คอมไพเลอร์ - การสร้างรหัสระดับกลาง
ซอร์สโค้ดสามารถแปลเป็นรหัสเครื่องเป้าหมายได้โดยตรงแล้วทำไมเราต้องแปลซอร์สโค้ดเป็นรหัสกลางซึ่งจะถูกแปลเป็นรหัสเป้าหมาย ให้เราดูเหตุผลที่เราต้องการรหัสกลาง
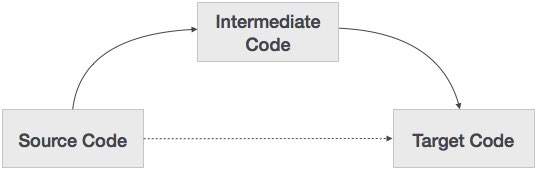
หากคอมไพลเลอร์แปลภาษาต้นทางเป็นภาษาเครื่องเป้าหมายโดยไม่มีตัวเลือกในการสร้างโค้ดกลางดังนั้นสำหรับเครื่องใหม่แต่ละเครื่องจำเป็นต้องมีคอมไพเลอร์เนทีฟแบบสมบูรณ์
โค้ดระดับกลางช่วยลดความจำเป็นในการใช้คอมไพเลอร์ใหม่สำหรับทุกเครื่องที่ไม่ซ้ำกันโดยทำให้ส่วนการวิเคราะห์เหมือนกันสำหรับคอมไพเลอร์ทั้งหมด
ส่วนที่สองของคอมไพเลอร์การสังเคราะห์จะเปลี่ยนไปตามเครื่องเป้าหมาย
การปรับเปลี่ยนซอร์สโค้ดจะง่ายขึ้นเพื่อปรับปรุงประสิทธิภาพของโค้ดโดยใช้เทคนิคการเพิ่มประสิทธิภาพโค้ดกับโค้ดระดับกลาง
การเป็นตัวแทนระดับกลาง
รหัสกลางสามารถแสดงได้หลายวิธีและมีประโยชน์ในตัวเอง
High Level IR- การแสดงรหัสระดับกลางระดับสูงนั้นใกล้เคียงกับภาษาต้นฉบับมาก สามารถสร้างได้อย่างง่ายดายจากซอร์สโค้ดและเราสามารถใช้การแก้ไขโค้ดเพื่อเพิ่มประสิทธิภาพได้อย่างง่ายดาย แต่สำหรับการเพิ่มประสิทธิภาพเครื่องเป้าหมายเป็นที่ต้องการน้อยกว่า
Low Level IR - เครื่องนี้อยู่ใกล้กับเครื่องเป้าหมายซึ่งทำให้เหมาะสำหรับการลงทะเบียนและการจัดสรรหน่วยความจำการเลือกชุดคำสั่ง ฯลฯ เหมาะสำหรับการปรับแต่งตามเครื่อง
รหัสระดับกลางอาจเป็นภาษาเฉพาะ (เช่น Byte Code for Java) หรือภาษาอิสระ (รหัสสามที่อยู่)
รหัสสามที่อยู่
ตัวสร้างโค้ดระดับกลางได้รับอินพุตจากเฟสก่อนหน้าตัววิเคราะห์ความหมายในรูปแบบของโครงสร้างไวยากรณ์ที่มีคำอธิบายประกอบ โครงสร้างไวยากรณ์นั้นสามารถถูกแปลงเป็นการแสดงเชิงเส้นเช่นสัญกรณ์ postfix รหัสระดับกลางมีแนวโน้มที่จะเป็นรหัสที่ไม่ขึ้นกับเครื่อง ดังนั้นตัวสร้างโค้ดจึงถือว่ามีพื้นที่จัดเก็บหน่วยความจำ (register) ไม่ จำกัด จำนวนเพื่อสร้างโค้ด
ตัวอย่างเช่น:
a = b + c * d;ตัวสร้างรหัสกลางจะพยายามแบ่งนิพจน์นี้ออกเป็นนิพจน์ย่อยแล้วสร้างรหัสที่เกี่ยวข้อง
r1 = c * d;
r2 = b + r1;
a = r2r ถูกใช้เป็นรีจิสเตอร์ในโปรแกรมเป้าหมาย
รหัสสามที่อยู่มีตำแหน่งแอดเดรสสูงสุดสามตำแหน่งเพื่อคำนวณนิพจน์ รหัสสามที่อยู่สามารถแสดงได้สองรูปแบบ: สี่เท่าและสามเท่า
สี่เท่า
แต่ละคำสั่งในการนำเสนอสี่เท่าแบ่งออกเป็นสี่ฟิลด์: ตัวดำเนินการ, arg1, arg2 และผลลัพธ์ ตัวอย่างด้านบนแสดงด้านล่างในรูปแบบสี่เท่า:
| Op | อาร์กิวเมนต์1 | อาร์กิวเมนต์2 | ผลลัพธ์ |
