Maschinelles Lernen - Kurzanleitung
Die heutige künstliche Intelligenz (KI) hat den Hype um Blockchain- und Quantencomputer weit übertroffen. Dies liegt an der Tatsache, dass dem einfachen Mann riesige Computerressourcen leicht zur Verfügung stehen. Die Entwickler nutzen dies nun, um neue Modelle für maschinelles Lernen zu erstellen und die vorhandenen Modelle für eine bessere Leistung und bessere Ergebnisse neu zu trainieren. Die einfache Verfügbarkeit von High Performance Computing (HPC) hat zu einer plötzlich gestiegenen Nachfrage nach IT-Fachleuten mit maschinellem Lernen geführt.
In diesem Tutorial erfahren Sie ausführlich über -
Was ist der Kern des maschinellen Lernens?
Was sind die verschiedenen Arten des maschinellen Lernens?
Welche unterschiedlichen Algorithmen stehen für die Entwicklung von Modellen für maschinelles Lernen zur Verfügung?
Welche Tools stehen für die Entwicklung dieser Modelle zur Verfügung?
Welche Programmiersprachen stehen zur Auswahl?
Welche Plattformen unterstützen die Entwicklung und Bereitstellung von Anwendungen für maschinelles Lernen?
Welche IDEs (Integrated Development Environment) sind verfügbar?
Wie können Sie Ihre Fähigkeiten in diesem wichtigen Bereich schnell verbessern?
Wenn Sie ein Gesicht in einem Facebook-Foto markieren, läuft die KI hinter den Kulissen und identifiziert Gesichter in einem Bild. Das Markieren von Gesichtern ist mittlerweile in mehreren Anwendungen allgegenwärtig, in denen Bilder mit menschlichen Gesichtern angezeigt werden. Warum nur menschliche Gesichter? Es gibt verschiedene Anwendungen, die Objekte wie Katzen, Hunde, Flaschen, Autos usw. erkennen. Auf unseren Straßen fahren autonome Autos, die Objekte in Echtzeit erkennen, um das Auto zu steuern. Wenn Sie reisen, verwenden Sie GoogleDirectionsErfahren Sie mehr über die Verkehrssituationen in Echtzeit und folgen Sie dem von Google zu diesem Zeitpunkt vorgeschlagenen besten Weg. Dies ist eine weitere Implementierung der Objekterkennungstechnik in Echtzeit.
Betrachten wir das Beispiel von Google TranslateAnwendung, die wir normalerweise bei Besuchen im Ausland verwenden. Mit der Online-Übersetzer-App von Google auf Ihrem Handy können Sie mit den Einheimischen kommunizieren, die eine Sprache sprechen, die Ihnen fremd ist.
Es gibt verschiedene Anwendungen von KI, die wir heute praktisch verwenden. Tatsächlich verwendet jeder von uns KI in vielen Teilen seines Lebens, auch ohne unser Wissen. Die heutige KI kann äußerst komplexe Aufgaben mit großer Genauigkeit und Geschwindigkeit ausführen. Lassen Sie uns ein Beispiel für eine komplexe Aufgabe diskutieren, um zu verstehen, welche Funktionen in einer KI-Anwendung erwartet werden, die Sie heute für Ihre Kunden entwickeln würden.
Beispiel
Wir alle verwenden Google Directionswährend unserer Reise überall in der Stadt für einen täglichen Pendelverkehr oder sogar für Reisen zwischen Städten. Die Google Directions-Anwendung schlägt zu diesem Zeitpunkt den schnellsten Weg zu unserem Ziel vor. Wenn wir diesem Weg folgen, haben wir festgestellt, dass Google in seinen Vorschlägen fast zu 100% richtig ist, und wir sparen unsere wertvolle Zeit auf der Reise.
Sie können sich die Komplexität vorstellen, die mit der Entwicklung dieser Art von Anwendung verbunden ist, wenn man bedenkt, dass es mehrere Pfade zu Ihrem Ziel gibt und die Anwendung die Verkehrssituation auf jedem möglichen Pfad beurteilen muss, um eine Schätzung der Reisezeit für jeden dieser Pfade zu erhalten. Berücksichtigen Sie außerdem die Tatsache, dass Google Directions den gesamten Globus abdeckt. Zweifellos werden unter den Hauben solcher Anwendungen viele KI- und maschinelle Lerntechniken verwendet.
Angesichts der ständigen Nachfrage nach der Entwicklung solcher Anwendungen werden Sie jetzt verstehen, warum plötzlich eine Nachfrage nach IT-Fachleuten mit KI-Kenntnissen besteht.
In unserem nächsten Kapitel lernen wir, wie man KI-Programme entwickelt.
Die Reise der KI begann in den 1950er Jahren, als die Rechenleistung einen Bruchteil dessen betrug, was sie heute ist. AI begann mit den Vorhersagen, die von der Maschine in einer Weise gemacht wurden, wie ein Statistiker Vorhersagen mit seinem Taschenrechner macht. Daher basierte die anfängliche gesamte KI-Entwicklung hauptsächlich auf statistischen Techniken.
Lassen Sie uns in diesem Kapitel detailliert diskutieren, was diese statistischen Techniken sind.
Statistische Methoden
Die Entwicklung der heutigen KI-Anwendungen begann mit der Verwendung der jahrhundertealten traditionellen statistischen Techniken. Sie müssen in Schulen eine lineare Interpolation verwendet haben, um einen zukünftigen Wert vorherzusagen. Es gibt mehrere andere solche statistischen Techniken, die bei der Entwicklung sogenannter AI-Programme erfolgreich angewendet werden. Wir sagen "so genannt", weil die KI-Programme, die wir heute haben, viel komplexer sind und Techniken verwenden, die weit über die statistischen Techniken hinausgehen, die von den frühen KI-Programmen verwendet werden.
Einige Beispiele für statistische Techniken, die in jenen Tagen für die Entwicklung von KI-Anwendungen verwendet wurden und noch in der Praxis sind, sind hier aufgeführt -
- Regression
- Classification
- Clustering
- Wahrscheinlichkeitstheorien
- Entscheidungsbäume
Hier haben wir nur einige primäre Techniken aufgelistet, die ausreichen, um Ihnen den Einstieg in die KI zu erleichtern, ohne Sie vor der Weite zu erschrecken, die die KI erfordert. Wenn Sie KI-Anwendungen auf der Grundlage begrenzter Daten entwickeln, verwenden Sie diese statistischen Techniken.
Heute sind die Daten jedoch reichlich vorhanden. Die Analyse der Art großer Datenmengen, über die wir verfügen, ist nicht sehr hilfreich, da sie einige eigene Einschränkungen aufweisen. Weiterentwickelte Methoden wie Deep Learning werden daher entwickelt, um viele komplexe Probleme zu lösen.
In diesem Tutorial werden wir verstehen, was maschinelles Lernen ist und wie es für die Entwicklung derart komplexer KI-Anwendungen verwendet wird.
Betrachten Sie die folgende Abbildung, die ein Diagramm der Immobilienpreise im Verhältnis zu ihrer Größe in Quadratfuß zeigt.

