빅 데이터 분석-시계열 분석
시계열은 날짜 또는 타임 스탬프로 인덱싱 된 범주 형 또는 숫자 변수의 관측 시퀀스입니다. 시계열 데이터의 명확한 예는 주가의 시계열입니다. 다음 표에서 시계열 데이터의 기본 구조를 볼 수 있습니다. 이 경우 관찰은 매시간 기록됩니다.
| 타임 스탬프 | 재고-가격 |
|---|---|
| 2015-10-11 09:00:00 | 100 |
| 2015-10-11 10:00:00 | 110 |
| 2015-10-11 11:00:00 | 105 |
| 2015-10-11 12:00:00 | 90 |
| 2015-10-11 13:00:00 | 120 |
일반적으로 시계열 분석의 첫 번째 단계는 시리즈를 그리는 것입니다. 이는 일반적으로 선 차트로 수행됩니다.
시계열 분석의 가장 일반적인 응용 프로그램은 데이터의 시간적 구조를 사용하여 숫자 값의 미래 값을 예측하는 것입니다. 즉, 사용 가능한 관측치는 미래의 값을 예측하는 데 사용됩니다.
데이터의 시간적 순서는 전통적인 회귀 방법이 유용하지 않음을 의미합니다. 강력한 예측을 구축하려면 데이터의 시간적 순서를 고려하는 모델이 필요합니다.
시계열 분석에 가장 널리 사용되는 모델은 Autoregressive Moving Average(ARMA). 모델은 두 부분으로 구성됩니다.autoregressive (AR) 부분과 moving average(MA) 부분. 그런 다음 모델은 일반적으로 ARMA (p, q) 모델이라고합니다. 여기서 p 는 자기 회귀 부분 의 차수 이고 q 는 이동 평균 부분의 차수입니다.
자기 회귀 모형
AR (p)의 차 (P)의 자기 회귀 모델로 판독된다. 수학적으로 다음과 같이 작성됩니다.
$$X_t = c + \sum_{i = 1}^{P} \phi_i X_{t - i} + \varepsilon_{t}$$
여기서 {φ 1 ,…, φ p }는 추정 할 매개 변수이고, c는 상수이고, 랜덤 변수 ε t 는 백색 잡음을 나타냅니다. 모델이 고정 된 상태로 유지되도록 매개 변수 값에 대한 일부 구속이 필요합니다.
이동 평균
표기 MA (Q)는 주문의 이동 평균 모델을 말한다 Q -
$$X_t = \mu + \varepsilon_t + \sum_{i = 1}^{q} \theta_i \varepsilon_{t - i}$$
여기서 θ 1 , ..., θ q 는 모델의 매개 변수이고, μ는 X t 의 기대 값 이며, ε t , ε t − 1 , ...은 백색 잡음 오류 항입니다.
자기 회귀 이동 평균
ARMA (P, Q) 모델 콤바인 P는 회귀 조건 및 Q 이동 평균 용어. 수학적으로 모델은 다음 공식으로 표현됩니다.
$$X_t = c + \varepsilon_t + \sum_{i = 1}^{P} \phi_iX_{t - 1} + \sum_{i = 1}^{q} \theta_i \varepsilon_{t-i}$$
우리는 것을 알 수 있습니다 ARMA (P, Q) 모델의 조합 AR (P) 및 MA (Q) 모델.
모델의 일부 직관을 제공하기 위해 방정식의 AR 부분이 X에 대한 매개 변수를 추정하고자하는 것이 생각 난 - t X의에서 변수의 값을 예측하기 위해 관찰을 t을 . 결국 과거 값의 가중 평균입니다. MA 섹션은 동일한 접근법을 사용하지만 이전 관측치의 오류 인 ε t − i를 사용 합니다. 결국 모델의 결과는 가중 평균입니다.
다음 코드 조각 은 R에서 ARMA (p, q) 를 구현하는 방법을 보여줍니다 .
# install.packages("forecast")
library("forecast")
# Read the data
data = scan('fancy.dat')
ts_data <- ts(data, frequency = 12, start = c(1987,1))
ts_data
plot.ts(ts_data)데이터 플로팅은 일반적으로 데이터에 시간적 구조가 있는지 확인하는 첫 번째 단계입니다. 플롯에서 매년 말에 강한 급등이 있음을 알 수 있습니다.
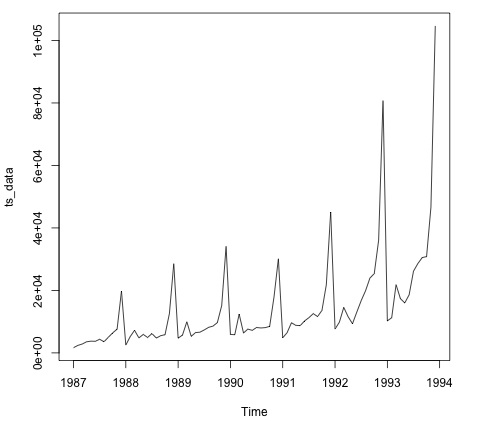
다음 코드는 ARMA 모델을 데이터에 맞 춥니 다. 여러 모델 조합을 실행하고 오류가 적은 모델을 선택합니다.
# Fit the ARMA model
fit = auto.arima(ts_data)
summary(fit)
# Series: ts_data
# ARIMA(1,1,1)(0,1,1)[12]
# Coefficients:
# ar1 ma1 sma1
# 0.2401 -0.9013 0.7499
# s.e. 0.1427 0.0709 0.1790
#
# sigma^2 estimated as 15464184: log likelihood = -693.69
# AIC = 1395.38 AICc = 1395.98 BIC = 1404.43
# Training set error measures:
# ME RMSE MAE MPE MAPE MASE ACF1
# Training set 328.301 3615.374 2171.002 -2.481166 15.97302 0.4905797 -0.02521172