Makine Öğrenimi - Hızlı Kılavuz
Günümüzün Yapay Zekası (AI), blok zinciri ve kuantum hesaplama yutturmacasını çok aştı. Bunun nedeni, devasa bilgi işlem kaynaklarının sıradan insan tarafından kolayca erişilebilir olmasıdır. Geliştiriciler artık yeni Makine Öğrenimi modelleri oluştururken ve daha iyi performans ve sonuçlar için mevcut modelleri yeniden eğitirken bundan yararlanıyor. Yüksek Performanslı Bilgi İşlem'in (HPC) kolay kullanılabilirliği, Makine Öğrenimi becerilerine sahip BT uzmanları için aniden artan bir taleple sonuçlandı.
Bu eğitimde, aşağıdakiler hakkında ayrıntılı bilgi edineceksiniz:
Makine öğreniminin özü nedir?
Makine öğreniminin farklı türleri nelerdir?
Makine öğrenimi modelleri geliştirmek için kullanılabilen farklı algoritmalar nelerdir?
Bu modelleri geliştirmek için hangi araçlar mevcut?
Programlama dili seçenekleri nelerdir?
Makine Öğrenimi uygulamalarının geliştirilmesini ve dağıtımını hangi platformlar destekliyor?
Hangi IDE'ler (Entegre Geliştirme Ortamı) mevcuttur?
Bu önemli alandaki becerilerinizi hızla nasıl geliştirebilirsiniz?
Bir Facebook fotoğrafındaki bir yüzü etiketlediğinizde, sahne arkasında çalışan ve bir resimdeki yüzleri tanımlayan AI'dır. Yüz etiketleme artık insan yüzleri olan resimleri görüntüleyen çeşitli uygulamalarda her yerde mevcuttur. Neden sadece insan yüzleri? Kediler, köpekler, şişeler, arabalar, vb. Gibi nesneleri algılayan çeşitli uygulamalar vardır. Yollarımızda çalışan ve arabayı yönlendirmek için nesneleri gerçek zamanlı olarak algılayan otonom arabalara sahibiz. Seyahat ederken Google'ı kullanırsınızDirectionsgerçek zamanlı trafik durumlarını öğrenmek ve o anda Google tarafından önerilen en iyi yolu takip etmek. Bu, gerçek zamanlı olarak nesne algılama tekniğinin başka bir uygulamasıdır.
Google örneğini ele alalım TranslateGenellikle yabancı ülkeleri ziyaret ederken kullandığımız uygulama. Google'ın cep telefonunuzdaki çevrimiçi çevirmen uygulaması, size yabancı bir dili konuşan yerel insanlarla iletişim kurmanıza yardımcı olur.
Bugün pratik olarak kullandığımız birkaç AI uygulaması var. Aslında her birimiz, bilgimiz olmasa bile hayatımızın birçok yerinde yapay zekayı kullanıyoruz. Günümüzün yapay zekası, son derece karmaşık işleri büyük bir doğruluk ve hızla gerçekleştirebilir. Müşterileriniz için bugün geliştireceğiniz bir AI uygulamasında hangi yeteneklerin beklendiğini anlamak için karmaşık bir görev örneğini tartışalım.
Misal
Hepimiz Google kullanıyoruz Directionsgezimiz sırasında şehrin herhangi bir yerine günlük gidip gelmek için veya hatta şehirler arası seyahatler için. Google Yol Tarifi uygulaması o andaki hedefimize giden en hızlı yolu önerir. Bu yolu izlediğimizde Google'ın önerilerinde neredeyse% 100 haklı olduğunu gözlemledik ve seyahatte değerli vaktimizi kurtarıyoruz.
Varış noktanıza giden birden fazla yol olduğunu ve uygulamanın size bu tür her yol için bir seyahat süresi tahmini vermesi için mümkün olan her yoldaki trafik durumunu yargılaması gerektiğini göz önünde bulundurarak bu tür bir uygulamanın geliştirilmesindeki karmaşıklığı hayal edebilirsiniz. Ayrıca, Google Yol Tarifi'nin tüm dünyayı kapsadığını düşünün. Kuşkusuz, bu tür uygulamaların başlıkları altında birçok AI ve Makine Öğrenimi tekniği kullanılmaktadır.
Bu tür uygulamaların geliştirilmesine yönelik sürekli talep göz önüne alındığında, yapay zeka becerilerine sahip BT uzmanlarına neden ani bir talep olduğunu şimdi anlayacaksınız.
Bir sonraki bölümde, AI programları geliştirmek için ne gerektiğini öğreneceğiz.
Yapay zekanın yolculuğu, bilgi işlem gücünün bugün olduğundan çok daha az olduğu 1950'lerde başladı. Yapay zeka, makinenin yaptığı tahminlerle yola çıktı ve bir istatistikçi hesap makinesini kullanarak tahminler yapıyor. Bu nedenle, ilk tüm AI geliştirme, temel olarak istatistiksel tekniklere dayanıyordu.
Bu bölümde, bu istatistiksel tekniklerin neler olduğunu ayrıntılı olarak tartışalım.
İstatistiksel teknikler
Günümüzün AI uygulamalarının gelişimi, eski geleneksel istatistiksel tekniklerin kullanılmasıyla başladı. Gelecekteki bir değeri tahmin etmek için okullarda düz çizgi enterpolasyonu kullanmış olmalısınız. Yapay zeka programları denen programların geliştirilmesinde başarıyla uygulanan bu tür birkaç başka istatistiksel teknik vardır. "Sözde" diyoruz çünkü bugün sahip olduğumuz AI programları çok daha karmaşıktır ve ilk AI programları tarafından kullanılan istatistiksel tekniklerin çok ötesinde teknikler kullanır.
O günlerde AI uygulamaları geliştirmek için kullanılan ve hala pratikte olan bazı istatistiksel teknik örnekleri burada listelenmiştir -
- Regression
- Classification
- Clustering
- Olasılık Teorileri
- Karar ağaçları
Burada, yapay zekanın gerektirdiği enginlikten sizi korkutmadan yapay zekaya başlamanıza yetecek bazı temel teknikleri listeledik. Sınırlı verilere dayanarak AI uygulamaları geliştiriyorsanız, bu istatistiksel teknikleri kullanıyor olacaksınız.
Ancak günümüzde veriler bol miktarda bulunmaktadır. İstatistiksel tekniklere sahip olduğumuz türden devasa verileri analiz etmek, kendilerine ait bazı sınırlamalara sahip oldukları için pek yardımcı olmaz. Derin öğrenme gibi daha gelişmiş yöntemler bu nedenle birçok karmaşık sorunu çözmek için geliştirilmiştir.
Bu eğitimde ilerledikçe, Makine Öğreniminin ne olduğunu ve bu tür karmaşık yapay zeka uygulamaları geliştirmek için nasıl kullanıldığını anlayacağız.
Metrekare cinsinden boyutuna karşı ev fiyatları grafiğini gösteren aşağıdaki rakamı düşünün.

