애자일 데이터 과학-데이터 시각화
데이터 시각화는 데이터 과학에서 매우 중요한 역할을합니다. 데이터 시각화를 데이터 과학의 모듈로 간주 할 수 있습니다. 데이터 과학에는 예측 모델 구축 이상의 것이 포함됩니다. 여기에는 모델에 대한 설명과이를 사용하여 데이터를 이해하고 결정을 내리는 것이 포함됩니다. 데이터 시각화는 가장 설득력있는 방식으로 데이터를 표현하는 데 없어서는 안될 부분입니다.
데이터 과학 관점에서 데이터 시각화는 변화와 추세를 보여주는 하이라이트 기능입니다.
효과적인 데이터 시각화를 위해 다음 지침을 고려하십시오-
공통 척도에 따라 데이터를 배치합니다.
막대를 사용하면 원과 사각형을 비교할 때 더 효과적입니다.
산점도에는 적절한 색상을 사용해야합니다.
비율을 표시하려면 원형 차트를 사용하십시오.
Sunburst 시각화는 계층 적 플롯에 더 효과적입니다.
Agile은 데이터 시각화를위한 간단한 스크립팅 언어가 필요하며 데이터 과학이 협력하여 데이터 시각화를 위해 제안되는 언어는 "Python"입니다.
예 1
다음 예는 특정 연도에 계산 된 GDP의 데이터 시각화를 보여줍니다. "Matplotlib"는 Python에서 데이터 시각화를위한 최고의 라이브러리입니다. 이 라이브러리의 설치는 다음과 같습니다.
이것을 이해하려면 다음 코드를 고려하십시오.
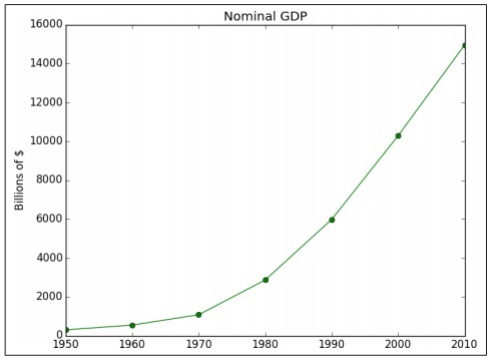
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()산출
위의 코드는 다음 출력을 생성합니다.
축 레이블, 선 스타일 및 포인트 마커를 사용하여 차트를 사용자 정의하는 방법에는 여러 가지가 있습니다. 더 나은 데이터 시각화를 보여주는 다음 예제에 집중 해 보겠습니다. 이러한 결과는 더 나은 결과를 위해 사용될 수 있습니다.
예 2
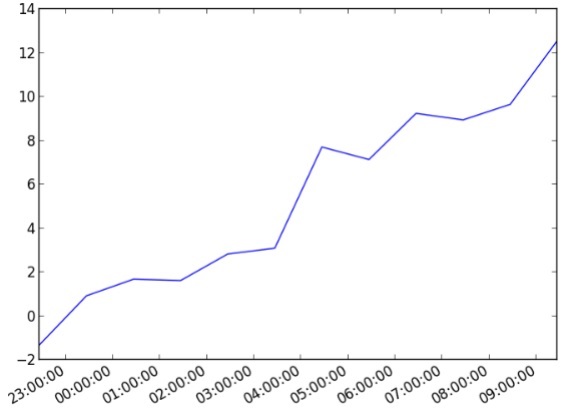
import datetime
import random
import matplotlib.pyplot as plt
# make up some data
x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)]
y = [i+random.gauss(0,1) for i,_ in enumerate(x)]
# plot
plt.plot(x,y)
# beautify the x-labels
plt.gcf().autofmt_xdate()
plt.show()산출
위의 코드는 다음 출력을 생성합니다.