Seaborn - คู่มือฉบับย่อ
ในโลกของ Analytics วิธีที่ดีที่สุดในการรับข้อมูลเชิงลึกคือการแสดงภาพข้อมูล ข้อมูลสามารถมองเห็นได้โดยแสดงเป็นพล็อตที่เข้าใจง่ายสำรวจและเข้าใจ ข้อมูลดังกล่าวช่วยในการดึงความสนใจขององค์ประกอบหลัก
ในการวิเคราะห์ชุดข้อมูลโดยใช้ Python เราใช้ Matplotlib ซึ่งเป็นไลบรารีการลงจุด 2D ที่ใช้กันอย่างแพร่หลาย ในทำนองเดียวกัน Seaborn เป็นไลบรารีการแสดงภาพใน Python มันถูกสร้างขึ้นบน Matplotlib
Seaborn Vs Matplotlib
สรุปได้ว่าถ้า Matplotlib“ พยายามทำให้สิ่งที่ง่ายง่ายและยากเป็นไปได้” Seaborn ก็พยายามที่จะสร้างชุดเรื่องยาก ๆ ที่กำหนดไว้อย่างชัดเจนให้เป็นเรื่องง่ายเช่นกัน”
Seaborn ช่วยแก้ไขปัญหาสำคัญสองประการที่ Matplotlib ประสบ ปัญหาคือ -
- พารามิเตอร์ Matplotlib เริ่มต้น
- การทำงานกับเฟรมข้อมูล
ในขณะที่ Seaborn ชมเชยและขยาย Matplotlib เส้นโค้งการเรียนรู้ค่อนข้างค่อยเป็นค่อยไป ถ้าคุณรู้จัก Matplotlib คุณก็มาถึง Seaborn ได้ครึ่งทางแล้ว
คุณสมบัติที่สำคัญของ Seaborn
Seaborn สร้างขึ้นจาก Matplotlib ไลบรารีการแสดงภาพหลักของ Python มีขึ้นเพื่อใช้เป็นส่วนเสริมไม่ใช่ทดแทน อย่างไรก็ตาม Seaborn มาพร้อมกับคุณสมบัติที่สำคัญบางอย่าง ให้เราดูบางส่วนของพวกเขาที่นี่ คุณสมบัติช่วยใน -
- สร้างขึ้นในธีมสำหรับการจัดแต่งทรงผมกราฟิก matplotlib
- แสดงภาพข้อมูลที่ไม่แปรผันและสองตัวแปร
- การติดตั้งและแสดงภาพแบบจำลองการถดถอยเชิงเส้น
- การพล็อตข้อมูลอนุกรมเวลาทางสถิติ
- Seaborn ทำงานได้ดีกับโครงสร้างข้อมูล NumPy และ Pandas
- มาพร้อมกับธีมในตัวสำหรับจัดแต่งทรงผมกราฟิก Matplotlib
ในกรณีส่วนใหญ่คุณจะยังคงใช้ Matplotlib สำหรับการวางแผนอย่างง่าย ขอแนะนำให้ใช้ความรู้ Matplotlib เพื่อปรับแต่งแผนการเริ่มต้นของ Seaborn
ในบทนี้เราจะพูดถึงการตั้งค่าสภาพแวดล้อมสำหรับ Seaborn ให้เราเริ่มต้นด้วยการติดตั้งและทำความเข้าใจวิธีการเริ่มต้นเมื่อเราก้าวไปข้างหน้า
การติดตั้ง Seaborn และเริ่มต้นใช้งาน
ในส่วนนี้เราจะเข้าใจขั้นตอนที่เกี่ยวข้องกับการติดตั้ง Seaborn
การใช้โปรแกรมติดตั้ง Pip
ในการติดตั้ง Seaborn รุ่นล่าสุดคุณสามารถใช้ pip -
pip install seabornสำหรับ Windows, Linux & Mac โดยใช้ Anaconda
อนาคอนดา (จาก https://www.anaconda.com/เป็นการแจกจ่าย Python ฟรีสำหรับ SciPy stack นอกจากนี้ยังสามารถใช้ได้กับ Linux และ Mac
นอกจากนี้ยังสามารถติดตั้งเวอร์ชันที่วางจำหน่ายโดยใช้ conda -
conda install seabornเพื่อติดตั้ง Seaborn เวอร์ชันพัฒนาได้โดยตรงจาก github
https://github.com/mwaskom/seaborn"
การพึ่งพา
พิจารณาการพึ่งพาต่อไปนี้ของ Seaborn -
- Python 2.7 หรือ 3.4+
- numpy
- scipy
- pandas
- matplotlib
ในบทนี้เราจะพูดถึงวิธีการนำเข้าชุดข้อมูลและไลบรารี เริ่มต้นด้วยการทำความเข้าใจวิธีการนำเข้าไลบรารี
การนำเข้าไลบรารี
ให้เราเริ่มต้นด้วยการนำเข้า Pandas ซึ่งเป็นไลบรารีที่ยอดเยี่ยมสำหรับการจัดการชุดข้อมูลเชิงสัมพันธ์ (รูปแบบตาราง) Seaborn มีประโยชน์เมื่อจัดการกับ DataFrames ซึ่งเป็นโครงสร้างข้อมูลที่ใช้กันอย่างแพร่หลายในการวิเคราะห์ข้อมูล
คำสั่งต่อไปนี้จะช่วยคุณนำเข้า Pandas -
# Pandas for managing datasets
import pandas as pdตอนนี้ให้เรานำเข้าไลบรารี Matplotlib ซึ่งช่วยให้เราปรับแต่งแปลงของเราได้
# Matplotlib for additional customization
from matplotlib import pyplot as pltเราจะนำเข้าไลบรารี Seaborn ด้วยคำสั่งต่อไปนี้ -
# Seaborn for plotting and styling
import seaborn as sbการนำเข้าชุดข้อมูล
เราได้นำเข้าไลบรารีที่ต้องการ ในส่วนนี้เราจะเข้าใจวิธีการนำเข้าชุดข้อมูลที่จำเป็น
Seaborn มาพร้อมกับชุดข้อมูลที่สำคัญบางอย่างในห้องสมุด เมื่อติดตั้ง Seaborn แล้วชุดข้อมูลจะดาวน์โหลดโดยอัตโนมัติ
คุณสามารถใช้ชุดข้อมูลเหล่านี้เพื่อการเรียนรู้ของคุณ ด้วยความช่วยเหลือของฟังก์ชันต่อไปนี้คุณสามารถโหลดชุดข้อมูลที่ต้องการได้
load_dataset()การนำเข้าข้อมูลเป็น Pandas DataFrame
ในส่วนนี้เราจะนำเข้าชุดข้อมูล ชุดข้อมูลนี้โหลดเป็น Pandas DataFrame ตามค่าเริ่มต้น หากมีฟังก์ชันใด ๆ ใน Pandas DataFrame ก็จะทำงานบน DataFrame นี้
โค้ดบรรทัดต่อไปนี้จะช่วยคุณนำเข้าชุดข้อมูล -
# Seaborn for plotting and styling
import seaborn as sb
df = sb.load_dataset('tips')
print df.head()บรรทัดด้านบนของรหัสจะสร้างผลลัพธ์ต่อไปนี้ -
