Weka - кластеризация
Алгоритм кластеризации находит группы похожих экземпляров во всем наборе данных. WEKA поддерживает несколько алгоритмов кластеризации, таких как EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans и т. Д. Вы должны полностью понимать эти алгоритмы, чтобы полностью использовать возможности WEKA.
Как и в случае классификации, WEKA позволяет визуализировать обнаруженные кластеры графически. Чтобы продемонстрировать кластеризацию, мы будем использовать предоставленную базу данных iris. Набор данных содержит три класса по 50 экземпляров в каждом. Каждый класс относится к типу ириса.
Загрузка данных
В проводнике WEKA выберите Preprocessтаб. Нажми наOpen file ... и выберите iris.arffфайл в диалоговом окне выбора файла. Когда вы загружаете данные, экран выглядит так, как показано ниже -
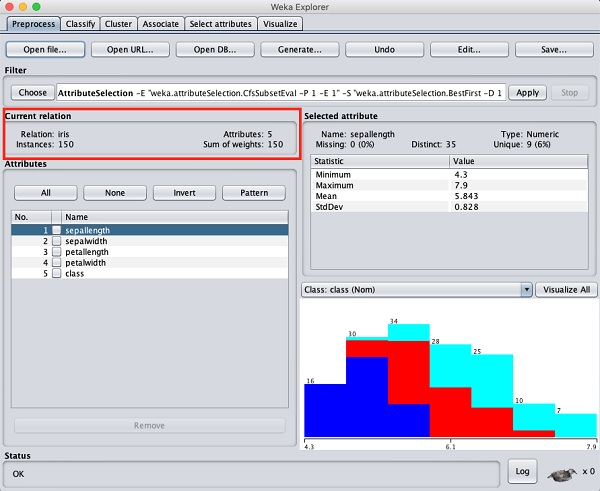
Вы можете заметить, что существует 150 экземпляров и 5 атрибутов. Имена атрибутов перечислены какsepallength, sepalwidth, petallength, petalwidth и class. Первые четыре атрибута относятся к числовому типу, а класс - к номинальному типу с 3 различными значениями. Изучите каждый атрибут, чтобы понять особенности базы данных. Мы не будем проводить предварительную обработку этих данных и сразу приступим к построению модели.
Кластеризация
Нажми на ClusterTAB, чтобы применить алгоритмы кластеризации к нашим загруженным данным. Нажми наChooseкнопка. Вы увидите следующий экран -

Теперь выберите EMкак алгоритм кластеризации. вCluster mode дополнительное окно, выберите Classes to clusters evaluation вариант, как показано на скриншоте ниже -

Нажми на Startкнопку для обработки данных. Через некоторое время результаты будут представлены на экране.
Далее изучим результаты.
Изучение вывода
Результат обработки данных показан на экране ниже -
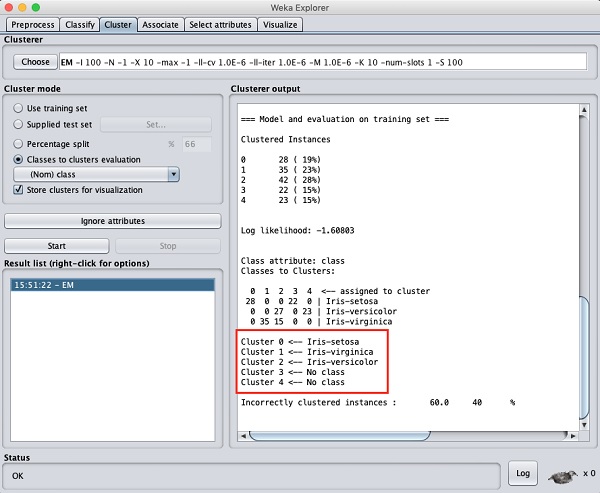
На экране вывода вы можете увидеть, что -
В базе данных обнаружено 5 кластерных экземпляров.
В Cluster 0 представляет сетоса, Cluster 1 представляет вирджинику, Cluster 2 представляет собой разноцветный, в то время как последние два кластера не имеют связанных с ними классов.
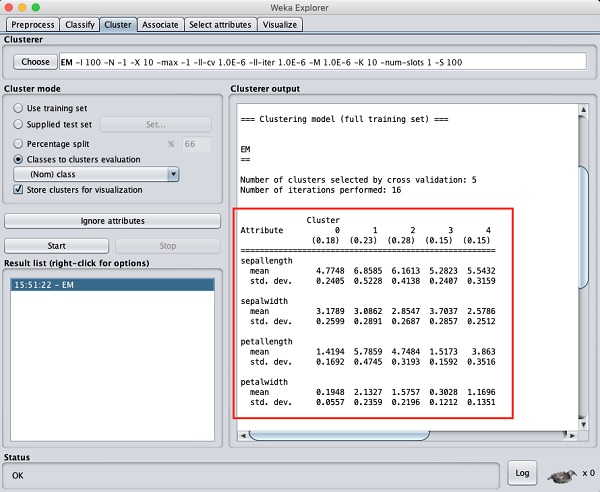
Если вы прокрутите окно вывода вверх, вы также увидите некоторую статистику, которая дает среднее значение и стандартное отклонение для каждого из атрибутов в различных обнаруженных кластерах. Это показано на скриншоте ниже -
Далее мы рассмотрим визуальное представление кластеров.