Nachdem wir verschiedene Datenpunkte auf dem XY-Diagramm gezeichnet haben, zeichnen wir eine am besten passende Linie, um unsere Vorhersagen für jedes andere Haus aufgrund seiner Größe zu treffen. Sie geben die bekannten Daten an die Maschine weiter und bitten sie, die am besten passende Linie zu finden. Sobald die Maschine die beste Anpassungslinie gefunden hat, testen Sie ihre Eignung, indem Sie eine bekannte Hausgröße eingeben, dh den Y-Wert in der obigen Kurve. Die Maschine gibt nun den geschätzten X-Wert zurück, dh den erwarteten Preis des Hauses. Das Diagramm kann extrapoliert werden, um den Preis eines Hauses zu ermitteln, das 3000 Quadratfuß oder noch größer ist. Dies wird in der Statistik als Regression bezeichnet. Insbesondere wird diese Art der Regression als lineare Regression bezeichnet, da die Beziehung zwischen X- und Y-Datenpunkten linear ist.
In vielen Fällen ist die Beziehung zwischen den X- und Y-Datenpunkten möglicherweise keine gerade Linie und es kann sich um eine Kurve mit einer komplexen Gleichung handeln. Ihre Aufgabe wäre es nun, die am besten passende Kurve herauszufinden, die extrapoliert werden kann, um die zukünftigen Werte vorherzusagen. Ein solches Anwendungsdiagramm ist in der folgenden Abbildung dargestellt.
Quelle:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
Sie werden die statistischen Optimierungstechniken verwenden, um hier die Gleichung für die beste Anpassungskurve herauszufinden. Und genau darum geht es beim maschinellen Lernen. Sie verwenden bekannte Optimierungstechniken, um die beste Lösung für Ihr Problem zu finden.
Als nächstes betrachten wir die verschiedenen Kategorien des maschinellen Lernens.
Maschinelles Lernen wird grob in die folgenden Überschriften eingeteilt:
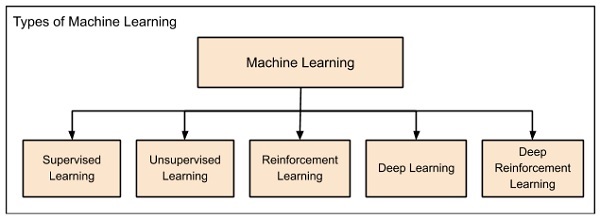
Das maschinelle Lernen entwickelte sich von links nach rechts, wie im obigen Diagramm gezeigt.
Zunächst begannen die Forscher mit Supervised Learning. Dies ist der Fall bei der zuvor diskutierten Vorhersage der Immobilienpreise.
Es folgte unbeaufsichtigtes Lernen, bei dem die Maschine ohne Aufsicht selbstständig lernen kann.
Wissenschaftler entdeckten weiter, dass es eine gute Idee sein könnte, die Maschine zu belohnen, wenn sie die Arbeit auf die erwartete Weise erledigt, und es kam das Reinforcement Learning.
Sehr bald sind die Daten, die heutzutage verfügbar sind, so umfangreich geworden, dass die bisher entwickelten konventionellen Techniken die Big Data nicht analysieren und uns die Vorhersagen liefern konnten.
So kam das tiefe Lernen, bei dem das menschliche Gehirn in den künstlichen neuronalen Netzen (ANN) simuliert wird, die in unseren Binärcomputern erstellt wurden.
Die Maschine lernt jetzt selbstständig mit der hohen Rechenleistung und den riesigen Speicherressourcen, die heute verfügbar sind.
Es wird nun beobachtet, dass Deep Learning viele der zuvor unlösbaren Probleme gelöst hat.
Die Technik wird jetzt weiterentwickelt, indem Anreize für Deep Learning-Netzwerke als Auszeichnungen vergeben werden, und schließlich kommt Deep Reinforcement Learning.
Lassen Sie uns nun jede dieser Kategorien genauer untersuchen.
Überwachtes Lernen
Betreutes Lernen ist analog zum Training eines Kindes zum Laufen. Sie halten die Hand des Kindes, zeigen ihm, wie er seinen Fuß nach vorne nimmt, gehen zu einer Demonstration und so weiter, bis das Kind lernt, selbstständig zu gehen.
Regression
In ähnlicher Weise geben Sie beim überwachten Lernen dem Computer konkrete bekannte Beispiele. Sie sagen, dass für einen gegebenen Merkmalswert x1 die Ausgabe y1 ist, für x2 y2, für x3 y3 und so weiter. Basierend auf diesen Daten lassen Sie den Computer eine empirische Beziehung zwischen x und y herausfinden.
Sobald die Maschine auf diese Weise mit einer ausreichenden Anzahl von Datenpunkten trainiert wurde, würden Sie die Maschine nun bitten, Y für ein gegebenes X vorherzusagen. Angenommen, Sie kennen den tatsächlichen Wert von Y für dieses gegebene X, können Sie ableiten ob die Vorhersage der Maschine korrekt ist.
So testen Sie anhand der bekannten Testdaten, ob die Maschine gelernt hat. Sobald Sie zufrieden sind, dass die Maschine die Vorhersagen mit der gewünschten Genauigkeit (z. B. 80 bis 90%) ausführen kann, können Sie das weitere Training der Maschine beenden.
Jetzt können Sie die Maschine sicher verwenden, um Vorhersagen für unbekannte Datenpunkte zu treffen, oder die Maschine bitten, Y für ein bestimmtes X vorherzusagen, für das Sie den tatsächlichen Wert von Y nicht kennen. Dieses Training fällt unter die Regression, über die wir gesprochen haben vorhin.
Einstufung
Sie können auch Techniken des maschinellen Lernens für Klassifizierungsprobleme verwenden. Bei Klassifizierungsproblemen klassifizieren Sie Objekte ähnlicher Art in eine einzelne Gruppe. Zum Beispiel möchten Sie in einer Gruppe von 100 Schülern sagen, dass Sie sie basierend auf ihrer Größe in drei Gruppen einteilen möchten - kurz, mittel und lang. Wenn Sie die Größe jedes Schülers messen, ordnen Sie ihn einer richtigen Gruppe zu.
Wenn ein neuer Schüler hereinkommt, werden Sie ihn in eine geeignete Gruppe einordnen, indem Sie seine Größe messen. Indem Sie die Prinzipien des Regressionstrainings befolgen, trainieren Sie die Maschine, um einen Schüler anhand seiner Funktion - der Größe - zu klassifizieren. Wenn die Maschine lernt, wie die Gruppen gebildet werden, kann sie jeden unbekannten neuen Schüler korrekt klassifizieren. Sie würden die Testdaten erneut verwenden, um zu überprüfen, ob die Maschine Ihre Klassifizierungstechnik gelernt hat, bevor Sie das entwickelte Modell in Produktion nehmen.
