Logistische Regression in Python - Kurzanleitung
Die logistische Regression ist eine statistische Methode zur Klassifizierung von Objekten. Dieses Kapitel gibt anhand einiger Beispiele eine Einführung in die logistische Regression.
Einstufung
Um die logistische Regression zu verstehen, sollten Sie wissen, was Klassifizierung bedeutet. Betrachten wir die folgenden Beispiele, um dies besser zu verstehen:
- Ein Arzt klassifiziert den Tumor als bösartig oder gutartig.
- Eine Banküberweisung kann betrügerisch oder echt sein.
Seit vielen Jahren führen Menschen solche Aufgaben aus - obwohl sie fehleranfällig sind. Die Frage ist, können wir Maschinen trainieren, um diese Aufgaben für uns mit einer besseren Genauigkeit zu erledigen?
Ein solches Beispiel für eine Maschine, die die Klassifizierung durchführt, ist die E-Mail Clientauf Ihrem Computer, der jede eingehende E-Mail als "Spam" oder "kein Spam" klassifiziert und dies mit einer ziemlich großen Genauigkeit tut. Die statistische Technik der logistischen Regression wurde im E-Mail-Client erfolgreich angewendet. In diesem Fall haben wir unsere Maschine geschult, um ein Klassifizierungsproblem zu lösen.
Die logistische Regression ist nur ein Teil des maschinellen Lernens, mit dem diese Art von Problem der binären Klassifizierung gelöst wird. Es gibt mehrere andere Techniken des maschinellen Lernens, die bereits entwickelt wurden und in der Praxis zur Lösung anderer Arten von Problemen eingesetzt werden.
Wenn Sie in allen obigen Beispielen festgestellt haben, hat das Ergebnis der Prädikation nur zwei Werte - Ja oder Nein. Wir nennen diese als Klassen - um zu sagen, dass unser Klassifizierer die Objekte in zwei Klassen klassifiziert. In technischer Hinsicht können wir sagen, dass das Ergebnis oder die Zielvariable dichotom ist.
Es gibt andere Klassifizierungsprobleme, bei denen die Ausgabe in mehr als zwei Klassen klassifiziert werden kann. Wenn Sie beispielsweise einen Korb voller Früchte haben, werden Sie aufgefordert, Früchte verschiedener Arten zu trennen. Jetzt kann der Korb Orangen, Äpfel, Mangos usw. enthalten. Wenn Sie also die Früchte trennen, trennen Sie sie in mehr als zwei Klassen. Dies ist ein multivariates Klassifizierungsproblem.
Bedenken Sie, dass eine Bank sich an Sie wendet, um eine Anwendung für maschinelles Lernen zu entwickeln, mit deren Hilfe sie die potenziellen Kunden identifizieren können, die bei ihnen eine Festgeldeinlage (von einigen Banken auch als Festgeld bezeichnet) eröffnen würden. Die Bank führt regelmäßig eine Umfrage mittels Telefonanrufen oder Webformularen durch, um Informationen über die potenziellen Kunden zu sammeln. Die Umfrage ist allgemeiner Natur und wird vor einem sehr großen Publikum durchgeführt, von dem viele möglicherweise nicht daran interessiert sind, sich mit dieser Bank selbst zu befassen. Von den übrigen sind möglicherweise nur wenige daran interessiert, eine Festgeldeinlage zu eröffnen. Andere könnten an anderen von der Bank angebotenen Einrichtungen interessiert sein. Die Umfrage wird also nicht unbedingt durchgeführt, um die Kunden zu identifizieren, die TDs öffnen. Ihre Aufgabe ist es, alle Kunden mit hoher Wahrscheinlichkeit, TD zu öffnen, anhand der umfangreichen Umfragedaten zu identifizieren, die die Bank mit Ihnen teilen wird.
Glücklicherweise ist eine solche Art von Daten für diejenigen öffentlich verfügbar, die maschinelle Lernmodelle entwickeln möchten. Diese Daten wurden von einigen Studenten der UC Irvine mit externer Finanzierung erstellt. Die Datenbank ist als Teil von verfügbarUCI Machine Learning Repositoryund wird von Studenten, Pädagogen und Forschern auf der ganzen Welt häufig verwendet. Die Daten können hier heruntergeladen werden .
