การออกแบบคอมไพเลอร์ - การวิเคราะห์ความหมาย
เราได้เรียนรู้ว่าโปรแกรมแยกวิเคราะห์สร้างโครงสร้างแยกวิเคราะห์อย่างไรในขั้นตอนการวิเคราะห์ไวยากรณ์ โดยทั่วไปแล้ว parse-tree ที่สร้างในเฟสนั้นโดยทั่วไปจะไม่มีประโยชน์สำหรับคอมไพเลอร์เนื่องจากไม่มีข้อมูลใด ๆ เกี่ยวกับวิธีการประเมินต้นไม้ การผลิตของไวยากรณ์ที่ไม่มีบริบทซึ่งทำให้กฎของภาษาไม่รองรับวิธีการตีความ
ตัวอย่างเช่น
E → E + Tการผลิต CFG ข้างต้นไม่มีกฎเชิงความหมายที่เกี่ยวข้องและไม่สามารถช่วยในการสร้างความรู้สึกใด ๆ เกี่ยวกับการผลิตได้
อรรถศาสตร์
ความหมายของภาษาให้ความหมายกับโครงสร้างเช่นโทเค็นและโครงสร้างไวยากรณ์ ความหมายช่วยตีความสัญลักษณ์ประเภทและความสัมพันธ์ซึ่งกันและกัน การวิเคราะห์เชิงความหมายจะตัดสินว่าโครงสร้างไวยากรณ์ที่สร้างขึ้นในโปรแกรมต้นทางนั้นมีความหมายหรือไม่
CFG + semantic rules = Syntax Directed Definitionsตัวอย่างเช่น:
int a = “value”;ไม่ควรแสดงข้อผิดพลาดในขั้นตอนการวิเคราะห์ศัพท์และไวยากรณ์เนื่องจากเป็นคำศัพท์และถูกต้องตามโครงสร้าง แต่ควรสร้างข้อผิดพลาดทางความหมายเนื่องจากประเภทของการกำหนดต่างกัน กฎเหล่านี้กำหนดโดยไวยากรณ์ของภาษาและประเมินด้วยการวิเคราะห์เชิงความหมาย งานต่อไปนี้ควรดำเนินการในการวิเคราะห์เชิงความหมาย:
- ความละเอียดขอบเขต
- พิมพ์การตรวจสอบ
- การตรวจสอบขอบเขตอาร์เรย์
ข้อผิดพลาดเชิงความหมาย
เราได้กล่าวถึงข้อผิดพลาดด้านความหมายบางประการที่คาดว่าเครื่องวิเคราะห์ความหมายจะรับรู้:
- พิมพ์ไม่ตรงกัน
- ตัวแปรที่ไม่ได้ประกาศ
- ใช้ตัวระบุที่สงวนไว้ในทางที่ผิด
- การประกาศตัวแปรหลายรายการในขอบเขต
- การเข้าถึงตัวแปรนอกขอบเขต
- พารามิเตอร์จริงและเป็นทางการไม่ตรงกัน
แอตทริบิวต์ไวยากรณ์
ไวยากรณ์ของแอตทริบิวต์เป็นรูปแบบพิเศษของไวยากรณ์ที่ไม่มีบริบทซึ่งข้อมูลเพิ่มเติมบางอย่าง (แอตทริบิวต์) จะถูกผนวกเข้ากับเทอร์มินัลที่ไม่ใช่เทอร์มินัลอย่างน้อยหนึ่งรายการเพื่อให้ข้อมูลที่ละเอียดอ่อนตามบริบท แต่ละแอตทริบิวต์มีโดเมนของค่าที่กำหนดไว้อย่างชัดเจนเช่นจำนวนเต็มจำนวนทศนิยมอักขระสตริงและนิพจน์
ไวยากรณ์ของแอตทริบิวต์เป็นสื่อที่ให้ความหมายแก่ไวยากรณ์ที่ไม่มีบริบทและสามารถช่วยระบุไวยากรณ์และความหมายของภาษาโปรแกรมได้ ไวยากรณ์ของแอตทริบิวต์ (เมื่อมองว่าเป็นโครงสร้างการแยกวิเคราะห์) สามารถส่งผ่านค่าหรือข้อมูลระหว่างโหนดของต้นไม้
Example:
E → E + T { E.value = E.value + T.value }ส่วนทางขวาของ CFG มีกฎความหมายที่ระบุว่าควรตีความไวยากรณ์อย่างไร ที่นี่ค่าของ E และ T ที่ไม่ใช่เทอร์มินัลจะถูกเพิ่มเข้าด้วยกันและผลลัพธ์จะถูกคัดลอกไปยัง non-terminal E
แอตทริบิวต์เชิงความหมายอาจถูกกำหนดให้กับค่าจากโดเมนของพวกเขาในเวลาที่แยกวิเคราะห์และประเมินผลในเวลาที่กำหนดหรือเงื่อนไข ขึ้นอยู่กับวิธีที่แอตทริบิวต์ได้รับค่าของพวกเขาพวกเขาสามารถแบ่งออกเป็นสองประเภทอย่างกว้าง ๆ ได้แก่ แอตทริบิวต์ที่สังเคราะห์และแอตทริบิวต์ที่สืบทอดมา