XY arsasında çeşitli veri noktalarını çizdikten sonra, boyutuna göre başka herhangi bir ev için tahminlerimizi yapmak için en uygun çizgiyi çizeriz. Bilinen verileri makineye besleyecek ve ondan en uygun çizgiyi bulmasını isteyeceksiniz. Makine tarafından en iyi uyum çizgisi bulunduğunda, uygunluğunu bilinen bir kümes boyutunda, yani yukarıdaki eğrideki Y-değerini besleyerek test edeceksiniz. Makine şimdi tahmini X değerini, yani evin beklenen fiyatını döndürecektir. Şema, 3000 fit kare veya daha büyük bir evin fiyatını bulmak için tahmin edilebilir. Buna istatistiklerde regresyon denir. Özellikle, X ve Y veri noktaları arasındaki ilişki doğrusal olduğundan, bu tür bir regresyon doğrusal regresyon olarak adlandırılır.
Çoğu durumda, X ve Y veri noktaları arasındaki ilişki düz bir çizgi olmayabilir ve karmaşık bir denklem içeren bir eğri olabilir. Şimdi göreviniz, gelecekteki değerleri tahmin etmek için tahmin edilebilecek en uygun eğriyi bulmak olacaktır. Aşağıdaki şekilde böyle bir uygulama planı gösterilmektedir.
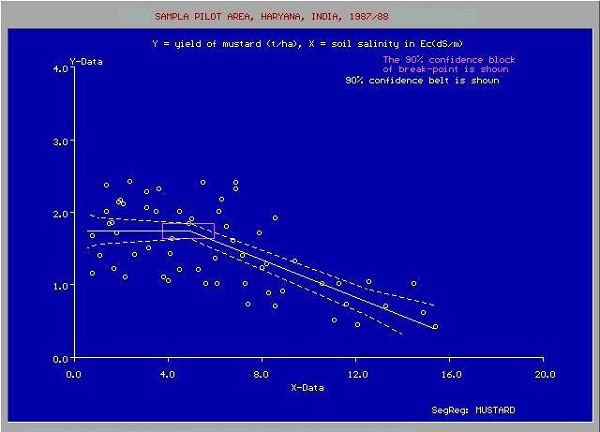
Kaynak:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
Burada en iyi uyum eğrisi için denklemi bulmak için istatistiksel optimizasyon tekniklerini kullanacaksınız. Ve Makine Öğrenimi tam olarak bununla ilgili. Sorununuza en iyi çözümü bulmak için bilinen optimizasyon tekniklerini kullanırsınız.
Ardından, Makine Öğreniminin farklı kategorilerine bakalım.
Makine Öğrenimi, genel olarak aşağıdaki başlıklar altında kategorize edilir -
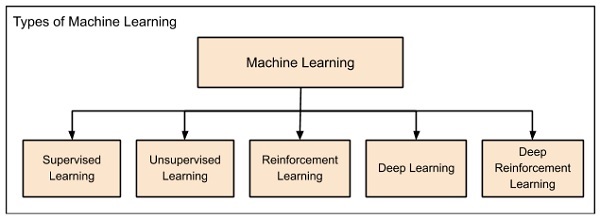
Makine öğrenimi, yukarıdaki şemada gösterildiği gibi soldan sağa doğru gelişti.
Başlangıçta, araştırmacılar Denetimli Öğrenme ile başladı. Bu, daha önce tartışılan konut fiyatı tahmini durumudur.
Bunu, makinenin herhangi bir denetim olmaksızın kendi kendine öğrenmesi için yapıldığı denetimsiz öğrenme izledi.
Bilim adamları ayrıca, işi beklenen şekilde yaptığında makineyi ödüllendirmenin iyi bir fikir olabileceğini keşfettiler ve orada Takviye Öğrenimi geldi.
Çok yakında, bugünlerde mevcut olan veriler o kadar muazzam hale geldi ki, şimdiye kadar geliştirilen geleneksel teknikler büyük veriyi analiz etmekte ve bize tahminler sağlamakta başarısız oldu.
Böylece, ikili bilgisayarlarımızda oluşturulan Yapay Sinir Ağlarında (YSA) insan beyninin simüle edildiği derin öğrenme geldi.
Makine artık bugün mevcut olan yüksek bilgi işlem gücünü ve devasa bellek kaynaklarını kullanarak kendi kendine öğreniyor.
Şimdi, Derin Öğrenmenin daha önce çözülemeyen sorunların çoğunu çözdüğü gözlemlenmektedir.
Teknik, artık Derin Öğrenme ağlarına ödül olarak teşvikler vererek daha da geliştirildi ve sonunda Derin Pekiştirmeli Öğrenme geliyor.
Şimdi bu kategorilerin her birini daha ayrıntılı inceleyelim.
Denetimli Öğrenme
Denetimli öğrenme, bir çocuğu yürümesi için eğitmeye benzer. Çocuğun elini tutacak, ona ayağını nasıl ileriye götüreceğini gösterecek, bir gösteri için kendi başına yürüyecek vb. Çocuk kendi başına yürümeyi öğrenene kadar.
Regresyon
Benzer şekilde, denetimli öğrenme durumunda, bilgisayara somut bilinen örnekler verirsiniz. Verilen x1 özellik değeri için çıktının y1, x2 için y2, x3 için y3 vb. Olduğunu söylüyorsunuz. Bu verilere dayanarak, bilgisayarın x ve y arasında deneysel bir ilişki bulmasına izin verirsiniz.
Makine yeterli sayıda veri noktası ile bu şekilde eğitildikten sonra, makineden belirli bir X için Y'yi tahmin etmesini isteyeceksiniz. Bu verilen X için Y'nin gerçek değerini bildiğinizi varsayarsak, sonuç çıkarabileceksiniz. makinenin tahmininin doğru olup olmadığı.
Böylece, makinenin bilinen test verilerini kullanarak öğrenip öğrenmediğini test edeceksiniz. Makinenin tahminleri istenen bir doğruluk düzeyinde (örneğin% 80 ila% 90) yapabildiğinden emin olduğunuzda, makineyi daha fazla eğitmeyi bırakabilirsiniz.
Artık bilinmeyen veri noktalarında tahmin yapmak için makineyi güvenle kullanabilir veya makineden Y'nin gerçek değerini bilmediğiniz belirli bir X için Y'yi tahmin etmesini isteyebilirsiniz. Bu eğitim, bahsettiğimiz regresyonun altında gelir. daha erken.
Sınıflandırma
Sınıflandırma problemleri için makine öğrenimi tekniklerini de kullanabilirsiniz. Sınıflandırma problemlerinde, benzer yapıdaki nesneleri tek bir grupta sınıflandırırsınız. Örneğin, 100 öğrenciden oluşan bir grupta, onları boylarına göre üç gruba ayırmak isteyebilirsiniz - kısa, orta ve uzun. Her öğrencinin boyunu ölçerek, onları uygun bir gruba yerleştireceksiniz.