Lassen Sie uns in den nächsten Kapiteln nun die Anwendungsentwicklung mit denselben Daten durchführen.
In diesem Kapitel werden wir den Prozess beim Einrichten eines Projekts zur Durchführung einer logistischen Regression in Python im Detail verstehen.
Jupyter installieren
Wir werden Jupyter verwenden - eine der am weitesten verbreiteten Plattformen für maschinelles Lernen. Wenn Sie Jupyter nicht auf Ihrem Computer installiert haben, laden Sie es hier herunter . Befolgen Sie zur Installation die Anweisungen auf der Website, um die Plattform zu installieren. Wie auf der Website vorgeschlagen, bevorzugen Sie möglicherweise die VerwendungAnaconda DistributionDies kommt zusammen mit Python und vielen häufig verwendeten Python-Paketen für wissenschaftliches Rechnen und Datenwissenschaft. Dadurch wird die Notwendigkeit verringert, diese Pakete einzeln zu installieren.
Starten Sie nach der erfolgreichen Installation von Jupyter ein neues Projekt. In diesem Stadium sieht Ihr Bildschirm wie folgt aus, um Ihren Code zu akzeptieren.
Ändern Sie nun den Namen des Projekts von Untitled1 to “Logistic Regression” indem Sie auf den Titelnamen klicken und ihn bearbeiten.
Zuerst werden wir mehrere Python-Pakete importieren, die wir in unserem Code benötigen.
Python-Pakete importieren
Geben Sie zu diesem Zweck den folgenden Code in den Code-Editor ein oder schneiden Sie ihn aus.
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splitIhre Notebook sollte zu diesem Zeitpunkt wie folgt aussehen -
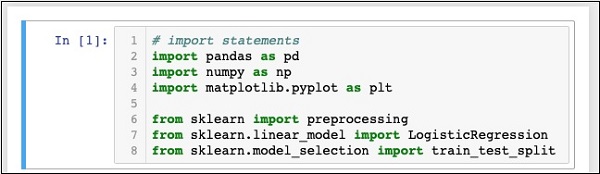
Führen Sie den Code aus, indem Sie auf klicken RunTaste. Wenn keine Fehler generiert werden, haben Sie Jupyter erfolgreich installiert und sind jetzt für den Rest der Entwicklung bereit.
Die ersten drei Importanweisungen importieren die Pakete pandas, numpy und matplotlib.pyplot in unserem Projekt. Die nächsten drei Anweisungen importieren die angegebenen Module aus sklearn.
Unsere nächste Aufgabe ist es, die für unser Projekt erforderlichen Daten herunterzuladen. Wir werden dies im nächsten Kapitel lernen.
In diesem Kapitel werden die Schritte zum Abrufen von Daten zum Durchführen einer logistischen Regression in Python ausführlich erläutert.
Datensatz herunterladen
Wenn Sie den zuvor erwähnten UCI-Datensatz noch nicht heruntergeladen haben, laden Sie ihn jetzt hier herunter . Klicken Sie auf den Datenordner. Sie sehen den folgenden Bildschirm -

Laden Sie die Datei bank.zip herunter, indem Sie auf den angegebenen Link klicken. Die Zip-Datei enthält die folgenden Dateien:

Wir werden die Datei bank.csv für unsere Modellentwicklung verwenden. Die Datei bank-names.txt enthält die Beschreibung der Datenbank, die Sie später benötigen werden. Die bank-full.csv enthält einen viel größeren Datensatz, den Sie für fortgeschrittenere Entwicklungen verwenden können.
Hier haben wir die Datei bank.csv in die herunterladbare Quell-Zip-Datei aufgenommen. Diese Datei enthält die durch Kommas getrennten Felder. Wir haben auch einige Änderungen an der Datei vorgenommen. Es wird empfohlen, dass Sie die im Projektquell-Zip enthaltene Datei für Ihr Lernen verwenden.
Lade Daten
Geben Sie die folgende Anweisung ein und führen Sie den Code aus, um die Daten aus der CSV-Datei zu laden, die Sie gerade kopiert haben.
