Python ile AI - Hızlı Kılavuz
Bilgisayarların veya makinelerin icadından bu yana, çeşitli görevleri yerine getirme yetenekleri katlanarak bir büyüme yaşadı. İnsanlar, bilgisayar sistemlerinin gücünü, farklı çalışma alanları, artan hızları ve zamana göre küçülen boyutları açısından geliştirdiler.
Yapay Zeka adlı bir Bilgisayar Bilimi dalı, insanlar kadar akıllı bilgisayarlar veya makineler yaratmayı hedefliyor.
Yapay Zekanın Temel Kavramı (AI)
Yapay Zekanın babası John McCarthy'ye göre, "Akıllı makineler, özellikle akıllı bilgisayar programları yapma bilimi ve mühendisliği" dir.
Yapay Zeka, akıllı insanların düşündüğü gibi bir bilgisayarı, bilgisayar kontrollü bir robotu veya bir yazılımı akıllıca düşündürmenin bir yoludur. AI, insan beyninin nasıl düşündüğünü ve bir sorunu çözmeye çalışırken insanların nasıl öğrendiğini, karar verdiğini ve çalıştığını inceleyerek ve ardından bu çalışmanın sonuçlarını akıllı yazılım ve sistemler geliştirmenin temeli olarak kullanarak başarılır.
Bilgisayar sistemlerinin gücünü, insanın merakını istismar ederken, merak etmesine neden olan bir makine, "Bir makine insanlar gibi düşünebilir ve davranabilir mi?"
Böylece, AI'nın gelişimi, insanlarda yüksek bulduğumuz ve değer verdiğimiz makinelerde benzer zeka yaratma niyetiyle başladı.
Yapay Zeka Öğrenmenin Gerekliliği
Yapay zekanın, insanlar kadar akıllı makineler yaratmaya çalıştığını bildiğimiz gibi. AI çalışmamız için çok sayıda neden var. Sebepler aşağıdaki gibidir -
AI, veriler aracılığıyla öğrenebilir
Günlük hayatımızda büyük miktarda veriyle uğraşıyoruz ve insan beyni bu kadar çok veriyi takip edemiyor. Bu yüzden işleri otomatikleştirmemiz gerekiyor. Otomasyon yapmak için AI çalışmamız gerekir çünkü verilerden öğrenebilir ve tekrar eden görevleri doğru ve yorulmadan yapabilir.
AI kendi kendine öğretebilir
Verinin kendisi değişmeye devam ettiği ve bu tür verilerden elde edilen bilginin sürekli olarak güncellenmesi gerektiğinden bir sistemin kendini öğretmesi çok gereklidir. Bu amacı gerçekleştirmek için AI kullanabiliriz çünkü AI özellikli bir sistem kendi kendine öğretebilir.
AI gerçek zamanlı olarak yanıt verebilir
Yapay zeka, sinir ağları yardımıyla verileri daha derinlemesine analiz edebilir. Bu yetenek sayesinde, AI gerçek zamanlı olarak koşullara dayalı durumları düşünebilir ve bunlara yanıt verebilir.
AI doğruluğa ulaşır
Derin sinir ağlarının yardımıyla, yapay zeka muazzam bir doğruluk elde edebilir. AI, tıp alanında hastaların MRI'larından kanser gibi hastalıkları teşhis etmeye yardımcı olur.
AI, en iyi şekilde yararlanmak için verileri düzenleyebilir
Veriler, kendi kendine öğrenen algoritmaları kullanan sistemler için fikri mülkiyettir. Verileri her zaman en iyi sonuçları verecek şekilde endekslemek ve düzenlemek için yapay zekaya ihtiyacımız var.
Zekayı Anlamak
AI ile akıllı sistemler kurulabilir. Beynimizin kendisi gibi başka bir zeka sistemi kurabilmesi için zeka kavramını anlamalıyız.
Zeka nedir?
Bir sistemin hesaplama, akıl yürütme, ilişkileri ve analojileri algılama, deneyimlerden öğrenme, hafızadan bilgi saklama ve geri alma, problem çözme, karmaşık fikirleri kavrama, doğal dili akıcı bir şekilde kullanma, yeni durumları sınıflandırma, genelleme ve uyarlama becerisi.
Zeka Türleri
Amerikalı bir gelişim psikoloğu Howard Gardner tarafından açıklandığı gibi, Zeka çok yönlü olarak gelir -
| Sr.No | Zeka ve Açıklama | Misal |
|---|---|---|
| 1 | Linguistic intelligence Fonoloji (konuşma sesleri), sözdizimi (dilbilgisi) ve anlambilim (anlam) mekanizmalarını konuşma, tanıma ve kullanma becerisi. |
Anlatıcılar, Hatipler |
| 2 | Musical intelligence Sesten oluşan anlamları, perdeyi, ritmi anlama, yaratma, iletişim kurma ve anlama yeteneği. |
Müzisyenler, Şarkıcılar, Besteciler |
| 3 | Logical-mathematical intelligence Eylem veya nesnelerin yokluğunda ilişkileri kullanma ve anlama yeteneği. Aynı zamanda karmaşık ve soyut fikirleri anlama yeteneğidir. |
Matematikçiler, Bilim Adamları |
| 4 | Spatial intelligence Görsel veya mekansal bilgileri algılama, değiştirme ve nesnelere referans vermeden görsel görüntüleri yeniden oluşturma, 3B görüntüler oluşturma ve bunları taşıma ve döndürme becerisi. |
Harita okuyucuları, Astronotlar, Fizikçiler |
| 5 | Bodily-Kinesthetic intelligence Problemleri veya ürünleri çözmek için vücudun tamamını veya bir bölümünü kullanma, ince ve kaba motor becerilerini kontrol etme ve nesneleri manipüle etme becerisi. |
Oyuncular, Dansçılar |
| 6 | Intra-personal intelligence Kişinin kendi hislerini, niyetlerini ve motivasyonlarını ayırt etme yeteneği. |
Gautam Buddhha |
| 7 | Interpersonal intelligence Diğer insanların duygularını, inançlarını ve niyetlerini tanıma ve bunlar arasında ayrım yapma yeteneği. |
Kitle İletişimcileri, Röportajcılar |
Bir makinenin veya bir sistemin en az bir veya tüm zeka ile donatıldığında yapay olarak akıllı olduğunu söyleyebilirsiniz.
Zeka Nedir?
Zeka soyuttur. Şunlardan oluşur -
- Reasoning
- Learning
- Problem çözme
- Perception
- Dilbilimsel Zeka

Kısaca tüm bileşenlerin üzerinden geçelim -
Muhakeme
Yargılama, karar verme ve tahmin için temel oluşturmamızı sağlayan süreçler bütünüdür. Genel olarak iki tür vardır -
| Endüktif Akıl Yürütme | Tümdengelim |
|---|---|
| Geniş genel açıklamalar yapmak için özel gözlemler yapar. | Genel bir ifadeyle başlar ve belirli, mantıklı bir sonuca ulaşma olasılıklarını inceler. |
| Tüm önermeler bir ifadede doğru olsa bile, tümevarımsal akıl yürütme, sonucun yanlış olmasına izin verir. | Genel olarak bir şeyler sınıfı için bir şey doğruysa, o sınıfın tüm üyeleri için de geçerlidir. |
| Example - "Nita bir öğretmen. Nita çalışkan. Bu nedenle, Tüm öğretmenler çalışkan." | Example - "60 yaş üstü tüm kadınlar büyükanne. Shalini 65 yaşında. Dolayısıyla Shalini bir büyükanne." |
Öğrenme - l
Öğrenme yeteneğine insanlar, belirli hayvan türleri ve yapay zeka destekli sistemler sahiptir. Öğrenme aşağıdaki şekilde kategorize edilir -
İşitsel Öğrenme
Dinleyerek ve duyarak öğrenmektir. Örneğin, kayıtlı sesli dersleri dinleyen öğrenciler.
Epizodik Öğrenme
Tanık olduğu veya deneyimlediği olayların sıralarını hatırlayarak öğrenmek. Bu doğrusal ve düzenlidir.
Motor Öğrenme
Kasların hassas hareketleriyle öğrenmektir. Örneğin, nesneleri seçmek, yazmak vb.
Gözlemsel öğrenme
Başkalarını izleyerek ve taklit ederek öğrenmek. Örneğin çocuk ebeveynini taklit ederek öğrenmeye çalışır.
Algısal Öğrenme
Daha önce gördüğü uyaranları tanımayı öğrenmektir. Örneğin, nesneleri ve durumları tanımlama ve sınıflandırma.
İlişkisel Öğrenme
Mutlak özellikler yerine ilişkisel özellikler temelinde çeşitli uyaranlar arasında ayrım yapmayı öğrenmeyi içerir. Örneğin, son kez tuzlu olan patatesleri pişirirken 'biraz daha az' tuz eklemek, diyelim ki bir çorba kaşığı tuz ilave ederek pişirin.
Spatial Learning - Görüntüler, renkler, haritalar vb. Görsel uyaranlarla öğrenmektir. Örneğin, Bir kişi gerçekten yolu takip etmeden önce akılda bir yol haritası oluşturabilir.
Stimulus-Response Learning- Belirli bir uyaran varken belirli bir davranışı gerçekleştirmeyi öğrenmektir. Örneğin, bir köpek kapı zilini duyunca kulağını kaldırır.
Problem çözme
Bilinen ya da bilinmeyen engellerle tıkanan bir yol izleyerek mevcut durumdan istenilen bir çözüme ulaşmaya çalışılması ve algılanması sürecidir.
Problem çözme ayrıca şunları içerir: decision making, istenen hedefe ulaşmak için birden fazla alternatif arasından en uygun alternatifi seçme sürecidir.
Algı
Duyusal bilgiyi edinme, yorumlama, seçme ve organize etme sürecidir.
Algı varsayar sensing. İnsanlarda algıya duyu organları yardımcı olur. AI alanında algı mekanizması, sensörler tarafından elde edilen verileri anlamlı bir şekilde bir araya getirir.
Dilbilimsel Zeka
Sözlü ve yazılı dili kullanma, anlama, konuşma ve yazma becerisidir. Kişilerarası iletişimde önemlidir.
Yapay Zekaya Neler Dahil?
Yapay zeka, geniş bir çalışma alanıdır. Bu çalışma alanı, gerçek dünya sorunlarına çözüm bulmada yardımcı olur.
Şimdi yapay zeka içindeki farklı çalışma alanlarını görelim -
Makine öğrenme
AI'nın en popüler alanlarından biridir. Bu dosyadaki temel kavram, makinenin verilerden öğrenilmesi ve insanların deneyimlerinden öğrenebilmesidir. Bilinmeyen veriler üzerinde tahminlerin yapılabileceği temelde öğrenme modelleri içerir.
Mantık
Bilgisayar programlarını yürütmek için matematiksel mantığın kullanıldığı bir diğer önemli çalışma alanıdır. Kalıp eşleştirme, anlamsal analiz vb. Gerçekleştirmek için kurallar ve gerçekleri içerir.
Aranıyor
Bu çalışma alanı temelde satranç, tic-tac-toe gibi oyunlarda kullanılmaktadır. Arama algoritmaları, tüm arama alanını araştırdıktan sonra en uygun çözümü verir.
Yapay sinir ağları
Bu, ana teması biyolojik sinir ağları analojisinden ödünç alınan verimli bir bilgi işlem sistemleri ağıdır. YSA robotik, konuşma tanıma, konuşma işleme vb. Alanlarda kullanılabilir.
Genetik Algoritma
Genetik algoritmalar, birden fazla programın yardımıyla problemlerin çözülmesine yardımcı olur. Sonuç, en uygun olanı seçmeye dayanır.
Bilgi temsili
Makine tarafından anlaşılabilir bir şekilde gerçekleri temsil edebileceğimiz çalışma alanıdır. Bilgi ne kadar verimli bir şekilde temsil edilir; daha fazla sistem akıllı olacaktır.
AI Uygulaması
Bu bölümde, AI tarafından desteklenen farklı alanları göreceğiz -
Oyun
Yapay zeka, satranç, poker, tic-tac-toe gibi stratejik oyunlarda, makinenin sezgisel bilgiye dayalı olarak çok sayıda olası konumu düşünebildiği çok önemli bir rol oynar.
Doğal Dil İşleme
İnsanlar tarafından konuşulan doğal dili anlayan bilgisayarla etkileşim kurmak mümkündür.
Uzman sistemler
Muhakeme ve tavsiye vermek için makine, yazılım ve özel bilgileri entegre eden bazı uygulamalar vardır. Kullanıcılara açıklama ve tavsiye sağlarlar.
Görüntü Sistemleri
Bu sistemler bilgisayardaki görsel girdiyi anlar, yorumlar ve kavrar. Örneğin,
Bir casus uçak, alanların mekansal bilgilerini veya haritasını çıkarmak için kullanılan fotoğrafları çeker.
Doktorlar hastayı teşhis etmek için klinik uzman sistemi kullanır.
Polis, adli tıp sanatçısı tarafından yapılan saklanan portre ile suçlunun yüzünü tanıyabilen bilgisayar yazılımı kullanıyor.
Konuşma tanıma
Bazı akıllı sistemler, bir insan konuşurken dili cümleler ve anlamları açısından duyabilir ve kavrayabilir. Farklı aksanları, argo sözcükleri, arka plandaki gürültüyü, soğuk nedeniyle insan gürültüsündeki değişiklikleri vb. İşleyebilir.
Elyazısı tanıma
El yazısı tanıma yazılımı, bir kalemle kağıda veya ekrana kalemle yazılan metni okur. Harflerin şekillerini tanıyabilir ve onu düzenlenebilir metne dönüştürebilir.
Akıllı Robotlar
Robotlar, bir insan tarafından verilen görevleri yerine getirebilir. Işık, ısı, sıcaklık, hareket, ses, çarpma ve basınç gibi gerçek dünyadan fiziksel verileri algılamak için sensörleri vardır. Zeka sergilemek için verimli işlemcilere, birden fazla sensöre ve devasa belleğe sahipler. Ayrıca hatalarından ders çıkarabilir ve yeni ortama uyum sağlayabilirler.
Bilişsel Modelleme: İnsan Düşünme Prosedürünün Simülasyonu
Bilişsel modelleme, temel olarak, insanoğlunun düşünme sürecini incelemek ve simüle etmekle ilgilenen bilgisayar bilimi içindeki çalışma alanıdır. AI'nın ana görevi, makinenin insan gibi düşünmesini sağlamaktır. İnsan düşünme sürecinin en önemli özelliği problem çözmektir. Bu nedenle, bilişsel modelleme, insanların sorunları nasıl çözebileceklerini anlamaya çalışır. Bundan sonra, bu model makine öğrenimi, robotik, doğal dil işleme vb. Gibi çeşitli yapay zeka uygulamaları için kullanılabilir. Aşağıda, insan beyninin farklı düşünme düzeylerinin diyagramı verilmiştir -

Aracı ve Çevre
Bu bölümde, ajan ve çevreye ve bunların Yapay Zeka'ya nasıl yardımcı olduğuna odaklanacağız.
Ajan
Bir ajan, çevresini sensörler aracılığıyla algılayabilen ve efektörler aracılığıyla o ortama etki eden herhangi bir şeydir.
Bir human agent sensörlere paralel göz, kulak, burun, dil ve deri gibi duyu organları ile efektörler için eller, bacaklar, ağız gibi diğer organlara sahiptir.
Bir robotic agent sensörler için kameraların ve kızılötesi mesafe bulucuların ve efektörler için çeşitli motorların ve aktüatörlerin yerini alır.
Bir software agent programları ve eylemleri olarak bit dizilerini kodlamıştır.
Çevre
Bazı programlar tamamen artificial environment klavye girişi, veritabanı, bilgisayar dosya sistemleri ve bir ekranda karakter çıkışı ile sınırlıdır.
Buna karşılık, bazı yazılım aracıları (yazılım robotları veya yazılım robotları) zengin, sınırsız yazılım alanlarında bulunur. Simülatörde birvery detailed, complex environment. Yazılım temsilcisinin gerçek zamanlı olarak uzun bir eylem dizisi arasından seçim yapması gerekir. Bir softbot, müşterinin çevrimiçi tercihlerini taramak için tasarlanmıştır ve müşteriye ilginç öğeler gösterir.real yanı sıra bir artificial çevre.
Bu bölümde Python'a nasıl başlayacağımızı öğreneceğiz. Python'un Yapay Zeka için nasıl yardımcı olduğunu da anlayacağız.
Neden AI için Python
Yapay zeka, geleceğin trend teknolojisi olarak kabul ediliyor. Zaten üzerinde yapılmış bir dizi uygulama var. Bundan dolayı pek çok firma ve araştırmacı ilgi görüyor. Ancak burada ortaya çıkan ana soru, bu AI uygulamaları hangi programlama dilinde geliştirilebilir? AI uygulamalarını geliştirmek için kullanılabilecek Lisp, Prolog, C ++, Java ve Python gibi çeşitli programlama dilleri vardır. Bunların arasında Python programlama dili büyük bir popülerlik kazanıyor ve nedenleri şu şekildedir -
Basit sözdizimi ve daha az kodlama
Python, AI uygulamaları geliştirmek için kullanılabilecek diğer programlama dilleri arasında çok daha az kodlama ve basit sözdizimi içerir. Bu özellik sayesinde test etmek daha kolay olabilir ve programlamaya daha fazla odaklanabiliyoruz.
AI projeleri için dahili kitaplıklar
AI için Python kullanmanın en büyük avantajı, dahili kitaplıklarla birlikte gelmesidir. Python, neredeyse tüm AI projeleri için kitaplıklara sahiptir. Örneğin,NumPy, SciPy, matplotlib, nltk, SimpleAI Python'un bazı önemli dahili kütüphaneleridir.
Open source- Python açık kaynaklı bir programlama dilidir. Bu, onu toplulukta oldukça popüler kılar.
Can be used for broad range of programming- Python, küçük kabuk komut dosyası gibi kurumsal web uygulamalarına kadar çok çeşitli programlama görevleri için kullanılabilir. Python'un AI projeleri için uygun olmasının bir başka nedeni de budur.
Python'un Özellikleri
Python, yüksek seviyeli, yorumlanmış, etkileşimli ve nesne yönelimli bir betik dilidir. Python, son derece okunabilir olacak şekilde tasarlanmıştır. Diğer dillerin noktalama işaretlerini kullandığı yerlerde sık sık İngilizce anahtar sözcükler kullanır ve diğer dillerden daha az sözdizimsel yapıya sahiptir. Python'un özellikleri şunları içerir -
Easy-to-learn- Python'da birkaç anahtar kelime, basit yapı ve açıkça tanımlanmış bir sözdizimi vardır. Bu, öğrencinin dili hızlı bir şekilde almasını sağlar.
Easy-to-read - Python kodu daha net tanımlanmıştır ve gözler tarafından görülebilir.
Easy-to-maintain - Python'un kaynak kodunun bakımı oldukça kolaydır.
A broad standard library - Python'un kütüphanenin büyük kısmı çok taşınabilir ve UNIX, Windows ve Macintosh'ta çapraz platform uyumludur.
Interactive Mode - Python, kod parçacıklarının etkileşimli testine ve hata ayıklamasına izin veren etkileşimli bir mod desteğine sahiptir.
Portable - Python, çok çeşitli donanım platformlarında çalışabilir ve tüm platformlarda aynı arayüze sahiptir.
Extendable- Python yorumlayıcısına düşük seviyeli modüller ekleyebiliriz. Bu modüller, programcıların araçlarını daha verimli olacak şekilde eklemelerini veya özelleştirmelerini sağlar.
Databases - Python, tüm büyük ticari veritabanlarına arayüz sağlar.
GUI Programming - Python, Windows MFC, Macintosh ve Unix'in X Window sistemi gibi birçok sistem çağrısına, kitaplığa ve Windows sistemine oluşturulabilen ve taşınabilen GUI uygulamalarını destekler.
Scalable - Python, büyük programlar için kabuk komut dosyalarına göre daha iyi bir yapı ve destek sağlar.
Python'un önemli özellikleri
Şimdi Python'un aşağıdaki önemli özelliklerini ele alalım -
İşlevsel ve yapılandırılmış programlama yöntemlerinin yanı sıra OOP'yi de destekler.
Bir komut dosyası dili olarak kullanılabilir veya büyük uygulamalar oluşturmak için bayt koduna derlenebilir.
Çok yüksek düzeyde dinamik veri türleri sağlar ve dinamik tür denetimini destekler.
Otomatik çöp toplamayı destekler.
C, C ++, COM, ActiveX, CORBA ve Java ile kolayca entegre edilebilir.
Python'u Yükleme
Python dağıtımı çok sayıda platform için mevcuttur. Yalnızca platformunuz için geçerli olan ikili kodu indirmeniz ve Python'u kurmanız gerekir.
Platformunuz için ikili kod mevcut değilse, kaynak kodunu manuel olarak derlemek için bir C derleyicisine ihtiyacınız vardır. Kaynak kodunu derlemek, kurulumunuzda ihtiyaç duyduğunuz özelliklerin seçimi açısından daha fazla esneklik sunar.
İşte Python'u çeşitli platformlara kurmaya hızlı bir bakış -
Unix ve Linux Kurulumu
Python'u Unix / Linux makinesine kurmak için aşağıdaki adımları izleyin.
Bir Web tarayıcısı açın ve şuraya gidin: https://www.python.org/downloads
Unix / Linux için mevcut olan sıkıştırılmış kaynak kodunu indirmek için bağlantıyı takip edin.
Dosyaları indirin ve çıkarın.
Bazı seçenekleri özelleştirmek istiyorsanız Modüller / Kurulum dosyasını düzenleme .
./configure komut dosyasını çalıştırın
make
kurmak yap
Bu, Python'u / usr / local / bin standart konumuna ve kitaplıklarını / usr / local / lib / pythonXX'e yükler ; burada XX, Python sürümüdür.
Windows Kurulumu
Python'u Windows makinesine yüklemek için bu adımları izleyin.
Bir Web tarayıcısı açın ve şuraya gidin: https://www.python.org/downloads
Windows yükleyici python-XYZ .msi dosyası için bağlantıyı izleyin; burada XYZ, yüklemeniz gereken sürümdür.
Bu yükleyiciyi python-XYZ .msi'yi kullanmak için, Windows sisteminin Microsoft Installer 2.0'ı desteklemesi gerekir. Yükleyici dosyasını yerel makinenize kaydedin ve ardından makinenizin MSI'yı destekleyip desteklemediğini öğrenmek için çalıştırın.
İndirilen dosyayı çalıştırın. Bu, kullanımı gerçekten kolay olan Python kurulum sihirbazını getirir. Varsayılan ayarları kabul edin ve kurulum bitene kadar bekleyin.
Macintosh Kurulumu
Mac OS X kullanıyorsanız, Python 3'ü yüklemek için Homebrew kullanmanız önerilir. Mac OS X için harika bir paket yükleyicidir ve kullanımı gerçekten çok kolaydır. Homebrew'iniz yoksa, aşağıdaki komutu kullanarak kurabilirsiniz -
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"Paket yöneticisini aşağıdaki komutla güncelleyebiliriz -
$ brew updateŞimdi sisteminize Python3 yüklemek için aşağıdaki komutu çalıştırın -
$ brew install python3PATH kurulumu
Programlar ve diğer yürütülebilir dosyalar birçok dizinde olabilir, bu nedenle işletim sistemleri, işletim sisteminin yürütülebilir dosyaları aradığı dizinleri listeleyen bir arama yolu sağlar.
Yol, işletim sistemi tarafından tutulan adlandırılmış bir dize olan bir ortam değişkeninde saklanır. Bu değişken, komut kabuğunda ve diğer programlarda bulunan bilgileri içerir.
Yol değişkeni, Unix'te PATH veya Windows'ta Yol olarak adlandırılır (Unix büyük / küçük harfe duyarlıdır; Windows değildir).
Mac OS'de, yükleyici yol ayrıntılarını yönetir. Herhangi bir dizinden Python yorumlayıcısını çağırmak için, Python dizinini yolunuza eklemelisiniz.
Unix / Linux'ta Yol Ayarlama
Python dizinini Unix'te belirli bir oturumun yoluna eklemek için -
Csh kabuğunda
Tür setenv PATH "$PATH:/usr/local/bin/python" ve bas Enter.
Bash kabuğunda (Linux)
Tür export ATH = "$PATH:/usr/local/bin/python" ve bas Enter.
Sh veya ksh kabuğunda
Tür PATH = "$PATH:/usr/local/bin/python" ve bas Enter.
Note - / usr / local / bin / python, Python dizininin yoludur.
Windows'ta Yol Ayarlama
Python dizinini Windows'ta belirli bir oturumun yoluna eklemek için -
At the command prompt - tür path %path%;C:\Python ve bas Enter.
Note - C: \ Python, Python dizininin yoludur.
Python çalıştırma
Şimdi Python'u çalıştırmanın farklı yollarını görelim. Yollar aşağıda açıklanmıştır -
Etkileşimli Tercüman
Python'u Unix, DOS veya size bir komut satırı yorumlayıcısı veya kabuk penceresi sağlayan diğer herhangi bir sistemden başlatabiliriz.
Giriş python komut satırında.
Etkileşimli yorumlayıcıda hemen kodlamaya başlayın.
$python # Unix/Linuxveya
python% # Unix/Linuxveya
C:> python # Windows/DOSİşte tüm mevcut komut satırı seçeneklerinin listesi -
| S.No. | Seçenek ve Açıklama |
|---|---|
| 1 | -d Hata ayıklama çıktısı sağlar. |
| 2 | -o Optimize edilmiş bayt kodu üretir (sonuç olarak .pyo dosyalarıyla sonuçlanır). |
| 3 | -S Başlangıçta Python yollarını aramak için içe aktarma sitesini çalıştırmayın. |
| 4 | -v Ayrıntılı çıktı (ithalat bildirimlerinde ayrıntılı izleme). |
| 5 | -x Sınıf tabanlı yerleşik istisnaları devre dışı bırakır (yalnızca dizeleri kullanın); 1.6 sürümünden itibaren kullanılmamaktadır. |
| 6 | -c cmd Cmd dizesi olarak gönderilen Python betiğini çalıştırır. |
| 7 | File Verilen dosyadan Python betiğini çalıştırın. |
Komut satırından komut dosyası
Aşağıdaki gibi uygulamanızda yorumlayıcıyı çalıştırarak komut satırında bir Python betiği çalıştırılabilir -
$python script.py # Unix/Linuxveya,
python% script.py # Unix/Linuxveya,
C:> python script.py # Windows/DOSNote - Dosya izin modunun yürütmeye izin verdiğinden emin olun.
Entegre geliştirme ortamı
Sisteminizde Python'u destekleyen bir GUI uygulamanız varsa, Python'u bir Grafik Kullanıcı Arayüzü (GUI) ortamından da çalıştırabilirsiniz.
Unix - IDLE, Python için ilk Unix IDE'dir.
Windows - PythonWin, Python için ilk Windows arayüzüdür ve GUI'li bir IDE'dir.
Macintosh - IDLE IDE ile birlikte Python'un Macintosh sürümü ana web sitesinden edinilebilir, MacBinary veya BinHex dosyaları olarak indirilebilir.
Ortamı düzgün bir şekilde ayarlayamıyorsanız, sistem yöneticinizden yardım alabilirsiniz. Python ortamının doğru şekilde kurulduğundan ve mükemmel şekilde çalıştığından emin olun.
Anaconda adlı başka bir Python platformunu da kullanabiliriz. Yüzlerce popüler veri bilimi paketini ve Windows, Linux ve MacOS için conda paketi ve sanal ortam yöneticisini içerir. Bağlantıdan işletim sisteminize göre indirebilirsiniz.https://www.anaconda.com/download/.
Bu eğitim için MS Windows üzerinde Python 3.6.3 sürümünü kullanıyoruz.
Öğrenme, çalışma veya deneyim yoluyla bilgi veya becerilerin edinilmesi anlamına gelir. Buna dayanarak, makine öğrenimini (ML) şu şekilde tanımlayabiliriz -
Bilgisayar bilimi alanı olarak tanımlanabilir, daha özel olarak bilgisayar sistemlerine verilerle öğrenme ve açıkça programlanmadan deneyimlerden gelişme yeteneği sağlayan bir yapay zeka uygulaması olarak tanımlanabilir.
Temel olarak, makine öğreniminin ana odak noktası, bilgisayarların insan müdahalesi olmadan otomatik olarak öğrenmesine izin vermektir. Şimdi soru, böyle bir öğrenmenin nasıl başlatılıp yapılabileceği sorusu ortaya çıkıyor. Verilerin gözlemlenmesi ile başlanabilir. Veriler bazı örnekler, talimatlar veya bazı doğrudan deneyimler olabilir. Daha sonra bu girdiye dayanarak, makine verilerdeki bazı kalıpları arayarak daha iyi kararlar verir.
Makine Öğrenimi Türleri (ML)
Makine Öğrenimi Algoritmaları, bilgisayar sisteminin açıkça programlanmadan öğrenmesine yardımcı olur. Bu algoritmalar denetimli veya denetimsiz olarak kategorize edilir. Şimdi birkaç algoritmaya bakalım -
Denetlenen makine öğrenimi algoritmaları
Bu, en yaygın kullanılan makine öğrenimi algoritmasıdır. Denetimli olarak adlandırılır çünkü eğitim veri setinden algoritma öğrenme süreci, öğrenme sürecini denetleyen bir öğretmen olarak düşünülebilir. Bu tür bir makine öğrenimi algoritmasında, olası sonuçlar zaten bilinmektedir ve eğitim verileri de doğru yanıtlarla etiketlenmiştir. Şu şekilde anlaşılabilir -
Giriş değişkenlerimiz olduğunu varsayalım x ve bir çıktı değişkeni y ve girdiden çıktıya eşleme işlevini öğrenmek için bir algoritma uyguladık, örneğin -
Y = f(x)Şimdi, ana hedef, eşleme işlevine o kadar iyi yaklaşmaktır ki, yeni girdi verisine (x) sahip olduğumuzda, bu veri için çıktı değişkenini (Y) tahmin edebiliriz.
Temelde denetlenen eğilme sorunları aşağıdaki iki tür soruna ayrılabilir:
Classification - "Siyah", "öğretme", "öğretmeme" gibi kategorize edilmiş çıktılara sahip olduğumuzda bir soruna sınıflandırma problemi denir.
Regression - "Mesafe", "kilogram" gibi gerçek değer çıktısına sahip olduğumuzda bir soruna regresyon problemi denir.
Karar ağacı, rastgele orman, knn, lojistik regresyon, denetimli makine öğrenimi algoritmalarına örnektir.
Denetimsiz makine öğrenimi algoritmaları
Adından da anlaşılacağı gibi, bu tür makine öğrenimi algoritmalarının herhangi bir rehberlik sağlayacak bir denetçisi yoktur. Bu nedenle, denetimsiz makine öğrenimi algoritmaları, bazılarının gerçek yapay zeka dediği şeyle yakından uyumludur. Şu şekilde anlaşılabilir -
Diyelim ki giriş değişkenimiz x var, o zaman denetimli öğrenme algoritmalarında olduğu gibi karşılık gelen çıktı değişkenleri olmayacak.
Basit bir deyişle, denetimsiz öğrenmede rehberlik için doğru cevap ve öğretmenin olmayacağını söyleyebiliriz. Algoritmalar, verilerdeki ilginç kalıpları keşfetmeye yardımcı olur.
Denetimsiz öğrenme sorunları aşağıdaki iki tür soruna ayrılabilir:
Clustering- Kümeleme problemlerinde, verilerdeki içsel gruplamaları keşfetmemiz gerekir. Örneğin, müşterileri satın alma davranışlarına göre gruplamak.
Association- Bir soruna ilişkilendirme sorunu denir çünkü bu tür sorunlar, verilerimizin büyük bir bölümünü tanımlayan kuralları keşfetmeyi gerektirir. Örneğin, her ikisini de alan müşterileri bulmakx ve y.
Kümeleme için K-araçları, ilişkilendirme için Apriori algoritması, denetimsiz makine öğrenme algoritmalarına örnektir.
Güçlendirme makine öğrenimi algoritmaları
Bu tür makine öğrenimi algoritmaları çok daha az kullanılır. Bu algoritmalar, sistemleri belirli kararlar almaları için eğitir. Temel olarak makine, deneme yanılma yöntemini kullanarak sürekli kendini eğittiği bir ortama maruz kalır. Bu algoritmalar geçmiş deneyimlerden öğrenir ve doğru kararlar vermek için mümkün olan en iyi bilgiyi yakalamaya çalışır. Markov Karar Süreci, pekiştirme makine öğrenimi algoritmalarına bir örnektir.
En Yaygın Makine Öğrenimi Algoritmaları
Bu bölümde, en yaygın makine öğrenimi algoritmaları hakkında bilgi edineceğiz. Algoritmalar aşağıda açıklanmıştır -
Doğrusal Regresyon
İstatistik ve makine öğreniminde en iyi bilinen algoritmalardan biridir.
Temel kavram - Esas olarak doğrusal regresyon, x diyelim giriş değişkenleri ve y diyelim tek çıkış değişkeni arasında doğrusal bir ilişki varsayan doğrusal bir modeldir. Başka bir deyişle, y'nin x girdi değişkenlerinin doğrusal bir kombinasyonundan hesaplanabileceğini söyleyebiliriz. Değişkenler arasındaki ilişki, bir en iyi doğrunun uydurulmasıyla kurulabilir.
Doğrusal Regresyon Türleri
Doğrusal regresyon aşağıdaki iki türdendir -
Simple linear regression - Doğrusal regresyon algoritması, yalnızca bir bağımsız değişkene sahipse basit doğrusal regresyon olarak adlandırılır.
Multiple linear regression - Doğrusal regresyon algoritması, birden fazla bağımsız değişkene sahipse çoklu doğrusal regresyon olarak adlandırılır.
Doğrusal regresyon, esas olarak sürekli değişken (ler) e dayalı gerçek değerleri tahmin etmek için kullanılır. Örneğin, bir mağazanın bir gün içindeki toplam satışı, gerçek değerlere dayalı olarak doğrusal regresyon ile tahmin edilebilir.
Lojistik regresyon
Bir sınıflandırma algoritmasıdır ve aynı zamanda logit gerileme.
Temelde lojistik regresyon, belirli bir bağımsız değişken kümesine dayalı olarak 0 veya 1, doğru veya yanlış, evet veya hayır gibi ayrı değerleri tahmin etmek için kullanılan bir sınıflandırma algoritmasıdır. Temel olarak, çıktısının 0 ile 1 arasında olması olasılığını tahmin eder.
Karar ağacı
Karar ağacı, çoğunlukla sınıflandırma problemleri için kullanılan denetimli bir öğrenme algoritmasıdır.
Temel olarak, bağımsız değişkenlere dayanan özyinelemeli bölüm olarak ifade edilen bir sınıflandırıcıdır. Karar ağacının köklü ağacı oluşturan düğümleri vardır. Köklü ağaç, "kök" adı verilen bir düğüme sahip yönlendirilmiş bir ağaçtır. Kök herhangi bir gelen kenara sahip değildir ve diğer tüm düğümlerin bir gelen kenarı vardır. Bu düğümlere yapraklar veya karar düğümleri denir. Örneğin, bir kişinin uygun olup olmadığını görmek için aşağıdaki karar ağacını düşünün.

