Python ile AI - Konuşma Tanıma
Bu bölümde, Python ile AI kullanarak konuşma tanıma hakkında bilgi edineceğiz.
Konuşma, yetişkin insan iletişiminin en temel yoludur. Konuşma işlemenin temel amacı, bir insan ve bir makine arasında bir etkileşim sağlamaktır.
Konuşma işleme sisteminin başlıca üç görevi vardır -
First, makinenin konuştuğumuz kelimeleri, cümleleri ve cümleleri yakalamasını sağlayan konuşma tanıma
Second, makinenin ne konuştuğumuzu anlamasını sağlamak için doğal dil işleme ve
Thirdmakinenin konuşmasını sağlamak için konuşma sentezi.
Bu bölüm, speech recognitioninsanoğlunun söylediği kelimeleri anlama süreci. Konuşma sinyallerinin bir mikrofon yardımıyla yakalandığını ve daha sonra sistem tarafından anlaşılması gerektiğini unutmayın.
Konuşma Tanıyıcı Oluşturma
Konuşma Tanıma veya Otomatik Konuşma Tanıma (ASR), robotik gibi yapay zeka projelerinin ilgi odağıdır. ASR olmadan, bir insanla etkileşime giren bir bilişsel robot hayal etmek mümkün değildir. Bununla birlikte, bir konuşma tanıyıcı oluşturmak pek de kolay değildir.
Bir konuşma tanıma sistemi geliştirmedeki zorluklar
Yüksek kaliteli bir konuşma tanıma sistemi geliştirmek gerçekten zor bir sorundur. Konuşma tanıma teknolojisinin zorluğu, aşağıda tartışıldığı gibi bir dizi boyutta genel olarak karakterize edilebilir -
Size of the vocabulary- Sözcük dağarcığının boyutu, ASR geliştirme kolaylığını etkiler. Daha iyi anlamak için aşağıdaki kelime dağarcığını düşünün.
Küçük boyutlu bir kelime dağarcığı, örneğin bir sesli menü sisteminde olduğu gibi 2-100 kelimeden oluşur.
Orta büyüklükte bir kelime dağarcığı, örneğin bir veritabanı alma görevinde olduğu gibi, birkaç 100 ila 1000 kelimeden oluşur.
Büyük boyutlu bir kelime dağarcığı, genel bir dikte görevinde olduğu gibi birkaç 10.000 kelimeden oluşur.
Channel characteristics- Kanal kalitesi de önemli bir boyuttur. Örneğin, insan konuşması tam frekans aralığı ile yüksek bant genişliği içerirken, bir telefon konuşması sınırlı frekans aralığı ile düşük bant genişliğinden oluşur. İkincisinin daha zor olduğuna dikkat edin.
Speaking mode- Bir ASR geliştirme kolaylığı aynı zamanda konuşma moduna, yani konuşmanın izole kelime modunda mı yoksa bağlantılı kelime modunda mı yoksa sürekli konuşma modunda mı olduğuna bağlıdır. Kesintisiz bir konuşmanın tanınmasının daha zor olduğunu unutmayın.
Speaking style- Bir okuma konuşması resmi bir tarzda veya spontane ve gündelik bir tarzda sohbetsel olabilir. İkincisini tanımak daha zordur.
Speaker dependency- Konuşma konuşmacıya bağlı, konuşmacıya göre uyarlanabilir veya konuşmacıdan bağımsız olabilir. Bağımsız bir konuşmacı inşa etmesi en zor olanıdır.
Type of noise- Bir ASR geliştirirken göz önünde bulundurulması gereken başka bir faktör de gürültüdür. Arka plan gürültüsüne karşı daha az gürültü gözlemleyen akustik ortama bağlı olarak sinyal-gürültü oranı çeşitli aralıklarda olabilir -
Sinyal-gürültü oranı 30dB'den büyükse, yüksek aralık olarak kabul edilir
Sinyal-gürültü oranı 30dB ile 10db arasında ise, orta SNR olarak kabul edilir.