In [2]: df = pd.read_csv('bank.csv', header=0)Sie können die geladenen Daten auch untersuchen, indem Sie die folgende Code-Anweisung ausführen:
IN [3]: df.head()Sobald der Befehl ausgeführt wird, wird die folgende Ausgabe angezeigt:
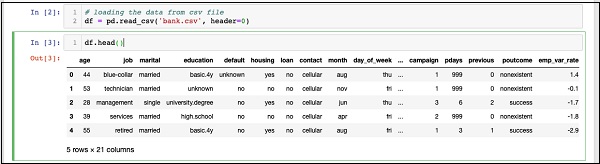
Grundsätzlich wurden die ersten fünf Zeilen der geladenen Daten gedruckt. Untersuche die 21 vorhandenen Spalten. Wir werden nur wenige Spalten davon für unsere Modellentwicklung verwenden.
Als nächstes müssen wir die Daten bereinigen. Die Daten können einige Zeilen mit enthaltenNaN. Verwenden Sie den folgenden Befehl, um solche Zeilen zu entfernen:
IN [4]: df = df.dropna()Glücklicherweise enthält die bank.csv keine Zeilen mit NaN, so dass dieser Schritt in unserem Fall nicht wirklich erforderlich ist. Im Allgemeinen ist es jedoch schwierig, solche Zeilen in einer riesigen Datenbank zu finden. Daher ist es immer sicherer, die obige Anweisung auszuführen, um die Daten zu bereinigen.
Note - Mit der folgenden Anweisung können Sie die Datengröße jederzeit problemlos überprüfen. -
IN [5]: print (df.shape)
(41188, 21)Die Anzahl der Zeilen und Spalten wird in der Ausgabe gedruckt, wie in der zweiten Zeile oben gezeigt.
Als nächstes müssen Sie die Eignung jeder Spalte für das Modell prüfen, das wir erstellen möchten.
Wenn eine Organisation eine Umfrage durchführt, versucht sie, so viele Informationen wie möglich vom Kunden zu sammeln, mit der Idee, dass diese Informationen zu einem späteren Zeitpunkt auf die eine oder andere Weise für die Organisation nützlich sein könnten. Um das aktuelle Problem zu lösen, müssen wir die Informationen abrufen, die für unser Problem direkt relevant sind.
Alle Felder anzeigen
Lassen Sie uns nun sehen, wie Sie die für uns nützlichen Datenfelder auswählen. Führen Sie die folgende Anweisung im Code-Editor aus.
In [6]: print(list(df.columns))Sie sehen die folgende Ausgabe -
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan',
'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx',
'euribor3m', 'nr_employed', 'y']Die Ausgabe zeigt die Namen aller Spalten in der Datenbank. Die letzte Spalte „y“ ist ein boolescher Wert, der angibt, ob dieser Kunde eine Festgeldeinlage bei der Bank hat. Die Werte dieses Feldes sind entweder "y" oder "n". Sie können die Beschreibung und den Zweck jeder Spalte in der Datei Banks-Name.txt lesen, die als Teil der Daten heruntergeladen wurde.
Unerwünschte Felder beseitigen
Wenn Sie die Spaltennamen untersuchen, werden Sie feststellen, dass einige der Felder für das jeweilige Problem keine Bedeutung haben. Zum Beispiel Felder wiemonth, day_of_week, Kampagne usw. nützen uns nichts. Wir werden diese Felder aus unserer Datenbank entfernen. Um eine Spalte zu löschen, verwenden wir den Befehl drop wie unten gezeigt -
In [8]: #drop columns which are not needed.
df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]],
axis = 1, inplace = True)Der Befehl besagt, dass die Spaltennummer 0, 3, 7, 8 usw. gelöscht wird. Verwenden Sie die folgende Anweisung, um sicherzustellen, dass der Index richtig ausgewählt ist:
In [7]: df.columns[9]
Out[7]: 'day_of_week'Dies gibt den Spaltennamen für den angegebenen Index aus.
Überprüfen Sie die Daten mit der head-Anweisung, nachdem Sie die nicht erforderlichen Spalten gelöscht haben. Die Bildschirmausgabe wird hier angezeigt -
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1Jetzt haben wir nur die Felder, die wir für unsere Datenanalyse und -vorhersage für wichtig halten. Die Wichtigkeit vonData Scientistkommt in diesem Schritt ins Bild. Der Datenwissenschaftler muss die geeigneten Spalten für die Modellbildung auswählen.
