Logistische Regression in Python - Daten aufteilen
Wir haben ungefähr einundvierzigtausend und ungerade Aufzeichnungen. Wenn wir die gesamten Daten für die Modellbildung verwenden, bleiben uns keine Daten zum Testen. Im Allgemeinen teilen wir den gesamten Datensatz in zwei Teile auf, beispielsweise 70/30 Prozent. Wir verwenden 70% der Daten für die Modellbildung und den Rest zum Testen der Vorhersagegenauigkeit unseres erstellten Modells. Sie können je nach Anforderung ein anderes Aufteilungsverhältnis verwenden.
Erstellen eines Features-Arrays
Bevor wir die Daten aufteilen, teilen wir die Daten in zwei Arrays X und Y auf. Das X-Array enthält alle Features (Datenspalten), die wir analysieren möchten, und das Y-Array ist ein eindimensionales Array von Booleschen Werten, dessen Ausgabe ist Die Vorhersage. Um dies zu verstehen, lassen Sie uns einen Code ausführen.
Führen Sie zunächst die folgende Python-Anweisung aus, um das X-Array zu erstellen:
In [17]: X = data.iloc[:,1:]Um den Inhalt von zu untersuchen X verwenden headum einige erste Datensätze zu drucken. Der folgende Bildschirm zeigt den Inhalt des X-Arrays.
In [18]: X.head ()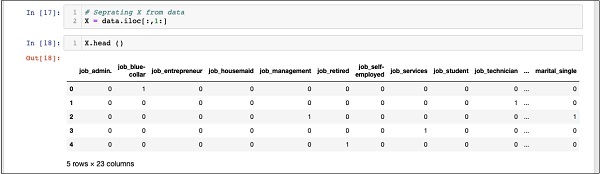
Das Array besteht aus mehreren Zeilen und 23 Spalten.
Als nächstes erstellen wir ein Ausgabearray mit “y”Werte.
Ausgabearray erstellen
Verwenden Sie die folgende Python-Anweisung, um ein Array für die Spalte mit den vorhergesagten Werten zu erstellen:
In [19]: Y = data.iloc[:,0]Überprüfen Sie den Inhalt, indem Sie anrufen head. Die folgende Bildschirmausgabe zeigt das Ergebnis -
In [20]: Y.head()
Out[20]: 0 0
1 0
2 1
3 0
4 1
Name: y, dtype: int64Teilen Sie nun die Daten mit dem folgenden Befehl auf:
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)Dadurch werden die vier aufgerufenen Arrays erstellt X_train, Y_train, X_test, and Y_test. Nach wie vor können Sie den Inhalt dieser Arrays mit dem Befehl head untersuchen. Wir werden X_train- und Y_train-Arrays zum Trainieren unseres Modells und X_test- und Y_test-Arrays zum Testen und Validieren verwenden.
Jetzt sind wir bereit, unseren Klassifikator zu bauen. Wir werden uns im nächsten Kapitel damit befassen.