Big Data Analytics - Cycle de vie des données
Cycle de vie de l'exploration de données traditionnelle
Afin de fournir un cadre pour organiser le travail nécessaire à une organisation et fournir des informations claires à partir du Big Data, il est utile de le considérer comme un cycle avec différentes étapes. Ce n'est en aucun cas linéaire, ce qui signifie que toutes les étapes sont liées les unes aux autres. Ce cycle présente des similitudes superficielles avec le cycle d'exploration de données plus traditionnel décrit dansCRISP methodology.
Méthodologie CRISP-DM
le CRISP-DM methodologyqui signifie Processus standard intersectoriel pour l'exploration de données, est un cycle qui décrit les approches couramment utilisées que les experts en exploration de données utilisent pour résoudre les problèmes de l'exploration de données BI traditionnelle. Il est toujours utilisé dans les équipes d'exploration de données BI traditionnelles.
Jetez un œil à l'illustration suivante. Il montre les principales étapes du cycle telles que décrites par la méthodologie CRISP-DM et comment elles sont interdépendantes.
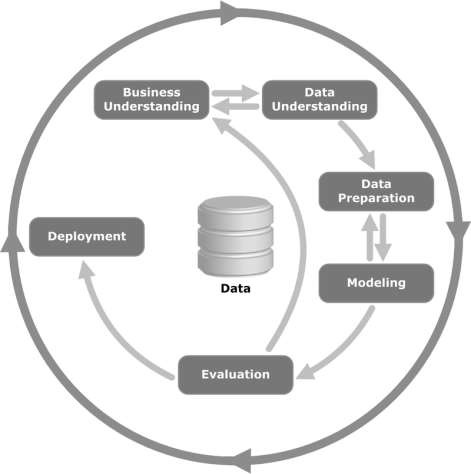
CRISP-DM a été conçu en 1996 et l'année suivante, il a été lancé en tant que projet de l'Union européenne dans le cadre de l'initiative de financement ESPRIT. Le projet était dirigé par cinq sociétés: SPSS, Teradata, Daimler AG, NCR Corporation et OHRA (une compagnie d'assurance). Le projet a finalement été intégré dans SPSS. La méthodologie est extrêmement détaillée sur la manière dont un projet d'exploration de données doit être spécifié.
Apprenons maintenant un peu plus sur chacune des étapes impliquées dans le cycle de vie du CRISP-DM -
Business Understanding- Cette phase initiale se concentre sur la compréhension des objectifs et des exigences du projet d'un point de vue commercial, puis sur la conversion de ces connaissances en une définition de problème d'exploration de données. Un plan préliminaire est conçu pour atteindre les objectifs. Un modèle de décision, en particulier celui construit à l'aide du standard Decision Model and Notation, peut être utilisé.
Data Understanding - La phase de compréhension des données commence par une première collecte de données et se poursuit par des activités afin de se familiariser avec les données, d'identifier les problèmes de qualité des données, de découvrir les premières informations sur les données, ou de détecter des sous-ensembles intéressants pour former des hypothèses d'informations cachées.
Data Preparation- La phase de préparation des données couvre toutes les activités de construction du jeu de données final (données qui seront introduites dans le ou les outils de modélisation) à partir des données brutes initiales. Les tâches de préparation des données sont susceptibles d'être effectuées plusieurs fois, et non dans un ordre prescrit. Les tâches incluent la sélection de table, d'enregistrement et d'attribut ainsi que la transformation et le nettoyage des données pour les outils de modélisation.
Modeling- Dans cette phase, diverses techniques de modélisation sont sélectionnées et appliquées et leurs paramètres sont calibrés à des valeurs optimales. En règle générale, il existe plusieurs techniques pour le même type de problème d'exploration de données. Certaines techniques ont des exigences spécifiques sur la forme des données. Par conséquent, il est souvent nécessaire de revenir à la phase de préparation des données.
Evaluation- À ce stade du projet, vous avez construit un modèle (ou des modèles) qui semble être de haute qualité, du point de vue de l'analyse des données. Avant de procéder au déploiement final du modèle, il est important de procéder à une évaluation approfondie du modèle et de passer en revue les étapes exécutées pour construire le modèle, pour être certain qu'il atteint correctement les objectifs commerciaux.
Un objectif clé est de déterminer s'il existe un problème commercial important qui n'a pas été suffisamment pris en compte. À la fin de cette phase, une décision sur l'utilisation des résultats de l'exploration de données doit être prise.
