회귀 모델 구축
로지스틱 회귀는 범주 형 종속 변수의 확률을 예측하는 데 사용되는 기계 학습 알고리즘을 나타냅니다. 로지스틱 회귀 분석에서 종속 변수는 1로 코딩 된 데이터로 구성된 이진 변수입니다 (부울 값 true 및 false).
이 장에서는 연속 변수를 사용하여 Python에서 회귀 모델을 개발하는 데 중점을 둡니다. 선형 회귀 모델의 예는 CSV 파일의 데이터 탐색에 중점을 둡니다.
분류 목표는 고객이 정기 예금에 가입 (1/0)할지 여부를 예측하는 것입니다.
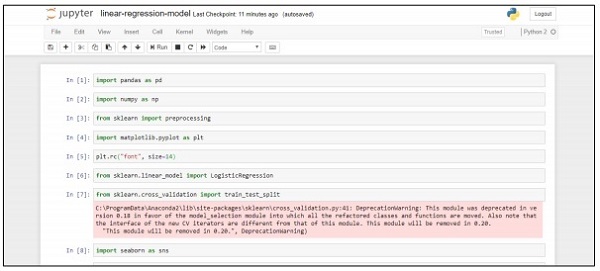
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
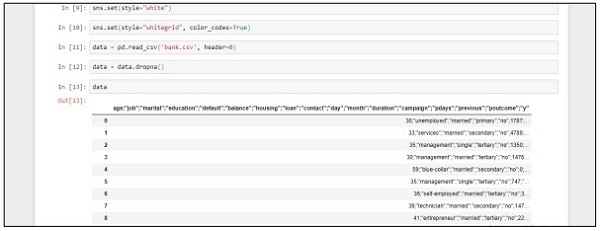
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))"Jupyter Notebook"을 사용하여 Anaconda Navigator에서 위 코드를 구현하려면 다음 단계를 따르십시오.
Step 1 − Anaconda Navigator로 Jupyter 노트북을 시작합니다.
Step 2 − csv 파일을 업로드하여 체계적으로 회귀 모델의 출력을 얻습니다.
Step 3 − 새 파일을 생성하고 위에서 언급 한 코드 라인을 실행하여 원하는 출력을 얻습니다.