Analiza dużych zbiorów danych - cykl życia danych
Cykl życia tradycyjnego wyszukiwania danych
Aby zapewnić ramy do organizowania prac potrzebnych organizacji i dostarczać przejrzystych spostrzeżeń z Big Data, warto myśleć o tym jako o cyklu o różnych etapach. W żadnym wypadku nie jest liniowy, co oznacza, że wszystkie etapy są ze sobą powiązane. Ten cykl ma powierzchowne podobieństwa z bardziej tradycyjnym cyklem eksploracji danych, jak opisano wCRISP methodology.
Metodologia CRISP-DM
Plik CRISP-DM methodologyto skrót od Cross Industry Standard Process for Data Mining, to cykl opisujący powszechnie stosowane podejścia, które eksperci od eksploracji danych używają do rozwiązywania problemów w tradycyjnym eksploracji danych BI. Nadal jest używany w tradycyjnych zespołach eksploracji danych BI.
Spójrz na poniższą ilustrację. Pokazuje główne etapy cyklu opisane w metodologii CRISP-DM i ich wzajemne powiązania.
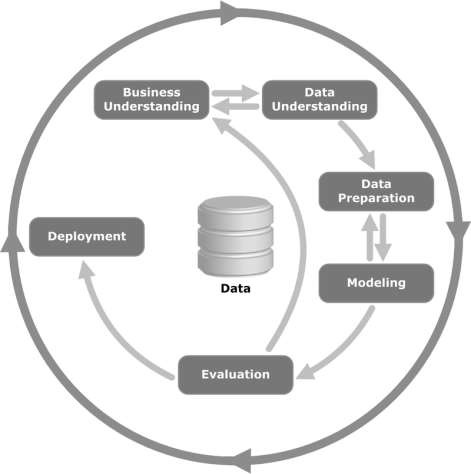
CRISP-DM powstał w 1996 roku, a rok później został uruchomiony jako projekt Unii Europejskiej w ramach inicjatywy ESPRIT. Projekt był prowadzony przez pięć firm: SPSS, Teradata, Daimler AG, NCR Corporation i OHRA (firma ubezpieczeniowa). Projekt został ostatecznie włączony do SPSS. Metodologia jest niezwykle szczegółowa, jeśli chodzi o sposób określenia projektu eksploracji danych.
Dowiemy się teraz trochę więcej na każdym z etapów cyklu życia CRISP-DM -
Business Understanding- Ta początkowa faza koncentruje się na zrozumieniu celów i wymagań projektu z perspektywy biznesowej, a następnie przekształceniu tej wiedzy w definicję problemu eksploracji danych. Wstępny plan ma na celu osiągnięcie celów. Można zastosować model decyzyjny, zwłaszcza zbudowany przy użyciu modelu decyzyjnego i standardu notacji.
Data Understanding - Faza zrozumienia danych rozpoczyna się od wstępnego zebrania danych i przechodzi do działań mających na celu zapoznanie się z danymi, zidentyfikowanie problemów z jakością danych, odkrycie pierwszych spostrzeżeń w danych lub wykrycie interesujących podzbiorów w celu sformułowania hipotez dotyczących ukrytych informacji.
Data Preparation- Faza przygotowania danych obejmuje wszystkie działania mające na celu skonstruowanie ostatecznego zbioru danych (dane, które zostaną wprowadzone do narzędzia (narzędzi) do modelowania) z początkowych surowych danych. Zadania związane z przygotowaniem danych będą prawdopodobnie wykonywane wiele razy, a nie w określonej kolejności. Zadania obejmują wybór tabeli, rekordów i atrybutów, a także transformację i czyszczenie danych na potrzeby narzędzi do modelowania.
Modeling- Na tym etapie wybiera się i stosuje różne techniki modelowania, a ich parametry są kalibrowane do optymalnych wartości. Zwykle istnieje kilka technik dla tego samego typu problemu eksploracji danych. Niektóre techniki mają określone wymagania dotyczące formy danych. Dlatego często trzeba cofnąć się do fazy przygotowania danych.
Evaluation- Na tym etapie projektu zbudowałeś model (lub modele), który wydaje się być wysokiej jakości z punktu widzenia analizy danych. Przed przystąpieniem do ostatecznego wdrożenia modelu ważne jest, aby dokładnie ocenić model i przejrzeć kroki wykonane w celu zbudowania modelu, aby mieć pewność, że prawidłowo realizuje cele biznesowe.
Kluczowym celem jest ustalenie, czy istnieje jakaś ważna kwestia biznesowa, która nie została dostatecznie rozważona. Pod koniec tej fazy powinna zapaść decyzja o wykorzystaniu wyników eksploracji danych.
Deployment- Tworzenie modelu to generalnie nie koniec projektu. Nawet jeśli celem modelu jest poszerzenie wiedzy o danych, zdobytą wiedzę trzeba będzie uporządkować i zaprezentować w sposób użyteczny dla klienta.
