TensorFlow-컨볼 루션 신경망
머신 러닝 개념을 이해 한 후에는 이제 딥 러닝 개념으로 초점을 이동할 수 있습니다. 딥 러닝은 기계 학습의 한 부분이며 최근 수십 년 동안 연구자들이 취한 중요한 단계로 간주됩니다. 딥 러닝 구현의 예에는 이미지 인식 및 음성 인식과 같은 애플리케이션이 포함됩니다.
다음은 심층 신경망의 두 가지 중요한 유형입니다.
- 컨볼 루션 신경망
- 순환 신경망
이 장에서는 Convolutional Neural Networks 인 CNN에 초점을 맞출 것입니다.
컨볼 루션 신경망
컨볼 루션 신경망은 여러 계층의 배열을 통해 데이터를 처리하도록 설계되었습니다. 이러한 유형의 신경망은 이미지 인식 또는 얼굴 인식과 같은 애플리케이션에 사용됩니다. CNN과 다른 일반 신경망의 주요 차이점은 CNN이 입력을 2 차원 배열로 받아들이고 다른 신경망이 집중하는 특징 추출에 초점을 맞추지 않고 이미지에서 직접 작동한다는 것입니다.
CNN의 지배적 인 접근 방식에는 인식 문제에 대한 솔루션이 포함됩니다. Google 및 Facebook과 같은 최고의 기업은 더 빠른 속도로 활동을 수행하기 위해 인식 프로젝트를위한 연구 개발에 투자했습니다.
컨볼 루션 신경망은 세 가지 기본 아이디어를 사용합니다.
- 지역별 분야
- Convolution
- Pooling
이 아이디어를 자세히 이해합시다.
CNN은 입력 데이터 내에 존재하는 공간 상관 관계를 활용합니다. 신경망의 각 동시 계층은 일부 입력 뉴런을 연결합니다. 이 특정 영역을 로컬 수용 필드라고합니다. 국소 수용 필드는 숨겨진 뉴런에 초점을 맞 춥니 다. 은닉 뉴런은 언급 된 필드 내부의 입력 데이터를 처리하여 특정 경계 밖의 변경 사항을 인식하지 못합니다.
다음은 로컬 각 필드를 생성하는 다이어그램 표현입니다.
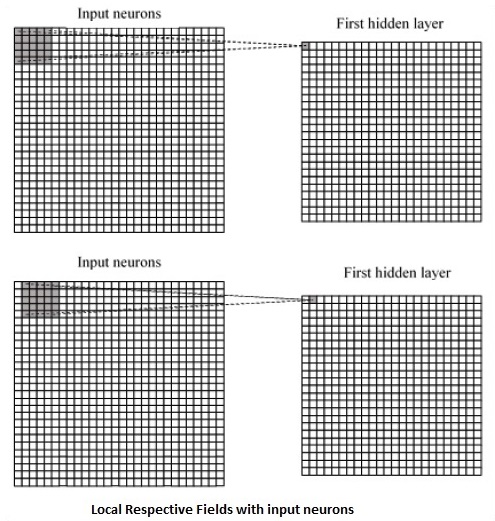
위의 표현을 관찰하면 각 연결은 한 레이어에서 다른 레이어로의 이동과 관련된 연결로 숨겨진 뉴런의 가중치를 학습합니다. 여기에서 개별 뉴런은 수시로 전환을 수행합니다. 이 프로세스를 "컨볼 루션"이라고합니다.
입력 계층에서 숨겨진 특징 맵으로의 연결 매핑은 "공유 가중치"로 정의되고 포함 된 편향은 "공유 편향"이라고합니다.
CNN 또는 컨벌루션 신경망은 CNN 선언 바로 뒤에 위치하는 계층 인 풀링 계층을 사용합니다. 컨볼 루션 네트워크에서 나오는 기능 맵으로 사용자의 입력을 받아 압축 된 기능 맵을 준비합니다. 풀링 레이어는 이전 레이어의 뉴런으로 레이어를 만드는 데 도움이됩니다.
CNN의 TensorFlow 구현
이 섹션에서는 CNN의 TensorFlow 구현에 대해 알아 봅니다. 전체 네트워크의 실행과 적절한 차원이 필요한 단계는 다음과 같습니다.
