Seaborn - ความสัมพันธ์เชิงเส้น
โดยส่วนใหญ่เราใช้ชุดข้อมูลที่มีตัวแปรเชิงปริมาณหลายตัวและเป้าหมายของการวิเคราะห์มักจะเชื่อมโยงตัวแปรเหล่านั้นเข้าด้วยกัน ซึ่งสามารถทำได้ผ่านเส้นการถดถอย
ในขณะที่สร้างแบบจำลองการถดถอยเรามักจะตรวจสอบ multicollinearity,โดยที่เราต้องดูความสัมพันธ์ระหว่างการรวมกันของตัวแปรต่อเนื่องทั้งหมดและจะดำเนินการที่จำเป็นเพื่อลบ multicollinearity หากมีอยู่ ในกรณีเช่นนี้เทคนิคต่อไปนี้ช่วยได้
ฟังก์ชั่นในการวาดแบบจำลองการถดถอยเชิงเส้น
มีฟังก์ชั่นหลักสองอย่างใน Seaborn เพื่อแสดงภาพความสัมพันธ์เชิงเส้นที่กำหนดผ่านการถดถอย ฟังก์ชันเหล่านี้คือregplot() และ lmplot().
regplot กับ lmplot
| regplot | lmplot |
|---|---|
| ยอมรับตัวแปร x และ y ในรูปแบบต่างๆรวมถึงอาร์เรย์ numpy ธรรมดาวัตถุชุดหมีแพนด้าหรือเป็นการอ้างอิงถึงตัวแปรใน DataFrame ของแพนด้า | มีข้อมูลเป็นพารามิเตอร์ที่จำเป็นและต้องระบุตัวแปร x และ y เป็นสตริง รูปแบบข้อมูลนี้เรียกว่าข้อมูล "แบบยาว" |
ตอนนี้ให้เราวาดพล็อต
ตัวอย่าง
การพล็อต regplot แล้ว lmplot ด้วยข้อมูลเดียวกันในตัวอย่างนี้
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = df)
sb.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()เอาต์พุต
คุณสามารถเห็นความแตกต่างของขนาดระหว่างสองแปลง
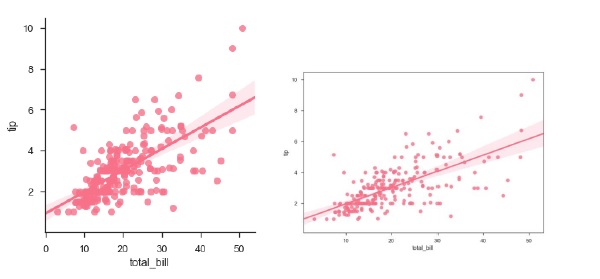
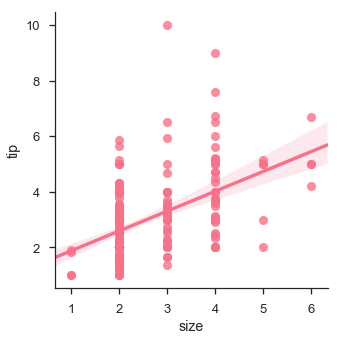
นอกจากนี้เรายังสามารถปรับให้พอดีกับการถดถอยเชิงเส้นเมื่อตัวแปรตัวใดตัวหนึ่งรับค่าไม่ต่อเนื่อง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.lmplot(x = "size", y = "tip", data = df)
plt.show()เอาต์พุต
ติดตั้งรุ่นต่างๆ
แบบจำลองการถดถอยเชิงเส้นอย่างง่ายที่ใช้ข้างต้นนั้นง่ายมากที่จะทำให้พอดี แต่ในกรณีส่วนใหญ่ข้อมูลไม่เป็นเชิงเส้นและวิธีการข้างต้นไม่สามารถสรุปเส้นการถดถอยได้
ให้เราใช้ชุดข้อมูลของ Anscombe กับพล็อตการถดถอย -
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x="x", y="y", data=df.query("dataset == 'I'"))
plt.show()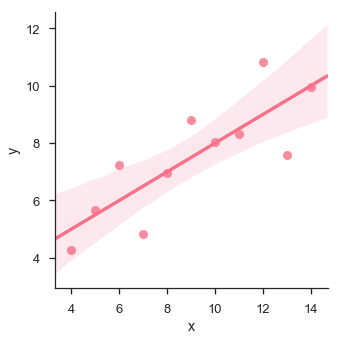
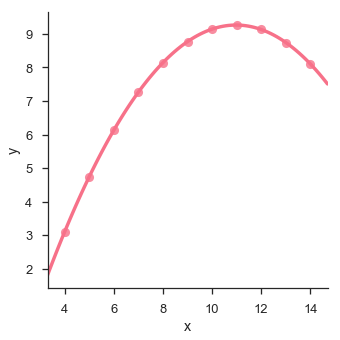
ในกรณีนี้ข้อมูลนี้เหมาะสำหรับแบบจำลองการถดถอยเชิงเส้นที่มีความแปรปรวนน้อยกว่า
ให้เราดูอีกตัวอย่างหนึ่งที่ข้อมูลมีค่าเบี่ยงเบนสูงซึ่งแสดงให้เห็นว่าบรรทัดที่เหมาะสมที่สุดนั้นไม่ดี
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"))
plt.show()เอาต์พุต
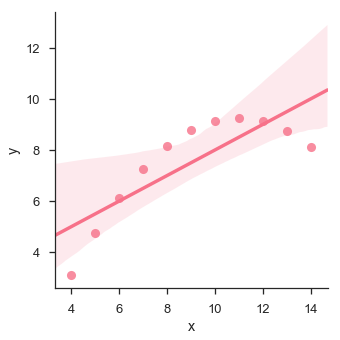
พล็อตแสดงความเบี่ยงเบนสูงของจุดข้อมูลจากเส้นถดถอย ลำดับที่สูงกว่าที่ไม่ใช่เชิงเส้นดังกล่าวสามารถมองเห็นได้โดยใช้lmplot() และ regplot()สิ่งเหล่านี้สามารถพอดีกับแบบจำลองการถดถอยพหุนามเพื่อสำรวจแนวโน้มที่ไม่เป็นเชิงเส้นในชุดข้อมูล -
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"),order = 2)
plt.show()เอาต์พุต