Визуализация кластеров
Чтобы визуализировать кластеры, щелкните правой кнопкой мыши на EM в результате Result list. Вы увидите следующие варианты -
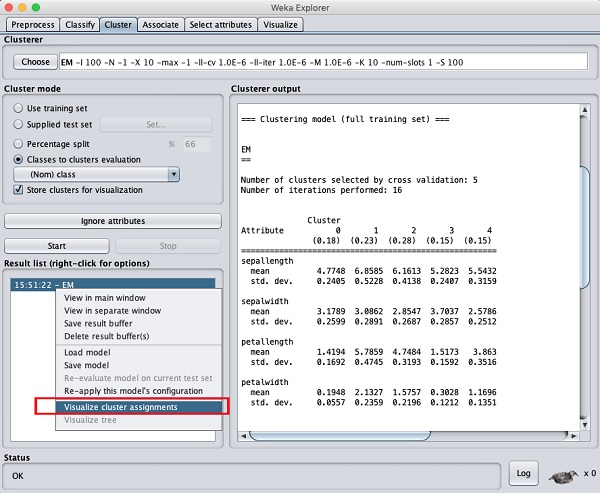
Выбрать Visualize cluster assignments. Вы увидите следующий вывод -
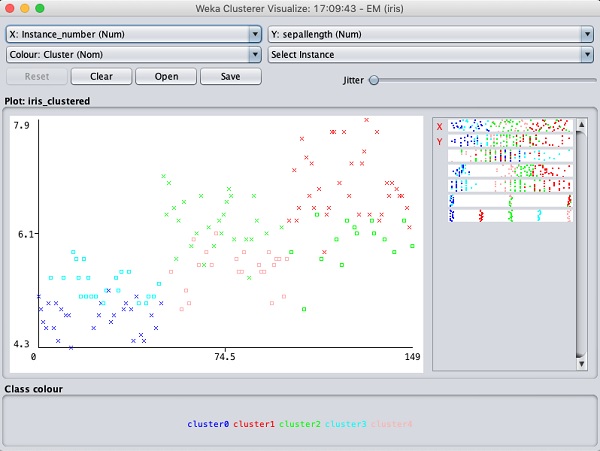
Как и в случае с классификацией, вы заметите различие между правильно и неправильно идентифицированными экземплярами. Вы можете поиграть, изменив оси X и Y, чтобы проанализировать результаты. Вы можете использовать дрожание, как и в случае классификации, чтобы узнать концентрацию правильно идентифицированных экземпляров. Операции на графике визуализации аналогичны тем, которые вы изучали в случае классификации.
Применение иерархического кластера
Чтобы продемонстрировать мощь WEKA, давайте теперь рассмотрим применение другого алгоритма кластеризации. В проводнике WEKA выберитеHierarchicalClusterer в качестве вашего алгоритма машинного обучения, как показано на скриншоте ниже -
Выбрать Cluster mode выбор в Classes to cluster evaluation, и нажмите на Startкнопка. Вы увидите следующий вывод -
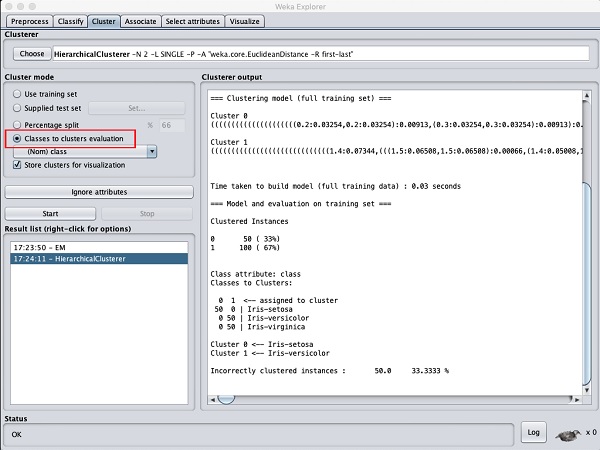
Обратите внимание, что в Result list, отображаются два результата: первый - результат EM, а второй - текущий иерархический. Точно так же вы можете применить несколько алгоритмов машинного обучения к одному и тому же набору данных и быстро сравнить их результаты.
Если вы изучите дерево, созданное этим алгоритмом, вы увидите следующий вывод:
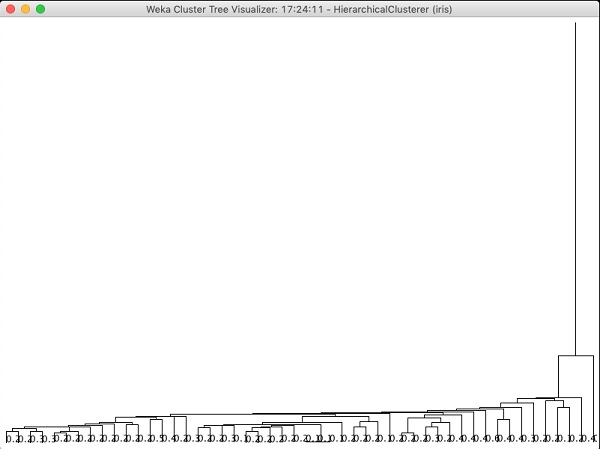
В следующей главе вы изучите Associate тип алгоритмов машинного обучения.