W zależności od wymagań faza wdrażania może być tak prosta, jak wygenerowanie raportu lub złożona, jak wdrożenie powtarzalnej oceny danych (np. Alokacja segmentu) lub proces eksploracji danych.
W wielu przypadkach to klient, a nie analityk danych, będzie wykonywał etapy wdrożenia. Nawet jeśli analityk wdroży model, ważne jest, aby klient z góry zrozumiał działania, które będzie musiał wykonać, aby faktycznie skorzystać z utworzonych modeli.
Metodologia SEMMA
SEMMA to kolejna metodologia opracowana przez SAS do modelowania eksploracji danych. To znaczySobszerny, Explore, Modify, Model i Asses. Oto krótki opis jego etapów -
Sample- Proces rozpoczyna się od próbkowania danych, np. Wyboru zbioru danych do modelowania. Zbiór danych powinien być wystarczająco duży, aby zawierał wystarczającą ilość informacji do pobrania, a jednocześnie wystarczająco mały, aby można go było efektywnie wykorzystać. Ta faza dotyczy również partycjonowania danych.
Explore - Faza ta obejmuje zrozumienie danych poprzez odkrycie przewidywanych i nieoczekiwanych relacji między zmiennymi, a także nieprawidłowości, za pomocą wizualizacji danych.
Modify - Faza modyfikacji obejmuje metody wybierania, tworzenia i transformowania zmiennych w ramach przygotowań do modelowania danych.
Model - W fazie Modelu nacisk kładziony jest na zastosowanie różnych technik modelowania (eksploracji danych) na przygotowanych zmiennych w celu stworzenia modeli, które mogą zapewnić pożądany wynik.
Assess - Ocena wyników modelowania wskazuje na rzetelność i użyteczność utworzonych modeli.
Główna różnica między CRISM-DM i SEMMA polega na tym, że SEMMA skupia się na aspekcie modelowania, podczas gdy CRISP-DM przywiązuje większą wagę do etapów cyklu poprzedzających modelowanie, takich jak zrozumienie problemu biznesowego do rozwiązania, zrozumienie i wstępne przetwarzanie danych, które mają być używane jako dane wejściowe, na przykład algorytmy uczenia maszynowego.
Cykl życia Big Data
W dzisiejszym kontekście dużych zbiorów danych poprzednie podejścia są albo niekompletne, albo nieoptymalne. Na przykład metodologia SEMMA całkowicie pomija gromadzenie danych i wstępne przetwarzanie różnych źródeł danych. Te etapy zwykle stanowią większość pracy w udanym projekcie Big Data.
Cykl analizy danych big data można opisać następującym etapem -
- Definicja problemu biznesowego
- Research
- Ocena zasobów ludzkich
- Pozyskiwanie danych
- Bezpowrotnie zniszczenie lub zmiana danych
- Przechowywanie danych
- Analiza danych rozpoznawczych
- Przygotowanie danych do modelowania i oceny
- Modeling
- Implementation
W tej sekcji rzucimy nieco światła na każdy z tych etapów cyklu życia dużych zbiorów danych.
Definicja problemu biznesowego
Jest to punkt wspólny w tradycyjnym cyklu życia BI i analizy dużych zbiorów danych. Zwykle nietrywialnym etapem projektu big data jest zdefiniowanie problemu i poprawna ocena, ile potencjalnych korzyści może on przynieść organizacji. Wspomnienie o tym wydaje się oczywiste, ale należy ocenić, jakie są spodziewane korzyści i koszty projektu.
Badania
Przeanalizuj, co inne firmy zrobiły w tej samej sytuacji. Wiąże się to z poszukiwaniem rozwiązań rozsądnych dla Twojej firmy, nawet jeśli wiąże się to z dostosowaniem innych rozwiązań do zasobów i wymagań, które ma Twoja firma. Na tym etapie należy określić metodologię dla przyszłych etapów.
Ocena zasobów ludzkich
Po zdefiniowaniu problemu rozsądne jest kontynuowanie analizy, czy obecny personel jest w stanie pomyślnie ukończyć projekt. Tradycyjne zespoły BI mogą nie być w stanie zapewnić optymalnego rozwiązania na wszystkich etapach, dlatego przed rozpoczęciem projektu należy rozważyć, czy istnieje potrzeba outsourcingu części projektu lub zatrudnienia większej liczby osób.
Pozyskiwanie danych
Ta sekcja jest kluczowa w cyklu życia dużych zbiorów danych; określa, jaki typ profili byłby potrzebny do dostarczenia wynikowego produktu danych. Gromadzenie danych jest nietrywialnym etapem procesu; zwykle obejmuje gromadzenie nieustrukturyzowanych danych z różnych źródeł. Na przykład może to obejmować napisanie robota indeksującego do pobierania recenzji z witryny internetowej. Obejmuje to zajmowanie się tekstem, być może w różnych językach, które zwykle wymaga dużo czasu na ukończenie.