Deployment- La création du modèle n'est généralement pas la fin du projet. Même si le but du modèle est d'accroître la connaissance des données, les connaissances acquises devront être organisées et présentées d'une manière utile au client.
Selon les besoins, la phase de déploiement peut être aussi simple que la génération d'un rapport ou aussi complexe que la mise en œuvre d'un scoring de données répétable (par exemple, allocation de segment) ou d'un processus d'exploration de données.
Dans de nombreux cas, ce sera le client, et non l'analyste de données, qui effectuera les étapes de déploiement. Même si l'analyste déploie le modèle, il est important que le client comprenne dès le départ les actions qui devront être menées pour pouvoir réellement utiliser les modèles créés.
Méthodologie SEMMA
SEMMA est une autre méthodologie développée par SAS pour la modélisation de l'exploration de données. Ça signifieSample, Explorez, Modifier, Model, et Asses. Voici une brève description de ses étapes -
Sample- Le processus commence par l'échantillonnage des données, par exemple, la sélection de l'ensemble de données pour la modélisation. L'ensemble de données doit être suffisamment grand pour contenir suffisamment d'informations à récupérer, mais suffisamment petit pour être utilisé efficacement. Cette phase traite également du partitionnement des données.
Explore - Cette phase couvre la compréhension des données en découvrant des relations anticipées et imprévues entre les variables, mais aussi des anomalies, à l'aide de la visualisation des données.
Modify - La phase de modification contient des méthodes pour sélectionner, créer et transformer des variables en vue de la modélisation des données.
Model - Dans la phase de modèle, l'accent est mis sur l'application de diverses techniques de modélisation (data mining) sur les variables préparées afin de créer des modèles susceptibles de fournir le résultat souhaité.
Assess - L'évaluation des résultats de la modélisation montre la fiabilité et l'utilité des modèles créés.
La principale différence entre CRISM – DM et SEMMA est que SEMMA se concentre sur l'aspect modélisation, tandis que CRISP-DM donne plus d'importance aux étapes du cycle avant la modélisation telles que la compréhension du problème métier à résoudre, la compréhension et le prétraitement des données à résoudre. utilisé comme entrée, par exemple, des algorithmes d'apprentissage automatique.
Cycle de vie du Big Data
Dans le contexte actuel du Big Data, les approches précédentes sont soit incomplètes, soit sous-optimales. Par exemple, la méthodologie SEMMA ignore complètement la collecte de données et le prétraitement des différentes sources de données. Ces étapes constituent normalement la majeure partie du travail d'un projet Big Data réussi.
Un cycle d'analyse de Big Data peut être décrit par l'étape suivante -
- Définition du problème commercial
- Research
- Évaluation des ressources humaines
- L'acquisition des données
- Munging de données
- Stockage de données
- L'analyse exploratoire des données
- Préparation des données pour la modélisation et l'évaluation
- Modeling
- Implementation
Dans cette section, nous allons jeter un peu de lumière sur chacune de ces étapes du cycle de vie du Big Data.
Définition du problème commercial
C'est un point commun dans le cycle de vie traditionnel de la BI et de l'analyse du Big Data. Normalement, il s'agit d'une étape non triviale d'un projet Big Data pour définir le problème et évaluer correctement le gain potentiel qu'il peut avoir pour une organisation. Il semble évident de le mentionner, mais il faut évaluer quels sont les gains et les coûts attendus du projet.
Recherche
Analysez ce que d'autres entreprises ont fait dans la même situation. Il s'agit de rechercher des solutions raisonnables pour votre entreprise, même si cela implique d'adapter d'autres solutions aux ressources et aux exigences de votre entreprise. À ce stade, une méthodologie pour les étapes futures doit être définie.
Évaluation des ressources humaines
Une fois le problème défini, il est raisonnable de continuer à analyser si le personnel actuel est en mesure de mener à bien le projet. Les équipes de BI traditionnelles peuvent ne pas être capables de fournir une solution optimale à toutes les étapes, il faut donc en tenir compte avant de démarrer le projet s'il est nécessaire d'externaliser une partie du projet ou d'embaucher plus de personnes.
L'acquisition des données
Cette section est essentielle dans un cycle de vie de Big Data; il définit le type de profils nécessaires pour fournir le produit de données résultant. La collecte de données est une étape non triviale du processus; il implique normalement la collecte de données non structurées provenant de différentes sources. Pour donner un exemple, il peut s'agir d'écrire un robot d'exploration pour récupérer les avis d'un site Web. Cela implique de traiter du texte, peut-être dans différentes langues, ce qui nécessite normalement un temps considérable.