Şimdi, yeni bir öğrenci geldiğinde, boyunu ölçerek onu uygun bir gruba koyacaksınız. Regresyon eğitimindeki ilkeleri takip ederek, makineyi öğrenciyi özelliğine - boyuna - göre sınıflandırması için eğiteceksiniz. Makine, grupların nasıl oluştuğunu öğrendiğinde, bilinmeyen her yeni öğrenciyi doğru bir şekilde sınıflandırabilecektir. Bir kez daha, geliştirilen modeli üretime koymadan önce makinenin sınıflandırma tekniğinizi öğrendiğini doğrulamak için test verilerini kullanırsınız.
Denetimli Öğrenme, AI'nın gerçekten yolculuğuna başladığı yerdir. Bu teknik, birkaç durumda başarıyla uygulandı. Makinenizde elle yazılmış tanıma yaparken bu modeli kullandınız. Denetimli öğrenme için çeşitli algoritmalar geliştirilmiştir. Sonraki bölümlerde onlar hakkında bilgi edineceksiniz.
Denetimsiz Öğrenme
Denetimsiz öğrenmede, makineye bir hedef değişken belirtmiyoruz, bunun yerine makineye "X hakkında bana ne söyleyebilirsiniz?" Diye soruyoruz. Daha spesifik olarak, büyük bir veri kümesi X verildiğinde, "X'ten çıkarabileceğimiz en iyi beş grup hangileridir?" Gibi sorular sorabiliriz. veya "X'te en sık birlikte hangi özellikler oluşur?". Bu tür soruların yanıtlarına ulaşmak için, makinenin bir strateji çıkarması için ihtiyaç duyacağı veri noktalarının sayısının çok büyük olacağını anlayabilirsiniz. Denetimli öğrenme durumunda, makine yaklaşık birkaç bin veri noktasıyla bile eğitilebilir. Ancak, denetimsiz öğrenme durumunda, öğrenme için makul olarak kabul edilen veri noktalarının sayısı birkaç milyonda başlar. Bu günlerde, veriler genellikle bol miktarda mevcuttur. Veriler ideal olarak küratörlüğü gerektirir. Bununla birlikte, bir sosyal alan ağında sürekli olarak akan veri miktarı, çoğu durumda veri iyileştirme imkansız bir görevdir.
Aşağıdaki şekil, denetimsiz makine öğrenimiyle belirlenen sarı ve kırmızı noktalar arasındaki sınırı gösterir. Açıkça görebileceğiniz gibi, makine siyah noktaların her birinin sınıfını oldukça iyi bir doğrulukla belirleyebilir.
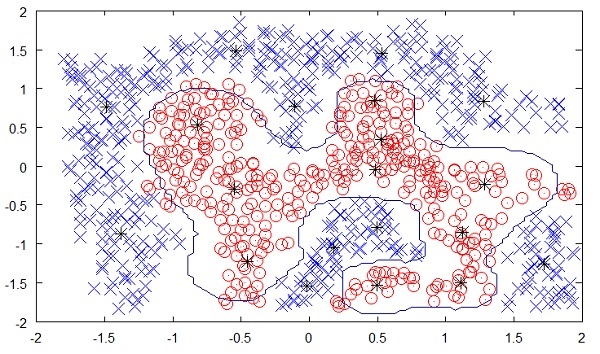
Kaynak:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
Denetimsiz öğrenme, yüz algılama, nesne algılama vb. Gibi birçok modern AI uygulamasında büyük bir başarı göstermiştir.
Takviye Öğrenme
Bir evcil köpek yetiştirmeyi düşünün, evcil hayvanımızı bize bir top getirmesi için eğitiyoruz. Topu belli bir mesafeye atıyoruz ve köpeğin bize geri getirmesini istiyoruz. Köpek bunu her doğru yaptığında köpeği ödüllendiriyoruz. Yavaş yavaş, köpek işi doğru yapmanın ona bir ödül verdiğini öğrenir ve daha sonra köpek gelecekte her seferinde işi doğru şekilde yapmaya başlar. Tam olarak, bu kavram “Pekiştirme” türü öğrenmede uygulanır. Teknik başlangıçta makinelerin oyun oynaması için geliştirildi. Makineye, oyunun her aşamasında olası tüm hareketleri analiz etmek için bir algoritma verilmiştir. Makine, hareketlerden birini rastgele seçebilir. Hareket doğruysa makine ödüllendirilir, aksi takdirde cezalandırılabilir. Yavaş yavaş, makine doğru ve yanlış hareketleri ayırt etmeye başlayacak ve birkaç yinelemeden sonra oyun bulmacasını daha iyi bir doğrulukla çözmeyi öğrenecektir. Oyunu kazanmanın doğruluğu, makine gittikçe daha fazla oyun oynadıkça artacaktır.
Tüm süreç aşağıdaki diyagramda gösterilebilir -
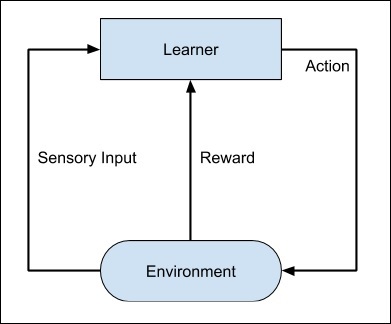
Bu makine öğrenimi tekniği, etiketli giriş / çıkış çiftlerini sağlamanız gerekmemesi açısından denetimli öğrenmeden farklıdır. Odak noktası, yeni çözümleri keşfetme ile öğrenilen çözümleri kullanma arasındaki dengeyi bulmaktır.
Derin Öğrenme
Derin öğrenme, Yapay Sinir Ağlarına (YSA), daha özel olarak Evrişimli Sinir Ağlarına (CNN) dayalı bir modeldir. Derin sinir ağları, derin inanç ağları, tekrarlayan sinir ağları ve evrişimli sinir ağları gibi derin öğrenmede kullanılan birkaç mimari vardır.
Bu ağlar, bilgisayarla görme, konuşma tanıma, doğal dil işleme, biyoinformatik, ilaç tasarımı, tıbbi görüntü analizi ve oyun sorunlarının çözümünde başarıyla uygulanmıştır. Derin öğrenmenin proaktif olarak uygulandığı birkaç başka alan vardır. Derin öğrenme, bugünlerde genellikle kolayca erişilebilen devasa bir işlem gücü ve muazzam veriler gerektirir.
İlerleyen bölümlerde derin öğrenmeden daha ayrıntılı olarak bahsedeceğiz.
Derin Pekiştirmeli Öğrenme
Deep Reinforcement Learning (DRL), hem derin hem de pekiştirmeli öğrenme tekniklerini birleştirir. Q-öğrenme gibi pekiştirmeli öğrenme algoritmaları artık güçlü bir DRL modeli oluşturmak için derin öğrenme ile birleştirildi. Teknik, robotik, video oyunları, finans ve sağlık hizmetleri alanlarında büyük bir başarı elde etti. Daha önce çözülemeyen birçok sorun artık DRL modelleri oluşturularak çözülmüştür. Bu alanda pek çok araştırma var ve bu endüstriler tarafından çok aktif bir şekilde takip ediliyor.
