การออกแบบคอมไพเลอร์ - การวิเคราะห์ไวยากรณ์
การวิเคราะห์ไวยากรณ์หรือการแยกวิเคราะห์เป็นขั้นตอนที่สองของคอมไพเลอร์ ในบทนี้เราจะเรียนรู้แนวคิดพื้นฐานที่ใช้ในการสร้างโปรแกรมแยกวิเคราะห์
เราได้เห็นว่าตัววิเคราะห์คำศัพท์สามารถระบุโทเค็นได้ด้วยความช่วยเหลือของนิพจน์ทั่วไปและกฎรูปแบบ แต่ตัววิเคราะห์คำศัพท์ไม่สามารถตรวจสอบไวยากรณ์ของประโยคที่กำหนดได้เนื่องจากข้อ จำกัด ของนิพจน์ทั่วไป นิพจน์ทั่วไปไม่สามารถตรวจสอบโทเค็นการปรับสมดุลเช่นวงเล็บ ดังนั้นขั้นตอนนี้จึงใช้ไวยากรณ์ที่ไม่มีบริบท (CFG) ซึ่งได้รับการยอมรับโดยออโตมาตาแบบกดลง
CFG ในทางกลับกันเป็นส่วนเหนือของไวยากรณ์ปกติดังที่แสดงด้านล่าง:

หมายความว่าไวยากรณ์ปกติทุกตัวไม่มีบริบทเช่นกัน แต่มีปัญหาบางอย่างซึ่งอยู่นอกเหนือขอบเขตของไวยากรณ์ปกติ CFG เป็นเครื่องมือที่มีประโยชน์ในการอธิบายไวยากรณ์ของภาษาโปรแกรม
ไวยากรณ์ที่ไม่มีบริบท
ในส่วนนี้ก่อนอื่นเราจะดูคำจำกัดความของไวยากรณ์ที่ไม่มีบริบทและแนะนำคำศัพท์ที่ใช้ในเทคโนโลยีการแยกวิเคราะห์
ไวยากรณ์ที่ไม่มีบริบทมีองค์ประกอบสี่ส่วน:
ชุดของ non-terminals(V). ไม่ใช่เทอร์มินัลเป็นตัวแปรทางวากยสัมพันธ์ที่แสดงถึงชุดของสตริง non-terminals กำหนดชุดของสตริงที่ช่วยกำหนดภาษาที่สร้างโดยไวยากรณ์
ชุดของโทเค็นที่เรียกว่า terminal symbols(Σ). เทอร์มินัลเป็นสัญลักษณ์พื้นฐานที่ใช้สร้างสตริง
ชุดของ productions(ป). การผลิตของไวยากรณ์ระบุลักษณะที่สามารถรวมเทอร์มินัลและไม่ใช่เทอร์มินัลเพื่อสร้างสตริงได้ การผลิตแต่ละรายการประกอบด้วยไฟล์non-terminal เรียกว่าด้านซ้ายของการผลิตลูกศรและลำดับของโทเค็นและ / หรือ on- terminalsเรียกว่าด้านขวาของการผลิต
หนึ่งในขั้วที่ไม่ใช่ขั้วถูกกำหนดให้เป็นสัญลักษณ์เริ่มต้น (S); จากจุดเริ่มต้นของการผลิต
สตริงได้มาจากสัญลักษณ์เริ่มต้นโดยการแทนที่เทอร์มินัลที่ไม่ใช่เทอร์มินัลซ้ำ ๆ (เริ่มแรกคือสัญลักษณ์เริ่มต้น) ทางด้านขวาของการผลิตสำหรับสิ่งที่ไม่ใช่เทอร์มินัลนั้น
ตัวอย่าง
เราใช้ปัญหาของภาษา palindrome ซึ่งไม่สามารถอธิบายได้ด้วย Regular Expression นั่นคือ L = {w | w = w R } ไม่ใช่ภาษาปกติ แต่สามารถอธิบายได้โดยใช้ CFG ดังภาพประกอบด้านล่าง:
G = ( V, Σ, P, S )ที่ไหน:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }ไวยากรณ์นี้อธิบายภาษา Palindrome เช่น: 1001, 11100111, 00100, 1010101, 11111 เป็นต้น
เครื่องวิเคราะห์ไวยากรณ์
ตัววิเคราะห์ไวยากรณ์หรือตัวแยกวิเคราะห์จะรับอินพุตจากตัววิเคราะห์คำศัพท์ในรูปแบบของโทเค็นสตรีม ตัวแยกวิเคราะห์จะวิเคราะห์ซอร์สโค้ด (โทเค็นสตรีม) กับกฎการใช้งานจริงเพื่อตรวจหาข้อผิดพลาดในโค้ด ผลลัพธ์ของเฟสนี้คือไฟล์parse tree.