Bezpowrotnie zniszczenie lub zmiana danych
Po pobraniu danych, na przykład z Internetu, należy je przechowywać w łatwym w użyciu formacie. Kontynuując przykłady recenzji, załóżmy, że dane są pobierane z różnych witryn, z których każda ma inny sposób wyświetlania danych.
Załóżmy, że jedno źródło danych podaje recenzje pod względem ocen w gwiazdkach, dlatego można to odczytać jako mapowanie dla zmiennej odpowiedzi y ∈ {1, 2, 3, 4, 5}. Inne źródło danych podaje recenzje za pomocą systemu dwóch strzałek, jednej do głosowania w górę, a drugiej do głosowania w dół. Oznaczałoby to zmienną odpowiedzi formularzay ∈ {positive, negative}.
Aby połączyć oba źródła danych, należy podjąć decyzję, aby te dwie reprezentacje odpowiedzi były równoważne. Może to obejmować konwersję pierwszej reprezentacji odpowiedzi źródła danych do drugiej postaci, uznając jedną gwiazdę za ujemną, a pięć za pozytywną. Proces ten często wymaga dużej ilości czasu, aby uzyskać dobrą jakość.
Przechowywanie danych
Po przetworzeniu danych czasami trzeba je przechowywać w bazie danych. Technologie Big Data oferują wiele alternatyw w tym zakresie. Najbardziej powszechną alternatywą jest użycie systemu plików Hadoop do przechowywania, który zapewnia użytkownikom ograniczoną wersję SQL, znaną jako język zapytań HIVE. Pozwala to na wykonanie większości zadań analitycznych w podobny sposób, jak w przypadku tradycyjnych hurtowni danych BI, z perspektywy użytkownika. Inne opcje przechowywania, które należy wziąć pod uwagę, to MongoDB, Redis i SPARK.
Ten etap cyklu związany jest ze znajomością zasobów ludzkich w zakresie ich zdolności do implementacji różnych architektur. Zmodyfikowane wersje tradycyjnych hurtowni danych są nadal używane w aplikacjach na dużą skalę. Na przykład teradata i IBM oferują bazy danych SQL, które mogą obsługiwać terabajty danych; Rozwiązania open source, takie jak postgreSQL i MySQL, są nadal używane w aplikacjach na dużą skalę.
Chociaż istnieją różnice w sposobie działania różnych magazynów w tle, po stronie klienta większość rozwiązań udostępnia interfejs API SQL. Dlatego dobra znajomość SQL jest nadal kluczową umiejętnością do analizy dużych zbiorów danych.
Ten etap a priori wydaje się być tematem najważniejszym, w praktyce nie jest to prawdą. Nie jest to nawet istotny etap. Możliwe jest zaimplementowanie rozwiązania big data, które działałoby na danych czasu rzeczywistego, więc w tym przypadku wystarczy zebrać dane, aby opracować model, a następnie wdrożyć go w czasie rzeczywistym. Nie byłoby więc potrzeby formalnego przechowywania danych w ogóle.
Analiza danych rozpoznawczych
Po wyczyszczeniu i zapisaniu danych w sposób umożliwiający uzyskanie z nich spostrzeżeń faza eksploracji danych jest obowiązkowa. Celem tego etapu jest zrozumienie danych, zwykle odbywa się to za pomocą technik statystycznych, a także wykreślanie danych. Jest to dobry etap do oceny, czy definicja problemu ma sens lub jest wykonalna.
Przygotowanie danych do modelowania i oceny
Ten etap obejmuje przekształcenie oczyszczonych danych odzyskanych wcześniej i wykorzystanie wstępnego przetwarzania statystycznego do imputacji brakujących wartości, wykrywania wartości odstających, normalizacji, ekstrakcji cech i wyboru cech.
Modelowanie
Na wcześniejszym etapie powinno powstać kilka zbiorów danych do szkolenia i testowania, na przykład model predykcyjny. Ten etap polega na wypróbowaniu różnych modeli i oczekiwaniu na rozwiązanie problemu biznesowego. W praktyce normalnie pożądane jest, aby model dawał pewien wgląd w biznes. Na koniec wybierany jest najlepszy model lub kombinacja modeli, oceniając jego wydajność na pominiętym zbiorze danych.
Realizacja
Na tym etapie opracowany produkt danych jest wdrażany w rurociągu danych firmy. Obejmuje to ustawienie schematu walidacji podczas działania produktu danych w celu śledzenia jego wydajności. Na przykład w przypadku wdrażania modelu predykcyjnego etap ten obejmowałby zastosowanie modelu do nowych danych i po uzyskaniu odpowiedzi dokonanie oceny modelu.