Sinyal-gürültü oranı 10dB'nin altındaysa, düşük aralık olarak kabul edilir
Microphone characteristics- Mikrofon kalitesi iyi, ortalama veya ortalamanın altında olabilir. Ayrıca ağız ile mikro telefon arasındaki mesafe değişebilir. Bu faktörler, tanıma sistemleri için de dikkate alınmalıdır.
Sözcük dağarcığının boyutu ne kadar büyükse, tanımayı gerçekleştirmenin o kadar zor olduğunu unutmayın.
Örneğin, sabit, insan dışı gürültü, arka plan konuşması ve diğer konuşmacılardan gelen parazit gibi arka plan gürültüsü de sorunun zorluğuna katkıda bulunur.
Bu zorluklara rağmen, araştırmacılar konuşma sinyalini, konuşmacıyı anlamak ve aksanları belirlemek gibi konuşmanın çeşitli yönleri üzerinde çok çalıştılar.
Bir konuşma tanıyıcı oluşturmak için aşağıda verilen adımları izlemeniz gerekecek -
Ses Sinyallerini Görselleştirme - Bir Dosyadan Okuma ve Üzerinde Çalışma
Bu, bir ses sinyalinin nasıl yapılandırıldığının anlaşılmasını sağladığı için konuşma tanıma sistemi oluşturmanın ilk adımıdır. Ses sinyalleriyle çalışmak için izlenebilecek bazı genel adımlar aşağıdaki gibidir -
Kayıt
Bir dosyadan ses sinyalini okumanız gerektiğinde, bunu önce bir mikrofon kullanarak kaydedin.
Örnekleme
Mikrofonla kayıt yapılırken sinyaller dijitalleştirilmiş bir biçimde saklanır. Ancak bunun üzerinde çalışmak için makinenin bunlara ayrı sayısal biçimde ihtiyacı var. Bu nedenle, belirli bir frekansta örnekleme yapmalı ve sinyali ayrı sayısal forma dönüştürmeliyiz. Örnekleme için yüksek frekansı seçmek, insanlar sinyali dinlediğinde, onu sürekli bir ses sinyali olarak hissettiklerini ima eder.
Misal
Aşağıdaki örnek, bir dosyada depolanan Python kullanarak bir ses sinyalini analiz etmek için aşamalı bir yaklaşımı gösterir. Bu ses sinyalinin frekansı 44.100 HZ'dir.
Gerekli paketleri burada gösterildiği gibi içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileŞimdi depolanan ses dosyasını okuyun. İki değer döndürecektir: örnekleme frekansı ve ses sinyali. Burada gösterildiği gibi, depolandığı ses dosyasının yolunu sağlayın -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Gösterilen komutları kullanarak ses sinyalinin örnekleme frekansı, sinyalin veri türü ve süresi gibi parametreleri görüntüleyin -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Bu adım, sinyali aşağıda gösterildiği gibi normalleştirmeyi içerir -
audio_signal = audio_signal / np.power(2, 15)Bu adımda, görselleştirmek için bu sinyalden ilk 100 değeri çıkarıyoruz. Bu amaçla aşağıdaki komutları kullanın -
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)Şimdi, aşağıda verilen komutları kullanarak sinyali görselleştirin -
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()Buradaki görüntüde gösterildiği gibi, yukarıdaki ses sinyali için çıkarılan verileri ve bir çıktı grafiğini görebilirsiniz.

Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 secondsSes Sinyalinin Karakterizasyonu: Frekans Alanına Dönüştürme
Bir ses sinyalinin karakterize edilmesi, zaman alanı sinyalinin frekans alanına dönüştürülmesini ve frekans bileşenlerinin anlaşılmasını içerir. Bu önemli bir adımdır çünkü sinyal hakkında birçok bilgi verir. Bu dönüşümü gerçekleştirmek için Fourier Dönüşümü gibi matematiksel bir araç kullanabilirsiniz.