Beim überwachten Lernen hat die KI ihre Reise wirklich begonnen. Diese Technik wurde in mehreren Fällen erfolgreich angewendet. Sie haben dieses Modell verwendet, während Sie die handschriftliche Erkennung auf Ihrem Computer durchgeführt haben. Für das überwachte Lernen wurden mehrere Algorithmen entwickelt. Sie werden in den folgenden Kapiteln mehr darüber erfahren.
Unbeaufsichtigtes Lernen
Beim unbeaufsichtigten Lernen geben wir keine Zielvariable für die Maschine an, sondern fragen die Maschine: „Was können Sie mir über X sagen?“. Insbesondere können wir Fragen stellen, z. B. bei einem riesigen Datensatz X: „Was sind die fünf besten Gruppen, die wir aus X machen können?“. oder "Welche Funktionen treten in X am häufigsten zusammen auf?". Um zu den Antworten auf solche Fragen zu gelangen, können Sie verstehen, dass die Anzahl der Datenpunkte, die die Maschine benötigen würde, um eine Strategie abzuleiten, sehr groß wäre. Im Falle eines überwachten Lernens kann die Maschine mit sogar einigen Tausend Datenpunkten trainiert werden. Bei unbeaufsichtigtem Lernen beginnt die Anzahl der Datenpunkte, die für das Lernen angemessen akzeptiert werden, jedoch bei einigen Millionen. Heutzutage sind die Daten im Allgemeinen reichlich verfügbar. Die Daten müssen idealerweise kuratiert werden. Die Datenmenge, die kontinuierlich in einem sozialen Netzwerk fließt, ist in den meisten Fällen eine unmögliche Aufgabe.
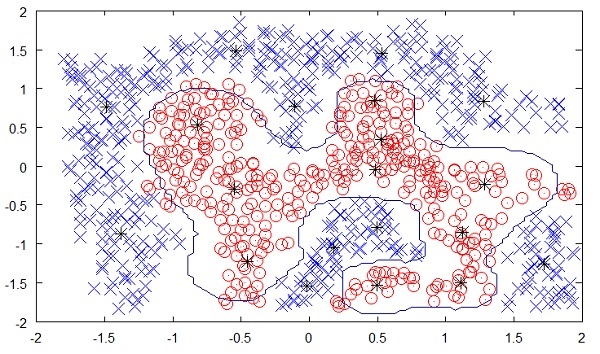
Die folgende Abbildung zeigt die Grenze zwischen den gelben und roten Punkten, die durch unbeaufsichtigtes maschinelles Lernen bestimmt wurde. Sie können deutlich sehen, dass die Maschine die Klasse jedes der schwarzen Punkte mit einer ziemlich guten Genauigkeit bestimmen kann.
Quelle:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
Das unbeaufsichtigte Lernen hat in vielen modernen KI-Anwendungen wie Gesichtserkennung, Objekterkennung usw. einen großen Erfolg gezeigt.
Verstärkungslernen
Ziehen Sie in Betracht, einen Hund zu trainieren. Wir trainieren unser Haustier, um einen Ball zu uns zu bringen. Wir werfen den Ball in einer bestimmten Entfernung und bitten den Hund, ihn uns zurückzuholen. Jedes Mal, wenn der Hund dies richtig macht, belohnen wir den Hund. Langsam lernt der Hund, dass die richtige Arbeit ihm eine Belohnung gibt, und dann beginnt der Hund jedes Mal in der Zukunft, die Arbeit richtig zu machen. Genau dieses Konzept wird beim Lernen vom Typ „Verstärkung“ angewendet. Die Technik wurde ursprünglich für Maschinen zum Spielen entwickelt. Die Maschine erhält einen Algorithmus zur Analyse aller möglichen Bewegungen in jeder Phase des Spiels. Die Maschine kann eine der Bewegungen zufällig auswählen. Wenn der Zug richtig ist, wird die Maschine belohnt, andernfalls kann sie bestraft werden. Langsam beginnt die Maschine zwischen richtigen und falschen Zügen zu unterscheiden und lernt nach mehreren Iterationen, das Spielrätsel mit einer besseren Genauigkeit zu lösen. Die Genauigkeit des Gewinns des Spiels würde sich verbessern, wenn die Maschine immer mehr Spiele spielt.
Der gesamte Prozess kann in der folgenden Abbildung dargestellt werden:
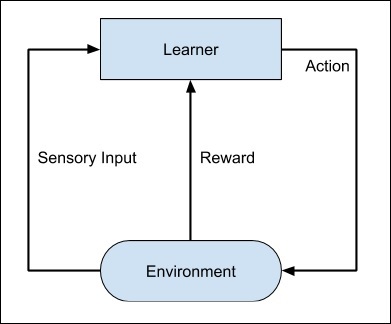
Diese Technik des maschinellen Lernens unterscheidet sich vom überwachten Lernen darin, dass Sie die gekennzeichneten Eingabe / Ausgabe-Paare nicht angeben müssen. Der Fokus liegt darauf, das Gleichgewicht zwischen der Erforschung der neuen Lösungen und der Nutzung der erlernten Lösungen zu finden.
Tiefes Lernen
Das Deep Learning ist ein Modell, das auf künstlichen neuronalen Netzen (ANN) basiert, insbesondere auf Faltungs-Neuronalen Netzen (CNN). Es gibt verschiedene Architekturen, die beim tiefen Lernen verwendet werden, wie tiefe neuronale Netze, tiefe Glaubensnetzwerke, wiederkehrende neuronale Netze und Faltungs-neuronale Netze.
Diese Netzwerke wurden erfolgreich bei der Lösung der Probleme von Computer Vision, Spracherkennung, Verarbeitung natürlicher Sprache, Bioinformatik, Arzneimitteldesign, medizinischer Bildanalyse und Spielen eingesetzt. Es gibt mehrere andere Bereiche, in denen Deep Learning proaktiv angewendet wird. Das tiefe Lernen erfordert enorme Rechenleistung und enorme Datenmengen, die heutzutage im Allgemeinen leicht verfügbar sind.
Wir werden in den kommenden Kapiteln ausführlicher über tiefes Lernen sprechen.
Deep Reinforcement Learning
Das Deep Reinforcement Learning (DRL) kombiniert die Techniken des Deep- und des Reinforcement-Lernens. Die Verstärkungslernalgorithmen wie Q-Learning werden jetzt mit Deep Learning kombiniert, um ein leistungsfähiges DRL-Modell zu erstellen. Die Technik war in den Bereichen Robotik, Videospiele, Finanzen und Gesundheitswesen mit großem Erfolg. Viele bisher unlösbare Probleme werden jetzt durch die Erstellung von DRL-Modellen gelöst. In diesem Bereich wird viel geforscht, und dies wird von den Branchen sehr aktiv betrieben.
Bisher haben Sie eine kurze Einführung in verschiedene Modelle des maschinellen Lernens erhalten. Lassen Sie uns nun etwas näher auf verschiedene Algorithmen eingehen, die unter diesen Modellen verfügbar sind.
Betreutes Lernen ist eines der wichtigsten Lernmodelle für Trainingsmaschinen. In diesem Kapitel wird ausführlich darauf eingegangen.