Şimdiye kadar, çeşitli makine öğrenimi modellerine kısa bir giriş yaptınız, şimdi bu modeller altında bulunan çeşitli algoritmaları biraz daha derinlemesine inceleyelim.
Denetimli öğrenme, eğitim makinelerinde yer alan önemli öğrenme modellerinden biridir. Bu bölüm aynı şeyi ayrıntılı olarak anlatıyor.
Denetimli Öğrenim için Algoritmalar
Denetimli öğrenme için çeşitli algoritmalar mevcuttur. Denetimli öğrenmenin yaygın olarak kullanılan algoritmalarından bazıları aşağıda gösterildiği gibidir -
- k-En Yakın Komşular
- Karar ağaçları
- Naif bayanlar
- Lojistik regresyon
- Vektör makineleri desteklemek
Bu bölümde ilerlerken, algoritmaların her biri hakkında ayrıntılı olarak tartışalım.
k-En Yakın Komşular
Basitçe kNN olarak adlandırılan k-En Yakın Komşular, sınıflandırma ve regresyon problemlerini çözmek için kullanılabilecek istatistiksel bir tekniktir. Bilinmeyen bir nesneyi kNN kullanarak sınıflandırma durumunu tartışalım. Aşağıda verilen resimde gösterildiği gibi nesnelerin dağılımını düşünün -
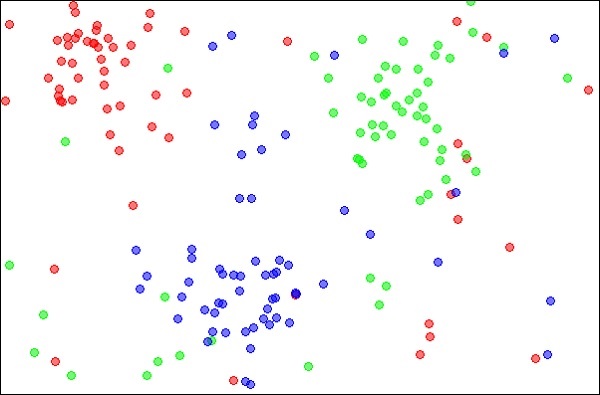
Kaynak:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Şema, kırmızı, mavi ve yeşil renklerle işaretlenmiş üç tür nesneyi göstermektedir. Yukarıdaki veri kümesinde kNN sınıflandırıcısını çalıştırdığınızda, her nesne türü için sınırlar aşağıda gösterildiği gibi işaretlenecektir -

Kaynak:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Şimdi, kırmızı, yeşil veya mavi olarak sınıflandırmak istediğiniz yeni bir bilinmeyen nesneyi düşünün. Bu, aşağıdaki şekilde tasvir edilmiştir.
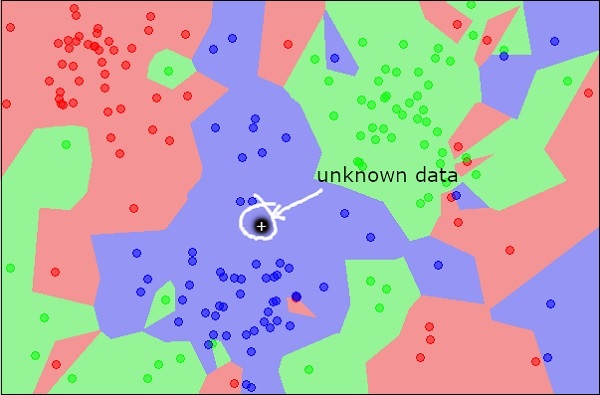
Görsel olarak gördüğünüz gibi, bilinmeyen veri noktası bir mavi nesneler sınıfına aittir. Matematiksel olarak bu, bu bilinmeyen noktanın mesafesini veri setindeki diğer her nokta ile ölçerek sonuçlandırılabilir. Bunu yaptığınızda, komşularının çoğunun mavi renkte olduğunu bileceksiniz. Kırmızı ve yeşil nesnelere olan ortalama mesafe, mavi nesnelere olan ortalama mesafeden kesinlikle daha fazla olacaktır. Bu nedenle, bu bilinmeyen nesne mavi sınıfına ait olarak sınıflandırılabilir.
KNN algoritması, regresyon problemleri için de kullanılabilir. KNN algoritması, ML kitaplıklarının çoğunda kullanıma hazır olarak mevcuttur.
Karar ağaçları
Akış şeması biçiminde basit bir karar ağacı aşağıda gösterilmiştir -
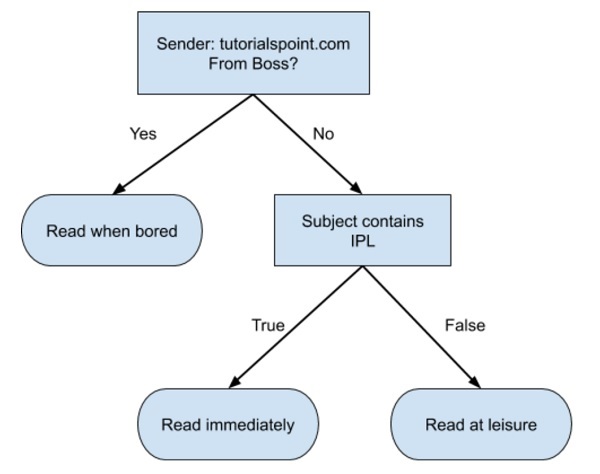
Giriş verilerinizi bu akış şemasına göre sınıflandırmak için bir kod yazarsınız. Akış şeması kendinden açıklamalıdır ve önemsizdir. Bu senaryoda, ne zaman okuyacağınıza karar vermek için gelen bir e-postayı sınıflandırmaya çalışıyorsunuz.
Gerçekte, karar ağaçları büyük ve karmaşık olabilir. Bu ağaçları oluşturmak ve geçmek için kullanılabilecek çeşitli algoritmalar vardır. Bir Makine Öğrenimi meraklısı olarak, karar ağaçlarını oluşturmak ve aşmak için bu teknikleri anlamanız ve bunlarda ustalaşmanız gerekir.
Naif bayanlar
Naive Bayes, sınıflandırıcılar oluşturmak için kullanılır. Bir meyve sepetinden farklı türdeki meyveleri ayırmak (sınıflandırmak) istediğinizi varsayalım. Bir meyvenin rengi, boyutu ve şekli gibi özellikleri kullanabilirsiniz, örneğin kırmızı renkli, yuvarlak şekilli ve yaklaşık 10 cm çapında olan herhangi bir meyve Elma olarak kabul edilebilir. Bu nedenle, modeli eğitmek için bu özellikleri kullanır ve belirli bir özelliğin istenen kısıtlamalara uyma olasılığını test edersiniz. Farklı özelliklerin olasılıkları, daha sonra, belirli bir meyvenin bir Elma olma olasılığına ulaşmak için birleştirilir. Naive Bayes, genellikle sınıflandırma için az sayıda eğitim verisi gerektirir.