Zum Beispiel die Art von jobObwohl auf den ersten Blick möglicherweise nicht alle davon überzeugt sind, in die Datenbank aufgenommen zu werden, wird dies ein sehr nützliches Feld sein. Nicht alle Kundentypen öffnen den TD. Personen mit niedrigerem Einkommen öffnen die TDs möglicherweise nicht, während Personen mit höherem Einkommen ihr überschüssiges Geld normalerweise in TDs parken. Daher wird die Art des Jobs in diesem Szenario erheblich relevant. Wählen Sie ebenfalls sorgfältig die Spalten aus, die Ihrer Meinung nach für Ihre Analyse relevant sind.
Im nächsten Kapitel werden wir unsere Daten für die Erstellung des Modells vorbereiten.
Zum Erstellen des Klassifikators müssen die Daten in einem Format vorbereitet werden, das vom Klassifikatorerstellungsmodul angefordert wird. Wir bereiten die Daten damit vorOne Hot Encoding.
Daten codieren
Wir werden kurz diskutieren, was wir unter Codierung von Daten verstehen. Lassen Sie uns zuerst den Code ausführen. Führen Sie den folgenden Befehl im Codefenster aus.
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])Wie der Kommentar sagt, erzeugt die obige Anweisung die eine Hot-Codierung der Daten. Mal sehen, was es geschaffen hat? Untersuchen Sie die erstellten erstellten Daten“data” durch Drucken der Kopfdatensätze in der Datenbank.
In [11]: data.head()Sie sehen die folgende Ausgabe -
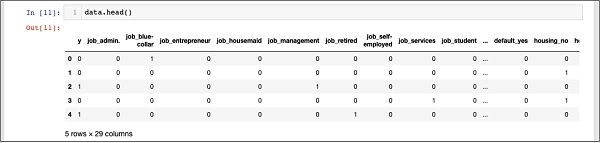
Um die obigen Daten zu verstehen, werden wir die Spaltennamen durch Ausführen von auflisten data.columns Befehl wie unten gezeigt -
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')Nun werden wir erklären, wie die eine Hot-Codierung von der gemacht wird get_dummiesBefehl. Die erste Spalte in der neu generierten Datenbank ist das Feld "y", das angibt, ob dieser Client einen TD abonniert hat oder nicht. Betrachten wir nun die Spalten, die codiert sind. Die erste codierte Spalte ist“job”. In der Datenbank finden Sie, dass die Spalte "Job" viele mögliche Werte wie "Admin", "Arbeiter", "Unternehmer" usw. enthält. Für jeden möglichen Wert haben wir eine neue Spalte in der Datenbank erstellt, an die der Spaltenname als Präfix angehängt ist.
Daher haben wir Spalten mit den Namen "job_admin", "job_blue -ollar" usw. Für jedes codierte Feld in unserer Originaldatenbank finden Sie eine Liste der in der erstellten Datenbank hinzugefügten Spalten mit allen möglichen Werten, die die Spalte in der Originaldatenbank annimmt. Untersuchen Sie die Liste der Spalten sorgfältig, um zu verstehen, wie die Daten einer neuen Datenbank zugeordnet werden.
Grundlegendes zur Datenzuordnung
Um die generierten Daten zu verstehen, drucken wir die gesamten Daten mit dem Befehl data aus. Die Teilausgabe nach Ausführung des Befehls ist unten dargestellt.
In [13]: data
Der obige Bildschirm zeigt die ersten zwölf Zeilen. Wenn Sie weiter nach unten scrollen, sehen Sie, dass die Zuordnung für alle Zeilen erfolgt.
Eine teilweise Bildschirmausgabe weiter unten in der Datenbank wird hier als Kurzreferenz angezeigt.
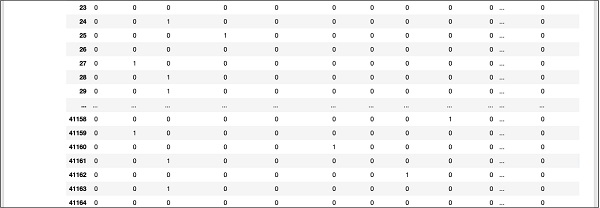
Um die zugeordneten Daten zu verstehen, untersuchen wir die erste Zeile.