ด้วยวิธีนี้โปรแกรมแยกวิเคราะห์จะทำงานสองอย่างให้สำเร็จนั่นคือการแยกวิเคราะห์รหัสค้นหาข้อผิดพลาดและสร้างแผนภูมิแยกวิเคราะห์เป็นผลลัพธ์ของเฟส
ตัววิเคราะห์คาดว่าจะแยกวิเคราะห์รหัสทั้งหมดแม้ว่าจะมีข้อผิดพลาดบางอย่างในโปรแกรมก็ตาม พาร์เซอร์ใช้กลยุทธ์การกู้คืนข้อผิดพลาดซึ่งเราจะเรียนรู้ในบทนี้ในภายหลัง
ที่มา
การได้มาเป็นลำดับของกฎการผลิตโดยทั่วไปเพื่อให้ได้สตริงอินพุต ในระหว่างการแยกวิเคราะห์เราจะตัดสินใจสองครั้งสำหรับรูปแบบการป้อนข้อมูลที่เป็นความรู้สึก:
- การตัดสินใจว่าจะเปลี่ยนขั้วที่ไม่ใช่ขั้วใด
- การตัดสินใจกฎการผลิตโดยที่ไม่ใช่ขั้วจะถูกแทนที่
ในการตัดสินใจว่าจะแทนที่ non-terminal ใดด้วยกฎการผลิตเรามีสองตัวเลือก
การมาจากซ้ายสุด
หากรูปแบบความรู้สึกของข้อมูลเข้าถูกสแกนและแทนที่จากซ้ายไปขวาจะเรียกว่าการมาจากซ้ายสุด รูปแบบความรู้สึกที่ได้มาจากการมาจากทางซ้ายสุดเรียกว่ารูปแบบความรู้สึกทางซ้าย
ที่มาที่ถูกต้องที่สุด
หากเราสแกนและแทนที่อินพุตด้วยกฎการผลิตจากขวาไปซ้ายจะเรียกว่าการมาจากขวาสุด รูปแบบความรู้สึกที่ได้มาจากรากศัพท์ด้านขวาที่สุดเรียกว่ารูปแบบความรู้สึกทางขวา
Example
กฎการผลิต:
E → E + E
E → E * E
E → idสตริงอินพุต: id + id * id
รากศัพท์ด้านซ้ายสุดคือ:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idสังเกตว่า non-terminal ด้านซ้ายสุดจะถูกประมวลผลก่อนเสมอ
รากศัพท์ที่ถูกต้องที่สุดคือ:
E → E + E
E → E + E * E
E → E + E * id
E → E + id * id
E → id + id * idแยกวิเคราะห์ต้นไม้
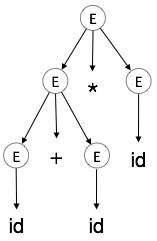
ต้นไม้แยกวิเคราะห์คือการแสดงภาพกราฟิกของการได้มา สะดวกในการดูว่าสตริงมาจากสัญลักษณ์เริ่มต้นอย่างไร สัญลักษณ์เริ่มต้นของการได้มากลายเป็นรากของต้นไม้แยกวิเคราะห์ ให้เราดูตัวอย่างจากหัวข้อสุดท้าย
เราหารากศัพท์ทางซ้ายสุดของ a + b * c
รากศัพท์ด้านซ้ายสุดคือ:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idขั้นตอนที่ 1:
| E → E * E |
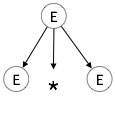
|
ขั้นตอนที่ 2:
| E → E + E * E |
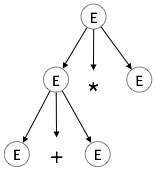
|
ขั้นตอนที่ 3:
| E → id + E * E |
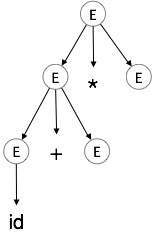
|
ขั้นตอนที่ 4:
| E → id + id * E |
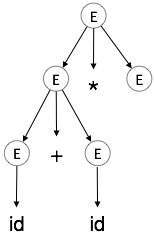
|
ขั้นตอนที่ 5:
| E → id + id * id |
|
ในต้นไม้แยกวิเคราะห์:
- โหนดใบทั้งหมดเป็นขั้ว
- โหนดภายในทั้งหมดไม่ใช่เทอร์มินัล
