Thuật toán phân loại - Cây quyết định
Giới thiệu về cây quyết định
Nói chung, phân tích cây quyết định là một công cụ mô hình dự báo có thể được áp dụng trên nhiều lĩnh vực. Cây quyết định có thể được xây dựng bằng cách tiếp cận thuật toán có thể phân chia tập dữ liệu theo nhiều cách khác nhau dựa trên các điều kiện khác nhau. Quyết định tress là thuật toán mạnh nhất thuộc loại thuật toán được giám sát.
Chúng có thể được sử dụng cho cả nhiệm vụ phân loại và hồi quy. Hai thực thể chính của cây là các nút quyết định, nơi dữ liệu được phân tách và rời đi, nơi chúng ta có kết quả. Ví dụ về cây nhị phân để dự đoán một người phù hợp hay không phù hợp cung cấp nhiều thông tin khác nhau như tuổi tác, thói quen ăn uống và thói quen tập thể dục, được đưa ra dưới đây:
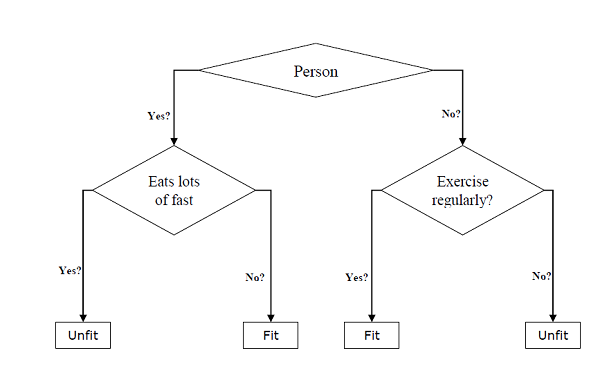
Trong cây quyết định ở trên, câu hỏi là các nút quyết định và kết quả cuối cùng là các lá. Chúng ta có hai loại cây quyết định sau:
Classification decision trees- Trong loại cây quyết định, biến quyết định là phân loại. Cây quyết định ở trên là một ví dụ về cây quyết định phân loại.
Regression decision trees - Trong loại cây quyết định này, biến quyết định là liên tục.
Triển khai thuật toán cây quyết định
Chỉ số Gini
Đây là tên của hàm chi phí được sử dụng để đánh giá các phân tách nhị phân trong tập dữ liệu và hoạt động với biến mục tiêu phân loại là "Thành công" hoặc "Thất bại".
Giá trị của chỉ số Gini càng cao thì độ đồng nhất càng cao. Giá trị chỉ số Gini hoàn hảo là 0 và tệ nhất là 0,5 (đối với bài toán 2 lớp). Chỉ số Gini cho một phân tách có thể được tính toán với sự trợ giúp của các bước sau:
Đầu tiên, tính toán chỉ số Gini cho các nút con bằng cách sử dụng công thức p ^ 2 + q ^ 2, là tổng bình phương của xác suất thành công và thất bại.
Tiếp theo, tính toán chỉ số Gini cho phần tách bằng cách sử dụng điểm Gini có trọng số của mỗi nút của phần tách đó.
Thuật toán Cây phân loại và hồi quy (CART) sử dụng phương pháp Gini để tạo ra các phân tách nhị phân.
Tạo tách
Phân tách về cơ bản bao gồm một thuộc tính trong tập dữ liệu và một giá trị. Chúng ta có thể tạo sự phân chia trong tập dữ liệu với sự trợ giúp của ba phần sau:
Part1: Calculating Gini Score - Chúng ta vừa thảo luận về phần này ở phần trước.
Part2: Splitting a dataset- Nó có thể được định nghĩa là tách một tập dữ liệu thành hai danh sách các hàng có chỉ mục của một thuộc tính và giá trị tách của thuộc tính đó. Sau khi nhận được hai nhóm - phải và trái, từ tập dữ liệu, chúng ta có thể tính toán giá trị của phép chia bằng cách sử dụng điểm Gini được tính ở phần đầu tiên. Giá trị phân tách sẽ quyết định thuộc tính sẽ nằm trong nhóm nào.
Part3: Evaluating all splits- Phần tiếp theo sau khi tìm điểm Gini và bộ dữ liệu tách là đánh giá tất cả các lần tách. Với mục đích này, trước tiên, chúng ta phải kiểm tra mọi giá trị được liên kết với từng thuộc tính dưới dạng phân tách ứng viên. Sau đó, chúng ta cần tìm ra mức phân chia tốt nhất có thể bằng cách đánh giá chi phí của việc phân chia. Phần tách tốt nhất sẽ được sử dụng như một nút trong cây quyết định.