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4หากต้องการดูชุดข้อมูลทั้งหมดที่มีอยู่ในไลบรารี Seaborn คุณสามารถใช้คำสั่งต่อไปนี้กับไฟล์ get_dataset_names() ฟังก์ชันดังแสดงด้านล่าง -
import seaborn as sb
print sb.get_dataset_names()บรรทัดโค้ดด้านบนจะส่งคืนรายการชุดข้อมูลที่มีให้เป็นเอาต์พุตต่อไปนี้
[u'anscombe', u'attention', u'brain_networks', u'car_crashes', u'dots',
u'exercise', u'flights', u'fmri', u'gammas', u'iris', u'planets', u'tips',
u'titanic']DataFramesจัดเก็บข้อมูลในรูปแบบของกริดสี่เหลี่ยมซึ่งสามารถดูข้อมูลได้อย่างง่ายดาย แต่ละแถวของตารางสี่เหลี่ยมมีค่าของอินสแตนซ์และแต่ละคอลัมน์ของกริดเป็นเวกเตอร์ที่เก็บข้อมูลสำหรับตัวแปรเฉพาะ ซึ่งหมายความว่าแถวของ DataFrame ไม่จำเป็นต้องมีค่าประเภทข้อมูลเดียวกันสามารถเป็นตัวเลขอักขระตรรกะ ฯลฯ DataFrames สำหรับ Python มาพร้อมกับไลบรารี Pandas และกำหนดเป็นโครงสร้างข้อมูลที่มีป้ายกำกับสองมิติ กับคอลัมน์ประเภทต่างๆที่อาจแตกต่างกัน
สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ DataFrames โปรดไปที่บทแนะนำเกี่ยวกับแพนด้าของเรา
การแสดงภาพข้อมูลเป็นขั้นตอนหนึ่งและการทำให้ข้อมูลที่แสดงภาพเป็นที่ชื่นชอบมากขึ้นเป็นอีกขั้น การแสดงภาพมีบทบาทสำคัญในการสื่อสารข้อมูลเชิงลึกเชิงปริมาณไปยังผู้ชมเพื่อดึงดูดความสนใจของพวกเขา
สุนทรียศาสตร์หมายถึงชุดของหลักการที่เกี่ยวข้องกับธรรมชาติและการชื่นชมความงามโดยเฉพาะอย่างยิ่งในงานศิลปะ การแสดงภาพเป็นศิลปะในการนำเสนอข้อมูลด้วยวิธีที่มีประสิทธิภาพและง่ายที่สุด
ไลบรารี Matplotlib สนับสนุนการปรับแต่งอย่างมาก แต่การรู้ว่าการตั้งค่าใดที่ต้องปรับแต่งเพื่อให้ได้พล็อตที่น่าสนใจและคาดหวังคือสิ่งที่ควรทราบเพื่อใช้ประโยชน์ ซึ่งแตกต่างจาก Matplotlib Seaborn มาพร้อมกับธีมที่กำหนดเองและอินเทอร์เฟซระดับสูงสำหรับปรับแต่งและควบคุมรูปลักษณ์ของตัวเลข Matplotlib
ตัวอย่าง
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
sinplot()
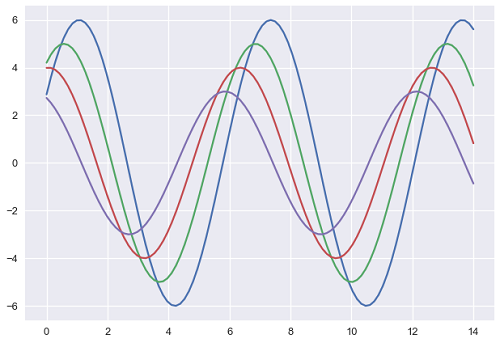
plt.show()นี่คือลักษณะของพล็อตที่มีค่าเริ่มต้น Matplotlib -

หากต้องการเปลี่ยนพล็อตเดียวกันเป็นค่าเริ่มต้นของ Seaborn ให้ใช้ไฟล์ set() ฟังก์ชัน -
ตัวอย่าง
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set()
sinplot()
plt.show()เอาต์พุต
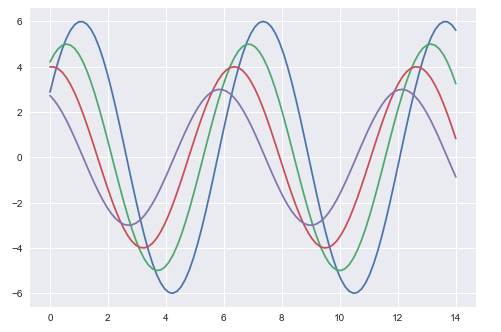
ตัวเลขสองตัวข้างต้นแสดงความแตกต่างในแผนเริ่มต้นของ Matplotlib และ Seaborn การแสดงข้อมูลเหมือนกัน แต่รูปแบบการเป็นตัวแทนจะแตกต่างกันไปทั้งสองอย่าง
โดยพื้นฐานแล้ว Seaborn จะแยกพารามิเตอร์ Matplotlib ออกเป็นสองกลุ่ม
- รูปแบบพล็อต
- พล็อตมาตราส่วน
รูปแบบของ Seaborn
อินเทอร์เฟซสำหรับการจัดการสไตล์คือ set_style(). การใช้ฟังก์ชันนี้คุณสามารถกำหนดธีมของพล็อตได้ ตามเวอร์ชันอัปเดตล่าสุดด้านล่างนี้คือห้าธีมที่มีให้
- Darkgrid
- Whitegrid
- Dark
- White
- Ticks
ให้เราลองใช้ชุดรูปแบบจากรายการดังกล่าวข้างต้น ธีมเริ่มต้นของพล็อตจะเป็นdarkgrid ซึ่งเราได้เห็นในตัวอย่างก่อนหน้านี้
ตัวอย่าง
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("whitegrid")
sinplot()
plt.show()เอาต์พุต
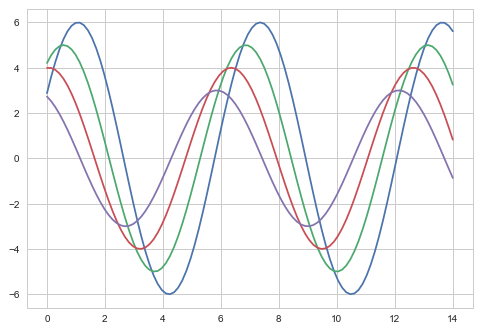
ความแตกต่างระหว่างสองแปลงข้างต้นคือสีพื้นหลัง
การถอดกระดูกสันหลังของแกน
ในธีมสีขาวและขีดเราสามารถลบแกนด้านบนและด้านขวาได้โดยใช้ despine() ฟังก์ชัน
ตัวอย่าง
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sinplot()
sb.despine()
plt.show()เอาต์พุต
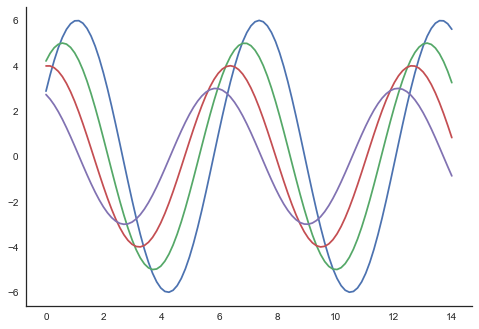
ในแปลงปกติเราใช้แกนซ้ายและแกนล่างเท่านั้น ใช้despine() ฟังก์ชันเราสามารถหลีกเลี่ยงกระดูกสันหลังด้านขวาและด้านบนที่ไม่จำเป็นซึ่งไม่รองรับใน Matplotlib
การลบล้างองค์ประกอบ
หากคุณต้องการปรับแต่งสไตล์ Seaborn คุณสามารถส่งพจนานุกรมพารามิเตอร์ไปยังไฟล์ set_style() ฟังก์ชัน พารามิเตอร์ที่มีให้ดูโดยใช้axes_style() ฟังก์ชัน
ตัวอย่าง
import seaborn as sb
print sb.axes_styleเอาต์พุต
{'axes.axisbelow' : False,
'axes.edgecolor' : 'white',
'axes.facecolor' : '#EAEAF2',
'axes.grid' : True,
'axes.labelcolor' : '.15',
'axes.linewidth' : 0.0,
'figure.facecolor' : 'white',
'font.family' : [u'sans-serif'],
'font.sans-serif' : [u'Arial', u'Liberation
Sans', u'Bitstream Vera Sans', u'sans-serif'],
