Big Data Analytics - wykresy i wykresy
Pierwszym podejściem do analizy danych jest ich wizualna analiza. Celem tego jest zwykle znalezienie relacji między zmiennymi i jednowymiarowych opisów zmiennych. Możemy podzielić te strategie na -
- W analizie jednoczynnikowej
- Analiza wielowymiarowa
Jednowymiarowe metody graficzne
Univariateto termin statystyczny. W praktyce oznacza to, że chcemy analizować zmienną niezależnie od pozostałych danych. Działki, które pozwalają na to sprawnie to -
Wykresy pudełkowe
Wykresy pudełkowe są zwykle używane do porównywania rozkładów. To świetny sposób na wizualne sprawdzenie, czy istnieją różnice między dystrybucjami. Możemy zobaczyć, czy istnieją różnice w cenie diamentów o różnym szlifie.
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)Na wykresie widać różnice w rozkładzie cen diamentów w różnych rodzajach szlifów.

Histogramy
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ .) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ ., scales = 'free') +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()Wynik powyższego kodu będzie następujący -
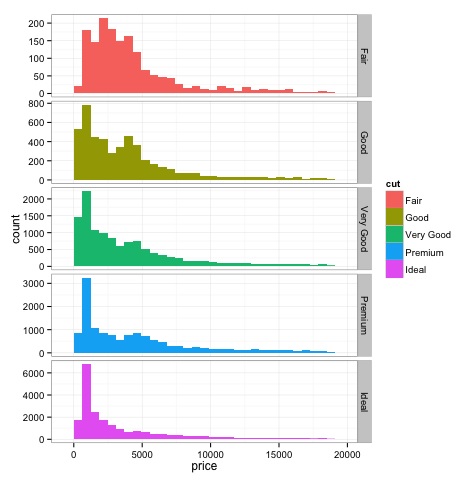
Wielowymiarowe metody graficzne
Wielowymiarowe metody graficzne stosowane w eksploracyjnej analizie danych mają na celu znalezienie zależności między różnymi zmiennymi. Istnieją dwa powszechnie używane sposoby osiągnięcia tego celu: wykreślenie macierzy korelacji zmiennych numerycznych lub po prostu wykreślenie surowych danych jako macierzy wykresów punktowych.
Aby to zademonstrować, użyjemy zestawu danych diamentów. Aby postępować zgodnie z kodem, otwórz skryptbda/part2/charts/03_multivariate_analysis.R.
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)Kod wygeneruje następujący wynik -

To jest podsumowanie, mówi nam, że istnieje silna korelacja między ceną a daszkiem, a niewiele między innymi zmiennymi.
Macierz korelacji może być przydatna, gdy mamy dużą liczbę zmiennych, w którym to przypadku wykreślenie surowych danych nie byłoby praktyczne. Jak wspomniano, możliwe jest również pokazanie surowych danych -
library(GGally)
ggpairs(df)Na wykresie widzimy, że wyniki wyświetlane na mapie ciepła są potwierdzone, istnieje korelacja 0,922 między zmiennymi cenowymi i karatowymi.
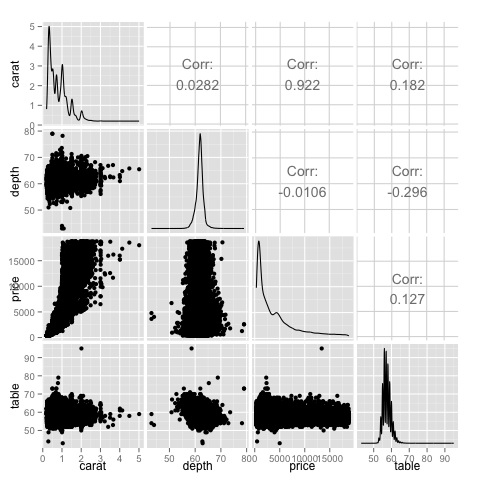
Zależność tę można zwizualizować na wykresie rozrzutu cena-karat znajdującym się w indeksie (3, 1) macierzy wykresu rozrzutu.