Python ile AI - NLTK Paketi
Bu bölümde, Natural Language Toolkit Paketine nasıl başlayacağımızı öğreneceğiz.
Önkoşul
Natural Language işleme ile uygulamalar oluşturmak istiyorsak, bağlamdaki değişiklik bunu en zor hale getirir. Bağlam faktörü, makinenin belirli bir cümleyi nasıl anladığını etkiler. Bu nedenle, makine öğrenimi yaklaşımlarını kullanarak Doğal dil uygulamaları geliştirmemiz gerekiyor, böylece makine aynı zamanda bir insanın bağlamı anlayabileceği yolu anlayabilir.
Bu tür uygulamaları oluşturmak için NLTK (Natural Language Toolkit Package) adlı Python paketini kullanacağız.
NLTK içe aktarılıyor
Kullanmadan önce NLTK'yi kurmamız gerekiyor. Aşağıdaki komut yardımı ile kurulabilir -
pip install nltkNLTK için bir conda paketi oluşturmak için aşağıdaki komutu kullanın -
conda install -c anaconda nltkŞimdi NLTK paketini kurduktan sonra, onu python komut istemi aracılığıyla içe aktarmamız gerekiyor. Python komut istemine aşağıdaki komutu yazarak içe aktarabiliriz -
>>> import nltkNLTK'nın Verilerini İndirme
Şimdi NLTK'yi içe aktardıktan sonra, gerekli verileri indirmemiz gerekiyor. Python komut isteminde aşağıdaki komutun yardımı ile yapılabilir -
>>> nltk.download()Diğer Gerekli Paketleri Kurmak
NLTK kullanarak doğal dil işleme uygulamaları oluşturmak için gerekli paketleri kurmamız gerekiyor. Paketler aşağıdaki gibidir -
Gensim
Birçok uygulama için yararlı olan sağlam bir anlamsal modelleme kitaplığıdır. Aşağıdaki komutu çalıştırarak kurabiliriz -
pip install gensimDesen
Yapmak için kullanılır gensimpaket düzgün çalışıyor. Aşağıdaki komutu çalıştırarak kurabiliriz
pip install patternTokenizasyon, Kök Oluşturma ve Lemmatizasyon Kavramı
Bu bölümde, jetonlaştırmanın, kökleştirmenin ve lemmatizasyonun ne olduğunu anlayacağız.
Tokenizasyon
Verilen metni, yani karakter dizisini simge adı verilen daha küçük birimlere ayırma işlemi olarak tanımlanabilir. Simgeler sözcükler, sayılar veya noktalama işaretleri olabilir. Aynı zamanda kelime bölümleme olarak da adlandırılır. Aşağıda basit bir tokenleştirme örneği verilmiştir -
Input - Mango, muz, ananas ve elma meyvedir.
Output -

Verilen metni kırma işlemi, kelime sınırlarının bulunması yardımı ile yapılabilir. Bir kelimenin sonu ve yeni bir kelimenin başlangıcı kelime sınırları olarak adlandırılır. Yazı sistemi ve kelimelerin tipografik yapısı sınırları etkiler.
Python NLTK modülünde, metni gereksinimlerimize göre belirteçlere bölmek için kullanabileceğimiz belirteçleştirmeyle ilgili farklı paketlerimiz var. Paketlerden bazıları aşağıdaki gibidir -
sent_tokenize paketi
Adından da anlaşılacağı gibi, bu paket giriş metnini cümlelere böler. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.tokenize import sent_tokenizeword_tokenize paketi
Bu paket, giriş metnini kelimelere ayırır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.tokenize import word_tokenizeWordPunctTokenizer paketi
Bu paket, girdi metnini sözcüklere ve noktalama işaretlerine ayırır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.tokenize import WordPuncttokenizerStemming
Kelimelerle çalışırken gramatik nedenlerden dolayı pek çok varyasyonla karşılaşıyoruz. Buradaki varyasyon kavramı, aynı kelimelerin farklı biçimleriyle uğraşmamız gerektiği anlamına gelir.democracy, democratic, ve democratization. Makinelerin bu farklı kelimelerin aynı temel forma sahip olduğunu anlaması çok gereklidir. Bu şekilde, biz metni analiz ederken kelimelerin temel formlarını çıkarmak faydalı olacaktır.
