Seaborn - การประมาณทางสถิติ
ในสถานการณ์ส่วนใหญ่เราจัดการกับการประมาณค่าการกระจายทั้งหมดของข้อมูล แต่เมื่อพูดถึงการประมาณแนวโน้มส่วนกลางเราจำเป็นต้องมีวิธีที่เฉพาะเจาะจงในการสรุปการกระจาย ค่าเฉลี่ยและค่ามัธยฐานเป็นเทคนิคที่ใช้บ่อยมากในการประมาณแนวโน้มศูนย์กลางของการแจกแจง
ในพล็อตทั้งหมดที่เราเรียนรู้ในหัวข้อข้างต้นเราได้สร้างภาพของการกระจายทั้งหมด ตอนนี้ให้เราพูดคุยเกี่ยวกับแปลงที่เราสามารถประมาณแนวโน้มกลางของการกระจาย
พล็อตบาร์
barplot()แสดงความสัมพันธ์ระหว่างตัวแปรจัดหมวดหมู่และตัวแปรต่อเนื่อง ข้อมูลจะแสดงเป็นแท่งสี่เหลี่ยมโดยที่ความยาวของแถบแสดงถึงสัดส่วนของข้อมูลในหมวดหมู่นั้น
พล็อตแท่งแสดงถึงการประมาณแนวโน้มเข้าสู่ส่วนกลาง ให้เราใช้ชุดข้อมูล 'ไททานิก' เพื่อเรียนรู้พล็อตแท่ง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()เอาต์พุต
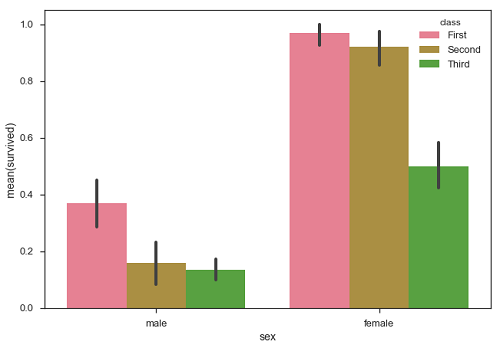
จากตัวอย่างข้างต้นเราจะเห็นว่าจำนวนผู้รอดชีวิตโดยเฉลี่ยของชายและหญิงในแต่ละคลาส จากพล็อตเราสามารถเข้าใจได้ว่ามีผู้หญิงรอดชีวิตมากกว่าเพศชาย ทั้งชายและหญิงจำนวนผู้รอดชีวิตมากขึ้นจากชั้นหนึ่ง
กรณีพิเศษใน barplot คือการไม่แสดงการสังเกตในแต่ละหมวดหมู่แทนที่จะคำนวณสถิติสำหรับตัวแปรที่สอง สำหรับสิ่งนี้เราใช้countplot().
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()เอาต์พุต
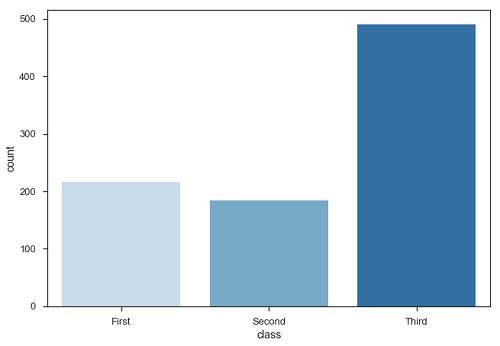
พล็อตบอกว่าจำนวนผู้โดยสารในชั้นสามสูงกว่าชั้นหนึ่งและชั้นสอง
พล็อตจุด
พล็อตจุดทำหน้าที่เหมือนกับพล็อตแท่ง แต่มีสไตล์ที่แตกต่างกัน แทนที่จะเป็นแถบเต็มค่าของการประมาณจะแสดงโดยจุดที่ความสูงหนึ่งบนแกนอื่น ๆ
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()เอาต์พุต
