DAA - Sequenza comune più lunga
Il problema di sottosequenza comune più lungo è trovare la sequenza più lunga che esiste in entrambe le stringhe date.
Sotto sequenza
Consideriamo una successione S = <s 1 , s 2 , s 3 , s 4 ,…, s n >.
Una successione Z = <z 1 , z 2 , z 3 , z 4 ,…, z m > su S è chiamata sottosequenza di S, se e solo se può essere derivata dalla cancellazione S di alcuni elementi.
Successione comune
Supponiamo, X e Ysono due sequenze su un insieme finito di elementi. Possiamo dirloZ è una sottosequenza comune di X e Y, Se Z è una sottosequenza di entrambi X e Y.
Successione comune più lunga
Se viene fornito un insieme di sequenze, il problema di sottosequenza comune più lungo è trovare una sottosequenza comune di tutte le sequenze che sia di lunghezza massima.
Il problema di sottosequenza comune più lungo è un classico problema di informatica, la base dei programmi di confronto dei dati come l'utilità diff e ha applicazioni in bioinformatica. È anche ampiamente utilizzato dai sistemi di controllo delle revisioni, come SVN e Git, per riconciliare più modifiche apportate a una raccolta di file controllata dalla revisione.
Metodo naïve
Permettere X essere una sequenza di lunghezza m e Y una sequenza di lunghezza n. Verificare ogni sottosequenza diX se si tratta di una sottosequenza di Ye restituisce la sottosequenza comune più lunga trovata.
Ci sono 2m sottosequenze di X. Verificare le sequenze che si tratti o meno di una sottosequenza diY prende O(n)tempo. Quindi, l'algoritmo ingenuo prenderebbeO(n2m) tempo.
Programmazione dinamica
Siano le sequenze X = <x 1 , x 2 , x 3 ,…, x m > e Y = <y 1 , y 2 , y 3 ,…, y n > . Per calcolare la lunghezza di un elemento viene utilizzato il seguente algoritmo.
In questa procedura, table C[m, n] viene calcolato in ordine di riga principale e un'altra tabella B[m,n] viene calcolato per costruire una soluzione ottimale.
Algorithm: LCS-Length-Table-Formulation (X, Y)
m := length(X)
n := length(Y)
for i = 1 to m do
C[i, 0] := 0
for j = 1 to n do
C[0, j] := 0
for i = 1 to m do
for j = 1 to n do
if xi = yj
C[i, j] := C[i - 1, j - 1] + 1
B[i, j] := ‘D’
else
if C[i -1, j] ≥ C[i, j -1]
C[i, j] := C[i - 1, j] + 1
B[i, j] := ‘U’
else
C[i, j] := C[i, j - 1]
B[i, j] := ‘L’
return C and BAlgorithm: Print-LCS (B, X, i, j)
if i = 0 and j = 0
return
if B[i, j] = ‘D’
Print-LCS(B, X, i-1, j-1)
Print(xi)
else if B[i, j] = ‘U’
Print-LCS(B, X, i-1, j)
else
Print-LCS(B, X, i, j-1)Questo algoritmo stamperà la sottosequenza comune più lunga di X e Y.
Analisi
A popolare la tabella, il file outer for ciclo itera m tempi e interiore for ciclo itera nvolte. Quindi, la complessità dell'algoritmo è O (m, n) , dovem e n sono la lunghezza di due stringhe.
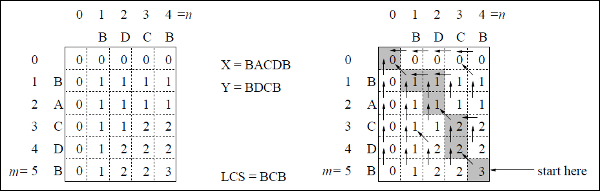
Esempio
In questo esempio, abbiamo due stringhe X = BACDB e Y = BDCB per trovare la sottosequenza comune più lunga.
Seguendo l'algoritmo LCS-Length-Table-Formulation (come indicato sopra), abbiamo calcolato la tabella C (mostrata a sinistra) e la tabella B (mostrata a destra).
Nella tabella B, invece di "D", "L" e "U", utilizziamo rispettivamente la freccia diagonale, la freccia sinistra e la freccia su. Dopo aver generato la tabella B, l'LCS è determinato dalla funzione LCS-Print. Il risultato è BCB.