- การส่งผ่านตามลำดับให้สตริงอินพุตดั้งเดิม
แผนผังการแยกวิเคราะห์แสดงถึงความเชื่อมโยงและลำดับความสำคัญของตัวดำเนินการ ทรีย่อยที่ลึกที่สุดจะถูกสำรวจก่อนดังนั้นตัวดำเนินการในแผนผังย่อยนั้นจะมีความสำคัญเหนือตัวดำเนินการซึ่งอยู่ในโหนดแม่
ความคลุมเครือ
ไวยากรณ์ G มีความคลุมเครือหากมีโครงสร้างการแยกวิเคราะห์มากกว่าหนึ่งรายการ (รากศัพท์ด้านซ้ายหรือด้านขวา) อย่างน้อยหนึ่งสตริง
Example
E → E + E
E → E – E
E → idสำหรับสตริง id + id - id ไวยากรณ์ข้างต้นจะสร้างโครงสร้างการแยกวิเคราะห์สองแบบ:

มีการกล่าวถึงภาษาที่สร้างโดยไวยากรณ์ที่ไม่ชัดเจน inherently ambiguous. ความคลุมเครือในไวยากรณ์ไม่ดีสำหรับการสร้างคอมไพเลอร์ ไม่มีวิธีใดที่สามารถตรวจจับและลบความคลุมเครือได้โดยอัตโนมัติ แต่สามารถลบออกได้โดยการเขียนไวยากรณ์ใหม่ทั้งหมดโดยไม่มีความคลุมเครือหรือโดยการตั้งค่าและปฏิบัติตามข้อ จำกัด ในการเชื่อมโยงและลำดับความสำคัญ
ความสัมพันธ์
ถ้าตัวถูกดำเนินการมีตัวดำเนินการอยู่ทั้งสองด้านฝั่งที่ตัวดำเนินการใช้ตัวถูกดำเนินการนี้จะถูกตัดสินโดยความเชื่อมโยงของตัวดำเนินการเหล่านั้น หากการดำเนินการเป็นแบบเชื่อมโยงทางซ้ายตัวถูกดำเนินการจะถูกดำเนินการโดยตัวดำเนินการด้านซ้ายหรือถ้าการดำเนินการเชื่อมโยงทางขวาตัวดำเนินการที่ถูกต้องจะรับตัวถูกดำเนินการ
Example
การดำเนินการเช่นการบวกการคูณการลบและการหารจะเหลือเพียงการเชื่อมโยง หากนิพจน์ประกอบด้วย:
id op id op idจะได้รับการประเมินเป็น:
(id op id) op idตัวอย่างเช่น (id + id) + id
การดำเนินการเช่นการยกกำลังเป็นการเชื่อมโยงที่ถูกต้องกล่าวคือลำดับของการประเมินผลในนิพจน์เดียวกันจะเป็น:
id op (id op id)ตัวอย่างเช่น id ^ (id ^ id)
ลำดับความสำคัญ
หากตัวดำเนินการสองตัวใช้ตัวถูกดำเนินการร่วมกันลำดับความสำคัญของตัวดำเนินการจะตัดสินใจว่าจะใช้ตัวถูกดำเนินการใด นั่นคือ 2 + 3 * 4 สามารถมีต้นไม้แยกวิเคราะห์ที่แตกต่างกันได้สองแบบโดยต้นหนึ่งที่สอดคล้องกับ (2 + 3) * 4 และอีกอันที่เกี่ยวข้องกับ 2+ (3 * 4) ด้วยการกำหนดลำดับความสำคัญระหว่างตัวดำเนินการปัญหานี้สามารถลบออกได้อย่างง่ายดาย ดังตัวอย่างก่อนหน้านี้ทางคณิตศาสตร์ * (การคูณ) มีความสำคัญมากกว่า + (การบวก) ดังนั้นนิพจน์ 2 + 3 * 4 จะถูกตีความเป็น:
2 + (3 * 4)วิธีการเหล่านี้ช่วยลดโอกาสของความคลุมเครือในภาษาหรือไวยากรณ์
วนซ้าย