Bunu kök oluşturarak başarabiliriz. Bu şekilde, kök bulmanın, kelimelerin uçlarını keserek kelimelerin temel formlarını çıkarmanın sezgisel süreci olduğunu söyleyebiliriz.
Python NLTK modülünde, kök oluşturmayla ilgili farklı paketlerimiz var. Bu paketler, kelimenin temel biçimlerini elde etmek için kullanılabilir. Bu paketler algoritmalar kullanır. Paketlerden bazıları aşağıdaki gibidir -
PorterStemmer paketi
Bu Python paketi, temel formu çıkarmak için Porter'ın algoritmasını kullanır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem.porter import PorterStemmerÖrneğin, kelimesini verirsek ‘writing’ bu kökleştiricinin girdisi olarak onları alacağız ‘write’ köklenmeden sonra.
LancasterStemmer paketi
Bu Python paketi, temel formu çıkarmak için Lancaster'ın algoritmasını kullanacaktır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem.lancaster import LancasterStemmerÖrneğin, kelimesini verirsek ‘writing’ bu kökleştiricinin girdisi olarak onları alacağız ‘write’ köklenmeden sonra.
SnowballStemmer paketi
Bu Python paketi, temel formu çıkarmak için kartopunun algoritmasını kullanacaktır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem.snowball import SnowballStemmerÖrneğin, kelimesini verirsek ‘writing’ bu kökleştiricinin girdisi olarak onları alacağız ‘write’ köklenmeden sonra.
Tüm bu algoritmalar farklı düzeyde katılığa sahiptir. Bu üç gövdeyi karşılaştırırsak, o zaman Porter saplayıcılar en az katıdır ve Lancaster en katı olanıdır. Kartopu sapı, hız ve sertlik açısından kullanmak için iyidir.
Lemmatizasyon
Sözcüklerin temel biçimini de lemmatize ederek çıkarabiliriz. Temelde bu görevi, bir kelime dağarcığı ve kelimelerin morfolojik analizini kullanarak yapar, normalde yalnızca çekimsel sonları kaldırmayı amaçlamaktadır. Herhangi bir kelimenin bu tür temel biçimine lemma denir.
Kökten türetme ve sözcüklendirme arasındaki temel fark, kelime dağarcığı kullanımı ve kelimelerin morfolojik analizidir. Diğer bir fark, kök oluşturmanın en yaygın olarak türevsel olarak ilişkili kelimeleri daraltmasıdır, oysa lemmatizasyon genellikle yalnızca bir lemmanın farklı çekim biçimlerini daraltır. Örneğin, girdi kelimesi olarak saw kelimesini sağlarsak, kök bulma 's' kelimesini döndürebilir ancak lemmatizasyon, simgenin kullanımının bir fiil mi yoksa bir isim mi olduğuna bağlı olarak gör veya gördü kelimesini döndürmeye çalışır.
Python NLTK modülünde, kelimenin temel biçimlerini elde etmek için kullanabileceğimiz lemmatizasyon süreciyle ilgili aşağıdaki paketimiz var -
WordNetLemmatizer paketi
Bu Python paketi, bir isim veya fiil olarak kullanılmasına bağlı olarak kelimenin temel biçimini çıkaracaktır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem import WordNetLemmatizerYığınlama: Verileri Parçalara Bölme
Doğal dil işlemede önemli süreçlerden biridir. Parçalama işleminin ana görevi, sözcük öbekleri gibi sözcük gruplarını ve kısa sözcük öbeklerini belirlemektir. Tokenleştirme sürecini, token oluşturma sürecini zaten inceledik. Chunking, temelde bu tokenlerin etiketlenmesidir. Başka bir deyişle, parçalama bize cümlenin yapısını gösterecektir.
Aşağıdaki bölümde, farklı Chunking türleri hakkında bilgi edineceğiz.
Yığın türleri
İki tür yığın vardır. Türler aşağıdaki gibidir -
Yığılma
Bu yığın oluşturma sürecinde nesne, şeyler vb. Daha genel olmaya doğru ilerler ve dil daha soyut hale gelir. Daha fazla anlaşma şansı var. Bu süreçte uzaklaşıyoruz. Örneğin, "arabalar ne amaçlıdır" sorusunu bir araya toplarsak? "Ulaşım" cevabını alabiliriz.