Algorithmen für überwachtes Lernen
Für das überwachte Lernen stehen verschiedene Algorithmen zur Verfügung. Einige der weit verbreiteten Algorithmen des überwachten Lernens sind wie folgt:
- k-Nächste Nachbarn
- Entscheidungsbäume
- Naive Bayes
- Logistische Regression
- Support-Vektor-Maschinen
Lassen Sie uns in diesem Kapitel die einzelnen Algorithmen ausführlich erläutern.
k-Nächste Nachbarn
Die k-Nearest Neighbors, einfach kNN genannt, sind statistische Techniken, mit denen Klassifizierungs- und Regressionsprobleme gelöst werden können. Lassen Sie uns den Fall der Klassifizierung eines unbekannten Objekts mit kNN diskutieren. Betrachten Sie die Verteilung der Objekte wie in der Abbildung unten gezeigt -
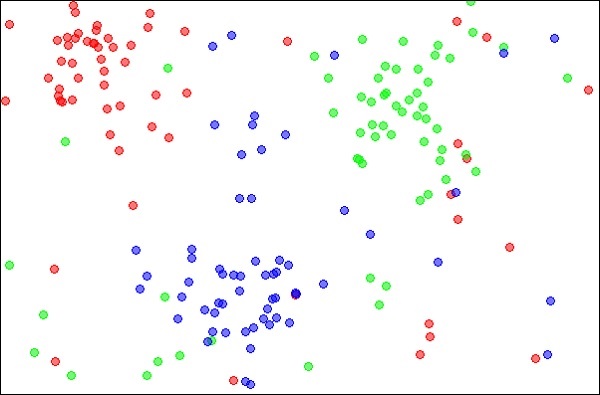
Quelle:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Das Diagramm zeigt drei Arten von Objekten, die in den Farben Rot, Blau und Grün markiert sind. Wenn Sie den kNN-Klassifizierer für den obigen Datensatz ausführen, werden die Grenzen für jeden Objekttyp wie unten gezeigt markiert.

Quelle:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Stellen Sie sich nun ein neues unbekanntes Objekt vor, das Sie als rot, grün oder blau klassifizieren möchten. Dies ist in der folgenden Abbildung dargestellt.
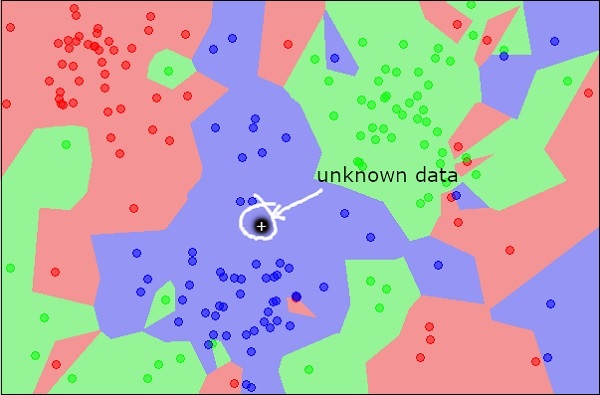
Wie Sie es visuell sehen, gehört der unbekannte Datenpunkt zu einer Klasse von blauen Objekten. Mathematisch kann dies geschlossen werden, indem die Entfernung dieses unbekannten Punktes mit jedem anderen Punkt im Datensatz gemessen wird. Wenn Sie dies tun, werden Sie wissen, dass die meisten Nachbarn von blauer Farbe sind. Die durchschnittliche Entfernung zu roten und grünen Objekten wäre definitiv größer als die durchschnittliche Entfernung zu blauen Objekten. Somit kann dieses unbekannte Objekt als zur blauen Klasse gehörend klassifiziert werden.
Der kNN-Algorithmus kann auch für Regressionsprobleme verwendet werden. Der kNN-Algorithmus ist in den meisten ML-Bibliotheken einsatzbereit.
Entscheidungsbäume
Ein einfacher Entscheidungsbaum in einem Flussdiagrammformat ist unten dargestellt -
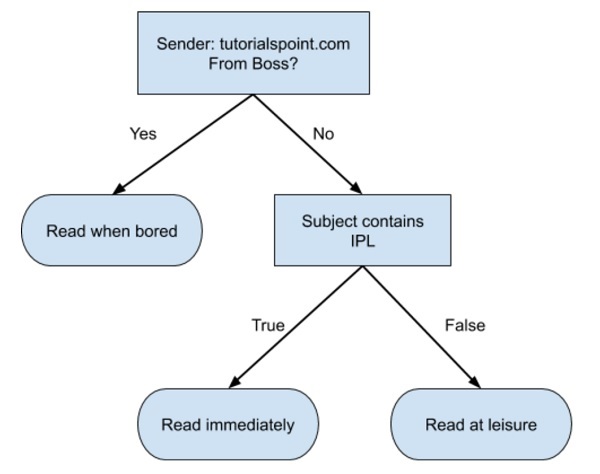
Sie würden einen Code schreiben, um Ihre Eingabedaten basierend auf diesem Flussdiagramm zu klassifizieren. Das Flussdiagramm ist selbsterklärend und trivial. In diesem Szenario versuchen Sie, eine eingehende E-Mail zu klassifizieren, um zu entscheiden, wann sie gelesen werden soll.
In der Realität können die Entscheidungsbäume groß und komplex sein. Es stehen verschiedene Algorithmen zur Verfügung, um diese Bäume zu erstellen und zu durchlaufen. Als Enthusiast des maschinellen Lernens müssen Sie diese Techniken zum Erstellen und Durchlaufen von Entscheidungsbäumen verstehen und beherrschen.
Naive Bayes
Naive Bayes wird zum Erstellen von Klassifikatoren verwendet. Angenommen, Sie möchten Früchte verschiedener Arten aus einem Obstkorb aussortieren (klassifizieren). Sie können Merkmale wie Farbe, Größe und Form einer Frucht verwenden. Beispielsweise kann jede Frucht mit roter Farbe, runder Form und einem Durchmesser von etwa 10 cm als Apfel betrachtet werden. Um das Modell zu trainieren, würden Sie diese Features verwenden und die Wahrscheinlichkeit testen, dass ein bestimmtes Feature den gewünschten Einschränkungen entspricht. Die Wahrscheinlichkeiten verschiedener Merkmale werden dann kombiniert, um eine Wahrscheinlichkeit zu erhalten, dass eine bestimmte Frucht ein Apfel ist. Naive Bayes benötigt im Allgemeinen eine kleine Anzahl von Trainingsdaten für die Klassifizierung.
Logistische Regression
Schauen Sie sich das folgende Diagramm an. Es zeigt die Verteilung der Datenpunkte in der XY-Ebene.

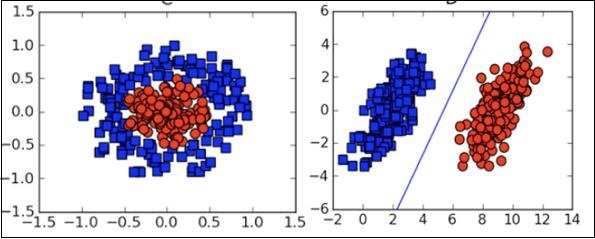
Aus dem Diagramm können wir die Trennung von roten und grünen Punkten visuell untersuchen. Sie können eine Grenzlinie zeichnen, um diese Punkte zu trennen. Um einen neuen Datenpunkt zu klassifizieren, müssen Sie nur noch bestimmen, auf welcher Seite der Linie der Punkt liegt.