'grid.color' : 'white',
'grid.linestyle' : u'-',
'image.cmap' : u'Greys',
'legend.frameon' : False,
'legend.numpoints' : 1,
'legend.scatterpoints': 1,
'lines.solid_capstyle': u'round',
'text.color' : '.15',
'xtick.color' : '.15',
'xtick.direction' : u'out',
'xtick.major.size' : 0.0,
'xtick.minor.size' : 0.0,
'ytick.color' : '.15',
'ytick.direction' : u'out',
'ytick.major.size' : 0.0,
'ytick.minor.size' : 0.0}การแก้ไขค่าของพารามิเตอร์ใด ๆ จะเปลี่ยนรูปแบบการลงจุด
ตัวอย่าง
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()เอาต์พุต
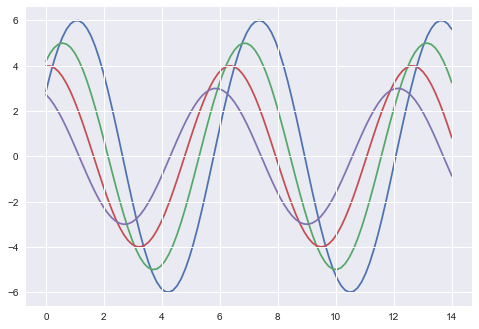
องค์ประกอบแผนภาพมาตราส่วน
นอกจากนี้เรายังมีการควบคุมองค์ประกอบของพล็อตและสามารถควบคุมขนาดของพล็อตโดยใช้ set_context()ฟังก์ชัน เรามีเทมเพลตที่ตั้งไว้ล่วงหน้าสี่แบบสำหรับบริบทตามขนาดสัมพัทธ์บริบทมีชื่อดังนี้
- Paper
- Notebook
- Talk
- Poster
โดยค่าเริ่มต้นบริบทจะถูกตั้งค่าเป็นสมุดบันทึก และถูกใช้ในแปลงข้างต้น
ตัวอย่าง
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()เอาต์พุต
ขนาดผลผลิตของแปลงจริงมีขนาดใหญ่กว่าเมื่อเทียบกับแปลงข้างต้น
Note - เนื่องจากการปรับขนาดภาพบนหน้าเว็บของเราคุณอาจพลาดความแตกต่างที่แท้จริงในตัวอย่างของเรา
สีมีบทบาทสำคัญกว่าด้านอื่น ๆ ในการแสดงภาพ เมื่อใช้อย่างมีประสิทธิภาพสีจะเพิ่มมูลค่าให้กับพล็อตมากขึ้น จานสีหมายถึงพื้นผิวเรียบที่จิตรกรจัดเรียงและผสมสี
การสร้างจานสี
Seaborn มีฟังก์ชันที่เรียกว่า color_palette()ซึ่งสามารถใช้เพื่อเพิ่มสีสันให้กับแปลงและเพิ่มคุณค่าทางสุนทรียะให้กับมันได้
การใช้งาน
seaborn.color_palette(palette = None, n_colors = None, desat = None)พารามิเตอร์
ตารางต่อไปนี้แสดงรายการพารามิเตอร์สำหรับการสร้างจานสี -
| ซีเนียร์ | Palatte และคำอธิบาย |
|---|---|
| 1 | n_colors จำนวนสีในจานสี หากไม่มีค่าเริ่มต้นจะขึ้นอยู่กับวิธีการระบุจานสี ตามค่าเริ่มต้นค่าของn_colors มี 6 สี |
| 2 | desat สัดส่วนที่จะไม่อิ่มตัวแต่ละสี |
กลับ
Return หมายถึงรายการสิ่งที่เพิ่มขึ้น RGB ต่อไปนี้เป็นจานสี Seaborn ที่หาซื้อได้ง่าย -
- Deep
- Muted
- Bright
- Pastel
- Dark
- Colorblind
นอกจากนี้ยังสามารถสร้างจานสีใหม่
เป็นการยากที่จะตัดสินใจว่าควรใช้จานสีใดสำหรับชุดข้อมูลที่กำหนดโดยไม่ทราบลักษณะของข้อมูล เมื่อตระหนักถึงเรื่องนี้เราจะแบ่งประเภทของวิธีการใช้งานต่างๆcolor_palette() ประเภท -
- qualitative
- sequential
- diverging
เรามีฟังก์ชั่นอื่น seaborn.palplot()ซึ่งเกี่ยวข้องกับจานสี ฟังก์ชันนี้จะพล็อตจานสีเป็นอาร์เรย์แนวนอน เราจะทราบข้อมูลเพิ่มเติมเกี่ยวกับseaborn.palplot() ในตัวอย่างต่อไป
จานสีเชิงคุณภาพ
จานสีเชิงคุณภาพหรือเชิงหมวดหมู่เหมาะสมที่สุดในการพล็อตข้อมูลเชิงหมวดหมู่
ตัวอย่าง
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(current_palette)
plt.show()เอาต์พุต

เราไม่ได้ส่งผ่านพารามิเตอร์ใด ๆ ใน color_palette();โดยค่าเริ่มต้นเราจะเห็น 6 สี คุณสามารถดูจำนวนสีที่ต้องการได้โดยส่งค่าไปที่ไฟล์n_colorsพารามิเตอร์. ที่นี่palplot() ใช้เพื่อพล็อตอาร์เรย์ของสีในแนวนอน
จานสีตามลำดับ
พล็อตแบบลำดับเหมาะสำหรับการแสดงการกระจายของข้อมูลตั้งแต่ค่าต่ำกว่าสัมพัทธ์ไปจนถึงค่าที่สูงกว่าภายในช่วง
การเพิ่มอักขระเพิ่มเติมเข้ากับสีที่ส่งผ่านไปยังพารามิเตอร์สีจะพล็อตพล็อตตามลำดับ
ตัวอย่าง
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("Greens"))
plt.show()
Note −เราจำเป็นต้องต่อท้าย 's' กับพารามิเตอร์เช่น 'Greens' ในตัวอย่างด้านบน
การเปลี่ยนจานสี
การเปลี่ยนจานสีใช้สองสีที่แตกต่างกัน แต่ละสีแสดงถึงความแปรผันของค่าตั้งแต่จุดร่วมในทิศทางใดทิศทางหนึ่ง
สมมติว่าการพล็อตข้อมูลตั้งแต่ -1 ถึง 1 ค่าตั้งแต่ -1 ถึง 0 ใช้สีเดียวและ 0 ถึง +1 ใช้สีอื่น
โดยค่าเริ่มต้นค่าจะอยู่กึ่งกลางจากศูนย์ คุณสามารถควบคุมได้ด้วยศูนย์พารามิเตอร์โดยการส่งผ่านค่า
ตัวอย่าง
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("BrBG", 7))
plt.show()เอาต์พุต

การตั้งค่าจานสีเริ่มต้น
ฟังก์ชั่น color_palette() มีเพื่อนที่เรียกว่า set_palette()ความสัมพันธ์ระหว่างพวกเขาคล้ายกับคู่ที่กล่าวถึงในบทสุนทรียศาสตร์ อาร์กิวเมนต์จะเหมือนกันสำหรับทั้งสองอย่างset_palette() และ color_palette(), แต่พารามิเตอร์ Matplotlib ดีฟอลต์มีการเปลี่ยนแปลงเพื่อให้ใช้จานสีสำหรับพล็อตทั้งหมด