Lojistik regresyon
Aşağıdaki şemaya bakın. Veri noktalarının XY düzlemindeki dağılımını gösterir.

Diyagramdan, kırmızı noktaların yeşil noktalardan ayrılmasını görsel olarak inceleyebiliriz. Bu noktaları ayırmak için bir sınır çizgisi çizebilirsiniz. Şimdi, yeni bir veri noktasını sınıflandırmak için, noktanın çizginin hangi tarafında olduğunu belirlemeniz yeterlidir.
Vektör makineleri desteklemek
Aşağıdaki veri dağılımına bakın. Burada üç veri sınıfı doğrusal olarak ayrılamaz. Sınır eğrileri doğrusal değildir. Böyle bir durumda, eğrinin denklemini bulmak karmaşık bir iş haline gelir.
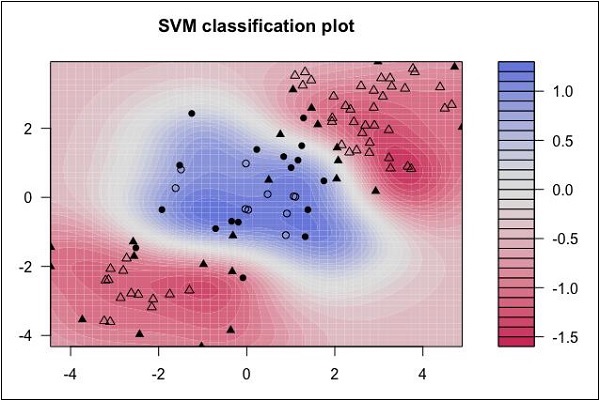
Kaynak: http://uc-r.github.io/svm
Destek Vektör Makineleri (SVM), bu tür durumlarda ayırma sınırlarının belirlenmesinde kullanışlıdır.
Neyse ki, çoğu zaman önceki derste bahsedilen algoritmaları kodlamak zorunda değilsin. Bu algoritmaların kullanıma hazır uygulamasını sağlayan birçok standart kitaplık vardır. Popüler olarak kullanılan bu tür araçlardan biri scikit-learn'dür. Aşağıdaki şekil, bu kitaplıkta kullanmanız için mevcut olan algoritma türlerini göstermektedir.

Kaynak: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Bu algoritmaların kullanımı önemsizdir ve bunlar iyi ve sahada test edildiğinden, bunları AI uygulamalarınızda güvenle kullanabilirsiniz. Bu kitaplıkların çoğu ticari amaçlarla bile kullanmakta serbesttir.
Şimdiye kadar gördüğünüz şey, makinenin hedefimiz için çözümü bulmayı öğrenmesini sağlamak. Regresyonda, makineyi gelecekteki bir değeri tahmin etmesi için eğitiyoruz. Sınıflandırmada, makineyi, bilinmeyen bir nesneyi tarafımızdan tanımlanan kategorilerden birinde sınıflandırması için eğitiyoruz. Kısacası, X verilerimiz için Y'yi tahmin edebilmesi için makineleri eğitiyoruz. Büyük bir veri kümesi verildiğinde ve kategorileri tahmin etmediğimizde, makineyi denetimli öğrenmeyi kullanarak eğitmek bizim için zor olurdu. Ya makine birkaç Gigabayt ve Terabaytta çalışan büyük veriyi arayıp analiz edebilir ve bize bu verilerin çok sayıda farklı kategori içerdiğini söylerse?
Örnek olarak, seçmen verilerini düşünün. Her seçmenden bazı girdileri dikkate alarak (bunlara AI terminolojisinde özellikler denir), makinenin X siyasi partisine oy verecek çok sayıda seçmen olduğunu ve pek çoğunun Y'ye oy vereceğini tahmin etmesine izin verin. Bu nedenle, genel olarak, makineye çok büyük bir veri noktaları kümesi verilmiş olan X, "Bana X hakkında ne söyleyebilirsiniz?" Diye soruyoruz. Ya da "X'ten çıkarabileceğimiz en iyi beş grup nedir?" Gibi bir soru olabilir. Ya da "X'te en sık birlikte hangi üç özellik birlikte görülür?" Gibi olabilir.
Bu tam olarak Denetimsiz Öğrenim ile ilgilidir.
Denetimsiz Öğrenme Algoritmaları
Şimdi, denetimsiz makine öğreniminde sınıflandırma için yaygın olarak kullanılan algoritmalardan birini tartışalım.
k-kümeleme anlamına gelir
Amerika Birleşik Devletleri'ndeki 2000 ve 2004 Başkanlık seçimleri yakındı - çok yakındı. Herhangi bir adayın aldığı en büyük halk oyu yüzdesi% 50,7 ve en düşük oranı% 47,9 oldu. Seçmenlerin bir yüzdesi taraf değiştirmiş olsaydı, seçimin sonucu farklı olurdu. Uygun şekilde başvurulduğunda taraf değiştirecek küçük seçmen grupları var. Bu gruplar çok büyük olmayabilir, ancak bu kadar yakın ırklarla seçimin sonucunu değiştirecek kadar büyük olabilirler. Bu insan gruplarını nasıl buluyorsunuz? Sınırlı bir bütçeyle onlara nasıl hitap ediyorsunuz? Cevap kümelemedir.
Nasıl yapıldığını anlayalım.
Birincisi, rızaları olsun ya da olmasın, insanlar hakkında bilgi topluyorsunuz: onlar için neyin önemli olduğu ve neyin oy verme şeklini etkileyeceği konusunda ipucu verebilecek her türlü bilgi.
Sonra bu bilgiyi bir çeşit kümeleme algoritmasına koyarsınız.
Daha sonra, her küme için (önce en büyüğünü seçmek akıllıca olacaktır) bu seçmenlere hitap edecek bir mesaj hazırlarsınız.
Son olarak, kampanyayı sunar ve işe yarayıp yaramadığını ölçersiniz.
Kümeleme, benzer şeylerin kümelerini otomatik olarak oluşturan bir tür denetimsiz öğrenmedir. Otomatik sınıflandırma gibidir. Neredeyse her şeyi kümeleyebilirsiniz ve kümedeki öğeler ne kadar benzer olursa, kümeler o kadar iyi olur. Bu bölümde, k-ortalamaları adı verilen bir tür kümeleme algoritmasını inceleyeceğiz. K-aracı olarak adlandırılır çünkü 'k' benzersiz kümeler bulur ve her kümenin merkezi, o kümedeki değerlerin ortalamasıdır.
Küme Tanımlaması
Küme tanımlama bir algoritmaya "İşte bazı veriler. Şimdi benzer şeyleri bir araya toplayın ve bana bu gruplardan bahsedin. " Sınıflandırmadan en önemli farkı, sınıflandırmada ne aradığınızı bilmenizdir. Kümelemede durum böyle olmasa da.
Kümeleme, bazen denetlenmemiş sınıflandırma olarak adlandırılır, çünkü sınıflandırmanın yaptığı gibi, ancak önceden tanımlanmış sınıflar olmadan aynı sonucu verir.