Support-Vektor-Maschinen
Sehen Sie sich die folgende Datenverteilung an. Hier können die drei Datenklassen nicht linear getrennt werden. Die Grenzkurven sind nicht linear. In einem solchen Fall wird das Finden der Kurvengleichung zu einer komplexen Aufgabe.
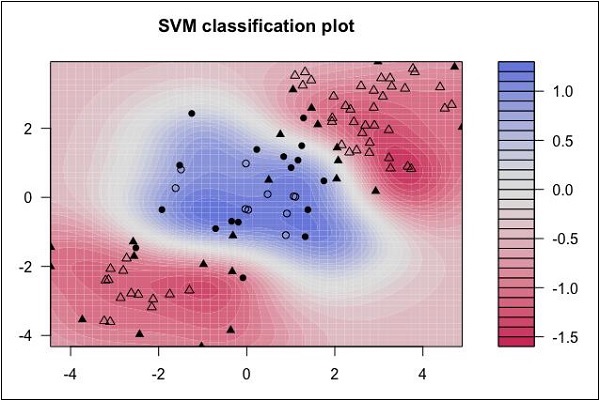
Quelle: http://uc-r.github.io/svm
Die Support Vector Machines (SVM) sind praktisch, um die Trennungsgrenzen in solchen Situationen zu bestimmen.
Glücklicherweise müssen Sie die in der vorherigen Lektion erwähnten Algorithmen die meiste Zeit nicht codieren. Es gibt viele Standardbibliotheken, die die gebrauchsfertige Implementierung dieser Algorithmen ermöglichen. Ein solches Toolkit, das im Volksmund verwendet wird, ist Scikit-Learn. Die folgende Abbildung zeigt die Art der Algorithmen, die für Ihre Verwendung in dieser Bibliothek verfügbar sind.

Quelle: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Die Verwendung dieser Algorithmen ist trivial und da diese gut und praxiserprobt sind, können Sie sie sicher in Ihren KI-Anwendungen verwenden. Die meisten dieser Bibliotheken können auch für kommerzielle Zwecke kostenlos verwendet werden.
Was Sie bisher gesehen haben, ist, dass die Maschine lernt, die Lösung für unser Ziel herauszufinden. In der Regression trainieren wir die Maschine, um einen zukünftigen Wert vorherzusagen. Bei der Klassifizierung trainieren wir die Maschine, um ein unbekanntes Objekt in eine der von uns definierten Kategorien zu klassifizieren. Kurz gesagt, wir haben Maschinen trainiert, damit sie Y für unsere Daten X vorhersagen können. Angesichts eines riesigen Datensatzes und ohne Schätzung der Kategorien wäre es für uns schwierig, die Maschine mithilfe von überwachtem Lernen zu trainieren. Was ist, wenn der Computer die Big Data mit mehreren Gigabyte und Terabyte nachschlagen und analysieren kann und uns mitteilt, dass diese Daten so viele verschiedene Kategorien enthalten?
Betrachten Sie als Beispiel die Daten des Wählers. Indem Sie einige Eingaben von jedem Wähler berücksichtigen (diese werden in der KI-Terminologie als Merkmale bezeichnet), lassen Sie die Maschine vorhersagen, dass es so viele Wähler gibt, die für die X-Partei stimmen würden, und so viele, die für Y stimmen würden, und so weiter. Daher fragen wir die Maschine im Allgemeinen mit einem riesigen Satz von Datenpunkten X: „Was können Sie mir über X sagen?“. Oder es könnte eine Frage wie "Was sind die fünf besten Gruppen, die wir aus X machen können?" Sein. Oder es könnte sogar so aussehen: "Welche drei Funktionen treten in X am häufigsten zusammen auf?".
Genau darum geht es beim unbeaufsichtigten Lernen.
Algorithmen für unbeaufsichtigtes Lernen
Lassen Sie uns nun einen der weit verbreiteten Algorithmen zur Klassifizierung im unbeaufsichtigten maschinellen Lernen diskutieren.
k-bedeutet Clustering
Die Präsidentschaftswahlen 2000 und 2004 in den Vereinigten Staaten standen kurz bevor - sehr nahe. Der größte Prozentsatz der Stimmen, die ein Kandidat erhielt, betrug 50,7% und der niedrigste 47,9%. Wenn ein Prozentsatz der Wähler die Seite gewechselt hätte, wäre das Wahlergebnis anders ausgefallen. Es gibt kleine Gruppen von Wählern, die, wenn sie richtig angesprochen werden, die Seite wechseln. Diese Gruppen mögen nicht riesig sein, aber bei solch engen Rennen können sie groß genug sein, um das Wahlergebnis zu ändern. Wie finden Sie diese Personengruppen? Wie appellieren Sie mit einem begrenzten Budget an sie? Die Antwort lautet Clustering.
Lassen Sie uns verstehen, wie es gemacht wird.
Zunächst sammeln Sie Informationen über Personen mit oder ohne deren Zustimmung: Informationen jeglicher Art, die einen Hinweis darauf geben, was für sie wichtig ist und wie sie abstimmen.
Dann fügen Sie diese Informationen in eine Art Clustering-Algorithmus ein.
Als nächstes erstellen Sie für jeden Cluster (es wäre klug, zuerst den größten auszuwählen) eine Nachricht, die diese Wähler anspricht.
Schließlich liefern Sie die Kampagne aus und messen, ob sie funktioniert.
Clustering ist eine Art unbeaufsichtigten Lernens, bei dem automatisch Cluster ähnlicher Dinge gebildet werden. Es ist wie eine automatische Klassifizierung. Sie können fast alles gruppieren. Je ähnlicher die Elemente im Cluster sind, desto besser sind die Cluster. In diesem Kapitel werden wir eine Art von Clustering-Algorithmus untersuchen, der als k-means bezeichnet wird. Es wird k-means genannt, weil es 'k' eindeutige Cluster findet und das Zentrum jedes Clusters der Mittelwert der Werte in diesem Cluster ist.
Cluster-Identifikation
Die Clusteridentifikation sagt einem Algorithmus: „Hier sind einige Daten. Gruppieren Sie jetzt ähnliche Dinge und erzählen Sie mir von diesen Gruppen. “ Der Hauptunterschied zur Klassifizierung besteht darin, dass Sie bei der Klassifizierung wissen, wonach Sie suchen. Dies ist beim Clustering zwar nicht der Fall.
Clustering wird manchmal als unbeaufsichtigte Klassifizierung bezeichnet, da es das gleiche Ergebnis wie die Klassifizierung liefert, jedoch ohne vordefinierte Klassen.
