Python ile Yapay Zeka - Zaman Serisi Verilerini Analiz Etme
Belirli bir girdi dizisinde bir sonrakini tahmin etmek, makine öğreniminde başka bir önemli kavramdır. Bu bölüm size zaman serisi verilerini analiz etme hakkında ayrıntılı bir açıklama sunar.
Giriş
Zaman serisi verileri, bir dizi belirli zaman aralığında bulunan veriler anlamına gelir. Makine öğreniminde sıra tahmini oluşturmak istiyorsak, sıralı veriler ve zamanla uğraşmamız gerekir. Seri verileri, sıralı verilerin bir özetidir. Verilerin sıralanması, sıralı verilerin önemli bir özelliğidir.
Sıra Analizi veya Zaman Serisi Analizi Temel Kavramı
Sıra analizi veya zaman serisi analizi, önceden gözlemlenene dayalı olarak belirli bir girdi dizisindeki bir sonrakini tahmin etmektir. Tahmin, daha sonra olabilecek herhangi bir şey olabilir: bir sembol, bir sayı, ertesi gün hava durumu, konuşmada sonraki terim vb. Sıra analizi, borsa analizi, hava durumu tahmini ve ürün önerileri gibi uygulamalarda çok kullanışlı olabilir.
Example
Sıra tahminini anlamak için aşağıdaki örneği düşünün. BurayaA,B,C,D verilen değerlerdir ve değeri tahmin etmelisiniz E Sıralı Tahmin Modeli kullanarak.

Yararlı Paketleri Kurmak
Python kullanarak zaman serisi veri analizi için aşağıdaki paketleri yüklememiz gerekir -
Pandalar
Pandas, Python için yüksek performans, veri yapısı kullanım kolaylığı ve veri analizi araçları sağlayan açık kaynak BSD lisanslı bir kütüphanedir. Pandaları aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install pandasAnaconda kullanıyorsanız ve kullanarak kurmak istiyorsanız conda paket yöneticisi, ardından aşağıdaki komutu kullanabilirsiniz -
conda install -c anaconda pandashmmöğrenmek
Python'da Gizli Markov Modellerini (HMM) öğrenmek için basit algoritmalar ve modellerden oluşan açık kaynak BSD lisanslı bir kütüphanedir. Aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install hmmlearnAnaconda kullanıyorsanız ve kullanarak kurmak istiyorsanız conda paket yöneticisi, ardından aşağıdaki komutu kullanabilirsiniz -
conda install -c omnia hmmlearnPyStruct
Yapılandırılmış bir öğrenme ve tahmin kitaplığıdır. PyStruct'ta uygulanan öğrenme algoritmaları, koşullu rastgele alanlar (CRF), Maximum-Margin Markov Random Networks (M3N) veya yapısal destek vektör makineleri gibi adlara sahiptir. Aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install pystructCVXOPT
Python programlama diline dayalı dışbükey optimizasyon için kullanılır. Aynı zamanda ücretsiz bir yazılım paketidir. Aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install cvxoptAnaconda kullanıyorsanız ve kullanarak kurmak istiyorsanız conda paket yöneticisi, ardından aşağıdaki komutu kullanabilirsiniz -
conda install -c anaconda cvdoxtPandalar: Zaman Serisi Verilerinden İstatistiği İşleme, Dilimleme ve Çıkarma
Zaman serisi verileriyle çalışmanız gerekiyorsa, Pandalar çok kullanışlı bir araçtır. Pandaların yardımıyla aşağıdakileri gerçekleştirebilirsiniz -
Kullanarak bir tarih aralığı oluşturun pd.date_range paket
Pandaları tarihlerle dizine eklemek için pd.Series paket
Kullanarak yeniden örnekleme gerçekleştirin ts.resample paket
Frekansı değiştir
Misal
Aşağıdaki örnek, Pandalar'ı kullanarak zaman serisi verilerini işlemenizi ve dilimlemenizi gösterir. Burada, month.ao.index.b50.current.ascii adresinden indirilebilen ve kullanımımız için metin biçimine dönüştürülebilen Aylık Arktik Salınım verilerini kullandığımızı unutmayın.
Zaman serisi verilerini işleme
Zaman serisi verilerinin işlenmesi için aşağıdaki adımları gerçekleştirmeniz gerekecektir -
İlk adım, aşağıdaki paketleri içe aktarmayı içerir -
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdArdından, aşağıda verilen kodda gösterildiği gibi giriş dosyasından verileri okuyacak bir işlev tanımlayın -
def read_data(input_file):
input_data = np.loadtxt(input_file, delimiter = None)Şimdi bu verileri zaman serisine dönüştürün. Bunun için zaman serimizin tarih aralığını oluşturun. Bu örnekte, veri sıklığı olarak bir ayı tutuyoruz. Dosyamızda Ocak 1950'den başlayan veriler var.
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')Bu adımda aşağıda gösterildiği gibi Pandas Series yardımı ile zaman serisi verilerini oluşturuyoruz -
output = pd.Series(input_data[:, index], index = dates)
return output
if __name__=='__main__':Giriş dosyasının yolunu burada gösterildiği gibi girin -
input_file = "/Users/admin/AO.txt"Şimdi, sütunu burada gösterildiği gibi zaman serisi biçimine dönüştürün -
timeseries = read_data(input_file)Son olarak, gösterilen komutları kullanarak verileri çizin ve görselleştirin -
plt.figure()
timeseries.plot()
plt.show()Aşağıdaki resimlerde gösterildiği gibi grafikleri gözlemleyeceksiniz -