Şimdi, hem denetimli hem de denetimsiz öğrenmede rahatız. Makine öğrenimi kategorilerinin geri kalanını anlamak için önce bir sonraki bölümde öğreneceğimiz Yapay Sinir Ağlarını (YSA) anlamalıyız.
Yapay sinir ağları fikri, insan beynindeki sinir ağlarından türetildi. İnsan beyni gerçekten karmaşık. Beyni dikkatlice inceleyen bilim adamları ve mühendisler, dijital ikili bilgisayar dünyamıza uyabilecek bir mimari buldular. Böyle tipik bir mimari, aşağıdaki şemada gösterilmektedir -
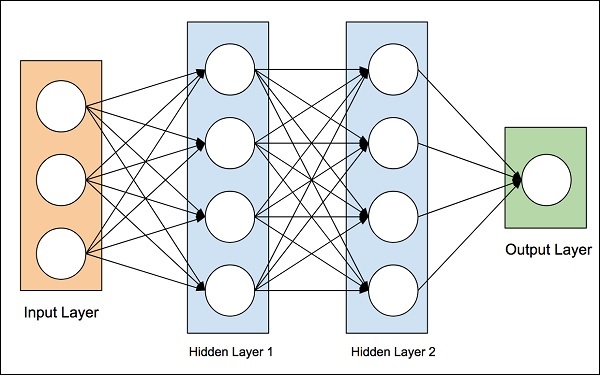
Dış dünyadan veri toplamak için birçok sensöre sahip bir giriş katmanı vardır. Sağ tarafta, bize ağ tarafından tahmin edilen sonucu veren bir çıktı katmanımız var. Bu ikisinin arasında birkaç katman gizlidir. Her ek katman, ağın eğitimine daha fazla karmaşıklık katar, ancak çoğu durumda daha iyi sonuçlar sağlar. Şimdi tartışacağımız birkaç tür mimari vardır.
YSA Mimarileri
Aşağıdaki şema, belirli bir süre boyunca geliştirilen ve bugün uygulanmakta olan birkaç YSA mimarisini göstermektedir.
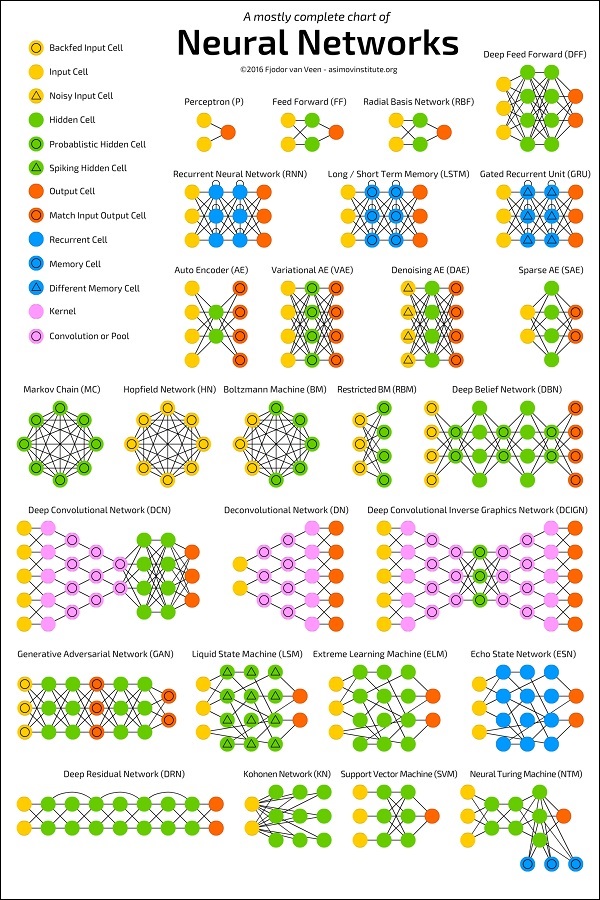
Kaynak:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Her mimari, belirli bir uygulama türü için geliştirilmiştir. Bu nedenle, makine öğrenimi uygulamanız için bir sinir ağı kullandığınızda, mevcut mimarilerden birini kullanmanız veya kendi mimarinizi tasarlamanız gerekecektir. Nihayet karar vereceğiniz uygulama türü, başvuru ihtiyaçlarınıza bağlıdır. Size belirli bir ağ mimarisini kullanmanızı söyleyen tek bir kılavuz yoktur.
Derin Öğrenme YSA kullanır. İlk olarak, gücü hakkında size bir fikir verecek birkaç derin öğrenme uygulamasına bakacağız.
Başvurular
Derin Öğrenme, makine öğrenimi uygulamalarının çeşitli alanlarında çok fazla başarı göstermiştir.
Self-driving Cars- Otonom sürücüsüz arabalar derin öğrenme tekniklerini kullanır. Genellikle sürekli değişen trafik koşullarına adapte olurlar ve belirli bir süre içinde daha iyi ve daha iyi araç kullanırlar.
Speech Recognition- Derin Öğrenmenin bir başka ilginç uygulaması konuşma tanımadır. Bugün hepimiz konuşmamızı tanıyabilen birkaç mobil uygulama kullanıyoruz. Apple'ın Siri'si, Amazon'un Alexa'sı, Microsoft'un Cortena'sı ve Google'ın Asistanı - bunların hepsi derin öğrenme tekniklerini kullanıyor.
Mobile Apps- Fotoğraflarımızı düzenlemek için çeşitli web tabanlı ve mobil uygulamalar kullanıyoruz. Yüz algılama, yüz kimliği, yüz etiketleme, bir görüntüdeki nesneleri tanımlama - bunların tümü derin öğrenmeyi kullanır.
Kullanılmayan Derin Öğrenim Fırsatları
İnsanlar derin öğrenme uygulamalarının birçok alanda elde ettiği büyük başarıya baktıktan sonra, makine öğreniminin şimdiye kadar uygulanmadığı diğer alanları keşfetmeye başladı. Derin öğrenme tekniklerinin başarıyla uygulandığı birkaç alan vardır ve yararlanılabilecek birçok başka alan vardır. Bunlardan bazıları burada tartışılmaktadır.
Tarım, insanların mahsul verimini artırmak için derin öğrenme tekniklerini uygulayabileceği türden bir endüstridir.
Tüketici finansmanı, makine öğreniminin dolandırıcılık konusunda erken tespit sağlamada ve müşterinin ödeme yeteneğini analiz etmede büyük ölçüde yardımcı olabileceği başka bir alandır.
Derin öğrenme teknikleri, yeni ilaçlar oluşturmak ve bir hastaya kişiselleştirilmiş bir reçete sağlamak için tıp alanında da uygulanır.
Olasılıklar sonsuzdur ve yeni fikirler ve gelişmeler sık sık ortaya çıktıkça kişi izlemeye devam etmelidir.
Derin Öğrenmeyi Kullanarak Daha Fazla Başarmak İçin Neler Gereklidir?