Es heißt, dass dieser Kunde TD nicht abonniert hat, wie durch den Wert im Feld "y" angegeben. Es zeigt auch an, dass dieser Kunde ein "Blue Collar" -Kunde ist. Wenn Sie horizontal nach unten scrollen, sehen Sie, dass er eine „Wohnung“ hat und keinen „Kredit“ aufgenommen hat.
Nach dieser einen heißen Codierung benötigen wir etwas mehr Datenverarbeitung, bevor wir mit der Erstellung unseres Modells beginnen können.
Das "Unbekannte" fallen lassen
Wenn wir die Spalten in der zugeordneten Datenbank untersuchen, werden Sie feststellen, dass nur wenige Spalten mit "unbekannt" enden. Untersuchen Sie beispielsweise die Spalte bei Index 12 mit dem folgenden Befehl, der im Screenshot angezeigt wird:
In [14]: data.columns[12]
Out[14]: 'job_unknown'Dies zeigt an, dass der Auftrag für den angegebenen Kunden unbekannt ist. Offensichtlich macht es keinen Sinn, solche Spalten in unsere Analyse und Modellbildung aufzunehmen. Daher sollten alle Spalten mit dem Wert "unbekannt" gelöscht werden. Dies geschieht mit dem folgenden Befehl:
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)Stellen Sie sicher, dass Sie die richtigen Spaltennummern angeben. Im Zweifelsfall können Sie den Spaltennamen jederzeit überprüfen, indem Sie den Index wie zuvor beschrieben im Befehl column angeben.
Nachdem Sie die unerwünschten Spalten gelöscht haben, können Sie die endgültige Liste der Spalten überprüfen, wie in der folgenden Ausgabe gezeigt.
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')Zu diesem Zeitpunkt sind unsere Daten für die Modellbildung bereit.
Wir haben ungefähr einundvierzigtausend und ungerade Aufzeichnungen. Wenn wir die gesamten Daten für die Modellbildung verwenden, bleiben uns keine Daten zum Testen. Im Allgemeinen teilen wir den gesamten Datensatz in zwei Teile auf, beispielsweise 70/30 Prozent. Wir verwenden 70% der Daten für die Modellbildung und den Rest zum Testen der Vorhersagegenauigkeit unseres erstellten Modells. Sie können je nach Anforderung ein anderes Aufteilungsverhältnis verwenden.
Erstellen eines Features-Arrays
Bevor wir die Daten aufteilen, teilen wir die Daten in zwei Arrays X und Y auf. Das X-Array enthält alle Features (Datenspalten), die wir analysieren möchten, und das Y-Array ist ein eindimensionales Array von Booleschen Werten, dessen Ausgabe ist Die Vorhersage. Um dies zu verstehen, lassen Sie uns einen Code ausführen.
Führen Sie zunächst die folgende Python-Anweisung aus, um das X-Array zu erstellen:
In [17]: X = data.iloc[:,1:]Um den Inhalt von zu untersuchen X verwenden headum einige erste Datensätze zu drucken. Der folgende Bildschirm zeigt den Inhalt des X-Arrays.
In [18]: X.head ()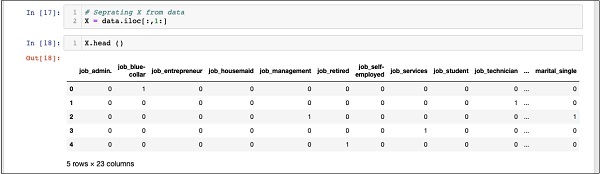
Das Array besteht aus mehreren Zeilen und 23 Spalten.
Als nächstes erstellen wir ein Ausgabearray mit “y”Werte.