Jetzt fühlen wir uns sowohl mit überwachtem als auch mit unbeaufsichtigtem Lernen wohl. Um den Rest der Kategorien des maschinellen Lernens zu verstehen, müssen wir zuerst die künstlichen neuronalen Netze (ANN) verstehen, die wir im nächsten Kapitel lernen werden.
Die Idee der künstlichen neuronalen Netze wurde von den neuronalen Netzen im menschlichen Gehirn abgeleitet. Das menschliche Gehirn ist sehr komplex. Die Wissenschaftler und Ingenieure untersuchten das Gehirn sorgfältig und entwickelten eine Architektur, die in unsere digitale Welt der Binärcomputer passen könnte. Eine solche typische Architektur ist in der folgenden Abbildung dargestellt -
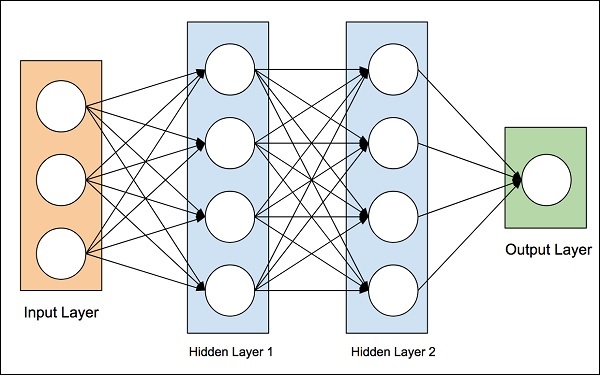
Es gibt eine Eingabeschicht mit vielen Sensoren zum Sammeln von Daten aus der Außenwelt. Auf der rechten Seite haben wir eine Ausgabeschicht, die uns das vom Netzwerk vorhergesagte Ergebnis liefert. Zwischen diesen beiden sind mehrere Ebenen versteckt. Jede zusätzliche Schicht erhöht die Komplexität beim Training des Netzwerks, würde jedoch in den meisten Situationen bessere Ergebnisse liefern. Es gibt verschiedene Arten von Architekturen, die wir jetzt diskutieren werden.
ANN-Architekturen
Das folgende Diagramm zeigt mehrere ANN-Architekturen, die über einen bestimmten Zeitraum entwickelt wurden und heute in der Praxis sind.
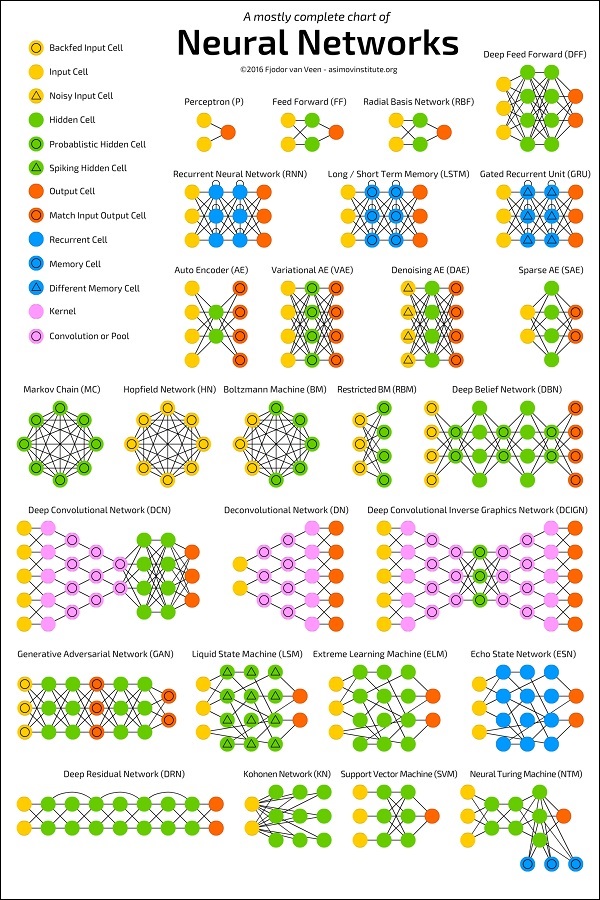
Quelle:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Jede Architektur wird für einen bestimmten Anwendungstyp entwickelt. Wenn Sie also ein neuronales Netzwerk für Ihre Anwendung für maschinelles Lernen verwenden, müssen Sie entweder eine der vorhandenen Architekturen verwenden oder Ihre eigene entwerfen. Die Art der Anwendung, für die Sie sich endgültig entscheiden, hängt von Ihren Anwendungsanforderungen ab. Es gibt keine einzige Richtlinie, die Sie auffordert, eine bestimmte Netzwerkarchitektur zu verwenden.
Deep Learning verwendet ANN. Zuerst werden wir uns einige Deep-Learning-Anwendungen ansehen, die Ihnen einen Eindruck von ihrer Leistungsfähigkeit vermitteln.
Anwendungen
Deep Learning hat in mehreren Bereichen maschineller Lernanwendungen große Erfolge gezeigt.
Self-driving Cars- Die autonomen selbstfahrenden Autos verwenden Deep-Learning-Techniken. Sie passen sich im Allgemeinen den sich ständig ändernden Verkehrssituationen an und können im Laufe der Zeit immer besser fahren.
Speech Recognition- Eine weitere interessante Anwendung von Deep Learning ist die Spracherkennung. Wir alle verwenden heute mehrere mobile Apps, die unsere Sprache erkennen können. Apples Siri, Amazonas Alexa, Microsofts Cortena und Googles Assistent - all dies verwendet Deep-Learning-Techniken.
Mobile Apps- Wir verwenden mehrere webbasierte und mobile Apps zum Organisieren unserer Fotos. Gesichtserkennung, Gesichtserkennung, Gesichtsmarkierung, Identifizierung von Objekten in einem Bild - all dies erfordert tiefes Lernen.
Ungenutzte Möglichkeiten des tiefen Lernens
Nachdem wir uns die großen Erfolge angesehen hatten, die Deep-Learning-Anwendungen in vielen Bereichen erzielt haben, begannen die Menschen, andere Bereiche zu erkunden, in denen maschinelles Lernen bisher nicht angewendet wurde. Es gibt mehrere Bereiche, in denen Deep-Learning-Techniken erfolgreich angewendet werden, und es gibt viele andere Bereiche, die genutzt werden können. Einige davon werden hier diskutiert.
Die Landwirtschaft ist eine solche Branche, in der Menschen Deep-Learning-Techniken anwenden können, um den Ernteertrag zu verbessern.
Konsumentenfinanzierung ist ein weiterer Bereich, in dem maschinelles Lernen wesentlich dazu beitragen kann, Betrug frühzeitig zu erkennen und die Zahlungsfähigkeit des Kunden zu analysieren.
Deep-Learning-Techniken werden auch auf dem Gebiet der Medizin angewendet, um neue Medikamente zu entwickeln und einem Patienten ein personalisiertes Rezept zu geben.
Die Möglichkeiten sind endlos und man muss weiter beobachten, wie die neuen Ideen und Entwicklungen häufig auftauchen.
Was ist erforderlich, um mit Deep Learning mehr zu erreichen?