Zaman serisi verilerini dilimleme
Dilimleme, zaman serisi verilerinin yalnızca bir bölümünü almayı içerir. Örneğin bir parçası olarak, verileri yalnızca 1980'den 1990'a dilimlere ayırıyoruz. Bu görevi yerine getiren aşağıdaki kodu inceleyin -
timeseries['1980':'1990'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00>
plt.show()Zaman serisi verilerini dilimlemek için kodu çalıştırdığınızda, buradaki resimde gösterildiği gibi aşağıdaki grafiği gözlemleyebilirsiniz -

Zaman Serisi Verilerinden İstatistiği Çıkarma
Bazı önemli sonuçlara varmanız gereken durumlarda, belirli bir veriden bazı istatistikler çıkarmanız gerekecektir. Ortalama, varyans, korelasyon, maksimum değer ve minimum değer bu tür istatistiklerden bazılarıdır. Bu tür istatistikleri belirli bir zaman serisi verilerinden çıkarmak istiyorsanız, aşağıdaki kodu kullanabilirsiniz -
Anlamına gelmek
Kullanabilirsiniz mean() burada gösterildiği gibi ortalamayı bulmak için fonksiyon -
timeseries.mean()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
-0.11143128165238671Maksimum
Kullanabilirsiniz max() burada gösterildiği gibi maksimum bulmak için fonksiyon -
timeseries.max()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
3.4952999999999999Minimum
Burada gösterildiği gibi minimum bulmak için min () işlevini kullanabilirsiniz -
timeseries.min()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
-4.2656999999999998Her şeyi aynı anda almak
Bir seferde tüm istatistikleri hesaplamak istiyorsanız, describe() burada gösterildiği gibi işlev -
timeseries.describe()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64Yeniden örnekleme
Verileri farklı bir zaman frekansına yeniden örnekleyebilirsiniz. Yeniden örnekleme yapmak için iki parametre şunlardır:
- Zaman dilimi
- Method
Ortalama () ile yeniden örnekleme
Verileri, varsayılan yöntem olan mean () yöntemiyle yeniden örneklemek için aşağıdaki kodu kullanabilirsiniz -
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()Ardından, mean () kullanarak yeniden örneklemenin çıktısı olarak aşağıdaki grafiği gözlemleyebilirsiniz -

Ortanca () ile yeniden örnekleme
Aşağıdaki kodu kullanarak verileri yeniden örneklemek için kullanabilirsiniz. median()yöntem -
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()Ardından, median () ile yeniden örneklemenin çıktısı olarak aşağıdaki grafiği gözlemleyebilirsiniz -

