Logistische Regression in Python - Daten vorbereiten
Zum Erstellen des Klassifikators müssen die Daten in einem Format vorbereitet werden, das vom Klassifikatorerstellungsmodul angefordert wird. Wir bereiten die Daten damit vorOne Hot Encoding.
Daten codieren
Wir werden kurz diskutieren, was wir unter Codierung von Daten verstehen. Lassen Sie uns zuerst den Code ausführen. Führen Sie den folgenden Befehl im Codefenster aus.
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])Wie der Kommentar sagt, erzeugt die obige Anweisung die eine Hot-Codierung der Daten. Mal sehen, was es geschaffen hat? Untersuchen Sie die erstellten erstellten Daten“data” durch Drucken der Kopfdatensätze in der Datenbank.
In [11]: data.head()Sie sehen die folgende Ausgabe -
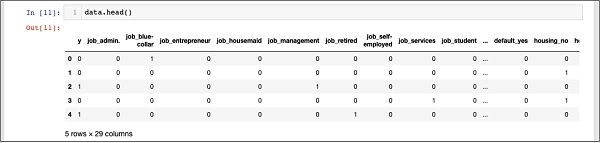
Um die obigen Daten zu verstehen, werden wir die Spaltennamen durch Ausführen von auflisten data.columns Befehl wie unten gezeigt -
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')Nun werden wir erklären, wie die eine Hot-Codierung von der gemacht wird get_dummiesBefehl. Die erste Spalte in der neu generierten Datenbank ist das Feld "y", das angibt, ob dieser Client einen TD abonniert hat oder nicht. Betrachten wir nun die Spalten, die codiert sind. Die erste codierte Spalte ist“job”. In der Datenbank finden Sie, dass die Spalte "Job" viele mögliche Werte wie "Admin", "Arbeiter", "Unternehmer" usw. enthält. Für jeden möglichen Wert haben wir eine neue Spalte in der Datenbank erstellt, an die der Spaltenname als Präfix angehängt ist.
Daher haben wir Spalten mit den Namen "job_admin", "job_blue -ollar" usw. Für jedes codierte Feld in unserer Originaldatenbank finden Sie eine Liste der in der erstellten Datenbank hinzugefügten Spalten mit allen möglichen Werten, die die Spalte in der Originaldatenbank annimmt. Untersuchen Sie die Liste der Spalten sorgfältig, um zu verstehen, wie die Daten einer neuen Datenbank zugeordnet werden.
Grundlegendes zur Datenzuordnung
Um die generierten Daten zu verstehen, drucken wir die gesamten Daten mit dem Befehl data aus. Die Teilausgabe nach Ausführung des Befehls ist unten dargestellt.
In [13]: data
Der obige Bildschirm zeigt die ersten zwölf Zeilen. Wenn Sie weiter nach unten scrollen, sehen Sie, dass die Zuordnung für alle Zeilen erfolgt.
Eine teilweise Bildschirmausgabe weiter unten in der Datenbank wird hier als Kurzreferenz angezeigt.
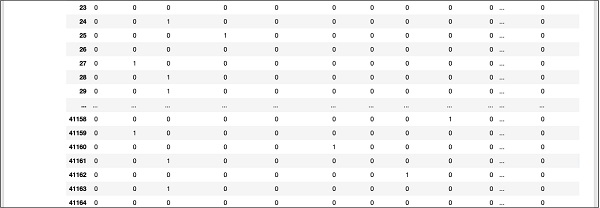
Um die zugeordneten Daten zu verstehen, untersuchen wir die erste Zeile.

Es heißt, dass dieser Kunde TD nicht abonniert hat, wie durch den Wert im Feld "y" angegeben. Es zeigt auch an, dass dieser Kunde ein "Blue Collar" -Kunde ist. Wenn Sie horizontal nach unten scrollen, sehen Sie, dass er eine „Wohnung“ hat und keinen „Kredit“ aufgenommen hat.
Nach dieser einen heißen Codierung benötigen wir etwas mehr Datenverarbeitung, bevor wir mit der Erstellung unseres Modells beginnen können.
Das "Unbekannte" fallen lassen
Wenn wir die Spalten in der zugeordneten Datenbank untersuchen, werden Sie feststellen, dass nur wenige Spalten mit "unbekannt" enden. Untersuchen Sie beispielsweise die Spalte bei Index 12 mit dem folgenden Befehl, der im Screenshot angezeigt wird:
In [14]: data.columns[12]
Out[14]: 'job_unknown'Dies zeigt an, dass der Auftrag für den angegebenen Kunden unbekannt ist. Offensichtlich macht es keinen Sinn, solche Spalten in unsere Analyse und Modellbildung aufzunehmen. Daher sollten alle Spalten mit dem Wert "unbekannt" gelöscht werden. Dies geschieht mit dem folgenden Befehl:
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)Stellen Sie sicher, dass Sie die richtigen Spaltennummern angeben. Im Zweifelsfall können Sie den Spaltennamen jederzeit überprüfen, indem Sie den Index wie zuvor beschrieben im Befehl column angeben.
Nachdem Sie die unerwünschten Spalten gelöscht haben, können Sie die endgültige Liste der Spalten überprüfen, wie in der folgenden Ausgabe gezeigt.
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')Zu diesem Zeitpunkt sind unsere Daten für die Modellbildung bereit.