Parçalama
Bu yığın oluşturma sürecinde nesne, şeyler vb. Daha spesifik olmaya doğru ilerler ve dil daha fazla nüfuz eder. Daha derin yapı, yığın halinde incelenecektir. Bu süreçte yakınlaştırırız. Örneğin, "Özellikle bir arabadan bahsedin" sorusunu kısaltarsak? Araba hakkında daha küçük bilgiler alacağız.
Example
Bu örnekte, Python'da NLTK modülünü kullanarak cümledeki isim cümleleri parçalarını bulacak bir öbekleme kategorisi olan İsim-Cümle parçalama yapacağız
Follow these steps in python for implementing noun phrase chunking −
Step 1- Bu adımda, yığın oluşturma için grameri tanımlamamız gerekiyor. Uymamız gereken kurallardan oluşacaktır.
Step 2- Bu adımda bir yığın ayrıştırıcı oluşturmamız gerekiyor. Dilbilgisini ayrıştırır ve çıktıyı verir.
Step 3 - Bu son adımda çıktı bir ağaç formatında üretilir.
Gerekli NLTK paketini aşağıdaki gibi içe aktaralım -
import nltkŞimdi cümleyi tanımlamamız gerekiyor. Burada DT determinant anlamına gelir, VBP fiil anlamına gelir, JJ sıfat anlamına gelir, IN edat anlamına gelir ve NN isim anlamına gelir.
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Şimdi grameri vermemiz gerekiyor. Burada grameri düzenli ifade biçiminde vereceğiz.
grammar = "NP:{<DT>?<JJ>*<NN>}"Dilbilgisini ayrıştıracak bir ayrıştırıcı tanımlamamız gerekiyor.
parser_chunking = nltk.RegexpParser(grammar)Ayrıştırıcı cümleyi şu şekilde ayrıştırır -
parser_chunking.parse(sentence)Sonra, çıktıyı almamız gerekiyor. Çıktı, adı verilen basit değişkende oluşturuluroutput_chunk.
Output_chunk = parser_chunking.parse(sentence)Aşağıdaki kodun çalıştırılmasıyla çıktımızı ağaç şeklinde çizebiliriz.
output.draw()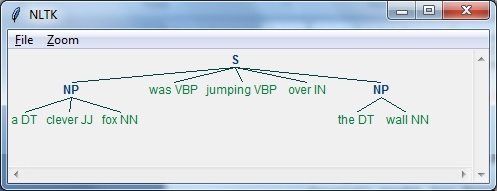
Kelime Çantası (BoW) Modeli
Doğal dil işlemede bir model olan Kelime Çantası (BoW), temelde metnin özelliklerini çıkarmak için kullanılır, böylece metin makine öğrenimi algoritmalarında olacak şekilde modellemede kullanılabilir.
Şimdi soru, neden özellikleri metinden çıkarmamız gerektiği sorusu ortaya çıkıyor. Bunun nedeni, makine öğrenimi algoritmalarının ham verilerle çalışamaması ve ondan anlamlı bilgiler çıkarabilmeleri için sayısal verilere ihtiyaç duymalarıdır. Metin verilerinin sayısal verilere dönüştürülmesine özellik çıkarma veya özellik kodlama denir.
Nasıl çalışır
Bu, özellikleri metinden çıkarmak için çok basit bir yaklaşımdır. Diyelim ki bir metin belgemiz var ve onu sayısal veriye dönüştürmek istiyoruz ya da özniteliklerini çıkarmak istediğimizi söylüyoruz, sonra öncelikle bu model belgedeki tüm sözcüklerden bir kelime haznesi çıkarıyor. Daha sonra bir belge terim matrisi kullanarak bir model oluşturacaktır. Böylelikle BoW, belgeyi yalnızca bir kelime paketi olarak temsil eder. Belgedeki kelimelerin sırası veya yapısı hakkında herhangi bir bilgi atılır.