| * | ค | ง | r1 |
| + | ข | r1 | r2 |
| + | r2 | r1 | r3 |
| = | r3 | ก |
สามเท่า
แต่ละคำสั่งในการนำเสนอแบบสามครั้งมีสามฟิลด์: op, arg1 และ arg2 ผลลัพธ์ของนิพจน์ย่อยที่เกี่ยวข้องจะแสดงด้วยตำแหน่งของนิพจน์ Triples แสดงความคล้ายคลึงกันกับ DAG และโครงสร้างไวยากรณ์ ซึ่งเทียบเท่ากับ DAG ในขณะที่แสดงนิพจน์
| Op | อาร์กิวเมนต์1 | อาร์กิวเมนต์2 |
| * | ค | ง |
| + | ข | (0) |
| + | (1) | (0) |
| = | (2) |
สามเท่าต้องเผชิญกับปัญหาความไม่สามารถเคลื่อนย้ายของโค้ดในขณะที่การปรับให้เหมาะสมเนื่องจากผลลัพธ์เป็นตำแหน่งและการเปลี่ยนลำดับหรือตำแหน่งของนิพจน์อาจทำให้เกิดปัญหา
สามเท่าทางอ้อม
การแสดงนี้เป็นการเพิ่มประสิทธิภาพมากกว่าการเป็นตัวแทนสามเท่า ใช้พอยน์เตอร์แทนตำแหน่งในการจัดเก็บผลลัพธ์ สิ่งนี้ทำให้เครื่องมือเพิ่มประสิทธิภาพสามารถจัดตำแหน่งนิพจน์ย่อยใหม่ได้อย่างอิสระเพื่อสร้างโค้ดที่ปรับให้เหมาะสม
ประกาศ
ต้องมีการประกาศตัวแปรหรือขั้นตอนก่อนจึงจะใช้งานได้ การประกาศเกี่ยวข้องกับการจัดสรรพื้นที่ในหน่วยความจำและการป้อนประเภทและชื่อในตารางสัญลักษณ์ โปรแกรมอาจได้รับการเข้ารหัสและออกแบบโดยคำนึงถึงโครงสร้างของเครื่องเป้าหมาย แต่อาจไม่สามารถแปลงซอร์สโค้ดเป็นภาษาเป้าหมายได้อย่างถูกต้องเสมอไป
การใช้โปรแกรมทั้งหมดเป็นชุดของโพรซีเดอร์และโพรซีเดอร์ย่อยจึงเป็นไปได้ที่จะประกาศชื่อทั้งหมดในโพรซีเดอร์ การจัดสรรหน่วยความจำจะทำในลักษณะติดต่อกันและชื่อจะถูกจัดสรรให้กับหน่วยความจำตามลำดับที่ประกาศในโปรแกรม เราใช้ตัวแปร offset และตั้งค่าเป็นศูนย์ {offset = 0} ซึ่งแสดงถึงที่อยู่ฐาน
ภาษาการเขียนโปรแกรมต้นทางและสถาปัตยกรรมเครื่องเป้าหมายอาจแตกต่างกันไปตามวิธีการจัดเก็บชื่อดังนั้นจึงใช้การกำหนดแอดเดรสแบบสัมพัทธ์ ในขณะที่ชื่อแรกได้รับการจัดสรรหน่วยความจำโดยเริ่มจากตำแหน่งหน่วยความจำ 0 {offset = 0} ชื่อถัดไปที่ประกาศในภายหลังควรได้รับการจัดสรรหน่วยความจำถัดจากชื่อแรก
Example:
เรานำตัวอย่างของการเขียนโปรแกรมภาษาซีที่ตัวแปรจำนวนเต็มถูกกำหนดหน่วยความจำ 2 ไบต์และตัวแปร float กำหนดหน่วยความจำ 4 ไบต์
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}ในการป้อนรายละเอียดนี้ในตารางสัญลักษณ์สามารถใช้ขั้นตอนการป้อนได้ วิธีนี้อาจมีโครงสร้างดังนี้
enter(name, type, offset)โพรซีเดอร์นี้ควรสร้างรายการในตารางสัญลักษณ์สำหรับชื่อตัวแปรโดยกำหนดประเภทเป็นประเภทและออฟเซ็ตที่อยู่สัมพัทธ์ในพื้นที่ข้อมูล