Minería de datos: minería de datos de texto
Las bases de datos de texto consisten en una gran colección de documentos. Recogen esta información de varias fuentes como artículos de noticias, libros, bibliotecas digitales, mensajes de correo electrónico, páginas web, etc. Debido al aumento en la cantidad de información, las bases de datos de texto están creciendo rápidamente. En muchas de las bases de datos de texto, los datos están semiestructurados.
Por ejemplo, un documento puede contener algunos campos estructurados, como título, autor, publicación_fecha, etc. Pero junto con los datos de estructura, el documento también contiene componentes de texto no estructurados, como resumen y contenido. Sin saber qué podría haber en los documentos, es difícil formular consultas efectivas para analizar y extraer información útil de los datos. Los usuarios necesitan herramientas para comparar los documentos y clasificar su importancia y relevancia. Por lo tanto, la minería de texto se ha vuelto popular y un tema esencial en la minería de datos.
Recuperación de información
La recuperación de información se ocupa de la recuperación de información de una gran cantidad de documentos basados en texto. Algunos de los sistemas de bases de datos no suelen estar presentes en los sistemas de recuperación de información porque ambos manejan diferentes tipos de datos. Los ejemplos de sistema de recuperación de información incluyen:
- Sistema de catálogo de biblioteca en línea
- Sistemas de gestión de documentos en línea
- Sistemas de búsqueda web, etc.
Note- El principal problema en un sistema de recuperación de información es localizar documentos relevantes en una colección de documentos basándose en la consulta de un usuario. Este tipo de consulta del usuario consta de algunas palabras clave que describen una necesidad de información.
En tales problemas de búsqueda, el usuario toma la iniciativa de extraer información relevante de una colección. Esto es apropiado cuando el usuario tiene una necesidad de información ad-hoc, es decir, una necesidad a corto plazo. Pero si el usuario tiene una necesidad de información a largo plazo, el sistema de recuperación también puede tomar una iniciativa para enviar al usuario cualquier elemento de información recién llegado.
Este tipo de acceso a la información se denomina filtrado de información. Y los sistemas correspondientes se conocen como Sistemas de filtrado o Sistemas de recomendación.
Medidas básicas para la recuperación de texto
Necesitamos comprobar la precisión de un sistema cuando recupera una serie de documentos sobre la base de la entrada del usuario. Deje que el conjunto de documentos relevantes para una consulta se indique como {Relevante} y el conjunto de documentos recuperados como {Recuperado}. El conjunto de documentos que son relevantes y recuperados se puede indicar como {Relevante} ∩ {Recuperado}. Esto se puede mostrar en forma de diagrama de Venn de la siguiente manera:
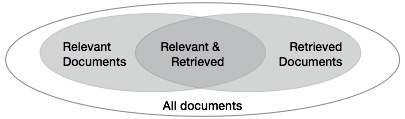
Hay tres medidas fundamentales para evaluar la calidad de la recuperación de texto:
- Precision
- Recall
- F-score
Precisión
La precisión es el porcentaje de documentos recuperados que de hecho son relevantes para la consulta. La precisión se puede definir como:
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|Recordar
La recuperación es el porcentaje de documentos que son relevantes para la consulta y que de hecho se recuperaron. La recuperación se define como:
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|Puntuación F
La puntuación F es la compensación más utilizada. El sistema de recuperación de información a menudo necesita compensar la precisión o viceversa. La puntuación F se define como la media armónica de recuperación o precisión de la siguiente manera:
F-score = recall x precision / (recall + precision) / 2