Maschinelles Lernen - Kategorien
Maschinelles Lernen wird grob in die folgenden Überschriften eingeteilt:
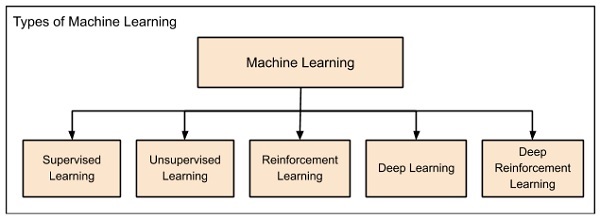
Das maschinelle Lernen entwickelte sich von links nach rechts, wie im obigen Diagramm gezeigt.
Zunächst begannen die Forscher mit Supervised Learning. Dies ist der Fall bei der zuvor diskutierten Vorhersage der Immobilienpreise.
Es folgte unbeaufsichtigtes Lernen, bei dem die Maschine ohne Aufsicht selbstständig lernen kann.
Wissenschaftler entdeckten weiter, dass es eine gute Idee sein könnte, die Maschine zu belohnen, wenn sie die Arbeit auf die erwartete Weise erledigt, und es kam das Reinforcement Learning.
Sehr bald sind die Daten, die heutzutage verfügbar sind, so umfangreich geworden, dass die bisher entwickelten konventionellen Techniken die Big Data nicht analysieren und uns die Vorhersagen liefern konnten.
So kam das tiefe Lernen, bei dem das menschliche Gehirn in den künstlichen neuronalen Netzen (ANN) simuliert wird, die in unseren Binärcomputern erstellt wurden.
Die Maschine lernt jetzt selbstständig mit der hohen Rechenleistung und den riesigen Speicherressourcen, die heute verfügbar sind.
Es wird nun beobachtet, dass Deep Learning viele der zuvor unlösbaren Probleme gelöst hat.
Die Technik wird jetzt weiterentwickelt, indem Anreize für Deep Learning-Netzwerke als Auszeichnungen vergeben werden, und schließlich kommt Deep Reinforcement Learning.
Lassen Sie uns nun jede dieser Kategorien genauer untersuchen.
Überwachtes Lernen
Betreutes Lernen ist analog zum Training eines Kindes zum Laufen. Sie halten die Hand des Kindes, zeigen ihm, wie er seinen Fuß nach vorne nimmt, gehen zu einer Demonstration und so weiter, bis das Kind lernt, selbstständig zu gehen.
Regression
In ähnlicher Weise geben Sie beim überwachten Lernen dem Computer konkrete bekannte Beispiele. Sie sagen, dass für einen gegebenen Merkmalswert x1 die Ausgabe y1 ist, für x2 y2, für x3 y3 und so weiter. Basierend auf diesen Daten lassen Sie den Computer eine empirische Beziehung zwischen x und y herausfinden.
Sobald die Maschine auf diese Weise mit einer ausreichenden Anzahl von Datenpunkten trainiert wurde, würden Sie die Maschine nun bitten, Y für ein gegebenes X vorherzusagen. Angenommen, Sie kennen den tatsächlichen Wert von Y für dieses gegebene X, können Sie ableiten ob die Vorhersage der Maschine korrekt ist.
So testen Sie anhand der bekannten Testdaten, ob die Maschine gelernt hat. Sobald Sie zufrieden sind, dass die Maschine die Vorhersagen mit der gewünschten Genauigkeit (z. B. 80 bis 90%) ausführen kann, können Sie das weitere Training der Maschine beenden.
Jetzt können Sie die Maschine sicher verwenden, um Vorhersagen für unbekannte Datenpunkte zu treffen, oder die Maschine bitten, Y für ein bestimmtes X vorherzusagen, für das Sie den tatsächlichen Wert von Y nicht kennen. Dieses Training fällt unter die Regression, über die wir gesprochen haben vorhin.
