애자일 데이터 과학-데이터 강화
데이터 강화는 원시 데이터를 향상, 정제 및 개선하는 데 사용되는 다양한 프로세스를 의미합니다. 유용한 데이터 변환 (원시 데이터를 유용한 정보로)을 나타냅니다. 데이터 보강 프로세스는 데이터를 현대 비즈니스 또는 기업의 귀중한 데이터 자산으로 만드는 데 중점을 둡니다.
가장 일반적인 데이터 보강 프로세스에는 특정 결정 알고리즘을 사용하여 데이터베이스의 철자 오류 또는 인쇄 오류 수정이 포함됩니다. 데이터 보강 도구는 간단한 데이터 테이블에 유용한 정보를 추가합니다.
단어의 철자 교정을 위해 다음 코드를 고려하십시오-
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probabilities of words"
return WORDS[word] / N
def correction(word):
"Spelling correction of word"
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
print(correction('speling'))
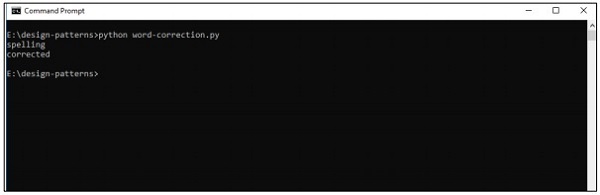
print(correction('korrectud'))이 프로그램에서는 수정 된 단어가 포함 된 "big.txt"와 일치합니다. 단어는 텍스트 파일에 포함 된 단어와 일치하고 그에 따라 적절한 결과를 인쇄합니다.
산출
위의 코드는 다음 출력을 생성합니다.