ตัวอย่าง
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sb.set_palette("husl")
sinplot()
plt.show()เอาต์พุต

การพล็อตการกระจาย Univariate
การกระจายข้อมูลเป็นสิ่งสำคัญที่สุดที่เราต้องเข้าใจในขณะที่วิเคราะห์ข้อมูล ที่นี่เราจะดูว่าทะเลบอร์นช่วยเราในการทำความเข้าใจการกระจายข้อมูลที่ไม่แปรผันได้อย่างไร
ฟังก์ชัน distplot()เป็นวิธีที่สะดวกที่สุดในการดูการกระจายแบบ Univariate อย่างรวดเร็ว ฟังก์ชันนี้จะลงจุดฮิสโตแกรมที่เหมาะกับการประมาณความหนาแน่นของเคอร์เนลของข้อมูล
การใช้งาน
seaborn.distplot()พารามิเตอร์
ตารางต่อไปนี้แสดงรายการพารามิเตอร์และคำอธิบาย -
| ซีเนียร์ | พารามิเตอร์และคำอธิบาย |
|---|---|
| 1 | data ซีรี่ส์อาร์เรย์ 1d หรือรายการ |
| 2 | bins ข้อมูลจำเพาะของถังขยะ |
| 3 | hist บูล |
| 4 | kde บูล |
สิ่งเหล่านี้เป็นพารามิเตอร์พื้นฐานและสำคัญที่ต้องพิจารณา
ฮิสโตแกรมแสดงถึงการกระจายของข้อมูลโดยการสร้างถังขยะตามช่วงของข้อมูลจากนั้นวาดแถบเพื่อแสดงจำนวนการสังเกตที่อยู่ในแต่ละถัง
Seaborn มาพร้อมกับชุดข้อมูลบางชุดและเราได้ใช้ชุดข้อมูลไม่กี่ชุดในบทก่อนหน้า เราได้เรียนรู้วิธีโหลดชุดข้อมูลและวิธีค้นหารายการชุดข้อมูลที่มี
Seaborn มาพร้อมกับชุดข้อมูลบางชุดและเราได้ใช้ชุดข้อมูลไม่กี่ชุดในบทก่อนหน้า เราได้เรียนรู้วิธีโหลดชุดข้อมูลและวิธีค้นหารายการชุดข้อมูลที่มี
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = False)
plt.show()เอาต์พุต
ที่นี่ kdeตั้งค่าสถานะเป็น False ด้วยเหตุนี้การแสดงพล็อตการประมาณค่าเคอร์เนลจะถูกลบออกและมีการพล็อตเฉพาะฮิสโตแกรม
การประมาณความหนาแน่นของเคอร์เนล (KDE) เป็นวิธีการประมาณฟังก์ชันความหนาแน่นของความน่าจะเป็นของตัวแปรสุ่มแบบต่อเนื่อง ใช้สำหรับการวิเคราะห์แบบไม่ใช้พารามิเตอร์
การตั้งค่า hist ตั้งค่าสถานะเป็น False in distplot จะได้พล็อตการประมาณความหนาแน่นของเคอร์เนล
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],hist=False)
plt.show()เอาต์พุต
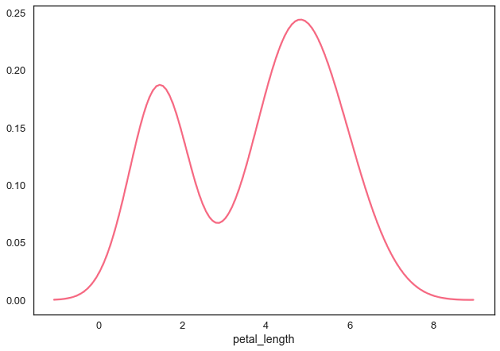
การกระจายพารามิเตอร์ที่เหมาะสม
distplot() ใช้เพื่อแสดงภาพการแจกแจงพารามิเตอร์ของชุดข้อมูล
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'])
plt.show()เอาต์พุต
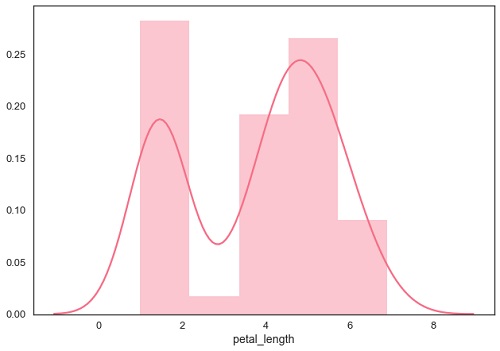
การพล็อตการกระจายแบบสองตัวแปร
Bivariate Distribution ใช้เพื่อกำหนดความสัมพันธ์ระหว่างสองตัวแปร ส่วนใหญ่เกี่ยวข้องกับความสัมพันธ์ระหว่างสองตัวแปรและการทำงานของตัวแปรหนึ่งเมื่อเทียบกับอีกตัวแปรหนึ่ง
วิธีที่ดีที่สุดในการวิเคราะห์ Bivariate Distribution ในทะเลคือการใช้ไฟล์ jointplot() ฟังก์ชัน
Jointplot สร้างตัวเลขหลายแผงที่แสดงความสัมพันธ์สองตัวแปรระหว่างสองตัวแปรและการแจกแจงแบบไม่แปรผันของแต่ละตัวแปรบนแกนที่แยกกัน
พล็อตกระจาย
แผนภาพการกระจายเป็นวิธีที่สะดวกที่สุดในการแสดงภาพการกระจายที่การสังเกตแต่ละครั้งแสดงในรูปแบบสองมิติผ่านแกน x และ y
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()เอาต์พุต
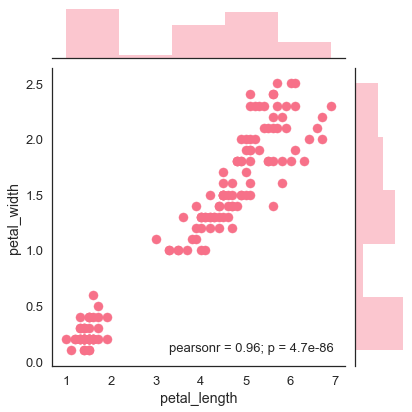
รูปด้านบนแสดงความสัมพันธ์ระหว่าง petal_length และ petal_widthในข้อมูล Iris แนวโน้มในพล็อตบอกว่ามีความสัมพันธ์เชิงบวกระหว่างตัวแปรที่ศึกษา
พล็อต Hexbin
Hexagonal binning ใช้ในการวิเคราะห์ข้อมูลแบบสองตัวแปรเมื่อข้อมูลมีความหนาแน่นเบาบางกล่าวคือเมื่อข้อมูลกระจัดกระจายมากและยากที่จะวิเคราะห์ผ่าน scatterplots
พารามิเตอร์เพิ่มเติมที่เรียกว่า 'ชนิด' และค่า 'ฐานสิบหก' จะแสดงพล็อต hexbin
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()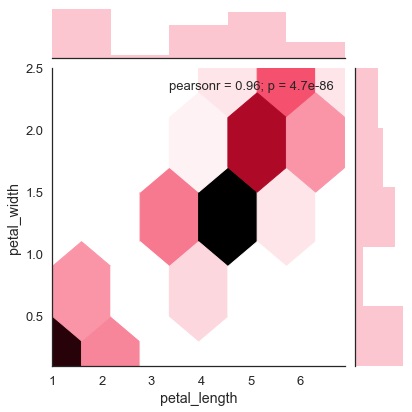
การประมาณความหนาแน่นของเคอร์เนล
การประมาณความหนาแน่นของเคอร์เนลเป็นวิธีที่ไม่ใช่พารามิเตอร์ในการประมาณการแจกแจงของตัวแปร ในทะเลเราสามารถพล็อต kde โดยใช้jointplot().
ส่งค่า 'kde' ไปยังชนิดพารามิเตอร์เพื่อลงจุดเคอร์เนลพล็อต
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()เอาต์พุต
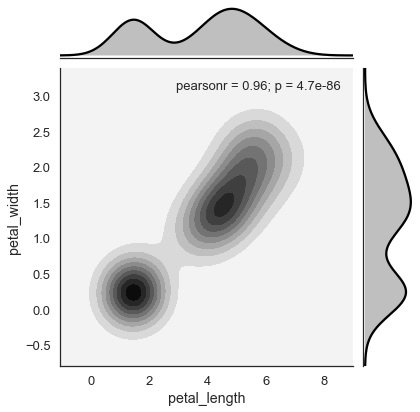
ชุดข้อมูลภายใต้การศึกษาแบบเรียลไทม์มีตัวแปรมากมาย ในกรณีเช่นนี้ควรวิเคราะห์ความสัมพันธ์ระหว่างตัวแปรแต่ละตัวและทุกตัวแปร การพล็อตการกระจายแบบสองตัวแปรสำหรับชุดค่าผสม (n, 2) จะเป็นกระบวนการที่ซับซ้อนและต้องใช้เวลามาก
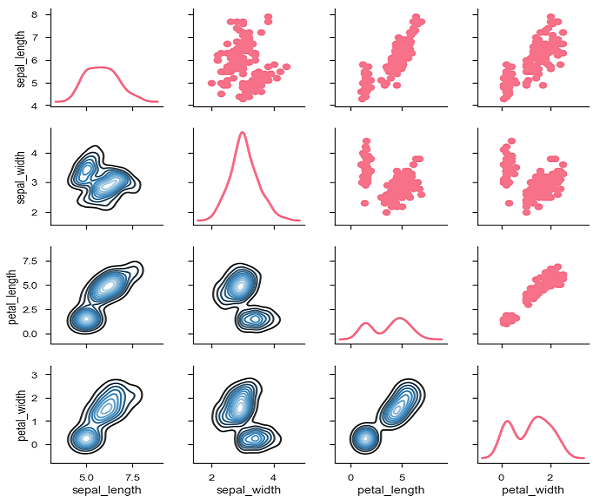