Destek Vektör Makinesi (SVM)
Hem sınıflandırma hem de regresyon problemleri için kullanılır. Ancak esas olarak sınıflandırma problemleri için kullanılır. SVM'nin ana kavramı, her bir veri öğesini n boyutlu uzayda bir nokta olarak çizmektir ve her özelliğin değeri belirli bir koordinatın değeridir. Burada n sahip olacağımız özellikler olacaktır. Aşağıda, SVM kavramını anlamak için basit bir grafik temsil verilmiştir -

Yukarıdaki diyagramda, iki özelliğimiz var, bu nedenle önce bu iki değişkeni, her noktanın destek vektörleri adı verilen iki koordinata sahip olduğu iki boyutlu uzayda çizmemiz gerekiyor. Çizgi, verileri iki farklı sınıflandırılmış gruba ayırır. Bu satır sınıflandırıcı olacaktır.
Naif bayanlar
Aynı zamanda bir sınıflandırma tekniğidir. Bu sınıflandırma tekniğinin arkasındaki mantık, sınıflandırıcılar oluşturmak için Bayes teoremini kullanmaktır. Varsayım, yordayıcıların bağımsız olmasıdır. Basit bir deyişle, bir sınıftaki belirli bir özelliğin varlığının başka herhangi bir özelliğin varlığıyla ilgisi olmadığını varsayar. Bayes teoremi için denklem aşağıdadır -
$$ P \ left (\ frac {A} {B} \ right) = \ frac {P \ left (\ frac {B} {A} \ right) P \ left (A \ sağ)} {P \ left ( B \ sağ)} $$
Naïve Bayes modelinin oluşturulması kolaydır ve özellikle büyük veri kümeleri için kullanışlıdır.
K-En Yakın Komşular (KNN)
Problemlerin hem sınıflandırılması hem de regresyonu için kullanılır. Sınıflandırma problemlerini çözmek için yaygın olarak kullanılmaktadır. Bu algoritmanın ana konsepti, mevcut tüm vakaları depolamak ve yeni vakaları k komşularının çoğunluk oylarıyla sınıflandırmasıdır. Daha sonra durum, bir mesafe fonksiyonu ile ölçülen K-en yakın komşuları arasında en yaygın olan sınıfa atanır. Uzaklık işlevi Öklid, Minkowski ve Hamming mesafesi olabilir. KNN'yi kullanmak için aşağıdakileri göz önünde bulundurun -
Hesaplama açısından KNN, sınıflandırma problemleri için kullanılan diğer algoritmalardan daha pahalıdır.
Değişkenlerin normalleştirilmesi, aksi takdirde daha yüksek aralık değişkenleri tarafından saptırılabilir.
KNN'de gürültü giderme gibi ön işleme aşamasında çalışmamız gerekiyor.
K-Kümeleme Demektir
Adından da anlaşılacağı gibi kümeleme problemlerini çözmek için kullanılır. Temelde bir tür denetimsiz öğrenmedir. K-Means kümeleme algoritmasının ana mantığı, veri kümesini bir dizi küme aracılığıyla sınıflandırmaktır. K-araçlarına göre küme oluşturmak için şu adımları izleyin -
K-anlamı, ağırlık merkezi olarak bilinen her küme için k sayıda puan alır.
Şimdi her veri noktası, en yakın ağırlık merkezlerine, yani k kümelerine sahip bir küme oluşturur.
Şimdi, mevcut küme üyelerine göre her bir kümenin centroidlerini bulacaktır.
Yakınsama gerçekleşene kadar bu adımları tekrar etmemiz gerekiyor.
Rastgele Orman
Denetimli bir sınıflandırma algoritmasıdır. Rasgele orman algoritmasının avantajı, hem sınıflandırma hem de regresyon türü problemler için kullanılabilmesidir. Temelde karar ağaçlarının (yani, orman) toplanmasıdır veya karar ağaçları topluluğu diyebilirsiniz. Rastgele ormanın temel kavramı, her ağacın bir sınıflandırma yapması ve ormanın bunlardan en iyi sınıflandırmaları seçmesidir. Rastgele Orman algoritmasının avantajları aşağıdadır -
Rastgele orman sınıflandırıcı, hem sınıflandırma hem de regresyon görevleri için kullanılabilir.
Eksik değerleri halledebilirler.
Ormanda daha fazla ağaç olsa bile modele fazla uymaz.
Denetimli ve denetimsiz makine öğrenimi algoritmaları üzerinde zaten çalıştık. Bu algoritmalar, eğitim sürecini başlatmak için biçimlendirilmiş veriler gerektirir. ML algoritmalarına girdi olarak sağlanabilmesi için verileri belirli bir şekilde hazırlamalı veya biçimlendirmeliyiz.
Bu bölüm, makine öğrenimi algoritmaları için veri hazırlamaya odaklanmaktadır.
Verileri Ön İşleme
Günlük hayatımızda birçok veriyle uğraşıyoruz ama bu veriler ham formdadır. Verileri makine öğrenimi algoritmalarının girdisi olarak sağlamak için, onu anlamlı bir veriye dönüştürmemiz gerekir. Veri ön işleme burada devreye giriyor. Diğer basit bir deyişle, verileri makine öğrenme algoritmalarına sağlamadan önce verileri önceden işlememiz gerektiğini söyleyebiliriz.
Veri ön işleme adımları
Verileri Python'da önceden işlemek için şu adımları izleyin -
Step 1 − Importing the useful packages - Python kullanıyorsak, bu, verileri belirli bir formata, yani ön işleme, dönüştürmek için ilk adım olacaktır. Aşağıdaki gibi yapılabilir -
import numpy as np
import sklearn.preprocessingBurada aşağıdaki iki paketi kullandık -
NumPy - Temel olarak NumPy, küçük çok boyutlu diziler için çok fazla hızdan ödün vermeden büyük çok boyutlu rasgele kayıt dizilerini verimli bir şekilde işlemek için tasarlanmış genel amaçlı bir dizi işleme paketidir.
Sklearn.preprocessing - Bu paket, ham özellik vektörlerini makine öğrenimi algoritmaları için daha uygun bir gösterime dönüştürmek için birçok yaygın yardımcı program işlevi ve dönüştürücü sınıfı sağlar.
Step 2 − Defining sample data - Paketleri içe aktardıktan sonra, bu verilere ön işleme tekniklerini uygulayabilmemiz için bazı örnek veriler tanımlamamız gerekir. Şimdi aşağıdaki örnek verileri tanımlayacağız -
input_data = np.array([2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8])Step3 − Applying preprocessing technique - Bu adımda, ön işleme tekniklerinden herhangi birini uygulamamız gerekiyor.
Aşağıdaki bölüm, veri ön işleme tekniklerini açıklamaktadır.
Veri Ön İşleme Teknikleri
Veri ön işleme teknikleri aşağıda açıklanmıştır -
İkilileştirme
Bu, sayısal değerlerimizi Boole değerlerine dönüştürmemiz gerektiğinde kullanılan ön işleme tekniğidir. Aşağıdaki şekilde eşik değeri olarak 0,5'i kullanarak giriş verilerini ikileştirmek için dahili bir yöntem kullanabiliriz -
data_binarized = preprocessing.Binarizer(threshold = 0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)Şimdi, yukarıdaki kodu çalıştırdıktan sonra aşağıdaki çıktıyı alacağız, 0,5'in (eşik değeri) üzerindeki tüm değerler 1'e ve 0,5'in altındaki tüm değerler 0'a dönüştürülecektir.
Binarized data
[[ 1. 0. 1.]
[ 0. 1. 1.]
[ 0. 0. 1.]
[ 1. 1. 0.]]Ortalama Kaldırma
Makine öğreniminde kullanılan çok yaygın bir başka ön işleme tekniğidir. Temel olarak, özellik vektöründen ortalamayı ortadan kaldırmak için kullanılır, böylece her özellik sıfıra ortalanır. Özellik vektöründeki özelliklerden de önyargıyı kaldırabiliriz. Örnek verilere ortalama kaldırma ön işleme tekniğini uygulamak için aşağıda gösterilen Python kodunu yazabiliriz. Kod, giriş verilerinin Ortalama ve Standart sapmasını gösterecektir -
print("Mean = ", input_data.mean(axis = 0))
print("Std deviation = ", input_data.std(axis = 0))Yukarıdaki kod satırlarını çalıştırdıktan sonra aşağıdaki çıktıyı alacağız -
Mean = [ 1.75 -1.275 2.2]
Std deviation = [ 2.71431391 4.20022321 4.69414529]Şimdi, aşağıdaki kod, giriş verilerinin Ortalama ve Standart sapmasını kaldıracaktır -
data_scaled = preprocessing.scale(input_data)
print("Mean =", data_scaled.mean(axis=0))
print("Std deviation =", data_scaled.std(axis = 0))Yukarıdaki kod satırlarını çalıştırdıktan sonra aşağıdaki çıktıyı alacağız -
Mean = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00]
Std deviation = [ 1. 1. 1.]Ölçeklendirme
Özellik vektörlerini ölçeklendirmek için kullanılan başka bir veri ön işleme tekniğidir. Özellik vektörlerinin ölçeklendirilmesi gereklidir, çünkü her özelliğin değerleri birçok rastgele değer arasında değişebilir. Yani herhangi bir özelliğin sentetik olarak büyük ya da küçük olmasını istemediğimiz için ölçeklendirmenin önemli olduğunu söyleyebiliriz. Aşağıdaki Python kodunun yardımıyla, girdi verilerimizin, yani özellik vektörünün ölçeklendirmesini yapabiliriz -
# Min max scaling
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)Yukarıdaki kod satırlarını çalıştırdıktan sonra aşağıdaki çıktıyı alacağız -
Min max scaled data
[ [ 0.48648649 0.58252427 0.99122807]
[ 0. 1. 0.81578947]
[ 0.27027027 0. 1. ]
[ 1. 0. 99029126 0. ]]Normalleştirme
Özellik vektörlerini değiştirmek için kullanılan başka bir veri ön işleme tekniğidir. Özellik vektörlerini ortak bir ölçekte ölçmek için bu tür bir modifikasyon gereklidir. Aşağıda, makine öğreniminde kullanılabilecek iki tür normalleştirme bulunmaktadır:
L1 Normalization
Aynı zamanda Least Absolute Deviations. Bu tür normalleştirme, değerleri değiştirir, böylece mutlak değerlerin toplamı her satırda her zaman 1'e kadar olur. Aşağıdaki Python kodunun yardımıyla giriş verilerine uygulanabilir -
# Normalize data
data_normalized_l1 = preprocessing.normalize(input_data, norm = 'l1')
print("\nL1 normalized data:\n", data_normalized_l1)Yukarıdaki kod satırı aşağıdaki çıktıyı üretir & miuns;
L1 normalized data:
[[ 0.22105263 -0.2 0.57894737]
[ -0.2027027 0.32432432 0.47297297]
[ 0.03571429 -0.56428571 0.4 ]
[ 0.42142857 0.16428571 -0.41428571]]L2 Normalization
Aynı zamanda least squares. Bu tür bir normalleştirme, değerleri değiştirir, böylece karelerin toplamı her satırda her zaman 1'e kadar olur. Aşağıdaki Python kodunun yardımıyla giriş verilerine uygulanabilir -
# Normalize data
data_normalized_l2 = preprocessing.normalize(input_data, norm = 'l2')
print("\nL2 normalized data:\n", data_normalized_l2)Yukarıdaki kod satırı aşağıdaki çıktıyı üretecektir -
L2 normalized data:
[[ 0.33946114 -0.30713151 0.88906489]
[ -0.33325106 0.53320169 0.7775858 ]
[ 0.05156558 -0.81473612 0.57753446]
[ 0.68706914 0.26784051 -0.6754239 ]]Verilerin Etiketlenmesi
Makine öğrenimi algoritmaları için belirli bir formattaki verilerin gerekli olduğunu zaten biliyoruz. Bir diğer önemli gereklilik de, verilerin makine öğrenimi algoritmalarının girdisi olarak gönderilmeden önce doğru şekilde etiketlenmesi gerektiğidir. Örneğin sınıflandırma hakkında konuşursak, veriler üzerinde çok sayıda etiket var. Bu etiketler kelimeler, sayılar vb. Biçimindedir. Makine öğrenimiyle ilgili işlevlersklearnverilerin numara etiketlerine sahip olması gerekir. Dolayısıyla, veriler başka bir biçimde ise sayılara dönüştürülmelidir. Sözcük etiketlerini sayısal biçime dönüştürme işlemine etiket kodlama denir.
Etiket kodlama adımları
Python'da veri etiketlerini kodlamak için şu adımları izleyin -
Step1 − Importing the useful packages
Python kullanıyorsak, bu, verileri belirli bir biçime, yani ön işleme dönüştürmek için ilk adım olacaktır. Aşağıdaki gibi yapılabilir -
import numpy as np
from sklearn import preprocessingStep 2 − Defining sample labels
Paketleri içe aktardıktan sonra, etiket kodlayıcıyı oluşturup eğitebilmemiz için bazı örnek etiketler tanımlamamız gerekir. Şimdi aşağıdaki örnek etiketleri tanımlayacağız -
# Sample input labels
input_labels = ['red','black','red','green','black','yellow','white']Step 3 − Creating & training of label encoder object
Bu adımda, etiket kodlayıcıyı oluşturmalı ve onu eğitmeliyiz. Aşağıdaki Python kodu bunu yapmanıza yardımcı olacaktır -
# Creating the label encoder
encoder = preprocessing.LabelEncoder()
encoder.fit(input_labels)Aşağıdaki Python kodunu çalıştırdıktan sonraki çıktı olacaktır -
LabelEncoder()Step4 − Checking the performance by encoding random ordered list
Bu adım, rastgele sıralı listeyi kodlayarak performansı kontrol etmek için kullanılabilir. Aşağıdaki Python kodu aynısını yapmak için yazılabilir -
# encoding a set of labels
test_labels = ['green','red','black']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)Etiketler aşağıdaki gibi yazdırılır -
Labels = ['green', 'red', 'black']Şimdi, kodlanmış değerlerin listesini, yani sayılara dönüştürülen kelime etiketlerini aşağıdaki gibi alabiliriz -
print("Encoded values =", list(encoded_values))Kodlanmış değerler şu şekilde yazdırılır -
Encoded values = [1, 2, 0]Step 5 − Checking the performance by decoding a random set of numbers −
Bu adım, rastgele sayı kümesinin kodunu çözerek performansı kontrol etmek için kullanılabilir. Aşağıdaki Python kodu aynısını yapmak için yazılabilir -
# decoding a set of values
encoded_values = [3,0,4,1]
decoded_list = encoder.inverse_transform(encoded_values)
print("\nEncoded values =", encoded_values)Şimdi, Kodlanmış değerler aşağıdaki gibi yazdırılacaktır -
Encoded values = [3, 0, 4, 1]
print("\nDecoded labels =", list(decoded_list))Şimdi, kodu çözülen değerler aşağıdaki gibi yazdırılır -
Decoded labels = ['white', 'black', 'yellow', 'green']Etiketli v / s Etiketsiz Veriler
Etiketsiz veriler temel olarak, dünyadan kolayca elde edilebilen doğal veya insan yapımı nesne örneklerinden oluşur. Bunlara ses, video, fotoğraflar, haber makaleleri vb. Dahildir.
Öte yandan, etiketli veriler bir dizi etiketlenmemiş veriyi alır ve bu etiketlenmemiş verilerin her bir parçasını anlamlı olan bir etiket veya etiket veya sınıfla artırır. Örneğin, bir fotoğrafımız varsa, etiket fotoğrafın içeriğine göre yerleştirilebilir, yani bir erkek veya kız çocuğunun veya hayvanın fotoğrafı veya başka herhangi bir şey. Verilerin etiketlenmesi, belirli bir etiketlenmemiş veri parçası hakkında insan uzmanlığı veya yargı gerektirir.
Etiketlenmemiş verilerin bol olduğu ve kolayca elde edildiği birçok senaryo vardır, ancak etiketlenmiş veriler genellikle bir insan / uzmanın açıklama eklemesini gerektirir. Yarı denetimli öğrenme, daha iyi modeller oluşturmak için etiketli ve etiketlenmemiş verileri birleştirmeye çalışır.
Bu bölümde, denetimli öğrenme - sınıflandırma uygulamaya odaklanacağız.
Sınıflandırma tekniği veya modeli, gözlemlenen değerlerden bir sonuç çıkarmaya çalışır. Sınıflandırma probleminde, "Siyah" veya "beyaz" veya "Öğretme" ve "Öğretim Dışı" gibi kategorilere ayrılmış çıktılarımız var. Sınıflandırma modelini oluştururken, veri noktalarını ve ilgili etiketleri içeren eğitim veri setine ihtiyacımız var. Örneğin, resmin bir arabaya ait olup olmadığını kontrol etmek istiyorsak. Bunu kontrol etmek için, "araba" ve "arabasız" ile ilgili iki sınıfa sahip bir eğitim veri kümesi oluşturacağız. Daha sonra eğitim örneklerini kullanarak modeli eğitmemiz gerekiyor. Sınıflandırma modelleri esas olarak yüz tanıma, istenmeyen posta tanımlama vb. Alanlarda kullanılır.
Python'da Sınıflandırıcı Oluşturma Adımları
Python'da bir sınıflandırıcı oluşturmak için Python 3 ve makine öğrenimi için bir araç olan Scikit-learn'ü kullanacağız. Python'da bir sınıflandırıcı oluşturmak için şu adımları izleyin -
Adım 1 - Scikit-learn'ü içe aktarın
Bu, Python'da bir sınıflandırıcı oluşturmanın ilk adımı olacaktır. Bu adımda, Python'daki en iyi makine öğrenimi modüllerinden biri olan Scikit-learn adlı bir Python paketi kuracağız. Aşağıdaki komut paketi içe aktarmamıza yardımcı olacaktır -
Import SklearnAdım 2 - Scikit-learn'ün veri kümesini içe aktarın
Bu adımda, makine öğrenimi modelimiz için veri kümesiyle çalışmaya başlayabiliriz. Burada kullanacağızthe Meme Kanseri Wisconsin Teşhis Veritabanı. Veri seti, meme kanseri tümörleri hakkında çeşitli bilgilerin yanı sıramalignant veya benign. Veri kümesinin 569 tümörle ilgili 569 örneği veya verisi vardır ve tümörün yarıçapı, dokusu, pürüzsüzlüğü ve alanı gibi 30 özellik veya özellik hakkında bilgi içerir. Aşağıdaki komutun yardımıyla Scikit-learn'ün meme kanseri veri setini içe aktarabiliriz -
from sklearn.datasets import load_breast_cancerŞimdi, aşağıdaki komut veri kümesini yükleyecektir.
data = load_breast_cancer()Aşağıda, önemli sözlük tuşlarının bir listesi verilmiştir -
- Sınıflandırma etiketi adları (target_names)
- Gerçek etiketler (hedef)
- Öznitelik / özellik adları (özellik adları)
- Öznitelik (veri)
Şimdi, aşağıdaki komutun yardımıyla, her önemli bilgi kümesi için yeni değişkenler oluşturabilir ve verileri atayabiliriz. Başka bir deyişle, verileri aşağıdaki komutlarla düzenleyebiliriz -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']Şimdi, daha net hale getirmek için, sınıf etiketlerini, ilk veri örneğinin etiketini, özellik isimlerimizi ve özelliğin değerini aşağıdaki komutların yardımıyla yazdırabiliriz -
print(label_names)Yukarıdaki komut, sırasıyla kötü huylu ve iyi huylu sınıf adlarını yazdıracaktır. Aşağıdaki çıktı olarak gösterilmiştir -
['malignant' 'benign']Şimdi, aşağıdaki komut, 0 ve 1 ikili değerlerine eşleştirildiklerini gösterecektir. Burada 0, kötü huylu kanseri temsil eder ve 1, iyi huylu kanseri temsil eder. Aşağıdaki çıktıyı alacaksınız -
print(labels[0])
0Aşağıda verilen iki komut, özellik adlarını ve özellik değerlerini üretecektir.
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]Yukarıdaki çıktıdan, ilk veri örneğinin, yarıçapı 1.7990000e + 01 olan kötü huylu bir tümör olduğunu görebiliriz.
Adım 3 - Verileri kümeler halinde düzenleme
Bu adımda, verilerimizi bir eğitim seti ve bir test seti olmak üzere ikiye ayıracağız. Verileri bu kümelere ayırmak çok önemlidir çünkü modelimizi görünmeyen veriler üzerinde test etmemiz gerekir. Verileri kümelere ayırmak için sklearn'ın adı verilen bir işlevi vardır.train_test_split()işlevi. Aşağıdaki komutların yardımıyla verileri bu setlere ayırabiliriz -
from sklearn.model_selection import train_test_splitYukarıdaki komut, train_test_splitsklearn fonksiyonunu kullanın ve aşağıdaki komut verileri eğitim ve test verilerine böler. Aşağıda verilen örnekte, verilerin% 40'ını test etmek için kullanıyoruz ve kalan veriler modeli eğitmek için kullanılacaktır.
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)Adım 4 - Modeli oluşturma
Bu adımda modelimizi oluşturacağız. Modeli oluşturmak için Naïve Bayes algoritmasını kullanacağız. Modeli oluşturmak için aşağıdaki komutlar kullanılabilir -
from sklearn.naive_bayes import GaussianNBYukarıdaki komut GaussianNB modülünü içe aktaracaktır. Şimdi, aşağıdaki komut modeli başlatmanıza yardımcı olacaktır.
gnb = GaussianNB()Modeli gnb.fit () kullanarak verilere uydurarak eğiteceğiz.
model = gnb.fit(train, train_labels)Adım 5 - Modeli ve doğruluğunu değerlendirme
Bu adımda test verilerimiz üzerinde tahminler yaparak modeli değerlendireceğiz. O zaman doğruluğunu da öğreneceğiz. Tahmin yapmak için predikt () işlevini kullanacağız. Aşağıdaki komut bunu yapmanıza yardımcı olacaktır -
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]Yukarıdaki 0'lar ve 1'ler, tümör sınıfları için tahmin edilen değerlerdir - kötü huylu ve iyi huylu.
Şimdi, iki diziyi, yani test_labels ve predsmodelimizin doğruluğunu öğrenebiliriz. Kullanacağızaccuracy_score()doğruluğu belirlemek için işlev. Bunun için aşağıdaki komutu düşünün -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965Sonuç, NaïveBayes sınıflandırıcısının% 95,17 doğru olduğunu göstermektedir.
Bu şekilde, yukarıdaki adımların yardımı ile sınıflandırıcımızı Python'da oluşturabiliriz.
Python'da Yapı Sınıflandırıcı
Bu bölümde, Python'da bir sınıflandırıcı oluşturmayı öğreneceğiz.
Naïve Bayes Sınıflandırıcı
Naïve Bayes, Bayes teoremini kullanarak sınıflandırıcı oluşturmak için kullanılan bir sınıflandırma tekniğidir. Varsayım, yordayıcıların bağımsız olmasıdır. Basit bir deyişle, bir sınıftaki belirli bir özelliğin varlığının başka herhangi bir özelliğin varlığıyla ilgisi olmadığını varsayar. Naïve Bayes sınıflandırıcı oluşturmak için scikit learn adlı python kitaplığını kullanmamız gerekir. Adlı üç tür Naif Bayes modeli vardır.Gaussian, Multinomial and Bernoulli scikit altında öğrenme paketi.
Naïve Bayes makine öğrenimi sınıflandırıcı modeli oluşturmak için aşağıdakilere & eksi
Veri kümesi
Breast Cancer Wisconsin Diagnostic Database adlı veri setini kullanacağız . Veri seti, meme kanseri tümörleri hakkında çeşitli bilgilerin yanı sıramalignant veya benign. Veri kümesinin 569 tümörle ilgili 569 örneği veya verisi vardır ve tümörün yarıçapı, dokusu, pürüzsüzlüğü ve alanı gibi 30 özellik veya özellik hakkında bilgi içerir. Bu veri setini sklearn paketinden içe aktarabiliriz.
Naif Bayes Modeli
Naïve Bayes sınıflandırıcı oluşturmak için, Naif Bayes modeline ihtiyacımız var. Daha önce de belirtildiği gibi, adında üç tür Naif Bayes modeli vardır.Gaussian, Multinomial ve Bernoulliscikit altında öğrenme paketi. Burada, aşağıdaki örnekte Gaussian Naif Bayes modelini kullanacağız.
Yukarıdakileri kullanarak, bir tümörün kötü huylu veya iyi huylu olup olmadığını tahmin etmek için tümör bilgisini kullanmak üzere bir Naif Bayes makine öğrenimi modeli oluşturacağız.
Başlamak için sklearn modülünü kurmamız gerekiyor. Aşağıdaki komutun yardımı ile yapılabilir -
Import SklearnŞimdi, Breast Cancer Wisconsin Diagnostic Database adlı veri setini içe aktarmamız gerekiyor.
from sklearn.datasets import load_breast_cancerŞimdi, aşağıdaki komut veri kümesini yükleyecektir.
data = load_breast_cancer()Veriler aşağıdaki şekilde düzenlenebilir -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']Şimdi, daha net hale getirmek için, aşağıdaki komutların yardımıyla sınıf etiketlerini, ilk veri örneğinin etiketini, özellik isimlerimizi ve özelliğin değerini yazdırabiliriz -
print(label_names)Yukarıdaki komut, sırasıyla kötü huylu ve iyi huylu sınıf adlarını yazdıracaktır. Aşağıdaki çıktı olarak gösterilmiştir -
['malignant' 'benign']Şimdi, aşağıda verilen komut, 0 ve 1 ikili değerlerine eşleştirildiklerini gösterecektir. Burada 0, kötü huylu kanseri temsil eder ve 1, iyi huylu kanseri temsil eder. Aşağıdaki çıktı olarak gösterilmiştir -
print(labels[0])
0Aşağıdaki iki komut, unsur adlarını ve unsur değerlerini üretecektir.
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]Yukarıdaki çıktıdan, ilk veri örneğinin ana yarıçapı 1.7990000e + 01 olan kötü huylu bir tümör olduğunu görebiliriz.
Modelimizi görünmeyen veriler üzerinde test etmek için verilerimizi eğitim ve test verilerine bölmemiz gerekir. Aşağıdaki kod yardımı ile yapılabilir -
from sklearn.model_selection import train_test_splitYukarıdaki komut, train_test_splitsklearn fonksiyonunu kullanın ve aşağıdaki komut verileri eğitim ve test verilerine böler. Aşağıdaki örnekte, test için verilerin% 40'ını kullanıyoruz ve anımsatıcı veriler modeli eğitmek için kullanılacaktır.
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)Şimdi, modeli aşağıdaki komutlarla oluşturuyoruz -
from sklearn.naive_bayes import GaussianNBYukarıdaki komut, GaussianNBmodül. Şimdi, aşağıda verilen komutla modeli başlatmamız gerekiyor.
gnb = GaussianNB()Modeli kullanarak verilere uydurarak eğiteceğiz gnb.fit().
model = gnb.fit(train, train_labels)Şimdi, test verileri üzerinde tahmin yaparak modeli değerlendirin ve şu şekilde yapılabilir -
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]Yukarıdaki 0'lar ve 1'ler, tümör sınıfları için tahmin edilen değerlerdir, yani kötü huylu ve iyi huylu.
Şimdi, iki diziyi, yani test_labels ve predsmodelimizin doğruluğunu öğrenebiliriz. Kullanacağızaccuracy_score()doğruluğu belirlemek için işlev. Şu komutu düşünün -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965Sonuç, NaïveBayes sınıflandırıcısının% 95,17 oranında doğru olduğunu göstermektedir.
Bu, Naïve Bayse Gauss modeline dayalı makine öğrenimi sınıflandırıcısıydı.
Destek Vektör Makineleri (SVM)
Temel olarak, Destek vektör makinesi (SVM), hem regresyon hem de sınıflandırma için kullanılabilen denetimli bir makine öğrenme algoritmasıdır. SVM'nin ana kavramı, her bir veri öğesini n boyutlu uzayda bir nokta olarak çizmektir ve her özelliğin değeri belirli bir koordinatın değeridir. Burada n sahip olacağımız özellikler olacaktır. Aşağıda, SVM kavramını anlamak için basit bir grafik temsil verilmiştir -
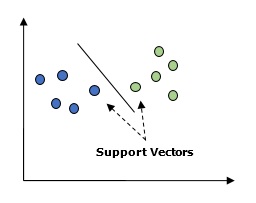
Yukarıdaki diyagramda iki özelliğimiz var. Bu nedenle, önce bu iki değişkeni, her noktanın destek vektörleri adı verilen iki koordinata sahip olduğu iki boyutlu uzayda çizmemiz gerekir. Çizgi, verileri iki farklı sınıflandırılmış gruba ayırır. Bu satır sınıflandırıcı olacaktır.
Burada, scikit-learn ve iris veri kümesini kullanarak bir SVM sınıflandırıcı oluşturacağız. Scikitlearn kütüphanesi,sklearn.svmmodül ve sınıflandırma için sklearn.svm.svc sağlar. 4 özelliğe dayalı olarak iris bitkisinin sınıfını tahmin etmek için SVM sınıflandırıcısı aşağıda gösterilmiştir.
Veri kümesi
Her biri 50 örnek içeren 3 sınıf içeren iris veri kümesini kullanacağız, burada her sınıf bir tür iris bitkisini ifade eder. Her örnek, ayrı uzunluk, ayrı genişlik, petal uzunluğu ve petal genişliği olmak üzere dört özelliğe sahiptir. 4 özelliğe dayalı olarak iris bitkisinin sınıfını tahmin etmek için SVM sınıflandırıcısı aşağıda gösterilmiştir.
Çekirdek
SVM tarafından kullanılan bir tekniktir. Temelde bunlar, düşük boyutlu girdi uzayını alıp daha yüksek boyutlu bir uzaya dönüştüren fonksiyonlardır. Ayrılmaz problemi ayrılabilir probleme dönüştürür. Çekirdek işlevi doğrusal, polinom, rbf ve sigmoid arasında herhangi biri olabilir. Bu örnekte doğrusal çekirdeği kullanacağız.
Şimdi aşağıdaki paketleri içe aktaralım -
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as pltŞimdi, giriş verilerini yükleyin -
iris = datasets.load_iris()İlk iki özelliği alıyoruz -
X = iris.data[:, :2]
y = iris.targetDestek vektör makinesi sınırlarını orijinal verilerle çizeceğiz. Çizmek için bir ağ oluşturuyoruz.
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]Düzenlileştirme parametresinin değerini vermemiz gerekiyor.
C = 1.0SVM sınıflandırıcı nesnesini oluşturmamız gerekiyor.
Svc_classifier = svm_classifier.SVC(kernel='linear',
C=C, decision_function_shape = 'ovr').fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
Lojistik regresyon
Temel olarak lojistik regresyon modeli, denetimli sınıflandırma algoritma ailesinin üyelerinden biridir. Lojistik regresyon, bir lojistik fonksiyon kullanarak olasılıkları tahmin ederek bağımlı değişkenler ile bağımsız değişkenler arasındaki ilişkiyi ölçer.
Burada bağımlı ve bağımsız değişkenlerden bahsedersek, bağımlı değişken tahmin edeceğimiz hedef sınıf değişkenidir ve diğer tarafta bağımsız değişkenler, hedef sınıfı tahmin etmek için kullanacağımız özelliklerdir.
Lojistik regresyonda, olasılıkları tahmin etmek, olayın gerçekleşme olasılığını tahmin etmek anlamına gelir. Örneğin, dükkan sahibi mağazaya giren müşterinin Playstation'ı satın alıp almayacağını (örneğin) tahmin etmek ister. Dükkan sahibi tarafından olasılığın tahmin edilmesi için gözlemlenebilecek, yani bir oyun istasyonu satın alıp almayacağına dair birçok müşteri özelliği - cinsiyet, yaş, vb. Lojistik fonksiyon, fonksiyonu çeşitli parametrelerle oluşturmak için kullanılan sigmoid eğridir.
Önkoşullar
Sınıflandırıcıyı lojistik regresyon kullanarak oluşturmadan önce, sistemimize Tkinter paketini kurmamız gerekiyor. Şuradan kurulabilirhttps://docs.python.org/2/library/tkinter.html.
Şimdi, aşağıda verilen kod yardımıyla, lojistik regresyon kullanarak bir sınıflandırıcı oluşturabiliriz -
İlk olarak, bazı paketleri içe aktaracağız -
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as pltŞimdi, yapılabilecek örnek verileri şu şekilde tanımlamamız gerekiyor -
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4],
[3.2, 0.9], [2.9, 1.9],[2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])Ardından, aşağıdaki gibi yapılabilen lojistik regresyon sınıflandırıcısını oluşturmamız gerekiyor -
Classifier_LR = linear_model.LogisticRegression(solver = 'liblinear', C = 75)Son olarak, ancak en az değil, bu sınıflandırıcıyı eğitmemiz gerekiyor -
Classifier_LR.fit(X, y)Şimdi çıktıyı nasıl görselleştirebiliriz? Logistic_visualize () adında bir işlev oluşturularak yapılabilir -
Def Logistic_visualize(Classifier_LR, X, y):
min_x, max_x = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
min_y, max_y = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0Yukarıdaki satırda, mesh gridde kullanılacak minimum ve maksimum değerleri X ve Y tanımladık. Ek olarak, örgü ızgarayı çizmek için adım boyutunu tanımlayacağız.
mesh_step_size = 0.02X ve Y değerlerinin örgü ızgarasını aşağıdaki gibi tanımlayalım -
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size),
np.arange(min_y, max_y, mesh_step_size))Aşağıdaki kodun yardımıyla, sınıflandırıcıyı kafes ızgarasında çalıştırabiliriz -
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = 'black',
linewidth=1, cmap = plt.cm.Paired)Aşağıdaki kod satırı, arsanın sınırlarını belirleyecektir
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(X[:, 0].min() - 1), int(X[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(X[:, 1].min() - 1), int(X[:, 1].max() + 1), 1.0)))
plt.show()Şimdi, kodu çalıştırdıktan sonra aşağıdaki çıktı olan lojistik regresyon sınıflandırıcısını alacağız -