Derin öğrenmeyi kullanmak için süper hesaplama gücü zorunlu bir gerekliliktir. Derin öğrenme modelleri geliştirmek için hem belleğe hem de CPU'ya ihtiyacınız var. Neyse ki, bugün HPC - Yüksek Performanslı Hesaplama için kolay kullanılabilirliğe sahibiz. Bundan dolayı yukarıda bahsettiğimiz derin öğrenme uygulamalarının gelişimi bugün gerçeğe dönüştü ve gelecekte de daha önce tartıştığımız bu kullanılmayan alanlardaki uygulamaları görebiliriz.
Şimdi, derin öğrenmenin makine öğrenimi uygulamamızda kullanmadan önce dikkate almamız gereken bazı sınırlamalarına bakacağız.
Derin Öğrenme Dezavantajları
Derin öğrenmeyi kullanmadan önce dikkat etmeniz gereken bazı önemli noktalar aşağıda listelenmiştir -
- Kara Kutu yaklaşımı
- Geliştirme Süresi
- Data miktarı
- Hesaplamalı Olarak Pahalı
Şimdi bu sınırlamaların her birini ayrıntılı olarak inceleyeceğiz.
Kara Kutu yaklaşımı
YSA, kara kutu gibidir. Siz ona belirli bir girdi verirsiniz ve size belirli bir çıktı sağlar. Aşağıdaki şema, bir hayvan görüntüsünü bir sinir ağına beslediğiniz bu tür bir uygulamayı gösterir ve görüntünün bir köpeğe ait olduğunu söyler.
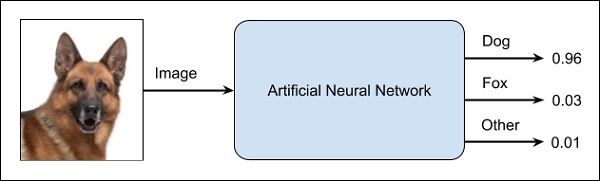
Buna neden kara kutu yaklaşımı deniyor, ağın neden belirli bir sonuç verdiğini bilmiyorsunuz. Ağın bunun bir köpek olduğu sonucuna nasıl vardığını bilmiyor musunuz? Şimdi, bankanın bir müşterinin kredi değerliliğine karar vermek istediği bir bankacılık uygulamasını düşünün. Ağ size bu soruya kesinlikle bir cevap verecektir. Ancak, bunu bir müşteriye gerekçelendirebilecek misiniz? Bankaların, krediye neden yaptırım uygulanmadığını müşterilerine açıklaması gerekir?
Geliştirme Süresi
Bir sinir ağını eğitme süreci aşağıdaki diyagramda gösterilmektedir -

Önce çözmek istediğiniz problemi tanımlarsınız, onun için bir spesifikasyon yaratırsınız, giriş özelliklerine karar verirsiniz, bir ağ tasarlar, devreye alır ve çıktıyı test edersiniz. Çıktı beklendiği gibi değilse, ağınızı yeniden yapılandırmak için bunu bir geri bildirim olarak alın. Bu yinelemeli bir süreçtir ve zaman ağı istenen çıktıları üretmek için tam olarak eğitilene kadar birkaç yineleme gerektirebilir.
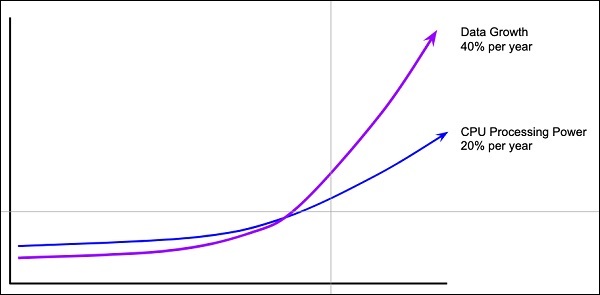
Data miktarı
Derin öğrenme ağları genellikle eğitim için büyük miktarda veriye ihtiyaç duyarken, geleneksel makine öğrenimi algoritmaları sadece birkaç bin veri noktasıyla bile büyük bir başarıyla kullanılabilir. Neyse ki, aşağıda verilen diyagramda görüldüğü gibi, veri bolluğu yılda% 40 ve CPU işlem gücü yılda% 20 artmaktadır -
Hesaplamalı Olarak Pahalı
Bir sinir ağını eğitmek, geleneksel algoritmaları çalıştırmak için gerekenden birkaç kat daha fazla hesaplama gücü gerektirir. Derin Sinir Ağlarının başarılı eğitimi, birkaç haftalık eğitim süresi gerektirebilir.
Bunun aksine, geleneksel makine öğrenimi algoritmalarının eğitilmesi yalnızca birkaç dakika / saat sürer. Ayrıca, derin sinir ağını eğitmek için gereken hesaplama gücü miktarı, büyük ölçüde verilerinizin boyutuna ve ağın ne kadar derin ve karmaşık olduğuna bağlıdır?
Makine Öğreniminin ne olduğuna, yeteneklerine, sınırlamalarına ve uygulamalarına genel bir bakış aldıktan sonra, şimdi “Makine Öğrenimi” öğrenmeye dalalım.
Makine Öğreniminin çok geniş bir genişliği vardır ve birçok alanda beceri gerektirir. Makine Öğrenimi konusunda uzman olmak için edinmeniz gereken beceriler aşağıda listelenmiştir -
- Statistics
- Olasılık Teorileri
- Calculus
- Optimizasyon teknikleri
- Visualization
Çeşitli Makine Öğrenimi Becerilerinin Gerekliliği
Hangi becerileri edinmeniz gerektiğine dair size kısa bir fikir vermek için, bazı örnekleri tartışalım -
Matematiksel Gösterim
Makine öğrenimi algoritmalarının çoğu ağırlıklı olarak matematiğe dayalıdır. Bilmeniz gereken matematik seviyesi muhtemelen başlangıç seviyesidir. Önemli olan matematikçilerin denklemlerinde kullandıkları gösterimi okuyabilmenizdir. Örneğin, notasyonu okuyabilir ve bunun ne anlama geldiğini kavrayabilirseniz, makine öğrenimini öğrenmeye hazırsınız demektir. Değilse, matematik bilginizi tazelemeniz gerekebilir.
$$ f_ {AN} (net- \ theta) = \ begin {case} \ gamma & if \: net- \ theta \ geq \ epsilon \\ net- \ theta & if - \ epsilon <net- \ theta <\ epsilon \\ - \ gamma & if \: net- \ theta \ leq- \ epsilon \ end {case} $$
$$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i, j = 1} ^ m etiket ^ \ left (\ begin {dizi} {c} i \\ \ end {dizi} \ sağ) \ cdot \: label ^ \ left (\ begin {dizi} {c} j \\ \ end {dizi} \ sağ) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {dizi} {c} i \\ \ end {dizi} \ sağ), x ^ \ left (\ begin {dizi} {c} j \\ \ end {dizi} \ sağ) \ rangle \ end {bmatrix} $$
$$ f_ {AN} (net- \ theta) = \ left (\ frac {e ^ {\ lambda (net- \ theta)} - e ^ {- \ lambda (net- \ theta)}} {e ^ { \ lambda (net- \ theta)} + e ^ {- \ lambda (net- \ theta)}} \ sağ) \; $$
Olasılık teorisi
İşte olasılık teorisi hakkındaki mevcut bilginizi test etmek için bir örnek: Koşullu olasılıklarla sınıflandırma.
$$ p (c_ {i} | x, y) \; = \ frac {p (x, y | c_ {i}) \; p (c_ {i}) \;} {p (x, y) \ ;} $$
Bu tanımlarla Bayes sınıflandırma kuralını tanımlayabiliriz -
- P (c1 | x, y)> P (c2 | x, y) ise, sınıf c1'dir.