ในการลงจุดการแจกแจงแบบทวิภาคีหลายคู่ในชุดข้อมูลคุณสามารถใช้ pairplot()ฟังก์ชัน สิ่งนี้แสดงความสัมพันธ์สำหรับ (n, 2) การรวมกันของตัวแปรใน DataFrame เป็นเมทริกซ์ของพล็อตและพล็อตแนวทแยงเป็นพล็อตที่ไม่แปรผัน
แกน
ในส่วนนี้เราจะเรียนรู้ว่าแกนคืออะไรการใช้งานพารามิเตอร์และอื่น ๆ
การใช้งาน
seaborn.pairplot(data,…)พารามิเตอร์
ตารางต่อไปนี้แสดงรายการพารามิเตอร์สำหรับแกน -
| ซีเนียร์ | พารามิเตอร์และคำอธิบาย |
|---|---|
| 1 | data ดาต้าเฟรม |
| 2 | hue ตัวแปรในข้อมูลเพื่อแมปลักษณะของพล็อตกับสีต่างๆ |
| 3 | palette ชุดสีสำหรับการแมปตัวแปรสี |
| 4 | kind ชนิดของพล็อตสำหรับความสัมพันธ์ที่ไม่ใช่ตัวตน {'scatter', 'reg'} |
| 5 | diag_kind ชนิดของพล็อตย่อยในแนวทแยง {'hist', 'kde'} |
ยกเว้นข้อมูลพารามิเตอร์อื่น ๆ ทั้งหมดเป็นทางเลือก มีพารามิเตอร์อื่น ๆ อีกเล็กน้อยที่pairplotยอมรับได้. ที่กล่าวมาข้างต้นมักใช้ params
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()เอาต์พุต
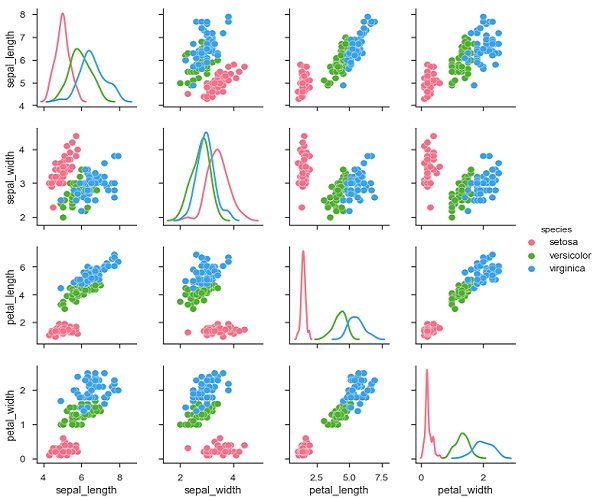
เราสามารถสังเกตการเปลี่ยนแปลงในแต่ละแปลง พล็อตอยู่ในรูปแบบเมทริกซ์โดยที่ชื่อแถวแสดงถึงแกน x และชื่อคอลัมน์แทนแกน y
แปลงทแยงมุมเป็นแปลงความหนาแน่นของเคอร์เนลโดยที่อีกแปลงเป็นแปลงกระจายตามที่กล่าวไว้
ในบทก่อนหน้านี้เราได้เรียนรู้เกี่ยวกับการกระจายพล็อตเฮกซินพล็อตและพล็อต kde ซึ่งใช้ในการวิเคราะห์ตัวแปรต่อเนื่องภายใต้การศึกษา พล็อตเหล่านี้ไม่เหมาะสมเมื่อตัวแปรภายใต้การศึกษาเป็นหมวดหมู่
เมื่อตัวแปรใดตัวแปรหนึ่งหรือทั้งสองตัวแปรภายใต้การศึกษาเป็นหมวดหมู่เราจะใช้พล็อตเช่น striplot (), swarmplot () ฯลฯ Seaborn มีอินเทอร์เฟซให้ทำเช่นนั้น
พล็อตการกระจายตามหมวดหมู่
ในส่วนนี้เราจะเรียนรู้เกี่ยวกับแผนการกระจายแบบแบ่งหมวดหมู่
เปลื้องผ้า ()
stripplot () ถูกใช้เมื่อตัวแปรใดตัวแปรหนึ่งที่อยู่ระหว่างการศึกษามีลักษณะเป็นหมวดหมู่ แสดงข้อมูลตามลำดับที่เรียงตามแกนใดแกนหนึ่ง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df)
plt.show()เอาต์พุต
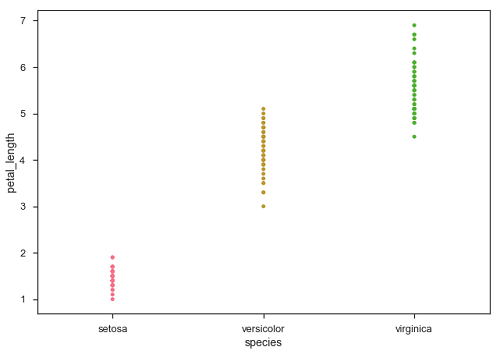
ในพล็อตข้างต้นเราจะเห็นความแตกต่างอย่างชัดเจน petal_lengthในแต่ละสายพันธุ์ แต่ปัญหาสำคัญของพล็อตการกระจายข้างต้นคือจุดบนพล็อตกระจายจะทับซ้อนกัน เราใช้พารามิเตอร์ 'Jitter' เพื่อจัดการกับสถานการณ์แบบนี้
Jitter เพิ่มสัญญาณรบกวนแบบสุ่มให้กับข้อมูล พารามิเตอร์นี้จะปรับตำแหน่งตามแกนหมวดหมู่
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df, jitter = Ture)
plt.show()เอาต์พุต
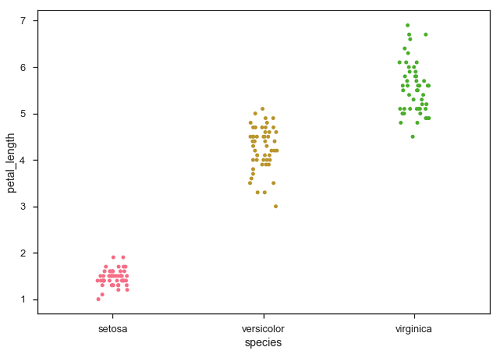
เดี๋ยวนี้การกระจายจุดสามารถมองเห็นได้ง่าย
Swarmplot ()
อีกทางเลือกหนึ่งที่สามารถใช้แทน 'Jitter' ได้คือฟังก์ชัน swarmplot(). ฟังก์ชั่นนี้จะวางตำแหน่งของจุดกระจายแต่ละจุดบนแกนหมวดหมู่และหลีกเลี่ยงจุดที่ทับซ้อนกัน -
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()เอาต์พุต
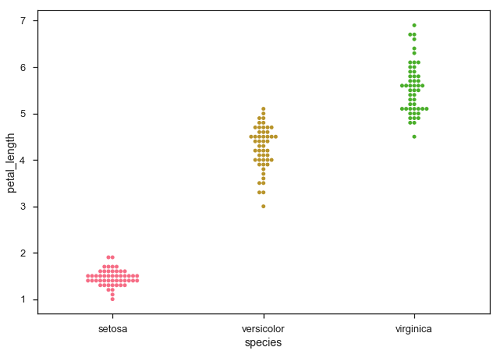
ในรูปแบบการกระจายตามหมวดหมู่ซึ่งเราได้จัดการในบทก่อนหน้านี้แนวทางจะ จำกัด ในข้อมูลที่สามารถให้ได้เกี่ยวกับการกระจายของค่าในแต่ละหมวดหมู่ ตอนนี้จะไปต่อให้เราดูว่าอะไรสามารถอำนวยความสะดวกให้เราในการเปรียบเทียบกับในหมวดหมู่
พล็อตกล่อง
Boxplot เป็นวิธีที่สะดวกในการแสดงภาพการกระจายข้อมูลผ่านควอไทล์
พล็อตกล่องมักจะมีเส้นแนวตั้งยื่นออกมาจากกล่องซึ่งเรียกว่าหนวด หนวดเหล่านี้บ่งบอกถึงความแปรปรวนนอกควอไทล์บนและล่างดังนั้น Box Plots จึงถูกเรียกว่าbox-and-whisker พล็อตและ box-and-whisker แผนภาพ ค่าผิดปกติใด ๆ ในข้อมูลจะถูกพล็อตเป็นแต่ละจุด
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()เอาต์พุต
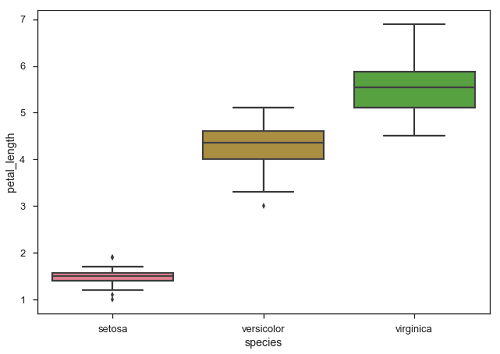
จุดบนพล็อตระบุค่าผิดปกติ
แปลงไวโอลิน
พลอตไวโอลินคือการรวมกันของพล็อตกล่องที่มีการประมาณความหนาแน่นของเคอร์เนล ดังนั้นพล็อตเหล่านี้จึงง่ายต่อการวิเคราะห์และทำความเข้าใจการกระจายของข้อมูล
ให้เราใช้ชุดข้อมูลเคล็ดลับที่เรียกว่าเพื่อเรียนรู้เพิ่มเติมเกี่ยวกับแปลงไวโอลิน ชุดข้อมูลนี้ประกอบด้วยข้อมูลที่เกี่ยวข้องกับเคล็ดลับที่ลูกค้าให้ไว้ในร้านอาหาร
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill", data=df)
plt.show()เอาต์พุต
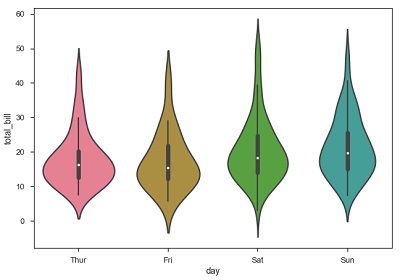