Karar Ağacı Sınıflandırıcısı
Karar ağacı, temelde, her düğümün bir gözlem grubunu bazı özellik değişkenlerine göre böldüğü bir ikili ağaç akış şemasıdır.
Burada, erkek veya dişi tahmin etmek için bir Karar Ağacı sınıflandırıcısı oluşturuyoruz. 19 örnek içeren çok küçük bir veri seti alacağız. Bu örnekler iki özellikten oluşacaktır - "yükseklik" ve "saç uzunluğu".
Önkoşul
Aşağıdaki sınıflandırıcıyı oluşturmak için yüklememiz gerekiyor pydotplus ve graphviz. Temel olarak, graphviz nokta dosyalarını kullanarak grafik çizmek için bir araçtır vepydotplusGraphviz'in Dot dili için bir modüldür. Paket yöneticisi veya pip ile kurulabilir.
Şimdi, aşağıdaki Python kodunun yardımıyla karar ağacı sınıflandırıcısını oluşturabiliriz -
Başlangıç olarak, bazı önemli kitaplıkları aşağıdaki gibi içe aktaralım -
import pydotplus
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn import cross_validation
import collectionsŞimdi, veri setini aşağıdaki gibi sağlamamız gerekiyor -
X = [[165,19],[175,32],[136,35],[174,65],[141,28],[176,15],[131,32],
[166,6],[128,32],[179,10],[136,34],[186,2],[126,25],[176,28],[112,38],
[169,9],[171,36],[116,25],[196,25]]
Y = ['Man','Woman','Woman','Man','Woman','Man','Woman','Man','Woman',
'Man','Woman','Man','Woman','Woman','Woman','Man','Woman','Woman','Man']
data_feature_names = ['height','length of hair']
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split
(X, Y, test_size=0.40, random_state=5)Veri setini sağladıktan sonra, yapılabilecek modeli aşağıdaki gibi uydurmamız gerekiyor -
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,Y)Aşağıdaki Python kodunun yardımıyla tahmin yapılabilir -
prediction = clf.predict([[133,37]])
print(prediction)Karar ağacını aşağıdaki Python kodunun yardımıyla görselleştirebiliriz -
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names,
out_file = None,filled = True,rounded = True)
graph = pydotplus.graph_from_dot_data(dot_data)
colors = ('orange', 'yellow')
edges = collections.defaultdict(list)
for edge in graph.get_edge_list():
edges[edge.get_source()].append(int(edge.get_destination()))
for edge in edges: edges[edge].sort()
for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0]
dest.set_fillcolor(colors[i])
graph.write_png('Decisiontree16.png')Yukarıdaki kod için tahmini verecek [‘Woman’] ve aşağıdaki karar ağacını oluşturun -

Tahmindeki özelliklerin değerlerini test etmek için değiştirebiliriz.
Rastgele Orman Sınıflandırıcısı
Topluluk yöntemlerinin, makine öğrenimi modellerini daha güçlü bir makine öğrenimi modelinde birleştiren yöntemler olduğunu biliyoruz. Karar ağaçlarından oluşan Random Forest, bunlardan biridir. Tek bir karar ağacından daha iyidir çünkü öngörü güçlerini korurken, sonuçların ortalamasını alarak fazla uyumu azaltabilir. Burada, rasgele orman modelini scikit learn kanser veri setine uygulayacağız.
Gerekli paketleri içe aktarın -
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as npŞimdi, aşağıdaki & eksi olarak yapılabilecek veri setini sağlamamız gerekiyor
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)Veri setini sağladıktan sonra, yapılabilecek modeli aşağıdaki gibi uydurmamız gerekiyor -
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)Şimdi, eğitim ve test alt kümesinin doğruluğunu öğrenin: o zaman tahmin edicilerin sayısını artıracaksak, test alt kümesinin doğruluğu da artacaktır.
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train)))
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test)))Çıktı
Accuracy on the training subset:(:.3f) 1.0
Accuracy on the training subset:(:.3f) 0.965034965034965Şimdi, karar ağacı gibi, rasgele orman, feature_importanceözellik ağırlığının karar ağacından daha iyi bir görünümünü sağlayacak modül. Aşağıdaki gibi arsa ve görselleştirilebilir -
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()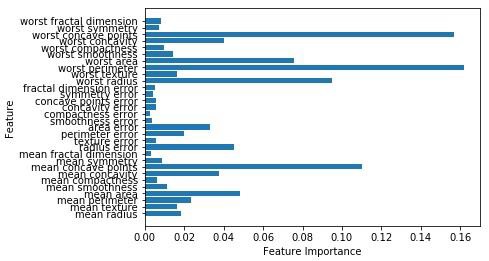
Bir sınıflandırıcının performansı
Bir makine öğrenimi algoritması uyguladıktan sonra, modelin ne kadar etkili olduğunu bulmamız gerekiyor. Etkinliğin ölçülmesine yönelik kriterler, veri kümelerine ve ölçüye dayalı olabilir. Farklı makine öğrenimi algoritmalarını değerlendirmek için farklı performans ölçütleri kullanabiliriz. Örneğin, farklı nesnelerin görüntülerini ayırt etmek için bir sınıflandırıcı kullanılıyorsa, ortalama doğruluk, AUC vb. Gibi sınıflandırma performansı ölçütlerini kullanabileceğimizi varsayalım. çok önemlidir çünkü ölçüm seçimi, bir makine öğrenimi algoritmasının performansının nasıl ölçüldüğünü ve karşılaştırıldığını etkiler. Aşağıda metriklerden bazıları verilmiştir -
Karışıklık Matrisi
Temel olarak, çıktının iki veya daha fazla sınıf türünden olabileceği sınıflandırma problemi için kullanılır. Bir sınıflandırıcının performansını ölçmenin en kolay yoludur. Karışıklık matrisi temelde "Gerçek" ve "Öngörülen" olmak üzere iki boyutlu bir tablodur. Her iki boyutta da “Gerçek Pozitifler (TP)”, “Gerçek Negatifler (TN)”, “Yanlış Pozitifler (FP)”, “Yanlış Negatifler (FN)” vardır.
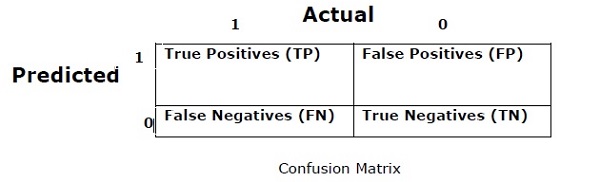
Yukarıdaki karışıklık matrisinde 1 pozitif sınıf ve 0 negatif sınıf içindir.
Karışıklık matrisi ile ilgili terimler aşağıdadır -
True Positives − TP'ler, gerçek veri noktası sınıfının 1 olduğu ve tahmin edilenin de 1 olduğu durumlardır.
True Negatives − TN'ler, veri noktasının gerçek sınıfının 0 ve tahmin edilenin de 0 olduğu durumlardır.
False Positives − FP'ler, gerçek veri noktası sınıfının 0 olduğu ve tahmin edilenin de 1 olduğu durumlardır.
False Negatives − FN'ler, veri noktasının gerçek sınıfının 1 olduğu ve tahmin edilenin de 0 olduğu durumlardır.
Doğruluk
Karışıklık matrisinin kendisi bir performans ölçüsü değildir, ancak neredeyse tüm performans matrisleri kafa karışıklığı matrisine dayanmaktadır. Bunlardan biri doğruluktur. Sınıflandırma problemlerinde, modelin yapılan her türlü tahmin üzerinden yaptığı doğru tahmin sayısı olarak tanımlanabilir. Doğruluğu hesaplamak için formül aşağıdaki gibidir -
$$ Doğruluk = \ frac {TP + TN} {TP + FP + FN + TN} $$
Hassas
Çoğunlukla belge erişiminde kullanılır. İade edilen belgelerin kaç tanesinin doğru olduğu şeklinde tanımlanabilir. Kesinliği hesaplamak için formül aşağıdadır -
$$ Precision = \ frac {TP} {TP + FP} $$
Hatırlama veya Hassasiyet
Modelin pozitiflerin kaçının geri döndüğü şeklinde tanımlanabilir. Modelin geri çağırma / hassasiyetini hesaplamak için formül aşağıdadır -
$$ Recall = \ frac {TP} {TP + FN} $$
Özgüllük
Modelin negatiflerin kaçını döndürdüğü şeklinde tanımlanabilir. Hatırlamanın tam tersi. Modelin özgüllüğünü hesaplamak için formül aşağıdadır -
$$ Özgüllük = \ frac {TN} {TN + FP} $$
Sınıf Dengesizliği Sorunu
Sınıf dengesizliği, bir sınıfa ait gözlem sayısının diğer sınıflara ait olanlardan önemli ölçüde düşük olduğu senaryodur. Örneğin nadir görülen hastalıkları, bankadaki dolandırıcılık işlemlerini vb. Tespit etmemiz gereken senaryoda bu sorun öne çıkıyor.
Dengesiz sınıf örnekleri
Dengesiz sınıf kavramını anlamak için bir dolandırıcılık tespit veri kümesi örneğini ele alalım -
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%Çözüm
Balancing the classes’dengesiz sınıflara bir çözüm görevi görür. Sınıfları dengelemenin temel amacı, ya azınlık sınıfının frekansını artırmak ya da çoğunluk sınıfının frekansını azaltmaktır. Dengesizlik sınıfları sorununu çözmek için yaklaşımlar şunlardır:
Yeniden Örnekleme
Yeniden örnekleme, örnek veri setlerini yeniden yapılandırmak için kullanılan bir dizi yöntemdir - hem eğitim setleri hem de test setleri. Modelin doğruluğunu artırmak için yeniden örnekleme yapılır. Aşağıda bazı yeniden örnekleme teknikleri verilmiştir -
Random Under-Sampling- Bu teknik, çoğunluk sınıf örneklerini rastgele eleyerek sınıf dağılımını dengelemeyi amaçlamaktadır. Bu, çoğunluk ve azınlık sınıfı örnekleri dengelenene kadar yapılır.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%Bu durumda, dolandırıcılık içermeyen örneklerden değiştirmeden% 10 numune alıyoruz ve ardından bunları dolandırıcılık örnekleriyle birleştiriyoruz -
Rastgele örneklemeden sonra hileli olmayan gözlemler = 4950'nin% 10'u = 495
Sahte gözlemlerle birleştirildikten sonraki toplam gözlemler = 50 + 495 = 545
Dolayısıyla şimdi, alt örneklemeden sonra yeni veri kümesi için olay oranı =% 9
Bu tekniğin temel avantajı, çalışma süresini azaltması ve depolamayı iyileştirmesidir. Ancak diğer yandan, eğitim verisi örneklerinin sayısını azaltırken faydalı bilgileri atabilir.
Random Over-Sampling - Bu teknik, azınlık sınıfındaki örneklerin sayısını çoğaltarak artırarak sınıf dağılımını dengelemeyi amaçlamaktadır.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%50 sahte gözlemi 30 kez tekrarlamamız durumunda, azınlık sınıfı gözlemlerini tekrarladıktan sonra hileli gözlemler 1500 olacaktır. Daha sonra, yüksek hızda örneklemeden sonra yeni verilerdeki toplam gözlemler 4950 + 1500 = 6450 olacaktır. Dolayısıyla, yeni veri seti için olay oranı 1500/6450 =% 23 olacaktır.
Bu yöntemin temel avantajı, yararlı bilgi kaybının olmamasıdır. Ancak öte yandan, azınlık sınıfı olaylarını taklit ettiği için aşırı uyma şansı artmıştır.
Topluluk Teknikleri
Bu metodoloji temel olarak, mevcut sınıflandırma algoritmalarını dengesiz veri setlerine uygun hale getirmek için değiştirmek için kullanılır. Bu yaklaşımda, orijinal verilerden birkaç iki aşamalı sınıflandırıcı oluşturuyor ve ardından tahminlerini topluyoruz. Rastgele orman sınıflandırıcı, topluluk tabanlı sınıflandırıcıya bir örnektir.

