Logistische Regression in Python - Daten abrufen
In diesem Kapitel werden die Schritte zum Abrufen von Daten zum Durchführen einer logistischen Regression in Python ausführlich erläutert.
Datensatz herunterladen
Wenn Sie den zuvor erwähnten UCI-Datensatz noch nicht heruntergeladen haben, laden Sie ihn jetzt hier herunter . Klicken Sie auf den Datenordner. Sie sehen den folgenden Bildschirm -

Laden Sie die Datei bank.zip herunter, indem Sie auf den angegebenen Link klicken. Die Zip-Datei enthält die folgenden Dateien:

Wir werden die Datei bank.csv für unsere Modellentwicklung verwenden. Die Datei bank-names.txt enthält die Beschreibung der Datenbank, die Sie später benötigen werden. Die bank-full.csv enthält einen viel größeren Datensatz, den Sie für fortgeschrittenere Entwicklungen verwenden können.
Hier haben wir die Datei bank.csv in die herunterladbare Quell-Zip-Datei aufgenommen. Diese Datei enthält die durch Kommas getrennten Felder. Wir haben auch einige Änderungen an der Datei vorgenommen. Es wird empfohlen, dass Sie die im Projektquell-Zip enthaltene Datei für Ihr Lernen verwenden.
Lade Daten
Geben Sie die folgende Anweisung ein und führen Sie den Code aus, um die Daten aus der CSV-Datei zu laden, die Sie gerade kopiert haben.
In [2]: df = pd.read_csv('bank.csv', header=0)Sie können die geladenen Daten auch untersuchen, indem Sie die folgende Code-Anweisung ausführen:
IN [3]: df.head()Sobald der Befehl ausgeführt wird, wird die folgende Ausgabe angezeigt:
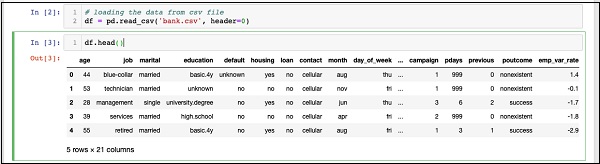
Grundsätzlich wurden die ersten fünf Zeilen der geladenen Daten gedruckt. Untersuche die 21 vorhandenen Spalten. Wir werden nur wenige Spalten davon für unsere Modellentwicklung verwenden.
Als nächstes müssen wir die Daten bereinigen. Die Daten können einige Zeilen mit enthaltenNaN. Verwenden Sie den folgenden Befehl, um solche Zeilen zu entfernen:
IN [4]: df = df.dropna()Glücklicherweise enthält die bank.csv keine Zeilen mit NaN, so dass dieser Schritt in unserem Fall nicht wirklich erforderlich ist. Im Allgemeinen ist es jedoch schwierig, solche Zeilen in einer riesigen Datenbank zu finden. Daher ist es immer sicherer, die obige Anweisung auszuführen, um die Daten zu bereinigen.
Note - Mit der folgenden Anweisung können Sie die Datengröße jederzeit problemlos überprüfen. -
IN [5]: print (df.shape)
(41188, 21)Die Anzahl der Zeilen und Spalten wird in der Ausgabe gedruckt, wie in der zweiten Zeile oben gezeigt.
Als nächstes müssen Sie die Eignung jeder Spalte für das Modell prüfen, das wir erstellen möchten.