ค่าควอไทล์และมัสสุจากบ็อกซ์พล็อตจะแสดงอยู่ภายในไวโอลิน เนื่องจากพล็อตไวโอลินใช้ KDE ส่วนที่กว้างขึ้นของไวโอลินจะบ่งบอกถึงความหนาแน่นที่สูงขึ้นและพื้นที่แคบแสดงถึงความหนาแน่นที่ค่อนข้างต่ำ ช่วง Inter-Quartile ใน boxplot และส่วนที่มีความหนาแน่นสูงกว่าใน kde จะตกอยู่ในภูมิภาคเดียวกันของแต่ละประเภทของไวโอลิน
พล็อตด้านบนแสดงการแจกแจงของ total_bill ในสี่วันของสัปดาห์ แต่นอกเหนือจากนั้นหากเราต้องการดูว่าการกระจายมีพฤติกรรมอย่างไรในเรื่องเพศให้สำรวจในตัวอย่างด้านล่าง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill",hue = 'sex', data = df)
plt.show()เอาต์พุต

ตอนนี้เราสามารถเห็นพฤติกรรมการใช้จ่ายระหว่างเพศชายและเพศหญิงได้อย่างชัดเจน เราสามารถพูดได้ง่ายๆว่าผู้ชายทำเงินได้มากกว่าผู้หญิงโดยดูที่พล็อต
และหากตัวแปรสีมีเพียงสองคลาสเราสามารถตกแต่งพล็อตให้สวยงามโดยการแยกไวโอลินแต่ละตัวออกเป็นสองตัวแทนที่จะเป็นไวโอลินสองตัวในวันที่กำหนด ส่วนใดส่วนหนึ่งของไวโอลินอ้างถึงแต่ละคลาสในตัวแปร hue
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y="total_bill",hue = 'sex', data = df)
plt.show()เอาต์พุต

ในสถานการณ์ส่วนใหญ่เราจัดการกับการประมาณค่าการกระจายทั้งหมดของข้อมูล แต่เมื่อพูดถึงการประมาณแนวโน้มส่วนกลางเราจำเป็นต้องมีวิธีที่เฉพาะเจาะจงในการสรุปการกระจาย ค่าเฉลี่ยและค่ามัธยฐานเป็นเทคนิคที่ใช้บ่อยมากในการประมาณแนวโน้มศูนย์กลางของการแจกแจง
ในพล็อตทั้งหมดที่เราเรียนรู้ในหัวข้อข้างต้นเราได้สร้างภาพของการกระจายทั้งหมด ตอนนี้ให้เราพูดคุยเกี่ยวกับแปลงที่เราสามารถประมาณแนวโน้มกลางของการกระจาย
พล็อตบาร์
barplot()แสดงความสัมพันธ์ระหว่างตัวแปรจัดหมวดหมู่และตัวแปรต่อเนื่อง ข้อมูลจะแสดงเป็นแท่งสี่เหลี่ยมโดยที่ความยาวของแถบแสดงถึงสัดส่วนของข้อมูลในหมวดหมู่นั้น
พล็อตแท่งแสดงถึงการประมาณแนวโน้มเข้าสู่ส่วนกลาง ให้เราใช้ชุดข้อมูล 'ไททานิก' เพื่อเรียนรู้พล็อตแท่ง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()เอาต์พุต
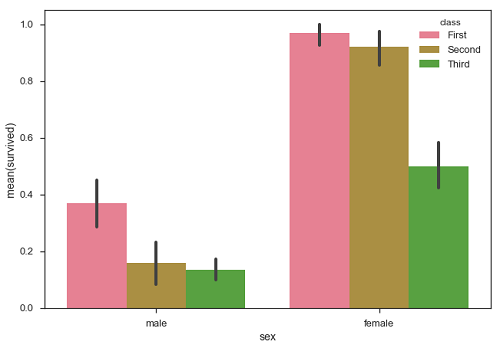
จากตัวอย่างข้างต้นเราจะเห็นว่าจำนวนผู้รอดชีวิตโดยเฉลี่ยของชายและหญิงในแต่ละคลาส จากพล็อตเราสามารถเข้าใจได้ว่ามีผู้หญิงรอดชีวิตมากกว่าเพศชาย ทั้งชายและหญิงจำนวนผู้รอดชีวิตมากขึ้นจากชั้นหนึ่ง
กรณีพิเศษใน barplot คือการไม่แสดงการสังเกตในแต่ละประเภทแทนที่จะคำนวณสถิติสำหรับตัวแปรที่สอง สำหรับสิ่งนี้เราใช้countplot().
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()เอาต์พุต
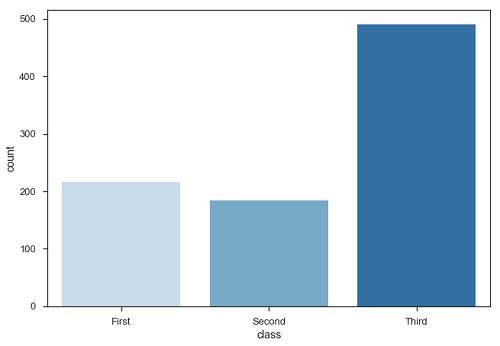
พล็อตบอกว่าจำนวนผู้โดยสารในชั้นสามสูงกว่าชั้นหนึ่งและชั้นสอง
พล็อตจุด
พล็อตจุดทำหน้าที่เหมือนกับพล็อตแท่ง แต่มีสไตล์ที่แตกต่าง แทนที่จะเป็นแถบเต็มค่าของการประมาณจะแสดงโดยจุดที่ความสูงหนึ่งบนแกนอีกแกนหนึ่ง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()เอาต์พุต

ควรใช้ชุดข้อมูลแบบ "long-from" หรือ "tidy" เสมอ แต่ในบางครั้งเมื่อเราไม่มีตัวเลือกใด ๆ แทนที่จะใช้ชุดข้อมูล "รูปแบบกว้าง" ฟังก์ชันเดียวกันนี้ยังสามารถนำไปใช้กับข้อมูล "รูปแบบกว้าง" ในรูปแบบต่างๆได้เช่น Pandas Data Frames หรือ NumPy สองมิติ อาร์เรย์ ออบเจ็กต์เหล่านี้ควรถูกส่งผ่านไปยังพารามิเตอร์ข้อมูลโดยตรงโดยต้องระบุตัวแปร x และ y เป็นสตริง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()เอาต์พุต
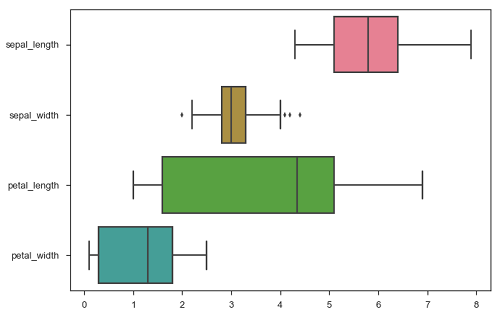
นอกจากนี้ฟังก์ชันเหล่านี้ยอมรับเวกเตอร์ของวัตถุ Pandas หรือ NumPy แทนที่จะเป็นตัวแปรใน DataFrame
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()เอาต์พุต
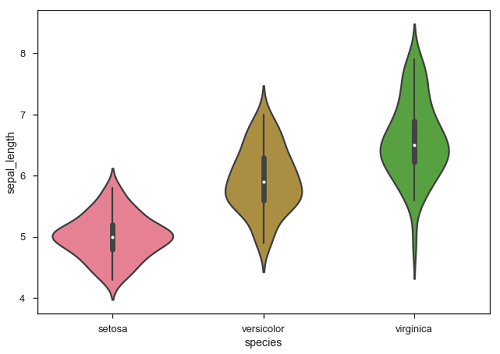
ข้อได้เปรียบที่สำคัญของการใช้ Seaborn สำหรับนักพัฒนาหลายคนในโลก Python คือเนื่องจากสามารถใช้วัตถุ DataFrame ของแพนด้าเป็นพารามิเตอร์ได้
ข้อมูลหมวดหมู่เราสามารถมองเห็นได้โดยใช้สองแปลงคุณสามารถใช้ฟังก์ชัน pointplot()หรือฟังก์ชันระดับสูงกว่า factorplot().
Factorplot
Factorplot วาดพล็อตหมวดหมู่บน FacetGrid การใช้พารามิเตอร์ 'kind' เราสามารถเลือกพล็อตเช่น boxplot, violinplot, barplot และ stripplot FacetGrid ใช้ pointplot ตามค่าเริ่มต้น
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = pulse", hue = "kind",data = df);
plt.show()เอาต์พุต
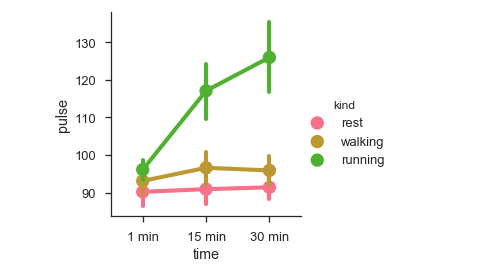
เราสามารถใช้พล็อตที่แตกต่างกันเพื่อแสดงภาพข้อมูลเดียวกันโดยใช้ไฟล์ kind พารามิเตอร์.