Einstufung
Sie können auch Techniken des maschinellen Lernens für Klassifizierungsprobleme verwenden. Bei Klassifizierungsproblemen klassifizieren Sie Objekte ähnlicher Art in eine einzelne Gruppe. Zum Beispiel möchten Sie in einer Gruppe von 100 Schülern sagen, dass Sie sie basierend auf ihrer Größe in drei Gruppen einteilen möchten - kurz, mittel und lang. Wenn Sie die Größe jedes Schülers messen, ordnen Sie ihn einer richtigen Gruppe zu.
Wenn ein neuer Schüler hereinkommt, werden Sie ihn in eine geeignete Gruppe einordnen, indem Sie seine Größe messen. Indem Sie die Prinzipien des Regressionstrainings befolgen, trainieren Sie die Maschine, um einen Schüler anhand seiner Funktion - der Größe - zu klassifizieren. Wenn die Maschine lernt, wie die Gruppen gebildet werden, kann sie jeden unbekannten neuen Schüler korrekt klassifizieren. Sie würden die Testdaten erneut verwenden, um zu überprüfen, ob die Maschine Ihre Klassifizierungstechnik gelernt hat, bevor Sie das entwickelte Modell in Produktion nehmen.
Beim überwachten Lernen hat die KI ihre Reise wirklich begonnen. Diese Technik wurde in mehreren Fällen erfolgreich angewendet. Sie haben dieses Modell verwendet, während Sie die handschriftliche Erkennung auf Ihrem Computer durchgeführt haben. Für das überwachte Lernen wurden mehrere Algorithmen entwickelt. Sie werden in den folgenden Kapiteln mehr darüber erfahren.
Unbeaufsichtigtes Lernen
Beim unbeaufsichtigten Lernen geben wir keine Zielvariable für die Maschine an, sondern fragen die Maschine: „Was können Sie mir über X sagen?“. Insbesondere können wir Fragen stellen, z. B. bei einem riesigen Datensatz X: „Was sind die fünf besten Gruppen, die wir aus X machen können?“. oder "Welche Funktionen treten in X am häufigsten zusammen auf?". Um zu den Antworten auf solche Fragen zu gelangen, können Sie verstehen, dass die Anzahl der Datenpunkte, die die Maschine benötigen würde, um eine Strategie abzuleiten, sehr groß wäre. Im Falle eines überwachten Lernens kann die Maschine mit sogar einigen Tausend Datenpunkten trainiert werden. Bei unbeaufsichtigtem Lernen beginnt die Anzahl der Datenpunkte, die für das Lernen angemessen akzeptiert werden, jedoch bei einigen Millionen. Heutzutage sind die Daten im Allgemeinen reichlich verfügbar. Die Daten müssen idealerweise kuratiert werden. Die Datenmenge, die kontinuierlich in einem sozialen Netzwerk fließt, ist in den meisten Fällen eine unmögliche Aufgabe.
Die folgende Abbildung zeigt die Grenze zwischen den gelben und roten Punkten, die durch unbeaufsichtigtes maschinelles Lernen bestimmt wurde. Sie können deutlich sehen, dass die Maschine die Klasse jedes der schwarzen Punkte mit einer ziemlich guten Genauigkeit bestimmen kann.
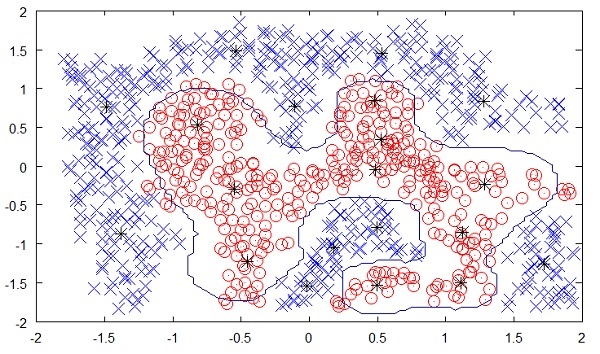
Quelle:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
Das unbeaufsichtigte Lernen hat in vielen modernen KI-Anwendungen wie Gesichtserkennung, Objekterkennung usw. einen großen Erfolg gezeigt.
