полках.
Когда база данных содержит большое количество атрибутов, будет несколько атрибутов, которые не станут важными для анализа, который вы в настоящее время ищете. Таким образом, удаление нежелательных атрибутов из набора данных становится важной задачей при разработке хорошей модели машинного обучения.
Вы можете визуально изучить весь набор данных и выбрать нерелевантные атрибуты. Это может быть огромной задачей для баз данных, содержащих большое количество атрибутов, таких как случай супермаркета, который вы видели на предыдущем уроке. К счастью, WEKA предоставляет автоматизированный инструмент для выбора функций.
В этой главе демонстрируется эта функция на базе данных, содержащей большое количество атрибутов.
Загрузка данных
в Preprocess тега WEKA explorer выберите labor.arffфайл для загрузки в систему. Когда вы загрузите данные, вы увидите следующий экран -
Обратите внимание на 17 атрибутов. Наша задача - создать сокращенный набор данных, исключив некоторые атрибуты, не имеющие отношения к нашему анализу.
Особенности извлечения
Нажми на Select attributesTAB. Вы увидите следующий экран -
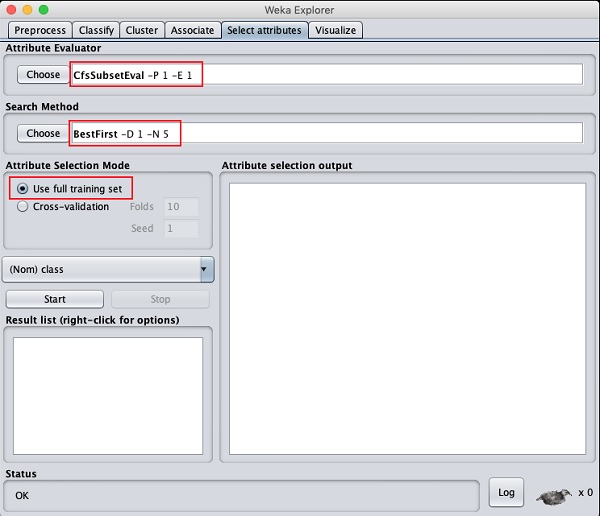
Под Attribute Evaluator и Search Method, вы найдете несколько вариантов. Здесь мы просто будем использовать значения по умолчанию. вAttribute Selection Mode, используйте опцию полного обучающего набора.
Нажмите кнопку «Пуск», чтобы обработать набор данных. Вы увидите следующий вывод -

Внизу окна результатов вы увидите список Selectedатрибуты. Чтобы получить визуальное представление, щелкните правой кнопкой мыши результат вResult список.
Результат показан на следующем снимке экрана -
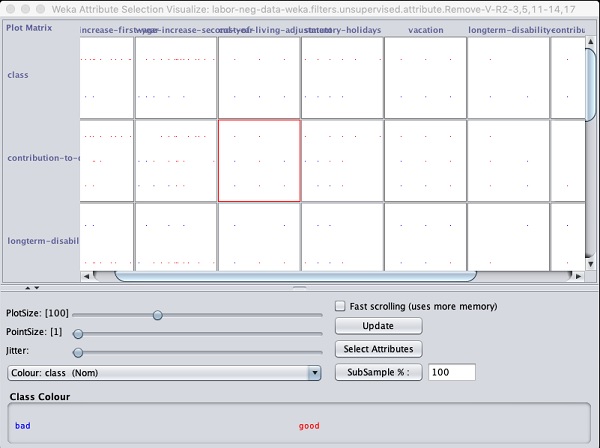
Нажав на любой из квадратов, вы получите график данных для дальнейшего анализа. Типичный график данных показан ниже -
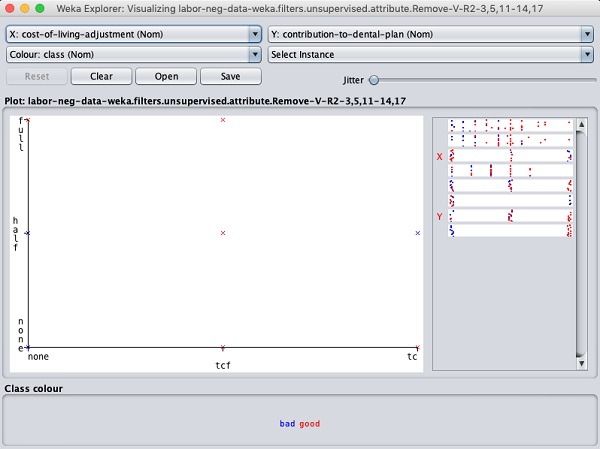
Это похоже на те, которые мы видели в предыдущих главах. Поиграйте с различными вариантами, доступными для анализа результатов.
Что дальше?
До сих пор вы видели силу WEKA в быстрой разработке моделей машинного обучения. Мы использовали графический инструмент под названиемExplorerдля разработки этих моделей. WEKA также предоставляет интерфейс командной строки, который дает вам больше возможностей, чем в проводнике.
Нажав на Simple CLI кнопка в GUI Chooser приложение запускает этот интерфейс командной строки, который показан на скриншоте ниже -
Введите свои команды в поле ввода внизу. Вы сможете делать все, что уже сделали, в проводнике, а также многое другое. Дополнительные сведения см. В документации WEKA (https://www.cs.waikato.ac.nz/ml/weka/documentation.html).
Наконец, WEKA разработана на Java и предоставляет интерфейс для своего API. Так что если вы разработчик Java и хотите включить реализации WEKA ML в свои собственные проекты Java, вы можете сделать это легко.
Заключение
WEKA - мощный инструмент для разработки моделей машинного обучения. Он обеспечивает реализацию нескольких наиболее широко используемых алгоритмов машинного обучения. Прежде чем эти алгоритмы будут применены к вашему набору данных, они также позволят вам предварительно обработать данные. Типы поддерживаемых алгоритмов классифицируются по атрибутам Classify, Cluster, Associate и Select. Результат на различных этапах обработки может быть визуализирован с помощью красивого и мощного визуального представления. Это позволяет специалисту по данным быстро применять различные методы машинного обучения к своему набору данных, сравнивать результаты и создавать наилучшую модель для окончательного использования.