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin',data = df);
plt.show()เอาต์พุต
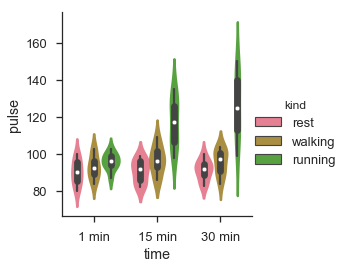
ใน factorplot ข้อมูลจะถูกพล็อตบนกริดด้าน
Facet Grid คืออะไร?
Facet grid สร้างเมทริกซ์ของแผงที่กำหนดโดยแถวและคอลัมน์โดยการหารตัวแปร เนื่องจากแผงควบคุมพล็อตเดียวจึงดูเหมือนหลายแปลง การวิเคราะห์ชุดค่าผสมทั้งหมดในตัวแปรแยกสองตัวมีประโยชน์มาก
ให้เราเห็นภาพคำจำกัดความข้างต้นด้วยตัวอย่าง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin', col = "diet", data = df);
plt.show()เอาต์พุต
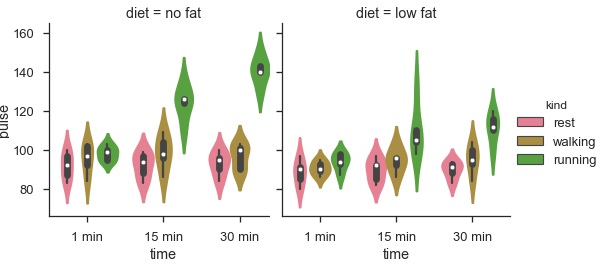
ข้อดีของการใช้ Facet คือเราสามารถใส่ตัวแปรอื่นเข้าไปในพล็อตได้ พล็อตข้างต้นแบ่งออกเป็นสองพล็อตตามตัวแปรที่สามที่เรียกว่า 'diet' โดยใช้พารามิเตอร์ 'col'
เราสามารถสร้างคอลัมน์หลายแง่มุมและจัดแนวให้ตรงกับแถวของตาราง -
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.factorplot("alive", col = "deck", col_wrap = 3,data = df[df.deck.notnull()],kind = "count")
plt.show()เอาท์พุท
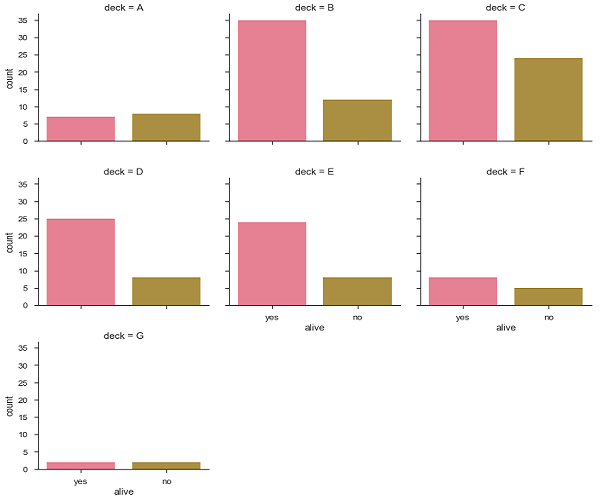
โดยส่วนใหญ่เราใช้ชุดข้อมูลที่มีตัวแปรเชิงปริมาณหลายตัวและเป้าหมายของการวิเคราะห์มักจะเชื่อมโยงตัวแปรเหล่านั้นเข้าด้วยกัน ซึ่งสามารถทำได้ผ่านเส้นการถดถอย
ในขณะที่สร้างแบบจำลองการถดถอยเรามักจะตรวจสอบ multicollinearity,โดยที่เราต้องดูความสัมพันธ์ระหว่างการรวมกันของตัวแปรต่อเนื่องทั้งหมดและจะดำเนินการที่จำเป็นเพื่อลบ multicollinearity หากมีอยู่ ในกรณีเช่นนี้เทคนิคต่อไปนี้ช่วยได้
ฟังก์ชั่นในการวาดแบบจำลองการถดถอยเชิงเส้น
มีฟังก์ชั่นหลักสองอย่างใน Seaborn เพื่อแสดงภาพความสัมพันธ์เชิงเส้นที่กำหนดผ่านการถดถอย ฟังก์ชันเหล่านี้คือregplot() และ lmplot().
regplot กับ lmplot
| regplot | lmplot |
|---|---|
| ยอมรับตัวแปร x และ y ในรูปแบบต่างๆรวมถึงอาร์เรย์ numpy ธรรมดาวัตถุชุดหมีแพนด้าหรือเป็นการอ้างอิงถึงตัวแปรใน DataFrame ของแพนด้า | มีข้อมูลเป็นพารามิเตอร์ที่จำเป็นและต้องระบุตัวแปร x และ y เป็นสตริง รูปแบบข้อมูลนี้เรียกว่าข้อมูล "แบบยาว" |
ตอนนี้ให้เราวาดพล็อต
ตัวอย่าง
การพล็อต regplot แล้ว lmplot ด้วยข้อมูลเดียวกันในตัวอย่างนี้
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = df)
sb.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()เอาต์พุต
คุณสามารถเห็นความแตกต่างของขนาดระหว่างสองแปลง
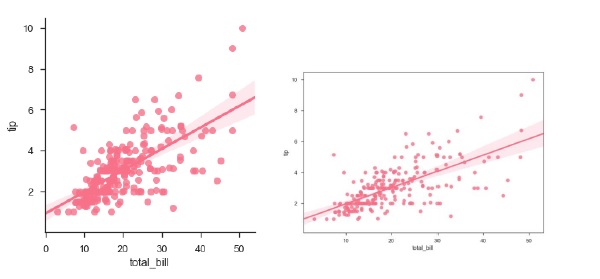
นอกจากนี้เรายังสามารถปรับให้พอดีกับการถดถอยเชิงเส้นเมื่อตัวแปรตัวใดตัวหนึ่งรับค่าไม่ต่อเนื่อง
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.lmplot(x = "size", y = "tip", data = df)
plt.show()เอาต์พุต
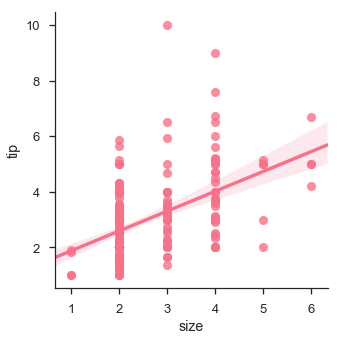
ติดตั้งรุ่นต่างๆ
แบบจำลองการถดถอยเชิงเส้นอย่างง่ายที่ใช้ข้างต้นนั้นง่ายมากที่จะทำให้พอดี แต่ในกรณีส่วนใหญ่ข้อมูลไม่เป็นเชิงเส้นและวิธีการข้างต้นไม่สามารถสรุปเส้นการถดถอยได้
ให้เราใช้ชุดข้อมูลของ Anscombe กับพล็อตการถดถอย -
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x="x", y="y", data=df.query("dataset == 'I'"))
plt.show()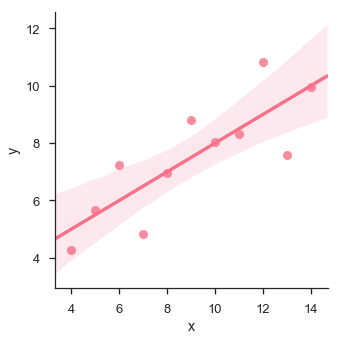
ในกรณีนี้ข้อมูลนี้เหมาะสำหรับแบบจำลองการถดถอยเชิงเส้นที่มีความแปรปรวนน้อยกว่า
ให้เราดูอีกตัวอย่างหนึ่งที่ข้อมูลมีค่าเบี่ยงเบนสูงซึ่งแสดงให้เห็นว่าบรรทัดที่เหมาะสมที่สุดนั้นไม่ดี
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"))
plt.show()เอาต์พุต
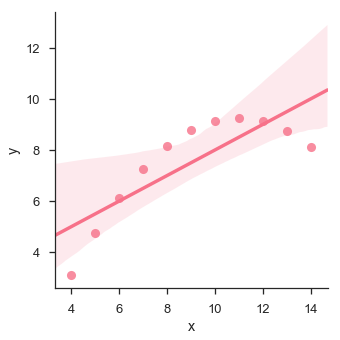