Regresyon, en önemli istatistiksel ve makine öğrenimi araçlarından biridir. Makine öğrenimi yolculuğunun gerilemeden başladığını söylemek yanlış olmaz. Veriye dayalı kararlar almamızı sağlayan veya başka bir deyişle girdi ve çıktı değişkenleri arasındaki ilişkiyi öğrenerek verilere dayalı tahminler yapmamızı sağlayan parametrik teknik olarak tanımlanabilir. Burada, girdi değişkenlerine bağlı çıktı değişkenleri, sürekli değerli gerçek sayılardır. Regresyonda, girdi ve çıktı değişkenleri arasındaki ilişki önemlidir ve girdi değişkeninin değişmesiyle çıktı değişkeninin değerinin nasıl değiştiğini anlamamıza yardımcı olur. Regresyon, fiyatların, ekonominin, varyasyonların vb. Tahminlerinde sıklıkla kullanılır.
Python'da Regresör Oluşturma
Bu bölümde, tek ve çok değişkenli regresörün nasıl oluşturulacağını öğreneceğiz.
Doğrusal Regresör / Tek Değişkenli Regresör
Birkaç gerekli paketi önemli hale getirelim -
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as pltŞimdi giriş verilerini sağlamamız gerekiyor ve verilerimizi linear.txt adlı dosyaya kaydettik.
input = 'D:/ProgramData/linear.txt'Bu verileri kullanarak yüklememiz gerekir. np.loadtxt işlevi.
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]Bir sonraki adım modeli eğitmek olacaktır. Eğitim ve test örnekleri verelim.
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]Şimdi, doğrusal bir regresör nesnesi oluşturmamız gerekiyor.
reg_linear = linear_model.LinearRegression()Nesneyi eğitim örnekleri ile eğitin.
reg_linear.fit(X_train, y_train)Tahminleri test verileri ile yapmamız gerekiyor.
y_test_pred = reg_linear.predict(X_test)Şimdi verileri çizin ve görselleştirin.
plt.scatter(X_test, y_test, color = 'red')
plt.plot(X_test, y_test_pred, color = 'black', linewidth = 2)
plt.xticks(())
plt.yticks(())
plt.show()Çıktı
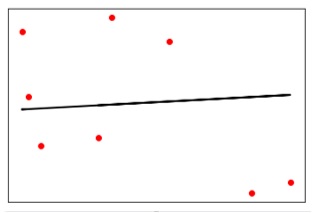
Şimdi, doğrusal regresyonumuzun performansını aşağıdaki gibi hesaplayabiliriz -
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred),
2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))Çıktı
Doğrusal Regresörün Performansı -
Mean absolute error = 1.78
Mean squared error = 3.89
Median absolute error = 2.01
Explain variance score = -0.09
R2 score = -0.09Yukarıdaki kodda bu küçük veriyi kullandık. Büyük bir veri kümesi istiyorsanız, daha büyük veri kümesini içe aktarmak için sklearn.dataset'i kullanabilirsiniz.
2,4.82.9,4.72.5,53.2,5.56,57.6,43.2,0.92.9,1.92.4,
3.50.5,3.41,40.9,5.91.2,2.583.2,5.65.1,1.54.5,
1.22.3,6.32.1,2.8Çok Değişkenli Regresör
Öncelikle, birkaç gerekli paketi içeri aktaralım -
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeaturesŞimdi giriş verilerini sağlamamız gerekiyor ve verilerimizi linear.txt adlı dosyaya kaydettik.
input = 'D:/ProgramData/Mul_linear.txt'Bu verileri kullanarak yükleyeceğiz np.loadtxt işlevi.
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]Bir sonraki adım modeli eğitmek olacaktır; eğitim ve test örnekleri vereceğiz.
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]Şimdi, doğrusal bir regresör nesnesi oluşturmamız gerekiyor.
reg_linear_mul = linear_model.LinearRegression()Nesneyi eğitim örnekleri ile eğitin.
reg_linear_mul.fit(X_train, y_train)Şimdi, sonunda test verileriyle tahmin yapmamız gerekiyor.
y_test_pred = reg_linear_mul.predict(X_test)
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))Çıktı
Doğrusal Regresörün Performansı -
Mean absolute error = 0.6
Mean squared error = 0.65
Median absolute error = 0.41
Explain variance score = 0.34
R2 score = 0.33Şimdi, 10 derecelik bir polinom oluşturup regresörü eğiteceğiz. Örnek veri noktasını sağlayacağız.
polynomial = PolynomialFeatures(degree = 10)
X_train_transformed = polynomial.fit_transform(X_train)
datapoint = [[2.23, 1.35, 1.12]]
poly_datapoint = polynomial.fit_transform(datapoint)
poly_linear_model = linear_model.LinearRegression()
poly_linear_model.fit(X_train_transformed, y_train)
print("\nLinear regression:\n", reg_linear_mul.predict(datapoint))
print("\nPolynomial regression:\n", poly_linear_model.predict(poly_datapoint))Çıktı
Doğrusal regresyon -
[2.40170462]Polinom regresyon -
[1.8697225]Yukarıdaki kodda bu küçük veriyi kullandık. Büyük bir veri kümesi istiyorsanız, daha büyük bir veri kümesini içe aktarmak için sklearn.dataset'i kullanabilirsiniz.
2,4.8,1.2,3.22.9,4.7,1.5,3.62.5,5,2.8,23.2,5.5,3.5,2.16,5,
2,3.27.6,4,1.2,3.23.2,0.9,2.3,1.42.9,1.9,2.3,1.22.4,3.5,
2.8,3.60.5,3.4,1.8,2.91,4,3,2.50.9,5.9,5.6,0.81.2,2.58,
3.45,1.233.2,5.6,2,3.25.1,1.5,1.2,1.34.5,1.2,4.1,2.32.3,
6.3,2.5,3.22.1,2.8,1.2,3.6Bu bölümde mantık programlamaya ve Yapay Zekaya nasıl yardımcı olduğuna odaklanacağız.
Zaten mantığın doğru akıl yürütme ilkelerinin incelenmesi olduğunu ya da basit bir deyişle, neyin ardından neyin geldiğinin incelenmesi olduğunu biliyoruz. Örneğin, iki ifade doğruysa, ondan herhangi bir üçüncü ifade çıkarabiliriz.
Konsept
Mantık Programlama, iki kelimenin, mantık ve programlamanın birleşimidir. Mantık Programlama, sorunların gerçekler ve kurallar olarak program ifadeleriyle ancak bir biçimsel mantık sistemi içinde ifade edildiği bir programlama paradigmasıdır. Tıpkı nesne yönelimli, işlevsel, bildirimsel ve prosedürel vb. Gibi diğer programlama paradigmaları gibi, programlamaya da yaklaşmanın özel bir yoludur.
Mantık Programlamayla Sorunları Çözme
Mantık Programlama, sorunu çözmek için gerçekleri ve kuralları kullanır. Bu nedenle, Mantık Programlamanın yapı taşları olarak adlandırılırlar. Mantık programlamada her program için bir hedef belirlenmelidir. Mantık programlamada bir problemin nasıl çözülebileceğini anlamak için yapı taşlarını bilmemiz gerekir - Gerçekler ve Kurallar -
Gerçekler
Aslında, her mantık programı, verilen hedefe ulaşabilmek için birlikte çalışmak için gerçeklere ihtiyaç duyar. Gerçekler temelde program ve veriler hakkında doğru ifadelerdir. Örneğin, Delhi Hindistan'ın başkentidir.
Kurallar
Aslında kurallar, sorun alanı hakkında sonuçlara varmamızı sağlayan kısıtlamalardır. Temelde çeşitli gerçekleri ifade etmek için mantıksal tümceler olarak yazılan kurallar. Örneğin, herhangi bir oyun geliştiriyorsak, tüm kurallar tanımlanmalıdır.
Mantık Programlamada herhangi bir sorunu çözmek için kurallar çok önemlidir. Kurallar, temelde gerçekleri ifade edebilen mantıksal sonuçlardır. Kuralın sözdizimi aşağıdadır -
A∶− B1, B2, ..., B n .
Burada, A kafadır ve B1, B2, ... Bn bedendir.
Örneğin - ata (X, Y): - baba (X, Y).
ata (X, Z): - baba (X, Y), ata (Y, Z).
Bu, her X ve Y için, X, Y'nin babası ve Y, Z'nin atası ise, X, Z'nin atasıdır. Her X ve Y için, X, Z'nin atasıdır, eğer X ise Y ve Y'nin babası, Z'nin atasıdır.
Yararlı Paketleri Kurmak
Python'da mantık programlamayı başlatmak için aşağıdaki iki paketi kurmamız gerekir -
Kanren
Bize iş mantığı için kod oluşturma yöntemimizi basitleştirmenin bir yolunu sunar. Mantığı kurallar ve gerçekler açısından ifade etmemizi sağlar. Aşağıdaki komut kanren'i kurmanıza yardımcı olacaktır -
pip install kanrenSymPy
SymPy, sembolik matematik için bir Python kütüphanesidir. Anlaşılabilir ve kolayca genişletilebilir olması için kodu olabildiğince basit tutarken tam özellikli bir bilgisayar cebir sistemi (CAS) olmayı amaçlamaktadır. Aşağıdaki komut SymPy'yi kurmanıza yardımcı olacaktır -
pip install sympyMantık Programlama Örnekleri
Aşağıda mantık programlama ile çözülebilecek bazı örnekler verilmiştir -
Matematiksel ifadeleri eşleştirme
Aslında bilinmeyen değerleri mantık programlamayı çok etkili bir şekilde kullanarak bulabiliriz. Aşağıdaki Python kodu, matematiksel bir ifadeyi eşleştirmenize yardımcı olacaktır -
Önce aşağıdaki paketleri içe aktarmayı düşünün -
from kanren import run, var, fact
from kanren.assoccomm import eq_assoccomm as eq
from kanren.assoccomm import commutative, associativeKullanacağımız matematiksel işlemleri tanımlamamız gerekiyor -
add = 'add'
mul = 'mul'Hem toplama hem de çarpma iletişimsel süreçlerdir. Dolayısıyla, bunu belirtmemiz gerekiyor ve bu şu şekilde yapılabilir -
fact(commutative, mul)
fact(commutative, add)
fact(associative, mul)
fact(associative, add)Değişkenleri tanımlamak zorunludur; bu şu şekilde yapılabilir -
a, b = var('a'), var('b')İfadeyi orijinal kalıpla eşleştirmemiz gerekiyor. Temelde (5 + a) * b - olan aşağıdaki orijinal kalıba sahibiz
Original_pattern = (mul, (add, 5, a), b)Orijinal kalıpla eşleştirmek için aşağıdaki iki ifadeye sahibiz -
exp1 = (mul, 2, (add, 3, 1))
exp2 = (add,5,(mul,8,1))Çıktı aşağıdaki komutla yazdırılabilir -
print(run(0, (a,b), eq(original_pattern, exp1)))
print(run(0, (a,b), eq(original_pattern, exp2)))Bu kodu çalıştırdıktan sonra aşağıdaki çıktıyı alacağız -
((3,2))
()İlk çıktı için değerleri temsil eder a ve b. İlk ifade, orijinal kalıpla eşleşti ve için değerleri döndürdüa ve b ancak ikinci ifade orijinal kalıpla eşleşmedi, dolayısıyla hiçbir şey döndürülmedi.
Asal Sayıların Kontrol Edilmesi
Mantıksal programlama yardımıyla, bir sayılar listesinden asal sayıları bulabilir ve ayrıca asal sayılar üretebiliriz. Aşağıda verilen Python kodu, bir sayı listesinden asal sayıyı bulacak ve ayrıca ilk 10 asal sayıyı üretecektir.
Önce aşağıdaki paketleri içe aktarmayı düşünelim -
from kanren import isvar, run, membero
from kanren.core import success, fail, goaleval, condeseq, eq, var
from sympy.ntheory.generate import prime, isprime
import itertools as itŞimdi, verilen sayılara göre asal sayıları veri olarak kontrol edecek olan prime_check adında bir işlev tanımlayacağız.
def prime_check(x):
if isvar(x):
return condeseq([(eq,x,p)] for p in map(prime, it.count(1)))
else:
return success if isprime(x) else failŞimdi, kullanılacak bir değişken tanımlamamız gerekiyor -
x = var()
print((set(run(0,x,(membero,x,(12,14,15,19,20,21,22,23,29,30,41,44,52,62,65,85)),
(prime_check,x)))))
print((run(10,x,prime_check(x))))Yukarıdaki kodun çıktısı aşağıdaki gibi olacaktır -
{19, 23, 29, 41}
(2, 3, 5, 7, 11, 13, 17, 19, 23, 29)Puzzle çözmek
Mantık programlama, 8-bulmaca, Zebra bulmacası, Sudoku, N-kraliçe vb. Gibi birçok sorunu çözmek için kullanılabilir. Burada Zebra bulmacasının bir çeşidinin bir örneğini alıyoruz, aşağıdaki gibi -
There are five houses.
The English man lives in the red house.
The Swede has a dog.
The Dane drinks tea.
The green house is immediately to the left of the white house.
They drink coffee in the green house.
The man who smokes Pall Mall has birds.
In the yellow house they smoke Dunhill.
In the middle house they drink milk.
The Norwegian lives in the first house.
The man who smokes Blend lives in the house next to the house with cats.
In a house next to the house where they have a horse, they smoke Dunhill.
The man who smokes Blue Master drinks beer.
The German smokes Prince.
The Norwegian lives next to the blue house.
They drink water in a house next to the house where they smoke Blend.Soru için çözüyoruz who owns zebra Python yardımıyla.
Gerekli paketleri ithal edelim -
from kanren import *
from kanren.core import lall
import timeŞimdi, iki işlevi tanımlamamız gerekiyor - left() ve next() kimin evinin kaldığını veya kimin evinin yanında olduğunu kontrol etmek için -
def left(q, p, list):
return membero((q,p), zip(list, list[1:]))
def next(q, p, list):
return conde([left(q, p, list)], [left(p, q, list)])Şimdi, aşağıdaki gibi bir değişken ev ilan edeceğiz -
houses = var()Kuralları lall paketi yardımıyla aşağıdaki gibi tanımlamamız gerekir.
5 ev var -
rules_zebraproblem = lall(
(eq, (var(), var(), var(), var(), var()), houses),
(membero,('Englishman', var(), var(), var(), 'red'), houses),
(membero,('Swede', var(), var(), 'dog', var()), houses),
(membero,('Dane', var(), 'tea', var(), var()), houses),
(left,(var(), var(), var(), var(), 'green'),
(var(), var(), var(), var(), 'white'), houses),
(membero,(var(), var(), 'coffee', var(), 'green'), houses),
(membero,(var(), 'Pall Mall', var(), 'birds', var()), houses),
(membero,(var(), 'Dunhill', var(), var(), 'yellow'), houses),
(eq,(var(), var(), (var(), var(), 'milk', var(), var()), var(), var()), houses),
(eq,(('Norwegian', var(), var(), var(), var()), var(), var(), var(), var()), houses),
(next,(var(), 'Blend', var(), var(), var()),
(var(), var(), var(), 'cats', var()), houses),
(next,(var(), 'Dunhill', var(), var(), var()),
(var(), var(), var(), 'horse', var()), houses),
(membero,(var(), 'Blue Master', 'beer', var(), var()), houses),
(membero,('German', 'Prince', var(), var(), var()), houses),
(next,('Norwegian', var(), var(), var(), var()),
(var(), var(), var(), var(), 'blue'), houses),
(next,(var(), 'Blend', var(), var(), var()),
(var(), var(), 'water', var(), var()), houses),
(membero,(var(), var(), var(), 'zebra', var()), houses)
)Şimdi, çözücüyü önceki kısıtlamalarla çalıştırın -
solutions = run(0, houses, rules_zebraproblem)Aşağıdaki kodun yardımıyla, çıktıyı çözücüden çıkarabiliriz -
output_zebra = [house for house in solutions[0] if 'zebra' in house][0][0]Aşağıdaki kod, çözümün yazdırılmasına yardımcı olacaktır -
print ('\n'+ output_zebra + 'owns zebra.')Yukarıdaki kodun çıktısı aşağıdaki gibi olacaktır -
German owns zebra.Denetimsiz makine öğrenimi algoritmalarında, herhangi bir tür rehberlik sağlayacak bir gözetmen bulunmamaktadır. Bazılarının gerçek yapay zeka dediği şeyle yakından bağlantılı olmasının nedeni budur.
Denetimsiz öğrenmede, rehberlik için doğru cevap ve öğretmen olmayacaktı. Algoritmaların öğrenme için verilerdeki ilginç modeli keşfetmesi gerekir.
Kümeleme nedir?
Temel olarak, bir tür denetimsiz öğrenme yöntemi ve birçok alanda kullanılan istatistiksel veri analizi için yaygın bir tekniktir. Kümeleme, temelde, gözlem kümesini kümeler adı verilen alt kümelere, aynı kümedeki gözlemler bir anlamda benzer olacak ve diğer kümelerdeki gözlemlerden farklı olacak şekilde bölme görevidir. Basit bir ifadeyle, kümelemenin temel amacının verileri benzerlik ve benzeşmezlik temelinde gruplamak olduğunu söyleyebiliriz.
Örneğin, aşağıdaki diyagram, farklı kümelerde benzer türde verileri göstermektedir -
Verileri Kümelemek İçin Algoritmalar
Aşağıda, verileri kümelemek için birkaç yaygın algoritma verilmiştir -
K-Means algoritması
K-ortalamalı kümeleme algoritması, verileri kümelemek için iyi bilinen algoritmalardan biridir. Küme sayısının zaten bilindiğini varsaymalıyız. Buna düz kümeleme de denir. Yinelemeli bir kümeleme algoritmasıdır. Bu algoritma için aşağıda verilen adımların izlenmesi gerekir -
Step 1 - İstenilen sayıda K alt grubu belirlememiz gerekiyor.
Step 2- Küme sayısını düzeltin ve her veri noktasını rastgele bir kümeye atayın. Ya da başka bir deyişle, verilerimizi küme sayısına göre sınıflandırmamız gerekiyor.
Bu adımda, küme centroidleri hesaplanmalıdır.
Bu yinelemeli bir algoritma olduğundan, global optimayı bulana kadar veya başka bir deyişle centroidler optimal konumlarına ulaşana kadar her yinelemede K centroidlerin konumlarını güncellememiz gerekir.
Aşağıdaki kod, Python'da K-ortalama kümeleme algoritmasının uygulanmasına yardımcı olacaktır. Scikit-learn modülünü kullanacağız.
Gerekli paketleri ithal edelim -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeansAşağıdaki kod satırı, kullanarak dört blob içeren iki boyutlu veri kümesinin oluşturulmasına yardımcı olacaktır. make_blob -den sklearn.dataset paketi.
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)Aşağıdaki kodu kullanarak veri setini görselleştirebiliriz -
plt.scatter(X[:, 0], X[:, 1], s = 50);
plt.show()
Burada, kmeans'ı kaç küme (n_küme) için gerekli parametresi ile KMeans algoritması olarak başlatıyoruz.
kmeans = KMeans(n_clusters = 4)K-ortalama modelini girdi verileriyle eğitmemiz gerekiyor.
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis')
centers = kmeans.cluster_centers_Aşağıda verilen kod, verilerimize dayanarak makinenin bulgularını ve bulunacak küme sayısına göre teçhizatı çizmemize ve görselleştirmemize yardımcı olacaktır.
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5);
plt.show()
Ortalama Kayma Algoritması
Denetimsiz öğrenmede kullanılan bir başka popüler ve güçlü kümeleme algoritmasıdır. Herhangi bir varsayımda bulunmaz, dolayısıyla parametrik olmayan bir algoritmadır. Aynı zamanda hiyerarşik kümeleme veya ortalama kayma kümeleme analizi olarak da adlandırılır. Bu algoritmanın temel adımları aşağıdakiler olacaktır -
Öncelikle, kendi kümelerine atanan veri noktaları ile başlamalıyız.
Şimdi, centroidleri hesaplar ve yeni centroidlerin konumunu günceller.
Bu işlemi tekrarlayarak, kümenin tepesine, yani daha yüksek yoğunluklu bölgeye yaklaşıyoruz.
Bu algoritma, ağırlık merkezlerinin artık hareket etmediği aşamada durur.
Aşağıdaki kodun yardımıyla Python'da Mean Shift kümeleme algoritması uyguluyoruz. Scikit-learn modülünü kullanacağız.
Gerekli paketleri ithal edelim -
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")Aşağıdaki kod, kullanarak dört blob içeren iki boyutlu veri kümesinin oluşturulmasına yardımcı olacaktır. make_blob -den sklearn.dataset paketi.
from sklearn.datasets.samples_generator import make_blobsVeri setini aşağıdaki kod ile görselleştirebiliriz
centers = [[2,2],[4,5],[3,10]]
X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1)
plt.scatter(X[:,0],X[:,1])
plt.show()
Şimdi, Ortalama Kayma küme modelini girdi verileriyle eğitmemiz gerekiyor.
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_Aşağıdaki kod, küme merkezlerini ve giriş verilerine göre beklenen küme sayısını yazdıracaktır -
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2Aşağıda verilen kod, verilerimize dayalı olarak makinenin bulgularını ve bulunacak küme sayısına göre teçhizatı çizmeye ve görselleştirmeye yardımcı olacaktır.
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10)
plt.show()
Kümeleme Performansını Ölçme
Gerçek dünya verileri doğal olarak farklı kümeler halinde düzenlenmemiştir. Bu nedenle görselleştirmek ve çıkarımlar yapmak kolay değildir. Bu nedenle, kümeleme performansını ve kalitesini ölçmemiz gerekiyor. Siluet analizi yardımı ile yapılabilir.
Siluet Analizi
Bu yöntem, kümeler arasındaki mesafeyi ölçerek kümelenme kalitesini kontrol etmek için kullanılabilir. Temel olarak, bir siluet puanı vererek küme sayısı gibi parametreleri değerlendirmenin bir yolunu sağlar. Bu puan, bir kümedeki her noktanın, komşu kümelerdeki noktalara ne kadar yakın olduğunu ölçen bir metriktir.
Siluet skorunun analizi
Skor [-1, 1] aralığına sahiptir. Bu puanın analizi aşağıdadır -
Score of +1 - +1 yakın puan, örneğin komşu kümeden uzakta olduğunu gösterir.
Score of 0 - Puan 0, numunenin iki komşu küme arasındaki karar sınırında veya buna çok yakın olduğunu gösterir.
Score of -1 - Negatif puan, numunelerin yanlış kümelere atandığını gösterir.
Siluet Puanının Hesaplanması
Bu bölümde siluet puanının nasıl hesaplanacağını öğreneceğiz.
Siluet puanı aşağıdaki formül kullanılarak hesaplanabilir -
$$ siluet puanı = \ frac {\ left (pq \ right)} {max \ left (p, q \ right)} $$
Burada, veri noktasının parçası olmadığı en yakın kümedeki noktalara olan ortalama uzaklıktır. Ve kendi kümesindeki tüm noktalara olan ortalama küme içi uzaklıktır.
En uygun küme sayısını bulmak için, kümeleme algoritmasını tekrar içe aktararak çalıştırmamız gerekir. metrics modülden sklearnpaketi. Aşağıdaki örnekte, optimum küme sayısını bulmak için K-ortalama kümeleme algoritmasını çalıştıracağız -
Gerekli paketleri gösterildiği gibi içe aktarın -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeansAşağıdaki kod yardımıyla, kullanarak dört blob içeren iki boyutlu veri setini oluşturacağız. make_blob -den sklearn.dataset paketi.
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0)Değişkenleri gösterildiği gibi başlatın -
scores = []
values = np.arange(2, 10)K-ortalama modelini tüm değerler aracılığıyla yinelememiz ve ayrıca onu girdi verileriyle eğitmemiz gerekir.
for num_clusters in values:
kmeans = KMeans(init = 'k-means++', n_clusters = num_clusters, n_init = 10)
kmeans.fit(X)Şimdi, Öklid mesafe metriğini kullanarak mevcut kümeleme modeli için siluet puanını tahmin edin -
score = metrics.silhouette_score(X, kmeans.labels_,
metric = 'euclidean', sample_size = len(X))Aşağıdaki kod satırı, küme sayısının yanı sıra Silhouette puanının görüntülenmesine yardımcı olacaktır.
print("\nNumber of clusters =", num_clusters)
print("Silhouette score =", score)
scores.append(score)Aşağıdaki çıktıyı alacaksınız -
Number of clusters = 9
Silhouette score = 0.340391138371
num_clusters = np.argmax(scores) + values[0]
print('\nOptimal number of clusters =', num_clusters)Şimdi, optimum küme sayısı için çıktı aşağıdaki gibi olacaktır -
Optimal number of clusters = 2En Yakın Komşuları Bulmak
Film tavsiye sistemi gibi tavsiye sistemleri kurmak istiyorsak, en yakın komşuları bulma konseptini anlamamız gerekir. Bunun nedeni, tavsiye sisteminin en yakın komşular kavramını kullanmasıdır.
concept of finding nearest neighborsVerilen veri setinden giriş noktasına en yakın noktayı bulma süreci olarak tanımlanabilir. Bu KNN) K-en yakın komşular) algoritmasının ana kullanımı, giriş veri noktasının çeşitli sınıflara olan yakınlığındaki bir veri noktasını sınıflandıran sınıflandırma sistemleri oluşturmaktır.
Aşağıda verilen Python kodu, belirli bir veri setinin K-en yakın komşularını bulmaya yardımcı olur -
Gerekli paketleri aşağıda gösterildiği gibi içe aktarın. Burada kullanıyoruzNearestNeighbors modülden sklearn paket
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import NearestNeighborsŞimdi giriş verilerini tanımlayalım -
A = np.array([[3.1, 2.3], [2.3, 4.2], [3.9, 3.5], [3.7, 6.4], [4.8, 1.9],
[8.3, 3.1], [5.2, 7.5], [4.8, 4.7], [3.5, 5.1], [4.4, 2.9],])Şimdi, en yakın komşuları tanımlamamız gerekiyor -
k = 3Ayrıca en yakın komşuların bulunabileceği test verilerini de vermemiz gerekiyor -
test_data = [3.3, 2.9]Aşağıdaki kod, tarafımızdan tanımlanan girdi verilerini görselleştirebilir ve çizebilir -
plt.figure()
plt.title('Input data')
plt.scatter(A[:,0], A[:,1], marker = 'o', s = 100, color = 'black')
Şimdi, K En Yakın Komşu'yu inşa etmemiz gerekiyor. Nesnenin de eğitilmesi gerekiyor
knn_model = NearestNeighbors(n_neighbors = k, algorithm = 'auto').fit(X)
distances, indices = knn_model.kneighbors([test_data])Şimdi, K en yakın komşuları aşağıdaki gibi yazdırabiliriz
print("\nK Nearest Neighbors:")
for rank, index in enumerate(indices[0][:k], start = 1):
print(str(rank) + " is", A[index])En yakın komşuları test veri noktasıyla birlikte görselleştirebiliriz
plt.figure()
plt.title('Nearest neighbors')
plt.scatter(A[:, 0], X[:, 1], marker = 'o', s = 100, color = 'k')
plt.scatter(A[indices][0][:][:, 0], A[indices][0][:][:, 1],
marker = 'o', s = 250, color = 'k', facecolors = 'none')
plt.scatter(test_data[0], test_data[1],
marker = 'x', s = 100, color = 'k')
plt.show()
Çıktı
K Nearest Neighbors
1 is [ 3.1 2.3]
2 is [ 3.9 3.5]
3 is [ 4.4 2.9]K-En Yakın Komşular Sınıflandırıcı
K-En Yakın Komşular (KNN) sınıflandırıcı, belirli bir veri noktasını sınıflandırmak için en yakın komşu algoritmasını kullanan bir sınıflandırma modelidir. Son bölümde KNN algoritmasını uyguladık, şimdi bu algoritmayı kullanarak bir KNN sınıflandırıcısı oluşturacağız.
KNN Sınıflandırıcı Kavramı
K-en yakın komşu sınıflandırmasının temel kavramı, önceden tanımlanmış bir sayı, yani sınıflandırılması gereken yeni bir numuneye en yakın eğitim numunelerinin 'k' - 'sini bulmaktır. Yeni örnekler etiketlerini komşularından alacak. KNN sınıflandırıcıları, belirlenmesi gereken komşuların sayısı için sabit bir kullanıcı tanımlı sabite sahiptir. Mesafe için, standart Öklid mesafesi en yaygın seçenektir. KNN Sınıflandırıcı, öğrenme kurallarını oluşturmak yerine doğrudan öğrenilen örnekler üzerinde çalışır. KNN algoritması, tüm makine öğrenimi algoritmalarının en basitleri arasındadır. Karakter tanıma veya görüntü analizi gibi çok sayıda sınıflandırma ve regresyon probleminde oldukça başarılı olmuştur.
Example
Rakamları tanımak için bir KNN sınıflandırıcı oluşturuyoruz. Bunun için MNIST veri setini kullanacağız. Bu kodu Jupyter Defterine yazacağız.
Gerekli paketleri aşağıda gösterildiği gibi içe aktarın.
Burada kullanıyoruz KNeighborsClassifier modülden sklearn.neighbors paket -
from sklearn.datasets import *
import pandas as pd
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as npAşağıdaki kod, hangi görüntüyü test etmemiz gerektiğini doğrulamak için rakamın görüntüsünü gösterecektir -
def Image_display(i):
plt.imshow(digit['images'][i],cmap = 'Greys_r')
plt.show()Şimdi MNIST veri setini yüklememiz gerekiyor. Aslında toplam 1797 görüntü var ancak ilk 1600 görüntüyü eğitim örneği olarak kullanıyoruz ve geri kalan 197 görüntü test amacıyla saklanacak.
digit = load_digits()
digit_d = pd.DataFrame(digit['data'][0:1600])Şimdi, görüntüleri görüntülerken çıktıyı aşağıdaki gibi görebiliriz -
Image_display(0)Resim_display (0)
0 görüntüsü aşağıdaki gibi görüntülenir -

Resim_display (9)
9 resmi aşağıdaki gibi gösterilir -

digit.keys ()
Şimdi, eğitim ve test veri setini oluşturmamız ve test veri setini KNN sınıflandırıcılarına sağlamamız gerekiyor.
train_x = digit['data'][:1600]
train_y = digit['target'][:1600]
KNN = KNeighborsClassifier(20)
KNN.fit(train_x,train_y)Aşağıdaki çıktı, K en yakın komşu sınıflandırıcı yapıcısını yaratacaktır -
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2,
weights = 'uniform')Eğitim örnekleri olan 1600'den büyük herhangi bir rastgele sayı sağlayarak test örneğini oluşturmamız gerekiyor.
test = np.array(digit['data'][1725])
test1 = test.reshape(1,-1)
Image_display(1725)Resim_display (6)
6 resmi aşağıdaki gibi gösterilir -