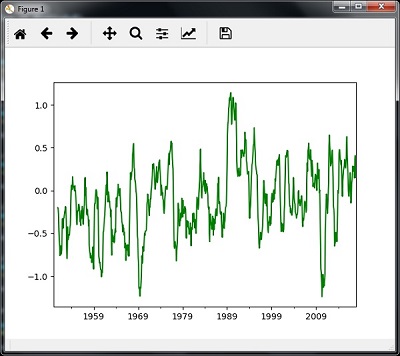
Rolling Mean
Dönen (hareketli) ortalamayı hesaplamak için aşağıdaki kodu kullanabilirsiniz -
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()Ardından, yuvarlanan (hareketli) ortalamanın çıktısı olarak aşağıdaki grafiği gözlemleyebilirsiniz -
Sıralı Verilerin Gizli Markov Modeli (HMM) ile Analizi
HMM, zaman serisi borsa analizi, sağlık kontrolü ve konuşma tanıma gibi sürekliliği ve genişletilebilirliği olan veriler için yaygın olarak kullanılan bir istatistik modelidir. Bu bölüm, sıralı verileri Gizli Markov Modeli (HMM) kullanarak analiz etme ile ayrıntılı olarak ilgilenir.
Gizli Markov Modeli (HMM)
HMM, gelecekteki istatistiklerin olasılığının kendisinden önceki herhangi bir duruma değil, yalnızca mevcut işlem durumuna bağlı olduğu varsayımına dayanan Markov zinciri kavramı üzerine inşa edilmiş stokastik bir modeldir. Örneğin yazı tura atarken, beşinci atışın sonucunun bir kafa olacağını söyleyemeyiz. Bunun nedeni, madeni paranın hafızası olmaması ve sonraki sonucun önceki sonuca bağlı olmamasıdır.
HMM matematiksel olarak aşağıdaki değişkenlerden oluşur -
Eyaletler (S)
Bir HMM'de bulunan bir dizi gizli veya gizli durumdur. S ile gösterilir.
Çıkış sembolleri (O)
Bir HMM'de bulunan bir dizi olası çıktı sembolüdür. O ile gösterilir.
Durum Geçiş Olasılık Matrisi (A)
Bir durumdan diğer durumların her birine geçiş yapma olasılığıdır. A. ile gösterilir.
Gözlem Emisyon Olasılık Matrisi (B)
Belirli bir durumda bir sembolü yayma / gözlemleme olasılığıdır. B ile gösterilir.
Önceki Olasılık Matrisi (Π)
Sistemin çeşitli durumlarından belirli bir durumda başlama olasılığıdır. Π ile gösterilir.
Dolayısıyla, bir HMM şu şekilde tanımlanabilir: = (S,O,A,B,),
nerede,
- S = {s1,s2,…,sN} N olası durum kümesidir,
- O = {o1,o2,…,oM} M olası gözlem sembolleri kümesidir,
- A bir NN durum Geçiş Olasılık Matrisi (TPM),
- B bir NM gözlem veya Emisyon Olasılık Matrisi (EPM),
- π, N boyutlu bir ilk durum olasılık dağılım vektörüdür.
Örnek: Borsa verilerinin analizi
Bu örnekte, HMM'nin sıralı veya zaman serisi verileriyle nasıl çalıştığı hakkında bir fikir edinmek için borsa verilerini adım adım analiz edeceğiz. Lütfen bu örneği Python'da uyguladığımızı unutmayın.
Gerekli paketleri aşağıda gösterildiği gibi içe aktarın -
import datetime
import warningsŞimdi, borsa verilerini kullanın. matpotlib.finance paket, burada gösterildiği gibi -
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMMVerileri bir başlangıç tarihi ve bitiş tarihinden, yani burada gösterildiği gibi iki belirli tarih arasında yükleyin -
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)Bu adımda, her gün kapanış tekliflerini çıkaracağız. Bunun için aşağıdaki komutu kullanın -
closing_quotes = np.array([quote[2] for quote in quotes])Şimdi, her gün işlem gören hisselerin hacmini çıkaracağız. Bunun için aşağıdaki komutu kullanın -
volumes = np.array([quote[5] for quote in quotes])[1:]Burada, aşağıda gösterilen kodu kullanarak kapanış hisse senedi fiyatlarının yüzde farkını alın -
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])Bu adımda, Gauss HMM'yi oluşturun ve eğitin. Bunun için aşağıdaki kodu kullanın -
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)Şimdi, gösterilen komutları kullanarak HMM modelini kullanarak veri oluşturun -
num_samples = 300
samples, _ = hmm.sample(num_samples)Son olarak, bu adımda, çıktı olarak işlem gören hisse senetlerinin fark yüzdesini ve hacmini grafik biçiminde çizip görselleştiriyoruz.
Fark yüzdelerini çizmek ve görselleştirmek için aşağıdaki kodu kullanın -
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')İşlem gören hisselerin hacmini çizmek ve görselleştirmek için aşağıdaki kodu kullanın -
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()