พล็อตแสดงความเบี่ยงเบนสูงของจุดข้อมูลจากเส้นถดถอย ลำดับที่สูงกว่าที่ไม่ใช่เชิงเส้นดังกล่าวสามารถมองเห็นได้โดยใช้lmplot() และ regplot()สิ่งเหล่านี้สามารถพอดีกับแบบจำลองการถดถอยพหุนามเพื่อสำรวจแนวโน้มที่ไม่เป็นเชิงเส้นในชุดข้อมูล -
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"),order = 2)
plt.show()เอาต์พุต
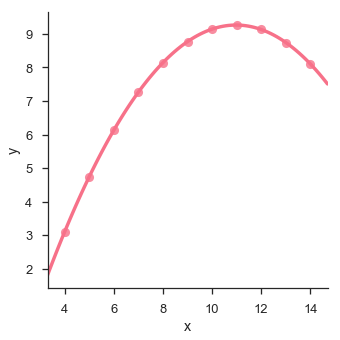
วิธีการที่มีประโยชน์ในการสำรวจข้อมูลขนาดกลางคือการวาดหลาย ๆ อินสแตนซ์ของพล็อตเดียวกันบนชุดย่อยต่างๆของชุดข้อมูลของคุณ
เทคนิคนี้เรียกกันโดยทั่วไปว่า "ตาข่าย" หรือ "โครงตาข่าย" และเกี่ยวข้องกับแนวคิดของ "การทวีคูณขนาดเล็ก"
ในการใช้คุณสมบัติเหล่านี้ข้อมูลของคุณจะต้องอยู่ใน Pandas DataFrame
การพล็อตชุดย่อยข้อมูลหลายรายการขนาดเล็ก
ในบทที่แล้วเราได้เห็นตัวอย่าง FacetGrid ที่คลาส FacetGrid ช่วยในการแสดงภาพการกระจายของตัวแปรหนึ่งตัวรวมทั้งความสัมพันธ์ระหว่างตัวแปรหลายตัวแยกกันภายในชุดย่อยของชุดข้อมูลของคุณโดยใช้แผงข้อมูลหลายแผง
FacetGrid สามารถวาดได้ถึงสามมิติ - row, col และ hue สองตัวแรกมีความสอดคล้องกันอย่างชัดเจนกับอาร์เรย์ของแกนที่เป็นผลลัพธ์ คิดว่าตัวแปรสีเป็นมิติที่สามตามแกนความลึกซึ่งระดับต่างๆจะถูกพล็อตด้วยสีที่ต่างกัน
FacetGrid ออบเจ็กต์รับดาต้าเฟรมเป็นอินพุตและชื่อของตัวแปรที่จะสร้างขนาดแถวคอลัมน์หรือสีของกริด
ตัวแปรควรเป็นหมวดหมู่และข้อมูลในแต่ละระดับของตัวแปรจะถูกใช้สำหรับแง่มุมตามแกนนั้น
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
plt.show()เอาต์พุต
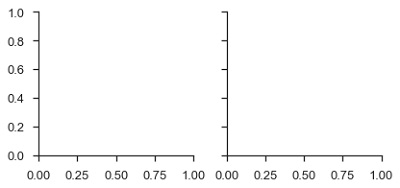
ในตัวอย่างข้างต้นเราเพิ่งเริ่มต้นไฟล์ facetgrid วัตถุที่ไม่ได้วาดอะไรเลย
แนวทางหลักในการแสดงข้อมูลบนกริดนี้คือการใช้ไฟล์ FacetGrid.map()วิธี. ให้เราดูการกระจายของเคล็ดลับในแต่ละส่วนย่อยเหล่านี้โดยใช้ฮิสโตแกรม
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
g.map(plt.hist, "tip")
plt.show()เอาต์พุต
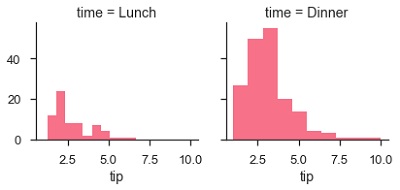
จำนวนพล็อตมีมากกว่าหนึ่งเนื่องจากพารามิเตอร์ col เราได้พูดคุยเกี่ยวกับพารามิเตอร์ col ในบทก่อนหน้าของเรา
ในการสร้างพล็อตเชิงสัมพันธ์ให้ส่งชื่อตัวแปรหลายตัว
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "sex", hue = "smoker")
g.map(plt.scatter, "total_bill", "tip")
plt.show()เอาต์พุต
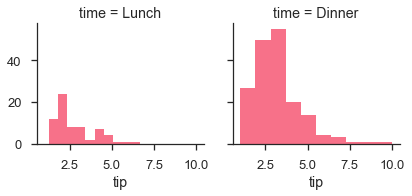
PairGrid ช่วยให้เราสามารถวาดตารางของพล็อตย่อยโดยใช้ประเภทพล็อตเดียวกันเพื่อแสดงภาพข้อมูล
ไม่เหมือน FacetGrid คือใช้คู่ของตัวแปรที่แตกต่างกันสำหรับแต่ละแผนย่อย มันสร้างเมทริกซ์ของแผนการย่อย บางครั้งเรียกว่า "scatterplot matrix"
การใช้ pairgrid นั้นคล้ายกับ facetgrid ก่อนอื่นให้เริ่มต้นตารางแล้วส่งผ่านฟังก์ชันการลงจุด
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
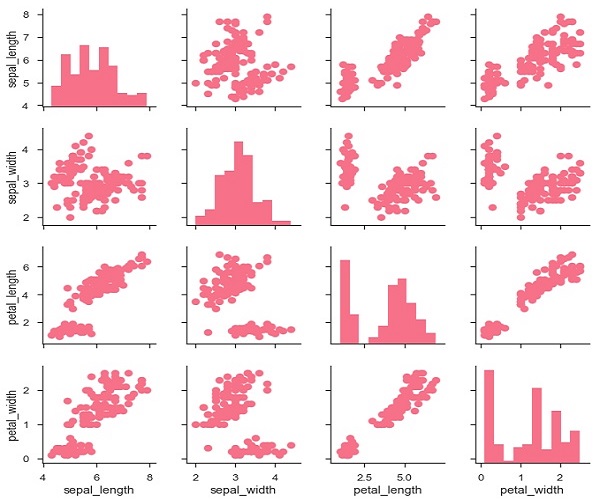
g = sb.PairGrid(df)
g.map(plt.scatter);
plt.show()
นอกจากนี้ยังสามารถพล็อตฟังก์ชันที่แตกต่างกันบนเส้นทแยงมุมเพื่อแสดงการแจกแจงแบบไม่แปรผันของตัวแปรในแต่ละคอลัมน์
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()เอาต์พุต
เราสามารถปรับแต่งสีของพล็อตเหล่านี้ได้โดยใช้ตัวแปรหมวดหมู่อื่น ตัวอย่างเช่นชุดข้อมูลไอริสมีการวัดสี่แบบสำหรับดอกไอริสแต่ละสายพันธุ์ที่แตกต่างกันสามชนิดเพื่อให้คุณเห็นว่ามันแตกต่างกันอย่างไร
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()เอาต์พุต
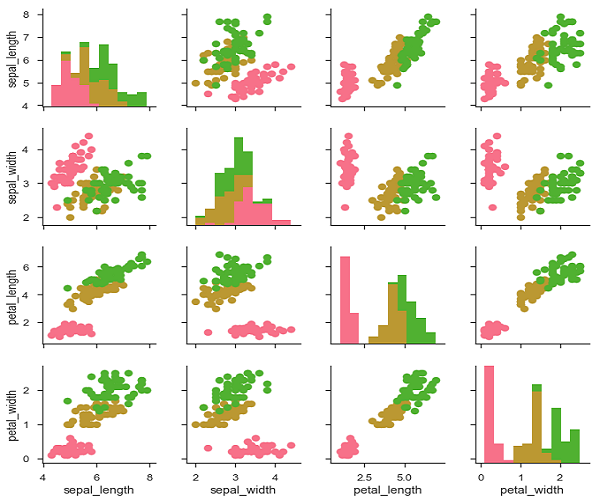
เราสามารถใช้ฟังก์ชันที่แตกต่างกันในสามเหลี่ยมบนและล่างเพื่อดูความสัมพันธ์ในแง่มุมต่างๆ
ตัวอย่าง
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_upper(plt.scatter)
g.map_lower(sb.kdeplot, cmap = "Blues_d")
g.map_diag(sb.kdeplot, lw = 3, legend = False);
plt.show()เอาต์พุต