Şimdi test verilerini şu şekilde tahmin edeceğiz -
KNN.predict(test1)Yukarıdaki kod aşağıdaki çıktıyı üretecektir -
array([6])Şimdi şunları düşünün -
digit['target_names']Yukarıdaki kod aşağıdaki çıktıyı üretecektir -
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])Doğal Dil İşleme (NLP), İngilizce gibi doğal bir dil kullanarak akıllı sistemlerle iletişim kurmanın yapay zeka yöntemini ifade eder.
Robot gibi akıllı bir sistemin talimatlarınıza göre çalışmasını istediğinizde, diyalog tabanlı bir klinik uzman sisteminden karar almak istediğinizde, vb. Doğal Dilin işlenmesi gerekir.
NLP alanı, bilgisayarların, insanların kullandığı doğal dillerle yararlı görevler oluşturmasını içerir. Bir NLP sisteminin girişi ve çıkışı şunlar olabilir:
- Speech
- Yazılı metin
NLP Bileşenleri
Bu bölümde, NLP'nin farklı bileşenleri hakkında bilgi edineceğiz. NLP'nin iki bileşeni vardır. Bileşenler aşağıda açıklanmıştır -
Natural Language Understanding (NLU)
Aşağıdaki görevleri içerir -
Verilen girdiyi doğal dilde yararlı temsillerle eşleştirmek.
Dilin farklı yönlerini incelemek.
Doğal Dil Üretimi (NLG)
Bazı iç temsillerden doğal dil biçiminde anlamlı ifadeler ve cümleler üretme sürecidir. İçerir -
Text planning - Bu, ilgili içeriğin bilgi tabanından alınmasını içerir.
Sentence planning - Bu, gerekli kelimelerin seçilmesini, anlamlı ifadelerin oluşturulmasını, cümlenin tonunun ayarlanmasını içerir.
Text Realization - Bu, cümle planını cümle yapısına eşlemektir.
NLU'daki zorluklar
NLU, biçim ve yapı bakımından çok zengindir; ancak belirsizdir. Farklı belirsizlik düzeyleri olabilir -
Sözcüksel belirsizlik
Kelime düzeyi gibi çok ilkel bir düzeydedir. Örneğin, "tahta" kelimesini isim veya fiil olarak ele almak?
Sözdizimi düzeyinde belirsizlik
Bir cümle farklı şekillerde çözümlenebilir. Örneğin, "Kırmızı bere ile böceği kaldırdı". - Böceği kaldırmak için şapka mı kullandı yoksa kırmızı başlıklı bir böceği kaldırdı mı?
Referans belirsizliği
Zamir kullanan bir şeye atıfta bulunmak. Örneğin, Rima Gauri'ye gitti. "Yorgunum" dedi. - Tam olarak kim yorgun?
NLP Terminolojisi
Şimdi NLP terminolojisinde birkaç önemli terimi görelim.
Phonology - Sesi sistematik bir şekilde organize etme çalışmasıdır.
Morphology - İlkel anlamlı birimlerden kelimelerin inşası üzerine yapılan bir çalışmadır.
Morpheme - Bir dilde ilkel bir anlam birimidir.
Syntax- Cümle kurmak için kelimeleri düzenlemeyi ifade eder. Aynı zamanda kelimelerin cümle ve cümle içindeki yapısal rolünün belirlenmesini de içerir.
Semantics - Kelimelerin anlamı ve kelimelerin anlamlı kelime öbekleri ve cümlelere nasıl birleştirileceği ile ilgilenir.
Pragmatics - Farklı durumlarda cümleleri kullanmak ve anlamakla ve cümlenin yorumunun nasıl etkilendiğiyle ilgilenir.
Discourse - Hemen önceki cümlenin bir sonraki cümlenin yorumunu nasıl etkileyebileceğini ele alır.
World Knowledge - Dünya hakkında genel bilgileri içerir.
NLP'deki adımlar
Bu bölümde NLP'deki farklı adımlar gösterilmektedir.
Sözcüksel Analiz
Kelimelerin yapısını tanımlamayı ve analiz etmeyi içerir. Bir dilin sözlüğü, bir dildeki kelime ve cümlelerin toplanması anlamına gelir. Sözcük analizi, tüm txt parçasını paragraflara, cümlelere ve kelimelere bölmektir.
Sözdizimsel Analiz (Ayrıştırma)
Cümledeki kelimelerin gramer için analizini ve kelimeler arasındaki ilişkiyi gösterecek şekilde kelimelerin düzenlenmesini içerir. "Okul çocuğa gider" gibi cümle, İngilizce sözdizimsel analizcisi tarafından reddedilir.
Anlamsal Analiz
Metinden tam anlamı veya sözlük anlamını çıkarır. Metnin anlamlı olup olmadığı kontrol edilir. Görev alanındaki sözdizimsel yapıları ve nesneleri eşleyerek yapılır. Anlamsal analizci, “sıcak dondurma” gibi cümleyi dikkate almaz.
Söylem Entegrasyonu
Herhangi bir cümlenin anlamı, cümlenin hemen önündeki anlamına bağlıdır. Ayrıca hemen ardından gelen cümlenin anlamını da beraberinde getirir.
Pragmatik Analiz
Bu sırada söylenenler, gerçekte ne anlama geldiği üzerinden yeniden yorumlanır. Dilin gerçek dünya bilgisi gerektiren yönlerinin türetilmesini içerir.
Bu bölümde, Natural Language Toolkit Paketine nasıl başlayacağımızı öğreneceğiz.
Önkoşul
Natural Language işleme ile uygulamalar oluşturmak istiyorsak, bağlamdaki değişiklik bunu en zor hale getirir. Bağlam faktörü, makinenin belirli bir cümleyi nasıl anladığını etkiler. Bu nedenle, makine öğrenimi yaklaşımlarını kullanarak Doğal dil uygulamaları geliştirmemiz gerekiyor, böylece makine aynı zamanda bir insanın bağlamı anlayabileceği yolu anlayabilir.
Bu tür uygulamaları oluşturmak için NLTK (Natural Language Toolkit Paketi) adlı Python paketini kullanacağız.
NLTK içe aktarılıyor
Kullanmadan önce NLTK'yi kurmamız gerekiyor. Aşağıdaki komutun yardımıyla kurulabilir -
pip install nltkNLTK için bir conda paketi oluşturmak için aşağıdaki komutu kullanın -
conda install -c anaconda nltkŞimdi NLTK paketini kurduktan sonra, onu python komut istemi aracılığıyla içe aktarmamız gerekiyor. Python komut istemine aşağıdaki komutu yazarak içe aktarabiliriz -
>>> import nltkNLTK Verilerini İndirme
Şimdi NLTK'yi içe aktardıktan sonra, gerekli verileri indirmemiz gerekiyor. Python komut isteminde aşağıdaki komutun yardımı ile yapılabilir -
>>> nltk.download()Diğer Gerekli Paketleri Kurmak
NLTK kullanarak doğal dil işleme uygulamaları oluşturmak için gerekli paketleri kurmamız gerekiyor. Paketler aşağıdaki gibidir -
Gensim
Birçok uygulama için yararlı olan sağlam bir anlamsal modelleme kitaplığıdır. Aşağıdaki komutu çalıştırarak kurabiliriz -
pip install gensimDesen
Yapmak için kullanılır gensimpaket düzgün çalışıyor. Aşağıdaki komutu çalıştırarak kurabiliriz
pip install patternTokenizasyon, Kök Oluşturma ve Lemmatizasyon Kavramı
Bu bölümde, jetonlaştırmanın, kökleştirmenin ve lemmatizasyonun ne olduğunu anlayacağız.
Tokenizasyon
Verilen metni, yani karakter dizisini simge adı verilen daha küçük birimlere ayırma işlemi olarak tanımlanabilir. Simgeler sözcükler, sayılar veya noktalama işaretleri olabilir. Aynı zamanda kelime bölümleme olarak da adlandırılır. Aşağıda basit bir tokenleştirme örneği verilmiştir -
Input - Mango, muz, ananas ve elma meyvedir.
Output -

Verilen metni kırma işlemi, kelime sınırlarının bulunması yardımı ile yapılabilir. Bir kelimenin sonu ve yeni bir kelimenin başlangıcı kelime sınırları olarak adlandırılır. Yazı sistemi ve kelimelerin tipografik yapısı sınırları etkiler.
Python NLTK modülünde, metni gereksinimlerimize göre belirteçlere bölmek için kullanabileceğimiz belirteçleştirme ile ilgili farklı paketlerimiz var. Paketlerden bazıları aşağıdaki gibidir -
sent_tokenize paketi
Adından da anlaşılacağı gibi, bu paket giriş metnini cümlelere böler. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.tokenize import sent_tokenizeword_tokenize paketi
Bu paket, giriş metnini kelimelere böler. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.tokenize import word_tokenizeWordPunctTokenizer paketi
Bu paket, girdi metnini sözcüklere ve noktalama işaretlerine ayırır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.tokenize import WordPuncttokenizerStemming
Kelimelerle çalışırken gramatik nedenlerden dolayı pek çok varyasyonla karşılaşıyoruz. Buradaki varyasyon kavramı, aynı kelimelerin farklı biçimleriyle uğraşmamız gerektiği anlamına gelir.democracy, democratic, ve democratization. Makinelerin bu farklı kelimelerin aynı temel forma sahip olduğunu anlaması çok gereklidir. Bu şekilde, biz metni analiz ederken kelimelerin temel formlarını çıkarmak faydalı olacaktır.
Bunu kök oluşturarak başarabiliriz. Bu şekilde, kök bulmanın, kelimelerin uçlarını keserek kelimelerin temel formlarını çıkarmanın sezgisel süreci olduğunu söyleyebiliriz.
Python NLTK modülünde, kök oluşturmayla ilgili farklı paketlerimiz var. Bu paketler, kelimenin temel biçimlerini elde etmek için kullanılabilir. Bu paketler algoritmalar kullanır. Paketlerden bazıları aşağıdaki gibidir -
PorterStemmer paketi
Bu Python paketi, temel formu çıkarmak için Porter'ın algoritmasını kullanır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem.porter import PorterStemmerÖrneğin, kelimesini verirsek ‘writing’ Bu kökleştiricinin girdisi olarak onları alacağız ‘write’ köklenmeden sonra.
LancasterStemmer paketi
Bu Python paketi, temel formu çıkarmak için Lancaster'ın algoritmasını kullanacaktır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem.lancaster import LancasterStemmerÖrneğin, kelimesini verirsek ‘writing’ Bu kökleştiricinin girdisi olarak onları alacağız ‘write’ köklenmeden sonra.
SnowballStemmer paketi
Bu Python paketi, temel formu çıkarmak için kartopunun algoritmasını kullanacaktır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem.snowball import SnowballStemmerÖrneğin, kelimesini verirsek ‘writing’ Bu kökleştiricinin girdisi olarak onları alacağız ‘write’ köklenmeden sonra.
Bu algoritmaların tümü farklı düzeyde katılığa sahiptir. Bu üç gövdeyi karşılaştırırsak, o zaman Porter saplayıcılar en az katıdır ve Lancaster en katı olanıdır. Kartopu sapı, hız ve sertlik açısından kullanmak için iyidir.
Lemmatizasyon
Sözcüklerin temel biçimini de lemmatize ederek çıkarabiliriz. Temelde bu görevi, bir kelime dağarcığı ve kelimelerin morfolojik analizini kullanarak yapar, normalde yalnızca çekimsel sonları kaldırmayı amaçlamaktadır. Herhangi bir kelimenin bu tür temel biçimine lemma denir.
Kökten türetme ve lemmatizasyon arasındaki temel fark, kelime dağarcığı kullanımı ve kelimelerin morfolojik analizidir. Diğer bir fark, kök oluşturmanın en yaygın olarak türevsel olarak ilişkili kelimeleri daraltmasıdır, oysa lemmatizasyon genellikle yalnızca bir lemmanın farklı çekim biçimlerini daraltır. Örneğin, girdi sözcüğü olarak saw sözcüğünü sağlarsak, kök bulma 's' sözcüğünü döndürebilir, ancak lemmatization, simgenin kullanımının bir fiil mi yoksa bir isim mi olduğuna bağlı olarak gör ya da gördü sözcüğünü döndürmeye çalışır.
Python NLTK modülünde, kelimenin temel formlarını elde etmek için kullanabileceğimiz lemmatizasyon süreciyle ilgili aşağıdaki paketimiz var -
WordNetLemmatizer paketi
Bu Python paketi, bir isim veya fiil olarak kullanılmasına bağlı olarak kelimenin temel biçimini çıkaracaktır. Bu paketi aşağıdaki Python kodunun yardımıyla içe aktarabiliriz -
from nltk.stem import WordNetLemmatizerYığınlama: Verileri Parçalara Bölme
Doğal dil işlemede önemli süreçlerden biridir. Parçalama işleminin ana görevi, sözcük öbekleri gibi sözcük gruplarını ve kısa sözcük öbeklerini belirlemektir. Tokenleştirme sürecini, token oluşturma sürecini zaten inceledik. Parçalama, temelde bu belirteçlerin etiketlenmesidir. Başka bir deyişle, parçalama bize cümlenin yapısını gösterecektir.
Aşağıdaki bölümde, farklı Chunking türleri hakkında bilgi edineceğiz.
Yığın türleri
İki tür yığın vardır. Türler aşağıdaki gibidir -
Yığılma
Bu yığın oluşturma sürecinde nesne, şeyler vb. Daha genel olmaya doğru ilerler ve dil daha soyut hale gelir. Daha fazla anlaşma şansı var. Bu süreçte uzaklaşıyoruz. Örneğin, "arabalar ne amaçlıdır" sorusunu bir araya toplarsak? "Ulaşım" cevabını alabiliriz.
Parçalama
Bu yığın oluşturma sürecinde nesne, şeyler vb. Daha spesifik olmaya doğru ilerler ve dil daha fazla nüfuz eder. Daha derin yapı, yığın halinde incelenecektir. Bu süreçte yakınlaştırırız. Örneğin, "Özellikle bir arabadan bahsedin" sorusunu kısaltacak olursak? Araba hakkında daha küçük bilgiler alacağız.
Example
Bu örnekte, Python'da NLTK modülünü kullanarak cümledeki isim cümleleri parçalarını bulacak bir öbekleme kategorisi olan İsim-Cümlesi parçalama yapacağız -
Follow these steps in python for implementing noun phrase chunking −
Step 1- Bu adımda, yığın oluşturma için dilbilgisini tanımlamamız gerekiyor. Uymamız gereken kurallardan oluşacaktır.
Step 2- Bu adımda, bir yığın ayrıştırıcı oluşturmamız gerekiyor. Dilbilgisini ayrıştırır ve çıktıyı verir.
Step 3 - Bu son adımda çıktı bir ağaç formatında üretilir.
Gerekli NLTK paketini aşağıdaki gibi içe aktaralım -
import nltkŞimdi cümleyi tanımlamamız gerekiyor. Burada DT determinant anlamına gelir, VBP fiil anlamına gelir, JJ sıfat anlamına gelir, IN edat anlamına gelir ve NN isim anlamına gelir.
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Şimdi grameri vermemiz gerekiyor. Burada grameri düzenli ifade biçiminde vereceğiz.
grammar = "NP:{<DT>?<JJ>*<NN>}"Dilbilgisini ayrıştıracak bir ayrıştırıcı tanımlamamız gerekiyor.
parser_chunking = nltk.RegexpParser(grammar)Ayrıştırıcı cümleyi şu şekilde ayrıştırır -
parser_chunking.parse(sentence)Sonra, çıktıyı almamız gerekiyor. Çıktı, adı verilen basit değişkende oluşturuluroutput_chunk.
Output_chunk = parser_chunking.parse(sentence)Aşağıdaki kodun çalıştırılmasıyla çıktımızı ağaç şeklinde çizebiliriz.
output.draw()
Kelime Çantası (BoW) Modeli
Doğal dil işlemede bir model olan Kelime Çantası (BoW), temelde metnin özelliklerini çıkarmak için kullanılır, böylece metin makine öğrenimi algoritmalarında olacak şekilde modellemede kullanılabilir.
Şimdi soru, neden özellikleri metinden çıkarmamız gerektiği sorusu ortaya çıkıyor. Bunun nedeni, makine öğrenimi algoritmalarının ham verilerle çalışamaması ve ondan anlamlı bilgiler çıkarabilmeleri için sayısal verilere ihtiyaç duymalarıdır. Metin verilerinin sayısal verilere dönüştürülmesi, özellik çıkarma veya özellik kodlaması olarak adlandırılır.
Nasıl çalışır
Bu, özellikleri metinden çıkarmak için çok basit bir yaklaşımdır. Diyelim ki bir metin belgemiz var ve onu sayısal verilere dönüştürmek istediğimizi ya da özniteliklerini çıkarmak istediğimizi varsayalım, sonra ilk olarak bu model belgedeki tüm sözcüklerden bir kelime haznesi çıkarır. Daha sonra bir belge terim matrisi kullanarak bir model oluşturacaktır. Böylelikle BoW, belgeyi yalnızca bir kelime paketi olarak temsil eder. Belgedeki kelimelerin sırası veya yapısı hakkında herhangi bir bilgi atılır.
Belge terim matrisi kavramı
BoW algoritması, belge terimi matrisini kullanarak bir model oluşturur. Adından da anlaşılacağı gibi, belge terimi matrisi, belgede meydana gelen çeşitli sözcük sayılarının matrisidir. Bu matrisin yardımıyla, metin belgesi çeşitli kelimelerin ağırlıklı bir kombinasyonu olarak temsil edilebilir. Eşiği ayarlayarak ve daha anlamlı kelimeleri seçerek, bir özellik vektörü olarak kullanılabilecek belgelerdeki tüm kelimelerin histogramını oluşturabiliriz. Aşağıda, belge terimi matrisi kavramını anlamak için bir örnek verilmiştir -
Example
Aşağıdaki iki cümleye sahip olduğumuzu varsayalım -
Sentence 1 - Kelime Çantası modelini kullanıyoruz.
Sentence 2 - Özelliklerin çıkarılmasında Bag of Words modeli kullanılmıştır.
Şimdi, bu iki cümleyi ele aldığımızda şu 13 farklı kelimeye sahibiz:
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
Şimdi, her cümledeki kelime sayısını kullanarak her cümle için bir histogram oluşturmamız gerekiyor -
Sentence 1 - [1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 - [0,0,0,1,1,1,1,1,1,1,1,1,1]
Bu şekilde, çıkarılan öznitelik vektörlerine sahibiz. Her özellik vektörü 13 boyutludur çünkü 13 farklı kelimemiz vardır.
İstatistik Kavramı
İstatistik kavramı TermFrequency-Inverse Document Frequency (tf-idf) olarak adlandırılır. Belgedeki her kelime önemlidir. İstatistikler, her kelimenin önemini anlamamıza yardımcı olur.
Dönem Frekansı (tf)
Bir belgede her kelimenin ne sıklıkta göründüğünün ölçüsüdür. Her kelimenin sayısını belirli bir belgedeki toplam kelime sayısına bölerek elde edilebilir.
Ters Belge Frekansı (idf)
Verilen belge setinde bir kelimenin bu belge için ne kadar benzersiz olduğunun ölçüsüdür. İdf'yi hesaplamak ve ayırt edici bir özellik vektörü formüle etmek için, gibi yaygın olarak ortaya çıkan kelimelerin ağırlıklarını azaltmalı ve nadir kelimeleri tartmalıyız.
NLTK'da Kelime Çantası Modeli Oluşturma
Bu bölümde, bu cümlelerden vektörler oluşturmak için CountVectorizer kullanarak bir dizi dizesi tanımlayacağız.
Gerekli paketi ithal edelim -
from sklearn.feature_extraction.text import CountVectorizerŞimdi cümle kümesini tanımlayın.
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)Yukarıdaki program, çıktıyı aşağıda gösterildiği gibi üretir. Yukarıdaki iki cümlede 13 farklı kelimemiz olduğunu gösteriyor -
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}Bunlar, makine öğrenimi için kullanılabilecek özellik vektörleridir (metinden sayısal biçime).
Sorunları çözmek
Bu bölümde, ilgili birkaç sorunu çözeceğiz.
Kategori Tahmin
Bir dizi belgede, yalnızca sözcükler değil, sözcüklerin kategorisi de önemlidir; belirli bir kelimenin hangi metin kategorisine girdiği. Örneğin, belirli bir cümlenin e-posta, haber, spor, bilgisayar vb. Kategorisine ait olup olmadığını tahmin etmek istiyoruz. Aşağıdaki örnekte, belge kategorisini bulmak için bir özellik vektörü formüle etmek için tf-idf'yi kullanacağız. Sklearn'ın 20 haber grubu veri setindeki verileri kullanacağız.
Gerekli paketleri ithal etmemiz gerekiyor -
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerKategori haritasını tanımlayın. Din, Otomobiller, Spor, Elektronik ve Uzay adlı beş farklı kategori kullanıyoruz.
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}Eğitim setini oluşturun -
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)Bir sayı vektörleştiricisi oluşturun ve terim sayılarını çıkarın -
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)Tf-idf transformatörü aşağıdaki gibi oluşturulur -
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)Şimdi test verilerini tanımlayın -
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]Yukarıdaki veriler, Multinomial Naive Bayes sınıflandırıcısını eğitmemize yardımcı olacaktır -
classifier = MultinomialNB().fit(train_tfidf, training_data.target)Giriş verilerini sayım vektörleyicisini kullanarak dönüştürün -
input_tc = vectorizer_count.transform(input_data)Şimdi, vektörleştirilmiş verileri tfidf trafosunu kullanarak dönüştüreceğiz -
input_tfidf = tfidf.transform(input_tc)Çıktı kategorilerini tahmin edeceğiz -
predictions = classifier.predict(input_tfidf)Çıktı aşağıdaki gibi oluşturulur -
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])Kategori tahmincisi aşağıdaki çıktıyı üretir -
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: ElectronicsCinsiyet Bulucu
Bu problem ifadesinde, bir sınıflandırıcı, isimleri sağlayarak cinsiyeti (erkek veya kadın) bulmak için eğitilecektir. Bir özellik vektörü oluşturmak ve sınıflandırıcıyı eğitmek için buluşsal yöntem kullanmalıyız. Scikit-learn paketindeki etiketli verileri kullanacağız. Cinsiyet bulucu oluşturmak için Python kodu aşağıdadır -
Gerekli paketleri ithal edelim -
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import namesŞimdi giriş kelimesinden son N harfi çıkarmamız gerekiyor. Bu harfler özellik olarak hareket edecek -
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':NLTK'da bulunan etiketli isimleri (erkek ve kadın) kullanarak eğitim verilerini oluşturun -
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)Şimdi, test verileri aşağıdaki gibi oluşturulacaktır -
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']Aşağıdaki kodla eğitim ve test için kullanılan örnek sayısını tanımlayın
train_sample = int(0.8 * len(data))Şimdi, doğruluğun karşılaştırılabilmesi için farklı uzunluklarda yinelememiz gerekiyor -
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)Sınıflandırıcının doğruluğu şu şekilde hesaplanabilir -
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')Şimdi, çıktıyı tahmin edebiliriz -
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))Yukarıdaki program aşağıdaki çıktıyı üretecektir -
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> femaleYukarıdaki çıktıda maksimum son harf sayısındaki doğruluğun iki olduğunu ve son harf sayısı arttıkça azaldığını görebiliriz.
Konu Modelleme: Metin Verilerindeki Modelleri Tanımlama
Genel olarak belgelerin konulara göre gruplandırıldığını biliyoruz. Bazen bir metindeki belirli bir konuya karşılık gelen kalıpları belirlememiz gerekir. Bunu yapma tekniğine konu modelleme denir. Başka bir deyişle, konu modellemenin verilen belge setindeki soyut temaları veya gizli yapıyı ortaya çıkarmak için bir teknik olduğunu söyleyebiliriz.
Konu modelleme tekniğini aşağıdaki senaryolarda kullanabiliriz -
Metin Sınıflandırması
Konu modelleme yardımıyla, her bir kelimeyi ayrı ayrı bir özellik olarak kullanmak yerine benzer kelimeleri bir arada gruplandırdığı için sınıflandırma geliştirilebilir.
Öneri Sistemleri
Konu modelleme yardımıyla, benzerlik ölçülerini kullanarak tavsiye sistemlerini oluşturabiliriz.
Konu Modelleme Algoritmaları
Konu modelleme, algoritmalar kullanılarak gerçekleştirilebilir. Algoritmalar aşağıdaki gibidir -
Gizli Dirichlet Tahsisi (LDA)
Bu algoritma, konu modelleme için en popüler olanıdır. Konu modellemesini uygulamak için olasılıklı grafik modelleri kullanır. LDA slgorithm'i kullanmak için Python'da gensim paketini içe aktarmamız gerekiyor.
Gizli Anlamsal Analiz (LDA) veya Gizli Anlamsal İndeksleme (LSI)
Bu algoritma, Doğrusal Cebire dayanmaktadır. Temel olarak, belge terimi matrisinde SVD (Tekil Değer Ayrışımı) kavramını kullanır.
Negatif Olmayan Matris Ayrıştırması (NMF)
Aynı zamanda Doğrusal Cebire dayanmaktadır.
Konu modelleme için yukarıda bahsedilen algoritmaların tümü, number of topics parametre olarak, Document-Word Matrix girdi olarak ve WTM (Word Topic Matrix) & TDM (Topic Document Matrix) çıktı olarak.
Belirli bir girdi dizisinde bir sonrakini tahmin etmek, makine öğreniminde başka bir önemli kavramdır. Bu bölüm size zaman serisi verilerini analiz etme hakkında ayrıntılı bir açıklama sunar.
Giriş
Zaman serisi verileri, bir dizi belirli zaman aralığında bulunan veriler anlamına gelir. Makine öğreniminde sıra tahmini oluşturmak istiyorsak, sıralı veriler ve zamanla uğraşmalıyız. Seri verileri, sıralı verilerin bir özetidir. Verilerin sıralanması, sıralı verilerin önemli bir özelliğidir.
Sıra Analizi veya Zaman Serisi Analizi Temel Kavramı
Sıra analizi veya zaman serisi analizi, önceden gözlemlenene dayalı olarak belirli bir girdi dizisindeki bir sonrakini tahmin etmektir. Tahmin, daha sonra olabilecek herhangi bir şey olabilir: bir sembol, bir sayı, ertesi gün hava durumu, konuşmada sonraki terim vb. Sıra analizi, borsa analizi, hava durumu tahmini ve ürün önerileri gibi uygulamalarda çok kullanışlı olabilir.
Example
Sıra tahminini anlamak için aşağıdaki örneği düşünün. BurayaA,B,C,D verilen değerlerdir ve değeri tahmin etmelisiniz E Sıralı Tahmin Modeli kullanarak.

Yararlı Paketleri Kurmak
Python kullanarak zaman serisi veri analizi için aşağıdaki paketleri yüklememiz gerekir -
Pandalar
Pandas, Python için yüksek performans, veri yapısı kullanım kolaylığı ve veri analizi araçları sağlayan açık kaynak BSD lisanslı bir kitaplıktır. Pandaları aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install pandasAnaconda kullanıyorsanız ve bunu kullanarak kurmak istiyorsanız conda paket yöneticisi, ardından aşağıdaki komutu kullanabilirsiniz -
conda install -c anaconda pandashmmöğrenmek
Python'da Gizli Markov Modellerini (HMM) öğrenmek için basit algoritmalar ve modellerden oluşan açık kaynaklı bir BSD lisanslı kütüphanedir. Aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install hmmlearnAnaconda kullanıyorsanız ve bunu kullanarak kurmak istiyorsanız conda paket yöneticisi, ardından aşağıdaki komutu kullanabilirsiniz -
conda install -c omnia hmmlearnPyStruct
Yapılandırılmış bir öğrenme ve tahmin kitaplığıdır. PyStruct'ta uygulanan öğrenme algoritmaları, koşullu rastgele alanlar (CRF), Maximum-Margin Markov Random Networks (M3N) veya yapısal destek vektör makineleri gibi adlara sahiptir. Aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install pystructCVXOPT
Python programlama diline dayalı dışbükey optimizasyon için kullanılır. Aynı zamanda ücretsiz bir yazılım paketidir. Aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install cvxoptAnaconda kullanıyorsanız ve bunu kullanarak kurmak istiyorsanız conda paket yöneticisi, ardından aşağıdaki komutu kullanabilirsiniz -
conda install -c anaconda cvdoxtPandalar: Zaman Serisi Verilerinden İstatistikleri İşleme, Dilimleme ve Çıkarma
Zaman serisi verileriyle çalışmanız gerekiyorsa, Pandalar çok kullanışlı bir araçtır. Pandaların yardımıyla aşağıdakileri gerçekleştirebilirsiniz -
Kullanarak bir tarih aralığı oluşturun pd.date_range paket
Pandaları tarihlerle dizine eklemek için pd.Series paket
Yeniden örnekleme yapmak için ts.resample paket
Frekansı değiştir
Misal
Aşağıdaki örnek, Pandalar'ı kullanarak zaman serisi verilerini işlemenizi ve dilimlediğinizi gösterir. Burada, month.ao.index.b50.current.ascii adresinden indirilebilen ve kullanımımız için metin biçimine dönüştürülebilen Aylık Arktik Salınım verilerini kullandığımızı unutmayın.
Zaman serisi verilerini işleme
Zaman serisi verilerinin işlenmesi için aşağıdaki adımları gerçekleştirmeniz gerekecektir -
İlk adım, aşağıdaki paketleri içe aktarmayı içerir -
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdArdından, aşağıda verilen kodda gösterildiği gibi giriş dosyasından verileri okuyacak bir işlev tanımlayın -
def read_data(input_file):
input_data = np.loadtxt(input_file, delimiter = None)Şimdi bu verileri zaman serisine dönüştürün. Bunun için zaman serimizin tarih aralığını oluşturun. Bu örnekte, veri sıklığı olarak bir ayı tutuyoruz. Dosyamızda Ocak 1950'den başlayan veriler var.
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')Bu adımda Pandas Series yardımı ile aşağıda gösterildiği gibi zaman serisi verilerini oluşturuyoruz -
output = pd.Series(input_data[:, index], index = dates)
return output
if __name__=='__main__':Giriş dosyasının yolunu burada gösterildiği gibi girin -
input_file = "/Users/admin/AO.txt"Şimdi, sütunu burada gösterildiği gibi zaman serisi biçimine dönüştürün -
timeseries = read_data(input_file)Son olarak, gösterilen komutları kullanarak verileri çizin ve görselleştirin -
plt.figure()
timeseries.plot()
plt.show()Aşağıdaki resimlerde gösterildiği gibi grafikleri gözlemleyeceksiniz -


Zaman serisi verilerini dilimleme
Dilimleme, zaman serisi verilerinin yalnızca bir kısmını almayı içerir. Örneğin bir parçası olarak, verileri yalnızca 1980'den 1990'a dilimlere ayırıyoruz. Bu görevi yerine getiren aşağıdaki kodu inceleyin -
timeseries['1980':'1990'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00>
plt.show()Zaman serisi verilerini dilimlemek için kodu çalıştırdığınızda, aşağıdaki grafiği buradaki resimde gösterildiği gibi gözlemleyebilirsiniz -

Zaman Serisi Verilerinden İstatistik Çıkarma
Bazı önemli sonuçlara varmanız gereken durumlarda, belirli bir veriden bazı istatistikler çıkarmanız gerekecektir. Ortalama, varyans, korelasyon, maksimum değer ve minimum değer bu tür istatistiklerden bazılarıdır. Bu tür istatistikleri belirli bir zaman serisi verilerinden çıkarmak isterseniz aşağıdaki kodu kullanabilirsiniz -
Anlamına gelmek
Kullanabilirsiniz mean() burada gösterildiği gibi ortalamayı bulmak için fonksiyon -
timeseries.mean()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
-0.11143128165238671Maksimum
Kullanabilirsiniz max() burada gösterildiği gibi maksimum bulmak için fonksiyon -
timeseries.max()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
3.4952999999999999Minimum
Burada gösterildiği gibi minimum bulmak için min () işlevini kullanabilirsiniz -
timeseries.min()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
-4.2656999999999998Her şeyi aynı anda almak
Bir seferde tüm istatistikleri hesaplamak istiyorsanız, describe() burada gösterildiği gibi işlev -
timeseries.describe()O zaman tartışılan örnek için gözlemleyeceğiniz çıktı:
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64Yeniden örnekleme
Verileri farklı bir zaman frekansına yeniden örnekleyebilirsiniz. Yeniden örnekleme yapmak için iki parametre şunlardır:
- Zaman dilimi
- Method
Ortalama ile yeniden örnekleme ()
Verileri, varsayılan yöntem olan mean () yöntemiyle yeniden örneklemek için aşağıdaki kodu kullanabilirsiniz -
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()Ardından, mean () kullanarak yeniden örneklemenin çıktısı olarak aşağıdaki grafiği gözlemleyebilirsiniz -