Munging de données
Une fois que les données sont extraites, par exemple, du Web, elles doivent être stockées dans un format facile à utiliser. Pour continuer avec les exemples de critiques, supposons que les données soient extraites de différents sites où chacun a un affichage différent des données.
Supposons qu'une source de données donne des avis en termes de notation en étoiles, il est donc possible de lire cela comme un mappage pour la variable de réponse y ∈ {1, 2, 3, 4, 5}. Une autre source de données donne des avis en utilisant deux systèmes de flèches, une pour le vote à la hausse et l'autre pour le vote à la baisse. Cela impliquerait une variable de réponse de la formey ∈ {positive, negative}.
Afin de combiner les deux sources de données, une décision doit être prise afin de rendre ces deux représentations de réponse équivalentes. Cela peut impliquer de convertir la première représentation de réponse de source de données en une seconde forme, en considérant une étoile comme négative et cinq étoiles comme positive. Ce processus nécessite souvent une grande allocation de temps pour être livré avec une bonne qualité.
Stockage de données
Une fois les données traitées, elles doivent parfois être stockées dans une base de données. Les technologies du Big Data offrent de nombreuses alternatives sur ce point. L'alternative la plus courante consiste à utiliser le système de fichiers Hadoop pour le stockage qui fournit aux utilisateurs une version limitée de SQL, connue sous le nom de langage de requête HIVE. Cela permet à la plupart des tâches d'analyse d'être effectuées de la même manière que dans les entrepôts de données BI traditionnels, du point de vue de l'utilisateur. Les autres options de stockage à considérer sont MongoDB, Redis et SPARK.
Cette étape du cycle est liée à la connaissance des ressources humaines en termes de leurs capacités à mettre en œuvre différentes architectures. Les versions modifiées des entrepôts de données traditionnels sont toujours utilisées dans les applications à grande échelle. Par exemple, teradata et IBM proposent des bases de données SQL capables de gérer des téraoctets de données; des solutions open source telles que postgreSQL et MySQL sont toujours utilisées pour des applications à grande échelle.
Même s'il existe des différences dans la façon dont les différents stockages fonctionnent en arrière-plan, du côté client, la plupart des solutions fournissent une API SQL. Par conséquent, avoir une bonne compréhension de SQL est toujours une compétence clé pour l'analyse de Big Data.
Cette étape semble a priori être le sujet le plus important, en pratique, ce n'est pas vrai. Ce n'est même pas une étape essentielle. Il est possible de mettre en œuvre une solution Big Data qui fonctionnerait avec des données en temps réel, donc dans ce cas, nous n'avons besoin que de collecter des données pour développer le modèle, puis de l'implémenter en temps réel. Il ne serait donc pas du tout nécessaire de stocker formellement les données.
L'analyse exploratoire des données
Une fois que les données ont été nettoyées et stockées de manière à pouvoir en extraire des informations, la phase d'exploration des données est obligatoire. L'objectif de cette étape est de comprendre les données, cela se fait normalement avec des techniques statistiques et également en traçant les données. C'est une bonne étape pour évaluer si la définition du problème a du sens ou est faisable.
Préparation des données pour la modélisation et l'évaluation
Cette étape consiste à remodeler les données nettoyées récupérées précédemment et à utiliser un prétraitement statistique pour l'imputation des valeurs manquantes, la détection des valeurs aberrantes, la normalisation, l'extraction des caractéristiques et la sélection des caractéristiques.
La modélisation
L'étape précédente aurait dû produire plusieurs ensembles de données pour la formation et les tests, par exemple un modèle prédictif. Cette étape consiste à essayer différents modèles et à avoir hâte de résoudre le problème commercial en question. En pratique, il est normalement souhaitable que le modèle donne un aperçu de l'entreprise. Enfin, le meilleur modèle ou combinaison de modèles est sélectionné en évaluant ses performances sur un ensemble de données laissé de côté.
la mise en oeuvre
Dans cette étape, le produit de données développé est implémenté dans le pipeline de données de l'entreprise. Cela implique la mise en place d'un schéma de validation pendant que le produit de données fonctionne, afin de suivre ses performances. Par exemple, dans le cas de la mise en œuvre d'un modèle prédictif, cette étape impliquerait l'application du modèle à de nouvelles données et une fois la réponse disponible, évaluer le modèle.