Spring Boot - Toplu Hizmet
Çalıştırılabilir bir JAR dosyası oluşturabilir ve aşağıda gösterildiği gibi Maven veya Gradle komutlarını kullanarak Spring Boot uygulamasını çalıştırabilirsiniz -
Maven için aşağıda verilen komutu kullanabilirsiniz -
mvn clean install"BUILD SUCCESS" sonrasında, JAR dosyasını hedef dizinin altında bulabilirsiniz.
Gradle için, komutu gösterildiği gibi kullanabilirsiniz -
gradle clean build"BUILD SUCCESSFUL" sonrasında, JAR dosyasını build / libs dizini altında bulabilirsiniz.
Burada verilen komutu kullanarak JAR dosyasını çalıştırın -
java –jar <JARFILE>Şimdi, uygulama gösterildiği gibi Tomcat 8080 portunda başlatıldı.

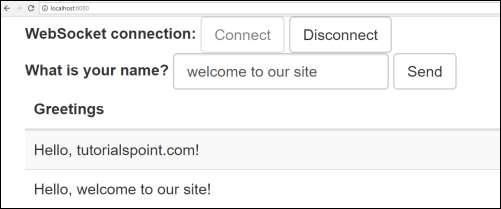
Şimdi, URL'ye basın http://localhost:8080/ web tarayıcınızda ve web soketini bağlayın ve karşılama mesajını gönderin ve mesajı alın.
Toplu Hizmet, tek bir görevde birden fazla komutu yürütme işlemidir. Bu bölümde, bir Spring Boot uygulamasında toplu hizmetin nasıl oluşturulacağını öğreneceksiniz.
CSV dosyası içeriğini HSQLDB'ye kaydedeceğimiz bir örneği ele alalım.
Bir Batch Service programı oluşturmak için, derleme yapılandırma dosyamıza Spring Boot Starter Batch bağımlılığını ve HSQLDB bağımlılığını eklememiz gerekir.
Maven kullanıcıları pom.xml dosyasına aşağıdaki bağımlılıkları ekleyebilir.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
</dependency>Gradle kullanıcıları build.gradle dosyasına aşağıdaki bağımlılıkları ekleyebilir.
compile("org.springframework.boot:spring-boot-starter-batch")
compile("org.hsqldb:hsqldb")Şimdi, basit CSV veri dosyasını sınıf yolu kaynakları altına ekleyin - src / main / resources ve dosyayı gösterildiği gibi file.csv olarak adlandırın -
William,John
Mike, Sebastian
Lawarance, LimeArdından, HSQLDB için bir SQL komut dosyası yazın - sınıf yolu kaynak dizini altında - request_fail_hystrix_timeout
DROP TABLE USERS IF EXISTS;
CREATE TABLE USERS (
user_id BIGINT IDENTITY NOT NULL PRIMARY KEY,
first_name VARCHAR(20),
last_name VARCHAR(20)
);Gösterilen şekilde KULLANICILAR modeli için bir POJO sınıfı oluşturun -
package com.tutorialspoint.batchservicedemo;
public class User {
private String lastName;
private String firstName;
public User() {
}
public User(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@Override
public String toString() {
return "firstName: " + firstName + ", lastName: " + lastName;
}
}Şimdi, verileri CSV dosyasından okuduktan sonra ve verileri SQL'e yazmadan önce işlemleri yapmak için bir ara işlemci oluşturun.
package com.tutorialspoint.batchservicedemo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
public class UserItemProcessor implements ItemProcessor<User, User> {
private static final Logger log = LoggerFactory.getLogger(UserItemProcessor.class);
@Override
public User process(final User user) throws Exception {
final String firstName = user.getFirstName().toUpperCase();
final String lastName = user.getLastName().toUpperCase();
final User transformedPerson = new User(firstName, lastName);
log.info("Converting (" + user + ") into (" + transformedPerson + ")");
return transformedPerson;
}
}CSV'den verileri okumak ve aşağıda gösterildiği gibi SQL dosyasına yazmak için bir Batch yapılandırma dosyası oluşturalım. Yapılandırma sınıfı dosyasına @EnableBatchProcessing ek açıklamasını eklememiz gerekiyor. @EnableBatchProcessing ek açıklaması, Spring Boot uygulamanız için toplu işlemleri etkinleştirmek için kullanılır.
package com.tutorialspoint.batchservicedemo;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Autowired
public DataSource dataSource;
@Bean
public FlatFileItemReader<User> reader() {
FlatFileItemReader<User> reader = new FlatFileItemReader<User>();
reader.setResource(new ClassPathResource("file.csv"));
reader.setLineMapper(new DefaultLineMapper<User>() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "firstName", "lastName" });
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<User>() {
{
setTargetType(User.class);
}
});
}
});
return reader;
}
@Bean
public UserItemProcessor processor() {
return new UserItemProcessor();
}
@Bean
public JdbcBatchItemWriter<User> writer() {
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter<User>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<User>());
writer.setSql("INSERT INTO USERS (first_name, last_name) VALUES (:firstName, :lastName)");
writer.setDataSource(dataSource);
return writer;
}
@Bean
public Job importUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory.get("importUserJob").incrementer(
new RunIdIncrementer()).listener(listener).flow(step1()).end().build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1").<User, User>chunk(10).reader(reader()).processor(processor()).writer(writer()).build();
}
}reader() yöntemi, CSV dosyasından verileri okumak için kullanılır ve writer () yöntemi, bir verileri SQL'e yazmak için kullanılır.
Daha sonra, İş tamamlandıktan sonra bildirimde bulunmak için bir İş Tamamlama Bildirimi Dinleyici sınıfı yazmamız gerekecek.
package com.tutorialspoint.batchservicedemo;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Component;
@Component
public class JobCompletionNotificationListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED !! It's time to verify the results!!");
List<User> results = jdbcTemplate.query(
"SELECT first_name, last_name FROM USERS", new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int row) throws SQLException {
return new User(rs.getString(1), rs.getString(2));
}
});
for (User person : results) {
log.info("Found <" + person + "> in the database.");
}
}
}
}Şimdi, yürütülebilir bir JAR dosyası oluşturun ve aşağıdaki Maven veya Gradle komutlarını kullanarak Spring Boot uygulamasını çalıştırın.
Maven için komutu gösterildiği gibi kullanın -
mvn clean install"BUILD SUCCESS" sonrasında, JAR dosyasını hedef dizinin altında bulabilirsiniz.
Gradle için, komutu gösterildiği gibi kullanabilirsiniz -
gradle clean build"BUILD SUCCESSFUL" sonrasında, JAR dosyasını build / libs dizini altında bulabilirsiniz.
Burada verilen komutu kullanarak JAR dosyasını çalıştırın -
java –jar <JARFILE>Çıkışı gösterildiği gibi konsol penceresinde görebilirsiniz -