ไวยากรณ์จะกลายเป็นแบบวนซ้ำทางซ้ายหากมี 'A' ที่ไม่ใช่เทอร์มินัลใด ๆ ที่มีรากศัพท์มี 'A' เป็นสัญลักษณ์ทางซ้ายสุด ไวยากรณ์แบบวนซ้ำด้านซ้ายถือเป็นสถานการณ์ที่มีปัญหาสำหรับตัวแยกวิเคราะห์จากบนลงล่าง ตัวแยกวิเคราะห์จากบนลงล่างเริ่มแยกวิเคราะห์จากสัญลักษณ์เริ่มซึ่งในตัวมันเองไม่ใช่เทอร์มินัล ดังนั้นเมื่อตัวแยกวิเคราะห์พบสิ่งที่ไม่ใช่เทอร์มินัลเดียวกันในการหาที่มามันจึงยากที่จะตัดสินว่าเมื่อใดที่จะหยุดการแยกส่วนที่ไม่ใช่เทอร์มินัลด้านซ้ายและจะเข้าสู่การวนซ้ำที่ไม่มีที่สิ้นสุด
Example:
(1) A => Aα | β
(2) S => Aα | β
A => Sd(1) เป็นตัวอย่างของการเรียกซ้ำด้านซ้ายทันทีโดยที่ A คือสัญลักษณ์ที่ไม่ใช่เทอร์มินัลใด ๆ และαแทนสตริงของขั้วที่ไม่ใช่ขั้ว
(2) เป็นตัวอย่างของการเรียกซ้ำทางอ้อมด้านซ้าย
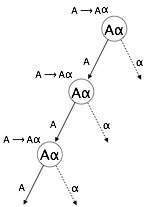
ตัวแยกวิเคราะห์จากบนลงล่างจะแยกวิเคราะห์ A ก่อนซึ่งในทางกลับกันจะให้สตริงที่ประกอบด้วย A เองและตัวแยกวิเคราะห์อาจวนซ้ำตลอดไป
การลบการเรียกซ้ำด้านซ้าย
วิธีหนึ่งในการลบการเรียกซ้ำทางซ้ายคือการใช้เทคนิคต่อไปนี้:
การผลิต
A => Aα | βถูกแปลงเป็นโปรดักชั่นต่อไปนี้
A => βA'
A'=> αA' | εสิ่งนี้ไม่ส่งผลกระทบต่อสตริงที่มาจากไวยากรณ์ แต่จะลบการเรียกซ้ำทางซ้ายทันที
วิธีที่สองคือการใช้อัลกอริทึมต่อไปนี้ซึ่งควรกำจัดการวนซ้ำทางซ้ายและทางอ้อมทั้งหมด
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai ⟹Aj
with Ai ⟹ δ1 | δ2 | δ3 |…|
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
ENDExample
ชุดการผลิต
S => Aα | β
A => Sdหลังจากใช้อัลกอริทึมข้างต้นควรเป็น
S => Aα | β
A => Aαd | βdจากนั้นลบการเรียกซ้ำทางซ้ายทันทีโดยใช้เทคนิคแรก
A => βdA'
A' => αdA' | εตอนนี้ไม่มีการผลิตใดที่มีการเรียกซ้ำด้านซ้ายทั้งทางตรงและทางอ้อม
แฟคตอริ่งด้านซ้าย
หากกฎการผลิตไวยากรณ์มากกว่าหนึ่งรายการมีสตริงคำนำหน้าทั่วไปตัวแยกวิเคราะห์จากบนลงล่างจะไม่สามารถเลือกได้ว่าควรใช้การผลิตใดในการแยกวิเคราะห์สตริงในมือ
Example
หากตัวแยกวิเคราะห์จากบนลงล่างพบการผลิตเช่น
A ⟹ αβ | α | …จากนั้นจึงไม่สามารถระบุได้ว่าต้องติดตามการผลิตใดเพื่อแยกวิเคราะห์สตริงเนื่องจากการผลิตทั้งสองเริ่มต้นจากเทอร์มินัลเดียวกัน (หรือไม่ใช่เทอร์มินัล) เพื่อขจัดความสับสนนี้เราใช้เทคนิคที่เรียกว่าการแยกตัวประกอบด้านซ้าย
การแยกตัวประกอบด้านซ้ายจะแปลงไวยากรณ์เพื่อให้เป็นประโยชน์สำหรับตัวแยกวิเคราะห์จากบนลงล่าง ในเทคนิคนี้เราทำการผลิตหนึ่งรายการสำหรับแต่ละคำนำหน้าทั่วไปและส่วนที่เหลือจะถูกเพิ่มโดยการผลิตใหม่