Misal
Aşağıdaki örnek, bir dosyada depolanan Python kullanılarak sinyalin nasıl karakterize edileceğini adım adım gösterir. Burada Fourier Dönüşümü matematiksel aracını frekans alanına dönüştürmek için kullandığımıza dikkat edin.
Burada gösterildiği gibi gerekli paketleri içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileŞimdi depolanan ses dosyasını okuyun. İki değer döndürecektir: örnekleme frekansı ve ses sinyali. Buradaki komutta gösterildiği gibi, kaydedildiği ses dosyasının yolunu belirtin -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")Bu adımda, aşağıda verilen komutları kullanarak ses sinyalinin örnekleme frekansı, sinyalin veri türü ve süresi gibi parametreleri göstereceğiz -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Bu adımda, aşağıdaki komutta gösterildiği gibi sinyali normalleştirmemiz gerekiyor -
audio_signal = audio_signal / np.power(2, 15)Bu adım, sinyalin uzunluğunun ve yarı uzunluğunun çıkarılmasını içerir. Bunun için aşağıdaki komutları kullanın -
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)Şimdi, frekans alanına dönüştürmek için matematik araçlarını uygulamamız gerekiyor. Burada Fourier Dönüşümünü kullanıyoruz.
signal_frequency = np.fft.fft(audio_signal)Şimdi, frekans alanı sinyalinin normalizasyonunu yapın ve karesini alın -
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal
signal_frequency **= 2Ardından, frekans dönüştürülmüş sinyalin uzunluğunu ve yarım uzunluğunu çıkarın -
len_fts = len(signal_frequency)Fourier dönüştürülmüş sinyalin tek ve çift durum için ayarlanması gerektiğini unutmayın.
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2Şimdi, gücü desibel (dB) cinsinden çıkarın -
signal_power = 10 * np.log10(signal_frequency)X ekseni için frekansı kHz olarak ayarlayın -
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0Şimdi, sinyalin karakterizasyonunu aşağıdaki gibi görselleştirin -
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()Yukarıdaki kodun çıktı grafiğini aşağıdaki resimde gösterildiği gibi gözlemleyebilirsiniz -

Monoton Ses Sinyali Oluşturma
Şimdiye kadar gördüğünüz iki adım, sinyaller hakkında bilgi edinmek için önemlidir. Şimdi, ses sinyalini önceden tanımlanmış bazı parametrelerle oluşturmak istiyorsanız bu adım yararlı olacaktır. Bu adımın ses sinyalini bir çıktı dosyasına kaydedeceğini unutmayın.
Misal
Aşağıdaki örnekte, Python kullanarak bir dosyada saklanacak tek tonlu bir sinyal üreteceğiz. Bunun için aşağıdaki adımları atmanız gerekecek -
Gerekli paketleri gösterildiği gibi içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import writeÇıktı dosyasının kaydedilmesi gereken dosyayı sağlayın
output_file = 'audio_signal_generated.wav'Şimdi, seçtiğiniz parametreleri gösterildiği gibi belirtin -
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piBu adımda, gösterildiği gibi ses sinyali oluşturabiliriz -
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)Şimdi, ses dosyasını çıktı dosyasına kaydedin -
write(output_file, frequency_sampling, signal_scaled)Grafiğimiz için ilk 100 değeri gösterildiği gibi çıkarın -
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)Şimdi, üretilen ses sinyalini aşağıdaki gibi görselleştirin -
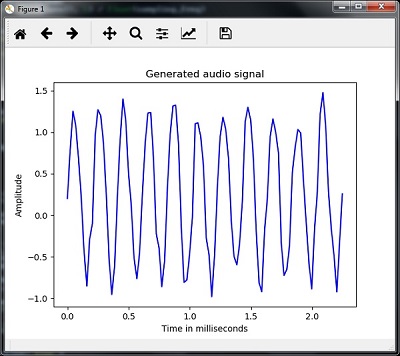
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()Grafiği, burada verilen şekilde gösterildiği gibi gözlemleyebilirsiniz -
Konuşmadan Özellik Çıkarma
Bu, bir konuşma tanıyıcı oluşturmanın en önemli adımıdır çünkü konuşma sinyalini frekans alanına dönüştürdükten sonra, onu kullanılabilir özellik vektörüne dönüştürmeliyiz. Bu amaçla MFCC, PLP, PLP-RASTA gibi farklı öznitelik çıkarma tekniklerini kullanabiliriz.