Verstärkungslernen
Ziehen Sie in Betracht, einen Hund zu trainieren. Wir trainieren unser Haustier, um einen Ball zu uns zu bringen. Wir werfen den Ball in einer bestimmten Entfernung und bitten den Hund, ihn uns zurückzuholen. Jedes Mal, wenn der Hund dies richtig macht, belohnen wir den Hund. Langsam lernt der Hund, dass die richtige Arbeit ihm eine Belohnung gibt, und dann beginnt der Hund jedes Mal in der Zukunft, die Arbeit richtig zu machen. Genau dieses Konzept wird beim Lernen vom Typ „Verstärkung“ angewendet. Die Technik wurde ursprünglich für Maschinen zum Spielen entwickelt. Die Maschine erhält einen Algorithmus zur Analyse aller möglichen Bewegungen in jeder Phase des Spiels. Die Maschine kann eine der Bewegungen zufällig auswählen. Wenn der Zug richtig ist, wird die Maschine belohnt, andernfalls kann sie bestraft werden. Langsam beginnt die Maschine zwischen richtigen und falschen Zügen zu unterscheiden und lernt nach mehreren Iterationen, das Spielrätsel mit einer besseren Genauigkeit zu lösen. Die Genauigkeit des Gewinns des Spiels würde sich verbessern, wenn die Maschine immer mehr Spiele spielt.
Der gesamte Prozess kann in der folgenden Abbildung dargestellt werden:
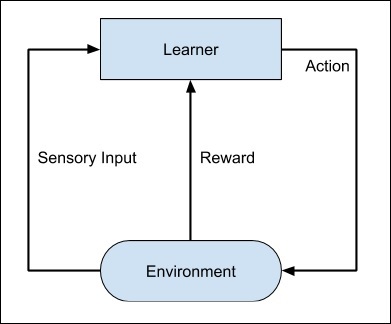
Diese Technik des maschinellen Lernens unterscheidet sich vom überwachten Lernen darin, dass Sie die gekennzeichneten Eingabe / Ausgabe-Paare nicht angeben müssen. Der Fokus liegt darauf, das Gleichgewicht zwischen der Erforschung der neuen Lösungen und der Nutzung der erlernten Lösungen zu finden.
Tiefes Lernen
Das Deep Learning ist ein Modell, das auf künstlichen neuronalen Netzen (ANN) basiert, insbesondere auf Faltungs-Neuronalen Netzen (CNN). Es gibt verschiedene Architekturen, die beim tiefen Lernen verwendet werden, wie tiefe neuronale Netze, tiefe Glaubensnetzwerke, wiederkehrende neuronale Netze und Faltungs-neuronale Netze.
Diese Netzwerke wurden erfolgreich bei der Lösung der Probleme von Computer Vision, Spracherkennung, Verarbeitung natürlicher Sprache, Bioinformatik, Arzneimitteldesign, medizinischer Bildanalyse und Spielen eingesetzt. Es gibt mehrere andere Bereiche, in denen Deep Learning proaktiv angewendet wird. Das tiefe Lernen erfordert enorme Rechenleistung und enorme Datenmengen, die heutzutage im Allgemeinen leicht verfügbar sind.
Wir werden in den kommenden Kapiteln ausführlicher über tiefes Lernen sprechen.
Deep Reinforcement Learning
Das Deep Reinforcement Learning (DRL) kombiniert die Techniken des Deep- und des Reinforcement-Lernens. Die Verstärkungslernalgorithmen wie Q-Learning werden jetzt mit Deep Learning kombiniert, um ein leistungsfähiges DRL-Modell zu erstellen. Die Technik war in den Bereichen Robotik, Videospiele, Finanzen und Gesundheitswesen mit großem Erfolg. Viele bisher unlösbare Probleme werden jetzt durch die Erstellung von DRL-Modellen gelöst. In diesem Bereich wird viel geforscht, und dies wird von den Branchen sehr aktiv betrieben.
Bisher haben Sie eine kurze Einführung in verschiedene Modelle des maschinellen Lernens erhalten. Lassen Sie uns nun etwas näher auf verschiedene Algorithmen eingehen, die unter diesen Modellen verfügbar sind.