- P (c1 | x, y) <P (c2 | x, y) ise, sınıf c2'dir.
Optimizasyon Sorunu
İşte bir optimizasyon işlevi
$$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i, j = 1} ^ m etiket ^ \ left (\ begin {dizi} {c} i \\ \ end {dizi} \ sağ) \ cdot \: label ^ \ left (\ begin {dizi} {c} j \\ \ end {dizi} \ sağ) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {dizi} {c} i \\ \ end {dizi} \ sağ), x ^ \ left (\ begin {dizi} {c} j \\ \ end {dizi} \ sağ) \ rangle \ end {bmatrix} $$
Aşağıdaki kısıtlamalara tabi -
$$ \ alpha \ geq0 ve \: \ displaystyle \ sum \ limits_ {i-1} ^ m \ alpha_ {i} \ cdot \: etiket ^ \ left (\ begin {dizi} {c} i \\ \ end {dizi} \ sağ) = 0 $$
Yukarıdakileri okuyabilir ve anlayabilirseniz, hazırsınız demektir.
Görselleştirme
Çoğu durumda, veri dağıtımınızı anlamak ve algoritmanın çıktısının sonuçlarını yorumlamak için çeşitli görselleştirme grafiklerini anlamanız gerekecektir.
Makine öğreniminin yukarıdaki teorik yönlerinin yanı sıra, bu algoritmaları kodlamak için iyi programlama becerilerine ihtiyacınız var.
Peki ML'yi uygulamak için ne gerekiyor? Bir sonraki bölümde buna bakalım.
Makine öğrenimi uygulamaları geliştirmek için platforma, IDE'ye ve geliştirme diline karar vermeniz gerekecektir. Mevcut birkaç seçenek vardır. Bunların çoğu, şimdiye kadar tartışılan AI algoritmalarının uygulanmasını sağladığı için gereksinimlerinizi kolayca karşılayacaktır.
Makine öğrenimi algoritmasını kendi başınıza geliştiriyorsanız, aşağıdaki hususların dikkatlice anlaşılması gerekir -
Seçtiğiniz dil - bu, esasen ML geliştirmede desteklenen dillerden birindeki yeterliliğinizdir.
Kullandığınız IDE - Bu, mevcut IDE'lere aşinalığınıza ve konfor seviyenize bağlı olacaktır.
Development platform- Geliştirme ve dağıtım için çeşitli platformlar mevcuttur. Bunların çoğu ücretsizdir. Bazı durumlarda, belirli bir kullanım miktarının ötesinde bir lisans ücreti ödemeniz gerekebilir. Hazır referansınız için dillerin, IDE'lerin ve platformların kısa bir listesi.
Dil Seçimi
Makine öğrenimi geliştirmeyi destekleyen dillerin bir listesi:
- Python
- R
- Matlab
- Octave
- Julia
- C++
- C
Bu liste esasen kapsamlı değildir; ancak, makine öğrenimi geliştirmede kullanılan birçok popüler dili kapsar. Konfor seviyenize bağlı olarak, geliştirme için bir dil seçin, modellerinizi geliştirin ve test edin.
IDE'ler
ML gelişimini destekleyen IDE'lerin listesi:
- R Studio
- Pycharm
- iPython / Jupyter Dizüstü Bilgisayar
- Julia
- Spyder
- Anaconda
- Rodeo
- Google –Colab
Yukarıdaki liste esasen kapsamlı değildir. Her birinin kendine özgü avantajları ve dezavantajları vardır. Okuyucu, tek bir IDE'ye geçmeden önce bu farklı IDE'leri denemeye teşvik edilir.
Platformlar
ML uygulamalarının dağıtılabileceği platformların bir listesi:
- IBM
- Microsoft Azure
- Google Cloud
- Amazon
- Mlflow
Bir kez daha bu liste ayrıntılı değildir. Okuyucu, yukarıda belirtilen hizmetlere kaydolmaya ve bunları kendileri denemeye teşvik edilir.
Bu eğitim sizi Makine Öğrenimi ile tanıştırdı. Şimdi, Makine Öğreniminin, ortalama bir insandan biraz daha hızlı ve daha iyi olmasına rağmen, bir insan beyninin yapabileceği etkinlikleri gerçekleştirmek için makineleri eğitmenin bir tekniği olduğunu biliyorsunuz. Bugün, makinelerin çok karmaşık kabul edilen Satranç, AlphaGO gibi oyunlarda insan şampiyonları yenebildiğini gördük. Makinelerin çeşitli alanlarda insan faaliyetlerini gerçekleştirmek için eğitilebileceğini ve insanların daha iyi yaşam sürmelerine yardımcı olabileceğini gördünüz.
Makine Öğrenimi Denetimli veya Denetimsiz olabilir. Daha az miktarda veriniz varsa ve eğitim için açıkça etiketlenmiş verileriniz varsa, Denetimli Öğrenimi seçin. Denetimsiz Öğrenme, genellikle büyük veri kümeleri için daha iyi performans ve sonuçlar verir. Kolayca erişilebilen büyük bir veri kümeniz varsa, derin öğrenme tekniklerine gidin. Ayrıca Takviye Öğrenme ve Derin Takviye Öğrenmeyi öğrendiniz. Artık Sinir Ağlarının ne olduğunu, uygulamalarını ve sınırlamalarını biliyorsunuz.
Son olarak, kendi makine öğrenimi modellerinin geliştirilmesi söz konusu olduğunda, çeşitli geliştirme dilleri, IDE'ler ve Platformların seçeneklerine baktınız. Yapmanız gereken sonraki şey, her makine öğrenimi tekniğini öğrenmeye ve uygulamaya başlamaktır. Konu çok geniş, bu genişlik var demek ama derinliği düşünürseniz her konu birkaç saat içinde öğrenilebilir. Her konu birbirinden bağımsızdır. Her seferinde bir konuyu dikkate almalı, öğrenmeli, pratik yapmalı ve kendi dil seçiminizi kullanarak algoritmayı / algoritmaları uygulamalısınız. Bu, Makine Öğrenimi okumaya başlamanın en iyi yoludur. Her seferinde bir konuyu uygulayarak, çok yakında bir Makine Öğrenimi uzmanının ihtiyaç duyduğu genişliği elde edersiniz.
İyi şanslar!