Belge terim matrisi kavramı
BoW algoritması, belge terimi matrisini kullanarak bir model oluşturur. Adından da anlaşılacağı gibi, belge terimi matrisi, belgede meydana gelen çeşitli sözcük sayılarının matrisidir. Bu matrisin yardımıyla, metin belgesi çeşitli kelimelerin ağırlıklı bir kombinasyonu olarak temsil edilebilir. Eşiği belirleyerek ve daha anlamlı kelimeleri seçerek, bir özellik vektörü olarak kullanılabilecek belgelerdeki tüm kelimelerin histogramını oluşturabiliriz. Aşağıda, belge terimi matrisi kavramını anlamak için bir örnek verilmiştir -
Example
Aşağıdaki iki cümleye sahip olduğumuzu varsayalım -
Sentence 1 - Kelime Çantası modelini kullanıyoruz.
Sentence 2 - Özelliklerin çıkarılmasında Bag of Words modeli kullanılmıştır.
Şimdi, bu iki cümleyi ele aldığımızda şu 13 farklı kelimeye sahibiz:
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
Şimdi, her cümledeki kelime sayısını kullanarak her cümle için bir histogram oluşturmamız gerekiyor -
Sentence 1 - [1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 - [0,0,0,1,1,1,1,1,1,1,1,1,1]
Bu şekilde, çıkarılan özellik vektörlerine sahibiz. Her özellik vektörü 13 boyutludur çünkü 13 farklı kelimemiz vardır.
İstatistik Kavramı
İstatistik kavramı TermFrequency-Inverse Document Frequency (tf-idf) olarak adlandırılır. Belgedeki her kelime önemlidir. İstatistikler, her kelimenin önemini anlamamıza yardımcı olur.
Dönem Frekansı (tf)
Bir belgede her kelimenin ne sıklıkta göründüğünün ölçüsüdür. Her kelimenin sayısını belirli bir belgedeki toplam kelime sayısına bölerek elde edilebilir.
Ters Belge Frekansı (idf)
Verilen belge setinde bir kelimenin bu belge için ne kadar benzersiz olduğunun ölçüsüdür. İdf'yi hesaplamak ve ayırt edici bir özellik vektörü formüle etmek için, gibi yaygın olarak ortaya çıkan kelimelerin ağırlıklarını azaltmalı ve nadir kelimeleri tartmalıyız.
NLTK'da Kelime Çantası Modeli Oluşturma
Bu bölümde, bu cümlelerden vektörler oluşturmak için CountVectorizer kullanarak bir dizi dizesi tanımlayacağız.
Gerekli paketi ithal edelim -
from sklearn.feature_extraction.text import CountVectorizerŞimdi cümle kümesini tanımlayın.
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)Yukarıdaki program, çıktıyı aşağıda gösterildiği gibi üretir. Yukarıdaki iki cümlede 13 farklı kelimemiz olduğunu gösteriyor -
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}Bunlar, makine öğrenimi için kullanılabilecek özellik vektörleridir (metinden sayısal biçime).
Sorunları çözmek
Bu bölümde, ilgili birkaç sorunu çözeceğiz.
Kategori Tahmin
Bir dizi belgede, sadece sözcükler değil, sözcüklerin kategorisi de önemlidir; belirli bir kelimenin hangi metin kategorisine girdiği. Örneğin, belirli bir cümlenin e-posta, haber, spor, bilgisayar vb. Kategorisine ait olup olmadığını tahmin etmek istiyoruz. Aşağıdaki örnekte, belge kategorisini bulmak için bir özellik vektörü formüle etmek için tf-idf'yi kullanacağız. Sklearn'ın 20 haber grubu veri setindeki verileri kullanacağız.
Gerekli paketleri ithal etmemiz gerekiyor -
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerKategori haritasını tanımlayın. Din, Otomobiller, Spor, Elektronik ve Uzay adlı beş farklı kategori kullanıyoruz.
