Thuật toán phân cụm - Phân cụm theo thứ bậc
Giới thiệu về phân cụm phân cấp
Phân cụm phân cấp là một thuật toán học tập không giám sát khác được sử dụng để nhóm các điểm dữ liệu không được gắn nhãn có các đặc điểm tương tự lại với nhau. Các thuật toán phân cụm phân cấp thuộc hai loại sau:
Agglomerative hierarchical algorithms- Trong các thuật toán phân cấp tích tụ, mỗi điểm dữ liệu được coi như một cụm duy nhất và sau đó hợp nhất hoặc kết tụ liên tiếp (cách tiếp cận từ dưới lên) các cặp cụm. Thứ bậc của các cụm được biểu diễn dưới dạng biểu đồ dendrogram hoặc cấu trúc cây.
Divisive hierarchical algorithms - Mặt khác, trong các thuật toán phân cấp phân chia, tất cả các điểm dữ liệu được coi như một cụm lớn và quá trình phân cụm bao gồm việc phân chia (cách tiếp cận từ trên xuống) một cụm lớn thành các cụm nhỏ khác nhau.
Các bước để thực hiện phân cụm phân cấp tổng hợp
Chúng tôi sẽ giải thích cụm từ phân cấp được sử dụng nhiều nhất và quan trọng, tức là kết tụ. Các bước thực hiện tương tự như sau:
Step 1- Coi mỗi điểm dữ liệu là một cụm đơn lẻ. Do đó, chúng ta sẽ có K cụm ở đầu. Số điểm dữ liệu cũng sẽ là K khi bắt đầu.
Step 2- Bây giờ, trong bước này, chúng ta cần tạo thành một cụm lớn bằng cách nối hai điểm dữ liệu tủ quần áo. Điều này sẽ dẫn đến tổng số các cụm K-1.
Step 3- Bây giờ, để tạo thành nhiều cụm hơn, chúng ta cần nối hai cụm tủ quần áo. Điều này sẽ dẫn đến tổng số K-2 cụm.
Step 4 - Bây giờ, để tạo thành một cụm lớn lặp lại ba bước trên cho đến khi K trở thành 0 tức là không còn điểm dữ liệu nào để tham gia.
Step 5 - Cuối cùng, sau khi tạo một cụm lớn duy nhất, các dendrograms sẽ được sử dụng để chia thành nhiều cụm tùy theo vấn đề.
Vai trò của Dendrograms trong phân cụm phân cấp tổng hợp
Như chúng ta đã thảo luận ở bước cuối cùng, vai trò của dendrogram bắt đầu khi cụm lớn được hình thành. Dendrogram sẽ được sử dụng để chia các cụm thành nhiều cụm điểm dữ liệu liên quan tùy thuộc vào vấn đề của chúng ta. Nó có thể được hiểu với sự trợ giúp của ví dụ sau:
ví dụ 1
Để hiểu, chúng ta hãy bắt đầu với việc nhập các thư viện bắt buộc như sau:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as npTiếp theo, chúng tôi sẽ vẽ các điểm dữ liệu mà chúng tôi đã lấy cho ví dụ này -
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],])
labels = range(1, 11)
plt.figure(figsize=(10, 7))
plt.subplots_adjust(bottom=0.1)
plt.scatter(X[:,0],X[:,1], label='True Position')
for label, x, y in zip(labels, X[:, 0], X[:, 1]):
plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom')
plt.show()
Từ sơ đồ trên, chúng ta rất dễ thấy rằng chúng ta có hai cụm trong các điểm dữ liệu nhưng trong dữ liệu thế giới thực, có thể có hàng nghìn cụm. Tiếp theo, chúng ta sẽ vẽ biểu đồ hình ảnh của các điểm dữ liệu bằng cách sử dụng thư viện Scipy -
from scipy.cluster.hierarchy import dendrogram, linkage
from matplotlib import pyplot as plt
linked = linkage(X, 'single')
labelList = range(1, 11)
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True)
plt.show()
Bây giờ, khi cụm lớn được hình thành, khoảng cách dọc dài nhất được chọn. Một đường thẳng đứng sau đó được vẽ qua nó như thể hiện trong sơ đồ sau. Khi đường ngang cắt đường màu xanh lam tại hai điểm, số cụm sẽ là hai.

Tiếp theo, chúng ta cần nhập lớp để phân cụm và gọi phương thức fit_p Dự đoán của nó để dự đoán cụm. Chúng tôi đang nhập lớp AgglomerativeClustering của thư viện sklearn.cluster -
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(X)Tiếp theo, vẽ sơ đồ cụm với sự trợ giúp của mã sau:
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')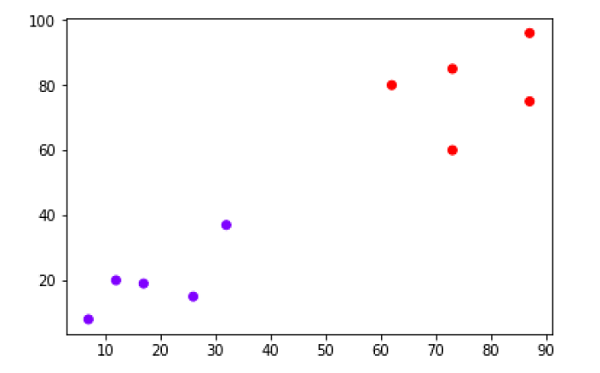
Sơ đồ trên cho thấy hai cụm từ điểm dữ liệu của chúng tôi.
Ví dụ2
Như chúng ta đã hiểu khái niệm về hình ảnh từ ví dụ đơn giản được thảo luận ở trên, chúng ta hãy chuyển sang một ví dụ khác, trong đó chúng ta đang tạo các cụm điểm dữ liệu trong Tập dữ liệu bệnh tiểu đường Ấn Độ Pima bằng cách sử dụng phân nhóm phân cấp -
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
import numpy as np
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
data.shape
(768, 9)
data.head()| SI. Không. | mang thai | Plas | Pres | da | kiểm tra | khối lượng | pedi | tuổi tác | lớp học |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33,6 | 0,627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26,6 | 0,351 | 31 | 0 |
| 2 | số 8 | 183 | 64 | 0 | 0 | 23.3 | 0,672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
cluster.fit_predict(patient_data)
plt.figure(figsize=(10, 7))
plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')