แอตทริบิวต์ที่สังเคราะห์
แอตทริบิวต์เหล่านี้ได้รับค่าจากค่าแอตทริบิวต์ของโหนดลูก เพื่อเป็นตัวอย่างสมมติการผลิตต่อไปนี้:
S → ABCถ้า S รับค่าจากโหนดลูก (A, B, C) ก็จะกล่าวได้ว่าเป็นแอตทริบิวต์ที่สังเคราะห์เนื่องจากค่าของ ABC จะถูกสังเคราะห์เป็น S
ดังตัวอย่างก่อนหน้าของเรา (E → E + T) โหนดแม่ E ได้รับค่าจากโหนดลูก แอตทริบิวต์ที่สังเคราะห์จะไม่รับค่าจากโหนดแม่หรือโหนดพี่น้องใด ๆ
แอตทริบิวต์ที่สืบทอด
ในทางตรงกันข้ามกับแอตทริบิวต์ที่สังเคราะห์แล้วแอตทริบิวต์ที่สืบทอดสามารถรับค่าจากผู้ปกครองและ / หรือพี่น้องได้ ในการผลิตต่อไปนี้
S → ABCA สามารถรับค่าจาก S, B และ C B สามารถรับค่าจาก S, A และ C ในทำนองเดียวกัน C สามารถรับค่าจาก S, A และ B
Expansion : เมื่อไม่มีการขยายเทอร์มินัลไปยังเทอร์มินัลตามกฎไวยากรณ์
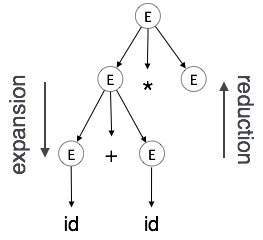
Reduction: เมื่อเทอร์มินัลลดลงเป็น non-terminal ที่สอดคล้องกันตามกฎไวยากรณ์ โครงสร้างไวยากรณ์จะแยกวิเคราะห์จากบนลงล่างและจากซ้ายไปขวา เมื่อใดก็ตามที่เกิดการลดลงเราจะใช้กฎความหมาย (การกระทำ) ที่สอดคล้องกัน
การวิเคราะห์ความหมายใช้การแปลที่กำกับด้วยไวยากรณ์เพื่อดำเนินการข้างต้น
ตัววิเคราะห์ความหมายได้รับ AST (Abstract Syntax Tree) จากขั้นตอนก่อนหน้า (การวิเคราะห์ไวยากรณ์)
ตัววิเคราะห์ความหมายแนบข้อมูลแอตทริบิวต์กับ AST ซึ่งเรียกว่า Attributed AST
แอตทริบิวต์คือค่าทูเปิลสองค่า <attribute name, attribute value>
ตัวอย่างเช่น:
int value = 5;
<type, “integer”>
<presentvalue, “5”>สำหรับการผลิตทุกครั้งเราแนบกฎความหมาย
S- แอตทริบิวต์ SDT
หาก SDT ใช้เฉพาะแอตทริบิวต์ที่สังเคราะห์ขึ้นจะเรียกว่าเป็น S-attributed SDT แอตทริบิวต์เหล่านี้ได้รับการประเมินโดยใช้ S-attributed SDT ที่มีการดำเนินการเชิงความหมายที่เขียนขึ้นหลังการผลิต (ด้านขวามือ)
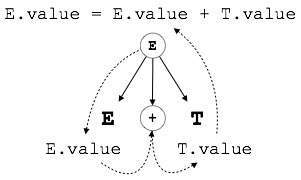
ดังที่แสดงไว้ด้านบนแอตทริบิวต์ใน SDT ที่มีการระบุแหล่งที่มาของ S จะได้รับการประเมินในการแยกวิเคราะห์จากล่างขึ้นบนเนื่องจากค่าของโหนดแม่ขึ้นอยู่กับค่าของโหนดลูก
L- แอตทริบิวต์ SDT
SDT รูปแบบนี้ใช้แอตทริบิวต์ที่สังเคราะห์และสืบทอดโดยมีข้อ จำกัด ในการไม่รับค่าจากพี่น้องที่เหมาะสม
ใน SDT ที่กำหนดโดย L นั้น non-terminal สามารถรับค่าจากโหนดแม่ลูกและโหนดพี่น้องได้ ดังต่อไปนี้การผลิต
S → ABCS สามารถรับค่าจาก A, B และ C (สังเคราะห์) A สามารถรับค่าจาก S เท่านั้น B สามารถรับค่าจาก S และ A C ได้ค่าจาก S, A และ B ไม่มี non-terminal ที่สามารถรับค่าจากพี่น้องไปทางขวาได้
แอตทริบิวต์ใน SDT ที่มีการระบุแหล่งที่มาของ L จะได้รับการประเมินโดยวิธีการแยกวิเคราะห์จากซ้ายไปขวาก่อนเชิงลึก
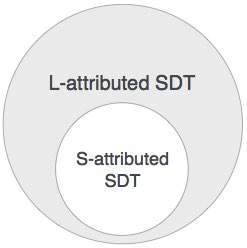
เราอาจสรุปได้ว่าถ้าคำจำกัดความเป็น S-attributed ก็จะเป็น L-attributed เช่นกันเนื่องจาก L-attributed definition จะมีการกำหนด S-attributed