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}Eğitim setini oluşturun -
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)Bir sayı vektörleştiricisi oluşturun ve terim sayılarını çıkarın -
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)Tf-idf transformatörü aşağıdaki gibi oluşturulur -
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)Şimdi test verilerini tanımlayın -
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]Yukarıdaki veriler, Multinomial Naive Bayes sınıflandırıcısını eğitmemize yardımcı olacaktır -
classifier = MultinomialNB().fit(train_tfidf, training_data.target)Sayım vektörleştiricisini kullanarak giriş verilerini dönüştürün -
input_tc = vectorizer_count.transform(input_data)Şimdi, vektörleştirilmiş verileri tfidf trafosunu kullanarak dönüştüreceğiz -
input_tfidf = tfidf.transform(input_tc)Çıktı kategorilerini tahmin edeceğiz -
predictions = classifier.predict(input_tfidf)Çıktı aşağıdaki gibi oluşturulur -
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])Kategori tahmincisi aşağıdaki çıktıyı üretir -
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: ElectronicsCinsiyet Bulucu
Bu problem ifadesinde, bir sınıflandırıcı, isimleri sağlayarak cinsiyeti (erkek veya kadın) bulmak için eğitilecektir. Bir özellik vektörü oluşturmak ve sınıflandırıcıyı eğitmek için buluşsal yöntem kullanmalıyız. Scikit-learn paketindeki etiketli verileri kullanacağız. Cinsiyet bulucu oluşturmak için Python kodu aşağıdadır -
Gerekli paketleri ithal edelim -
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import namesŞimdi giriş kelimesinden son N harfi çıkarmamız gerekiyor. Bu harfler özellik olarak hareket edecek -
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':NLTK'da bulunan etiketli isimleri (erkek ve kadın) kullanarak eğitim verilerini oluşturun -
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)Şimdi, test verileri aşağıdaki gibi oluşturulacaktır -
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']Aşağıdaki kodla eğitim ve test için kullanılan örnek sayısını tanımlayın
train_sample = int(0.8 * len(data))Şimdi, doğruluğun karşılaştırılabilmesi için farklı uzunluklarda yinelememiz gerekiyor -
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)Sınıflandırıcının doğruluğu şu şekilde hesaplanabilir -
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')Şimdi, çıktıyı tahmin edebiliriz -
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))Yukarıdaki program aşağıdaki çıktıyı üretecektir -
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> femaleYukarıdaki çıktıda maksimum son harf sayısındaki doğruluğun iki olduğunu ve son harf sayısı arttıkça azaldığını görebiliyoruz.
Konu Modelleme: Metin Verilerindeki Modelleri Tanımlama
Genel olarak belgelerin konulara göre gruplandırıldığını biliyoruz. Bazen bir metindeki belirli bir konuya karşılık gelen kalıpları belirlememiz gerekir. Bunu yapma tekniğine konu modelleme denir. Diğer bir deyişle, konu modellemenin verilen belge setindeki soyut temaları veya gizli yapıyı ortaya çıkarmak için bir teknik olduğunu söyleyebiliriz.
Konu modelleme tekniğini aşağıdaki senaryolarda kullanabiliriz -
Metin Sınıflandırması
Konu modellemesinin yardımıyla, her bir kelimeyi ayrı ayrı bir özellik olarak kullanmak yerine, benzer kelimeleri bir arada gruplandırdığı için sınıflandırma geliştirilebilir.
Öneri Sistemleri
Konu modelleme yardımıyla, benzerlik ölçülerini kullanarak tavsiye sistemlerini oluşturabiliriz.
Konu Modelleme Algoritmaları
Konu modelleme, algoritmalar kullanılarak gerçekleştirilebilir. Algoritmalar aşağıdaki gibidir -
Gizli Dirichlet Tahsisi (LDA)
Bu algoritma, konu modelleme için en popüler olanıdır. Konu modellemesini uygulamak için olasılıklı grafik modelleri kullanır. LDA slgorithm'i kullanmak için Python'da gensim paketini içe aktarmamız gerekiyor.
Gizli Anlamsal Analiz (LDA) veya Gizli Anlamsal İndeksleme (LSI)
Bu algoritma, Doğrusal Cebire dayanmaktadır. Temel olarak, belge terimi matrisinde SVD (Tekil Değer Ayrışımı) kavramını kullanır.
Negatif Olmayan Matris Ayrıştırması (NMF)
Aynı zamanda Lineer Cebire dayanmaktadır.
Konu modelleme için yukarıda bahsedilen algoritmaların tümü, number of topics parametre olarak, Document-Word Matrix girdi olarak ve WTM (Word Topic Matrix) & TDM (Topic Document Matrix) çıktı olarak.