Example
โปรดักชั่นข้างต้นสามารถเขียนเป็นไฟล์
A => αA'
A'=> β | | …ตอนนี้ตัวแยกวิเคราะห์มีการผลิตเพียงรายการเดียวต่อคำนำหน้าซึ่งช่วยให้ตัดสินใจได้ง่ายขึ้น
ชุดแรกและชุดติดตาม
ส่วนสำคัญของการสร้างตาราง parser คือการสร้างชุดแรกและตามหลัง ชุดเหล่านี้สามารถระบุตำแหน่งจริงของเทอร์มินัลใดก็ได้ในการสร้าง สิ่งนี้ทำเพื่อสร้างตารางการแยกวิเคราะห์ที่การตัดสินใจแทนที่ T [A, t] = αด้วยกฎการผลิตบางส่วน
ชุดแรก
ชุดนี้สร้างขึ้นเพื่อให้ทราบว่าสัญลักษณ์เทอร์มินัลใดได้มาในตำแหน่งแรกโดย non-terminal ตัวอย่างเช่น,
α → t βนั่นคือαมาจาก t (เทอร์มินัล) ในตำแหน่งแรกสุด ดังนั้น t ∈ FIRST (α)
อัลกอริทึมสำหรับการคำนวณชุดแรก
ดูคำจำกัดความของชุด FIRST (α):
- ถ้าαเป็นเทอร์มินัลแล้ว FIRST (α) = {α}
- ถ้าαไม่ใช่เทอร์มินัลและα→ℇเป็นการผลิตดังนั้น FIRST (α) = {ℇ}
- ถ้าαเป็น non-terminal และα→ 1 2 3 … n และ FIRST () ใด ๆ มี t ดังนั้น t จะอยู่ใน FIRST (α)
ชุดแรกสามารถมองเห็นได้ดังนี้:
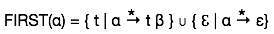
ติดตาม Set
ในทำนองเดียวกันเราคำนวณว่าสัญลักษณ์เทอร์มินัลใดตามหลังαที่ไม่ใช่เทอร์มินัลในกฎการผลิตทันที เราไม่ได้พิจารณาสิ่งที่ non-terminal สามารถสร้างได้ แต่เราจะเห็นว่าอะไรคือสัญลักษณ์เทอร์มินัลถัดไปที่ตามหลังการผลิตของ non-terminal
อัลกอริทึมสำหรับการคำนวณชุดติดตาม:
ถ้าαเป็นสัญลักษณ์เริ่มต้นให้ FOLLOW () = $
ถ้าαไม่ใช่เทอร์มินัลและมีการผลิตα→ AB FIRST (B) จะอยู่ใน FOLLOW (A) ยกเว้นℇ
ถ้าαไม่ใช่เทอร์มินัลและมีการผลิตα→ AB โดยที่ B ℇดังนั้น FOLLOW (A) จะอยู่ใน FOLLOW (α)
ชุดติดตามสามารถมองเห็นได้ดังนี้: FOLLOW (α) = {t | S * αt *}
ข้อ จำกัด ของเครื่องวิเคราะห์ไวยากรณ์
ตัววิเคราะห์ไวยากรณ์ได้รับอินพุตในรูปแบบของโทเค็นจากตัววิเคราะห์ศัพท์ ตัววิเคราะห์คำศัพท์มีหน้าที่รับผิดชอบต่อความถูกต้องของโทเค็นที่มาจากเครื่องวิเคราะห์ไวยากรณ์ เครื่องวิเคราะห์ไวยากรณ์มีข้อบกพร่องดังต่อไปนี้ -
- ไม่สามารถระบุได้ว่าโทเค็นถูกต้องหรือไม่
- ไม่สามารถระบุได้ว่ามีการประกาศโทเค็นก่อนที่จะใช้หรือไม่
- ไม่สามารถระบุได้ว่าโทเค็นถูกเตรียมใช้งานก่อนที่จะถูกใช้หรือไม่
- ไม่สามารถระบุได้ว่าการดำเนินการกับประเภทโทเค็นถูกต้องหรือไม่
งานเหล่านี้ทำได้โดยตัววิเคราะห์ความหมายซึ่งเราจะศึกษาในการวิเคราะห์ความหมาย