Um Deep Learning nutzen zu können, ist Supercomputing-Leistung eine zwingende Voraussetzung. Sie benötigen sowohl Speicher als auch CPU, um Deep-Learning-Modelle zu entwickeln. Glücklicherweise haben wir heute eine einfache Verfügbarkeit von HPC - High Performance Computing. Aus diesem Grund wurde die Entwicklung der oben erwähnten Deep-Learning-Anwendungen heute Realität, und auch in Zukunft können wir die Anwendungen in den zuvor diskutierten unerschlossenen Bereichen sehen.
Jetzt werden wir uns einige der Einschränkungen des Deep Learning ansehen, die wir berücksichtigen müssen, bevor wir es in unserer Anwendung für maschinelles Lernen verwenden.
Deep Learning Nachteile
Einige der wichtigen Punkte, die Sie berücksichtigen müssen, bevor Sie Deep Learning anwenden, sind nachstehend aufgeführt:
- Black-Box-Ansatz
- Entwicklungsdauer
- Datenmenge
- Rechenintensiv
Wir werden nun jede dieser Einschränkungen im Detail untersuchen.
Black-Box-Ansatz
Ein ANN ist wie eine Blackbox. Sie geben ihm eine bestimmte Eingabe und es gibt Ihnen eine bestimmte Ausgabe. Das folgende Diagramm zeigt Ihnen eine solche Anwendung, bei der Sie einem neuronalen Netzwerk ein Tierbild zuführen und das Ihnen zeigt, dass es sich bei dem Bild um einen Hund handelt.
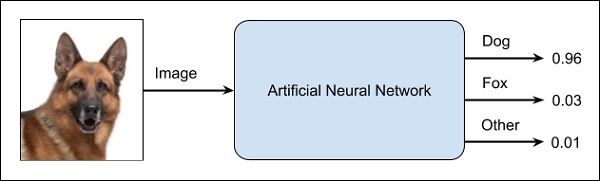
Dies wird als Black-Box-Ansatz bezeichnet, da Sie nicht wissen, warum das Netzwerk ein bestimmtes Ergebnis erzielt hat. Sie wissen nicht, wie das Netzwerk zu dem Schluss kam, dass es sich um einen Hund handelt? Stellen Sie sich nun einen Bankantrag vor, bei dem die Bank über die Kreditwürdigkeit eines Kunden entscheiden möchte. Das Netzwerk wird Ihnen auf jeden Fall eine Antwort auf diese Frage geben. Können Sie dies jedoch einem Kunden gegenüber rechtfertigen? Banken müssen ihren Kunden erklären, warum der Kredit nicht sanktioniert wird.
Entwicklungsdauer
Der Prozess des Trainings eines neuronalen Netzwerks ist in der folgenden Abbildung dargestellt:

Sie definieren zunächst das Problem, das Sie lösen möchten, erstellen eine Spezifikation dafür, legen die Eingabefunktionen fest, entwerfen ein Netzwerk, stellen es bereit und testen die Ausgabe. Wenn die Ausgabe nicht wie erwartet ist, nehmen Sie dies als Feedback, um Ihr Netzwerk neu zu strukturieren. Dies ist ein iterativer Prozess und erfordert möglicherweise mehrere Iterationen, bis das Zeitnetzwerk vollständig trainiert ist, um die gewünschten Ausgaben zu erzeugen.
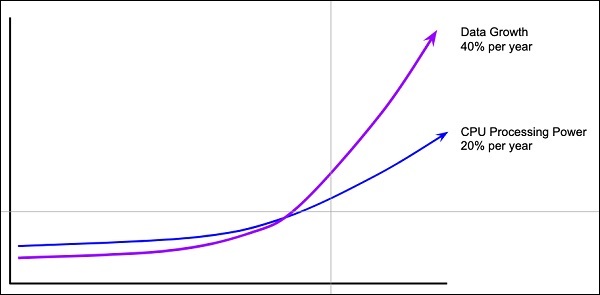
Datenmenge
Die Deep-Learning-Netzwerke erfordern normalerweise eine große Datenmenge für das Training, während die herkömmlichen Algorithmen für maschinelles Lernen selbst mit nur wenigen Tausend Datenpunkten mit großem Erfolg verwendet werden können. Glücklicherweise wächst die Datenmenge um 40% pro Jahr und die CPU-Verarbeitungsleistung um 20% pro Jahr, wie in der folgenden Abbildung dargestellt.
Rechenintensiv
Das Training eines neuronalen Netzwerks erfordert ein Mehrfaches an Rechenleistung als das Ausführen herkömmlicher Algorithmen. Ein erfolgreiches Training tiefer neuronaler Netze kann mehrere Wochen Trainingszeit erfordern.
Im Gegensatz dazu benötigen herkömmliche Algorithmen für maschinelles Lernen nur wenige Minuten / Stunden zum Trainieren. Außerdem hängt die Menge an Rechenleistung, die zum Trainieren eines tiefen neuronalen Netzwerks benötigt wird, stark von der Größe Ihrer Daten ab und davon, wie tief und komplex das Netzwerk ist.
Nachdem wir uns einen Überblick über das maschinelle Lernen, seine Fähigkeiten, Einschränkungen und Anwendungen verschafft haben, wollen wir uns nun mit dem Erlernen des „maschinellen Lernens“ befassen.
Maschinelles Lernen hat eine sehr große Breite und erfordert Fähigkeiten in mehreren Bereichen. Die Fähigkeiten, die Sie erwerben müssen, um Experte für maschinelles Lernen zu werden, sind nachstehend aufgeführt:
- Statistics
- Wahrscheinlichkeitstheorien
- Calculus
- Optimierungstechniken
- Visualization
Notwendigkeit verschiedener Fähigkeiten des maschinellen Lernens
Um Ihnen eine kurze Vorstellung davon zu geben, welche Fähigkeiten Sie erwerben müssen, lassen Sie uns einige Beispiele diskutieren -
Mathematische Notation
Die meisten Algorithmen für maschinelles Lernen basieren stark auf Mathematik. Das Niveau der Mathematik, das Sie kennen müssen, ist wahrscheinlich nur ein Anfängerlevel. Wichtig ist, dass Sie die Notation lesen können, die Mathematiker in ihren Gleichungen verwenden. Zum Beispiel: Wenn Sie die Notation lesen und verstehen können, was sie bedeutet, sind Sie bereit, maschinelles Lernen zu lernen. Wenn nicht, müssen Sie möglicherweise Ihre mathematischen Kenntnisse auffrischen.
$$ f_ {AN} (net- \ theta) = \ begin {case} \ gamma & if \: net- \ theta \ geq \ epsilon \\ net- \ theta & if - \ epsilon <net- \ theta <\ epsilon \\ - \ gamma & if \: net- \ theta \ leq- \ epsilon \ end {case} $$
$$ \ displaystyle \\\ max \ limit _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limit_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limit_ { i, j = 1} ^ m label ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {array} {c} i \\ \ end {array} \ rechts), x ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ rangle \ end {bmatrix} $$
$$ f_ {AN} (net- \ theta) = \ left (\ frac {e ^ {\ lambda (net- \ theta)} - e ^ {- \ lambda (net- \ theta)}} {e ^ { \ lambda (net- \ theta)} + e ^ {- \ lambda (net- \ theta)}} \ right) \; $$
Wahrscheinlichkeitstheorie
Hier ist ein Beispiel, um Ihre aktuellen Kenntnisse der Wahrscheinlichkeitstheorie zu testen: Klassifizieren mit bedingten Wahrscheinlichkeiten.
$$ p (c_ {i} | x, y) \; = \ frac {p (x, y | c_ {i}) \; p (c_ {i}) \;} {p (x, y) \ ;} $$
Mit diesen Definitionen können wir die Bayes'sche Klassifikationsregel definieren -
- Wenn P (c1 | x, y)> P (c2 | x, y) ist, ist die Klasse c1.
