애자일 데이터 과학-예측의 역할
이 장에서는 애자일 데이터 과학에서 예측의 역할에 대해 알아 보겠습니다. 대화 형 보고서는 데이터의 다양한 측면을 노출합니다. 예측은 민첩한 스프린트의 네 번째 계층을 형성합니다.
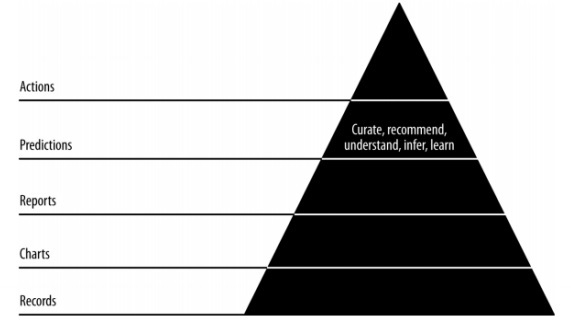
예측을 할 때 우리는 항상 과거 데이터를 참조하고 향후 반복을위한 추론으로 사용합니다. 이 전체 프로세스에서 데이터를 과거 데이터의 일괄 처리에서 미래에 대한 실시간 데이터로 전환합니다.
예측의 역할은 다음과 같습니다.
예측은 예측에 도움이됩니다. 일부 예측은 통계적 추론을 기반으로합니다. 일부 예측은 전문가의 의견을 기반으로합니다.
통계적 추론은 모든 종류의 예측과 관련됩니다.
때로는 예측이 정확하고 때로는 예측이 정확하지 않습니다.
예측 분석
예측 분석에는 현재 및 과거 사실을 분석하여 미래 및 알려지지 않은 이벤트에 대한 예측을 수행하는 예측 모델링, 기계 학습 및 데이터 마이닝의 다양한 통계 기술이 포함됩니다.
예측 분석에는 교육 데이터가 필요합니다. 훈련 된 데이터에는 독립 및 종속 기능이 포함됩니다. 종속 기능은 사용자가 예측하려는 값입니다. 독립 기능은 종속 기능을 기반으로 예측하려는 것을 설명하는 기능입니다.
기능 연구를 기능 공학이라고합니다. 이것은 예측을하는 데 중요합니다. 데이터 시각화 및 탐색 적 데이터 분석은 기능 엔지니어링의 일부입니다. 이들은의 핵심을 형성합니다Agile data science.
예측하기
애자일 데이터 과학에서 예측을 수행하는 방법에는 두 가지가 있습니다.
Regression
Classification
회귀 또는 분류를 구축하는 것은 비즈니스 요구 사항 및 분석에 완전히 의존합니다. 연속 변수 예측은 회귀 모델로 이어지고 범주 형 변수 예측은 분류 모델로 이어집니다.
회귀
회귀는 기능을 구성하는 예를 고려하여 숫자 출력을 생성합니다.
분류
분류는 입력을 받아 범주 분류를 생성합니다.
Note − 통계적 예측에 대한 입력을 정의하고 기계가 학습 할 수 있도록하는 예제 데이터 세트를 "훈련 데이터"라고합니다.