Ausgabearray erstellen
Verwenden Sie die folgende Python-Anweisung, um ein Array für die Spalte mit den vorhergesagten Werten zu erstellen:
In [19]: Y = data.iloc[:,0]Überprüfen Sie den Inhalt, indem Sie anrufen head. Die folgende Bildschirmausgabe zeigt das Ergebnis -
In [20]: Y.head()
Out[20]: 0 0
1 0
2 1
3 0
4 1
Name: y, dtype: int64Teilen Sie nun die Daten mit dem folgenden Befehl auf:
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)Dadurch werden die vier aufgerufenen Arrays erstellt X_train, Y_train, X_test, and Y_test. Nach wie vor können Sie den Inhalt dieser Arrays mit dem Befehl head untersuchen. Wir werden X_train- und Y_train-Arrays zum Trainieren unseres Modells und X_test- und Y_test-Arrays zum Testen und Validieren verwenden.
Jetzt sind wir bereit, unseren Klassifikator zu bauen. Wir werden uns im nächsten Kapitel damit befassen.
Es ist nicht erforderlich, dass Sie den Klassifikator von Grund auf neu erstellen müssen. Das Erstellen von Klassifizierern ist komplex und erfordert Kenntnisse in verschiedenen Bereichen wie Statistik, Wahrscheinlichkeitstheorien, Optimierungstechniken usw. Auf dem Markt sind mehrere vorgefertigte Bibliotheken verfügbar, die eine vollständig getestete und sehr effiziente Implementierung dieser Klassifizierer aufweisen. Wir werden ein solches vorgefertigtes Modell aus demsklearn.
Der sklearn Classifier
Das Erstellen des Klassifikators für die logistische Regression aus dem sklearn-Toolkit ist trivial und erfolgt in einer einzigen Programmanweisung, wie hier gezeigt.
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)Sobald der Klassifikator erstellt ist, geben Sie Ihre Trainingsdaten in den Klassifikator ein, damit dieser seine internen Parameter optimieren und für die Vorhersagen Ihrer zukünftigen Daten bereit sein kann. Um den Klassifikator abzustimmen, führen wir die folgende Anweisung aus:
In [23]: classifier.fit(X_train, Y_train)Der Klassifikator ist jetzt zum Testen bereit. Der folgende Code ist die Ausgabe der Ausführung der beiden oben genannten Anweisungen -
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2', random_state=0,
solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))Jetzt können wir den erstellten Klassifikator testen. Wir werden dies im nächsten Kapitel behandeln.
Wir müssen den oben erstellten Klassifikator testen, bevor wir ihn für die Produktion verwenden. Wenn die Tests ergeben, dass das Modell nicht die gewünschte Genauigkeit aufweist, müssen wir den obigen Vorgang wiederholen, einen anderen Satz von Funktionen (Datenfeldern) auswählen, das Modell erneut erstellen und es testen. Dies ist ein iterativer Schritt, bis der Klassifikator Ihre Anforderungen an die gewünschte Genauigkeit erfüllt. Testen wir also unseren Klassifikator.
Vorhersage von Testdaten
Zum Testen des Klassifikators verwenden wir die in der früheren Phase generierten Testdaten. Wir nennen daspredict Methode für das erstellte Objekt und übergeben Sie die X Array der Testdaten wie im folgenden Befehl gezeigt -
In [24]: predicted_y = classifier.predict(X_test)Dies erzeugt ein eindimensionales Array für den gesamten Trainingsdatensatz, das die Vorhersage für jede Zeile im X-Array gibt. Sie können dieses Array mit dem folgenden Befehl untersuchen:
In [25]: predicted_yDas Folgende ist die Ausgabe bei der Ausführung der beiden oben genannten Befehle -
Out[25]: array([0, 0, 0, ..., 0, 0, 0])Die Ausgabe zeigt an, dass die ersten und letzten drei Kunden nicht die potenziellen Kandidaten für die Term Deposit. Sie können das gesamte Array untersuchen, um die potenziellen Kunden zu sortieren. Verwenden Sie dazu das folgende Python-Code-Snippet:
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")Die Ausgabe des Ausführens des obigen Codes wird unten gezeigt -

Die Ausgabe zeigt die Indizes aller Zeilen, die wahrscheinlich Kandidaten für das Abonnieren von TD sind. Sie können diese Ausgabe jetzt an das Marketing-Team der Bank weitergeben, das die Kontaktdaten für jeden Kunden in der ausgewählten Zeile abruft und mit seiner Arbeit fortfährt.