Ortanca () ile yeniden örnekleme
Aşağıdaki kodu kullanarak verileri yeniden örneklemek için kullanabilirsiniz. median()yöntem -
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()Ardından, median () ile yeniden örneklemenin çıktısı olarak aşağıdaki grafiği gözlemleyebilirsiniz -

Rolling Mean
Dönen (hareketli) ortalamayı hesaplamak için aşağıdaki kodu kullanabilirsiniz -
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()Ardından, yuvarlanan (hareketli) ortalamanın çıktısı olarak aşağıdaki grafiği gözlemleyebilirsiniz -
Sıralı Verilerin Gizli Markov Modeli (HMM) ile Analizi
HMM, zaman serisi hisse senedi piyasa analizi, sağlık kontrolü ve konuşma tanıma gibi devamlılığı ve genişletilebilirliği olan veriler için yaygın olarak kullanılan bir istatistik modelidir. Bu bölüm, sıralı verileri Gizli Markov Modeli (HMM) kullanarak analiz etme ile ayrıntılı olarak ilgilenir.
Gizli Markov Modeli (HMM)
HMM, gelecekteki istatistiklerin olasılığının kendisinden önceki herhangi bir duruma değil, yalnızca mevcut işlem durumuna bağlı olduğu varsayımına dayanan Markov zinciri kavramı üzerine inşa edilmiş stokastik bir modeldir. Örneğin yazı tura atarken, beşinci atışın sonucunun bir kafa olacağını söyleyemeyiz. Bunun nedeni, madeni paranın hafızası olmaması ve sonraki sonucun önceki sonuca bağlı olmamasıdır.
HMM matematiksel olarak aşağıdaki değişkenlerden oluşur -
Eyaletler (S)
Bir HMM'de bulunan bir dizi gizli veya gizli durumdur. S ile gösterilir.
Çıkış sembolleri (O)
Bir HMM'de bulunan bir dizi olası çıktı sembolüdür. O ile gösterilir.
Durum Geçiş Olasılık Matrisi (A)
Bir durumdan diğer durumların her birine geçiş yapma olasılığıdır. A. ile gösterilir.
Gözlem Emisyon Olasılık Matrisi (B)
Belirli bir durumda bir sembolü yayma / gözlemleme olasılığıdır. B ile gösterilir.
Önceki Olasılık Matrisi (Π)
Sistemin çeşitli durumlarından belirli bir durumda başlama olasılığıdır. Π ile gösterilir.
Dolayısıyla, bir HMM şu şekilde tanımlanabilir: = (S,O,A,B,),
nerede,
- S = {s1,s2,…,sN} N olası durum kümesidir,
- O = {o1,o2,…,oM} M olası gözlem sembolleri kümesidir,
- A bir NN durum Geçiş Olasılık Matrisi (TPM),
- B bir NM gözlem veya Emisyon Olasılık Matrisi (EPM),
- π, N boyutlu bir ilk durum olasılık dağılım vektörüdür.
Örnek: Borsa verilerinin analizi
Bu örnekte, HMM'nin sıralı veya zaman serisi verileriyle nasıl çalıştığı hakkında bir fikir edinmek için borsa verilerini adım adım analiz edeceğiz. Lütfen bu örneği Python'da uyguladığımızı unutmayın.
Gerekli paketleri aşağıda gösterildiği gibi içe aktarın -
import datetime
import warningsŞimdi, borsa verilerini kullanın. matpotlib.finance paket, burada gösterildiği gibi -
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMMVerileri bir başlangıç tarihi ve bitiş tarihinden, yani burada gösterildiği gibi iki belirli tarih arasında yükleyin -
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)Bu adımda, her gün kapanış tekliflerini çıkaracağız. Bunun için aşağıdaki komutu kullanın -
closing_quotes = np.array([quote[2] for quote in quotes])Şimdi, her gün işlem gören hisse hacmini çıkaracağız. Bunun için aşağıdaki komutu kullanın -
volumes = np.array([quote[5] for quote in quotes])[1:]Burada, aşağıda gösterilen kodu kullanarak kapanış hisse senedi fiyatlarının yüzde farkını alın -
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])Bu adımda, Gauss HMM'yi oluşturun ve eğitin. Bunun için aşağıdaki kodu kullanın -
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)Şimdi, gösterilen komutları kullanarak HMM modelini kullanarak veri oluşturun -
num_samples = 300
samples, _ = hmm.sample(num_samples)Son olarak, bu adımda, çıktı olarak işlem gören hisse senetlerinin fark yüzdesini ve hacmini grafik biçiminde çizip görselleştiriyoruz.
Fark yüzdelerini çizmek ve görselleştirmek için aşağıdaki kodu kullanın -
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')İşlem gören hisselerin hacmini çizmek ve görselleştirmek için aşağıdaki kodu kullanın -
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()Bu bölümde, Python ile AI kullanarak konuşma tanımayı öğreneceğiz.
Konuşma, yetişkin insan iletişiminin en temel yoludur. Konuşma işlemenin temel amacı, bir insan ve bir makine arasında bir etkileşim sağlamaktır.
Konuşma işleme sisteminin başlıca üç görevi vardır -
First, makinenin konuştuğumuz kelimeleri, cümleleri ve cümleleri yakalamasını sağlayan konuşma tanıma
Second, makinenin ne konuştuğumuzu anlamasını sağlamak için doğal dil işleme ve
Thirdmakinenin konuşmasını sağlamak için konuşma sentezi.
Bu bölüm, speech recognitioninsanoğlunun söylediği kelimeleri anlama süreci. Konuşma sinyallerinin bir mikrofon yardımıyla yakalandığını ve daha sonra sistem tarafından anlaşılması gerektiğini unutmayın.
Konuşma Tanıyıcı Oluşturma
Konuşma Tanıma veya Otomatik Konuşma Tanıma (ASR), robotik gibi yapay zeka projelerinin ilgi odağıdır. ASR olmadan, bir insanla etkileşime giren bir bilişsel robot hayal etmek mümkün değildir. Bununla birlikte, bir konuşma tanıyıcı oluşturmak pek de kolay değildir.
Bir konuşma tanıma sistemi geliştirmedeki zorluklar
Yüksek kaliteli bir konuşma tanıma sistemi geliştirmek gerçekten zor bir sorundur. Konuşma tanıma teknolojisinin zorluğu, aşağıda tartışıldığı gibi bir dizi boyutta geniş bir şekilde karakterize edilebilir -
Size of the vocabulary- Sözcük dağarcığının boyutu, ASR geliştirme kolaylığını etkiler. Daha iyi anlamak için aşağıdaki kelime dağarcığını düşünün.
Küçük boyutlu bir kelime dağarcığı, örneğin bir sesli menü sisteminde olduğu gibi 2-100 kelimeden oluşur.
Orta büyüklükte bir kelime dağarcığı, örneğin bir veritabanı alma görevinde olduğu gibi, birkaç 100 ila 1000 kelimeden oluşur.
Büyük boyutlu bir kelime dağarcığı, genel bir dikte görevinde olduğu gibi, birkaç 10.000 kelimeden oluşur.
Channel characteristics- Kanal kalitesi de önemli bir boyuttur. Örneğin, insan konuşması tam frekans aralığı ile yüksek bant genişliği içerirken, bir telefon konuşması sınırlı frekans aralığı ile düşük bant genişliğinden oluşur. İkincisinin daha zor olduğuna dikkat edin.
Speaking mode- Bir ASR geliştirme kolaylığı aynı zamanda konuşma moduna, yani konuşmanın izole kelime modunda mı yoksa bağlantılı kelime modunda mı yoksa sürekli konuşma modunda mı olduğuna bağlıdır. Kesintisiz bir konuşmanın tanınmasının daha zor olduğunu unutmayın.
Speaking style- Bir okuma konuşması resmi bir tarzda veya spontane ve gündelik bir tarzda konuşmalı olabilir. İkincisini tanımak daha zordur.
Speaker dependency- Konuşma konuşmacıya bağlı, konuşmacıya göre uyarlanabilir veya konuşmacıdan bağımsız olabilir. Bağımsız bir konuşmacı, yapımı en zor olanıdır.
Type of noise- Bir ASR geliştirirken göz önünde bulundurulması gereken başka bir faktör de gürültüdür. Arka plan gürültüsüne karşı daha az gürültü gözlemleyen akustik ortama bağlı olarak sinyal-gürültü oranı çeşitli aralıklarda olabilir -
Sinyal-gürültü oranı 30dB'den büyükse, yüksek aralık olarak kabul edilir
Sinyal-gürültü oranı 30dB ile 10db arasında ise, orta SNR olarak kabul edilir
Sinyal-gürültü oranı 10dB'den düşükse, düşük aralık olarak kabul edilir
Microphone characteristics- Mikrofon kalitesi iyi, ortalama veya ortalamanın altında olabilir. Ayrıca ağız ile mikro telefon arasındaki mesafe değişebilir. Bu faktörler, tanıma sistemleri için de dikkate alınmalıdır.
Sözcük dağarcığının boyutu ne kadar büyükse, tanımayı gerçekleştirmenin o kadar zor olduğunu unutmayın.
Örneğin, sabit, insan dışı gürültü, arka plan konuşması ve diğer konuşmacılardan gelen parazit gibi arka plan gürültüsü de sorunun zorluğuna katkıda bulunur.
Bu zorluklara rağmen, araştırmacılar konuşma sinyalini, konuşmacıyı anlamak ve aksanları belirlemek gibi konuşmanın çeşitli yönleri üzerinde çok çalıştılar.
Bir konuşma tanıyıcı oluşturmak için aşağıda verilen adımları izlemeniz gerekecek -
Ses Sinyallerini Görselleştirme - Bir Dosyadan Okuma ve Üzerinde Çalışma
Bu, bir ses sinyalinin nasıl yapılandırıldığının anlaşılmasını sağladığı için konuşma tanıma sistemi oluşturmanın ilk adımıdır. Ses sinyalleri ile çalışmak için izlenebilecek bazı genel adımlar aşağıdaki gibidir -
Kayıt
Bir dosyadan ses sinyalini okumanız gerektiğinde, bunu önce bir mikrofon kullanarak kaydedin.
Örnekleme
Mikrofonla kayıt yapılırken sinyaller dijitalleştirilmiş bir biçimde saklanır. Ancak bunun üzerinde çalışmak için makinenin bunlara ayrı sayısal biçimde ihtiyacı var. Bu nedenle, belirli bir frekansta örnekleme yapmalı ve sinyali ayrı sayısal forma dönüştürmeliyiz. Örnekleme için yüksek frekansı seçmek, insanlar sinyali dinlediğinde, onu sürekli bir ses sinyali olarak hissettiklerini ima eder.
Misal
Aşağıdaki örnek, bir dosyada depolanan Python kullanarak bir ses sinyalini analiz etmek için aşamalı bir yaklaşımı gösterir. Bu ses sinyalinin frekansı 44.100 HZ'dir.
Gerekli paketleri burada gösterildiği gibi içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileŞimdi depolanan ses dosyasını okuyun. İki değer döndürecektir: örnekleme frekansı ve ses sinyali. Burada gösterildiği gibi, saklandığı ses dosyasının yolunu sağlayın -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Gösterilen komutları kullanarak ses sinyalinin örnekleme frekansı, sinyalin veri türü ve süresi gibi parametreleri görüntüleyin -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Bu adım, sinyali aşağıda gösterildiği gibi normalleştirmeyi içerir -
audio_signal = audio_signal / np.power(2, 15)Bu adımda, görselleştirmek için bu sinyalden ilk 100 değeri çıkarıyoruz. Bu amaçla aşağıdaki komutları kullanın -
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)Şimdi, aşağıda verilen komutları kullanarak sinyali görselleştirin -
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()Buradaki görüntüde gösterildiği gibi, yukarıdaki ses sinyali için çıkarılan verileri ve bir çıktı grafiğini görebilirsiniz.

Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 secondsSes Sinyalinin Karakterizasyonu: Frekans Alanına Dönüştürme
Bir ses sinyalinin karakterize edilmesi, zaman alanı sinyalinin frekans alanına dönüştürülmesini ve frekans bileşenlerinin anlaşılmasını içerir. Bu, sinyal hakkında çok fazla bilgi verdiği için önemli bir adımdır. Bu dönüşümü gerçekleştirmek için Fourier Dönüşümü gibi matematiksel bir araç kullanabilirsiniz.
Misal
Aşağıdaki örnek, bir dosyada depolanan Python kullanılarak sinyalin nasıl karakterize edileceğini adım adım gösterir. Burada Fourier Dönüşümü matematiksel aracını onu frekans alanına dönüştürmek için kullandığımıza dikkat edin.
Burada gösterildiği gibi gerekli paketleri içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileŞimdi depolanan ses dosyasını okuyun. İki değer döndürecektir: örnekleme frekansı ve ses sinyali. Buradaki komutta gösterildiği gibi, kaydedildiği ses dosyasının yolunu sağlayın -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")Bu adımda, aşağıda verilen komutları kullanarak ses sinyalinin örnekleme frekansı, sinyalin veri tipi ve süresi gibi parametreleri göstereceğiz -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Bu adımda, aşağıdaki komutta gösterildiği gibi sinyali normalleştirmemiz gerekiyor -
audio_signal = audio_signal / np.power(2, 15)Bu adım, sinyalin uzunluğunun ve yarı uzunluğunun çıkarılmasını içerir. Bu amaçla aşağıdaki komutları kullanın -
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)Şimdi, frekans alanına dönüştürmek için matematik araçlarını uygulamamız gerekiyor. Burada Fourier Dönüşümünü kullanıyoruz.
signal_frequency = np.fft.fft(audio_signal)Şimdi, frekans alanı sinyalinin normalizasyonunu yapın ve karesini alın -
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal
signal_frequency **= 2Ardından, frekans dönüştürülmüş sinyalin uzunluğunu ve yarım uzunluğunu çıkarın -
len_fts = len(signal_frequency)Fourier dönüştürülmüş sinyalin tek ve çift durum için ayarlanması gerektiğini unutmayın.
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2Şimdi, gücü desibel (dB) cinsinden çıkarın -
signal_power = 10 * np.log10(signal_frequency)X ekseni için frekansı kHz olarak ayarlayın -
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0Şimdi, sinyalin karakterizasyonunu aşağıdaki gibi görselleştirin -
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()Yukarıdaki kodun çıktı grafiğini aşağıdaki resimde gösterildiği gibi gözlemleyebilirsiniz -

Monoton Ses Sinyali Oluşturma
Şimdiye kadar gördüğünüz iki adım, sinyaller hakkında bilgi edinmek için önemlidir. Şimdi, ses sinyalini önceden tanımlanmış bazı parametrelerle oluşturmak istiyorsanız bu adım yararlı olacaktır. Bu adımın ses sinyalini bir çıktı dosyasına kaydedeceğini unutmayın.
Misal
Aşağıdaki örnekte, Python kullanarak bir dosyada saklanacak tek tonlu bir sinyal üreteceğiz. Bunun için aşağıdaki adımları atmanız gerekecek -
Gerekli paketleri gösterildiği gibi içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import writeÇıktı dosyasının kaydedilmesi gereken dosyayı sağlayın
output_file = 'audio_signal_generated.wav'Şimdi, seçtiğiniz parametreleri gösterildiği gibi belirtin -
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piBu adımda, gösterildiği gibi ses sinyali oluşturabiliriz -
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)Şimdi, ses dosyasını çıktı dosyasına kaydedin -
write(output_file, frequency_sampling, signal_scaled)Grafiğimiz için ilk 100 değeri gösterildiği gibi çıkarın -
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)Şimdi, üretilen ses sinyalini aşağıdaki gibi görselleştirin -
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()Grafiği, burada verilen şekilde gösterildiği gibi gözlemleyebilirsiniz -
Konuşmadan Özellik Çıkarma
Bu, bir konuşma tanıyıcı oluşturmanın en önemli adımıdır çünkü konuşma sinyalini frekans alanına dönüştürdükten sonra, onu kullanılabilir özellik vektörüne dönüştürmeliyiz. Bu amaçla MFCC, PLP, PLP-RASTA gibi farklı öznitelik çıkarma tekniklerini kullanabiliriz.
Misal
Aşağıdaki örnekte, MFCC tekniğini kullanarak Python kullanarak sinyalden özellikleri adım adım çıkaracağız.
Burada gösterildiği gibi gerekli paketleri içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbankŞimdi depolanan ses dosyasını okuyun. İki değer döndürecektir - örnekleme frekansı ve ses sinyali. Kaydedildiği ses dosyasının yolunu sağlayın.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Burada analiz için ilk 15000 numuneyi alıyoruz.
audio_signal = audio_signal[:15000]MFCC tekniklerini kullanın ve MFCC özelliklerini çıkarmak için aşağıdaki komutu yürütün -
features_mfcc = mfcc(audio_signal, frequency_sampling)Şimdi, gösterildiği gibi MFCC parametrelerini yazdırın -
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])Şimdi, aşağıda verilen komutları kullanarak MFCC özelliklerini çizin ve görselleştirin -
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')Bu adımda, gösterildiği gibi filtre bankası özellikleriyle çalışıyoruz -
Filtre bankası özelliklerini çıkarın -
filterbank_features = logfbank(audio_signal, frequency_sampling)Şimdi, filtre bankası parametrelerini yazdırın.
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])Şimdi, filtre bankası özelliklerini çizin ve görselleştirin.
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()Yukarıdaki adımların bir sonucu olarak, aşağıdaki çıktıları gözlemleyebilirsiniz: MFCC için Şekil 1 ve Filtre Bankası için Şekil2

Sözlü Kelimelerin Tanınması
Konuşma tanıma, insanlar konuşurken bir makinenin onu anlaması anlamına gelir. Bunu gerçekleştirmek için Python'da Google Speech API kullanıyoruz. Bunun için aşağıdaki paketleri kurmamız gerekiyor -
Pyaudio - Kullanılarak kurulabilir pip install Pyaudio komut.
SpeechRecognition - Bu paket kullanılarak kurulabilir pip install SpeechRecognition.
Google-Speech-API - komutu kullanılarak kurulabilir pip install google-api-python-client.
Misal
Sözlü kelimelerin tanınmasını anlamak için aşağıdaki örneği inceleyin -
Gerekli paketleri gösterildiği gibi içe aktarın -
import speech_recognition as srAşağıda gösterildiği gibi bir nesne oluşturun -
recording = sr.Recognizer()Şimdi Microphone() modül sesi girdi olarak alacaktır -
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)Artık Google API sesi tanıyacak ve çıktıyı verecektir.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)Aşağıdaki çıktıyı görebilirsiniz -
Please Say Something:
You said:Örneğin, dediyseniz tutorialspoint.com, sonra sistem bunu aşağıdaki gibi doğru bir şekilde tanır -
tutorialspoint.comSezgisel arama, yapay zekada önemli bir rol oynar. Bu bölümde ayrıntılı olarak öğreneceksiniz.
Yapay Zekada Sezgisel Arama Kavramı
Sezgisel, bizi olası çözüme götüren pratik bir kuraldır. Yapay zekadaki çoğu sorun üstel niteliktedir ve birçok olası çözümü vardır. Hangi çözümlerin doğru olduğunu tam olarak bilmiyorsunuz ve tüm çözümleri kontrol etmek çok pahalıya mal olur.
Böylelikle sezgisel kullanım, çözüm arayışını daraltır ve yanlış seçenekleri ortadan kaldırır. Arama uzayında aramaya öncülük etmek için sezgisel kullanım yöntemine Sezgisel Arama denir. Sezgisel teknikler çok kullanışlıdır, çünkü bunları kullandığınızda arama artırılabilir.
Bilgisiz ve Bilgisiz Arama Arasındaki Fark
İki tür kontrol stratejisi veya arama tekniği vardır: bilgisiz ve bilgili. Burada verildiği gibi ayrıntılı olarak açıklanmıştır -
Bilgisiz Arama
Aynı zamanda kör arama veya kör kontrol stratejisi olarak da adlandırılır. Bu şekilde adlandırılmıştır çünkü yalnızca problem tanımı hakkında bilgi vardır ve durumlar hakkında başka ek bilgi yoktur. Bu tür arama teknikleri, çözümü elde etmek için tüm durum alanını araştıracaktır. Kapsamlı İlk Arama (BFS) ve İlk Derinlik Araması (DFS), bilgisiz arama örnekleridir.
Bilgilendirilmiş Arama
Sezgisel arama veya sezgisel kontrol stratejisi olarak da adlandırılır. Eyaletler hakkında bazı ekstra bilgiler olduğu için böyle adlandırılmıştır. Bu ekstra bilgi, alt düğümler arasında keşfedilecek ve genişletilecek tercihi hesaplamak için kullanışlıdır. Her düğümle ilişkili bir sezgisel işlev olacaktır. En İyi İlk Arama (BFS), A *, Ortalama ve Analiz, bilgiye dayalı arama örnekleridir.
Kısıt Memnuniyet Sorunları (CSP'ler)
Kısıtlama, kısıtlama veya sınırlama anlamına gelir. AI'da kısıtlama tatmin problemleri, bazı kısıtlamalar altında çözülmesi gereken problemlerdir. Bu tür problemleri çözerken kısıtı ihlal etmemek üzerinde durulmalıdır. Son olarak, nihai çözüme ulaştığımızda, CSP kısıtlamaya uymalıdır.
Kısıt Memnuniyetiyle Çözülen Gerçek Dünya Problemi
Önceki bölümler, kısıtlama tatmin problemlerinin yaratılmasıyla ilgiliydi. Şimdi bunu gerçek dünya sorunlarına da uygulayalım. Kısıt memnuniyetiyle çözülen bazı gerçek dünya sorunları örnekleri aşağıdaki gibidir:
Cebirsel ilişkiyi çözme
Kısıt doyumu problemi yardımıyla cebirsel ilişkileri çözebiliriz. Bu örnekte, basit bir cebirsel ilişkiyi çözmeye çalışacağıza*2 = b. Değerini döndürecektira ve b tanımlayacağımız aralık dahilinde.
Bu Python programını tamamladıktan sonra, kısıtlama memnuniyetiyle sorunları çözmenin temellerini anlayabileceksiniz.
Programı yazmadan önce python-constraint adlı Python paketini kurmamız gerektiğini unutmayın. Aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install python-constraintAşağıdaki adımlar size kısıt memnuniyetini kullanarak cebirsel ilişkiyi çözmek için bir Python programı gösterir -
İçe aktar constraint aşağıdaki komutu kullanarak paketleyin -
from constraint import *Şimdi, adlı bir modül nesnesi oluşturun problem() aşağıda gösterildiği gibi -
problem = Problem()Şimdi değişkenleri tanımlayın. Burada a ve b olmak üzere iki değişkenimiz olduğunu ve 10'u bunların aralığı olarak tanımladığımızı, yani çözümü ilk 10 sayı içinde bulduğumuzu unutmayın.
problem.addVariable('a', range(10))
problem.addVariable('b', range(10))Sonra, bu soruna uygulamak istediğimiz belirli kısıtlamayı tanımlayın. Burada kısıtlamayı kullandığımıza dikkat edina*2 = b.
problem.addConstraint(lambda a, b: a * 2 == b)Şimdi, nesnesini oluşturun getSolution() aşağıdaki komutu kullanarak modül -
solutions = problem.getSolutions()Son olarak, aşağıdaki komutu kullanarak çıktıyı yazdırın -
print (solutions)Yukarıdaki programın çıktısını aşağıdaki gibi gözlemleyebilirsiniz -
[{'a': 4, 'b': 8}, {'a': 3, 'b': 6}, {'a': 2, 'b': 4}, {'a': 1, 'b': 2}, {'a': 0, 'b': 0}]Sihirli Kare
Sihirli kare, her satırdaki ve her sütundaki sayıların ve köşegendeki sayıların toplamının "sihirli sabit" olarak adlandırılan aynı sayıyı oluşturduğu bir kare ızgarada farklı sayıların, genellikle tam sayıların bir düzenlemesidir .
Aşağıdaki, sihirli kareler oluşturmak için basit Python kodunun adım adım yürütülmesidir -
Adlı bir işlev tanımlayın magic_squareaşağıda gösterildiği gibi -
def magic_square(matrix_ms):
iSize = len(matrix_ms[0])
sum_list = []Aşağıdaki kod, karelerin dikey kodunu gösterir -
for col in range(iSize):
sum_list.append(sum(row[col] for row in matrix_ms))Aşağıdaki kod yatay karelerin kodunu gösterir -
sum_list.extend([sum (lines) for lines in matrix_ms])Aşağıdaki kod, karelerin yatay kodunu gösterir -
dlResult = 0
for i in range(0,iSize):
dlResult +=matrix_ms[i][i]
sum_list.append(dlResult)
drResult = 0
for i in range(iSize-1,-1,-1):
drResult +=matrix_ms[i][i]
sum_list.append(drResult)
if len(set(sum_list))>1:
return False
return TrueŞimdi matrisin değerini verin ve çıktıyı kontrol edin -
print(magic_square([[1,2,3], [4,5,6], [7,8,9]]))Çıktının olacağını gözlemleyebilirsiniz. False toplam aynı sayıya kadar olmadığı için.
print(magic_square([[3,9,2], [3,5,7], [9,1,6]]))Çıktının olacağını gözlemleyebilirsiniz. True toplam aynı sayı olduğu için 15 buraya.
Oyunlar bir strateji ile oynanır. Her oyuncu veya takım oyuna başlamadan önce bir strateji yapar ve oyundaki mevcut duruma / durumlara göre yeni bir strateji geliştirmeleri veya değiştirmeleri gerekir.
Arama Algoritmaları
Bilgisayar oyunlarını da yukarıdaki ile aynı stratejiyle düşünmeniz gerekecek. Bilgisayar oyunlarındaki stratejiyi belirleyenlerin Arama Algoritmaları olduğunu unutmayın.
Nasıl çalışır
Arama algoritmalarının amacı, nihai hedefe ulaşıp kazanabilmeleri için en uygun hamle setini bulmaktır. Bu algoritmalar, en iyi hamleleri bulmak için her oyun için farklı olan kazanan koşullar kümesini kullanır.
Bir bilgisayar oyununu ağaç olarak görselleştirin. Ağacın düğümleri olduğunu biliyoruz. Kökten başlayarak, son kazanan düğüme gelebiliriz, ancak en uygun hareketlerle. Bu, arama algoritmalarının işidir. Böyle bir ağaçtaki her düğüm gelecekteki bir durumu temsil eder. Arama algoritmaları, oyunun her adımında veya düğümünde kararlar almak için bu ağaçta arama yapar.
Kombinasyonel Arama
Arama algoritmalarını kullanmanın en büyük dezavantajı, doğaları gereği kapsamlı olmalarıdır, bu nedenle kaynak israfına yol açan çözümü bulmak için tüm arama alanını keşfederler. Bu algoritmaların nihai çözümü bulmak için tüm arama alanını araştırması gerekmesi daha zahmetli olacaktır.
Bu tür bir sorunu ortadan kaldırmak için, arama alanını keşfetmek için buluşsal yöntemi kullanan ve olası yanlış hareketleri ortadan kaldırarak boyutunu küçülten kombinasyonel aramayı kullanabiliriz. Dolayısıyla, bu tür algoritmalar kaynakları kurtarabilir. Alanı aramak ve kaynakları kurtarmak için buluşsal yöntem kullanan algoritmalardan bazıları burada tartışılmaktadır -
Minimax Algoritması
Arama stratejisini hızlandırmak için buluşsal yöntem kullanan kombinasyonel arama tarafından kullanılan stratejidir. Minimax stratejisi kavramı, her oyuncunun rakibin bir sonraki hamlesini tahmin etmeye çalıştığı ve bu işlevi en aza indirmeye çalıştığı iki oyunculu oyun örneğiyle anlaşılabilir. Ayrıca, kazanmak için oyuncu her zaman mevcut duruma göre kendi işlevini en üst düzeye çıkarmaya çalışır.
Sezgisel, Minimax gibi bu tür stratejilerde önemli bir rol oynar. Ağacın her düğümü, kendisiyle ilişkili bir sezgisel işleve sahip olacaktır. Bu buluşsal yönteme dayanarak, kendilerine en çok fayda sağlayacak düğüme doğru bir hareket etme kararını alacaktır.
Alfa Beta Budama
Minimax algoritmasının önemli bir sorunu, ağacın alakasız kısımlarını keşfedebilmesi ve kaynak israfına yol açmasıdır. Bu nedenle, ağacın hangi kısmının alakalı ve hangisinin ilgisiz olduğuna karar verecek ve ilgisiz kısmı keşfedilmemiş bırakacak bir strateji olmalıdır. Alfa-Beta budama bu tür bir stratejidir.
Alfa-Beta budama algoritmasının temel amacı, ağacın herhangi bir çözümü olmayan kısımlarını aramaktan kaçınmaktır. Alfa-Beta budamanın ana konsepti, adı verilen iki sınır kullanmaktır.Alpha, maksimum alt sınır ve Beta, minimum üst sınır. Bu iki parametre, olası çözümler kümesini sınırlayan değerlerdir. Geçerli düğümün değerini alfa ve beta parametrelerinin değeriyle karşılaştırır, böylece ağacın çözüme sahip olan kısmına hareket edebilir ve geri kalanını atabilir.
Negamax Algoritması
Bu algoritma Minimax algoritmasından farklı değildir, ancak daha zarif bir uygulaması vardır. Minimax algoritmasını kullanmanın temel dezavantajı, iki farklı sezgisel işlevi tanımlamamız gerekmesidir. Bu buluşsal yöntemler arasındaki bağlantı, bir oyunun durumu bir oyuncu için ne kadar iyiyse, diğer oyuncu için o kadar kötüdür. Negamax algoritmasında, iki sezgisel fonksiyonun aynı çalışması tek bir sezgisel fonksiyon yardımıyla yapılır.
Oyun Oynamak için Botlar Oluşturma
AI'da iki oyunculu oyunlar oynayacak botlar oluşturmak için, easyAIkütüphane. İki oyunculu oyunlar oluşturmak için tüm işlevselliği sağlayan bir yapay zeka çerçevesidir. Aşağıdaki komutun yardımıyla indirebilirsiniz -
pip install easyAISon Madeni Parayı Oynayan Bir Bot
Bu oyunda bir yığın para olacaktı. Her oyuncunun o desteden bir miktar jeton alması gerekir. Oyunun amacı yığındaki son parayı almaktan kaçınmaktır. Sınıfı kullanacağızLastCoinStanding -dan miras TwoPlayersGame sınıfı easyAIkütüphane. Aşağıdaki kod, bu oyun için Python kodunu gösterir -
Gerekli paketleri gösterildiği gibi içe aktarın -
from easyAI import TwoPlayersGame, id_solve, Human_Player, AI_Player
from easyAI.AI import TTŞimdi, sınıfı, TwoPlayerGame oyunun tüm işlemlerini gerçekleştirecek sınıf -
class LastCoin_game(TwoPlayersGame):
def __init__(self, players):Şimdi oyuna başlayacak oyuncuları ve oyuncuyu tanımlayın.
self.players = players
self.nplayer = 1Şimdi oyundaki jeton sayısını tanımlayın, burada oyun için 15 jeton kullanıyoruz.
self.num_coins = 15Bir oyuncunun hareket halindeyken alabileceği maksimum jeton sayısını belirleyin.
self.max_coins = 4Şimdi, aşağıdaki kodda gösterildiği gibi tanımlanması gereken bazı şeyler var. Olası hareketleri tanımlayın.
def possible_moves(self):
return [str(a) for a in range(1, self.max_coins + 1)]Madeni paraların kaldırılmasını tanımlayın
def make_move(self, move):
self.num_coins -= int(move)Son parayı kimin aldığını tanımlayın.
def win_game(self):
return self.num_coins <= 0Oyunu ne zaman durduracağınızı belirleyin, yani birisi kazanırsa.
def is_over(self):
return self.win()Puanı nasıl hesaplayacağınızı tanımlayın.
def score(self):
return 100 if self.win_game() else 0Yığın içinde kalan jeton sayısını tanımlayın.
def show(self):
print(self.num_coins, 'coins left in the pile')
if __name__ == "__main__":
tt = TT()
LastCoin_game.ttentry = lambda self: self.num_coinsOyunu aşağıdaki kod bloğu ile çözme -
r, d, m = id_solve(LastCoin_game,
range(2, 20), win_score=100, tt=tt)
print(r, d, m)Oyuna kimin başlayacağına karar vermek
game = LastCoin_game([AI_Player(tt), Human_Player()])
game.play()Aşağıdaki çıktıyı ve bu oyunun basit bir oyununu bulabilirsiniz -
d:2, a:0, m:1
d:3, a:0, m:1
d:4, a:0, m:1
d:5, a:0, m:1
d:6, a:100, m:4
1 6 4
15 coins left in the pile
Move #1: player 1 plays 4 :
11 coins left in the pile
Player 2 what do you play ? 2
Move #2: player 2 plays 2 :
9 coins left in the pile
Move #3: player 1 plays 3 :
6 coins left in the pile
Player 2 what do you play ? 1
Move #4: player 2 plays 1 :
5 coins left in the pile
Move #5: player 1 plays 4 :
1 coins left in the pile
Player 2 what do you play ? 1
Move #6: player 2 plays 1 :
0 coins left in the pileTic Tac Toe Oynamak İçin Bir Bot
Tic-Tac-Toe çok tanıdık ve en popüler oyunlardan biri. Bu oyunu kullanarak yaratalımeasyAIPython'da kütüphane. Aşağıdaki kod, bu oyunun Python kodudur -
Paketleri gösterildiği gibi içe aktarın -
from easyAI import TwoPlayersGame, AI_Player, Negamax
from easyAI.Player import Human_PlayerSınıfı, TwoPlayerGame oyunun tüm işlemlerini gerçekleştirecek sınıf -
class TicTacToe_game(TwoPlayersGame):
def __init__(self, players):Şimdi, oyuna başlayacak oyuncuları ve oyuncuyu tanımlayın -
self.players = players
self.nplayer = 1Kart türünü tanımlayın -
self.board = [0] * 9Şimdi tanımlanması gereken bazı şeyler var:
Olası hareketleri tanımlayın
def possible_moves(self):
return [x + 1 for x, y in enumerate(self.board) if y == 0]Bir oyuncunun hareketini tanımlayın -
def make_move(self, move):
self.board[int(move) - 1] = self.nplayerYapay zekayı artırmak için bir oyuncunun ne zaman hamle yapacağını tanımlayın -
def umake_move(self, move):
self.board[int(move) - 1] = 0Rakibin bir hatta üç tane olması durumunda kaybetme koşulunu tanımlayın
def condition_for_lose(self):
possible_combinations = [[1,2,3], [4,5,6], [7,8,9],
[1,4,7], [2,5,8], [3,6,9], [1,5,9], [3,5,7]]
return any([all([(self.board[z-1] == self.nopponent)
for z in combination]) for combination in possible_combinations])Oyunun bitişi için bir kontrol tanımlayın
def is_over(self):
return (self.possible_moves() == []) or self.condition_for_lose()Oyuncuların oyundaki mevcut konumunu göster
def show(self):
print('\n'+'\n'.join([' '.join([['.', 'O', 'X'][self.board[3*j + i]]
for i in range(3)]) for j in range(3)]))Puanları hesaplayın.
def scoring(self):
return -100 if self.condition_for_lose() else 0Algoritmayı tanımlamak ve oyunu başlatmak için ana yöntemi tanımlayın -
if __name__ == "__main__":
algo = Negamax(7)
TicTacToe_game([Human_Player(), AI_Player(algo)]).play()Aşağıdaki çıktıyı ve bu oyunun basit bir oyununu görebilirsiniz -
. . .
. . .
. . .
Player 1 what do you play ? 1
Move #1: player 1 plays 1 :
O . .
. . .
. . .
Move #2: player 2 plays 5 :
O . .
. X .
121
. . .
Player 1 what do you play ? 3
Move #3: player 1 plays 3 :
O . O
. X .
. . .
Move #4: player 2 plays 2 :
O X O
. X .
. . .
Player 1 what do you play ? 4
Move #5: player 1 plays 4 :
O X O
O X .
. . .
Move #6: player 2 plays 8 :
O X O
O X .
. X .Sinir ağları, beynin bir bilgisayar modelini yapmaya çalışan paralel bilgi işlem cihazlarıdır. Arkasındaki temel amaç, çeşitli hesaplama görevlerini geleneksel sistemlerden daha hızlı gerçekleştirmek için bir sistem geliştirmektir. Bu görevler arasında Örüntü Tanıma ve Sınıflandırma, Yaklaşım, Optimizasyon ve Veri Kümeleme bulunur.
Yapay Sinir Ağları (YSA) nedir
Yapay Sinir Ağı (YSA), ana teması biyolojik sinir ağları analojisinden ödünç alınan verimli bir bilgi işlem sistemidir. YSA'lar ayrıca Yapay Sinir Sistemleri, Paralel Dağıtılmış İşleme Sistemleri ve Bağlantısal Sistemler olarak adlandırılır. YSA, aralarında iletişime izin vermek için bazı modellerde birbirine bağlı geniş bir birim koleksiyonu elde eder. Bu birimler, aynı zamandanodes veya neuronsparalel olarak çalışan basit işlemcilerdir.
Her nöron diğer nöronlarla bir connection link. Her bağlantı linki, giriş sinyali hakkında bilgiye sahip olan bir ağırlık ile ilişkilidir. Bu, nöronların belirli bir sorunu çözmesi için en yararlı bilgidir çünküweightgenellikle iletilen sinyali uyarır veya engeller. Her nöronun kendi iç durumu vardır.activation signal. Giriş sinyalleri ve aktivasyon kuralı birleştirildikten sonra üretilen çıkış sinyalleri diğer birimlere gönderilebilir.
Sinir ağlarını ayrıntılı olarak incelemek istiyorsanız, o zaman Yapay Sinir Ağı bağlantısını takip edebilirsiniz .
Yararlı Paketleri Kurmak
Python'da sinir ağları oluşturmak için, sinir ağları için güçlü bir paket kullanabiliriz. NeuroLab. Python için esnek ağ yapılandırmaları ve öğrenme algoritmaları ile temel sinir ağları algoritmalarından oluşan bir kitaplıktır. Bu paketi, komut isteminde aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install NeuroLabAnaconda ortamını kullanıyorsanız, NeuroLab'ı kurmak için aşağıdaki komutu kullanın -
conda install -c labfabulous neurolabSinir Ağları Oluşturmak
Bu bölümde NeuroLab paketini kullanarak Python'da bazı sinir ağları oluşturalım.
Perceptron tabanlı Sınıflandırıcı
Algılayıcılar YSA'nın yapı taşlarıdır. Perceptron hakkında daha fazla bilgi edinmek istiyorsanız, - artificial_neural_network bağlantısını takip edebilirsiniz.
Aşağıda, basit bir sinir ağı algılayıcı tabanlı sınıflandırıcı oluşturmak için Python kodunun aşamalı olarak yürütülmesi yer almaktadır -
Gerekli paketleri gösterildiği gibi içe aktarın -
import matplotlib.pyplot as plt
import neurolab as nlGiriş değerlerini girin. Bunun denetimli öğrenmeye bir örnek olduğunu, dolayısıyla hedef değerleri de sağlamanız gerekeceğini unutmayın.
input = [[0, 0], [0, 1], [1, 0], [1, 1]]
target = [[0], [0], [0], [1]]Ağı 2 giriş ve 1 nöron ile oluşturun -
net = nl.net.newp([[0, 1],[0, 1]], 1)Şimdi ağı eğitin. Burada eğitim için Delta kuralı kullanıyoruz.
error_progress = net.train(input, target, epochs=100, show=10, lr=0.1)Şimdi çıktıyı görselleştirin ve grafiği çizin -
plt.figure()
plt.plot(error_progress)
plt.xlabel('Number of epochs')
plt.ylabel('Training error')
plt.grid()
plt.show()Hata metriğini kullanarak egzersiz ilerlemesini gösteren aşağıdaki grafiği görebilirsiniz -