Step 1 − CNN 모델을 계산하는 데 필요한 TensorFlow 및 데이터 세트 모듈에 필요한 모듈을 포함합니다.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_dataStep 2 − 호출 된 함수 선언 run_cnn(), 데이터 자리 표시 자의 선언과 함께 다양한 매개 변수 및 최적화 변수를 포함합니다. 이러한 최적화 변수는 훈련 패턴을 선언합니다.
def run_cnn():
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
learning_rate = 0.0001
epochs = 10
batch_size = 50Step 3 −이 단계에서는 28 x 28 픽셀 = 784에 대해 입력 매개 변수를 사용하여 훈련 데이터 자리 표시자를 선언합니다. 이것은 다음에서 가져온 평면화 된 이미지 데이터입니다. mnist.train.nextbatch().
요구 사항에 따라 텐서를 재구성 할 수 있습니다. 첫 번째 값 (-1)은 전달 된 데이터 양에 따라 해당 차원을 동적으로 형성하도록 함수에 지시합니다. 두 개의 중간 크기는 이미지 크기 (예 : 28 x 28)로 설정됩니다.
x = tf.placeholder(tf.float32, [None, 784])
x_shaped = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, [None, 10])Step 4 − 이제 일부 conv 층을 생성하는 것이 중요합니다 −
layer1 = create_new_conv_layer(x_shaped, 1, 32, [5, 5], [2, 2], name = 'layer1')
layer2 = create_new_conv_layer(layer1, 32, 64, [5, 5], [2, 2], name = 'layer2')Step 5− 완전히 연결된 출력 단계를 위해 출력을 평평하게 만들어 보겠습니다. 28 x 28 크기의 stride 2 풀링의 두 레이어 후 14 x 14 또는 최소 7 x 7 x, y 좌표로 출력 채널. "조밀 한"레이어로 완전히 연결하려면 새 모양이 [-1, 7 x 7 x 64]이어야합니다. 이 레이어에 대한 가중치와 바이어스 값을 설정 한 다음 ReLU로 활성화 할 수 있습니다.
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev = 0.03), name = 'wd1')
bd1 = tf.Variable(tf.truncated_normal([1000], stddev = 0.01), name = 'bd1')
dense_layer1 = tf.matmul(flattened, wd1) + bd1
dense_layer1 = tf.nn.relu(dense_layer1)Step 6 − 필요한 옵티마이 저가있는 특정 소프트 맥스 활성화가있는 또 다른 계층은 정확도 평가를 정의하여 초기화 연산자를 설정합니다.
wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev = 0.03), name = 'wd2')
bd2 = tf.Variable(tf.truncated_normal([10], stddev = 0.01), name = 'bd2')
dense_layer2 = tf.matmul(dense_layer1, wd2) + bd2
y_ = tf.nn.softmax(dense_layer2)
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = dense_layer2, labels = y))
optimiser = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_op = tf.global_variables_initializer()Step 7− 녹화 변수를 설정해야합니다. 이것은 데이터의 정확성을 저장하기 위해 요약을 추가합니다.
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('E:\TensorFlowProject')
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size = batch_size)
_, c = sess.run([optimiser, cross_entropy], feed_dict = {
x:batch_x, y: batch_y})
avg_cost += c / total_batch
test_acc = sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
summary = sess.run(merged, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
writer.add_summary(summary, epoch)
print("\nTraining complete!")
writer.add_graph(sess.graph)
print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels}))
def create_new_conv_layer(
input_data, num_input_channels, num_filters,filter_shape, pool_shape, name):
conv_filt_shape = [
filter_shape[0], filter_shape[1], num_input_channels, num_filters]
weights = tf.Variable(
tf.truncated_normal(conv_filt_shape, stddev = 0.03), name = name+'_W')
bias = tf.Variable(tf.truncated_normal([num_filters]), name = name+'_b')
#Out layer defines the output
out_layer =
tf.nn.conv2d(input_data, weights, [1, 1, 1, 1], padding = 'SAME')
out_layer += bias
out_layer = tf.nn.relu(out_layer)
ksize = [1, pool_shape[0], pool_shape[1], 1]
strides = [1, 2, 2, 1]
out_layer = tf.nn.max_pool(
out_layer, ksize = ksize, strides = strides, padding = 'SAME')
return out_layer
if __name__ == "__main__":
run_cnn()다음은 위의 코드에 의해 생성 된 출력입니다.
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-19 17:22:58.802268: I
T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2
2018-09-19 17:25:41.522845: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.
2018-09-19 17:25:44.630941: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 501760000 exceeds 10% of system memory.
Epoch: 1 cost = 0.676 test accuracy: 0.940
2018-09-19 17:26:51.987554: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.