Bevor wir dieses Modell in Produktion nehmen, müssen wir die Genauigkeit der Vorhersage überprüfen.
Überprüfen der Genauigkeit
Um die Genauigkeit des Modells zu testen, verwenden Sie die Bewertungsmethode für den Klassifikator wie unten gezeigt -
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))Die Bildschirmausgabe zum Ausführen dieses Befehls wird unten angezeigt -
Accuracy: 0.90Es zeigt, dass die Genauigkeit unseres Modells 90% beträgt, was in den meisten Anwendungen als sehr gut angesehen wird. Somit ist keine weitere Abstimmung erforderlich. Jetzt ist unser Kunde bereit, die nächste Kampagne durchzuführen, die Liste potenzieller Kunden abzurufen und sie für die Eröffnung des TD mit einer wahrscheinlich hohen Erfolgsrate zu verfolgen.
Wie Sie aus dem obigen Beispiel gesehen haben, ist die Anwendung der logistischen Regression für maschinelles Lernen keine schwierige Aufgabe. Es hat jedoch seine eigenen Einschränkungen. Die logistische Regression kann eine große Anzahl von kategorialen Merkmalen nicht verarbeiten. In dem bisher diskutierten Beispiel haben wir die Anzahl der Features sehr stark reduziert.
Wenn diese Merkmale für unsere Vorhersage wichtig wären, wären wir gezwungen gewesen, sie einzubeziehen, aber dann würde uns die logistische Regression keine gute Genauigkeit liefern. Die logistische Regression ist auch anfällig für Überanpassungen. Es kann nicht auf ein nichtlineares Problem angewendet werden. Es funktioniert schlecht mit unabhängigen Variablen, die nicht mit dem Ziel korreliert sind und miteinander korreliert sind. Daher müssen Sie die Eignung der logistischen Regression für das zu lösende Problem sorgfältig prüfen.
Es gibt viele Bereiche des maschinellen Lernens, in denen andere Techniken entwickelt wurden. Um nur einige zu nennen, haben wir Algorithmen wie k-nächste Nachbarn (kNN), lineare Regression, Support Vector Machines (SVM), Entscheidungsbäume, naive Bayes und so weiter. Bevor Sie ein bestimmtes Modell fertigstellen, müssen Sie die Anwendbarkeit dieser verschiedenen Techniken auf das Problem bewerten, das wir zu lösen versuchen.
Die logistische Regression ist eine statistische Technik der binären Klassifizierung. In diesem Lernprogramm haben Sie gelernt, wie Sie die Maschine für die Verwendung der logistischen Regression trainieren. Die wichtigste Voraussetzung für die Erstellung von Modellen für maschinelles Lernen ist die Verfügbarkeit der Daten. Ohne angemessene und relevante Daten können Sie die Maschine nicht einfach zum Lernen bringen.
Sobald Sie Daten haben, besteht Ihre nächste Hauptaufgabe darin, die Daten zu bereinigen, unerwünschte Zeilen und Felder zu entfernen und die entsprechenden Felder für Ihre Modellentwicklung auszuwählen. Danach müssen Sie die Daten in ein Format abbilden, das der Klassifizierer für sein Training benötigt. Daher ist die Datenaufbereitung eine Hauptaufgabe in jeder maschinellen Lernanwendung. Sobald Sie mit den Daten fertig sind, können Sie einen bestimmten Klassifizierertyp auswählen.
In diesem Lernprogramm haben Sie gelernt, wie Sie einen in der sklearnBibliothek. Um den Klassifikator zu trainieren, verwenden wir ungefähr 70% der Daten zum Trainieren des Modells. Wir verwenden den Rest der Daten zum Testen. Wir testen die Genauigkeit des Modells. Wenn dies nicht innerhalb akzeptabler Grenzen liegt, kehren wir zur Auswahl der neuen Funktionen zurück.
Verfolgen Sie erneut den gesamten Prozess der Datenaufbereitung, trainieren Sie das Modell und testen Sie es, bis Sie mit seiner Genauigkeit zufrieden sind. Bevor Sie ein maschinelles Lernprojekt aufnehmen, müssen Sie eine Vielzahl von Techniken erlernen und kennenlernen, die bisher entwickelt und in der Branche erfolgreich angewendet wurden.