Xây dựng cây
Như chúng ta biết rằng một cây có nút gốc và các nút đầu cuối. Sau khi tạo nút gốc, chúng ta có thể xây dựng cây bằng hai phần sau:
Phần 1: Tạo nút đầu cuối
Trong khi tạo các nút đầu cuối của cây quyết định, một điểm quan trọng là quyết định thời điểm ngừng phát triển cây hoặc tạo các nút đầu cuối khác. Nó có thể được thực hiện bằng cách sử dụng hai tiêu chí cụ thể là độ sâu cây tối đa và bản ghi nút tối thiểu như sau:
Maximum Tree Depth- Như tên cho thấy, đây là số nút tối đa trong một cây sau nút gốc. Chúng ta phải ngừng thêm các nút đầu cuối khi cây đạt đến độ sâu tối đa tức là khi một cây có số lượng nút đầu cuối tối đa.
Minimum Node Records- Nó có thể được định nghĩa là số lượng mẫu huấn luyện tối thiểu mà một nút nhất định chịu trách nhiệm. Chúng tôi phải ngừng thêm các nút đầu cuối khi cây đạt đến các bản ghi nút tối thiểu này hoặc dưới mức tối thiểu này.
Nút đầu cuối được sử dụng để đưa ra dự đoán cuối cùng.
Phần 2: Tách đệ quy
Như chúng ta đã hiểu về thời điểm tạo các nút đầu cuối, bây giờ chúng ta có thể bắt đầu xây dựng cây của mình. Tách đệ quy là một phương pháp để xây dựng cây. Trong phương pháp này, khi một nút được tạo, chúng ta có thể tạo các nút con (các nút được thêm vào một nút hiện có) một cách đệ quy trên mỗi nhóm dữ liệu, được tạo bằng cách tách tập dữ liệu, bằng cách gọi đi gọi lại cùng một hàm.
Sự dự đoán
Sau khi xây dựng cây quyết định, chúng ta cần đưa ra dự đoán về nó. Về cơ bản, dự đoán liên quan đến việc điều hướng cây quyết định với hàng dữ liệu được cung cấp cụ thể.
Chúng ta có thể đưa ra dự đoán với sự trợ giúp của hàm đệ quy, như đã làm ở trên. Quy trình dự đoán tương tự được gọi lại với các nút bên trái hoặc nút con bên phải.
Giả định
Sau đây là một số giả định chúng tôi đưa ra trong khi tạo cây quyết định -
Trong khi chuẩn bị cây quyết định, tập huấn luyện là nút gốc.
Bộ phân loại cây quyết định ưu tiên các giá trị tính năng được phân loại. Trong trường hợp nếu bạn muốn sử dụng các giá trị liên tục thì chúng phải được thực hiện cẩn thận trước khi xây dựng mô hình.
Dựa trên các giá trị của thuộc tính, các bản ghi được phân phối một cách đệ quy.
Phương pháp thống kê sẽ được sử dụng để đặt các thuộc tính tại bất kỳ vị trí nút nào, tức là nút gốc hoặc nút nội bộ.
Triển khai bằng Python
Thí dụ
Trong ví dụ sau, chúng tôi sẽ triển khai bộ phân loại Cây Quyết định trên bệnh Tiểu đường Ấn Độ Pima -
Đầu tiên, hãy bắt đầu với việc nhập các gói python cần thiết -
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_splitTiếp theo, tải xuống tập dữ liệu mống mắt từ liên kết web của nó như sau:
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
pima = pd.read_csv(r"C:\pima-indians-diabetes.csv", header=None, names=col_names)
pima.head()pregnant glucose bp skin insulin bmi pedigree age label
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
3 1 89 66 23 94 28.1 0.167 21 0
4 0 137 40 35 168 43.1 2.288 33 1Bây giờ, hãy chia tập dữ liệu thành các tính năng và biến mục tiêu như sau:
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variableTiếp theo, chúng tôi sẽ chia dữ liệu thành phân chia huấn luyện và thử nghiệm. Đoạn mã sau sẽ chia tập dữ liệu thành 70% dữ liệu đào tạo và 30% dữ liệu kiểm tra -
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)Tiếp theo, đào tạo mô hình với sự trợ giúp của lớp DecisionTreeClassifier của sklearn như sau:
clf = DecisionTreeClassifier()
clf = clf.fit(X_train,y_train)Cuối cùng, chúng ta cần phải dự đoán. Nó có thể được thực hiện với sự trợ giúp của tập lệnh sau:
y_pred = clf.predict(X_test)Tiếp theo, chúng ta có thể nhận được điểm chính xác, ma trận nhầm lẫn và báo cáo phân loại như sau:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)Đầu ra
Confusion Matrix:
[[116 30]
[ 46 39]]
Classification Report:
precision recall f1-score support
0 0.72 0.79 0.75 146
1 0.57 0.46 0.51 85
micro avg 0.67 0.67 0.67 231
macro avg 0.64 0.63 0.63 231
weighted avg 0.66 0.67 0.66 231
Accuracy: 0.670995670995671Hình dung cây quyết định
Cây quyết định trên có thể được hình dung với sự trợ giúp của đoạn mã sau:
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('Pima_diabetes_Tree.png')
Image(graph.create_png())