Tek Katmanlı Yapay Sinir Ağları
Bu örnekte, çıktıyı üretmek için girdi verilerine etki eden bağımsız nöronlardan oluşan tek katmanlı bir sinir ağı oluşturuyoruz. Adlı metin dosyasını kullandığımızı unutmayın.neural_simple.txt bizim girdi olarak.
Yararlı paketleri gösterildiği gibi içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
import neurolab as nlVeri kümesini aşağıdaki gibi yükleyin -
input_data = np.loadtxt(“/Users/admin/neural_simple.txt')Aşağıdaki, kullanacağımız verilerdir. Bu verilerde ilk iki sütunun özellikler ve son iki sütunun da etiketler olduğunu unutmayın.
array([[2. , 4. , 0. , 0. ],
[1.5, 3.9, 0. , 0. ],
[2.2, 4.1, 0. , 0. ],
[1.9, 4.7, 0. , 0. ],
[5.4, 2.2, 0. , 1. ],
[4.3, 7.1, 0. , 1. ],
[5.8, 4.9, 0. , 1. ],
[6.5, 3.2, 0. , 1. ],
[3. , 2. , 1. , 0. ],
[2.5, 0.5, 1. , 0. ],
[3.5, 2.1, 1. , 0. ],
[2.9, 0.3, 1. , 0. ],
[6.5, 8.3, 1. , 1. ],
[3.2, 6.2, 1. , 1. ],
[4.9, 7.8, 1. , 1. ],
[2.1, 4.8, 1. , 1. ]])Şimdi, bu dört sütunu 2 veri sütunu ve 2 etikete ayırın -
data = input_data[:, 0:2]
labels = input_data[:, 2:]Aşağıdaki komutları kullanarak giriş verilerini çizin -
plt.figure()
plt.scatter(data[:,0], data[:,1])
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Input data')Şimdi, her bir boyut için minimum ve maksimum değerleri burada gösterildiği gibi tanımlayın -
dim1_min, dim1_max = data[:,0].min(), data[:,0].max()
dim2_min, dim2_max = data[:,1].min(), data[:,1].max()Ardından, çıktı katmanındaki nöron sayısını aşağıdaki gibi tanımlayın -
nn_output_layer = labels.shape[1]Şimdi, tek katmanlı bir sinir ağı tanımlayın -
dim1 = [dim1_min, dim1_max]
dim2 = [dim2_min, dim2_max]
neural_net = nl.net.newp([dim1, dim2], nn_output_layer)Sinir ağını, gösterildiği gibi dönem sayısı ve öğrenme oranıyla eğitin -
error = neural_net.train(data, labels, epochs = 200, show = 20, lr = 0.01)Şimdi, aşağıdaki komutları kullanarak eğitim ilerlemesini görselleştirin ve planlayın -
plt.figure()
plt.plot(error)
plt.xlabel('Number of epochs')
plt.ylabel('Training error')
plt.title('Training error progress')
plt.grid()
plt.show()Şimdi, yukarıdaki sınıflandırıcıdaki test veri noktalarını kullanın -
print('\nTest Results:')
data_test = [[1.5, 3.2], [3.6, 1.7], [3.6, 5.7],[1.6, 3.9]] for item in data_test:
print(item, '-->', neural_net.sim([item])[0])Test sonuçlarını burada gösterildiği gibi bulabilirsiniz -
[1.5, 3.2] --> [1. 0.]
[3.6, 1.7] --> [1. 0.]
[3.6, 5.7] --> [1. 1.]
[1.6, 3.9] --> [1. 0.]Şimdiye kadar tartışılan kodun çıktısı olarak aşağıdaki grafikleri görebilirsiniz -


Çok Katmanlı Sinir Ağları
Bu örnekte, eğitim verilerindeki temel kalıpları çıkarmak için birden fazla katmandan oluşan çok katmanlı bir sinir ağı oluşturuyoruz. Bu çok katmanlı sinir ağı bir regresör gibi çalışacak. Y = 2x 2 +8 denklemine dayalı olarak bazı veri noktaları oluşturacağız .
Gerekli paketleri gösterildiği gibi içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
import neurolab as nlYukarıda belirtilen denkleme dayalı olarak bazı veri noktaları oluşturun -
min_val = -30
max_val = 30
num_points = 160
x = np.linspace(min_val, max_val, num_points)
y = 2 * np.square(x) + 8
y /= np.linalg.norm(y)Şimdi, bu veri kümesini aşağıdaki gibi yeniden şekillendirin -
data = x.reshape(num_points, 1)
labels = y.reshape(num_points, 1)Aşağıdaki komutları kullanarak giriş veri kümesini görselleştirin ve çizin -
plt.figure()
plt.scatter(data, labels)
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Data-points')Şimdi, iki gizli katmana sahip sinir ağını oluşturun. neurolab ile ten ilk gizli katmandaki nöronlar, six ikinci gizli katmanda ve one çıktı katmanında.
neural_net = nl.net.newff([[min_val, max_val]], [10, 6, 1])Şimdi gradyan eğitim algoritmasını kullanın -
neural_net.trainf = nl.train.train_gdŞimdi, ağı yukarıda üretilen verileri öğrenmek amacıyla eğitin -
error = neural_net.train(data, labels, epochs = 1000, show = 100, goal = 0.01)Şimdi, eğitim veri noktalarında sinir ağlarını çalıştırın -
output = neural_net.sim(data)
y_pred = output.reshape(num_points)Şimdi arsa ve görselleştirme görevi -
plt.figure()
plt.plot(error)
plt.xlabel('Number of epochs')
plt.ylabel('Error')
plt.title('Training error progress')Şimdi, tahmin edilen çıktıya karşı gerçek çıktıyı çizeceğiz -
x_dense = np.linspace(min_val, max_val, num_points * 2)
y_dense_pred = neural_net.sim(x_dense.reshape(x_dense.size,1)).reshape(x_dense.size)
plt.figure()
plt.plot(x_dense, y_dense_pred, '-', x, y, '.', x, y_pred, 'p')
plt.title('Actual vs predicted')
plt.show()Yukarıdaki komutların bir sonucu olarak, aşağıda gösterildiği gibi grafikleri gözlemleyebilirsiniz -



Bu bölümde, Python ile AI'da pekiştirmeli öğrenme kavramları hakkında ayrıntılı bilgi edineceksiniz.
Takviyeli Öğrenmenin Temelleri
Bu tür bir öğrenme, eleştirel bilgilere dayalı olarak ağı güçlendirmek veya güçlendirmek için kullanılır. Yani, pekiştirmeli öğrenme kapsamında eğitilen bir ağ, çevreden bir miktar geri bildirim alır. Ancak, geribildirim değerlendiricidir ve denetimli öğrenim durumunda olduğu gibi öğretici değildir. Ağ, bu geribildirime dayanarak, gelecekte daha iyi kritik bilgileri elde etmek için ağırlık ayarlamalarını gerçekleştirir.
Bu öğrenme süreci denetimli öğrenmeye benzer, ancak çok daha az bilgiye sahip olabiliriz. Aşağıdaki şekil, pekiştirmeli öğrenmenin blok diyagramını vermektedir -

Yapı Taşları: Çevre ve Aracı
Çevre ve Aracı, AI'daki pekiştirmeli öğrenmenin ana yapı taşlarıdır. Bu bölüm bunları ayrıntılı olarak tartışmaktadır -
Ajan
Bir ajan, çevresini sensörler aracılığıyla algılayabilen ve efektörler aracılığıyla o ortama etki eden herhangi bir şeydir.
Bir human agent sensörlere paralel göz, kulak, burun, dil ve deri gibi duyu organları ile efektörler için eller, bacaklar, ağız gibi diğer organlara sahiptir.
Bir robotic agent sensörler için kameraların ve kızılötesi mesafe bulucuların ve efektörler için çeşitli motorların ve aktüatörlerin yerini alır.
Bir software agent programları ve eylemleri olarak bit dizilerini kodlamıştır.
Aracı Terminolojisi
Aşağıdaki terimler, AI'da pekiştirmeli öğrenmede daha sık kullanılır -
Performance Measure of Agent - Bir temsilcinin ne kadar başarılı olduğunu belirleyen kriterlerdir.
Behavior of Agent - Herhangi bir algı dizisinden sonra aracının gerçekleştirdiği eylemdir.
Percept - Ajanın belirli bir durumdaki algısal girdileridir.
Percept Sequence - Bir ajanın bugüne kadar algıladığı her şeyin tarihçesi.
Agent Function - İlke dizisinden bir eyleme uzanan bir harita.
Çevre
Bazı programlar tamamen artificial environment klavye girişi, veritabanı, bilgisayar dosya sistemleri ve bir ekranda karakter çıkışı ile sınırlıdır.
Buna karşılık, yazılım robotları veya yazılım botları gibi bazı yazılım aracıları, zengin ve sınırsız softbot etki alanlarında bulunur. Simülatörde birvery detailed, ve complex environment. Yazılım temsilcisinin gerçek zamanlı olarak uzun bir eylem dizisi arasından seçim yapması gerekir.
Örneğin, müşterinin çevrimiçi tercihlerini taramak ve müşteriye ilginç öğeleri görüntülemek için tasarlanmış bir softbot, real yanı sıra bir artificial çevre.
Çevrenin Özellikleri
Ortam, aşağıda tartışıldığı gibi çok katlı özelliklere sahiptir -
Discrete/Continuous- Ortamın sınırlı sayıda farklı, açıkça tanımlanmış durumu varsa, ortam ayrıktır, aksi takdirde süreklidir. Örneğin, satranç ayrı bir ortamdır ve araba kullanmak sürekli bir ortamdır.
Observable/Partially Observable- Algılamalardan her zaman noktasında ortamın tam durumunu belirlemek mümkün ise gözlemlenebilir; aksi takdirde sadece kısmen gözlemlenebilir.
Static/Dynamic- Bir aracı hareket ederken ortam değişmezse, statiktir; aksi takdirde dinamiktir.
Single agent/Multiple agents - Ortam, ajanınki ile aynı veya farklı türden başka ajanlar içerebilir.
Accessible/Inaccessible- Eğer ajanın duyusal aparatı, çevrenin tam durumuna erişebiliyorsa, o zaman ortama o ajan tarafından erişilebilir; aksi takdirde erişilemez.
Deterministic/Non-deterministic- Ortamın bir sonraki durumu tamamen mevcut durum ve aracının eylemleri tarafından belirlenirse, ortam deterministiktir; aksi takdirde deterministik değildir.
Episodic/Non-episodic- Epizodik bir ortamda, her bölüm, algılayan ve sonra oyunculuk yapan failden oluşur. Eyleminin kalitesi sadece bölümün kendisine bağlıdır. Sonraki bölümler, önceki bölümlerdeki eylemlere bağlı değildir. Epizodik ortamlar çok daha basittir çünkü temsilcinin ileriyi düşünmesi gerekmez.
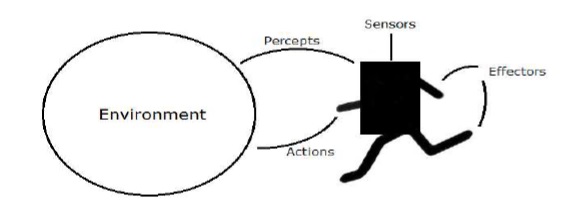
Python ile Ortam Oluşturmak
Takviye öğrenme aracısı oluşturmak için, OpenAI Gym aşağıdaki komut yardımı ile kurulabilen paket -
pip install gymOpenAI spor salonunda çeşitli amaçlarla kullanılabilecek çeşitli ortamlar bulunmaktadır. Çok azıCartpole-v0, Hopper-v1, ve MsPacman-v0. Farklı motorlara ihtiyaç duyarlar. Ayrıntılı dokümantasyonOpenAI Gym bulunabilir https://gym.openai.com/docs/#environments.
Aşağıdaki kod, cartpole-v0 ortamı için bir Python kodu örneğini gösterir -
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())
Diğer ortamları da benzer şekilde inşa edebilirsiniz.
Python ile bir öğrenim aracısı oluşturmak
Takviye öğrenme aracısı oluşturmak için, OpenAI Gym gösterildiği gibi paket -
import gym
env = gym.make('CartPole-v0')
for _ in range(20):
observation = env.reset()
for i in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(i+1))
break
Kıkırdak direğinin kendi kendini dengeleyebildiğini gözlemleyin.
Bu bölümde AI'nın Genetik Algoritmaları ayrıntılı olarak tartışılmaktadır.
Genetik Algoritmalar nedir?
Genetik Algoritmalar (GA'lar), doğal seleksiyon ve genetik kavramlarına dayanan arama tabanlı algoritmalardır. GA'lar, Evrimsel Hesaplama olarak bilinen çok daha büyük bir hesaplama dalının bir alt kümesidir.
GA'lar, John Holland ve Michigan Üniversitesi'ndeki öğrencileri ve meslektaşları, özellikle de David E. Goldberg tarafından geliştirildi. O zamandan beri çeşitli optimizasyon problemlerinde yüksek derecede başarı ile denenmiştir.
GA'larda, verilen soruna yönelik olası çözüm havuzumuz var. Bu çözümler daha sonra rekombinasyona ve mutasyona uğrar (doğal genetikte olduğu gibi), yeni çocuklar üretir ve süreç çeşitli nesiller için tekrarlanır. Her bir bireye (veya aday çözüme) bir uygunluk değeri (hedef işlev değerine bağlı olarak) atanır ve uygun kişilere çiftleşme ve verim için daha yüksek bir şans verilir.fitterbireyler. Bu, Darvvinci Teori ile uyumludur.Survival of the Fittest.
Böylece tutar evolving durdurma kriterine ulaşana kadar nesiller boyunca daha iyi bireyler veya çözümler.
Genetik Algoritmalar, doğaları gereği yeterince rasgeleleştirilmiştir, ancak tarihsel bilgileri de kullandıkları için rasgele yerel aramadan çok daha iyi performans gösterirler (rastgele çözümler denediğimiz, şimdiye kadarki en iyiyi takip ettiğimiz).
Optimizasyon Sorunları için GA Nasıl Kullanılır?
Optimizasyon, tasarımı, durumu, kaynağı ve sistemi olabildiğince etkili hale getirme eylemidir. Aşağıdaki blok diyagram optimizasyon sürecini göstermektedir -