- Wenn P (c1 | x, y) <P (c2 | x, y) ist, ist die Klasse c2.
Optimierungsproblem
Hier ist eine Optimierungsfunktion
$$ \ displaystyle \\\ max \ limit _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limit_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limit_ { i, j = 1} ^ m label ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {array} {c} i \\ \ end {array} \ rechts), x ^ \ left (\ begin {array} {c} j \\ \ end {array} \ right) \ rangle \ end {bmatrix} $$
Vorbehaltlich der folgenden Einschränkungen -
$$ \ alpha \ geq0 und \: \ displaystyle \ sum \ limit_ {i-1} ^ m \ alpha_ {i} \ cdot \: label ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) = 0 $$
Wenn Sie das Obige lesen und verstehen können, sind Sie fertig.
Visualisierung
In vielen Fällen müssen Sie die verschiedenen Arten von Visualisierungsdiagrammen verstehen, um Ihre Datenverteilung zu verstehen und die Ergebnisse der Ausgabe des Algorithmus zu interpretieren.
Neben den oben genannten theoretischen Aspekten des maschinellen Lernens benötigen Sie gute Programmierkenntnisse, um diese Algorithmen zu codieren.
Was braucht es also, um ML zu implementieren? Lassen Sie uns dies im nächsten Kapitel untersuchen.
Um ML-Anwendungen zu entwickeln, müssen Sie sich für die Plattform, die IDE und die Sprache für die Entwicklung entscheiden. Es stehen mehrere Optionen zur Verfügung. Die meisten davon würden Ihre Anforderungen leicht erfüllen, da alle die Implementierung der bisher diskutierten KI-Algorithmen ermöglichen.
Wenn Sie den ML-Algorithmus selbst entwickeln, müssen die folgenden Aspekte sorgfältig verstanden werden:
Die Sprache Ihrer Wahl - dies ist im Wesentlichen Ihre Beherrschung einer der in der ML-Entwicklung unterstützten Sprachen.
Die von Ihnen verwendete IDE - Dies hängt von Ihrer Vertrautheit mit den vorhandenen IDEs und Ihrem Komfortniveau ab.
Development platform- Für die Entwicklung und Bereitstellung stehen mehrere Plattformen zur Verfügung. Die meisten davon sind kostenlos. In einigen Fällen muss möglicherweise eine Lizenzgebühr erhoben werden, die über eine bestimmte Nutzungsdauer hinausgeht. Hier finden Sie eine kurze Liste mit ausgewählten Sprachen, IDEs und Plattformen als Referenz.
Sprachwahl
Hier ist eine Liste von Sprachen, die die ML-Entwicklung unterstützen -
- Python
- R
- Matlab
- Octave
- Julia
- C++
- C
Diese Liste ist im Wesentlichen nicht vollständig; Es werden jedoch viele beliebte Sprachen behandelt, die in der Entwicklung des maschinellen Lernens verwendet werden. Wählen Sie je nach Komfortniveau eine Sprache für die Entwicklung aus, entwickeln Sie Ihre Modelle und testen Sie sie.
IDEs
Hier ist eine Liste von IDEs, die die ML-Entwicklung unterstützen -
- R Studio
- Pycharm
- iPython / Jupyter Notebook
- Julia
- Spyder
- Anaconda
- Rodeo
- Google –Colab
Die obige Liste ist nicht wesentlich. Jeder hat seine eigenen Vor- und Nachteile. Der Leser wird aufgefordert, diese verschiedenen IDEs auszuprobieren, bevor er sich auf eine einzige beschränkt.
Plattformen
Hier ist eine Liste der Plattformen, auf denen ML-Anwendungen bereitgestellt werden können:
- IBM
- Microsoft Azure
- Google Cloud
- Amazon
- Mlflow
Auch diese Liste ist nicht vollständig. Der Leser wird aufgefordert, sich für die oben genannten Dienste anzumelden und diese selbst auszuprobieren.
Dieses Tutorial hat Sie in das maschinelle Lernen eingeführt. Jetzt wissen Sie, dass maschinelles Lernen eine Technik ist, mit der Maschinen trainiert werden, um die Aktivitäten auszuführen, die ein menschliches Gehirn ausführen kann, wenn auch etwas schneller und besser als ein durchschnittlicher Mensch. Heute haben wir gesehen, dass die Maschinen menschliche Champions in Spielen wie Schach, AlphaGO schlagen können, die als sehr komplex gelten. Sie haben gesehen, dass Maschinen trainiert werden können, um menschliche Aktivitäten in verschiedenen Bereichen auszuführen, und Menschen dabei helfen können, ein besseres Leben zu führen.
Maschinelles Lernen kann überwacht oder unbeaufsichtigt sein. Wenn Sie weniger Daten und eindeutig gekennzeichnete Daten für das Training haben, entscheiden Sie sich für betreutes Lernen. Unbeaufsichtigtes Lernen würde im Allgemeinen zu einer besseren Leistung und besseren Ergebnissen bei großen Datenmengen führen. Wenn Sie einen großen Datensatz haben, der leicht verfügbar ist, entscheiden Sie sich für Deep-Learning-Techniken. Sie haben auch Reinforcement Learning und Deep Reinforcement Learning gelernt. Sie wissen jetzt, was neuronale Netze sind, welche Anwendungen sie haben und welche Einschränkungen sie haben.
Bei der Entwicklung eigener Modelle für maschinelles Lernen haben Sie sich schließlich die Auswahl verschiedener Entwicklungssprachen, IDEs und Plattformen angesehen. Als nächstes müssen Sie mit dem Lernen und Üben jeder maschinellen Lerntechnik beginnen. Das Thema ist groß, es bedeutet, dass es eine Breite gibt, aber wenn Sie die Tiefe berücksichtigen, kann jedes Thema in wenigen Stunden gelernt werden. Jedes Thema ist unabhängig voneinander. Sie müssen jeweils ein Thema berücksichtigen, es lernen, üben und die darin enthaltenen Algorithmen mithilfe einer von Ihnen gewählten Sprache implementieren. Dies ist der beste Weg, um maschinelles Lernen zu lernen. Wenn Sie jeweils ein Thema üben, werden Sie sehr bald die Breite erreichen, die ein Experte für maschinelles Lernen letztendlich benötigt.
Viel Glück!