Misal
Aşağıdaki örnekte, MFCC tekniğini kullanarak Python kullanarak sinyalden özellikleri adım adım çıkaracağız.
Burada gösterildiği gibi gerekli paketleri içe aktarın -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbankŞimdi depolanan ses dosyasını okuyun. İki değer döndürecektir - örnekleme frekansı ve ses sinyali. Kaydedildiği ses dosyasının yolunu sağlayın.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Burada analiz için ilk 15000 numuneyi alıyoruz.
audio_signal = audio_signal[:15000]MFCC tekniklerini kullanın ve MFCC özelliklerini çıkarmak için aşağıdaki komutu yürütün -
features_mfcc = mfcc(audio_signal, frequency_sampling)Şimdi, gösterildiği gibi MFCC parametrelerini yazdırın -
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])Şimdi, aşağıda verilen komutları kullanarak MFCC özelliklerini çizin ve görselleştirin -
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')Bu adımda, gösterildiği gibi filtre bankası özellikleriyle çalışıyoruz -
Filtre bankası özelliklerini çıkarın -
filterbank_features = logfbank(audio_signal, frequency_sampling)Şimdi, filtre bankası parametrelerini yazdırın.
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])Şimdi, filtre bankası özelliklerini çizin ve görselleştirin.
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()Yukarıdaki adımların bir sonucu olarak, aşağıdaki çıktıları gözlemleyebilirsiniz: MFCC için Şekil 1 ve Filtre Bankası için Şekil2

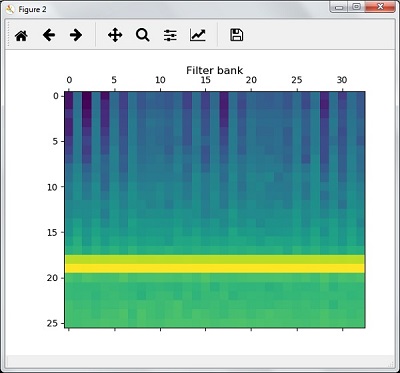
Sözlü Kelimelerin Tanınması
Konuşma tanıma, insanlar konuşurken bir makinenin onu anlaması anlamına gelir. Bunu gerçekleştirmek için Python'da Google Speech API kullanıyoruz. Bunun için aşağıdaki paketleri kurmamız gerekiyor -
Pyaudio - Kullanılarak kurulabilir pip install Pyaudio komut.
SpeechRecognition - Bu paket kullanılarak kurulabilir pip install SpeechRecognition.
Google-Speech-API - komutu kullanılarak kurulabilir pip install google-api-python-client.
Misal
Sözlü kelimelerin tanınmasını anlamak için aşağıdaki örneği inceleyin -
Gerekli paketleri gösterildiği gibi içe aktarın -
import speech_recognition as srAşağıda gösterildiği gibi bir nesne oluşturun -
recording = sr.Recognizer()Şimdi Microphone() modül sesi girdi olarak alacaktır -
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)Artık Google API sesi tanıyacak ve çıktıyı verecektir.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)Aşağıdaki çıktıyı görebilirsiniz -
Please Say Something:
You said:Örneğin, dediyseniz tutorialspoint.com, sonra sistem bunu aşağıdaki gibi doğru bir şekilde tanır -
tutorialspoint.com