Optimizasyon süreci için GA mekanizmasının aşamaları
Aşağıda, problemlerin optimizasyonu için kullanıldığında GA mekanizmasının bir dizi adımları verilmiştir.
Adım 1 - İlk popülasyonu rastgele oluşturun.
Adım 2 - En iyi uygunluk değerlerine sahip ilk çözümü seçin.
Adım 3 - Mutasyon ve çaprazlama operatörlerini kullanarak seçilen çözümleri yeniden birleştirin.
Adım 4 - Nüfusa bir yavru ekleyin.
Adım 5 - Şimdi, durdurma koşulu karşılanırsa, çözümü en iyi uygunluk değeriyle iade edin. Aksi takdirde 2. adıma gidin.
Gerekli Paketleri Kurmak
Python'da Genetik Algoritmalar kullanarak sorunu çözmek için, GA için güçlü bir paket kullanacağız. DEAP. Fikirlerin hızlı prototiplenmesi ve test edilmesi için yeni evrimsel hesaplama çerçevesinin bir kütüphanesidir. Bu paketi, komut isteminde aşağıdaki komutun yardımıyla kurabiliriz -
pip install deapEğer kullanıyorsanız anaconda ortam, daha sonra deap'i yüklemek için aşağıdaki komut kullanılabilir -
conda install -c conda-forge deapGenetik Algoritmaları Kullanan Çözümleri Uygulama
Bu bölüm size Genetik Algoritmaları kullanan çözümlerin uygulanmasını açıklamaktadır.
Bit desenleri oluşturma
Aşağıdaki örnek, 15 tane içeren bir bit dizesinin nasıl oluşturulacağını gösterir. One Max sorun.
Gerekli paketleri gösterildiği gibi içe aktarın -
import random
from deap import base, creator, toolsDeğerlendirme işlevini tanımlayın. Genetik bir algoritma oluşturmanın ilk adımıdır.
def eval_func(individual):
target_sum = 15
return len(individual) - abs(sum(individual) - target_sum),Şimdi, doğru parametrelerle araç kutusunu oluşturun -
def create_toolbox(num_bits):
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)Araç kutusunu başlatın
toolbox = base.Toolbox()
toolbox.register("attr_bool", random.randint, 0, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual,
toolbox.attr_bool, num_bits)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)Değerlendirme operatörünü kaydedin -
toolbox.register("evaluate", eval_func)Şimdi, geçiş operatörünü kaydedin -
toolbox.register("mate", tools.cxTwoPoint)Bir mutasyon operatörü kaydedin -
toolbox.register("mutate", tools.mutFlipBit, indpb = 0.05)Yetiştirme için operatörü tanımlayın -
toolbox.register("select", tools.selTournament, tournsize = 3)
return toolbox
if __name__ == "__main__":
num_bits = 45
toolbox = create_toolbox(num_bits)
random.seed(7)
population = toolbox.population(n = 500)
probab_crossing, probab_mutating = 0.5, 0.2
num_generations = 10
print('\nEvolution process starts')Tüm popülasyonu değerlendirin -
fitnesses = list(map(toolbox.evaluate, population))
for ind, fit in zip(population, fitnesses):
ind.fitness.values = fit
print('\nEvaluated', len(population), 'individuals')Nesiller boyunca oluşturun ve yineleyin -
for g in range(num_generations):
print("\n- Generation", g)Yeni nesil bireyleri seçmek -
offspring = toolbox.select(population, len(population))Şimdi, seçilen kişileri klonlayın -
offspring = list(map(toolbox.clone, offspring))Yavrulara çaprazlama ve mutasyon uygulayın -
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < probab_crossing:
toolbox.mate(child1, child2)Çocuğun fitness değerini silin
del child1.fitness.values
del child2.fitness.valuesŞimdi, mutasyonu uygulayın -
for mutant in offspring:
if random.random() < probab_mutating:
toolbox.mutate(mutant)
del mutant.fitness.valuesUygunluğu geçersiz olan bireyleri değerlendirin -
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
print('Evaluated', len(invalid_ind), 'individuals')Şimdi, nüfusu yeni nesil bireyle değiştirin -
population[:] = offspringMevcut nesiller için istatistikleri yazdırın -
fits = [ind.fitness.values[0] for ind in population]
length = len(population)
mean = sum(fits) / length
sum2 = sum(x*x for x in fits)
std = abs(sum2 / length - mean**2)**0.5
print('Min =', min(fits), ', Max =', max(fits))
print('Average =', round(mean, 2), ', Standard deviation =',
round(std, 2))
print("\n- Evolution ends")Son çıktıyı yazdırın -
best_ind = tools.selBest(population, 1)[0]
print('\nBest individual:\n', best_ind)
print('\nNumber of ones:', sum(best_ind))
Following would be the output:
Evolution process starts
Evaluated 500 individuals
- Generation 0
Evaluated 295 individuals
Min = 32.0 , Max = 45.0
Average = 40.29 , Standard deviation = 2.61
- Generation 1
Evaluated 292 individuals
Min = 34.0 , Max = 45.0
Average = 42.35 , Standard deviation = 1.91
- Generation 2
Evaluated 277 individuals
Min = 37.0 , Max = 45.0
Average = 43.39 , Standard deviation = 1.46
… … … …
- Generation 9
Evaluated 299 individuals
Min = 40.0 , Max = 45.0
Average = 44.12 , Standard deviation = 1.11
- Evolution ends
Best individual:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1,
1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0,
1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1]
Number of ones: 15Sembol Regresyon Problemi
Genetik programlamada bilinen en iyi problemlerden biridir. Tüm sembolik regresyon problemleri, rastgele bir veri dağılımı kullanır ve en doğru verileri sembolik bir formülle uydurmaya çalışır. Genellikle, bir bireyin uygunluğunu ölçmek için RMSE (Ortalama Karekök Hata) gibi bir ölçü kullanılır. Bu klasik bir regresör problemidir ve burada denklemi kullanıyoruz5x3-6x2+8x=1. Yukarıdaki örnekte takip edilen tüm adımları izlemeliyiz, ancak asıl kısım ilkel kümeleri oluşturmak olacaktır çünkü bunlar bireyler için yapı taşlarıdır, böylece değerlendirme başlayabilir. Burada klasik ilkelleri kullanacağız.
Aşağıdaki Python kodu bunu ayrıntılı olarak açıklamaktadır -
import operator
import math
import random
import numpy as np
from deap import algorithms, base, creator, tools, gp
def division_operator(numerator, denominator):
if denominator == 0:
return 1
return numerator / denominator
def eval_func(individual, points):
func = toolbox.compile(expr=individual)
return math.fsum(mse) / len(points),
def create_toolbox():
pset = gp.PrimitiveSet("MAIN", 1)
pset.addPrimitive(operator.add, 2)
pset.addPrimitive(operator.sub, 2)
pset.addPrimitive(operator.mul, 2)
pset.addPrimitive(division_operator, 2)
pset.addPrimitive(operator.neg, 1)
pset.addPrimitive(math.cos, 1)
pset.addPrimitive(math.sin, 1)
pset.addEphemeralConstant("rand101", lambda: random.randint(-1,1))
pset.renameArguments(ARG0 = 'x')
creator.create("FitnessMin", base.Fitness, weights = (-1.0,))
creator.create("Individual",gp.PrimitiveTree,fitness=creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register("expr", gp.genHalfAndHalf, pset=pset, min_=1, max_=2)
toolbox.expr)
toolbox.register("population",tools.initRepeat,list, toolbox.individual)
toolbox.register("compile", gp.compile, pset = pset)
toolbox.register("evaluate", eval_func, points = [x/10. for x in range(-10,10)])
toolbox.register("select", tools.selTournament, tournsize = 3)
toolbox.register("mate", gp.cxOnePoint)
toolbox.register("expr_mut", gp.genFull, min_=0, max_=2)
toolbox.register("mutate", gp.mutUniform, expr = toolbox.expr_mut, pset = pset)
toolbox.decorate("mate", gp.staticLimit(key = operator.attrgetter("height"), max_value = 17))
toolbox.decorate("mutate", gp.staticLimit(key = operator.attrgetter("height"), max_value = 17))
return toolbox
if __name__ == "__main__":
random.seed(7)
toolbox = create_toolbox()
population = toolbox.population(n = 450)
hall_of_fame = tools.HallOfFame(1)
stats_fit = tools.Statistics(lambda x: x.fitness.values)
stats_size = tools.Statistics(len)
mstats = tools.MultiStatistics(fitness=stats_fit, size = stats_size)
mstats.register("avg", np.mean)
mstats.register("std", np.std)
mstats.register("min", np.min)
mstats.register("max", np.max)
probab_crossover = 0.4
probab_mutate = 0.2
number_gen = 10
population, log = algorithms.eaSimple(population, toolbox,
probab_crossover, probab_mutate, number_gen,
stats = mstats, halloffame = hall_of_fame, verbose = True)Bit desenleri oluştururken tüm temel adımların aynı olduğuna dikkat edin. Bu program bize çıktıyı 10 nesilden sonra min, max, std (standart sapma) olarak verecektir.
Bilgisayar görüşü, bilgisayar yazılımı ve donanımı kullanarak insan görüşünün modellenmesi ve kopyalanmasıyla ilgilidir. Bu bölümde bunun hakkında detaylı bilgi edineceksiniz.
Bilgisayar görüşü
Bilgisayar görüşü, sahnede bulunan yapının özellikleri açısından bir 3 boyutlu sahnenin 2 boyutlu görüntülerinden nasıl yeniden yapılandırılacağını, kesileceğini ve anlaşılacağını inceleyen bir disiplindir.
Bilgisayarla Görme Hiyerarşisi
Bilgisayar görüşü aşağıdaki gibi üç temel kategoriye ayrılmıştır:
Low-level vision - Özellik çıkarma için işlem görüntüsü içerir.
Intermediate-level vision - Nesne tanıma ve 3B sahne yorumunu içerir
High-level vision - Etkinlik, niyet ve davranış gibi bir sahnenin kavramsal tanımını içerir.
Computer Vision Vs Görüntü İşleme
Görüntü işleme, görüntüden görüntüye dönüşümünü inceler. Görüntü işlemenin girdisi ve çıktısı her iki görüntüdür.
Bilgisayar görüşü, fiziksel nesnelerin görüntülerinden açık, anlamlı tanımlamalarının oluşturulmasıdır. Bilgisayarla görmenin çıktısı, 3B sahnedeki yapıların açıklaması veya yorumudur.
Uygulamalar
Bilgisayar görüşü aşağıdaki alanlarda uygulama bulur -
Robotics
Yerelleştirme-robot konumunu otomatik olarak belirle
Navigation
Engellerden kaçınma
Montaj (delik içi, kaynak, boyama)
Manipülasyon (örneğin PUMA robot manipülatörü)
İnsan Robot Etkileşimi (HRI): İnsanlarla etkileşimde bulunmak ve insanlara hizmet etmek için akıllı robotik
Medicine
Sınıflandırma ve tespit (örn. Lezyon veya hücre sınıflandırması ve tümör tespiti)
2D / 3D segmentasyon
3D insan organı rekonstrüksiyonu (MRI veya ultrason)
Görme kılavuzlu robotik cerrahi
Security
- Biyometri (iris, parmak izi, yüz tanıma)
- Belirli şüpheli etkinlikleri veya davranışları gözetimle tespit etme
Transportation
- Otonom araç
- Güvenlik, örneğin sürücü dikkat izleme
Industrial Automation Application
- Endüstriyel muayene (kusur tespiti)
- Assembly
- Barkod ve paket etiketi okuma
- Nesne sıralama
- Belgenin anlaşılması (örneğin OCR)
Yararlı Paketleri Kurmak
Python ile Bilgisayar görüşü için, adlı popüler bir kitaplığı kullanabilirsiniz. OpenCV(Açık Kaynak Bilgisayarla Görme). Esas olarak gerçek zamanlı bilgisayar görüşünü hedefleyen bir programlama işlevleri kütüphanesidir. C ++ ile yazılmıştır ve birincil arayüzü C ++ 'dadır. Bu paketi aşağıdaki komutun yardımıyla kurabilirsiniz -
pip install opencv_python-X.X-cp36-cp36m-winX.whlBurada X, makinenizde yüklü olan Python sürümünü ve sahip olduğunuz win32 veya 64 bit'i temsil eder.
Eğer kullanıyorsanız anaconda ortam, ardından OpenCV'yi yüklemek için aşağıdaki komutu kullanın -
conda install -c conda-forge opencvBir Resmi Okuma, Yazma ve Görüntüleme
CV uygulamalarının çoğu görüntüleri girdi olarak alıp çıktı olarak üretmelidir. Bu bölümde, OpenCV tarafından sağlanan işlevler yardımıyla görüntü dosyasını nasıl okuyup yazacağınızı öğreneceksiniz.
Bir Görüntü Dosyasını Okumak, Göstermek, Yazmak için OpenCV işlevleri
OpenCV, bu amaç için aşağıdaki işlevleri sağlar -
imread() function- Bu, bir görüntüyü okumak için kullanılan işlevdir. OpenCV imread (), PNG, JPEG, JPG, TIFF vb. Gibi çeşitli resim formatlarını destekler.
imshow() function- Bu, bir pencerede bir görüntüyü gösterme işlevidir. Pencere otomatik olarak görüntü boyutuna sığar. OpenCV imshow (), PNG, JPEG, JPG, TIFF vb. Gibi çeşitli görüntü formatlarını destekler.
imwrite() function- Bu, bir görüntü yazma işlevidir. OpenCV imwrite (), PNG, JPEG, JPG, TIFF vb. Gibi çeşitli resim formatlarını destekler.
Misal
Bu örnek, bir görüntüyü tek bir biçimde okumak için Python kodunu gösterir - onu bir pencerede göstermek ve aynı görüntüyü başka bir biçimde yazmak. Aşağıda gösterilen adımları düşünün -
OpenCV paketini gösterildiği gibi içe aktarın -
import cv2Şimdi, belirli bir görüntüyü okumak için imread () işlevini kullanın -
image = cv2.imread('image_flower.jpg')Resmi göstermek için şunu kullanın: imshow()işlevi. Görüntüyü görebileceğiniz pencerenin adı,image_flower.
cv2.imshow('image_flower',image)
cv2.destroyAllwindows()
Şimdi, aynı görüntüyü diğer biçime, örneğin .png imwrite () işlevini kullanarak yazabiliriz -
cv2.imwrite('image_flower.png',image)True çıktısı, görüntünün .png dosyası olarak aynı klasöre başarıyla yazıldığı anlamına gelir.
TrueNot - destroyallWindows () işlevi basitçe oluşturduğumuz tüm pencereleri yok eder.
Renk Uzayı Dönüşümü
OpenCV'de, görüntüler geleneksel RGB rengi kullanılarak depolanmaz, bunun yerine ters sırada yani BGR düzeninde depolanırlar. Bu nedenle, bir görüntüyü okurken varsayılan renk kodu BGR'dir. cvtColor() Görüntüyü bir renk kodundan diğerine dönüştürmek için renk dönüştürme işlevi.
Misal
Görüntüyü BGR'den gri tonlamaya dönüştürmek için bu örneği düşünün.
İçe aktar OpenCV gösterildiği gibi paket -
import cv2Şimdi, belirli bir görüntüyü okumak için imread () işlevini kullanın -
image = cv2.imread('image_flower.jpg')Şimdi, bu resmi kullandığımızı görürsek imshow() fonksiyon, o zaman bu görüntünün BGR'de olduğunu görebiliriz.
cv2.imshow('BGR_Penguins',image)
Şimdi kullan cvtColor() bu görüntüyü gri tonlamaya dönüştürme işlevi.
image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray_penguins',image)
Kenar algılama
İnsanlar kaba bir taslağı gördükten sonra birçok nesne türünü ve pozlarını kolayca tanıyabilir. Bu nedenle kenarlar, insan yaşamında ve bilgisayarla görü uygulamalarında önemli bir rol oynamaktadır. OpenCV, çok basit ve kullanışlı bir işlev sağlar.Canny()kenarları tespit etmek için.
Misal
Aşağıdaki örnek, kenarların net bir şekilde tanımlanmasını göstermektedir.
OpenCV paketini gösterildiği gibi içe aktarın -
import cv2
import numpy as npŞimdi, belirli bir resmi okumak için, imread() işlevi.
image = cv2.imread('Penguins.jpg')Şimdi kullanın Canny () önceden okunan görüntünün kenarlarını algılama işlevi.
cv2.imwrite(‘edges_Penguins.jpg’,cv2.Canny(image,200,300))Şimdi, görüntüyü kenarlı göstermek için imshow () işlevini kullanın.
cv2.imshow(‘edges’, cv2.imread(‘‘edges_Penguins.jpg’))Bu Python programı adlı bir görüntü oluşturacak edges_penguins.jpg kenar algılama ile.

Yüz tanıma
Yüz algılama, bilgisayar görüşünün büyüleyici uygulamalarından biridir ve bu da onu daha gerçekçi ve fütüristik kılar. OpenCV, yüz algılama gerçekleştirmek için yerleşik bir tesise sahiptir. KullanacağızHaar yüz algılama için kademeli sınıflandırıcı.
Haar Basamaklama Verileri
Haar kademeli sınıflandırıcıyı kullanmak için verilere ihtiyacımız var. Bu verileri OpenCV paketimizde bulabilirsiniz. OpenCv'yi kurduktan sonra klasör adını görebilirsiniz.haarcascades. Farklı uygulamalar için .xml dosyaları olacaktır. Şimdi, hepsini farklı kullanım için kopyalayın ve ardından mevcut projenin altındaki yeni bir klasöre yapıştırın.
Example
Aşağıdaki resimde gösterilen Amitabh Bachan'ın yüzünü algılamak için Haar Cascade kullanan Python kodu aşağıdadır -

İçe aktar OpenCV gösterildiği gibi paket -
import cv2
import numpy as npŞimdi kullanın HaarCascadeClassifier yüzü tespit etmek için -
face_detection=
cv2.CascadeClassifier('D:/ProgramData/cascadeclassifier/
haarcascade_frontalface_default.xml')Şimdi, belirli bir resmi okumak için, imread() işlev -
img = cv2.imread('AB.jpg')Şimdi, gri tonlamaya dönüştürün çünkü gri görüntüleri kabul eder -
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)Şimdi, kullanarak face_detection.detectMultiScale, gerçek yüz algılama gerçekleştir
faces = face_detection.detectMultiScale(gray, 1.3, 5)Şimdi, tüm yüzün etrafına bir dikdörtgen çizin -
for (x,y,w,h) in faces:
img = cv2.rectangle(img,(x,y),(x+w, y+h),(255,0,0),3)
cv2.imwrite('Face_AB.jpg',img)Bu Python programı adlı bir görüntü oluşturacak Face_AB.jpg gösterildiği gibi yüz algılama ile

Göz Algılama
Göz algılama, bilgisayar görüşünün bir başka büyüleyici uygulamasıdır ve bu da onu daha gerçekçi ve fütüristik kılar. OpenCV, göz algılama gerçekleştirmek için yerleşik bir tesise sahiptir. KullanacağızHaar cascade göz algılama için sınıflandırıcı.
Misal
Aşağıdaki örnek, aşağıdaki resimde verilen Amitabh Bachan'ın yüzünü algılamak için Haar Cascade kullanan Python kodunu verir -

OpenCV paketini gösterildiği gibi içe aktarın -
import cv2
import numpy as npŞimdi kullanın HaarCascadeClassifier yüzü tespit etmek için -
eye_cascade = cv2.CascadeClassifier('D:/ProgramData/cascadeclassifier/haarcascade_eye.xml')Şimdi, belirli bir resmi okumak için, imread() işlevi
img = cv2.imread('AB_Eye.jpg')Şimdi, gri tonlamaya dönüştürün çünkü gri görüntüleri kabul eder -
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)Şimdi yardımıyla eye_cascade.detectMultiScale, gerçek yüz algılama gerçekleştir
eyes = eye_cascade.detectMultiScale(gray, 1.03, 5)Şimdi, tüm yüzün etrafına bir dikdörtgen çizin -
for (ex,ey,ew,eh) in eyes:
img = cv2.rectangle(img,(ex,ey),(ex+ew, ey+eh),(0,255,0),2)
cv2.imwrite('Eye_AB.jpg',img)Bu Python programı adlı bir görüntü oluşturacak Eye_AB.jpg gösterildiği gibi göz algılama ile -

Yapay Sinir Ağı (YSA), ana teması biyolojik sinir ağları analojisinden ödünç alınan verimli bir bilgi işlem sistemidir. Yapay sinir ağları, makine öğrenimi için bir tür modeldir. 1980'lerin ortasında ve 1990'ların başında, sinir ağlarında çok önemli mimari ilerlemeler kaydedildi. Bu bölümde, bir AI yaklaşımı olan Derin Öğrenme hakkında daha fazla bilgi edineceksiniz.
Derin öğrenme, sahada ciddi bir rakip olarak on yıllık patlayıcı hesaplama büyümesinden ortaya çıktı. Bu nedenle, derin öğrenme, algoritmaları insan beyninin yapısından ve işlevinden ilham alan belirli bir makine öğrenimidir.
Makine Öğrenimi v / s Derin Öğrenme
Derin öğrenme, bugünlerde en güçlü makine öğrenimi tekniğidir. O kadar güçlü ki, problemi nasıl çözeceklerini öğrenirken problemi temsil etmenin en iyi yolunu öğreniyorlar. Derin öğrenme ve Makine öğreniminin bir karşılaştırması aşağıda verilmiştir -
Veri Bağımlılığı
İlk fark noktası, veri ölçeği arttığında DL ve ML performansına dayanmaktadır. Veriler büyük olduğunda, derin öğrenme algoritmaları çok iyi performans gösterir.
Makine Bağımlılığı
Derin öğrenme algoritmalarının mükemmel çalışması için son teknoloji makinelere ihtiyacı vardır. Öte yandan, makine öğrenimi algoritmaları düşük kaliteli makinelerde de çalışabilir.
Özellik çıkarma
Derin öğrenme algoritmaları, yüksek seviyeli özellikleri çıkarabilir ve aynı şekilde öğrenmeye de çalışabilir. Öte yandan, makine öğrenimi ile çıkarılan özelliklerin çoğunu belirlemek için bir uzmanın olması gerekir.
Yürütme Zamanı
Yürütme süresi, bir algoritmada kullanılan çok sayıda parametreye bağlıdır. Derin öğrenmenin, makine öğrenimi algoritmalarından daha fazla parametresi vardır. Dolayısıyla, DL algoritmalarının çalıştırılma süresi, özellikle eğitim süresi, ML algoritmalarından çok daha fazladır. Ancak DL algoritmalarının test süresi, ML algoritmalarından daha azdır.
Problem Çözme Yaklaşımı
Derin öğrenme, problemi uçtan uca çözerken, makine öğrenimi problemi çözmek için geleneksel yöntemi kullanır, yani parçalara ayırarak.
Evrişimli Sinir Ağı (CNN)
Evrişimli sinir ağları, sıradan sinir ağları ile aynıdır çünkü bunlar aynı zamanda öğrenilebilir ağırlıklara ve önyargılara sahip nöronlardan oluşur. Sıradan sinir ağları, giriş verilerinin yapısını görmezden gelir ve tüm veriler, ağa beslenmeden önce 1 boyutlu diziye dönüştürülür. Bu işlem, normal verilere uygundur, ancak veriler görüntü içeriyorsa, işlem zahmetli olabilir.
CNN bu sorunu kolayca çözer. Görüntülerin 2D yapısını işlerken hesaba katarak görüntülere özgü özellikleri çıkarmalarına olanak tanır. Böylelikle CNN'lerin temel amacı, girdi katmanındaki ham görüntü verilerinden çıktı katmanında doğru sınıfa gitmektir. Sıradan bir NN'ler ile CNN'ler arasındaki tek fark, giriş verilerinin işlenmesinde ve katman tiplerindedir.
CNN'lerin Mimarisine Genel Bakış
Mimari olarak, sıradan sinir ağları bir girdi alır ve onu bir dizi gizli katman aracılığıyla dönüştürür. Her katman, nöronlar yardımıyla diğer katmana bağlanır. Sıradan sinir ağlarının temel dezavantajı, tam görüntülere iyi ölçeklenmemeleridir.
CNN'lerin mimarisi, genişlik, yükseklik ve derinlik olarak adlandırılan 3 boyutta düzenlenmiş nöronlara sahiptir. Mevcut katmandaki her nöron, önceki katmandan gelen çıktının küçük bir parçasına bağlanır. Üst üste bindirmeye benzer×giriş görüntüsünde filtre. KullanırMtüm ayrıntıları aldığınızdan emin olmak için filtreler. BunlarM filtreler, kenarlar, köşeler vb. gibi özellikleri çıkaran özellik çıkarıcılardır.
CNN'leri oluşturmak için kullanılan katmanlar
CNN'leri oluşturmak için aşağıdaki katmanlar kullanılır -
Input Layer - Ham görüntü verilerini olduğu gibi alır.
Convolutional Layer- Bu katman, hesaplamaların çoğunu yapan CNN'lerin temel yapı taşıdır. Bu katman, girişteki nöronlar ve çeşitli yamalar arasındaki kıvrımları hesaplar.
Rectified Linear Unit Layer- Önceki katmanın çıktısına bir aktivasyon işlevi uygular. Ağa doğrusal olmayanlık ekler, böylece herhangi bir işleve iyi bir şekilde genellenebilir.
Pooling Layer- Havuzlama, ağda ilerlerken yalnızca önemli parçaları tutmamıza yardımcı olur. Havuzlama katmanı, girdinin her derinlik diliminde bağımsız olarak çalışır ve onu uzamsal olarak yeniden boyutlandırır. MAX işlevini kullanır.
Fully Connected layer/Output layer - Bu katman, son katmandaki çıktı puanlarını hesaplar. Ortaya çıkan çıktı şu boyuttadır×× , burada L, sayı eğitim veri kümesi sınıflarıdır.
Yararlı Python Paketlerini Yükleme
Kullanabilirsiniz KerasPython'da yazılmış ve TensorFlow, CNTK veya Theno üzerinde çalışabilen üst düzey bir sinir ağları API'si olan. Python 2.7-3.6 ile uyumludur. Bunun hakkında daha fazla bilgi edinebilirsiniz.https://keras.io/.
Keras'ı kurmak için aşağıdaki komutları kullanın -
pip install kerasAçık conda ortam, aşağıdaki komutu kullanabilirsiniz -
conda install –c conda-forge kerasYSA kullanarak Doğrusal Regresör Oluşturma
Bu bölümde, yapay sinir ağlarını kullanarak bir doğrusal regresörün nasıl oluşturulacağını öğreneceksiniz. KullanabilirsinizKerasRegressorBunu başarmak için. Bu örnekte, Boston'daki mülkler için 13 sayısal Boston ev fiyatı veri kümesini kullanıyoruz. Aynısı için Python kodu burada gösterilmektedir -
Gerekli tüm paketleri gösterildiği gibi içe aktarın -
import numpy
import pandas
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFoldŞimdi, yerel dizine kaydedilen veri setimizi yükleyin.
dataframe = pandas.read_csv("/Usrrs/admin/data.csv", delim_whitespace = True, header = None)
dataset = dataframe.valuesŞimdi, verileri giriş ve çıkış değişkenlerine bölün, yani X ve Y -
X = dataset[:,0:13]
Y = dataset[:,13]Temel sinir ağlarını kullandığımız için modeli tanımlayın -
def baseline_model():Şimdi modeli aşağıdaki gibi oluşturun -
model_regressor = Sequential()
model_regressor.add(Dense(13, input_dim = 13, kernel_initializer = 'normal',
activation = 'relu'))
model_regressor.add(Dense(1, kernel_initializer = 'normal'))Ardından modeli derleyin -
model_regressor.compile(loss='mean_squared_error', optimizer='adam')
return model_regressorŞimdi, tekrarlanabilirlik için rastgele tohumu aşağıdaki gibi düzeltin -
seed = 7
numpy.random.seed(seed)Keras sarmalayıcı nesnesi scikit-learn regresyon tahmincisi olarak adlandırılır KerasRegressor. Bu bölümde bu modeli standartlaştırılmış veri seti ile değerlendireceğiz.
estimator = KerasRegressor(build_fn = baseline_model, nb_epoch = 100, batch_size = 5, verbose = 0)
kfold = KFold(n_splits = 10, random_state = seed)
baseline_result = cross_val_score(estimator, X, Y, cv = kfold)
print("Baseline: %.2f (%.2f) MSE" % (Baseline_result.mean(),Baseline_result.std()))Yukarıda gösterilen kodun çıktısı, modelin görünmeyen veriler için problem üzerindeki performansının tahmini olacaktır. Çapraz doğrulama değerlendirmesinin tüm 10 katındaki ortalama ve standart sapma dahil olmak üzere ortalama kare hatası olacaktır.
Görüntü Sınıflandırıcı: Derin Öğrenme Uygulaması
Evrişimli Sinir Ağları (CNN'ler), bir görüntü sınıflandırma problemini, yani girdi görüntüsünün hangi sınıfa ait olduğunu çözer. Keras derin öğrenme kitaplığını kullanabilirsiniz. Aşağıdaki bağlantıdaki kedi ve köpeklerin eğitim ve test veri setini kullandığımızı unutmayın.https://www.kaggle.com/c/dogs-vs-cats/data.
Önemli keras kitaplıklarını ve paketlerini gösterildiği gibi içe aktarın -
Sıralı olarak adlandırılan aşağıdaki paket, sinir ağlarını sıralı ağ olarak başlatacaktır.
from keras.models import SequentialAşağıdaki paket aradı Conv2D CNN'nin ilk adımı olan evrişim işlemini gerçekleştirmek için kullanılır.
from keras.layers import Conv2DAşağıdaki paket aradı MaxPoling2D CNN'nin ikinci adımı olan havuzlama işlemini gerçekleştirmek için kullanılır.
from keras.layers import MaxPooling2DAşağıdaki paket aradı Flatten elde edilen tüm 2B dizileri tek bir uzun sürekli doğrusal vektöre dönüştürme işlemidir.
from keras.layers import FlattenAşağıdaki paket aradı Dense CNN'in dördüncü adımı olan sinir ağının tam bağlantısını gerçekleştirmek için kullanılır.
from keras.layers import DenseŞimdi, sıralı sınıfın bir nesnesini oluşturun.
S_classifier = Sequential()Şimdi, bir sonraki adım evrişim kısmını kodlamaktır.
S_classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))Buraya relu doğrultucu işlevidir.
Şimdi, CNN'nin bir sonraki adımı, evrişim kısmından sonra ortaya çıkan özellik haritalarında havuzlama işlemidir.
S-classifier.add(MaxPooling2D(pool_size = (2, 2)))Şimdi, tüm havuzlanmış görüntüleri iltifat kullanarak sürekli bir vektöre dönüştürün -
S_classifier.add(Flatten())Ardından, tamamen bağlantılı bir katman oluşturun.
S_classifier.add(Dense(units = 128, activation = 'relu'))Burada 128 gizli birimlerin sayısıdır. Gizli birimlerin sayısını 2'nin gücü olarak tanımlamak yaygın bir uygulamadır.
Şimdi çıktı katmanını aşağıdaki gibi başlatın -
S_classifier.add(Dense(units = 1, activation = 'sigmoid'))Şimdi, CNN'yi derleyin, biz inşa ettik -
S_classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])Burada optimizer parametresi, stokastik gradyan iniş algoritmasını seçmektir, kayıp parametresi, kayıp fonksiyonunu seçmektir ve metrik parametresi, performans metriğini seçmektir.
Şimdi, görüntü büyütme işlemleri gerçekleştirin ve ardından görüntüleri sinir ağlarına yerleştirin -
train_datagen = ImageDataGenerator(rescale = 1./255,shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
training_set =
train_datagen.flow_from_directory(”/Users/admin/training_set”,target_size =
(64, 64),batch_size = 32,class_mode = 'binary')
test_set =
test_datagen.flow_from_directory('test_set',target_size =
(64, 64),batch_size = 32,class_mode = 'binary')Şimdi, verileri oluşturduğumuz modele uydurun -
classifier.fit_generator(training_set,steps_per_epoch = 8000,epochs =
25,validation_data = test_set,validation_steps = 2000)Burada steps_per_epoch, eğitim görüntülerinin sayısına sahiptir.
Şimdi model eğitildiği için, onu aşağıdaki gibi tahmin için kullanabiliriz -
from keras.preprocessing import image
test_image = image.load_img('dataset/single_prediction/cat_or_dog_1.jpg',
target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
if result[0][0] == 1:
prediction = 'dog'
else:
prediction = 'cat'